基于迁移学习的小样本恶意域名检测
2022-12-30常兆斌
赵 凡,赵 宏,常兆斌
(1.甘肃省科学技术情报研究所 创新平台中心,甘肃 兰州 730000;2.兰州理工大学 计算机与通信学院,甘肃 兰州 730050)
0 引 言
域名系统(domain name system,DNS)难以实时预判攻击行为,极易受到攻击者的关注[1]。攻击者正是利用域名解析的机制[2,3],将合法访问的DNS请求映射到攻击者提前设定的服务器上,并通过命令控制中心C&C(command and control)控制受感染主机[4],窃取受感染主机的信息,导致用户财产、隐私信息等受到威胁。
传统的域名检测方法通过综合分析域名在构词、字符统计和网络结构等方面存在统计特征快速判定恶意域名[5,6]。如文献[7]通过统计大量合法域名的Bi-Gram特征,并根据待测域名中包含的Bi-Gram频次,给出待测域名的分类结果。文献[8]提出了一种结合词法特征的域名判定方法,通过计算待测域名与历史数据之间的编辑距离和差异度值,快速做出判定。文献[9]通过提取28维域名字符特征,并结合粗糙集增量式规则的机器学习分类算法实现恶意域名的分类。利用提取的域名字符特征并结合机器学习分类算法识别恶意域名是一种最直接的检测方法,但检测中大多依赖手工设计的特征,且特征维度有限,影响检测效果。
结合深度学习相关算法快速判定待测域名的合法性,成为近年来的热点研究。如文献[10]将可分离卷积引入恶意域名检测领域,综合考虑了检测时间开销和检测精度。文献[11]使用长短时记忆神经网络LSTM并引入注意力机制构建恶意域名检测模型,通过实验验证了模型的有效性。文献[12]结合深度学习和自然语言处理技术,构建了一种用于DGA(domains generation algorithm)算法生成的恶意域名检测模型。文献[13]在循环神经网络的基础上引入注意力机制,提出了一种恶意域名检测方法,缓解了利用随机生成模型生成的恶意域名随机性强而难以检测的问题。
近年来的研究成果表明,基于深度学习的恶意域名检测算法检测性能明显优于传统基于字符特征匹配的恶意域名检测算法[14]。然而随着检测方法的增多,新变种、新出现或伪造等域名的类型不断丰富。现有主流的恶意域名检测模型对于该类小样本恶意域名的识别效果不佳。因此设计出一种能够识别出多种家族多种类型的小样本恶意域名检测模型是恶意域名检测领域的一个重要研究方向。
综上,针对现有恶意域名检测模型对新变种、伪造等类型的域名识别精度不高和识别类型较少的问题。首先,通过构造BiLSTM和CNN的组合模型BiLSTM-CNN,并利用数据量充足的多家族恶意域名集进行迁移知识的预训练;然后,迁移混合模型BiLSTM-CNN的知识到小样本恶意域名检测模型中,并利用已有小样本历史数据微调提出的BiLSTM-CNN,构造一种小样本恶意域名检测算法。
1 算法设计与分析
基于迁移学习的小样本恶意域名检测算法分为数据预处理、BiLSTM-CNN模型构造、小样本迁移模型构造等3个步骤,算法框架如图1所示。
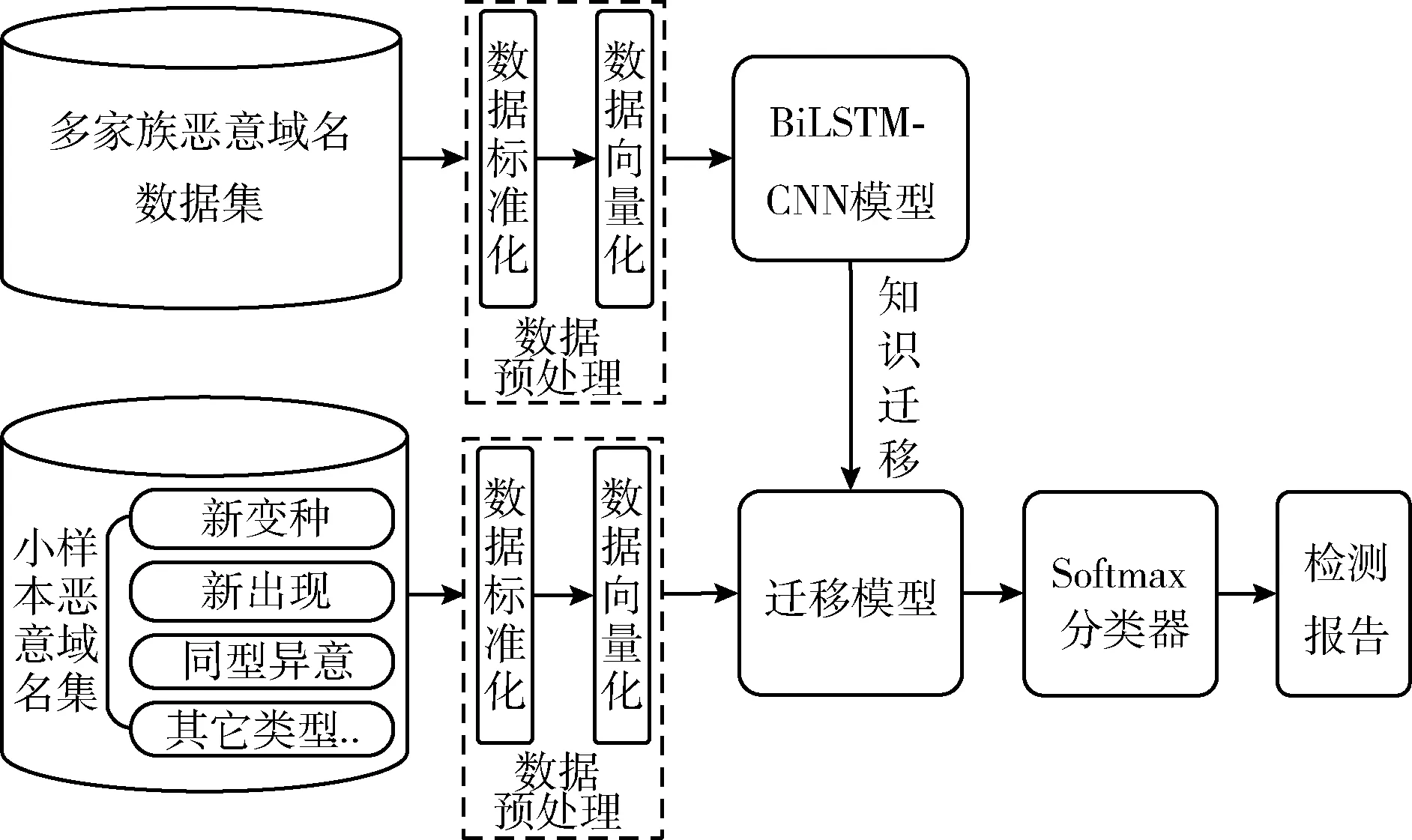
图1 算法框架
首先,采用Keras中的Embedding层将规整后的URL(uniform resource locator)映射为数值向量;然后,利用BiLSTM提取多家族URL的全局特征,利用卷积神经网络CNN在学习BiLSTM网络提取域名上下文信息的基础上,进行局部强特征提取,并采用充足的多家族域名数据集进行预训练;最后,通过迁移BiLSTM-CNN恶意域名检测模型预训练的知识参数到小样本的恶意域名检测模型中,并利用新变种、新出现等小样本恶意域名集进行参数微调。
1.1 数据预处理
由于顶级域名数量少、长度短、知名度高、容易识别等原因,很少在域名顶层设计恶意域名[15]。因此,本文模型首先提取第二层域名和其余子域名层,构造恶意域名集和合法域名集。
为了将域名送入到神经网络中进行特征提取,首先需要对URL中的字符进行向量化。传统字符向量化存在One-hot编码和分布式(distributed word representation,DWR)表示等两种,其中One-hot编码表示如 [0,0,…,0,1,0], 其中1表示该字符在字典集中的位置,当字典维度较大时,该类编码方式计算开销较大,且编码稀疏,无法表达上下文关联信息;DWR编码方式可以将字符映射为定长向量,维度可控,因其出色的上下文信息包含能力被广泛地应用。因此,本文采用分布式编码DWR对URL中的每个字符进行数值向量化。URL字符量化前需统计URL中常见的字符个数,本文根据ASCII码字符集设定映射字典为128维。图2以甘肃省科学技术情报研究所的主体域名“gsinfo”为例说明量化过程。
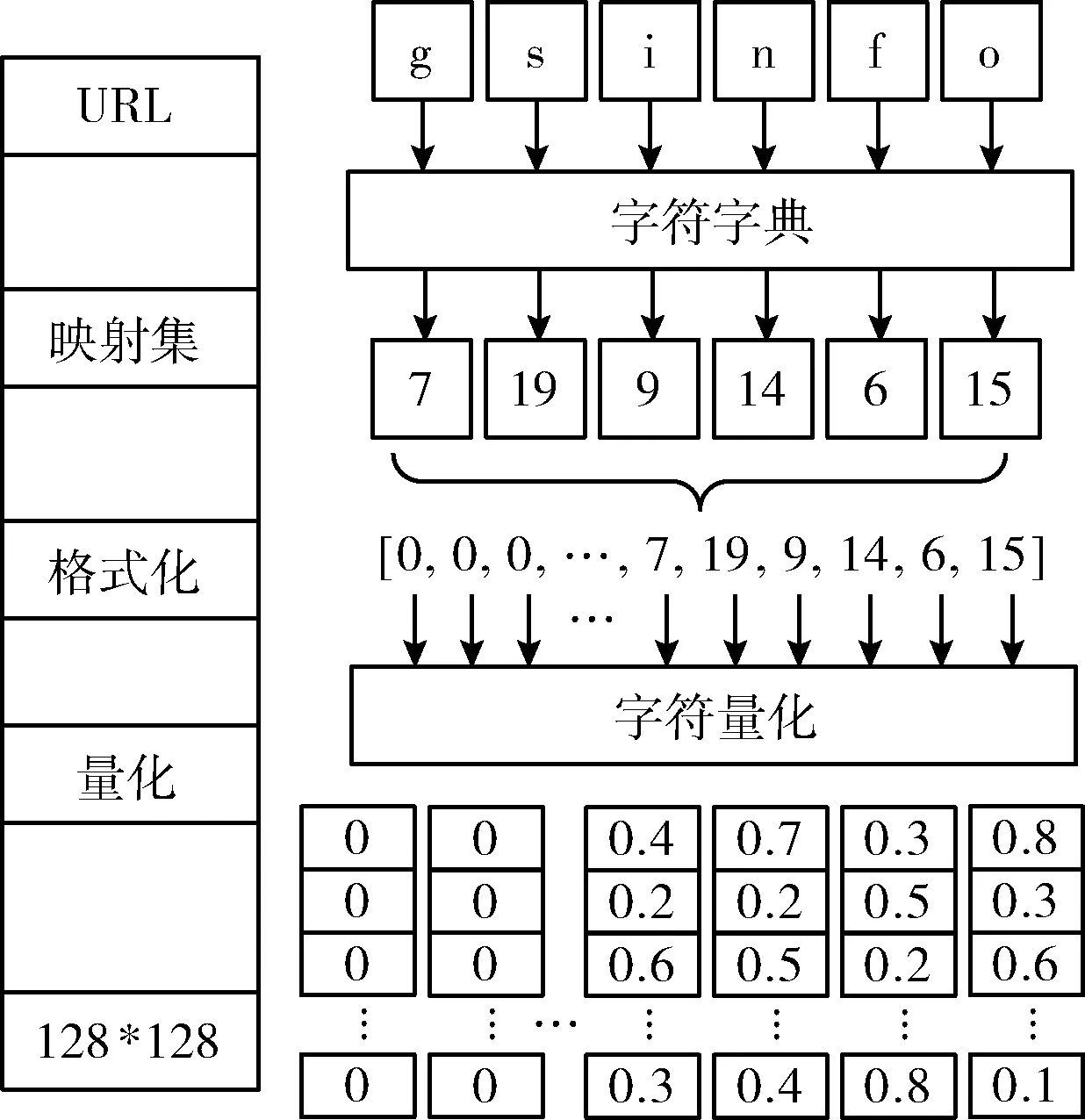
图2 域名向量化
由于神经网络的输入为定长的向量,此处设定域名字符串截断长度为Len。如果字符串长度大于Len,对超出部分的字符或字符串剪切;当字符串长度小于Len时,利用零向量补全,本文Len取值128。具体截断方式采用式(1)
(1)
式中: F(urli) 为规整后的域名字符串向量;urli为待调整的域名字符串;Vz是零向量。
1.2 BiLSTM-CNN模型
(1)BiLSTM模型
不同家族的域名生成方式和结构特征各不相同,然而,在字符统计特征和语义关联上仍存在上下文依赖关系[16]。为此,本文利用BiLSTM网络提取域名字符序列的上下文特征。BiLSTM网络的结构如图3所示。
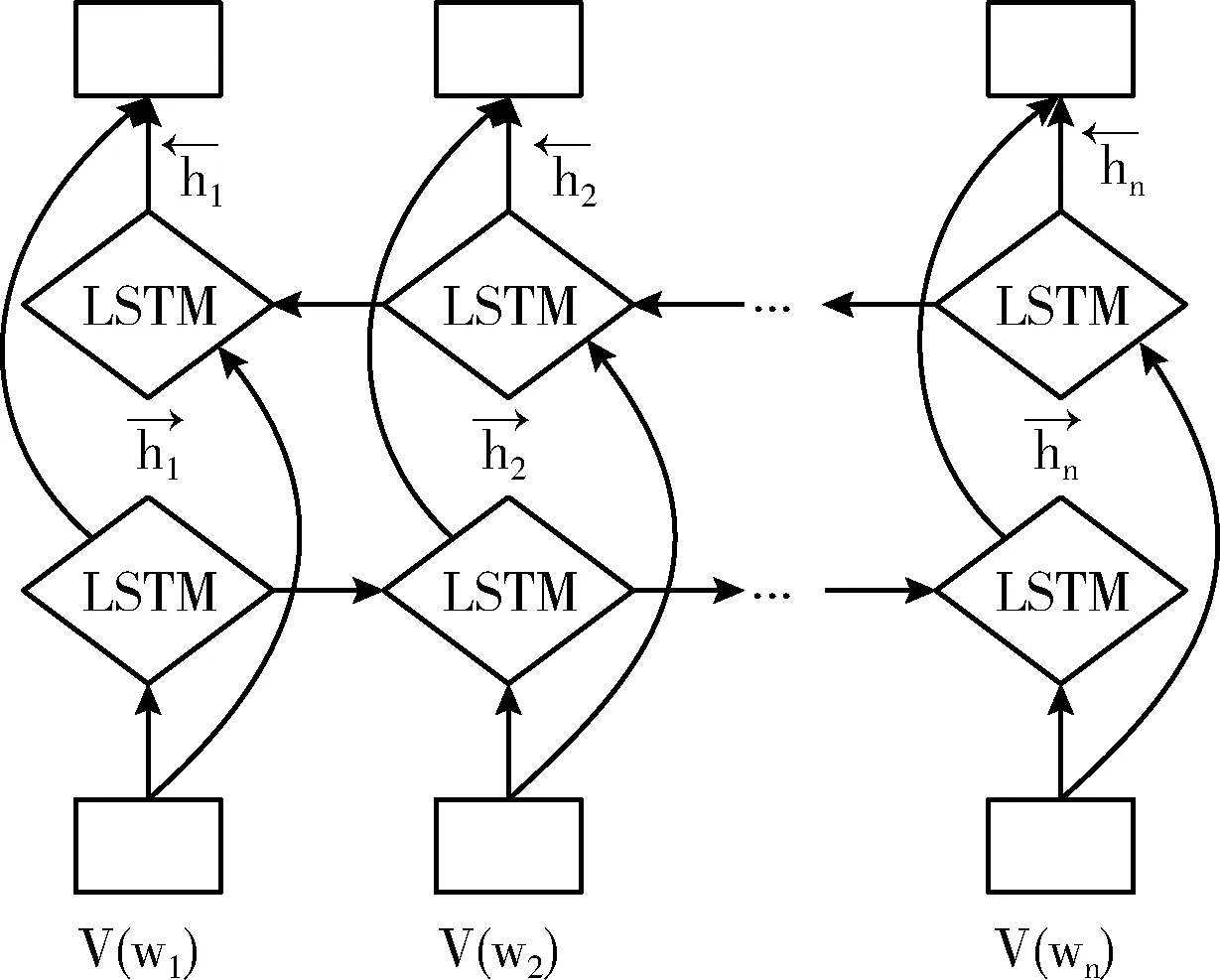
图3 BiLSTM结构
图3中, S={V(w1),V(w2),…,V(wn)} 表示域名向量化矩阵,利用BiLSTM进行上下文特征提取,BiLSTM上下文提取计算请参见文献[17]。
(2)CNN模型
卷积神经网络CNN是一种前馈神经网络,近年来被广泛地应用于时间序列分析[10]。本文采用图4中的CNN网络模型在学习BiLSTM提取URL序列的上下文特征的基础上,进行局部深度特征提取。
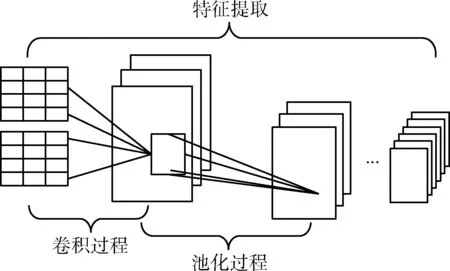
图4 CNN网络结构
卷积层将BiLSTM的输出作为输入,通过CNN的卷积运算提取域名字符序列在空间维度上的深层特征。计算如式(2)所示
ot=f(wd·ht+bt)
(2)
式中:ot为t时刻卷积层的输出特征;f为缩放指数线性函数Selu,wd表示卷积核的大小,ht表示t时刻BiLSTM的输出,bt表示偏置。当卷积核计算完成所有BiLSTM的输出 HBiLSTM={h1,h2,…,ht,…,hn} 后,得到输出特征Oconv={o1,o2,…,ot,…,on}。
获得特征序列Oconv后,对其进行池化操作,本文采用平均池化的方法,计算如式(3)所示
pt=ave_pool[Oconv]
(3)
(3)BiLSTM-CNN混合模型
图5给出了BiLSTM-CNN构造流程。在特征提取阶段,首先采用双向长短时记忆神经网络BiLSTM提取URL序列的上下文特征;然后,利用卷积神经网络CNN进行局部深度特征提取;在分类阶段,为防止模型过拟合,提升模型的鲁棒性,在全连接层之前使用Dropout对神经元随机丢弃,并将Dropout层的输出作为Softmax的输入,计算出分类结果,本文Dropout取值为0.5。
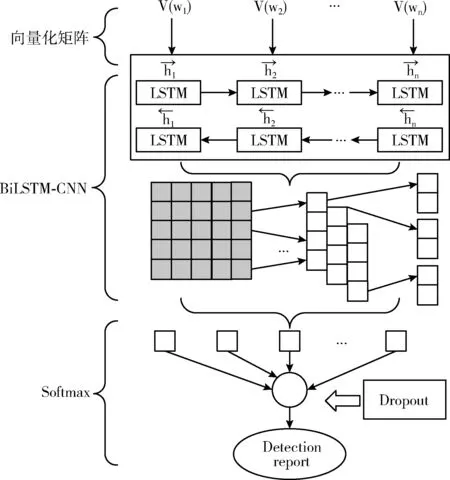
图5 BiLSTM-CNN网络结构
1.3 小样本恶意域名检测模型
参数迁移的方法能够实现模型间参数的共享,有效解决因训练数据样本严重不足的问题。采用域名变换技术或人工生成的方式产生的新变种或新出现的恶意域名由于更新快、数据样本少和信息不全等原因难以精确检测。因此,本文采用迁移学习的方法将已训练好的BiLSTM-CNN混合模型的参数迁移到小样本恶意域名检测模型中,并利用有标签的小样本数据结合全样本梯度下降算法完成小样本恶意域名检测模型的参数微调。模型参数迁移如图6所示。
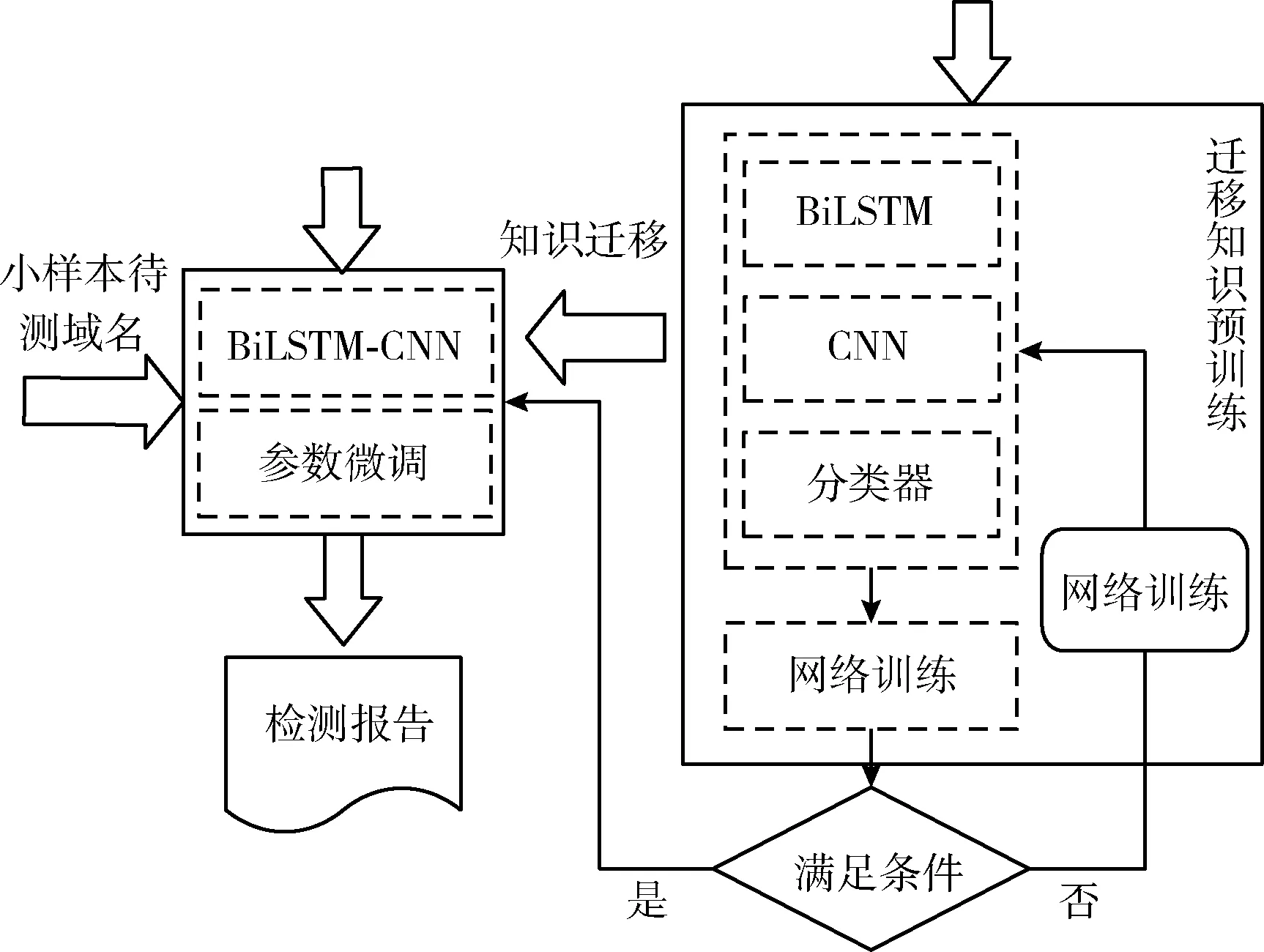
图6 迁移模型
2 实验及结果分析
2.1 数据集
本文数据集包含180 000条合法域名和76 000条恶意域名。样本集详细信息见表1。
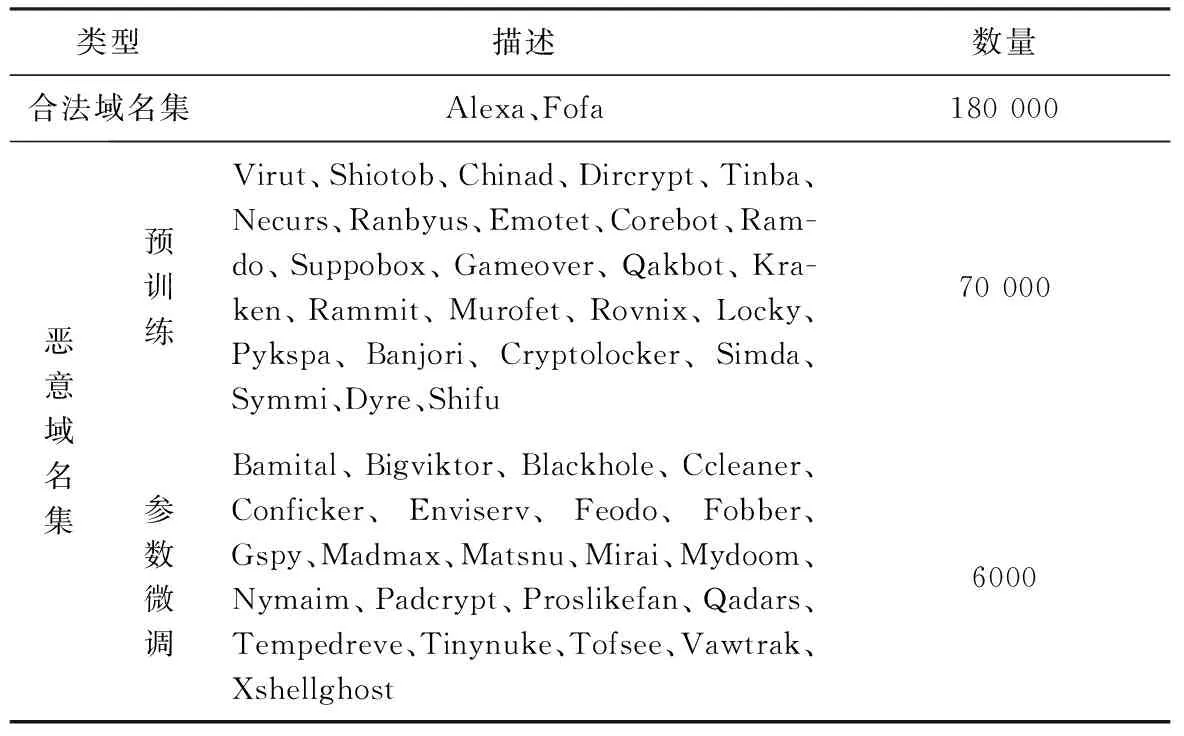
表1 数据集描述

2.2 实验环境与评价标准
实验在Intel Core i7/16 GB的Windows 10下进行;模型的实现基于Tensorflow深度学习框架。
为评估模型对于合法域名与恶意域名的识别性能,采用Accuracy、Precision、误报率FPR和漏报率FNR作为度量指标,通常Accuracy和Precision越高、FPR和FNR越低,表明检测效果越好。计算如式(4)所示,混淆矩阵见表2。此外,为避免单次实验结果不稳定的问题,采用多次实验的平均值作为最终评价结果
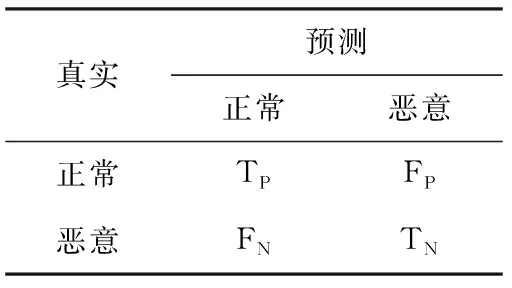
表2 混淆矩阵计算
(4)
2.3 超参数设置
本文模型采用2层BiLSTM层、5层卷积层、5层池化层和1层全连接层。模型详细参数见表3。

表3 参数设置
为防止模型过拟合,在BiLSTM层后加入Dropout层,设定Dropout率为0.5,最后连接一个全连接层,并使用激活函数Softmax完成计算。
2.4 实验结果分析
基于迁移学习的小样本恶意域名检测算法对黑名单集和25种数据量充足的家族恶意域名集的检测性能见表4。表5给出了对22类小样本家族恶意的检测性能。

表4 黑名单集和25种数据量充足的家族恶意域名集的检测性能/%
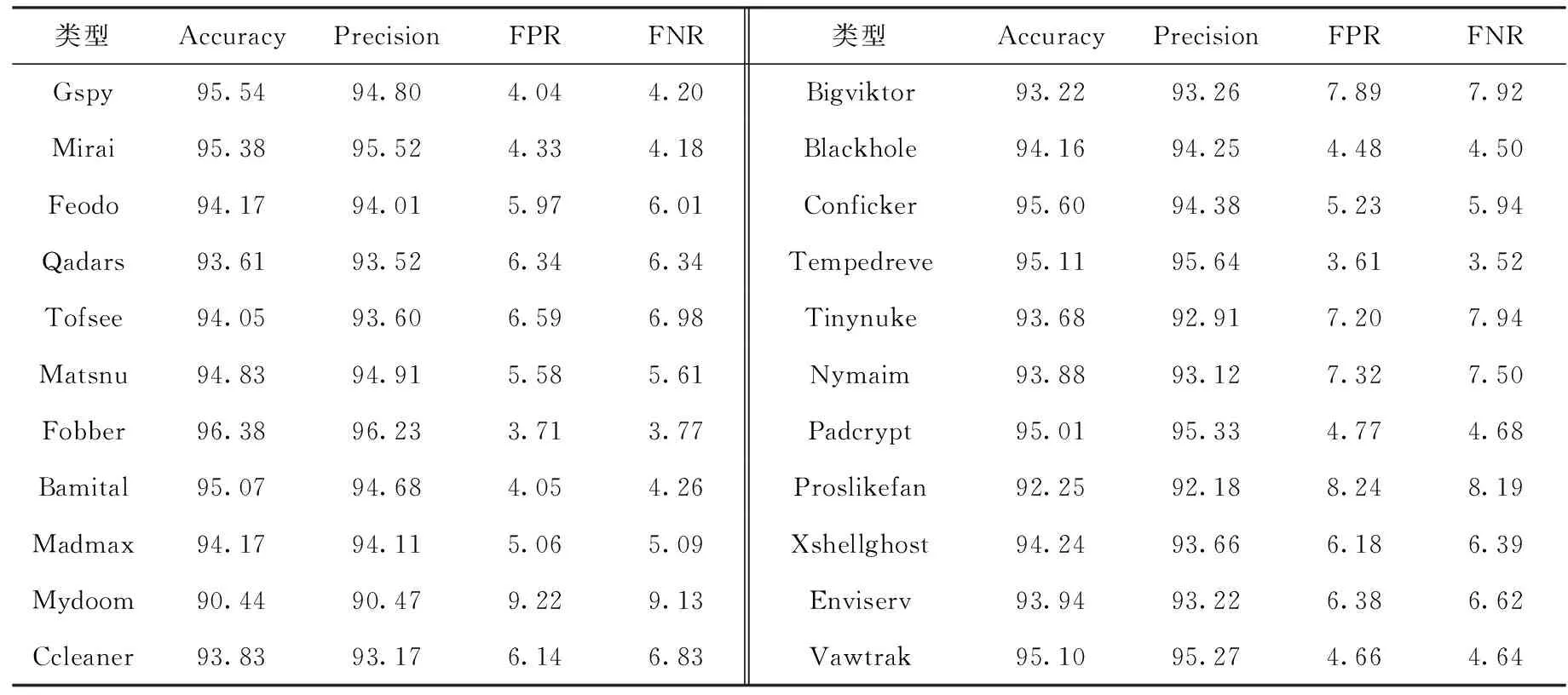
表5 小样本恶意域名检测结果/%
2.5 同类相关工作性能对比
本文对比分析了文献[6]基于卷积神经网络的恶意域名检测算法、文献[10]基于可分离卷积的恶意域名检测算法、文献[16]基于CNN-BiLSTM并行的恶意域名检测算法、文献[20]基于深度学习的恶意DGA域名检测算法。性能对比结果如图7和图8所示。
由图7可知,本文模型对22类小样本的家族恶意域名平均检测准确率均优于当前主流的域名检测模型。上述数据也进一步验证了本文模型在小样本恶意域名集上的高效性;由图8可知,本文模型在历史恶意域名和25种数据量充足的常规恶意域名数据集上的平均识别准确率均优于同类主流恶意域名检测算法。
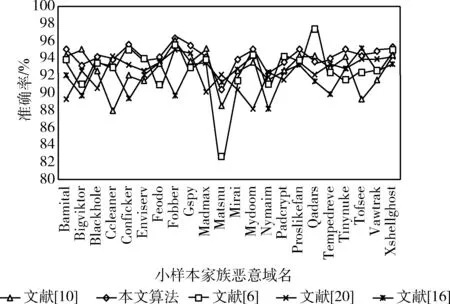
图7 5种算法对小样本的恶意域名检测准确率
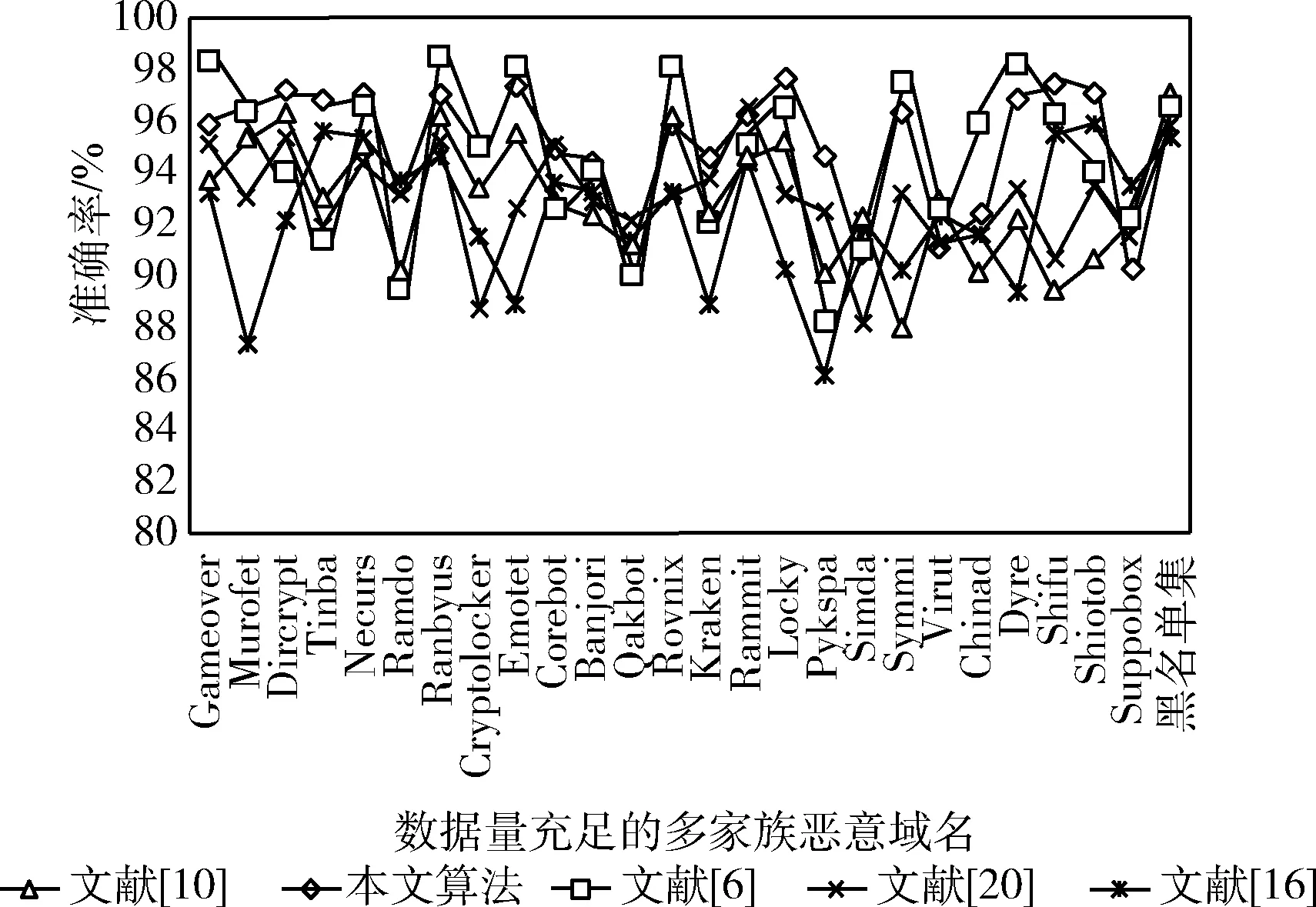
图8 5种算法对数据量充足的恶意域名集检测准确率
综上,本文模型在保持较高检测精度的基础上,可以识别出多家族多种类型的恶意域名,具有更广泛检测范围。此外,与同类相关工作对比,本文模型更适合在真实场景中应用。
3 结束语
考虑到在实际网络环境中检测恶意域名,需兼顾检测精度和恶意域名类型,本文提出了一种基于迁移学习的小样本的恶意域名检测算法。该算法利用数据量充足的黑名单集和多家族恶意域名集进行BiLSTM-CNN模型参数预训练,并迁移模型参数至小样本恶意域名检测模型,利用当前已有小样本恶意域名历史数据微调模型参数。通过在数据量充足的多家族恶意域名集和小样本恶意域名集上进行实验,结果表明了该算法在保持较高检测精度的基础上,能够识别多种类型的恶意域名。
