基于特征工程和树增强贝叶斯网络的个人信用评估研究*
2023-01-30范彦勤黄海午杨智凯
范彦勤 黄海午 杨智凯
(1 桂林航天工业学院 理学院,广西 桂林 541004;2 桂林航天工业学院 科技处,广西 桂林 541004)
随着我国经济的快速发展,个人消费信贷业务急剧增长,个人信用评估显得尤为重要。个人信用评估模型主要包括统计方法、专家系统、数学规划、分类树(CART)、K最邻近算法(KNN)、支持向量机(SVM)、人工神经网络(ANN)、贝叶斯网络(BN)及各类集成算法等。其中,贝叶斯网络分类模型作为一种先验知识与样本信息相结合、依赖关系与概率表示相结合的分类方法,具有良好的分类精度,广泛应用于各领域中。尤其是高效应用的树增强贝叶斯分类器(TANC),放松了朴素贝叶斯分类器(NBC)中的条件独立假设,具有较好的综合性能。目前国内外研究个人信用评估模型的重点,主要是通过对机器学习算法[1-4]的改进,实现模型的不断优化。 综述各类评估模型,目前仍存在一些不足:如模型构建前,数据的优化和准备工作,特别是合理有效的特征选择、不平衡数据处理等问题,会对后续模型构建的稳定性造成影响;同时模型的选择不当,将直接影响分类结果。
针对以上问题的分析,本文基于特征工程,通过数据平衡、特征编码和特征选择,达到优化数据集的目的,减少后续模型的输入和数据的维数;然后把特征选择后的属性特征应用到树增强贝叶斯分类器(TANC)上,建立个人信用评估模型。并使用真实数据进行对比验证,结果表明该模型在不同分区数据集上分类准确率高,模型性能良好,同时减少了模型的计算量,有效地缩短了评估所需的时间。
1 特征工程
1.1 数据平衡
目前有效使用的个人信用评估数据集大多不平衡,常用的方法如下:从数据本身出发,改变数据集分布,减少数据的不平衡性;改进算法,减少模型对多数类样本的依赖,该方法对先验知识的要求较高;SMOTE[5-6]数据合成法,即合成少数类过采样技术,通过对少数类样本进行分析并根据少数类样本人工插值合成新样本,实现跟大类样本数据相当)添加到数据集中,构成均衡数据集,其中本文处理方法基于此合成法。
1.2 特征选择
常用的特征选择方法分为以下三种[7-8],如图1所示。

图1 特征选择方法分类
各方法均有优劣性,其中Pearson相关系数可以有效避免评分等级膨胀(grade inflation)的问题,且简单易操作。因此,本文在特征选择方面,采用过滤法中的Pearson相关系数法。Pearson 相关系数法,主要用来反映变量间相似度的统计量。计算公式如式(1):
(1)
其中:r表示相关程度,取值为[-1,1]。通常,r小于0.4为弱相关,r大于0.6为强相关,大于0.8为极强相关。
2 树增强朴素贝叶斯分类器(TANC)
贝叶斯分类器[9]应用广泛,具有良好的分类性能和稳健性,它的原理是将先验概率与后验概率相结合,利用已知的先验信息和样本数据集信息,获得其后验概率,并将具有最大后验概率的类作为所属的类。其中NB和TANC 分类器最具有代表性。贝叶斯定理可表示为:
P(C=cj|x1,x2,…,xn)
=aP(cj)·P(x1,x2,…,xn|cj)
(2)
其中:a是正则化因子;P(cj)是类cj的先验概率;P(cj|x1,x2,…,xn)是类cj的后验概率。
树扩展朴素贝叶斯分类器(TANC)[10-11]是基于NB的改进,放宽了独立性假设要求,允许属性变量除类变量为父结点外,至多有1个其他的属性作为其父结点,各属性变量之间可形成一个树形结构。由于限制每个属性结点最多有一个非类变量的父结点,因此可以进行有效的学习。TANC分类器的一个例子如图2所示。

图2 树扩展朴素贝叶斯分类器
TANC模型构造方法如下[11]:
a)计算各属性变量间的条件互信息I(Xi;Xj|C),
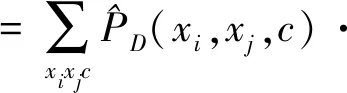
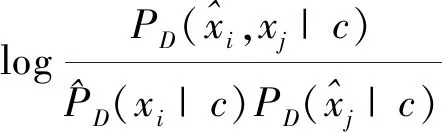
(3)

b)构造一个完全无向图,它的顶点是属性变量。标注Xi和Xj相连接边的权重为I(Xi;Xj|C)且i≠j。
c)建立一个最大的权重跨度树。
d)将选择出的父节点指向子节点,把无向树转化为有向树。
e)增加一个类变量节点及类变量节点与属性节点之间的弧。
贝叶斯分类模型的复杂度一般为o(n2)或者o(n),其中n为属性节点的个数,因此通过特征选择后的属性节点将简化建模的输入,减少计算量,缩短评估时间。
3 实验结果及分析
3.1 样本数据
本文数据采用UCI[12]上德国个人信用评估数据集。样本总数为1000条,信用分类结果为好和坏两种,其中 好坏客户样本占比为7∶3。包含其中20个为特征变量,1个类变量。20个特征变量中,数值型7个,字符型13个,表1给出了德国信用数据的属性,表2给出德国信用数据的分布。

表1 德国信用数据的属性

表2 德国信用数据的分布
3.2 数据预处理
由于本文采用数据中好坏客户样本比为7∶3,存在一定的不平衡性。本文对非数值型数据进行编码,根据类别的数量分别用自然数0~N之间替代;采用Z-Score标准化数据集;采用SMOTE过采样,对样本数据平衡处理;最后利用Pearson 相关系数法进行特性选择,作为TANC的输入节点。
3.3 模型构建
本文基于IBM SPSS modeler18.0软件构建三种模型如下:
模型一,不对数据进行平衡处理和特征选择,直接构建模型。
模型二,先对数据进行分区、平衡处理,再对数据进行特征选择后构建模型。
模型三,只对数据进行分区、平衡处理,未进行特征选择,然后构建模型。图3给出评估流程图,图4给出不同特征工程下整体模型构建过程。

图3 评估流程图

图4 不同特征工程下的整体模型
3.4 实验结果及分析
3.4.1 模型评估指标
分类准确率作为评价模型优劣的重要指标,但对于不平衡数据的个人信用评估研究,还需要引入混淆矩阵、ROC曲线及AUC值,共同作为模型评价指标。其中混淆矩阵规定如表3:

表3 混淆矩阵
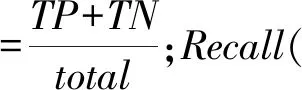

3.4.2 仿真实验结果
3.4.2.1 预测变量重要性及模型构建图
本文数据中的20个特征变量经过筛选后,根据变量重要性,选取前13个特征变量作为后续建模的输入,同时进行数据分区,训练集与测试集占比为7∶3,前者用于模型的训练,后者用于对模型进行评价。其中图5给出前10个重要性大于0.95的特征变量,通过特征变量重要性排序,有利于帮助决策者进行有效判断。图6给出基于特征选择的TANC模型图。

图5 预测变量重要性排序

图6 基于特征选择的TANC模型
20个特征变量选择出13个作为后续建模的输入,节点输入减少了35%,有效降低数据维数,减少冗余,降低模型复杂度。
3.4.2.2 基于特征工程的TANC模型实验结果及分析
ROC和AUC作为模型性能度量的重要评估方法,有着较为广泛的应用。其中,ROC曲线[13-14]描述的是分类器性能随着分类器阈值的变化而变化的过程。对于ROC曲线,如果横轴是1-特异度,纵轴是灵敏度。那么该弯曲曲线与45度的直线形成一个曲线下面积,即为 AUC,AUC越大,说明判断的效果越好。面积越接近于1,识别能力越强。一般合适的模型,AUC值不低于0.5。基于三种不同模型进行建模分析,给出三种模型分别在训练集和测试集上的ROC曲线,具体曲线如下图7、8、9所示:

图7 模型1 ROC曲线

图8 模型2 ROC曲线

图9 模型3 ROC曲线
给出三种模型分别在训练集和测试集上的分类正确率、错误率、AUC值,分类结果如表4所示:

表4 三种模型评估度量
模型1:直接构建的TANC模型;模型2:基于特征工程的TANC模型;模型3:只对数据进行分区、平衡处理,未进行特征选择,所构建的TANC模型。
表4中的数值是验证结果的平均值,给出了三种模型评估度量。分“训练”“测试”两个不同的数据集,分别给出了准确和错误率。由表4分类结果不难得出:基于特征工程的TANC模型(模型2),在“训练”“测试”两个数据集上的分类准确率最高,错误率最低。
由图7、图8、图9,三种模型下ROC曲线及表4中三种模型对应的AUC值大小,可以得出,基于特征工程的TANC模型(模型2),在“训练”“测试”两个数据集上不仅分类效果均最好,且模型性能优越。
3.4.2.3 基于特征工程的TANC模型与其他模型性能比较
为了进一步验证基于特征工程的TANC模型的有效性和稳健性,将此模型与常见的NBC、SVM、 KNN、 CART 、ANN模型的准确率进行实验比较,结果如表5所示:

表5 基于特征工程的各信用评估模型的分类结果

表5(续)
CART模型在训练集中的准确率略高于TANC模型,但个人信用评估更为看重测试集中的分类准确率,综合各类模型,可以得出基于特征工程和树增强贝叶斯网络的个人信用评估模型在信用评估中分类效果较好,模型可靠性较高,具有良好的推广应用价值。
4 结束语
针对目前个人信用评估数据,存在着不平衡性、属性指标较多、模型分类准确度不高等问题,模型构建前的数据集的选取、平衡、分区、特征选择和优化显得较为关键。本文讨论了一种基于特征工程和TANC模型的个人信用评估模型。基于SPSS Modeler 18.0软件进行模型构建,通过实验验证结果可得,该模型通过特征工程,优化了数据集,减少了构建模型的输入,在两个不同分区的数据集上均取得了较高的准确率,尤其是在测试集中准确率较高,且通过ROC曲线、AUC值,论证了模型的分类效果好,性能良好。同时将该模型与其他信用评估模型相比较,也取得了较优的分类准确率,进一步证明该模型的稳健性。还可以进一步探究将该模型应用到其他相关领域中。
