基于对比学习的细粒度未知恶意流量分类方法
2023-01-09王一丰郭渊博陈庆礼方晨林韧昊
王一丰,郭渊博,陈庆礼,方晨,林韧昊
(1.信息工程大学密码工程学院,河南 郑州 450001;2.郑州大学计算机与人工智能学院,河南 郑州 450001)
0 引言
基于流量的网络入侵检测系统(NIDS,network intrusion detection system)是网络空间中最重要的安全设备类型之一,已被广泛应用于各类信息系统的防护中。随着移动互联网和物联网(IoT,Internet of things)等技术的发展,系统的规模不断扩大,且终端设备的种类和数量也不断增多。而这些资源受限的终端设备由于难以部署安全软件或代理且更易存在较多漏洞,更易遭受攻击。这种趋势使NIDS 在网络防御中的重要性日益凸显。
NIDS 的主要作用是对恶意流量的分类。目前,流量分类方法主要有基于端口、基于载荷和基于流3 种[1]。然而,如今网络攻击愈发具有对抗性,常采用各种途径规避NIDS 检测。例如,端口混淆和端口跳变等技术使基于端口的方法准确率大幅下降[2];加密技术的广泛应用使基于载荷的方法几乎完全失效[3],此外,隐私和计算开销等问题也是这类方法的缺点[1]。2020 年,超过70%的恶意活动在通信中使用了加密技术[4]。而基于流的方法不存在上述问题,并且由于机器学习(ML,machine learning)和深度学习(DL,deep learning)的快速发展,这类方法的检测性能大幅提高,现已成为流量分类领域的主流方法[5-6]。然而,以往研究发现这类方法在实际恶意流量检测中存在以下3 个问题。
1) 机器学习,特别是深度学习的分类性能严重依赖于训练数据的数量和质量[7]。但由于实际中标注数据成本昂贵或存在新型网络威胁,往往没有足够标注数据可用。此外,更细粒度的分类能提供更多威胁信息,有助于安全专家快速响应。而以往大多研究没有考虑此问题,缺乏在细粒度小样本(C2FS,coarse-to-fine few-shot)条件下的评估结果。
2) 恶意流量检测也是一个开集分类问题,数量快速增长的未知攻击(如恶意软件新变种、零日攻击以及针对IoT 等新兴技术的攻击)产生了各类未知恶意流量,现今的NIDS 需应对未知恶意流量分类的挑战[8]。而以往大多实验结果是在闭集上,未考虑对未知类的检测。
3) 机器学习算法容易遭受逃逸攻击,或者说对抗样本攻击[9]。研究表明,某些恶意流量只需添加不影响恶意功能的微小扰动即可绕过NIDS 的检测[10-11]。此外,流量欺骗[12]、混淆[13]等技术的发展也使恶意类流量可以伪装接近于良性类,从而误导分类器[14]。
为了解决以上问题,本文提出一种基于对比学习[15]的细粒度未知恶意流量分类方法,主要贡献如下。
1) 提出了在C2FS 条件下的恶意流量检测任务,并提出了一种基于条件变分编码器(CVAE,conditional variational auto-encoder)[16]和极值理论(EVT,extreme value theory)[17]的半监督在线学习方法。相比以往方法,本文在一个框架下实现了对已知、未知和小样本类上的细粒度高性能分类。
2) 在流量分类的各阶段设计并加入了对比损失,并采用了再训练架构,使对小样本恶意类流量的分类性能和模型的泛化性能相比以往大幅提高。
3) 在公开数据集上的实验结果表明,相比以往方法,本文方法对所有恶意类,特别是小样本类的分类精度更高,且能够有效降低逃逸攻击效果。
1 相关工作
1.1 基于机器学习的恶意流量分类
恶意流量分类的基本目标是区分良性类和恶意类流量。随着数据规模的增加,相比传统方法,机器学习在恶意流量分类中的性能优势愈发凸显[18]。采用机器学习的方法具有使用场景广、分类准确率高、能分类加密流量等优点。这些研究的区别主要在于流特征、分类对象和分类算法的选择。常用的流特征包括头部、负载、时空和统计特征[7]。依据颗粒度,可将分类对象划分为分组、主机和会话级[19]。常用的分类算法包括支持向量机(SVM,support vector machine)[20]、高斯混合模型(GMM,Gaussian mixture model)[21]、随机森林(RF,random forest)[22]、卷积神经网络(CNN,convolutional neural network)[23]等,且都在实验环境下取得了不错的效果。
基于头部和负载特征的方法在应对精心设计的攻击时表现不佳。例如,各类公共服务(社交网站、云平台等)由于允许用户定义内容,常被用作隐蔽信道发布命令或传递窃取信息[24]。加密或随机填充等方式也会改变负载特征,从而导致分类性能下降。相比之下,基于统计和时空特征的方法虽然也存在上述问题,但由于在保持恶意功能条件下修改特征成本较大且往往会产生新的可分类特征[13],因此更适用于具有对抗性的恶意流量分类。
部分研究还考虑了实际应用中细粒度、小/零样本等现实需求和问题。文献[25]提出了一种多级半监督学习框架来缓解恶意流量分类中的类不平衡问题。文献[8]采用CVAE 和EVT 来实现流量的细粒度检测和对未知类的分类。但据本文所知,目前缺乏同时考虑上述3 个问题的恶意流量分类方法。
1.2 开集分类与流量分类
开集分类是指模型通过在训练阶段学习已知类样本,并在测试阶段辨别一个样本是已知类还是未知类。目标是找到一个可测函数f(f(x) > 0表示分类正确),既要最小化已知分类经验风险Rε(f(V)),也要最小化开放空间风险Ro(f)[26],即其中,V是训练数据,λr是正则化常数。

开集分类包括判别和生成两类方法。在判别方法中,实现开集分类主要有基于稀疏表示[27]、极值机(EVM,extreme value machine)[28]、OpenMax[29]等。在生成方法中,主要有基于实例生成[30]和非实例生成[31]两类。在这些方法中,EVT 最常被引入用以对未知类进行评估。当前流量分类中考虑开集分类问题的文献还相对较少。文献[32]采用Weibull-calibrated SVM 对流量进行细粒度分类,并采用EVT 评估校准。文献[33]通过EVT 近似计算每个已知类的边缘距离分布,实现开集流量分类。
1.3 恶意流量分类中的逃逸攻击
逃逸攻击(或对抗样本攻击)是指攻击者在不改变目标系统的情况下,通过构造特定对抗样本以欺骗目标系统的攻击。机器学习,特别是深度学习方法普遍存在容易遭受逃逸攻击的问题[34],且各类对抗样本生成方法层出不穷,如FGSM(fast gradient sign method)[35]、FFF(fast feature fool)[36]等。
逃逸攻击近年来已应用于恶意流量伪装中,以逃避基于机器学习的NIDS 检测。文献[37]采用生成对抗网络(GAN,generative adversarial network)修改流量的非功能性特征,将原始恶意流量转换为对抗流量绕过黑盒NIDS 检测。文献[38]同样采用GAN 模型学习良性流特征指导对抗样本生成,以传出/传入数据包等6 个特征实现逃逸攻击。文献[10]不仅实现了基于GAN的加密恶意流量伪装,还模仿了良性类的主机级通信时间特征。随着逃逸攻击在恶意流量分类中不断发展,未来NIDS 中需要考虑对此类攻击的防御。
1.4 对比学习
对比学习属于表征学习,目的是学习一种数据变换方式,其更容易解决下游任务。通过学习数据的特征表示,使特征空间中相同类数据较近,不同类数据彼此远离。大多数方法是基于对比损失实现的。而其他方法,如BYOL(bootstrap your own latent)模型[39]虽然没有采用负样本,但其多层感知机(MLP,multilayer perception)预测器也可以视作负样本网络。文献[40]指出对比学习模型的性能与负样本的数量和质量相关。本文总结了当前3 种主流的对比学习方法。
1) 以SimCLR[41]为代表的方法。这类方法将当前训练批次中的其他类样本作为负样本,通过对比损失实现对比学习。这类方法训练难度较大且会丢失以往部分负样本。
2) 以MoCo[42]为代表的方法。这类方法维护一个大的先入先出负样本队列(x-1,x-2,…,x-m),每次训练更新最旧的一小批负样本。经典的MoCo 架构如图1 所示,采用模板网络fM来实现对正负样本的特征提取。对于fM,其初始化参数为原始特征提取网络fq,训练时基于动量缓慢更新参数。这类方法因不需要反向传播而计算量较小,但负样本更新速度较慢。

图1 经典的MoCo 架构
3) 以AdCo[43]为代表的方法。这类方法设计负样本网络表示“整体”负样本,用以生成高质量负样本信息[44]。这类方法由于需要设计训练负样本网络,模型结构比较复杂。
2 方法设计
现有基于流特征的NIDS 存在缺乏标注数据和易受逃逸攻击的问题,本节在文献[8]的基础上,受文献[45-46]启发将对比学习与CVAE 结合,以实现已知、未知、小样本类的流量细粒度分类。
流量的流特征可以采用CICFlowMeter[47]等流量特征提取工具提取。本文中流量的流特征经过提取和预处理后记作d维实值特征向量xi∈Rd,对应类标签记作yi∈ {0,1}k+f+1,用k+f+1维的独热(one-hot)向量表示。记O为one-hot 编码函数,作用是将输入向量的最大维度设为1,其余维度值设为 0。类标签集合可以表示为Call={B,M1,…,Mk,Mk+1,… ,Mk+f,Mk+f+1},其中,B表示良性类,M1,…,Mk表示k类大样本已知恶意类,Mk+1,…,Mk+f表示f类小样本已知恶意类,Mk+f+1表示未知恶意类 。训练集Strain=Strain-B∪Strain-K∪Strain-F由大量良性类样本Strain-B={(xi,yi)|yi=B}、一定量的已知恶意类样本Strain-K={(xi,yi)|yi∈ {M1,… ,Mk}}以及极少量的小样本已知恶意类样本Strain-F={(xi,yi)|yi∈{Mk+1,…,Mk+f}}组成。本文利用训练集Strain训练分类网络Pθ,使其对所有类样本x∈ {xi|yi∈Call}的预测结果都尽量接近其真实标签y,即目标为
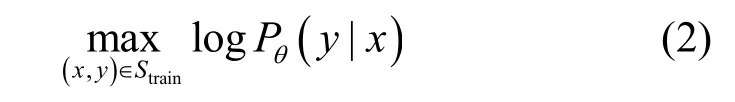
本文提出了一个基于流特征的流量分类方法,可同时实现对已知、未知、小样本类的流量细粒度分类,整体结构如图2 所示。模型分为已知恶意流量训练、未知恶意流量训练和测试3 个阶段。首先,在已知恶意流量训练阶段采用CVAE 模型,并设计对比损失结合CVAE 编码器训练,使不同类样本在潜特征空间中进一步区分。相比以往方法,加入对比损失后对于小样本类检测有显著提升。其次,在模型未知恶意流量训练阶段采用EVT 模型。当模型在已知恶意流量训练后,固定编码器和解码器的网络参数训练重构网络参数,并在重构阶段也加入了对比损失,基于重构误差训练EVT 模型,使模型对未知类的分类性能显著提高。最后,在测试阶段用训练后的CVAE 和EVT 模型对新样本进行分类。并且重采样、再训练和L2 正则化等技巧在此也被采用,以进一步提升模型的检测和泛化性能。

图2 基于对比学习的细粒度恶意流量检测模型整体结构
2.1 已知恶意流量训练阶段
该阶段结构如图2 中的已知恶意流量训练阶段所示,目标是采用训练集Strain对良性类(B)和已知恶意类(M1,…,Mk+f)样本进行分类。本文在此阶段采用对比学习结合CVAE 模型[8]实现。CVAE可视为有监督VAE 模型,在恶意流量检测中表现优异,更重要的是其独特的“解码重构”架构可以帮助分类未知恶意类样本。
首先,将样本x∈Rd转化为更低维的潜特征z∈R h,h<<d,更低维的特征空间计算速度更快且能更好地区分不同类的样本[8]。对于给定x,y,其z的真实分布记为P(z|x,y),采用一个网络Q(z|x,y)近似模拟P(z|x,y)。对于目标式(2)的logPθ(y|x)可以改写为[16]

其中,DKL表示KL 散度[48],用于衡量2 个分布之间的差异。式(3)中前两项合称为CVAE 证据下界值(ELBO,evidence lower-bound),即

由于式(3)第三项中P(z|x,y)无法计算,但KL散度一定非负,因此 logPθ(y|x) ≥LELBO,则式(2)可以等价为

其中,P(z|x)、Q(z|x,y)、P(y|x,z)均采用GMLP(Gaussian multi-layered perceptron)近似模拟。假设P(z|x)服从正态分布,采用先验网络P(x)近似;Q(z|x,y)采用编码网络QE(x,y)近似,对应CVAE编码器;P(y|x,z)采用解码网络QD(x,z)近似,对应CVAE 解码器。则基于目标式(5),P(x)、QE(x,y)和QD(x,z)采用随机梯度下降(SGD,stochastic gradient descent)算法通过最小化损失函数式(6)更新网络参数,实现流量分类

其中,z=SA(QE(x,y))是QE(x,y)编码后正态分布的采样,SA 表示采样函数。
但以上CVAE 模型存在一定缺陷:一是难以分类小样本类,二是易遭受对抗样本的攻击。为了缓解这2 个问题,本文学习潜特征z时加入了对比学习。在潜特征空间中,本文希望同类样本之间更加紧凑,异类样本之间更加分散。这样即使是小样本类也可与其他类区分开,并且有助于分类未知恶意类流量和防御逃逸攻击。
为了实现对比学习,对于任意样本对(xi,yi)∈Strain,P(xi)首先应与同类样本x+的P(x+)接近,与异类样本x-的P(x-)远离;同样QE(xi,yi)应与同类样本x+的QE(x+,yi)接近,与异类样本x-的QE(x-,yi)远离;最后,P(xi)应与其对应的QE(xi,yi)接近,与其他不正确的y-≠yi生成的QE(xi,y-)远离。而对比学习的损失函数可以采用InfoNCE 损失[49]的形式来表示

其中,τ是归一化超参数。计算时对P(x)和QE(x,y)进行重采样,以 SA(P(x))和 SA(QE(x,y))计算损失函数。
对比学习中负样本的选择至关重要。为了兼顾效率与精度,本文对不同类型x采用不同策略选取负样本。首先,采用SimCLR 类方法迅速训练P(x)、QE(x,y);当模型收敛速度下降后,选择负样本时采用AdCo 类思想,选择针对性负样本。即当样本对(xi,yi)∈Strain-K时,选择属于同一粗粒度类但不同细粒度类或良性类样本作为负样本;最后,对于小样本类样本对(xi,yi)∈Strain-F,希望其与尽可能多的负样本训练,因此对于这部分样本采用MoCo类方法训练至模型收敛。
本文在CVAE 模型训练时加入了对比损失,以不平衡采样数据训练整体的CVAE 模型,其损失函数如式(8)所示,对应图2 中的①。

其中,λC是权重超参数。
该阶段的训练策略如算法1 的步骤1)~步骤16)所示。
2.2 未知恶意流量训练阶段
该阶段结构如图2 中的未知恶意流量训练阶段所示,目标是对未知类(Mk+f+1)恶意样本进行分类。在此阶段,本文采用对比学习结合CVAE 重构网络和EVT 方法实现流量分类。
在CVAE 模型完成2.1 节训练后,首先固定QE(x,y)的参数训练重构网络R(z,y)。重构网络R(z,y)用于对输入潜特征z(由编码器网络QE生成)和给定标签y'并生成重构样本x'。其目标是编码网络QE输入的x和解码网络QD输出的x'尽量接近。重构损失函数如式(9)所示,重构损失采用均方误差(MSE,mean square error)来衡量。

对于未知类检测思路是训练后的CVAE 模型对已知类样本对(xi,yi)∈{(xi,yi)|yi∈ {M1,…,Mk+f}}的预测标签yi'大概率是正确的,即yi' =yi,其重构样本也应接近xi;而对未知类样本对(xi,yi)∈{(xi,yi)|yi=Mk+f+1},其预测类标签yi'必定错误,即yi' ≠yi,其重构样本xi'应与原样本xi相差较大。这样就可以判断新样本xi'是否属于未知恶意类。
为了减少对未知类的误判,训练时重构样本xi'应与输入样本xi接近,与其他类样本y-≠yi生成的R(zi,y-)较远。为此,采用对比学习式(10)放大这种需求。
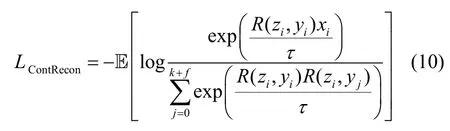
最后利用式(11)训练重构网络R(z,y)。训练时固 定P(x)和QE(x,y)参数,实际计算时z=SA(QE(x,y))由QE(x,y)编码后正态分布采样,对应图2 中的②。由于对比损失几何上类似余弦相似度,因此在重构样本时潜特征z也需归一化。
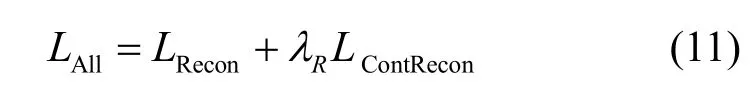
其中,λR是权重超参数。
未知恶意类分类时,由于模型对不同已知类的分类和重构能力不同,难以采用统一阈值进行分类。为此,本文采用EVT 为每个已知大样本类估计分类阈值。EVT 认为对于任意的随机变量X,其极值相对于阈值t超出的部分应服从 GPD(generalized pareto distribution)分布

其中,γ,σ> 0,实际中可以采用极大似然估计方法计算γ,σ,对数似然函数表示为

其中,Nt表示观测数据中超过阈值t的样本数量,Xi表示观察数据。本文采用Strain-B∪Strain-K中样本的重构误差作为观察数据,分别对大样本已知类(B,M1,…,Mk)构建k+1 个EVT 模型,对应于图2中的③。
该阶段的训练策略如算法1 的步骤17)~步骤24)所示。
2.3 细粒度恶意流量的训练策略与测试阶段
本文模型的整体训练策略如算法1 所示。
算法1细粒度恶意流量分类模型训练算法
输入标记训练数据集Strain
输出训练后的P(x)、QE(x,y)、QD(x,z)和R(z,y),以及k+1 个训练后的EVT 模型参数
1) 随机初始化P(x)、QE(x,y)、QD(x,z)、R(z,y);
2) for(xi,yi)∈Straindo
3) 计算QE(xi,yi)和P(xi)得到潜特征;
4) 随机选择负样本,基于式(8)计算损失和梯度,并采用SGD 更新P(x)、QE(x,y)、QD(x,z)参数;
5) end for
6) 重复步骤2)~步骤5),直至模型大致收敛;
7) for(xi,yi)∈Strain-Kdo
8) 计算QE(xi,yi)和P(xi)得到潜特征;
9) 选择xi的同一粗粒度类但不同细粒度类或良性类样本为负样本,基于式(8)采用SGD 更新P(x)、QE(x,y)、QD(x,z)参数;
10) end for
11) 重复步骤7)~步骤10),直至模型大致收敛;
12) for (xi,yi)∈Strain-Fdo
13) 计算QE(xi,yi)和P(xi)得到潜特征;
14) 采用MoCo 架构,维持大量负样本,基于式(8)采用动量方式更新P(x)、QE(x,y)、QD(x,z)参数;
15) end for
16) 重复步骤12)~步骤15),直至模型收敛;
17) for(xi,yi)∈Strain-B∪Strain-Kdo
18) 计算QE(xi,yi)得到潜特征;
19) 固定当前P(x)、QE(x,y)、QD(x,z)网络参数,基于式(11)采用 SGD 更新R(z,y)参数;
20) end for
21) 重复步骤17)~步骤20),直至模型收敛;
22) forci∈{B,M1,…,Mk} do
23) 计算ci类所有训练样本的重构误差,并将其作为观察数据,选取经验阈值ti并基于式(13)估算ci类的EVT 模型参数γi,σi;
24) end for
训练完成后,模型在测试阶段的流程如图2 中的测试阶段所示。具体来说,对于一个待分类的新样本xi,首先采用先验网络P得到潜特征分布zi。接着解码器QD给出预测标签。若为小样本恶意类,则直接将作为分类向量输出;若为良性类或大样本已知恶意类,则继续用重构网络R计算x与所有大样本已知类的标签计算重构样本R(SA(zi),{B,M1,…,Mk})及其重构误差。之所以不对被分类为小样本类的样本进行重构,是因为模型对小样本类分类能力不足。接着,基于大样本已知类EVT 模型,对当前重构误差计算概率,用于对的修正,得到修正后的概率向量。若分类结果改变(即O或其最大值小于阈值(即),则最终分类结果为未知恶意类Mk+f+1;否则,分类结果仍为
为了进一步提升对小样本类的分类能力,本文还采用半监督学习中的再训练架构。测试时的无标记样本xi经过模型预测得到分类向量,若,则先基于式(14)分析质量并筛选其中高质量伪标签。其中高置信度样本对作为新标注数据,再次重新用于模型训练以提升对小样本类的分类能力。再训练时只更新解码器QD(x,z)参数。
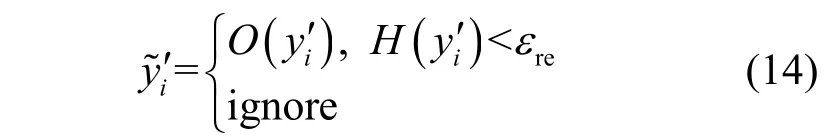
对抗逃逸攻击需要增强模型的泛化能力[50],常见方法主要分为两类:一是对数据处理,例如通过添加随机噪声进行数据增强、部署检测器分类输入数据、中间层随机Dropout 等[51];二是对模型参数处理,例如L1、L2 正则化[52]和对抗训练[53]等。
本文采用了3 种技巧来增强模型的泛化能力以降低逃逸攻击的效果。首先,训练和测试时在潜特征空间中进行重采样,相当于对数据添加了噪声进行数据增强,而这其中对比损失的加入使重采样对模型原本分类性能的影响减少。其次,模型在训练损失函数式(8)和式(11)时加入了L2正则项。文献[35]指出L2 正则化能有效增强线性模型的泛化能力且容易实现。最后,逃逸攻击在未知类分类阶段大多被分类为未知攻击,实现对抗样本的分类。此外,对比学习在此也提高了模型的泛化性能。
3 实验分析
本节在一个恶意流量分类文献中广泛采用的公开数据集NSL-KDD[54]上评估了所提方法。首先,对所提方法各个组件的有效性进行了分析。其次,将所提方法与现有方法进行了对比分析。实验表明,所提方法在分类小样本恶意类、分类未知恶意类和抵御逃避攻击等方面明显优于其他方法。
3.1 数据集
本文实验采用NSL-KDD[54]数据集,该数据集是著名KDD 99 数据集的修订版本。NSL-KDD 数据集包括良性类和39 种细粒度攻击类。其中,攻击可以分为4 个粗粒度类,即拒绝服务(DoS,denial of service)类攻击、扫描(Probe)类攻击、远程入侵(R2L,remote to login)类攻击和本地提权(U2R,user to root)类攻击,具体数据分布如表1 所示。本文选择NSL-KDD 作为实验数据集主要基于以下两点:1) NSL-KDD 虽然发布时间较早,但一直被高水平研究所采用,可以与经典和先进方法比较;2) 更重要的是,相比其他公开数据集,NSL-KDD包含了丰富的细粒度类标签,适用于本文场景,而其他数据集大多只有粗粒度标签,或细粒度标签种类不够丰富。
结合表1 的数据分布和实际情况发现,DoS 类和Probe 类在实际中如果存在,则一般有大量标记样本。而U2R 类和R2L 类在实际中存在较少,更频繁存在小样本情况。本文在表1 中列举并采取了接近实际的实验设置。对于小样本类,每类只选取5 个样本(5-shot)用于训练。

表1 NSL-KDD 数据集各细粒度类的数据分布
3.2 评估标准
在分类任务中,TP 为被模型预测为正类的正样本,TN 为被模型预测为负类的负样本,FP 为被模型预测为正类的负样本,FN 为被模型预测为负类的正样本,则分类任务通常采用以下3 个衡量指标:精度(Precision)、召回率(Recall)和F1值。

在已知类分类阶段,本文同样关注稀疏类(小样本类),因此在训练时采用宏(macro)平均值对模型分类性能进行评估,式(18)表示宏平均F1值。在后续模型性能评估时,都采用宏平均指标。
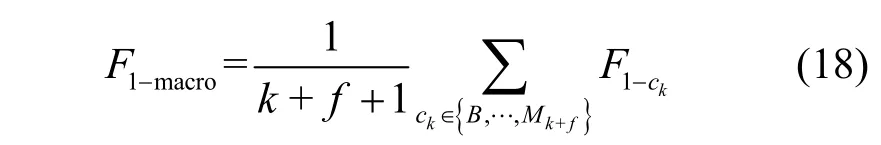
3.3 有效性分析
本节对本文模型中各个组件的有效性进行分析。实验选择了200 次训练后的各模型进行比较分析。
本节首先讨论了第2 节中几个重要超参数的设置。式(8)中λC和式(11)中λR都是训练时对比学习的权重,是随着训练过程动态变化的。实验发现,若初始训练时权重取正值,则模型收敛速度很慢。因此前30 个训练批次时,权重均取0;之后训练时权重均取0.5,使模型能快速收敛。其次,对于未知分类阈值εun,选择训练集上的最佳分类设置,实验中εun=0.82。最后,对于再训练过程中的交叉熵阈值εre,其取值应是训练集上小样本类分类性能最佳时的最小值,实验发现,当εre=1.88时取得了最佳效果。
在已知恶意流量训练阶段,首先分析对比学习对检测性能(特别是小样本类)的提升效果。本节比较了本文模型、不采用对比学习的模型和采用SimCLR 对比学习的模型的性能。如图3 所示,在100 次训练后,不采用对比学习的模型由于训练难度低模型已经收敛。而采用对比学习的模型,虽然训练难度高导致所需的训练次数较多,但在进一步充分训练后,模型性能还可以进一步提升。
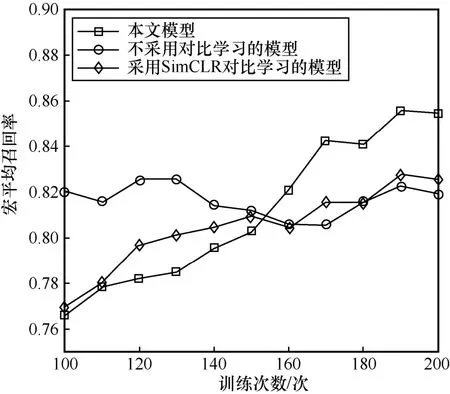
图3 已知恶意流量训练阶段不同模型的性能变化
已知类分类阶段不同设置下的归一化矩阵如图4所示。如图4(a)和图4(b)所示,加入对比学习后本文模型对部分大样本类(如良性类和back 类)和小样本类的分类性能有明显提升。但由于加入对比学习后,模型训练难度较大,导致同样训练次数下模型可能训练不充分,极少类(如warezclient 类)性能反而略微下降。
其次,分析再训练过程对小样本类的提升效果。如图4(a)和4(c)所示,再训练后模型对小样本类分类性能几乎都有明显提升。如图4(b)和4(d)所示,再训练过程对不采用对比学习的模型几乎没有帮助。这是因为不采用对比学习的模型对小样本恶意类分类能力较差,其输出的伪标签质量较差,对分类小样本类几乎没有帮助,反而可能降低检测性能。

图4 已知类分类阶段不同设置下的归一化混淆矩阵
在未知类分类训练阶段,本节以已知阶段本文模型为基线继续未知阶段训练过程,分别对比了本文模型和在重构阶段不采用对比学习的模型。如图5(a)和图5(b)所示,在重构阶段采用对比学习对未知类分类性能有一定提升,并且降低了对部分类(特别是良性类)的误判。这是因为对比学习将同类更加聚合,从而使误报减少。由于良性类在实际检测中频繁出现,这对于实际检测性能影响较大。
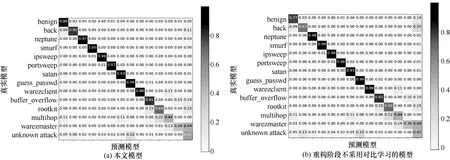
图5 未知类分类阶段不同设置下的归一化混淆矩阵
最后,分析模型对逃逸攻击的防御效果。实验采用FGSM 算法对所有已知恶意类生成对抗样本测试。如图6(a)和图6(b)所示,相比不采样的模型,采取重采样的本文模型在同样烈度的逃逸攻击下分类性能更高,证明了重采样能有效对抗逃逸攻击。如图6(a)和图6(c)所示,不采用对比学习的模型也增强了对抗逃逸攻击的能力。最后,如图6(a)和图6(d)所示,大部分逃逸攻击即使在已知类分类阶段骗过了模型,但在未知类分类阶段逃逸攻击大多被分类为未知攻击类,也能一定程度上发现逃逸攻击。

图6 不同设置下遭受逃逸攻击后的归一化混淆矩阵
3.4 性能分析
本节讨论本文方法与其他方法的性能对比。其中,基线模型是先进的CVAE-EVT 模型[8]。在此实验结果与文献[8]中不同的原因主要包括以下两点:一是数据预处理方式和MLP 网络结构不同;二是采用价标准不同,本文采用宏平均指标评。
在已知类分类阶段,分类模型都能实现对大样本已知恶意类的分类。但实际中由于网络欺骗流量或业务变化,往往存在概念漂移等问题,模型需要能快速训练并应用。因此,本节在此主要测试在相同训练时间内(本文模型在实验环境下训练200 次的时间——约5 min),几种方法对良性类、大样本已知类和小样本已知类的宏平均指标如表2 所示。表2 中,尽管随机森林方法在大样本类部分指标得到了更优结果,但不能兼顾精度与召回率。这是因为随机森林方法未采取措施平衡稀疏类,导致对稀疏(小样本)类精度提升但召回率下降,对大样本类则反之。实际中对于出现次数较少的恶意类,高召回率则代表了低漏报率,这对攻击检测而言更为重要。且随机森林对小样本类束手无策,而本文模型由于加入了对比学习以及再训练方法,在各阶段都表现出了最佳综合性能,特别是在小样本类的分类上提升明显。

表2 已知类分类阶段不同模型检测性能对比
在未知类分类训练阶段,相同训练时间内本文模型与先进的CVAE-EVT 模型[8]进行了对比。图7 给出了不同未知类设置下的宏平均F1值。加入对比学习的本文模型对各类未知类的检测性能基本优于CVAE-EVT 模型,证明了本文方法的先进性。
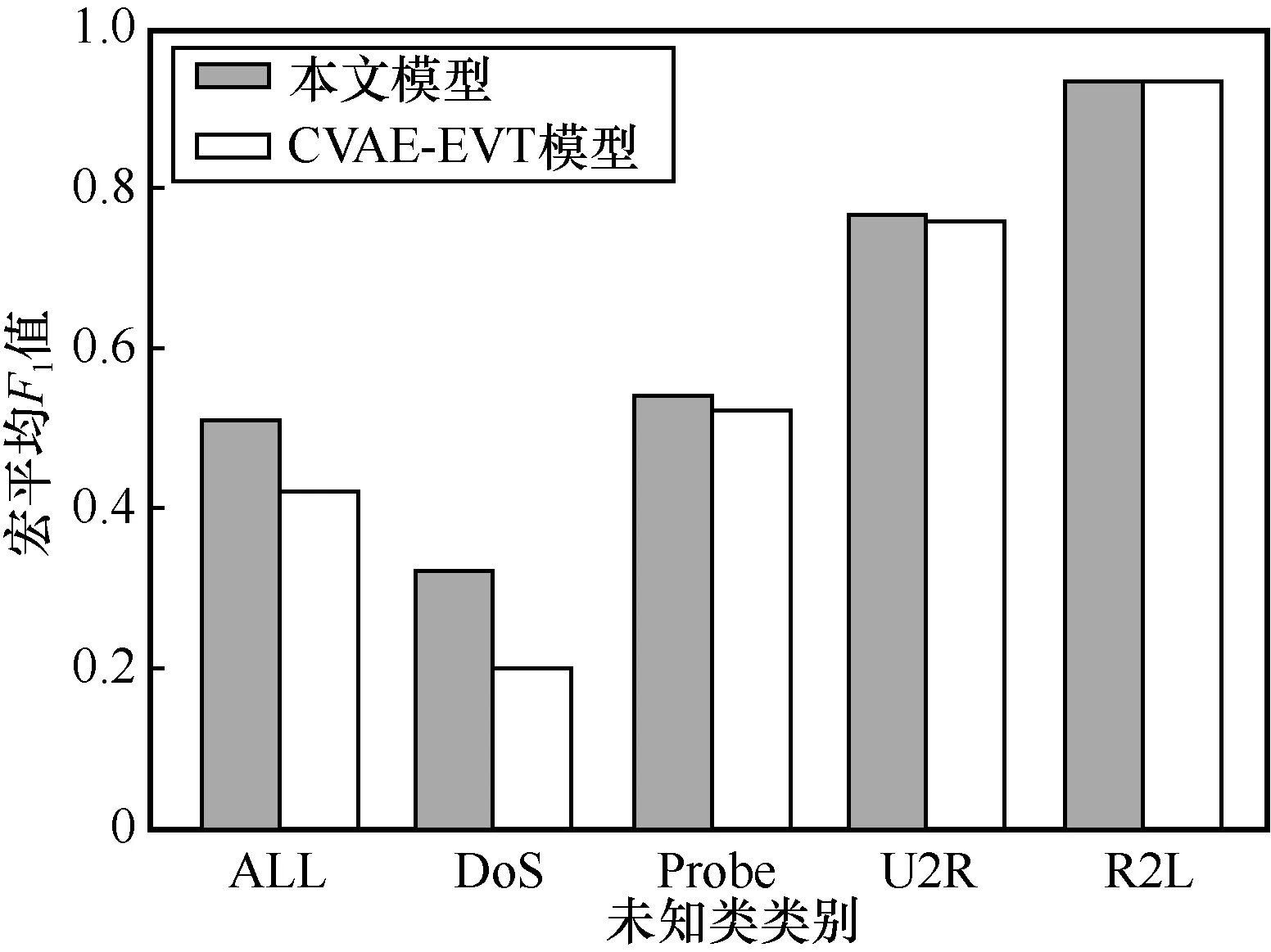
图7 不同未知类设置下的宏平均F1 值
4 结束语
本文旨在设计一种应用于NIDS 的细粒度恶意流量分类方法。在CVAE-EVT 模型[8]的基础上,本文提出了一个能够兼顾已知类、小样本类和未知类的方法,且所设计模型需具有较强的泛化性,能够在一定程度上对抗逃逸攻击。该方法通过在各阶段引入了对比学习策略提高分类性能。并且,融合再训练、重采样、L2 正则化等技巧,使模型泛化性能进一步提高。实验结果证明了该方法的有效性和先进性。最后,由于当前逃逸攻击技术不断发展,未来拟在此基础上进一步研究在保证分类性能条件下的防御逃逸攻击流量的方法。
