融合改进FCM与PFS的知识供需匹配
2023-01-31张建华刘艺琳郭启迪杨俊晓徐佳璐
张建华,刘艺琳,郭启迪,杨俊晓,徐佳璐
(郑州大学 管理工程学院,河南 郑州 450001)
0 引 言
作为隐性知识深度服务体系中的重要一环,知识供需匹配是实现知识应用价值的关键。其以用户需求为出发点,是缓解“知识迷向”问题的一种行之有效的方法,已被广泛应用于医疗[1]、农业[2]、公共交通管理[3]等领域。目前关于知识供需匹配的研究,根据研究范围界定的不同主要集中在以下两个方面:①关于知识自身的供需匹配问题研究,主要聚焦于匹配方法、匹配效果等方面。Wan等采用信息熵描述轨迹的移动频率,并通过构建LightGBM分类模型确定车辆与手机匹配度,提高了算法的有效性[4]。Deng等融合地理信息系统技术和遗传算法,提出了针对空间案例的匹配模型,以此来弥补传统CBR方法未考虑地质环境因素的空间关系的不足,改善了匹配算法的精度与效度[5]。李佳敏等采用三元组深度哈希学习方法将司法案例转化为二进制编码,提高了算法的匹配效率[6]。臧振春等从用户需求出发,采用Vague集语言分别表示用户需求及产品属性,同时兼顾用户兴趣,实现了高效精准的知识需求匹配[7]。②关于知识应用的供需匹配研究,侧重于知识组织服务,集中于知识需求和供给关联体的匹配研究,即如何从众多的知识服务中选择与用户需求最契合的服务。马仁杰等考虑用户需求与既有知识服务属性的不确定性,设计了一套基于区间和灰色关联度的知识服务匹配方法,以区间数表示其不确定性,同时兼顾用户需求偏好,提高了匹配方法的查准率与查全率[8]。关盟等充分考虑用户及服务提供方的利益需求,基于改进i-NSGA-Ⅱ-JG算法构建了服务组合双方互选模型,实现了对用户需求服务的最优选取[9]。郑小雪等基于语言信息和区间数的双边匹配决策方法,有效解决了在跨境电商供应链中对众多服务方的寻优问题[10]。沈明辉等采用医学知识图谱构建交互式可视化知识服务系统,有效提高了医疗就诊的服务效率[11]。陈希等兼顾患者的需求差异,提出了E-HR算法,并构建了考虑患者预约行为的两阶段供需匹配模型,优化了医疗服务的供需匹配决策[12]。
综上所述,既有关于知识供需匹配的研究,在一定程度上改善了知识匹配算法的精度与效率;不过,其也存在如下不足:其一,在运用聚类算法压缩匹配空间时,通过人为设定聚类数目导致算法容错性不高,聚类结果有失客观性,进而影响了匹配精度。其二,在计算相似度时,未充分考虑知识自身的不确定性和模糊性,采用精确的离散化方法进行相似度计算造成知识属性值的信息损失;或者仅以模糊粗糙集为基础,使得相似度计算所蕴含信息不充分,从而导致匹配精度低下。针对既有研究之不足,本文提出以下改进思路:①知识匹配集的确定。首先基于DBSCAN算法确定FCM的最优聚类数目,而后采用改进的FCM算法寻找与用户知识需求最相关的区域,并在该区域内进行相似度计算,以压缩相似度计算空间,减少算法的时间开销。②既有知识与用户知识需求间相似度的测度。将毕达哥拉斯模糊集(pythagorean fuzzy sets, PFS)与Zadeh模糊算子相结合对相似度进行改进,以确保视图相似度计算结果的客观性及可靠性;而后,以PFS相关系数测度两者间的关联度,并将两者融合得到一种新的知识模糊关联匹配度模型,以确定与用户知识需求匹配度最佳的知识。
1 预备知识
1.1 FCM聚类算法
传统聚类算法均属于“硬”划分,即只判定一个对象是否归属于一个类别;然而,在实际应用场景中,存在着许多难以界定的待测对象,无法将其严格划分到某一类中。针对此不足,模糊C均值(fuzzy C-Means,FCM)聚类算法被提出,其基于目标函数最优化来实施聚类,聚类效果更加灵活[13]。FCM聚类算法通过引入模糊隶属度可将一个对象划分到多个类别中,这与实际应用场景更为契合[14]。设C={c1,c2,…,cn} 为论域U上的一个隐性知识外显案例知识集,若将知识集划分为k类,则对应有k个聚类中心,其中μij表示案例Ci属于第k类的隶属度。
1.2 毕达哥拉斯模糊集

2 知识供需匹配算法
知识是以信息为原料,并对其进行深加工而形成的系统化的信息本质与内容(表现为编码后的显性知识)及认知主体技能(隐性知识),是数据和信息的更高层次。在人类的知识结构中,隐性知识占据绝大部分,是实现知识传播及价值创新的主要源泉。隐性知识存储在人的大脑中,基于案例的知识表示方法通过结构化描述知识实现对隐性知识的外显化。该方法以结构化属性集(包括条件属性集与决策属性/集)的形式蕴含表征隐性知识从条件到决策的映射关系,即案例知识 C=(条件属性1,条件属性2,…,条件属性m,决策属性), 并通过权重向量 (w=(w1,w2,w3,…,wm)) 表征各条件属性影响决策属性的程度。知识用户面临新问题或任务时,向隐性知识外显案例库提交知识匹配需求以获取所需知识,是实现非零基高效求解的有效途径。知识供需匹配以用户需求为导向,基于相似度衡量既有隐性知识外显案例间与用户知识需求的匹配程度;相似度越高,表明其与用户需求匹配性越好。
2.1 基于改进FCM算法的知识匹配子集的确定
在知识匹配过程中,知识匹配的效率很大程度上取决于系统知识库的规模,其中包含众多与用户知识需求相似度较小或不相关的知识。传统知识匹配方法大都需遍历全知识库以寻找与用户需求匹配度最高的知识,导致知识匹配的时间成本大大增加。FCM是一种基于目标函数最优的聚类算法,利用微积分求最优代价函数,使得被划分到同一簇的知识之间相似度最大,而不同簇之间的相似度最小,可用于确定与用户知识需求最相关的知识子集,进而提高匹配效率。然而,FCM算法需要预先设置聚类数目和初始聚类中心,初始值的设置会对聚类结果产生影响,且它往往需要使用者事先掌握数据的分布结构,才能确保设置的合理性,进而消减聚类结果对初始值的敏感性。
在实际应用场景中,大多数使用者仅依据主观经验设置聚类数目,欠缺科学性与客观性。DBSCAN(density-based spatial clustering of applications with noise)算法由密度可达关系导出最大密度相连的样本集合,即通过样本分布的紧密程度来判定样本的聚类结果,具有依据对象的空间、非空间和时间值寻找聚类中心的能力[18]。本文引入DBSCAN算法计算待分类知识样本的密度和距离,确定FCM算法的最优的聚类数目,从而避免主观决策的片面性、提升传统FCM算法的聚类效果。
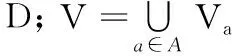
(1)
在此基础上,采用DBSCAN算法确定FCM算法的最优聚类数目。首先给定半径邻域ε以及该邻域内包含的最少样本点数Minpts,而后对于案例知识集U={C1,C2,…,Cn}, 将其聚类中心表示为 {k1,k2,…,kn}, 则对于任意的案例知识Ci∈U, 可得到各条知识间的距离,如式(2)所示
(2)
式中:xij表示第i条知识在属性j上的值,xkj表示聚类中心k所对应的属性值。
进而依据求得的各知识间距离,通过式(3)计算得到第i条知识Ci的密度
(3)
同时,考虑到在运用DBSCAN算法时,所形成的簇中心相较于近邻而言是一个高密度数据点,且与其它簇中心距离较远,故可进一步地计算簇中各点的距离,则较大密度的最小距离可表示为
(4)
若其具有最大局部密度,则上式可转变为
(5)
如此,基于上述公式可计算得到各条知识间的距离及密度,并通过合理设定阈值与参数,得到FCM算法的聚类数目k。而后对所有知识实施聚类,将其划分为k个区域,并保存区域中心及区域半径作为初级分类器(Z,R)={(z1,r1),(z2,r2),…,(zk,rk)}, 其目标函数可表示为
(6)
传统FCM聚类算法仅采用欧式距离来衡量各条知识与聚类中心的距离,其应用于球型结构数据集时聚类效果较优;然而,由于案例知识的属性类别多样化且维度较高,仅采用欧式距离度量很难使数据达到全局一致性,导致聚类效果欠佳。相似度计算方法可有效表示高维度、不同类型的数据间的接近程度,余弦相似度对绝对数值不敏感,可进一步从方向角度评估知识间的相似性,更适用于高维数据空间。不过,传统余弦相似度无法区分各个维度取值成比例变化的两个知识样本。本文对其进行改进,以增强相似度计算的可靠性,并采用改进的余弦相似度来替代欧式距离,以提升FCM算法的聚类效果
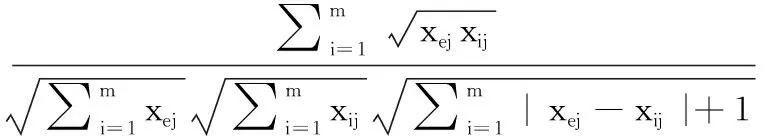
(7)
式中:xej为第e条知识在条件属性j上的属性值。
在此基础上,进一步得到新的FCM算法的目标函数,如式(8)所示
(8)
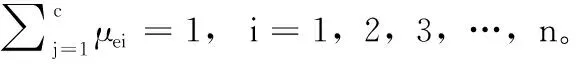
同时,为使聚类效果更优,将聚类中心及半径通过以下公式进行更新
(9)
(10)
式中:n表示案例知识数,β为模糊加权指数,zq为聚类中心。
至此,依据前述计算得到的聚类数目k,设定模糊加权指数β,通过不断迭代使得FCM算法的目标函数达到最小值,从而实现对案例知识集的聚类划分;进而,分别测算用户知识需求与聚类区域间的距离,并对其升序排列,其值最小的区域即为与用户知识需求最相关的知识子集。
基于改进FCM的聚类算法为:
输入:案例知识集U={C1,C2,…,Cn}, 邻域参数ε,Minpts。
输出:聚类中心矩阵和隶属度矩阵。
步骤1 根据式(2)和式(3)分别计算既有知识间的距离以及各条知识的密度。
步骤2 通过距离和密度度量方式,确定知识xi的ε-邻域子样本集N∈(xi), 若子数据集样本个数满足 |N∈(xi)|≥Minpts, 则将知识xi纳入核心对象样本集合: Ω=Ω∪U{xi}。
步骤3 随机选取核心对象o,记为Ωcur={o}, 更新未访问知识集合Γ=Γ-{o}, 若Ωcur为空集,形成聚类簇Ck,记为C={c1,c2,…,ck}, 更新核心对象集合Ω=Ω-Ck, 并转步骤5;否则,转步骤4。
步骤4 在核心对象Ωcur中取出一个核心对象o,依据邻域距离阈值ε确定ε-邻域子样本集N∈(o′), 令Δ=N∈(o′)∩Γ, 更新当前簇样本集合Ck=Ck∪Δ, 更新未访问知识集合Γ=Γ-Δ, 更新Ωcur=Ωcur∪(Δ∩Ω)-o′, 执行步骤3,直至生成聚类簇Ck。
步骤5 依据生成的聚类数目k,设置加权指数m=2, 设置迭代门限次数η。
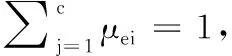
步骤7 通过式(8)计算价值函数。若其小于某个确定的阀值或相对上次价值函数值的改变量小于某个阀值,则算法停止。
步骤8 根据式(10)计算新的隶属矩阵,并返回步骤6,直到算法迭代结束。
综上,通过改进FCM算法对案例知识集实施聚类,横向压缩算法的遍历空间,以简化后续相似度的计算过程,提升匹配算法的效率。
2.2 知识视图相似度的计算
实际应用场景中存在着大量不确定性、不完备性的知识,使其精准地服务于用户需求是实现知识有效配置的关键所在。视图相似度的计算是实施知识供需匹配的重要环节,其值越趋近于1,表明该知识越接近于用户的知识需求。传统的视图相似度算法大多采用精确的离散化方法来表示具有不确定性、模糊性的知识间的相似程度,会导致知识属性的信息缺失;此外,亦有采用以模糊粗糙集为理论基础的Zadeh模糊贴近度来衡量既有知识与用户需求两个模糊集之间的相似度,其以隶属度表示“是”与“否”两方面的信息,却欠缺语义的包容性。毕达哥拉斯模糊集兼顾隶属度、非隶属度及犹豫度三方面信息,更符合模糊决策规律;并且,相较于直觉模糊集,PFS既能解释隶属度与非隶属度之和不大于1的情况,又能描述隶属度与非隶属度之和大于1的现象,其蕴含的特征信息较多,适用范围更广。
在知识匹配过程中往往会出现许多知识属性值的隶属度与非隶属度之和大于1的现象,若仅采用传统相似度计算方法,会导致相似度结果失真,进而影响匹配算法的准确性。因此,本文利用PFS在处理不确定性知识时的优势,将其与Zadeh模糊算子相结合,衡量用户知识需求与既有知识之间的相似性,以此弥补传统模糊集与直觉模糊集表达范围受限的不足。在此基础上,兼顾知识属性成分对匹配结果的影响,引入知识属性权重向量,得到用户需求与既有知识间的视图相似度,提高计算结果的准确性与客观性,进而提升匹配算法的精度。
(1)基于Zadeh-PFS模糊算子的相似度计算
(11)
(12)
采用熵权法计算知识的条件属性权重,其计算公式如式(13)和式(14)所示。在此基础上,得到用户知识需求与既有知识间的视图相似度Sim(Cq,Ci)
(13)
(14)
(15)
(2)知识相关度计算
基于视图相似度可定位与用户知识需求相似的知识,然而在实际应用场景中,不完全相似但存在一定相关度的知识才更有利于用户进行知识创新。简言之,与用户知识需求既相似又相关的知识可更有效地满足用户的需求,进而最大程度地实现知识的应用价值。故本文采用PFS相关系数来测度用户知识需求与既有知识间的相关度,计算公式如下
(16)
式中: E(Cq) 表示Cq的信息量, Corr(Cq,Ci) 为用户知识需求与既有知识间的相关指标, ρ(Cq,Ci) 表示两者间的相关系数。
在此基础上,本文将基于Zadeh-PFS模糊算子的视图相似度与两者之间的关联度相融合,构建知识模糊关联匹配度模型,得到既有知识与用户需求间的匹配度
S(Cq,Ci)=γSim(Cq,Ci)+(1-γ)ρ(Cq,Ci)
(17)
其中, S(Cq,Ci) 为匹配度, Sim(Cq,Ci) 为基于Zadeh-PFS模糊算子的相似度, ρ(Cq,Ci) 为相关度,γ为调节因子, γ∈[0,1]。
综上,本文在既有研究的基础上,设计了一套知识供需匹配方法,以期提高知识匹配的效率与精度,进而提高知识用户满意度。该方法的具体过程如下:①首先基于案例知识表示法实现隐性知识外显化,并构建知识表达系统。②采用DBSCAN算法计算既有知识间的距离及密度以确定FCM算法的最佳聚类数目,而后运用改进FCM聚类算法对知识全库实施区域划分,寻找与用户知识需求最相关的聚类区域,得到与用户知识需求相匹配的知识子集。③采用PFS模糊数表征知识的各属性值,并将PFS与Zadeh模糊算子相融合改进属性相似度计算;而后,引入熵权法计算属性权重,得到用户需求与知识间的视图相似度;在此基础上,以PFS相关系数测度两者间的关联度,并将其与前述视图相似度相融合得到既有知识与用户需求间的匹配度。④将计算得到的匹配度与预设匹配阈值相比较,若匹配度为1,则将该条知识直接提交给用户;若匹配度小于1但大于匹配阈值,则对其进行降序排列,将与用户需求匹配度最高的知识提交给用户,同时辅助推荐高于匹配阈值的其它知识,以支撑用户后续的多案例诱导型适配(已另文探讨);若所有匹配度均小于匹配阈值,则匹配失败。
3 实证分析
本文实验数据来源于加州大学欧文分校创建的UCI数据库,目前共包含488个数据集,它是一个标准测试数据库。本文选用“wine”数据集(含13个条件属性、1个决策属性),共178条红酒的样本数据,实验环境为Intel core i5处理器、8 GB内存,windows10(64 bit)操作系统,利用MATLAB R2014a软件测试本文所提知识供需匹配算法的效果。
首先,采用基于案例的知识表示方法实现隐性知识外显化,将wine数据集的每一行视为一个外显案例,并将其转化到m维向量空间中,则该案例库可转化为n×m阶矩阵。其中,案例知识Ci的属性值向量为Ci={xi1,xi2,…,xij,…,xim}。 假设知识用户面临待解问题(发出一条知识需求), Cq=(0.74,0.18,0.66,0.34,0.26,0.51,0.56,0.17,0.59,0.37,0.62,0.77,0.70,dq)。 通过应用本文的知识供需匹配方法,寻找与用户知识需求最接近的案例知识,从而实现对待解问题的求解(确定dq)。
在确定知识匹配子集的过程中,分别设置邻域参数ε=0.15、0.25、0.5,Minpts=3、4、5,并依据式(2)~式(6)计算既有知识间的距离及密度,同时分别在不同的邻域参数下确定邻域核心对象,不断访问知识集,并进行迭代更新,直至生成稳定的聚类簇数目,而后对聚类结果进行比较,最终得到FCM算法的较优聚类数目,结果如图1所示。
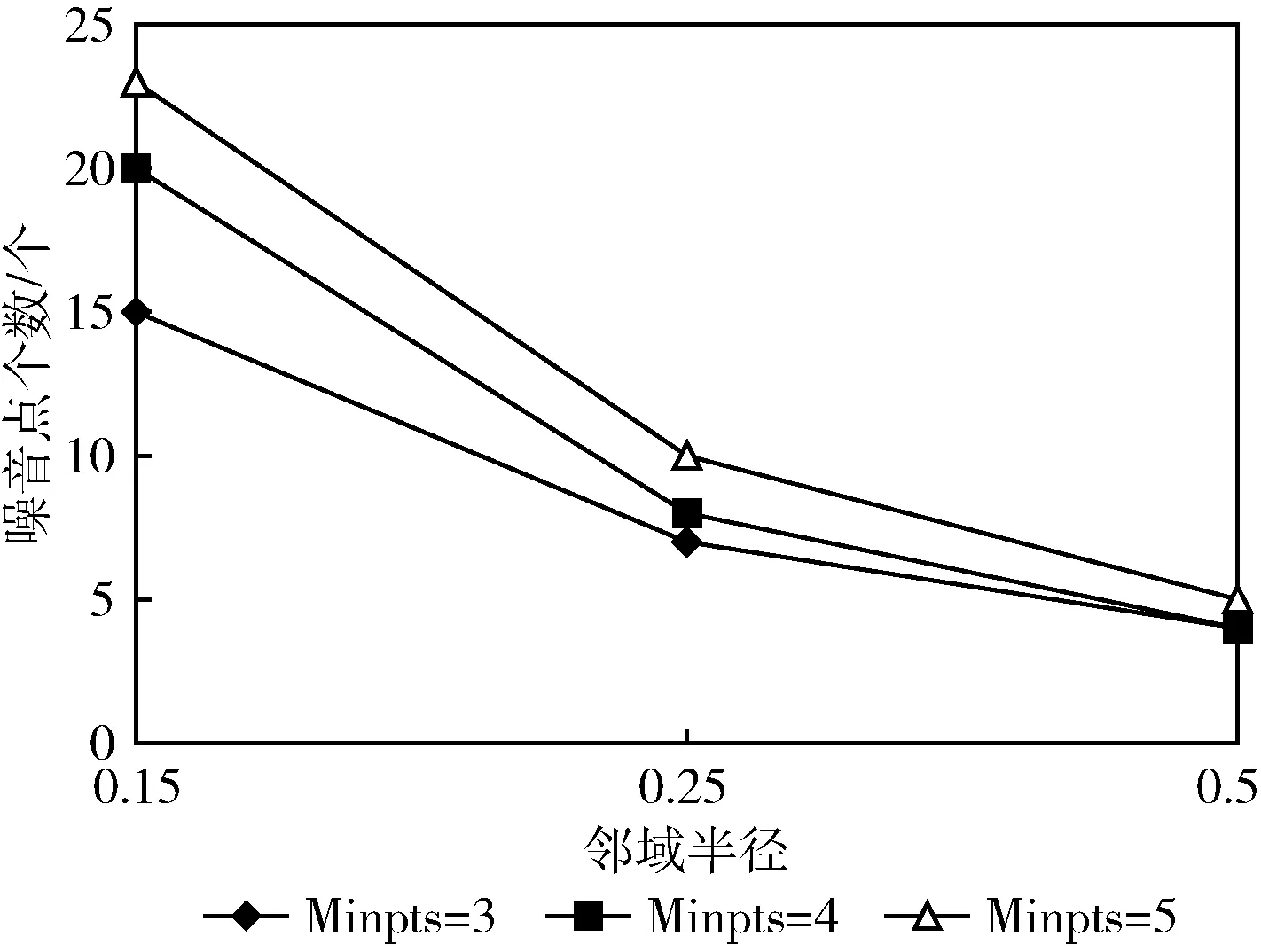
图1 聚类结果对比
由图1可知,当ε=0.5,Minpts=3时,噪音点个数最少,此时案例知识集被分为3类,效果达到最优。因此设置该数据集的聚类数k=3,模糊加权指数β=2(由文献[19]可知,当β=2时聚类效果最佳),而后采用改进的FCM算法对知识全库实施聚类,得到各区域的聚类中心,并分别计算用户知识需求与各聚类区域中心的距离(结果见表1),以确定与用户知识需求最相近的区域。
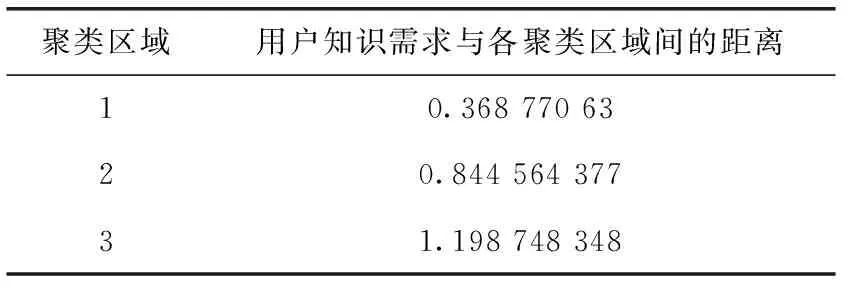
表1 用户知识需求与各聚类区域间的距离
可以看出,用户知识需求与聚类区域1间的距离最短。如此在后续的相似度计算过程中,仅需计算该区域内的各条知识(共61条,部分数据见表2)与用户需求间的匹配度,即可确定与用户需求匹配度最高的知识。显然,对比传统算法的全库遍历,实施聚类区域划分压缩了计算空间,简化了后续计算过程,降低了匹配算法的时间成本。
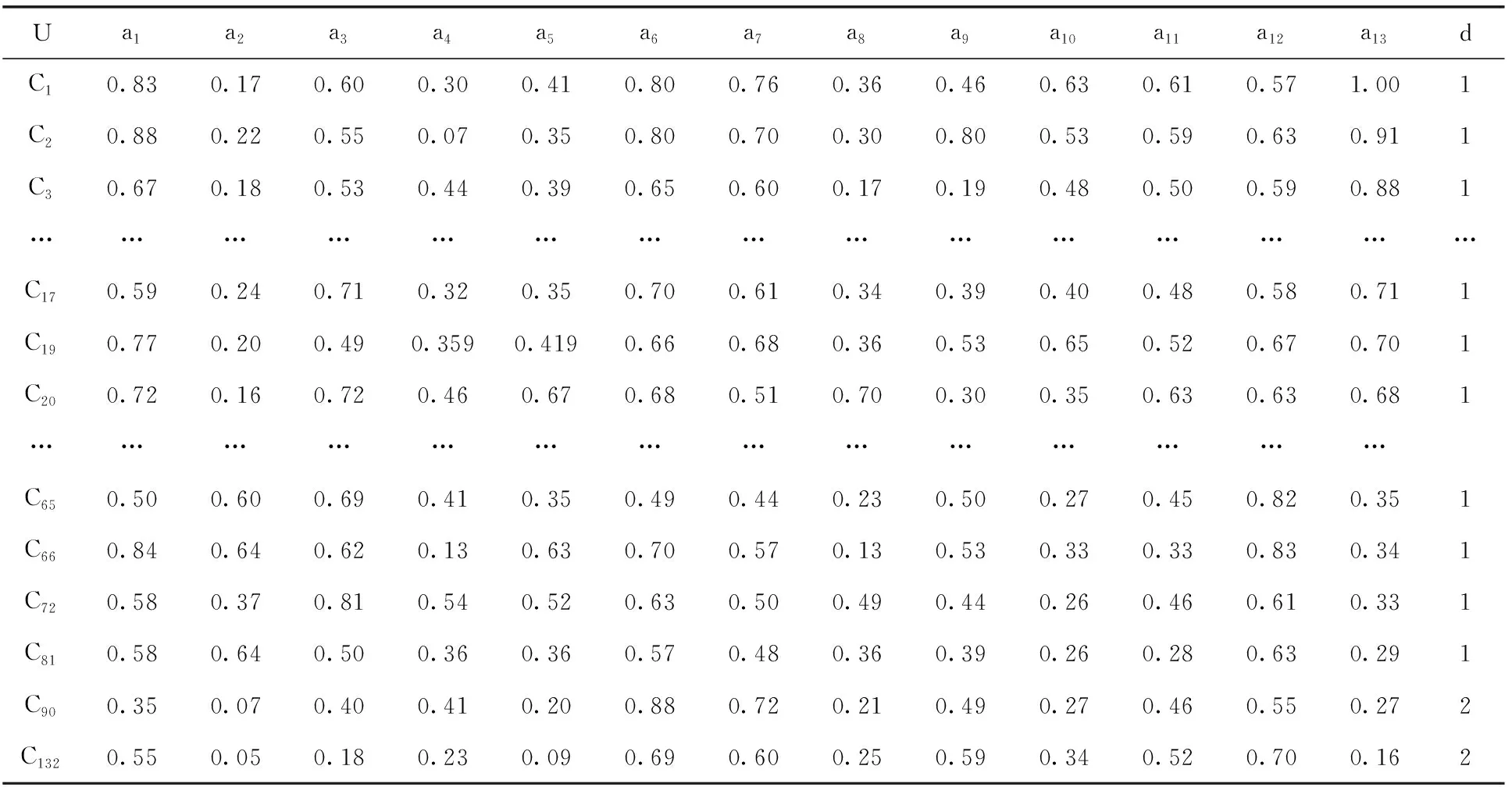
表2 聚类区域1知识子集(部分)
采用熵权法计算知识视图中各个条件属性的权重,最终得到权重向量为wj=(0.003,0.153,0.01,0.022,0.014,0.056,0.193,0.086,0.095,0.146,0.043,0.057,0.124)。 而后采用PFS模糊数表征用户知识需求及既有知识的特征值,其中用户的知识需求矩阵转化为: Cq={<0.263,0.737>,<0.820,0.180>,<0.337,0.663>,<0.660,0.340>,<0.739,0.261>,<0.493,0.507>,<0.441,0.559>,<0.830,0.170>,<0.407,0.593>,<0.631,0.369>,<0.382,0.618>,<0.231,0.769>,<0.296,0.704>}。
继而,依据本文所提出的Zadeh-PFS模糊相似度算法,计算既有知识与用户知识需求间的属性相似度,并将其与对应权重相乘,得到两者间视图相似度。限于篇幅仅列出对视图相似度降序排列后的前12条知识,结果见表3。

表3 用户知识需求与既有知识间的视图相似度(TOP12)
根据式(16)分别计算用户各知识需求与既有知识间的相关度(仅列出对相关度降序排列后的前12条知识),结果见表4。
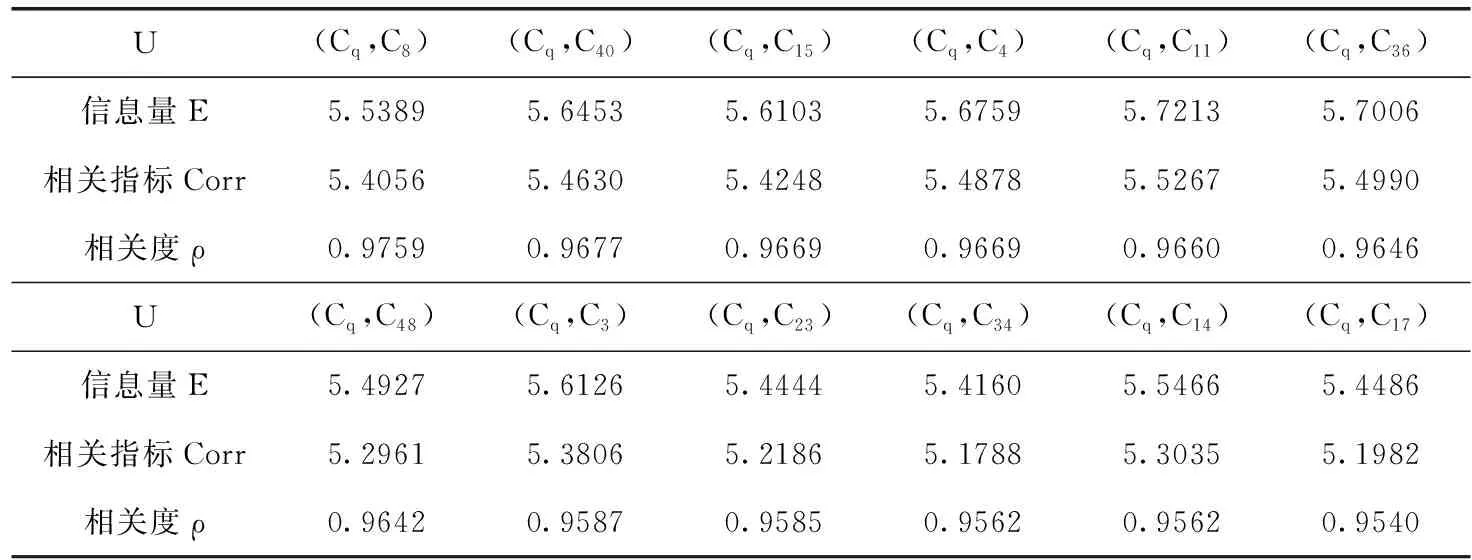
表4 用户知识需求与既有知识间的相关度(TOP12)
兼顾用户知识需求与既有知识间的相似度与相关度,设定调节因子γ=0.5, 依据式(17)得到融合的匹配度,并对其进行降序排列。在实践应用中,很难从系统知识库中匹配出完全满足用户需求的知识(也即S(Cq,Ci)=1)。 故本文通过设置匹配阈值为0.87,寻找与用户知识需求匹配程度足够高的知识,将匹配度最高且大于匹配阈值的知识提交给用户,其它满足匹配阈值的知识推荐给用户,以支撑用户实施后续的多案例诱导适配,计算结果见表5。
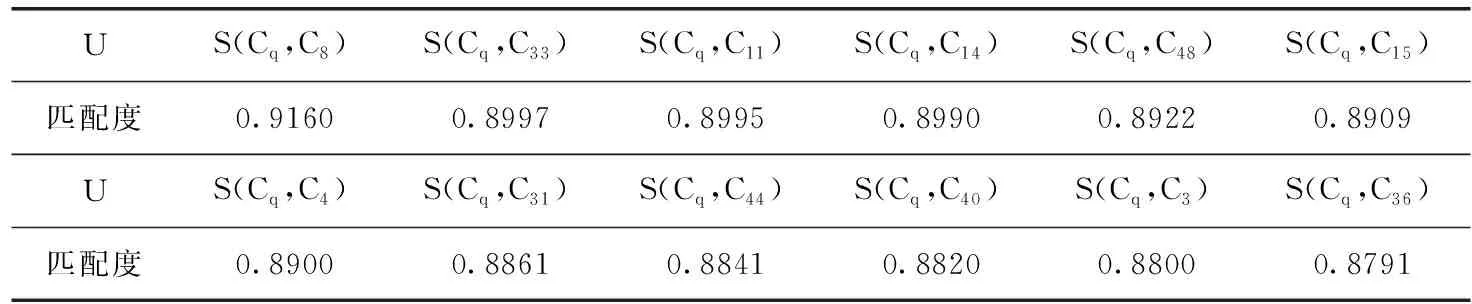
表5 用户知识需求与既有知识间的匹配度(TOP12)
为验证本文所提知识供需匹配算法的有效性,将其与基于Zadeh-PFS的相似度算法、基于Zadeh算子的相似度算法及基于欧氏距离的知识匹配算法进行对比验证。其中,基于Zadeh-PFS的相似度算法未考虑用户知识需求与既有知识间的相关度(未计算PFS相关系数),基于Zadeh算子的匹配算法仅采用Zadeh算子计算相似度且未进行相关度的测度(仅采用隶属度来衡量相似度,未将非隶属度与犹豫度纳入计算),基于欧式距离(仅通过计算各属性与用户知识需求在特征值方面上的距离远近)的匹配算法未考虑知识系统的非完备性,直接对知识属性值进行离散化处理,其计算结果见表6。
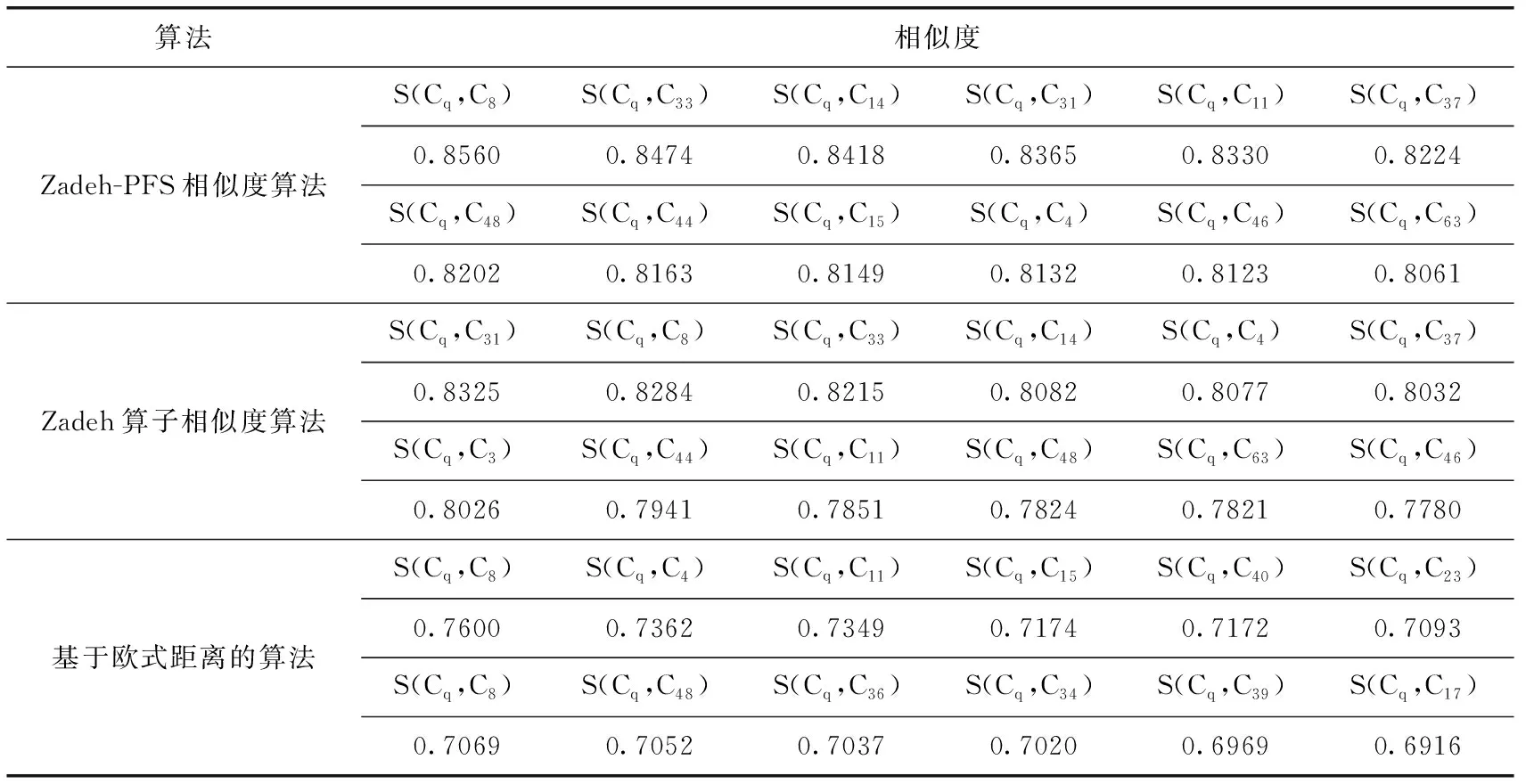
表6 3种传统方法下的视图相似度
从上述实验分析结果可知,本文算法的知识匹配度明显大于前述3种算法,匹配效果较优。究其原因,对比Zadeh-PFS的相似度算法与Zadeh算子的相似度算法,本文兼顾用户知识需求与既有知识间的相似度与相关度,从而使匹配度计算结果蕴含的特征信息更加完备,区分度更优。相较于传统算法,本文利用PFS在描述不确定知识时具有的优势,采用PFS模糊数表征知识属性值,弥补了Zadeh模糊算子表达范围受限的不足,从而使匹配度计算结果更加准确、客观。
综上可知,相较于既有算法,本文所提的融合改进FCM与Zadeh-PFS的知识供需匹配算法,具有一定的有效性与进步性,其比较优势如下:
(1)传统知识供需匹配算法需遍历知识全库以确定与用户需求匹配度最高的知识,效率相对低下;或者通过人为设定聚类算法的聚类数目来进行区域划分,导致聚类效果欠佳,从而使得匹配结果有失客观性。本文首先采用基于密度的DBSCAN算法,并依据既有知识间的距离及密度,确定了较为客观合理的聚类数目,而后采用改进的余弦相似度代替传统FCM算法中的欧式距离,弥补了传统算法中仅采用欧式距离计算的不足,优化了聚类效果。
(2)相较传统的相似度计算方法,本文首先考虑知识表达系统的不完备及不确定性,为减少离散化处理所造成的信息损失,采用PFS模糊数表征知识属性特征值,并将其与Zadeh模糊算子相结合,提升了视图相似度的区分度;而后兼顾相似度与相关度测度,使匹配度计算结果蕴含的特征信息更加完备,从而确保计算结果的可靠性、准确性,提高了知识供需匹配算法的精度。本文算法的匹配结果与其它算法的匹配结果对比如图2所示,可见本文算法的匹配精度均高于其它3种算法,表明其区分度更优,能够更好地满足知识用户需求。
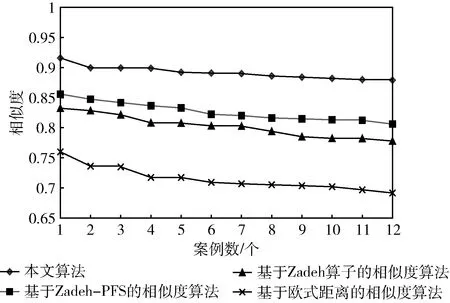
图2 匹配结果对比
4 结束语
得益于信息技术的发展,知识体量不断增加,知识供需匹配问题也日渐显现。本文设计了一套知识供需匹配算法,以提高知识获取及重用的效益。为提高知识匹配算法的效率及其容错性,首先基于DBSCAN算法确定FCM算法的聚类数目,而后采用改进的FCM聚类算法实施区域划分,横向压缩匹配空间,以降低算法的时间成本,提升算法的有效性;为确保知识视图相似度具有更好的区分度,首先将知识属性值转化为PFS模糊数,有效地避免了离散化处理所造成的信息损失,之后将其与Zadeh模糊算子融合对视图相似度进行改进,同时兼顾用户需求与知识间的相关度,构建模糊关联匹配度模型,以提升匹配算法的精确度。不过,本文在计算视图相似度时,仅采用单一的知识属性赋权方式,在后续的研究中可通过多种赋权方法相结合以进一步确保赋权结果的客观性。
