行车障碍识别算法的精度提升方法
2022-12-25余颖舜李成瑶潘长开
余颖舜,李成瑶,潘长开
(佛山职业技术学院,广东 佛山 528137)
0 前言
YOLOv4(以下简称“YOLO”)算法是目前自动驾驶中使用最广泛的目标检测算法[1],其在晴朗白天光线充足的环境下进行车辆目标识别任务时能达到96%的准确率,而且每秒能处理100帧以上的图片,可以实时处理视频流。尽管如此,96%的白天准确率依然是不够的,为了进一步提升YOLO算法的目标识别准确率,对其展开研究是当前自动驾驶行业较为迫切的问题。
1 提升YOLO算法识别准确率的措施
YOLO算法将图片划分为若干个区域,然后对每个区域进行目标检测。默认是把1帧图片压缩为448×448分辨率的图片,然后再平均划分为7×7个区域。与Faster-RCNN算法[2]相比,YOLO算法为了提高处理速度,并没有使用滑移窗口与区域提议的方式,所以容易导致某些目标对象被分割在多个不同的区域中,导致不管YOLO算法对哪个区域进行识别,都只能看到目标对象的局部,引起识别准确率的下降。为此,可以通过区域交错、元学习、知识蒸馏、参数微调提升YOLO算法的识别准确率。
1.1 区域交错
针对YOLO算法识别准确率偏低的问题,可以通过增加所划分区域的数量,同时重叠一部分相邻的区域来提高YOLO算法的目标识别准确率。假设YOLO算法把图片划分为3×3个区域,如图1实线所示,图片中会出现4个交点。假如有1个目标对象的中心恰好就在交点附近,则这个目标对象会被分割在与该交点相邻的4个不同的区域中。对于YOLO算法来说,这个目标对象是难以识别的。所以提出一种新方法:以每个交点为中心,再增加1个区域让YOLO算法进行识别,新增加的区域大小与原来划分的区域大小一致,如图1虚线所示。

图1 区域交错示例
随着YOLO算法需要识别的区域增加,其识别准确率会有所提高,但计算量也会越来越大。因此,只在识别过程最容易失效的区域边角处增加新的识别区域,以减少新增区域的数量,限制新增的运算量。
新增加的区域会增加运算量,但是该方案的串行运算量未增加,所增加的是并行的运算量。因此,可以使用多进程等并行运算技术来运行,这样就可以在不降低YOLO算法速度的情况下提升YOLO算法的目标识别准确率。
1.2 元学习
虽然YOLO算法有不错的准确率与速度,但是其泛化性较差。泛化性差的原因与训练数据分布不均衡及小样本有高度关联。训练数据分布不均衡导致YOLO算法很难学习到在训练集中出现概率较低的路况。
针对这个问题,使用元学习来确定YOLO算法的初始化参数。元学习并不会训练出强大的YOLO算法,但可以训练出有潜力的YOLO算法。然后再使用训练集对YOLO算法进一步训练,就可以获得泛化能力更加强大的YOLO算法。选用元学习理论中的Reptile算法[3]对YOLO算法进行元学习,基本过程如下:
(1) 人工分类训练数据,根据白天、黑夜,以及天气状况,将数据集划分为12个不同的任务训练集。
(2) 复制YOLO算法,取名YOLO1。随机抽取1个任务训练集,取名“任务i”。使用“任务i”对YOLO1进行训练,使用Adam优化器,直到YOLO1收敛。
(3) 对YOLO的参数进行更新,即
θ←f(θ,λ(θ1-θ))
(1)
式中:θ为YOLO的参数;θ1为YOLO1训练收敛后的参数;λ为超参数,取0.001;λ(θ1-θ)为优化器输入中的梯度;f(θ)为优化算法函数,可以是梯度下降、动量、AdaGrad、RMSprop等。
(4) 重复步骤(2)与步骤(3),直到YOLO收敛。
1.3 知识蒸馏
YOLO在进行元学习后,使用知识蒸馏技术[4]对其进一步训练。
使用目标检测准确率最高的Faster-RCNN模型作为教师模型,YOLO作为学生模型进行训练。
对于YOLO中的分类任务,教师模型提供的标签是soft-max标签,能提供各个不同类别之间具有关联性的信息;而如果直接使用训练数据进行训练,YOLO得到的标签是one-hot标签,所能够学习的信息相对较少。
1.4 YOLO算法参数微调
即使经历了知识蒸馏的训练,YOLO算法模型在实际应用中依然会对少部分目标对象存在分类错误的情况。为了改善这个问题,需要对YOLO算法的参数进行微调。
YOLO算法参数微调的训练集由两部分组成:
(1) YOLO做分类任务时,分类结果与one-hot标签相差较大的样本会被放进微调训练集。这种方式类似于强化学习中的优先级回放技术[5]。
(2) 使用对抗训练中的FGSM算法[6]生成对抗样本,把对抗样本放进微调训练集中。
考虑到深度学习模型通常存在“灾难性遗忘”现象,参数微调阶段的训练可能会导致YOLO算法丢失知识蒸馏阶段的训练成果。因此,在微调阶段,使用增量学习中的EWC算法对YOLO算法的参数进行微调训练。
EWC算法使用的损失函数为:
(2)
(3)
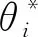
2 提升YOLO算法速度的措施
尽管YOLO算法已经能够处理实时的视频流数据,但是对于自动驾驶领域来说依然不够快。很重要的原因是由于在YOLO算法给自动驾驶系统信号后,自动驾驶系统不能马上进行响应。从自动驾驶系统接收到YOLO算法信号到汽车的机械部件实施响应,大概有0.5 s延迟。为了进一步减少延迟,采用了一种能让YOLO算法具备预判能力的方式进行训练,并对YOLO算法模型的部分参数进行了量子化处理。
2.1 预判式训练
在YOLO算法的训练阶段(元学习阶段、知识蒸馏训练阶段、参数微调阶段),YOLO(在元学习阶段是YOLO1)的输入是一帧图片,但是其对应的标签并非该帧图片的标签,而是视频流数据中0.5 s后的另一帧图片的标签。所以YOLO算法并不是对当前帧的图片做目标检测,而是根据当前帧的图片,预测0.5 s后行车障碍物最有可能出现的位置。
使用这种方式训练出来的YOLO算法具备对路况的预判能力。尽管其运算速度并没有真正得到提升,但是其表现出来的效果与速度提升一致。
2.2 参数量子化处理
在YOLO算法参数微调阶段,EWC算法会计算出YOLO算法每个参数的重要程度。假如YOLO算法中的某个张量中的大部分参数被EWC算法评价为非重要参数,则更换其数据类型,让张量的数据类型从占用字节较多的双精度浮点型数据转换为短整形数据。该方式能有效减少YOLO算法占用的内存,并且可以提高其工作时的运算速度。
3 实验结果
使用训练出来的YOLO算法能在训练集中获得95.2%的识别准确度,在测试集中能获得93.8%的识别准确度。
通过对YOLO算法识别错误的图片进行分析,其识别失败主要分为以下3种情况:
(1) 人群识别。图片中有多个行人,并且相互重叠时,YOLO算法对行人的识别效果较差,通常只能识别人群中的一部分,无法识别全部行人。值得庆幸的是,对于自动驾驶系统来说,这种情况下出现的漏检往往不会对自动驾驶系统构成太大的负面影响。只要YOLO算法能检测到前方有行人,自动驾驶的车辆就会制动,行人依然是安全的。
(2) 远距离目标识别。当目标在远处时,YOLO算法容易出现漏检的情况。即使没有漏检,YOLO算法对于远处的目标对象容易出现识别错误的问题。这种情况的错误不会对自动驾驶的行车安全构成直接影响,但可能会导致自动驾驶系统无法识别远处的交通灯或交通标志而导致车辆行驶时违反交通规则。
(3) 目标对象不在线框中。矩形线框的位置与目标对象的位置差距较大,例如线框的位置在电动自行车的前方,电动自行车大部分都不在边框里面。从某个角度来看,这种情况不算是YOLO算法识别失败,反而是YOLO算法的成功预判。因为YOLO在训练时使用的数据标签本来就不是图片的标签,而是0.5 s后的另一帧图片的标签。
4 结语
本文使用了元学习、知识蒸馏等方式对YOLO算法进行训练,使YOLO算法获得更好的泛化能力并获得一定的预判能力。尽管如此,YOLO算法的表现与工程需求依然存在一定距离,需要进一步提升以保障自动驾驶系统的可靠性。
