一体化光电融合计算发展与挑战
2022-12-26淡一航樊泽洋来一航徐兴元
张 天 淡一航 樊泽洋 陈 奇 来一航 徐兴元 徐 坤
(北京邮电大学信息光子学与光通信国家重点实验室,北京 100876)
1 引言
20 世纪90 年代的海湾战争中,大量高科技作战手段、新型信息化作战模式的出现正式拉开了现代化战争的序幕,全新的作战理念改变了世界对战争样式的理解,对现代军事发展产生了深远的影响。陆、海、空、天、网电“五维一体”全方位、跨域协同、信息共享的联合作战样式成为未来战争的重要特点,期待利用综合一体化技术,实现雷达、通信、电子战、导航、敌我识别等多种设备集中共用射频资源和数据处理资源,克服作战平台上叠加电子信息系统导致的质量/体积/功耗增加、保障维护困难等问题[1-3]。
面对一体化的联合作战需求,雷达、通信设备等往往要处理共享的海量战场信息数据,对于计算平台的计算速度和能效都提出了极大的要求;同时,一体化信号处理包含了一体化波形设计、联合发射波束成型、联合信号接收等方面,其对于矩阵乘法运算具有大量的需求[3];此外,机器学习方法也广泛应用于综合一体化技术中,比如在雷达通信一体化接收机设计中,在噪声和干扰同时存在的情况下使用机器学习方法区分雷达与通信信号[3]。其中,神经网络是机器学习的重要网络构型之一。面对一体化技术对于计算速度、能耗、矩阵乘法运算和神经网络计算加速等方面急迫的需求,传统设备往往利用中央处理器(CPU)等采用冯·诺依曼架构的计算单元进行数据处理,而这类计算单元都存在存储和计算单元空间分离的“存储墙”问题,这将导致存储单元和计算单元之间产生大量潮汐性数据荷载,从而限制计算速率,增加单次计算功耗[4]。虽然当前已有研究者提出非冯·诺依曼的计算架构来克服“存储墙”问题,如类脑计算[5],典型代表包括曼彻斯特大学的SpiNNaker 芯片[6]、IBM 的TrueNorth芯片[7]、斯坦福大学的Neurogrid 芯片[8]以及清华大学的天机芯片[9]等,然而这类电子神经拟态计算受限于集成电路的带宽、功耗、时延等,计算速度和能效比的提升仍然受到很大限制。
为了解决电子计算芯片算力和功耗的瓶颈问题,光学处理机制被引入计算领域。光子高速、大带宽、低串扰等特性非常适合海量信息的超快处理,通过构建矩阵乘法运算、卷积运算、非线性运算等基本运算单元,目前已被应用于矩阵加速、全连接神经网络、卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络、储备池计算(Reser⁃voir Computing,RC)、Ising 机等多种计算构型,在数据分类、图像分类、图像重建、优化问题等多方面崭露头角。但是由于光子具有不易存储和调控的特点,实现通用全光子计算仍然很遥远。逻辑操作、系统控制和存储等更适合用电子手段实现,在未来十年甚至更长时间,一体化系统中仍将光电混合的计算架构为主,通过引入光的固有特性,如低延迟、低损耗、超宽频带、多维复用、波动特性等,与电子计算的灵活性结合起来[10],设计软硬件深度结合的光电融合计算(Optoelectronic Computing,OEC)系统,将在综合一体化领域大放异彩,突破传统微电子处理器的局限性,实现作战平台更快的响应速度和更高的能效。
目前,光电融合计算主要包括四大类典型计算平台:片上集成相干平台、片上集成非相干平台、基于光纤系统的光电融合计算和空间光学衍射平台,同时朝着计算大规模化、非线性光学计算实现、光电高效融合三个典型方向发展。本文旨在阐述光电融合计算的研究现状,展望光电融合计算的发展趋势。
2 光电融合计算的研究现状
2.1 片上集成相干平台
光子集成回路(Photonic Integrated Circuits,PICs)具有器件尺寸小、传输损耗低、系统性能稳定、可与CMOS 兼容的特点,是实现大规模OEC 应用的理想平台之一。基于PICs 实现OEC 主要有两种技术路径,一种是基于干涉的相干技术,另一种是基于波分复用的非相干技术。目前,利用相干技术的PICs 已被用于实现计算和信号处理等多种功能,例如全光的矩阵乘法[11]、快速傅里叶变换[12]、卷积运算[13]、Multiple-Input-Multiple-Output(MIMO)[14]、滤波[15]、逻辑运算[16]等。其中,由于矩阵乘法、卷积运算在人工智能中广泛应用,所构建的光学神经网络(Optical Neural Network,ONN)是OEC 最重要的应用之一,本节重点介绍这两种计算功能的发展情况。
1994 年,Reck 等[17]提出一种三角分解算法,可利用分束器、移相器阵列实现任意N阶酉矩阵,并且可通过调整移相器进行任意的重构。2016 年,Ri⁃beiro 等[18]基于该分解算法在PICs 中利用马赫曾德尔干涉回路(Mach Zehnder Interferometer,MZI)构建的网络实现了4×4 酉矩阵的映射。同年,Clements等[19]对三角分解算法进行优化,提出了矩形分解方案,该方案具有对称的光学路径,光学深度更浅,损耗更低且鲁棒性更强。Reck 和Clements 的这两种MZI网络结构也被称作GridNet。2017年,Shen等[11]将奇异值分解原理和Reck的三角分解算法结合,研制了首款用于神经网络计算的基于光学干涉单元(Optical Interference Unit,OIU)的集成芯片,通过两层OIU芯片级联可实现单个实矩阵乘法运算。如图1(a)所示,该OIU 芯片分别具有4 个输入和输出端口,通过4层OIU和2层非线性激活级联的方式实现了一个两层的ONNs,该ONNs 可实现四种元音的分类,实验准确率达76.7%。2018 年,Bagherian 等[13]提出利用延时线对该OIU 芯片进行时分复用,分段地对图像进行卷积,从而构建了光学CNN 结构。2019 年,Fang 等[12]提出了一种误差容忍性更强的MZI 网络结构—FFTNet,如图1(b)所示。虽然FFT⁃Net不具备如GridNet完备的酉矩阵表达能力,但FF⁃TNet可以方便的实现快速傅里叶(Fast Fourier Trans⁃form,FFT)变换和卷积运算,同时FFTNet 网络深度更浅,对制造误差的鲁棒性更强。2020 年,Zhou等[14]基于GridNet 结构在PICs 中搭建了一个4×4 的线性光学网络,如图1(c)所示。通过对该网络进行优化编程,可实现多通道光开关、MIMO 解码和可调光学滤波多种功能。Saygin等[20]在同年提出一种可编程通用酉矩阵的高鲁棒架构,如图1(d)所示,通过级联多个模式混合层和移相器层,并对移相器层进行编程实现任意酉矩阵的映射。该架构避免了Grid⁃Net中分束器的完美分光比要求,在存在制造误差的缺陷下仍能高保真地表达高阶酉矩阵。Roques-Carmes等[21]利用基于GridNet的矩阵乘法网络,并结合循环采样算法实现了Ising问题的求解,为集成光子Ising 机的实现提供了一种解决方案。2021 年,Zhang等[22]利用GridNet以及MZI可进行相位检测的特点,充分利用了酉矩阵的复值表达能力,实现了任意的复值矩阵乘法运算。Zhang 等提出的复值神经网络在Iris、Circle和Spiral等非线性数据集的分类中都表现出更好的性能。同年,Tian 等[23]提出了一种新型MZI网络结构,如图1(e)所示,通过将实值矩阵信息全部加载至单个酉矩阵的实部,可将表达实值矩阵的网络结构的复杂度从UΣV†降低为U。2022 年,Zhu 等[24]提出了一种基于片上集成衍射单元的ONN,如图1(f)所示,其中星型耦合器作为衍射单元来实现多路光信号的模式混合,完成离散傅里叶变换和离散傅里叶反变换,配合移相器层调制,该衍射ONN可以实现数据分类和图像识别功能。相比于GridNet,星型耦合器的使用将系统规模从O(k2)减少至O(k),其中k代表端口数。此外,基于表面等离激元的集成光子器件也可以通过特殊设计实现多种光学计算和信号处理功能。本团队通过对表面等离子体波导系统中的可编码超材料进行逆向设计,实现了可调谐滤波、类电磁诱导透明效应[15]和全光逻辑运算[16],如图1(g)所示,相比于硅基集成平台,表面等离激元器件的尺寸可以更小,集成度更高。
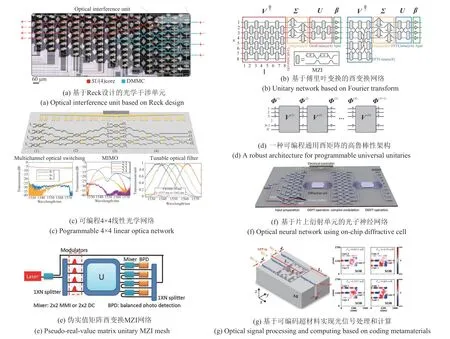
图1 7种典型光学计算和信号处理的相干片上集成方案Fig.1 Seven typical coherent on-chip integration schemes for optical computing and signal processing
2.2 片上集成非相干平台
上节所述的方案均工作在同一个工作波长,属于相干系统,信号通过改变载波的幅度来加载到系统中。除了这种幅度调制的方式外,信号还可以通过波长、模式、偏振态进行调制,即波分复用技术、模分复用技术和偏振复用技术,这些复用技术可以极大增加信号处理系统的传输容量。该类复用技术也为光学计算提供了一个新思路,目前已有很多工作将波分复用技术应用于光电融合计算中,可以进一步提升算力。
2014年,Prucnal等[25]提出了一种名为广播加权(Broadcast-and-Weight,BAW)的方法,为利用集成光子器件实现神经拟态计算(Neuromorphic Comput⁃ing,NMC)建立了一种技术途径。NMC 又叫做类脑计算或脉冲神经网络(Spiking Neural Network,SNN)计算,是借鉴脑神经网络的新一代计算架构,基本单元是模拟真实生物神经元的脉冲神经元,NMC 采用存储计算一体化的架构,将高维信息放在多层、多粒度、高可塑性的复杂网络空间中进行处理。它具有低功耗、高鲁棒性、高效并行、自适应等特点,既适用于处理复杂环境下非结构化信息,又有利于发展自主学习机制[26]。Prucnal 等[27]基于BAW 方法构建了一种神经拟态光子网络,并验证其可以实现振荡动力学的模拟和微分方程求解,其结构如图2(a)所示,神经元是具有应激性动力学的激光器,其输出是特定波长的光信号,这个信号和其他神经元的信号经过波分复用广播到整个网络,所有输入信号经过一个微环谐振腔(Microring Resonators,MRR)权重库进行加权,加权后的光信号无需进行解复用,其总功率被直接检测。除了实现NMC,MRR也是实现光学卷积运算的常用器件。2020 年,Bangari 等[28]基于MRR与BAW 方法设计了适用于卷积运算的OEC架构,通过扩展多个并行的权重库,一次可执行多个卷积运算,如图2(b)所示,该架构执行卷积运算的速度比一般GPU快2.8到14倍,功耗降低约25%,并可进行大规模扩展。同年,Mehrabian等[29]设计了一种基于Winograd 滤波算法的CNN 光子加速器架构,如图2(c)所示,相比于Bangari等提出的架构,Winograd算法可以将传统卷积乘法数从(m×r)2降低为(m+r−1)2,其中m是输出特征映射通道的大小,r是滤波器的大小,该算法提高了卷积运算效率,降低了系统复杂度,减少了总体的器件数(指核心的MRRs和调制器)。经测试,该光子加速器在速度和功耗方面能与先进的电子平台相当。
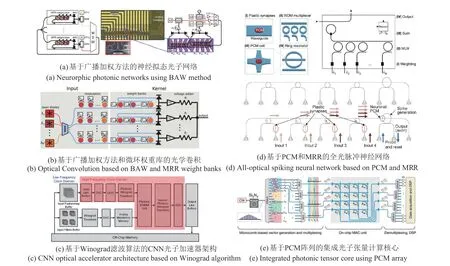
图2 5种典型的非相干NMC和卷积计算方案Fig.2 Five typical incoherent NMC and convolution schemes
相变材料(Phase-Change Materials,PCM)是另一种实现OEC 非常有前景的手段,PCM 的相变特性可以提供神经元的整合发放功能以及突触可塑的加权功能。Feldmann 等[30]基于PCM 和MRR 实现了一种全光突触的、可集成和可扩展的NMC框架。如图2(d)所示,全光突触使用内嵌PCM 的波导实现,PCM 在非晶态和晶体态对光的吸收有很大差异,通过调节PCM 的状态可对波导中传输的光进行衰减加权。突触传递的光信号经MRR 波分复用进入到由PCM 和环形腔组成的集成光神经元中,PCM 可改变环形腔的共振条件及其传播损耗来实现非线性激活。两年后,Feldmann等[31]又利用PCM阵列构建了可执行高并行度卷积运算的集成光子张量核心,得益于集成光频梳提供密集的波长通道,该张量核可每秒进行超1012次MAC(Multiply-Accumulate)操作。如图2(e)所示,片上激光器和氮化硅微腔产生频梳,经波分复用分成4组通道,每组通道对光信号调制后传入片上MAC 计算单元,4 列耦合PCM 的波导并行对光信号进行加权求和,最后解复用探测后得到4组并行卷积运算结果。
2.3 基于光纤系统的光电融合计算
由于有源器件和无源器件集成在一块芯片上的难度大,因此也有许多基于光纤和光电子器件的OEC 方案。虽然集成度不如片上集成方案,但计算能力和性能也可与先进电子计算硬件相当。
RC是一种适用于时间序列处理的计算框架[32],属于循环神经网络的一种。RC 系统将输入映射到高维状态空间并对高维状态空间中的数据进行线性组合,从而得到目标输出。储备池的输入权重和隐藏层权重都是固定的,只有输出权重需要进行训练。与其他的循环神经网络相比,RC的优势是学习速度快,训练成本低。光子RC 的实现主要有两种方案,第一种是利用大量的物理节点充当储备池中的节点;第二种是用单个非线性节点加延迟反馈环的方式实现储备池。2011 年,Vandoorne 等[33]利用半导体光放大器(Semiconductor Optical Amplifier,SOA)搭建了一个81节点的旋流拓扑结构的光储备池,对带有噪声的孤立数字识别的平均误差率为4.5%。2012 年,Paquot 等[34]利用延迟反馈原理在光电混合系统中搭建了储备池,如图3(a)所示,输入信号通过强度调制器加载到光上,储备池的非线性由电压驱动的调制器提供,通过对输出权重进行训练,系统可以实现方波与正弦波的识别。同年,Duport 等[35]也利用延迟线反馈和SOA 搭建了一个全光的储备池,如图3(b)所示,储备池所需要的非线性由SOA 提供,该方案的优势在于非线性的处理在光域进行,避免了光电转换,可以进一步提高处理速度。近些年,还出现了利用半导体吸收镜[36]、相干光驱动的无源腔[37]作为非线性器件的全光储备池。2021 年,Borghi 等[38]提出了基于硅MRR 和时间复用的储备池系统,如图3(c)所示。MRR的使用突破了延迟环路中分束器、合并器和互联损失造成的节点数量限制,非线性由自由载流子的动力学提供,MRR 中双光子吸收和载流子色散效应会造成MRR 输出端强度变化,通过对强度的变化进行采样记录,可得到储备池的内部状态,再经过后续训练实现目标任务。为了进一步提高储备池的规模和集成度,使用可集成平台实现储备池是未来的发展方向之一,2021年,Nakajima 等[39]提出了可扩展的相干光子储备池系统,该系统分为输入调制、掩码处理、储备池和数字处理4 个模块,其中非线性部分由输入调制模块和数字处理模块提供,掩码处理和储备池模块均可在硅基平台集成,输入调制芯片和储备池回路芯片尺寸分别为41×46 mm2和28×47 mm2。
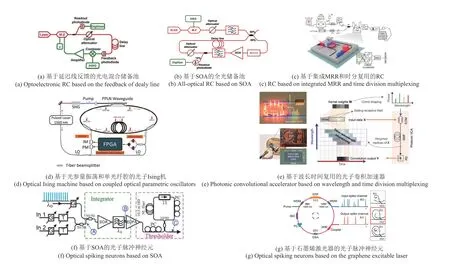
图3 基于光纤器件的光子储备池、Ising机、卷积加速器、脉冲神经元方案Fig.3 Optical reservoir computing,Ising machine,convolutional accelerator and spiking neuron based on optical fiber devices
2016 年,McMahon 等[40]基于光参量振荡和单光纤腔实现了光子Ising 机,如图3(d)所示,FPGA 对光纤腔中的脉冲信号进行测量与循环反馈实现自旋间相互作用信息的加载,通过缓慢注入泵浦光,非线性晶体在光纤谐振腔中对脉冲信号实现光参量振荡,使得满足相位匹配条件的信号得到放大,系统将一定概率收敛到Ising基态,该方案有望解决超大规模Ising 问题。2021 年,Xu 等[41]提出了基于波长时间交织的光子卷积加速器(Photonic Convolu⁃tional Accelerator,PCA),并用其构建了可进行图像识别的光学卷积神经网络。如图3(e)所示,通过MRR 的光参量振荡产生频梳,卷积核权重被编码在频梳功率上,输入向量经过电光调制器调制(加权)在所有波长通道,经过单模光纤的等间隔色散延时后,加权信号也在时域上等间隔错位,经过解复用、光电探测功率求和后,刚好得到输入信号与卷积核的卷积运算结果。该方案充分利用了波长和时间两个维度,计算算力被极大提升。
如上节所提到的,SNN 作为一种计算能力、信息处理能力更强的新网络结构也是近年的研究热点。SNN 的基本单元(脉冲神经元)不会在每次输入信号后都被激活,其激活水平取决于与其相连的神经元的脉冲到达时间、强度,故具有更强的空间信息处理能力。因此,脉冲神经元及其光子实现也是重要的研究方向之一。Rosenbluth 等[42]基于光纤实现了光学LIF(Leaky-Integrate-and-Fire,LIF)脉冲神经元,如图3(f)所示。神经元输入首先通过衰减器进行加权,然后被延时线附加延时,再通过SOA进行输入整合,最后在Ge掺杂光纤的阈值作用下进行激活。2016 年,Shastri 等[43]在基于石墨烯的环形腔中实现了光学LIF神经元的脉冲处理特性,如图3(g)所示。该LIF 神经元的脉冲处理特性来自于环形腔中可饱和吸收体(石墨烯)与增益介质(掺铒光纤)相互耦合的非线性动力学,实验证明了该光子脉冲神经元具有LIF神经元一样的应激、不应期等特性。此后,Peng 等[44]提出了基于分布式反馈激光器结构的可集成光子脉冲神经元。
2.4 空间光学衍射平台
2.1~2.2 节介绍了利用光波导及其相关器件作为传输和处理信号的OEC 方案,该种方案具有稳定性强、可集成度高等优势,但也有一些挑战。例如,受当前工艺水平的限制,非线性功能难以在芯片大规模集成,矩阵计算规模也难以进一步扩大。2.3节介绍了利用光纤系统实现OEC 的方案,虽然能够更容易的实现OEC 中的各种功能元件,比如不同函数的非线性运算,但是光子的衍射特性被波导所限制,计算速度难以进一步提升。而在自由空间中,两平面间的衍射可以看成是一种连接关系,密度极高,因此利用空间光的衍射搭建的计算系统为实现高速计算提供了另外一种可能途径。
2018年,Lin 等[45]提出“衍射深度神经网络(Dif⁃fractive Deep Neural Network,D2NN)”全光机器学习框架,如图4(a)所示,D2NN 通过使用多个衍射层构建,层上的每个点代表一个神经元,通过光学衍射连接到下层的其他神经元,每个点的局部透射或反射系数代表了神经元间的连接权重。这种D2NN 设计,一旦使用例如3D 打印、光刻等进行物理制造,就可以在无源的条件下进行光速推演,是一种高效快速地执行机器学习任务的方法。次年,Yan 等[46]对D2NN 框架进行了优化,如图4(b)所示,通过将衍射调制层放在了光学系统中的傅里叶平面上,提出了傅里叶空间衍射深度神经网络(F-D2NN),与真实空间D2NN 相比,F-D2NN 框架通过结合双2f光学系统更自然地保持了空间对应性,这有助于完成那些需要图像到图像映射的任务。2021年,Zhou等[47]提出可重构的衍射处理单元(Diffractive Processing Unit,DPU)实现大规模的神经拟态OEC,该DPU 可支持实现不同类型的神经网络,构建百万级神经元规模的复杂网络。此外,Chang 等[48]提出一种基于“4f”系统的混合光电卷积神经网络架构。其光学卷积层具有一个可优化的相位掩模,该相位掩模利用线性的、空间不变的成像系统执行固有卷积。“4f”系统结构如图4(c)所示,由两个凸透镜组成,每个凸透镜的焦距为f,完成两个傅里叶变换的级联。卷积核被编码在傅里叶平面上的相位掩膜板,在傅里叶空间与输入图像进行卷积。2019 年,Zuo 等[49]提出一种全光神经网络结构,其中线性运算由空间光调制器(Spatial Light Modulator,SLM)和“4f”透镜系统实现。如图4(d)所示,SLM1将入射光束按神经元数量进行分离并将输入信号编码在光功率上,输入光在透镜3 的后焦面上被SLM1 调制加权,然后在透镜4的傅里叶平面进行求和完成线性运算,最后再通过激光冷冻Rb原子实现非线性激活,由于使用了全光非线性,计算速度不再受光电转换速率限制。
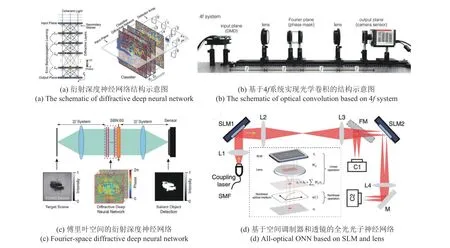
图4 基于空间衍射的光电融合计算Fig.4 Optoelectronic computing based on spatial diffraction
3 光电融合计算的发展趋势
光电融合计算(OEC)相比于传统电子计算,具有计算速度快、带宽大、功耗低、时延小等优势,在未来替代传统电子计算芯片进行海量数据实时处理具有很大的潜力。然而,受限于光电子器件的性能,集成工艺的制造水平以及光子不易存储、不易于控制、非线性难实现等特点,OEC 仍然存在着难以大规模扩展、不同非线性函数光电实现困难、融合架构效率有待进一步提升等问题。
3.1 计算大规模化
第2章中介绍了多种结合光电子技术实现OEC的方案,这些方案技术路线各不相同,但是都向可集成、可扩展方向发展。然而,由于光子集成工艺的制造水平和控制的灵活性还不及电子集成电路,单片可集成的光器件数量和精准控制仍受到极大限制,实现大规模OEC仍是一大挑战。
Lin 等[45]提出的D2NN 是一种易于扩展计算规模的方案。其利用“相位调制”板作为衍射层时,如图5(a)所示,板中每个像素块都相当于神经元,通过改变像素块的厚度可以实现对光的相位、幅度调制,使得神经元间的连接具有可调的权重,这种“相位调制”板使得D2NN 以可扩展且节能的方式高效地连接数千万到数亿个神经元和几千亿个连接。Zang等[50]提出了一种基于时域拉伸的串行ONN,其基本结构如图5(b)所示,通过拉伸时域超短脉冲,可以在光上实现大规模权重矩阵和向量的乘法,理论上该方案可以大规模扩展神经元的数量,其模拟的神经网络节点数取决于展宽光脉冲的宽度和信号发生器的最大模拟带宽。2021 年,Ashtiani 等[51]演示了一个完整的端到端光子神经网络集成芯片用于图形分类任务,如图5(c)所示,线性计算、非线性激活均被集成在同一块芯片上,其中通过驱动微环调制器获得了Relu 型非线性激活函数。经测量,整个端到端光子芯片的推演时间约为570 ps,可与最先进的数字平台的单时钟周期相媲美。
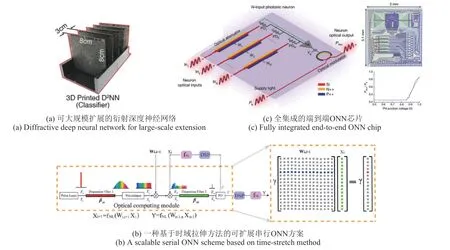
图5 可扩展大规模光电融合计算的三个方案Fig.5 Three shcemes allowing scalability to large-scale optoelectronic computing
另一方面,由于光子无法像电子一样存储和读取状态,对于ONN 和光子NMC,传统训练算法难以直接移植,如何实现OEC 高效片上训练也是未来的重要研究方向之一。Shen等提出的ONN架构中,得益于正向传播的超快速度和低功耗,可通过前向传播和有限差分法来获得每个参数的梯度[11,14],这避免了训练传统神经网络的反向传播。Hughes等[52]提出了一种ONN的片上训练算法,在如图6(a)所示的MZI构型ONN中,通过使用伴随场和原位场传播,可以计算出损失函数关于移相器介电常数的梯度。然而该算法需要在实验上测量器件中的局部场强,操作难度大。本团队提出了一种基于神经进化策略的ONN 训练算法[53],如图6(b)所示,通过将ONN 中对应于权重的物理超参数表示为待求解,利用遗传算法或粒子群优化算法的迭代优化让ONN的输出逼近预期,以达到训练的目的。因为权重所对应超参数的更新只依赖于进化策略,而不需要损失函数关于权重的梯度,因此避免了对ONN内部状态的测量,只需测量ONN的输出就可以进行参数的更新。
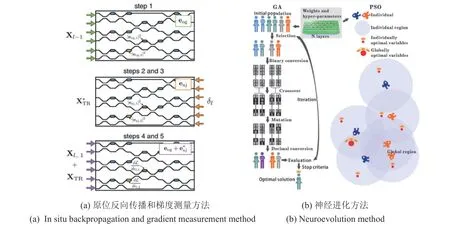
图6 梯度测量方法和神经进化方法训练光子神经网络Fig.6 Training optical neural network by gradient measurement and neuroevolution
3.2 非线性光学计算实现
为实现更高级的计算功能,非线性激活往往是必需的,而光电子器件相比电子器件实现非线性函数更加困难,并且存在很多非理想特性。因此,实现高效的光学非线性也是促进OEC发展的重要手段。目前应用于OEC中的非线性一般可分为全光非线性和光电混合非线性。全光非线性主要通过具有非线性效应的材料或器件实现,例如,Dejonckheere 等[36]利用半导体饱和吸收体镜的饱和吸收效应产生非线性激活函数,并构建了全光的储备池;Yan 等[46]在F-D2NN中使用光折变晶体的非线性构建激活函数,提升了光子衍射神经网络的分类准确率和鲁棒性;Feldmann等[30]利用PCM不同状态对光吸收效率的差异,实现了全光的非线性激活功能,如图7(a)所示,PCM 状态随输入光功率在晶态和非晶态切换,从而改变环形谐振腔的共振条件和损耗来获得具有非线性的传输谱。传输特性随输入光脉冲能量的关系如图7(a)右图所示,开关的最大对比度为9 dB;Jha等[54]提出基于自由载流子色散(Free-Carrier Dispersion,FCD)效应的全光非线性,如图7(b)所示,MRR 腔触发FCD效应,表现出对光功率的非线性相位响应,非线性相位响应通过MZI干涉结构转换为非线性的透射率变化;Zuo 等[49]利用激光冷冻Rb 原子实现了电磁诱导透明非线性激活函数,如图7(c)所示,该电磁诱导透明效应是通过将激光冷冻Rb原子置于暗线二维磁光阱中获得的;Mourgias-Alexandris 等[55]基于SOA提出了一种可实现Sigmoid激活功能的全光神经元,如图7(d)所示,该激活函数由深饱和差分偏置的半导体光放大器马赫曾德尔干涉仪和SOA交叉增益调制实现;除此之外,还有利用热原子饱和吸收[56]、二维MXene材料[57]实现的全光非线性。全光非线性的优点是几乎不损失计算速度或损失极小,但光学非线性所需的能量往往较大,能量开销高。
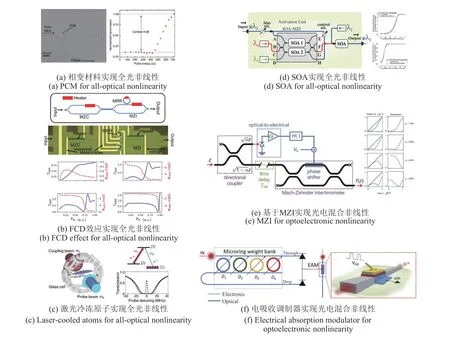
图7 光电融合计算中使用的全光非线性和光电混合非线性Fig.7 All-optical nonlinearity and optoelectronic hybrid nonlinearity in optoelectronic computing
光电混合非线性往往利用光电转换后使用电子器件实现非线性运算,Williamson 等[58]提出了一种光电混合可控的非线性运算模块,其结构如图7(e)所示。输入的光通过定向耦合器分成两路,一路通过延时线传递至MZI 的输入臂,另一路通过光电二极管转化成电信号,随后在电域上经过相应处理后与偏置电压一起控制MZI 上移相器的相位,最后输出干涉结果。通过调节移相器可对非线性函数线型进行重构;George 等[59]对基于电吸收调制器产生的非线性激活进行了建模,并对不同类型电吸收调制器构建的ONN 性能进行了对比;Amin 等[60]利用基于铟锡氧化物的电吸收调制器实现了光学神经元的非线性激活功能,如图7(f)所示,在基于BAW 方法实现的ONN 中,加权求和的光信号通过平衡光电探测后转为电信号,并被用以控制电吸收调制器,实现非线性激活。光电混合非线性优势在于手段灵活、易于控制,但光电转换的过程会损失全光计算的速度优势。为实现大规模的光电融合计算,不管是全光非线性还是光电混合非线性,未来都应向着易于集成、低功耗、可重构的方向发展。
3.3 光电高效融合
由于光子具有易于计算但不易调控的特点,光子计算主要是完成通用矩阵乘法运算(General Ma⁃trix Multiplication,GeMM)、卷积运算等特定运算,但是逻辑控制、中间数据值存储及前端数据的预处理等一般采用电子计算完成。如何充分结合两者优势,克服光电融合机制匮乏、接口带宽低和功耗高、系统集成度低、光电延时难以匹配等问题,联合光域与电域共同处理信号,实现系统级的高效光电融合计算,也是未来的一个研究重点。
2019 年,Liu 等[61]提出了深度学习纳米光子加速器“HolyLight”,通过采用一种高效卷积算法,减少了一般计算所需开销。在此基础上设计了两种加速器架构“HolyLight-M”和“HolyLight-A”,前者将中间计算值在ADC(Analog-to-Digital Converter)转换时进行量化操作,在保证精度没有太大损失的前提下,降低了计算开销;后者在前者基础上,用微碟搭建的光子累加器和移位器取代了ADC 模块,更进一步地提高了数据吞吐量,加快了模型推理效率。
2021 年,Demirkiran 等[62]提出了一种高效率的光电混合计算系统架构。其结构如图8(a)所示,其中光子核心执行线性GeMM 运算,专用集成电路执行非GeMM 操作。主机CPU 和存储器DRAM 通过PCI-e 总线与光电加速器(ADEPT)相连,主要负责数据的调度,单独的SRAM负责存储网络的权值、输入和输出值。SRAM 的数据通过DAC(Digital-to-Analog Converter)进行编码,然后输入到MZI阵列所搭建的光核中运算,计算完成后,通过ADC 转换到数字域并写回SRAM。同时,采用流水线操作,利用权值缓冲区作为暂存区,在执行当前GeMM 操作时,将下一次运算所需数据从SRAM 预加载到权值缓冲区中,从而可以将权值快速编程到ADEPT 中,而不会产生大的数据传输延迟。
同年,Sunny 等[63]提出了基于跨层优化的硅光子神经网络加速器“CrossLight”,在保持高分辨率精度的同时,显著提升了整体能效。“CrossLight”一方面改进了传统微环调制器设计,使工艺制造引入的额外谐振漂移量减小,进而降低了后期所需补偿的功耗,并利用热特征分解算法减少了热光调谐器数量。在光计算部分,如图8(b)所示,按照网络结构分为全连接区域和卷积区域两个部分,分别执行矩阵乘法和卷积运算,一定程度避免了两种结构因尺寸、运算方式差别较大造成整体时延增加、吞吐量降低的问题。在16位分辨率下,与当时最先进的光子深度学习加速器相比,“CrossLight”平均每比特能耗降低了9.5倍,每瓦性能提高了15.9倍。
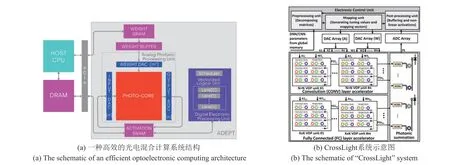
图8 两种高效光电融合计算架构Fig.8 Two efficient optoelectronic computing architectures
近年来,光电计算的高效融合主要针对上述所提到的架构、数据流调度等方面进行优化,在系统性能提升方面取得了一定进展,为后续研究提供指导方向。另一方面,以相变材料等为代表的新型材料,有望研发出稳定可靠的光存储器以取代电存储器件,进一步提高光电融合计算的效率。
4 总结与展望
光电融合计算旨在采用光子低延迟、低损耗、超宽频带、多维复用、波动性等特性实现部分计算的加速外,包括矩阵乘法运算、卷积运算、非线性运算等基本运算,再利用电子手段灵活、易于调控的优势,克服光子不易控制、不易存储、非线性实现难的问题,目前已对全连接神经网络、卷积神经网络、储备池计算、Ising 机等多种计算构型都能起到高效的加速效果。在信号处理、图像处理、语音识别、文本识别等众多人工智能领域都崭露头角。同时,光电融合计算也仍然存在不足之处,比如,计算规模不大、不同非线性函数难以高效构建、光电融合效率有望进一步大幅提高等问题。未来有望突破光电协同、软硬结合的计算新范式,从运算硬件、控制模块、存储单元、架构、指令集、流水线、软件编译、用户使用等几个维度循序渐进的开发出一套可重构、用户友好的计算加速系统,用于解决目前综合一体化技术中对于海量数据高速处理的急迫需求,为未来战争实现陆、海、空、天、网电“五维一体”全方位、跨域协同、信息共享的联合作战提供重要的支撑。
