基于LBP特征和权重最优下的CNN人脸表情识别
2023-01-31冯宇平逄腾飞管玉宇赵德钊
冯宇平 逄腾飞 管玉宇 刘 宁 赵德钊
(青岛科技大学自动化与电子工程学院 山东 青岛 266061)
0 引 言
丰富的表情变化是人类社会交流中不可或缺的一部分,表情能够传达出很多平时无法用语言代替的信息,如何使机器高效地“理解”人类表达的表情信息在如今人工智能大潮中具有重要的研究意义。早在20世纪70年代,Ekman等[1]研究学者就已经将人类表情进行了细微的划分,并将人类表情具体地划分了六种不同的表达,即生气、憎恶、恐惧、开心、悲伤和惊讶,这为表情研究开辟了划时代的意义,表情识别研究也如同雨后春芽般发展起来。
近年来,随着计算机算力的高度飞跃以及深度学习的飞速发展,人脸表情识别也被越来越多的研究学者所关注,人脸表情识别领域也开启了新的大门。表情识别的研究根据方法不同分为两大类:基于传统算法的表情识别和基于深度学习的表情识别。基于传统算法的表情识别是利用传统算法检测,然后提取表情信息,最后进行分类。常用的传统表情识别算法有局部二值模式(LBP)[2]、Gabor小波法[3]和尺度不变特征变换(Scale Invariant Feature Transform,SIFT)[4-5]等,这些算法都在当时取得了良好的效果。文献[6]将人脸表情通过LBP处理得到具有辨识性的纹理特征,然后利用增强局部特征的支持向量机(Support Vector Machine,SVM)作为分类器,该方法在CK+数据集中的识别率为91.4%;莫修飞[7]采用Fisher准则[8]选取15个特征代表点表征图像,然后利用SIFT算法提取表情特征,最后采用权重投票机制(WMV)进行分类,该方法在JAFFE数据集上取得了良好的识别效果;杨凡等[9]重新定义Gabor参数矩阵,并结合Adboost算法来构建分类器,该方法平均的识别率为88%左右。传统的人脸表情算法提取的特征属于浅层特征,不能更加深入地提取高语义特征,而且必须结合手工特征的帮助,标注特征繁杂,在如今大数据的背景下,传统提取特征算法显得略有不足。深度学习表情识别算法的常用模型主要有CNN、深度置信网络(Deep Belief Networks,DBNs)和堆叠式自动编码器(Stacked Auto-encoder,SAE)等[10],这些深度学习的模型能够更好地解决传统手工提取特征的缺点,甚至能够提取人类肉眼无法查别的深层特征。也有很多学者将传统特征提取算法与深度学习相结合,将人脸表情识别领域推向了一个新的高度,使得人脸表情的识别率不断地提升。文献[11]提出了一种两阶段CNN级联的结构:在第一阶段使用VGG16网络提取视频序列中人脸的自然特征和充分的表情特征,第二阶段加入多个卷积层和全连接层提取两种表情的不同特征来进行分类,该方法在CK+数据集取得了95.4%的识别率。文献[12]采用三种不同的CNN模型,比较了浅层CNN、双通道CNN和预训练CNN模型的不同识别效果,其中浅层CNN在CK+和FER2013数据集分别取得了92.86%和68%的识别率,但是该文将实验数据集FER2013做了镜像的数据增强且浅层CNN仅卷积层数目也多达18层。张俞晴等[13]采用SIFT算法提取局部特征,并将在CNN中得到的全局特征进行融合,最后利用Softmax进行分类,该方法在CK+和FER2013数据集上分别取得了95.4%和68.1%的识别率。
以上的方法都取得了不错的识别效果,但是文献[12]扩充了数据集的大小,文献[11]和文献[12]使用了大规模的网络模型,都使得训练时间过长,同时识别率还有进一步提升空间。为此为了避免一味追求高准确率而不断扩充实验数据集大小或者增加网络模型深度的缺点,本文不再改动实验数据集样本数量,但是将样本的呈现顺序进行随机打乱训练并验证,同时创建了仅含有5个卷积层的CNN模型,使网络训练速度变快,并且借鉴了将传统LBP算法和CNN相结合的策略,采用SGD算法进行模型权重更新,选取权重最优的CNN模型,最后在CK+与FER2013数据集做了仿真实验,经过与多个文献方法对比,本文方法在训练时间较短的情况下,提高了表情的识别效果。
1 实验表情数据集介绍
1.1 CK+表情数据集
CK+表情数据集是人脸表情识别领域的开源库之一,可以供用户免费下载使用,该数据集创建于2010年,是在数据集Cohn-Kanade Dataset的基础上添加动态视频序列变化而来的,该数据集包含123名参与者,共含有593个图片序列,每名参与者都包含7种带有表情标签的表情序列,图片大小为640×490,图1选取了部分参与者不同表情的实例图片。

图1 CK+数据集部分参与者图片
1.2 FER2013表情数据集
FER2013表情数据集是由Kaggle公司在2013年的比赛提供的,该数据集图片大小均为48×48,全部为统一的灰度图像。数据集包含具有一定差异的35 886幅人脸表情图片,同样含有7种不同的面部表情,由标签0-6组成,每种表情的数量各不相同,最少的与最多的表情图片数量相差十几倍,图2清晰地显示了每种表情的数量差距。

图2 FER2013数据集构成图
图3选取了数据集中的部分图片,可以看出FER2013数据集参与者种族、年龄差距跨度大,图片背景信息参差不齐,图片没有经过特意的预处理矫正,更甚至有些图片并不是人脸表情图片并且有些图片的标签也存在错误。因为该数据集样本不是经过实验室环境下准确获取,所以数据集要求网络的泛化能力和鲁棒性能必须强大,很多文献在该数据集上的识别率并不是很高。本文选取了以上两种数据集作为实验数据集,确保了网络模型的可靠性。

图3 FER2013数据集部分示例图片
2 LBP和权重最优下的CNN识别模型
原始的表情数据集图片包含许多无用的背景信息,并且图片特征单一,本文首先对图片进行预处理,然后使用LBP算法提取图片的纹理特征,并且与CNN进行级联,创建了具有权重更迭的CNN模型。该模型能够准确地训练网络,得到更好的识别效果。本文算法的总体流程如图4所示。
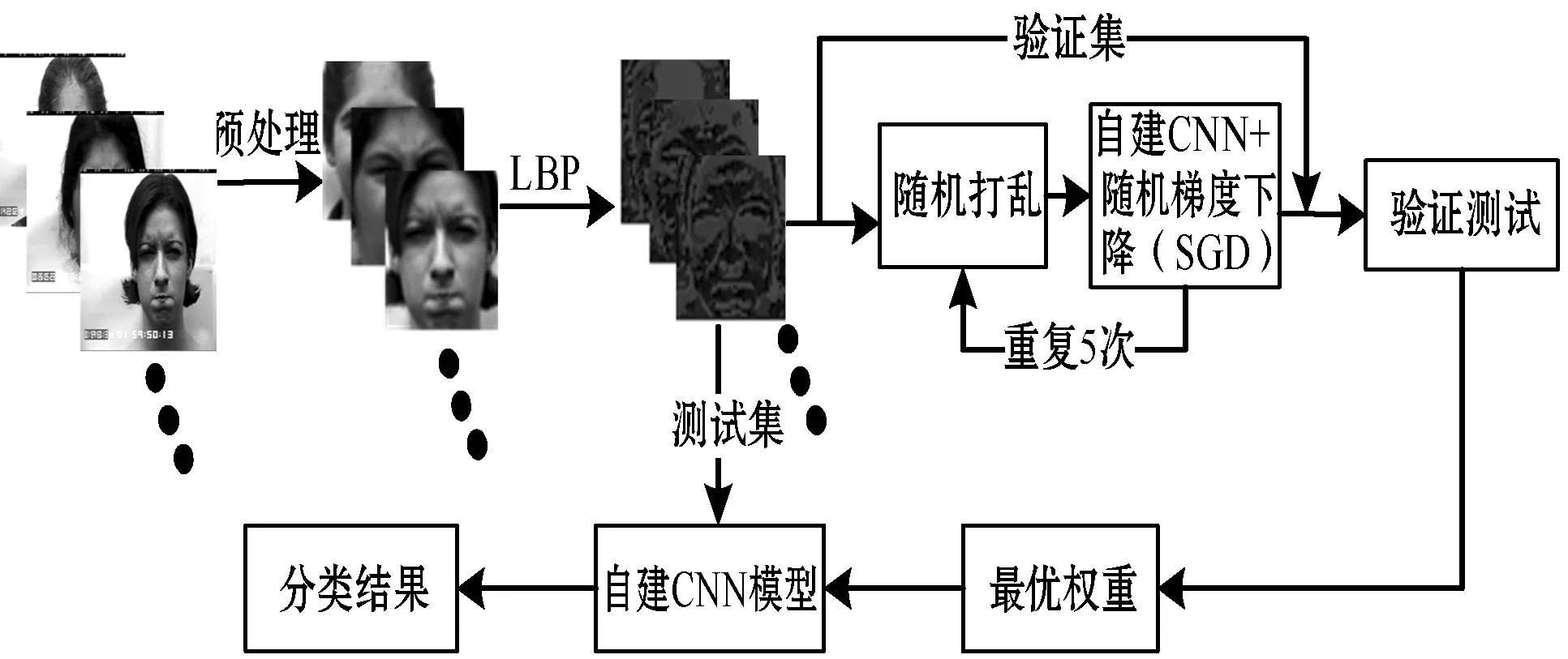
图4 LBP和权重最优下的CNN算法流程
2.1 数据集图像预处理
原始的表情数据集背景尺寸宽,包含拍摄时的一些与表情特征无关的信息,比如图片背景、配饰、头发等,这些都会在一定程度上影响识别的结果,所以本文对这些信息进行了剔除,只保留了与表情相关的有用信息,然后对图片进行了像素的归一化操作,将两个数据集的图片的像素都变为44×44。图5显示了数据集预处理前后的差异。
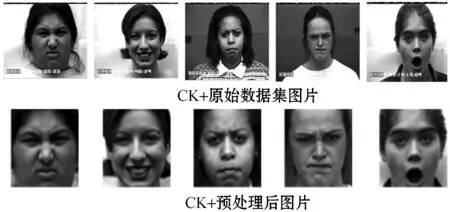
图5 CK+数据集预处理前后图片
2.2 LBP特征提取
LBP特征是在20世纪末被学者Ojala等[14]研究得到的,与SIFT和HOG算法一样,都可以提取图片的局部特征,并且不受旋转和灰度变化的影响。使用LBP算子能够更好地利用图片的浅层特征,同时可以提高CNN的训练速度和识别效果。
2.2.1LBP算子原理
最初的LBP算子定义在一个3×3的方形框内,把框内区域的中心点像素视作基准点,剩余8个像素点的灰度值与中心点像素做差值,根据差值的大小分别将对应像素点标记为1或0,依次排列构成一个8位二进制数,该值的大小等于LBP算子值,如图6所示。

图6 LBP算子模型
2.2.2不同的LBP算子
由图6可以看出,最初的LBP算子只能在固定的区域内运算,然而不同的图片尺寸、频率纹理各不相同,这就使研究学者再次创新了LBP算子,将原始的3×3正方形框拓展到n×n的圆形区域,改进的圆形LBP算子在半径R区域内可以含有任意多的P个采样点,称为Circular LBP,并由符号LBPP,R表示,图7中定义了三种不同的圆形算子。

(a) LBP8,1 (b) LBP8,2(c) LBP16,2图7 Circular LBP算子模型
由图7(a)可以看出,里面包含8个黑色采样点,每个采样点的位置坐标如式(1)所示。
(1)
式中:(xc,yc)是圆点,(xp,yp)是黑色的某个采样点。采样点的位置坐标可能会出现小数,所以可以用双线性插值来取整,如式(2)所示。

(2)
之后,许多改进的LBP算法也层出不穷,例如Uniform Pattern LBP等价模式、MB-LBP(Multiscale Block LBP)特征和LBPH特征向量等,本文通过比较采用了Circular LBP算法,将预处理好的数据集进行了LBP特征提取,并通过多次实验比较了LBP(P=8,R=1)、LBP(P=8,R=3)和LBP(P=6,R=1)时不同的表情识别效果,选取了最优的半径R和采样点P,即P=6、R=1时结果最佳。提取的特征图片如图8所示。

图8 不同LBP特征提取图
2.3 卷积神经网络
CNN模型是机器学习中最常用的前馈神经网络模型,特别对于大规模的图片处理有着强大的功能。CNN的多层结构使得它具有自主学习能力,并不断更新网络参数,最后得到良好的识别效果。CNN模型的结构主要有输入层、卷积层、池化层、激活函数、全连接层和输出层等[15],下面介绍CNN的主要层特点及作用。
2.3.1卷积层
卷积层主要负责执行卷积的运算,它可以使图片的某些原始特征得到加强,并降低了图片的噪声,一幅图片经过卷积运算之后得到的输出值是线性的,它必须将输出经过激励函数来实现非线性表达,使数据更加复杂,卷积层的操作公式为:
Gi=f(Gi-1*ωi+bi)
(3)
式中:Gi代表第i个卷积层;f代表卷积后的激活函数;ωi代表第i个卷积层的权重参数;bi代表偏移量;*表示卷积的乘法运算。
2.3.2池化层
池化层就是将上层卷积操作后的特征进行聚合,主要操作为下采样[16],池化层不会产生新的训练参数,而且下采样更简化了网络的规模,本文采取了最大池化操作,可以提取特征图中每一块最大的特征值,最大池化的运算如式(4)所示。
Gi=max sample(Gi-1)
(4)
式中:Gi代表第i个下采样层;maxsample代表最大池化操作。
2.3.3激活函数
激活函数是CNN模型中很重要的一个单元,随着CNN网络模型的逐渐成熟,激活函数也更新得很快,它可以使网络引入非线性因素,使模型不再单一,而且更加复杂化,有利于网络更好地学习。本文选用了ReLU激活函数[17],它的计算公式为:
f(x)=max(0,x)
(5)
2.3.4全连接层
在CNN模型中,全连接层往往出现在最后几层,目的是将前面设计的特征进行加权,并且实现分类,全连接层每个节点都与前层的节点进行连接,这就意味着全连接层的参数数目比较大。运算公式如下:
F(x)=f(x*ω+b)
(6)
式中:F(x)为全连接层;f为激活函数;ω为权重参数;b为偏移量。
2.4 融合LBP和自建CNN模型
众所周知,大规模复杂的网络模型能够在一定程度上提高表情识别的准确率,但是这就需要大量的实验训练样本,并且对计算机的硬性条件也有着苛刻的要求,此外还会耗费大量的成本和降低模型的训练速度。
为了提高训练速度,需采用浅层CNN,为了达到和深层CNN网络同样好的识别效果,必须在图片的特征提取阶段提取更具有表现力和鲁棒性的特征。原始图片的纹理特征表现力差,并且易受光照条件变化,包含的多是浅层的表情特征,所以在CNN之前先提取LBP特征,便可以得到更深的具有良好鲁棒性的纹理特征。同时将实验样本进行多次随机打乱训练并验证,选取权重最优的CNN作为最终模型,即本文设计的基于LBP和权重最优下的CNN识别方法。
实验时本文对实验数据集样本数量不进行扩充,首先对原始图片进行了灰度值转换和尺寸的归一化操作,然后利用Circular LBP算子提取出LBP纹理特征。在借鉴CNN模型的通用架构设计的基础上创建了一种比较浅层的CNN模型,CNN模型参数如表1所示。
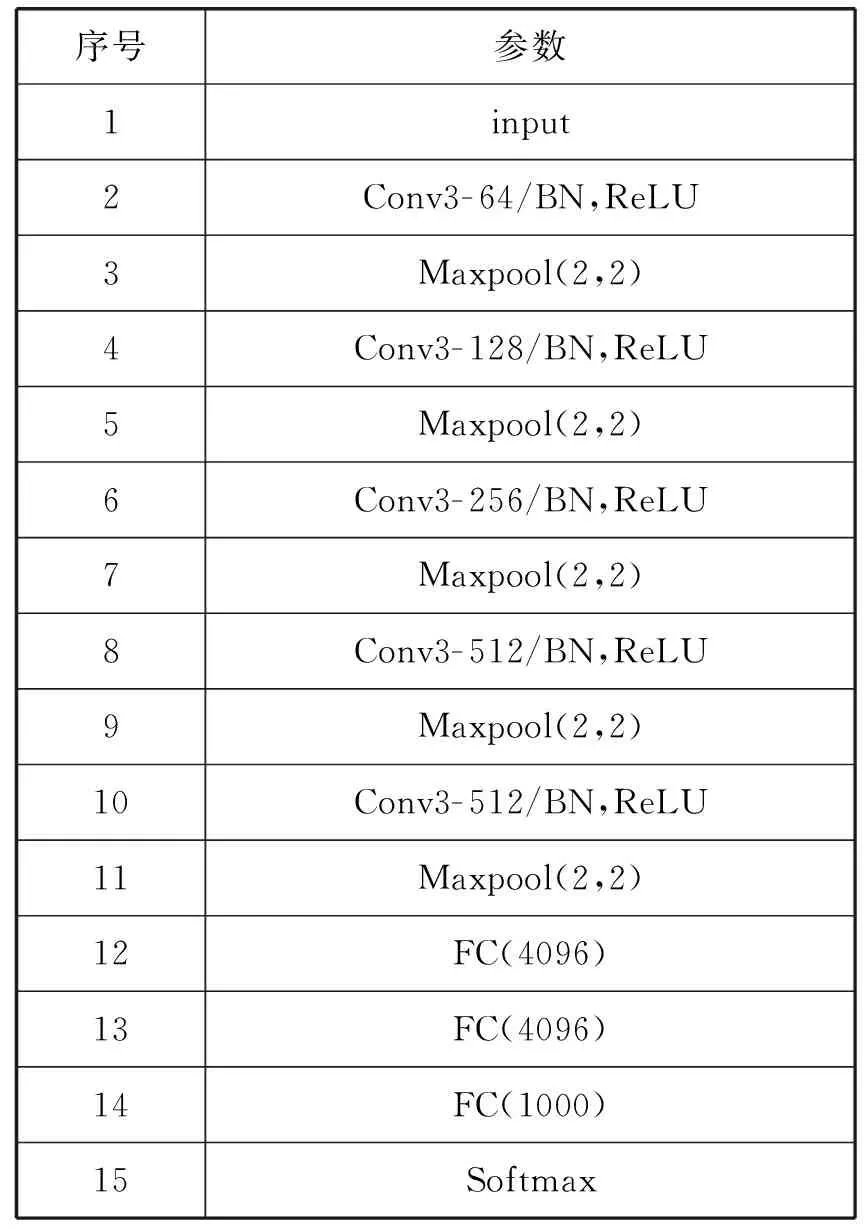
表1 CNN模型参数
本文构建的CNN模型共有5个卷积层和5个最大池化层。每一个卷积层卷积核的数目分别是64、128、256、512、512,使用数目多的卷积核能够在网络加深时提取更高阶的深层特征。卷积核大小统一为3×3,有利于降低网络参数的数量,加快运算效率。在每个卷积层之后,本文还添加了ReLU激活函数、BN归一化层和2×2最大池化层。ReLU激活函数和BN归一化层可以使卷积层的线性输出的数据变为非线性化表达,并且可以防止梯度爆炸和弥漫,而最大池化层能够继续提取特征并且减少参数数量。池化层之后还使用3个全连接层提取更为深度的图片特征,解决网络最后输出的非线性问题。最后使用Softmax层进行表情图片的输出分类。
3 实 验
3.1 实验条件
本文实验采用Python3.6语言编写,实验软硬件平台为:64位Linux操作系统、CPU为英特尔酷睿i5- 9400F,主频是2.90 GHz,内存是16 GB、显卡型号为GeForce GTX 1080Ti,显存是11 GB。将预处理好的CK+和FER2013数据集首先平均划分为10组,并且无受试者重叠(同一幅图片不能同时出现在同一个分组里面),选出1组作为验证集,1组作为测试集,其余为训练集,对训练集采用自建CNN和随机梯度下降法进行训练,利用验证集验证;然后随机打乱数据集顺序,继续划分验证集、测试集和训练集再次进行训练和验证(本文共进行了5次随机打乱)得到最优的权重;最后将权重最优的模型进行保存,并进行测试,测试时进行10倍交叉验证算出模型最终的识别率。
由于两个实验数据集样本数量存在较大差异,所以在不同数据集下CNN模型参数也有所不同,表2列出了不同数据集的参数比较。
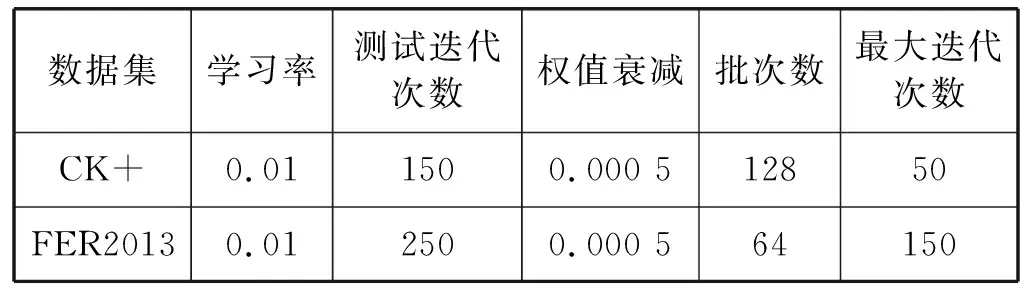
表2 不同数据集的模型参数
3.2 实验结果及分析
为了得到模型最终稳定的识别率,经过多次实验,在CK+和FER2013数据集上,将最大迭代次数分别设置为50和150次。多次训练迭代后,CNN模型的识别率达到了稳定,最终在CK+数据集的识别率达到了97.2%,在FER2013数据集的识别率达到了71.4%。图9显示了在不同数据集上训练时不同迭代次数识别率的变化。

图9 不同数据集的识别率折线图
可以看出,在CK+数据集上,当CNN模型迭代到第20次时,就会基本收敛,识别率也会逐渐稳定;而在FER2013数据集上,当CNN模型到第35代(识别率69%)时还在缓慢增长(图9中最大的迭代次数只显示到第35代),最终在115代(识别率71%)达到峰值,这是由于CK+数据集与FER2013数据集相比,图片的拍摄条件更为苛刻,并且图片更为规整。同时为了比较本文方法的有效性,将本文方法进行拆分并逐一比较,并在数据集CK+上做了多次测试,并取平均值作为最终的结果,如表3所示。实验结果表明,相对于单一的CNN模型,加入权重最优下的CNN模型的识别率得到提高,CNN与LBP进行融合后,识别率进一步提高,达到了比较好的识别效果。同时本文自建的CNN在CK+数据集上训练迭代一次的平均时间为0.1 s,将其他网络模型如VGG19进行替换后,进行多次实验,训练迭代一次的平均时间为0.2 s,对比发现本文自建的CNN模型训练速度比较快。

表3 在CK+数据集上的模型识别率(%)
为了比较本文方法与其他传统算法以及不同深度学习方法的性能,在CK+数据集上与SIFT融合CNN方法[13]、并行CNN模型[15]、HOG融合CNN方法[18]进行了对比;在FER2013数据集上与CNN[19]和深度神经网络(DNN)[20]的深度学习算法进行了比较。结果表明,本文提出的基于LBP特征和权重最优下的人脸表情识别方法的识别率明显高于其他方法。比较结果如表4、表5所示。

表4 不同方法在CK+数据集上的识别率对比

表5 不同方法在FER2013数据集上的识别率对比
为了比较各个表情在CK+和FER2013数据集上不同的识别效果,本文方法的混淆矩阵如表6、表7所示。表6的结果说明在CK+数据集上开心、惊讶和蔑视表情的识别率最高,因为这3种表情的特点都非常明显,而且不至于混淆;生气、憎恶、恐惧和悲伤的识别效果较差,这是因为这几种表情都反映了人在消极情况下的特点,而人在消极情况下的表情具有一定的相似性,这给表情分类带来了难度。表7的结果说明在FER2013数据集上对开心和惊讶的识别效果较好,剩余的表情识别效果较差,原因在于本身FER2013数据集受干扰因素比CK+数据集要大得多得多,标签也存在错误,并且人类肉眼的识别率也不到70%,这也从侧面反映了原始样本数据的重要性。

表6 本文方法在CK+数据集上的混淆矩阵
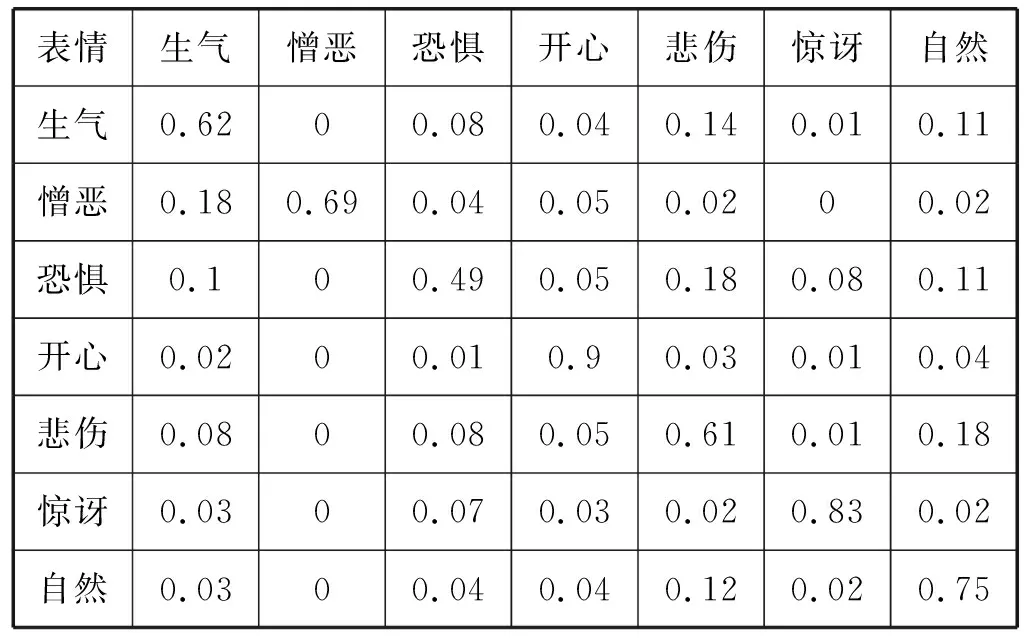
表7 本文方法在FER2013数据集上的混淆矩阵
4 结 语
本文提出的基于LBP特征和权重最优下的CNN面部表情识别算法在CK+和FER2013数据集上分别取得了97.2%和71.4%的识别率,反映了自建的浅层CNN在融入传统算法LBP,并且随机打乱数据集后利用梯度下降算法训练来保存最优权重后的模型取得了良好的性能提升,同时在不同数据集上展现了较好的鲁棒性。但是有些表情,比如恐惧、悲伤的识别效果并不如人意,在接下来的工作中考虑能否改进一些经典的网络模型,或者通过数据增强技术,使其在表情特征的提取中,提取出更加细微的表情特征,以及利用迁移学习的方法对网络模型进行进一步的优化,期望达到更高的识别效果。
