球类运动中人体姿态估计研究进展
2023-01-03张漫秸杨芳艳季云峰
张漫秸,杨芳艳,季云峰
(1.上海理工大学 机械工程学院,上海 200093; 2.上海理工大学 机器智能研究院,上海 200093)
在体育运动中,运动员的姿态分析可以直观呈现运动员的姿势,为运动员、教练员或者裁判员对赛事评价提供参考。随着计算机视觉技术日益成熟,在体育运动中也开始引入人体姿态估计技术来为运动员的比赛姿态提供了准确的动作分析。
在球类运动中进行人体姿态估计分析有助于运动员技术训练和比赛辅助判罚。技术训练是指通过对运动员的比赛视频进行分析,提取出其比赛动作和轨迹并进行信息处理,为运动员量身定做训练计划,提升其竞技水平。比赛辅助判罚主要是在球类运动中通过对运动员比赛动作和球的位置定位,对 “遮挡球”和“两跳球”等争议球的判罚提供依据。
人体姿态估计的目的是通过对图片、视频以及摄像头视频流等对人体关键点进行定位,抽象表示出人体的形态,并同时进行目标识别、分割、回归与检测等多方面的任务。主流的人体姿态估计算法由基于传统的方法和基于深度学习的方法组成。基于图结构模型和形变部件模型是传统算法的基础,且需要进行特征人工标注,将人体姿态估计问题转变为回归问题,通过回归函数得到人体的关节点坐标,精度低且适用范围小。近年来深度学习的发展日趋完善,人体姿态估计通过使用神经网络学习捕捉图片信息,可获得不同感受野下多尺度多类型的人体关键点的特征向量和每个关键点的全部上下文,从而更准确地反映人体姿态信息。
随着深度学习的发展,人体姿态估计逐渐被应用在球类运动中,并且在提高运动员竞技水平方面取得了一定的效果。通过对高分辨率的视频进行实时标定、分析,将长片段分解为各小片段,可将运动员的各个动作进行分解,得到运动员每个动作的关节点的坐标数据。依赖这项技术可以对运动员的姿势进行比对,清晰地反映出运动员的不规范动作,促进运动员训练和比赛水平的提高。
1 球类运动中视频分析系统与技术研究
体育比赛中因误判球导致比赛结果争议的事件时有发生,国内外运动组织和团队先后开始借助网络技术来提高比赛判罚的科学性,例如在众多大型比赛中引入“鹰眼”[1]或“视频助理裁判(Video Assistant Referee,VAR)”[2]等技术来提高比赛裁决的科学性。近年来,随着对视频分析系统的研究越发深入,通过视频分析可以直观地表现出运动员的运动轨迹和相关力学作用,最大程度上降低了误判的可能,同时该技术也可以作为运动员科学训练的辅助手段。
1.1 球类运动的视频分析系统应用现状
美国STATS的SportVU(https://www.stats.com/sportvu-footbal)多镜头动态追踪系统于2013年率先被应用于篮球比赛中。该系统由6个3D高清摄像头和计算机组成,每个摄像头在每秒内能采集25张图片。该系统采用光学追踪技术捕捉运动员的动作,其统计算法能够提取出球员和球的坐标,结合机器学习中的主动框架追踪和分析数据,可将比赛时获得的实时数据与运动员日常训练的数据相结合,整体分析运动员的动作和速度。但该系统只能将比赛场上的对象以圆点的形式进行表现,并不能描绘出人体姿态。在2014年的索契冬奥会上,瑞士的“Dartfish”[3]运动视频分析系统也被投入使用。该系统使用数字视频作为输入,能够生成二维标记位置的值,同时能将运动员的动作进行叠加和分解,逐帧看到运动员的姿态,但是该系统的操作步骤较为复杂。由8部分辨率极高的快速黑白摄像机组成的“鹰眼”[1]系统能够以每秒2 000帧的速度读取摄像机中的图像,并将其传输给主控电脑。该系统能全面分析发球的速度、时间、方向等问题,为运动员的训练和判罚提供依据,因此也被称为“即时回放系统”。但是该系统也无法定位到人体的各个关节点,不能将人体坐标与球坐标融合。在国内,创冰DATA(http://data.champdas.com)系统主要用于对足球比赛的数据分析。通过对每场比赛视频进行秒级数据切片,可多维度地对云端数据进行分析。该系统依赖于分布式计算平台,虽可保证比赛数据的准确性,但依然缺少对于球员的定位与分析。灵信体育近几年开发的“赛事数据采集与分析系统”(http://www.listensport.com)由8部具有热成像功能的高速相机和灵信体育大数据分析软件组成,主要被应用于足球比赛中。其利用图像的颜色信息分割出球员,通过结合基于灵信体育系统中模板匹配的方法来实现球员的追踪,但运动员的动作分析准确率和效率仍有待提高。
1.2 球类运动的视频分析技术研究进展
随着视频分析在运动训练和判罚领域被逐步开发应用,视频分析的技术也在不断提高。视频分析从最初的提取低层次特征作为研究对象提升为提取高层次特征进行处理分析。文献[4]提出了一种基于子窗口区域的镜头分类方法,在HSV (Hue Saturation Value)颜色空间中计算出像素比率,结合检测到的边缘信息,对足球视频中的各类型镜头进行分类。文献[5]提出了一种基于隐马尔可夫模型的分类技术,对每一帧的颜色变化速度进行计算,并将其作为HMM(Hidden Markov Model)中的观察序列进行分类。文献[6]提出体育视频冗余数据的概念,采用主区域颜色和多重区域分割的算法检测出较为准确的比赛视频。文献[7]利用光流和颜色特征对足球比赛视频进行检测,基于光流变化分割视频的连续帧,并对检测到的所有事件进行分类。文献[8]引入了共享粒子,使用组合外观和运动模型全局评估的模型场粒子,将目标之间的交互封装在状态空间模型中。该方法在足球比赛中能较好地进行有相似外观和不可预测运动模式的运动员追踪。文献[9]提出一种基于粗糙时间约束的语义匹配足球视频标注的方法,利用视频事件和外部文本信息在时间序列上的语义进行匹配,并结合高级特征分析足球比赛视频。文献[10]提出自动分类球员和跟踪球运动的技术,利用上下文信息跟踪球员并结合多模特征进行球员比赛的动作跟踪与分析。
仅提取出视频中的关键帧并对各事件进行分类已经无法满足运动员对于视频分析的要求,准确定位到运动员的关节点并进行姿态分析的应用需求对视频分析技术提出了更高的要求。文献[11]提出了一种用于瑜伽训练的纠正不良姿势的系统,通过计算机视觉技术提取身体轮廓、骨骼主导轴和特征点,将姿态矫正可视化。文献[12]提出了一种使用联合纠正管道来估计游泳比赛中运动员的关节点坐标,利用关节整流的时间一致性来提高关节点定位的准确性,进而辅助运动员矫正动作姿势。文献[13]将运动员的追踪与动作识别通过一个联合框架完成,用一种缩放和遮挡鲁棒跟踪器来定位运动员在每帧画面中的位置,并用一种长期循环的区域引导卷积网络进行动作识别和姿态估计。文献[14]在乒乓球比赛中提出了一种基于长期-短期位姿的乒乓球实时预测系统,以运动员的姿态估计坐标作为输入,并结合乒乓球的轨迹坐标来预测乒乓球的落点坐标,主要用于无法预测落点的乒乓球训练中。表1展示了当前应用在运动类的视频分析技术的研究成果。
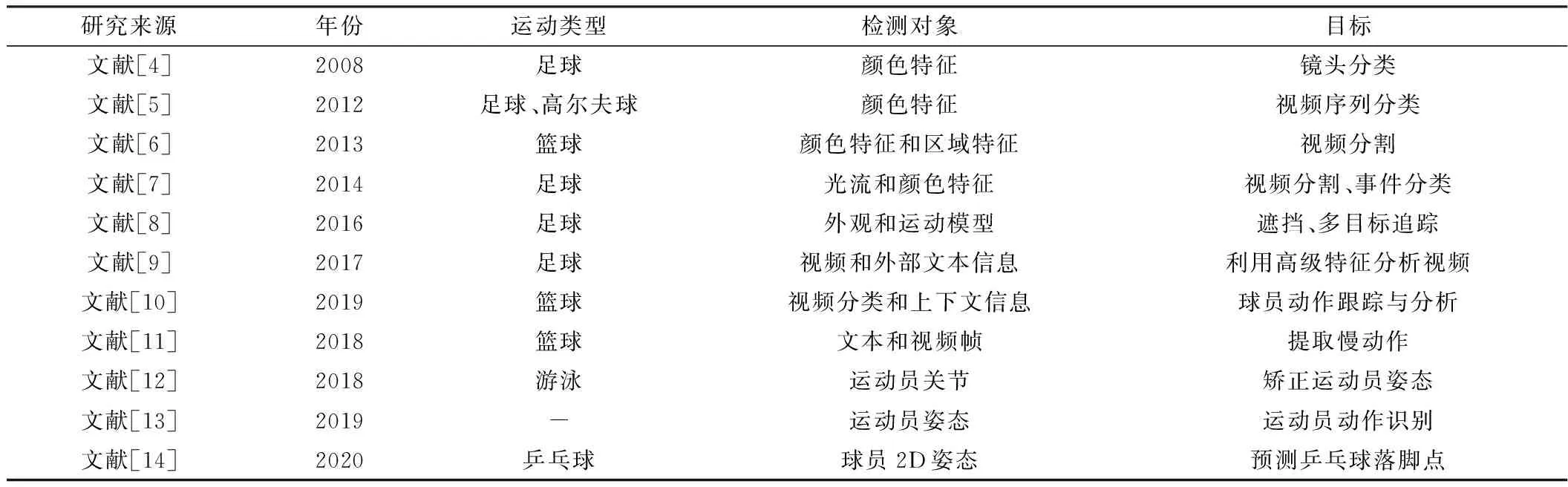
表1 运动类视频分析技术研究进展Table 1. Research progress of motion video analysis technology
2 球类运动视频分析中的人体姿态估计
随着人体姿态估计算法的不断创新,在球类运动中通过提取视频信息逐帧分析运动员的比赛动作的工作效率已有大幅提高。根据人体姿态估计算法原理的不同,可以将其分为基于传统算法和基于深度学习算法两种方法。下文将基于这两种方法来回顾人体姿态估计的研究过程。

图1 人体姿态估计方法分类Figure 1. Human body pose estimation methods classification
2.1 基于传统算法
传统算法是基于几何先验基础进行模块匹配。其中文献[15]提出的图结构模型是最具代表性的传统算法。利用图结构进行人体检测是将待检测的物件表示为多个部件的集合,且在部件之前存在着空间约束。关节点的检测则需要经过人工指定的特征检测组件来完成。其中图结构主要包括部件模型和空间模型两部分。
在部件模型方面,文献[16]在2005年提出了HOG(Histogram of Oriented Gradient)特征描述方法,其构成特征需计算和统计图像局部区域的方向梯度直方图。这种方法首先引入细胞单元的概念,即将图像分为各小的连通区域,然后采集细胞单元中各像素点或边缘的方向直方图,最后组合采集到的该图像的直方图。文献[17]提出的SIFT(Scale Invariant Feature Transform)特征通过对特征点进行极值检测、定位、方向赋值及描述来提取图像的特征。这种方法检测的特征能较好地应对旋转、尺度缩放、亮度变化等情况,是一种较稳定的局部特征。
在空间模型方面,文献[18]提出的混合部件模型除了关注两个部件之间的空间约束,也有了一些更大工作范围的约束,能够表达更为复杂多样的空间约束,用于解决人体姿态估计中的自遮挡问题。
但是传统算法依赖于人为设计的模板,难以应用到多人姿态估计中,并且由于模型结构的单一简单,因此对于复杂场景中的人体姿态估计较为低效,当人体姿态发生大幅度变化时,可能出现姿态估计不唯一的情况。
2.2 基于深度学习算法
传统算法中由于模型的结构单一,当人体姿态变化较大时,不能准确地刻画和表达出这种变化,同一数据存在多个可行的解,也就是说姿态估计结果不唯一。另一方面,这种传统的基于手工提取特征并利用部件模型建立特征之间联系的方法较为低效和昂贵。卷积神经网络的发展给计算机视觉技术发展带来了新方向。文献[19]提出了Deep-Pose网络,将人体姿态估计的研究由传统算法带入到深度学习方法。基于深度学习方法的人体姿态估计可以被分为单人姿态估计和多人姿态估计。
2.2.1 单人姿态估计
单人姿态估计是对输入的单人图片进行检测,检测出其全部关键点。单人姿态估计主要有以下几种思路:基于坐标回归、基于热图检测以及两者混合模式。
基于坐标回归的模型(Coordinate Net)将关节点的二维坐标作为Ground Truth,训练网络可直接得到每个关节点的坐标。文献[19]首先提出了基于深度学习进行单人姿态估计的Deep-Pose网络,并设计卷积神经网络(Convolutional Neural Networks,CNN),通过运用多阶段回归的思路,以关节点二维坐标作为优化目标直接回归到人体骨骼关节二维坐标。这种方法被称为多阶段直接回归,可以在检测初期得到人体关节点的大概位置,并以当前得到的关节点作为坐标中心在进入下一阶段进行回归前,对检测到的关节点附近切取小尺度的子图像,并以此作为该阶段回归的输入,不断修正坐标值。其网络结构如图2所示。文献[20]在基于坐标回归的基础上提出了另一种多阶段分步回归的IEF(Iterative Error Feedback)模型。IEF模型并不像Deep-Pose方法使用多阶段端到端进行一个批次的训练,而是在训练时分成4个阶段,每个阶段进行3个完整的批次迭代,通过反馈错误预测逐步调整初始预测。这种方法将关节点的二维坐标作为迭代目标,将热图作为特征图,同包含纹理信息的原始图像级联起来输入网络,通过多阶段回归得到关节点位置。

图2 Deep-Pose网络结构Figure 2. Deep-Pose network architecture
总体而言,基于坐标回归的结构可以看出它并没有结合人体各关节间的信息,且通过以上文献的训练结果不难看出单独使用坐标回归进行人体姿态估计误差较大。坐标回归模型对多尺度的姿态估计泛化性能较差,因此在2015年以后这种方法很少被采用,但是该网络所呈现的利用多分辨率进行图像处理的策略和多阶段的思想得到了广泛应用。
基于热图检测的模型(Heatmap Net)用概率图heatmap来表示关节点坐标,其估算图像中每一个像素对应了一个概率值。当像素点位置越接近关节点时,其对应的概率值越接近1,越远离关节点越接近0。Heatmap Net的优点在于建立了基于概率分布的Ground Truth,同时建立了部分人体部件之间的结构信息。文献[21]将图结构模型与CNN进行联合训练,将人体关节看为抽象的变量节点,通过heatmap得到关于关节点变量的概率分布,并依赖MRF(Markov Random Field)[22]对所有相邻关节点组成的关节对进行建模。最后,构建相应的网络结构计算每个pair-wise内的条件概率分布,使得每个pair-wise内的节点可以互相修正相邻节点的heatmap。每个pair-wise关系需要构建4个子网络模块作为部件检测器进行训练,其中两个用于训练heatmap,另外两个用于训练亲和力图。整体的MRF进行训练时,会不断删除联合概率较小的冗余pair-wise关节点,优化人体所有关节点的联合概率分布,进而生成一个相对准确完整的人体姿态关节点位置分布图。
文献[23]提出的堆叠沙漏网络(Stacked Hourglass Network)同时利用了局部信息和全局信息,其网络结构如图3所示。其主要贡献在于利用多尺度特征识别姿态,整体的网络结构是单个沙漏模块串联组成,通过重复利用全身关节信息提高了单个关节的识别精度。堆叠沙漏网络一方面通过多分辨率的heatmap检测局部关节点的位置信息;另一方面通过多尺度感受野机制学习获得关节之间的学习特征。文献[24]在堆叠沙漏网络基础上进行了改进,通过对残差模块嵌入多支卷积搭建了一个金字塔残差模块来学习图像特征,用以解决因为人体姿态大幅度变化导致的关节点尺度变化。特征金字塔模块PRM(Pyramid Residual Module)共有4种,分别是PRM-A、PRM-B、PRM-C和PRM-D,其网络结构如图4所示。PRM-A在原有残差模块的分支基础上加入了分辨率分支,增加的多个分辨率分支主要是通过下采样实现其分辨率的不同。残差模块需要将不同分支的结果进行相加得到最终的残差模块结果,因此下采样后的特征需要通过上采样恢复原来的分辨率。PRM-B则是以PRM-A为基础,将PRM-A中不同分辨率的分支以1×1卷积的方式进行参数共享,减少了参数数量。PRM-C将PRM-B中多分辨率特征的相加改为了串联,串联后的特征通道与旧模式有所不同,因此可能需要引入一个1×1的卷积将特征通道对齐后与原特征进行相加。PRM-D则是使用空洞卷积代替下采样和上采样得到多尺度的特征。除此之外,对原始特征添加一个Bn-ReLU-Conv操作即可解决原始特征直接与卷积后的特征相加导致的方差较大的问题。

图3 堆叠沙漏网络Figure 3. Stacked hourglass network

图4 特征金字塔模型(a)PRM-A (b)PRM-B=Addition; PRM-C=Concatenation (c)PRM-DFigure 4. Pyramid residual modules(a)PRM-A (b)PRM-B=Addition; PRM-C=Concatenation (c)PRM-D
文献[25]提出了一种新颖的高分辨率网络HRNet(High-Resoultion Net),不同于之前的网络在信息融合过程中采用低层信息与高层信息融合的方式,HRNet能保持高分辨率进行特征提取,并在学习过程中进行多次多尺度融合使预测的热图精确率更高。文献[26]在HRNet的基础上设计了一种编码-解码网络,其中编码器沿用HRNet,解码器采用了提出的一种高效网络结构CCM(Cascaded Context Mixer)。CCM可以有效整合空间和上下文信息并逐步完善信息。该研究还开发了一种利用大量未标记的数据进行困难负样本的人体检测策略,使CCM能够从大量不同的姿态中学习识别特征。文献[27]提出了一个用于人体姿态估计的统一框架:UniPose。该网络基于WASP(Waterfall Atrous Spatial Pooling)模块,不仅不依赖后续处理的信息,还结合了上下文分割和联合定位功能,使得人体姿态估计在单阶段具备高精度。
回归与检测的混合模型主要是将Coordinate Net和Heatmap Net的结构通过串联或者并联结构直接级联在一起。文献[28]率先提出Coordinate Net和Heatmap Net的串联结构,即整体包括部件检测器和回归网络两部分。在部件检测器获得部分heatmap信息后预测可见关节点的近似热力图,串联回归网络模块获得更多关节点互相依赖的语义信息,并且在回归模块中设计了同样大小的卷积核,这样低置信度的heatmap对后面坐标修正的影响较小,其网络结构如图5所示。文献[29]提出了双源卷积网络用来构建两个并行的网络模块,即设置了关节点检测网络和关节点定位回归网络交互式辅助训练,其具体结构如图6所示。关节点检测网络用于检测图像补丁(Part Patch)包含的局部关节点类别信息。关节点定位网络模块通过结合整幅图像(Body Patch)。Part Patch和Body Patch的二进制掩码回归关节点位置坐标,检测模块利用Body Patch的全局特征判断腕关节的左右属性,定位回归模块则根据Part Patch的局部信息归一化位置坐标。

图5 串联结构图Figure 5. Diagram of the series structure

图6 双源卷积网络结构Figure 6. Dual-source deep convolutional neural networks
2.2.2 多人姿态估计
通过以上单人姿态估计的方法可以得到单人的2D关节点坐标,但是多人姿态估计并不仅仅是单人的多次检测,还需要区分不同人体的关节点,避免不同人之间的关节点误连。因此,多人姿态估计的算法主要分为自顶向下的两步法和自底向上的基于部件的框架两种。
自顶向下的人体姿态估计方法可分为两步:首先进行目标检测,将图像中的人体框处;随后对每个框内进行单独的人体检测。目前经典的目标检测算法可分为两步走和一步走两类。两步走策略基于先选出候选区域然后通过CNN进行分类;一步走算法则可以通过端到端进行输出类别的划分和关节点定位。文献[30]构建了1个两阶段网络,其中第1阶段使用FasterR-CNN[31]划分出可能包含人的区域;第2阶使用全卷积残差网络预测每个人的关节点坐标,并引入了两个偏移参数来提高关节点的预测精度。文献[32]通过将第1阶段网络得到的所有层次特征整合到一起,并结合在线困难关键点挖掘技术,更侧重于“困难”关键点的检测,其网络结构如图7所示。文献[33]提出了1种新的方法进行人体姿态估计,其通过剪切视频的中心帧,将视频剪切成重叠的片段然后进行人体检测,将来自不同时空的姿势合并成任意长度的轨迹。文献[34]针对自顶向下方法中数据处理所存在的没有系统考虑的问题,提出了1种将分类与回归组合进行编码解码的数据处理方法。该算法有效解决了由于关键点预测过程中进行的翻转操作所带来结果不对齐的问题。文献[35]针对Anchor-Free模型用于行人搜索过程中所存在的尺度不对齐、区域不对齐、任务不对齐问题提出了AlignPS(Feature Aligned Person Search Network)模型。该模型通过可变性卷积重新塑造了FPN(Feature Pyramid Networks)网络,使用3×3的可变形卷积代替FPN中相邻侧所连接的1×1的卷积,扩大了输入图像的感受野;使用连接代替求和从而融合了多尺度特征;输出层使用3×3的可变形卷积代替FPN输出层的3×3卷积,提高了特征图的精度。文献[36]提出1种基于“上下文建模”的方法进行人体姿态估计,即估计出1个关节的位置可相互充当其它关节的“上下文”。在估计某一关节点时,首先通过其“上下文”的信息收集特征,并对其施加肢体长度的约束,随后整合其收集的特征并更新该关节点。

图7 级联金字塔网络Figure 7. Cascaded pyramid network
自底向上的人体姿态估计算法过程与自顶向下相反,其基于部件的框架进行人体检测时,分为进行关节点部件检测和关节点部件聚类。文献[37]通过在向量场中对人体不同肢体结构建模,有效解决了单纯使用肢体中间点方法所产生的多人检测中的错连问题。文献[38]则通过部位分割对关键点间的关系进行建模,该方法既可以提供人体关键点之间的空间先验知识,还对关键点的聚类产生辅助作用。文献[39]提出了一种新的自底向上的人体姿态估计方法,利用高分辨率特征金字塔来学习尺度感知表示,将图像进行上采样之后再进行特征提取与检测,解决了自底向上的多人姿态估计问题中的尺度变化问题,特别是小尺寸关键点的精确定位问题。文献[40]提出了1种从単目RGB图像中进行多人姿态识别的方法,使用高分辨率的体积热图对关节位置进行建模。利用完全卷积网络将热图压缩成密集的中间表示,可以有效减少热图的四维体积,使其输出形状与二维卷积输出一致,随后利用Code Predictor来预测解压时的原始值。文献[41]针对自底向上方法所存在的针对同一张图不同尺度对象会对应不同的感受野问题,提出了尺度自适应热力图回归,根据人体大小自适应生成对应感受野的标准差。该研究还提出了权重自适应回归平衡正负样本,提高了尺度自适应热力图回归效果。文献[42]提出了一种基于YOLOv3算法的行人检测模型,通过构造Darknet19为主干网络,引入广义交并比损失函数来提高检测精度。
3 人体姿态估计数据集与方法技术指标
为了保证算法训练的准确性,需要进行大量的数据训练与学习。本章节总结了近年主流的用于算法测试的数据集,并对算法测试的结果进行对比。
3.1 相关数据集基准
如表2所示,列举了近年来主流的人体姿态估计数据集。由于早期研究资源的匮乏,人体姿态数据集多是针对单人姿态估计的标注。LSP(Leeds Sports Pose)[43]和FLIC(Frames Labeled in Cinema)[44]数据集则是针对单人姿态进行标注。随后,MPII[45]数据集标注了16个人体关节点,并将其作为单人人体姿态估计算法的训练与评估的基准。在多人姿态估计方面,MSCOCO(Microsoft Common Objects in Context)[46]是于2014年发布的用于深度学习的综合性数据集,其标注了人体17个关节点。AI Challenger[47]数据集包含了海量的人体姿态训练测试图,是当前最大的人体姿势图像数据集。Crowd Pose[48]从现有的数据集中筛选出20 000张有关人体姿态研究的图片,且将人体关节点统一标注为14个,作为研究拥挤场景下的人体姿态的数据集。

表2 人体姿态估计数据集介绍Table 2. Introduction to human pose estimation data sets
3.2 评价指标
现在主流的人体姿态估计算法评价指标有PCP(Percentage of Correct Parts)、PCK(Percentage of Correct Keypoints)和mAP(mean Average Precision)等。
PCP即正确估计人体部位的百分比。其评判标准是两个预测的关节点位置与实际关节点的关节点位置距离应小于肢体长度的一半。
PCK即正确估计人体关节点的比例。其依据肢体长度为基准值,以此来评估身体其他部位的检测精度,也就是被检测的关节点是否与其对应的真实标注数据间的统一化距离小于设定的阈值。
mAP即平均精度。其计算方式是将每一个关节点在不同阈值下所检测到的AP值取平均值得到最终的结果,可反映人体全部关节的平均检出率。
3.3 对比分析
本文从单人姿态估计和多人姿态估计两个角度比较各个算法的性能。表3列出了在FILC、LSP、MPII数据集上单人姿态估计算法的表现情况。表4列出了在MPII、MSCOCO、MAP数据集上不同多人姿态估计算法的表现。

表3 单人人体姿态估计方法比较Table 3. Comparison of individual body pose estimation methods

表4 多人人体姿态估计方法比较Table 4. Comparison of human body pose estimation methods for multiple people
4 结束语
本文对球类视频分析系统的发展做了介绍,对人体姿态估计的研究进行了全面综述。由于球类运动具有快速性和连续性,因此引入人体姿态估计可以有效解决人体遮挡问题,并准确定位人体与球的坐标,进行空间坐标分析。较之以往,当下对于运动中人体姿态的数据集的需求显著增加,正确标注的运动姿态的数据集能提高人体姿态估计的准确性,这也是将人体姿态估计推广应用到各类比赛中的重要基础。对于人体姿态估计方面,可将基于传统算法的几何先验知识与基于深度学习算法融合,同时将多模态信息融合,并进一步通过改进网络结构来提高人体姿态估计的准确率,可为以后的体育视频分析提供新的更加有效的方法。
