辅助驾驶的车辆与行人检测模型YOLO-DNF
2022-12-22张修懿陈长兴成宽洪
张修懿,陈长兴,杜 娟,李 佳,成宽洪
1.空军工程大学 基础部,西安 710051
2.西安理工大学 计算机科学与工程学院,西安 710048
目标检测的任务是找出图像中所有感兴趣的目标并确定它们的位置与类别,其作为无人驾驶技术环境感知模块的关键部分,可在车辆行驶过程中准确并快速地检测周围车辆与行人,用于辅助车辆规划路径、保障交通安全。该技术目前已成为计算机视觉领域的研究热点,并在工业生产[1]、医学影像[2]以及安防监控[3]等领域得到了广泛的应用。
在目标检测技术研究的早期常需要手工限定待检目标的低级视觉特征如方向梯度直方图[4](histogram of gradient,HoG)或加速稳健特征[5](speeded up robust features,SURF)等,在图像中通过滑动窗口分区域计算上述特征后使用支持向量机[6](support vector machine,SVM),或可变形部件模型[7](deformable part-based mod‐el,DPM)等技术进行分类。这些传统算法的检测精度很大程度上取决于手工限定的特征是否贴切待检目标及是否受到背景变化的干扰,因此以上算法适合于目标形似、背景固定的目标检测场景。但车辆行驶中道路环境复杂,车辆与行人多样,因此这类算法不适合用于车辆行驶环境。
卷积神经网络(convolutional neural network,CNN)通过大量数据集训练后,其仿生的多层神经元可以从原始图像像素中学习待检目标的深层特征,这些深层特征在复杂环境中有更强的区分表达能力。利用这一优势,CNN在目标检测领域取得了显著的进展。
目前基于CNN的算法主要分为两大类,两阶段检测与一阶段检测。R-CNN[8],作为两阶段检测的开创之作,在第一阶段使用选择性搜索算法提出一系列可能包含目标的感兴趣区域(region of interest,RoI),在第二阶段中利用CNN提取区域内的深层特征并据此进行分类和定位。针对每一个区域提案分别提取特征并检测使R-CNN[8]具有较高的检测精度,但复杂的提议算法和冗余的区域提案使得检测器效率较低。Fast-RCNN[9]将卷积层位置提前,在每个位置上计算出一组特征向量,通过图像与特征的位置映射关系使第二阶段为每一个感兴趣区域提取特征转为计算其对应位置上的特征向量,降低了第二阶段的计算量和计算时间。Faster-RCNN[10]提出区域提案网络(region proposal network,RPN)以替代选择性搜索算法,使一部分卷积层直接生成区域提案和区域内检测特征,简化了第一阶段的计算流程。Fast-RCNN与Faster-RCNN[9]在R-CNN[8]的基础上分别缩短了第一、第二阶段的计算时间,但针对大量冗余的区域提案进行计算不可避免地拉低了检测效率,为此不适用于车辆驾驶这种对实时性要求较高的检测场景。
作为一阶段检测算法的代表作,YOLOv3[11]算法首先在图像上平均划分出分辨率不同的网格并在其顶点放置大小、形状不同的锚框,由于这些锚框与CNN提取的特征存在位置映射关系,所以对特征进行预测和回归就可以得到锚框中的目标类别以及位置。YOLOv3[11]算法以固定数量的锚框代替二阶段算法中无定量且大量冗余的区域提案,大幅提升了检测效率,满足了车辆驾驶场景下检测的实时性需求。但由于只在固定位置提取一定数量的特征会造成图像中信息的遗漏,其检测精度略低。
为了提高检测精度,研究人员基于YOLOv3[11]进一步改进、搭建目标检测模型,例如YOLOv4模型[12]中使用更优秀的CSPDarknet网络来提升特征提取能力,Scaled-YOLOv4模型[13]通过缩放技术搭建更深的Scaled-CSP网络也取得了检测精度的提升。虽然YOLOv4[12]与Scaled-YOLOv4[13]模型都取得了精度的提升,但CNN的复杂化随之带来检测速度变慢和检测泛化性退化等新问题。更深和更复杂的网络一方面需要的计算量与参数量更大,造成计算时间增加,检测速度变慢,因此需要使用更经济的计算结构。而在另一方面,网络无根据的加深会引起泛化性的退化[14-15],使检测难以适用于复杂多变的道路场景,为此需要对数据集进行拓展。
本文针对以上问题,进行了模型结构和数据拓展方面的研究,具体如下:
(1)针对复杂网络计算量较大造成检测速度慢的问题提出了Arrow-Block结构,与CSP-Block共同组建模型主干网络,并通过分析结构学习能力和计算成本调整合适的网络深度。
(2)针对模型泛化性不足难以拟合复杂的道路环境的问题使用HSV扰动和亮度增强的数据拓展方法提升模型泛化性能。
1 相关工作
1.1 YOLOv3检测算法
车辆行驶过程中速度快,对目标检测的实时性要求较高。由于一阶段检测算法YOLO系列根据卷积运算的位置不变特性只使用一次网络计算就能完成对整张图像进行检测,相较二阶段检测算法具有速度快、计算量小的优点,鉴于此本文基于YOLOv3[11]检测算法进行研究。YOLOv3[11]是该系列的代表作,其结构被分为主干网络(BackBone)、特征融合层(Neck)和检测头(Head)三个部分。分别起到提取特征、融合特征和将特征转为输出信息的作用,算法结构如图1所示。
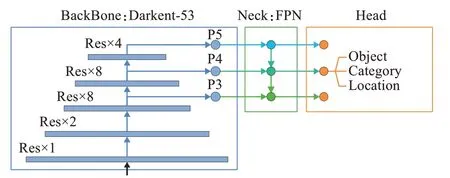
图1 YOLOv3算法结构图Fig.1 Schematic diagram of YOLOv3 algorithm structure
YOLOv3[11]的主干网络使用了Darknet-53网络。Darknet-53网络利用五组Res-Block从网络中递进提取五组深度不同的特征P1~P5。Res-Block是Darknet-53[11]网络中提取图像特征的关键,每一组都由不同的数量的Res-Layer重复堆叠而成,依次为1-2-8-8-4。
YOLOv3[11]的特征融合层使用了特征金字塔(feature pyramid network,FPN)结构,FPN融合了Darknet-53网络提取出的后3组特征进行,其中特征P5经过卷积组降维、上采样后与特征P4拼接Concat融合成新的特征,重复向上便能够将特征P4、P5融入特征P3。
YOLOv3[11]的检测头部分通过三个卷积层将网络提取到的特征通过卷积输出为前后景分类、目标类别分类和位置回归数据。
鉴于YOLOv3[11]性能优良和结构清晰,本文以其为基础框架进行优化。提出低计算成本、高特征提取能力的ACNet作为模型的主干网络,具体细节及设计思路于2.1节展开。
1.2 数据集与数据增强
CNN的学习建立在数据之上,数据分布影响着网络的学习方向和最终的学习成果,因此需要根据应用场景选择合适的数据集。训练和测试车辆与行人检测模型常采用KITTI[16]和SODA10M数据集[17],其图像均在车辆上以固定的视角进行采集,因此相较于其他公开数据集更加贴切实际的驾驶场景。KITTI数据集[16]类别涵盖汽车、货车、行人,图像拍摄于白天的德国卡尔斯鲁厄市市区,数据多样性较低,对于车辆驾驶的实际检测需求而言研究价值不强。SODA10M数据集[17]类别涵盖行人、自行车、汽车、卡车、公交车、三轮车,训练集图像仅拍摄于白天的上海市市区,而测试集覆盖了夜间的其他城市,道路环境包括乡村和高速公路。具体分布如表1所示。
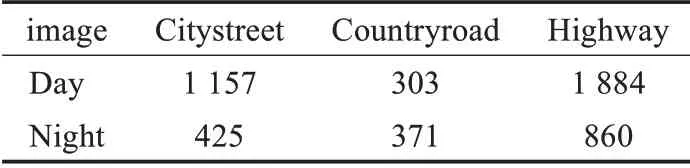
表1 测试集图像分布Table 1 Testset image distribution
虽然模型使用SODA10M数据集[17]训练会难以拟合测试集多样的图像分布,但也正因为训练集的数据多样性小于测试集而更贴切实际工程中有限的数据集无法包含无限的实际驾驶场景。鉴于此本文选用SODA10M数据集[17]进行模型训练与测试。
车辆行驶的道路复杂多样,虽然车辆和行人在不同道路上的样本视觉差距较小,但在夜晚和白天不同光照下差距较大。仅使用训练集进行训练网络会在夜晚检测精度较低,难以满足夜间车辆驾驶的检测需要。数据增强是训练CNN的常用策略,可以帮助扩展数据的多样性,增强网络的泛化性并避免网络学习至局部损失最小值[18]。HSV域扰动[19]通过在训练中以50%的概率随机改变图像的色相、饱和度、对比度以及亮度拓展训练集图像的色彩分布,使得对图像颜色、亮度变化具有一定的泛化性,扰动效果如图2所示。

图2 HSV扰动效果对比图Fig.2 Comparison of HSV disturbance effect
通过HSV域随机扰动,每张图像的色彩和亮度都产生多种变化。虽然数据集的色彩与光照分布得到了扩充,但扰动后的图像仍与夜晚差距较大,为此本文分析了白天与夜晚图像亮度的差距,通过在训练中降低图像亮度来弥补与实际检测的差距,具体细节于2.1节展开。
2 模型结构与数据增强
2.1 YOLO-DNF模型结构
YOLO-DNF模型遵循YOLOv3[11]的基础框架,整体网络仍分为主干网络、特征融合层和检测头三部分,其中主干网络使用低计算成本、强特征提取能力的ACNet,特征融合层和检测头保持原结构,整体结构如图3所示。
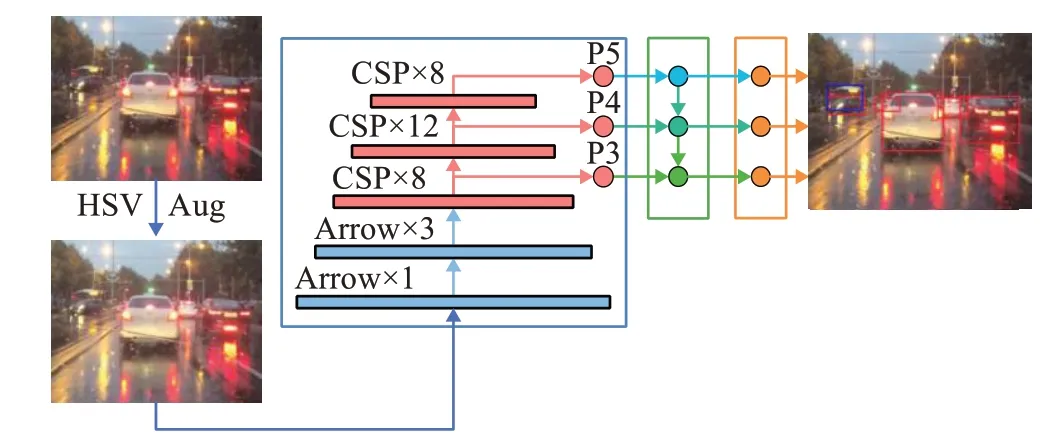
图3 YOLO-DNF算法结构图Fig.3 Schematic diagram of YOLO-DNF algorithm structure
在神经网络中,神经元的连接方式与数量对于其特征学习和提取能力至关重要,而神经元的连接方式与数量反映到目标检测模型中正是主干网络中卷积模块结构以及网络深度。本文通过分析主流目标检测模型中主干网络的结构以及深度提出的具有低成本高特征提取能力的ACNet,其具体结构如表2。
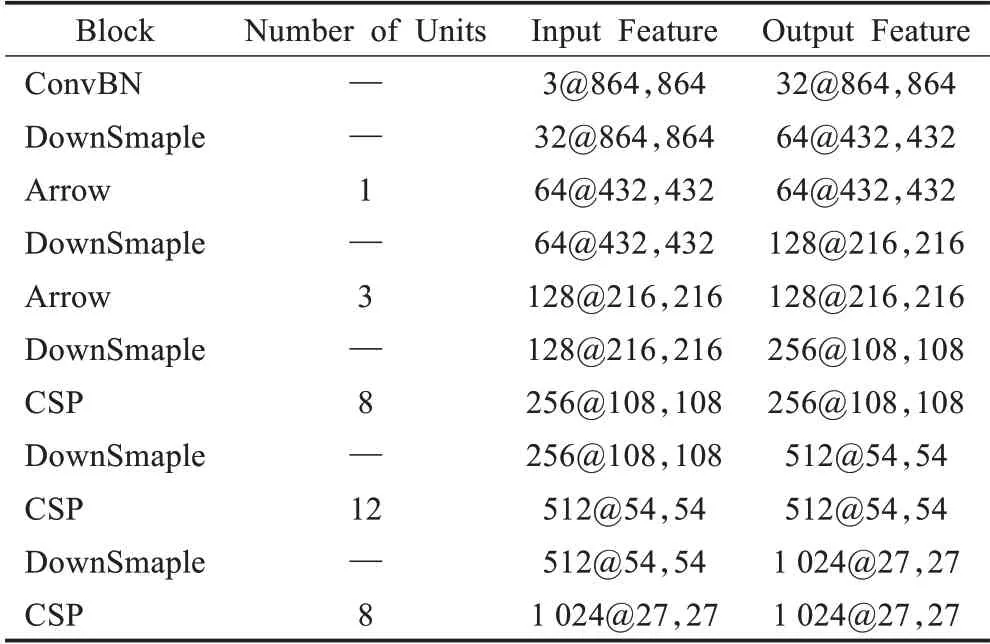
表2 ACNet网络结构Table 2 ACNet network structure
2.1.1 卷积结构
适用于目标检测的卷积结构需要考虑特征提取能力与计算成本的问题,本文通过分析该领域中常用的卷积模块Res-Block以及CSP-Block选择ACNet中的卷积结构。
卷积模块Res-Block因独特的Shortcut传导方式和卷积维度变化而具有相较普通卷积层更强的特征提取能力。整体模块由数个基础单元Res-Layer堆叠连接而成,随着堆叠单元Res-Layer数量的增加,Res-Block中特征维度变化愈加频繁,这需要占据更大的内存访问成本并花费更多的计算时间。
卷积模块CSP-Block由Arrow-Block以及四个卷积核尺寸为1×1的卷积层组成。在模块起始处通过两个降维卷积将特征划分成两路,两路特征的维度皆被降至原始特征的一半。其中一路特征在经过Arrow-Block及卷积计算后与另一路特征作通道拼接,拼接得到的特征经归一化及非线性激活后作最后一次卷积计算完成融合,卷积融合后的特征作为CSP-Block整体模块的计算结果输出。CSP-Block通过特征划分避免了不断学习重复的信息,并通过特征融合使得浅层的神经元在反向传播中直接获得深层的反馈从而接受更大梯度,因此相较Res-Block具有更强的提取能力,且特征维度变换频率固定。
Arrow-Block作为卷积模块CSP-Block的一部分,并未在主流的目标检测模型中单独使用过,其结构与Res-Block相似,同样使用Shortcut连接并由数个基础单元Arrow-Layer堆叠连接而成,区别仅在于其计算过程中特征维度保持不变,避免数据读取时维度频繁变换,因此可以降低内存访问成本。
Res-Block、Arrow-Block中基础单元以及CSP-Block的具体结构如图4所示。
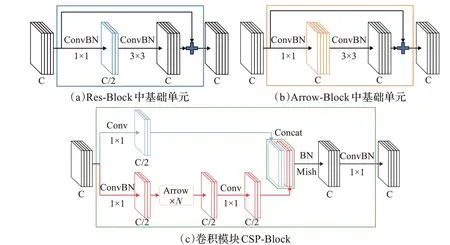
图4 不同模块卷积结构示意图Fig.4 Schematic diagram of convolutional structure in different modules
搭建目标检测模型的主干网络时常通过在卷积模块中使用一定数量的堆叠单元来控制网络深度,此时卷积模块的特征提取能力与计算成本同时受到模块结构与堆叠单元数量的影响。作为计算密集型算法,卷积神经网络的计算成本包括数据运算与内存访问两方面,其中卷积层的数据运算成本可用浮点数运算次数(floatingpoint operations,FLOPs)表示,内存访问成本可用内存访问次数(memory access cost,MAC)表示,忽略卷积层中的归一化与非线性激活,卷积层的FLOPs与MAC的计算如式(1)与式(2)所示:

式(1)与式(2)中h和w代表特征图的高和宽,C代表特征图的维度,K代表卷积核大小,角标in和out表明该参数属于输入或输出特征图,鉴于网络中卷积层的输入特征通道数Cin皆大于等于32且为2的高次幂,因此可忽略式(1)中的常数因子1。
卷积模块Res-Block结构单一,其计算成本为单个基础单元Res-Layer的计算成本乘以其堆叠单元数量N,结合卷积模块中卷积层的参数可依据式(1)与(2)得到卷积模块Res-Block的计算成本式(3)与式(4):
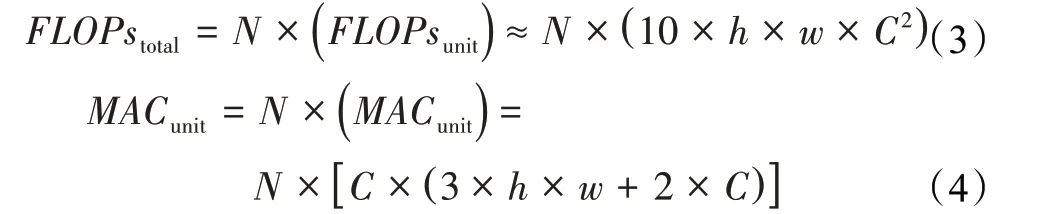
与之不同的是卷积模块CSP-Block中除了使用了模块Arrow-Block,还额外使用4个卷积层以划分与融合特征,因此卷积模块CSP-Block的计算成本可分为堆叠单元unit部分以及划分与融合extra部分。结合卷积模块中卷积层的参数可依据式(1)与式(2)得到卷积模块CSP-Block的计算成本式(5)与式(6):
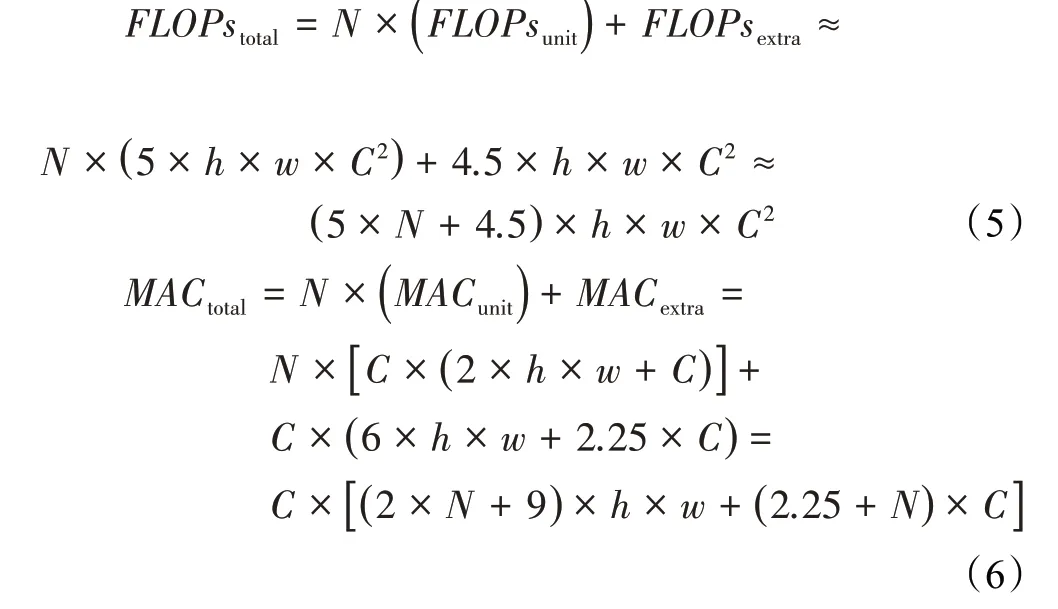
依据式(3)~(6)可以得出在堆叠同样数量基本单元的情况下卷积模块CSP-Block与Res-Block针对不同维度、分辨率的特征图进行卷积计算所消耗的计算成本。为了数据对比清晰易察,本文选取维度与分辨率的中位数组合(256,108)计算卷积模块CSP-Block与Res-Block的计算成本对比结果得到图5。
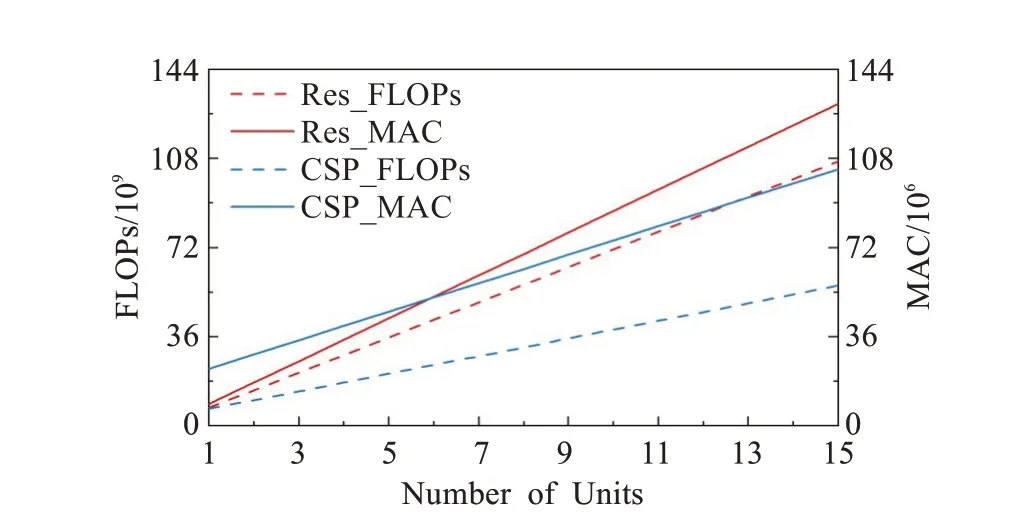
图5 卷积模块计算成本对比图Fig.5 Comparison of calculation cost for convolutional block
如图5所示,卷积模块CSP-Block的计算成本低于Res-Block,且当堆叠单元增多时差距更为明显。这是因为卷积模块CSP-Block在起始处将特征维度降低一半且在堆叠单元部分计算时特征维度保持不变,因此堆叠同样数量基本单元时卷积模块CSP-Block中unit部分的计算成本小于Res-Block。随着堆叠单元的增加,extra部分的计算成本在整个卷积模块中占比越来越小,使得整体计算成本的差距增大。又因为划分与融合机制,卷积模块CSP-Block相较Res-Block具有更强的特征提取能力,因此CSP-Block模块能够以较低的计算成本在堆叠单元较多的区域发挥较强的特征提取能力。
但当堆叠单元较少时,extra部分的计算成本在整体模块中占比较大,依据式(5)与式(6)可得到随着堆叠单元增加extra部分所耗计算成本在卷积模块CSP-Block中占比变化趋势图6,其中特征维度与分辨率仍选择中位数组合(256,108)。
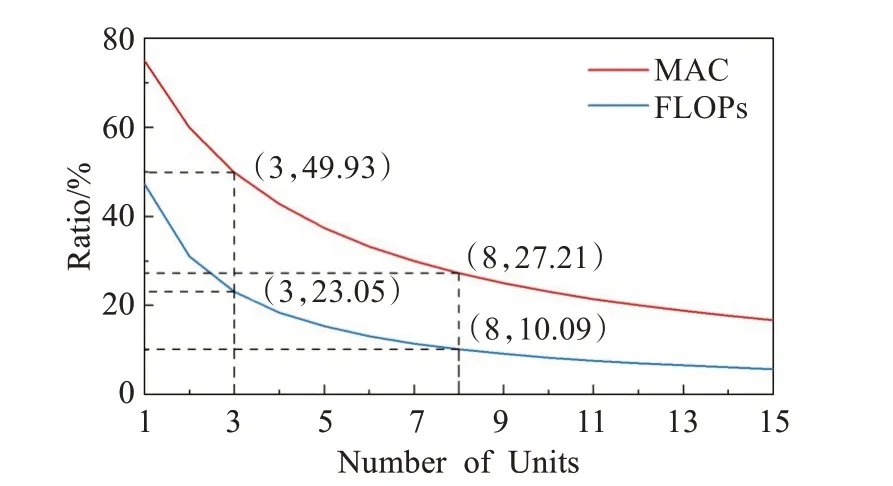
图6 CSP-Block模块中extra部分计算成本占比与单元数关系Fig.6 Relationship between ratio of extra component in total calculation cost of CSP-Block and amount of units
如图6所示,当堆叠单元数为1~3时extra部分数据运算成本FLOPs占据整体卷积模块CSP-Block的47.33%~23.05%,内存访问成本MAC更是达到整体卷积模块的74.94%~49.93%。这意味着当堆叠单元较少时特征与融合机制会消耗卷积模块中绝大部分的计算成本。但此时各层神经元相距较近,学习的内容类似,且梯度传递衰减效应较弱,划分和融合机制对于CSPBlock模块的特征提取能力增益较小。即当堆叠单元较少时,CSP-Block模块相较Arrow-Block模块在消耗更多的计算成本的条件下特征提取能力的提升极为有限。因此在堆叠单元较少的区域Arrow-Block模块能够以牺牲较少特征提取能力为代价大幅减少计算成本。
基于上述考虑,本文提出的ACNet将于堆叠单元数较少处使用Arrow-Block模块,于较多处使用CSP-Block模块,Arrow-Block搭配CSP-Block的组合使得网络保持了较强的特征提取能力和较低的计算成本,此外由于Arrow-Block也是CSP-Block模块的一部分,因此ACNet网络的硬件实现方式也较为简单。
2.1.2 网络深度
确定ACNet网络的深度,即确定Arrow-Block模块与CSP-Block模块中堆叠单元的数量。当卷积结构相同但深度不同时,主干网络的特征提取能力以及计算成本都会改变。例如同样使用CSP-Block模块的CSP‐Darknet网络[12]与Scaled-CSP网络[13],其各自的堆叠单元数量如表3所示。
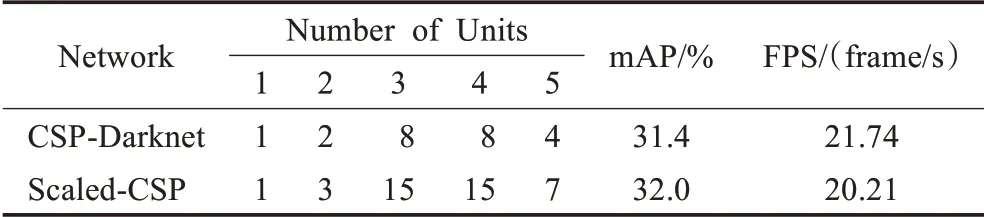
表3 CSP-Darknet与Scaled-CSP网络深度对比Table 3 Comparison between CSP-Darknet and Scaled-CSP in network depths
通过对比两种网络堆叠单元数量可发现:(1)两种网络的堆叠单元在P1、P2层都较少,而在P3~P5层较多。(2)两种网络的堆叠单元在P1、P2层差距较小,而在P3~P5层较大。(3)网络更深的Scaled-CSP[13]精度高于CSP-Darknet[12],但检测速度低于CSP-Darknet[12]。因此ACNet网络将在P1、P2层以1~3的堆叠单元数量使用Arrow-Block模块,而在P3~P5层使用CSP-Block模块,其中P3~P5层CSP-Block模块内堆叠单元数量通过分析其在不同层的计算成本来决定。
CSP-Block模块中堆叠单元的计算成本已由式(5)与式(6)中FLOPsunit给出。由于P3~P5层的特征维度从256至1 024以二次幂递增,且特征图分辨率由108至27以二次幂递减可知单个Arrow-Layer单元的数据运算成本FLOPs不受所处位置的影响。而内存访问成本MAC同时受到分辨率与维度变化的影响,选取式(6)中unit部分计算可得到P3~P5层单个Arrow-Layer单元内存访问成本MAC的相对百分比变化图,如图7所示。
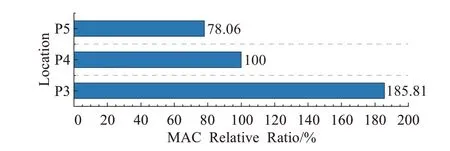
图7 P3~P5处Arrow-Layer单元MAC相对百分比Fig.7 MAC of Arrow-Layer in P3 to P5
如图7所示单个Arrow-Layer单元的内存访问成本MAC随着特征的深入而降低,这表明ACNet可通过降低P3、P4处堆叠单元数量,增加P5处堆叠单元数量的方法以较低的计算成本实现较高的计算精度,因此ACNet选择以1-3-8-12-8的单元堆叠数组合搭建网络。重新计算Darknet-53[11]、CSPDarknet[12]、Scaled-CSP[13]与ACNet网络整体与逐层的数据运算成本FLOPs和内存访问成本MAC,计算成本结果如图8所示。
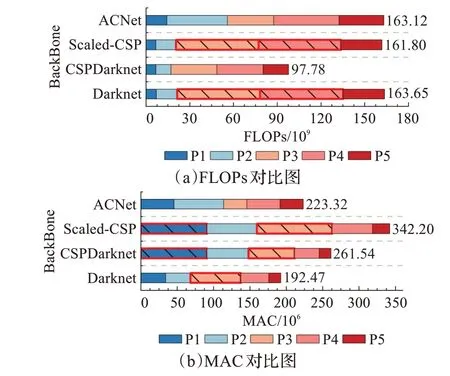
图8 卷积网络整体及逐层计算成本对比图Fig.8 Comparison of different convolutional network overall and layer-by-layer calculation cost
通过对比四种网络的计算成本可以发现:(1)与Darknet-53[11]及CSPDarknet[12]网络相比,ACNet在加深网络的同时通过搭配Arrow-Block与CSP-Block模块因而并未消耗过多的计算成本,其中数据运算成本小于较浅层网络Darknet-53[11],而内存访问成本更是低于CSP‐Darknet[12]网络。(2)与Scaled-CSP[13]网络相比,ACNet网络通过将堆叠单元较少处的卷积模块替换为Arrow-Block从而实现了内存访问成本MAC的大幅缩减。(3)与Darknet-53[11]、CSPDarknet[12]及Scaled-CSP[13]相比,ACNet网络层与层之间数据运算成本FLOPs及内存访问成本MAC相差较小,并未出现明显的计算瓶颈(图8中以红色边框及黑色斜杠填充突出标记),避免了因特定层较大计算量阻碍其他层计算而延缓检测速度。(5)ACNet网络在P1、P2层数据运算成本FLOPs略高,这是由于Arrow-Block单独使用时特征维度未经卷积层降低,但由于P1、P2层特征维度处于64、128的较低阶段,因此使用完整的维度进行计算并不会造成网络整体计算成本过高。
通过卷积结构和网络深度上的设计,ACNet具有低计算成本、高特征提取能力的优势。为了验证这一优势可以带来实质的性能提升,将ACNet网络Darknet-53[11]、CSPDarknet[12]、Scaled-CSP[13]以及额外设计的三组网络进行对比,对比细节可见实验(1)与实验(2)。
2.2 HSV域数据增强
道路图像在夜晚与白天最明显的差别在于光照,对比分析训练集与测试集图像在HSV域中的亮度可知,测试集中所有白天图像的亮度均值为112.86,与训练集相等;而黑夜图像亮度均值为63.66。做出测试集中图像亮度均值归一化直方图进行对比,直方图如图9所示。
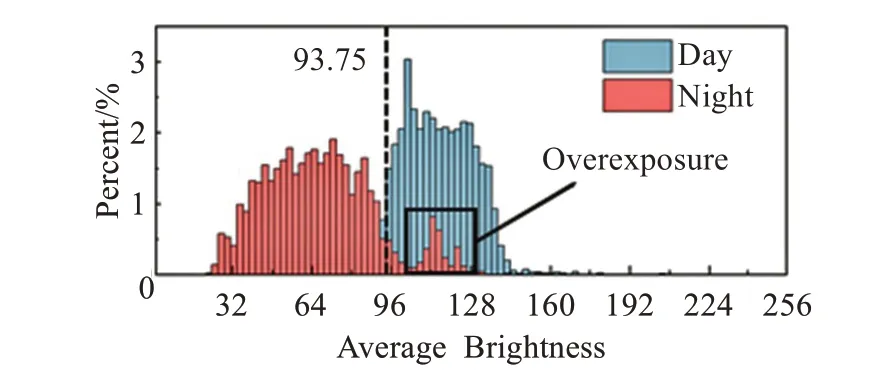
图9 测试集图像亮度均值归一化直方图Fig.9 Normalized histogram of mean of image brightness in test set
均值直方图如图9所示,夜晚与白天图像亮度均值在93.75处区分最大,即只有8.05%的白天图像亮度均值小于93.75以及10.38%的夜间图像亮度均值大于该值。若在训练时将所有图像的亮度调整至93.75则可以模拟一个“黄昏”的光照场景,使得训练集图像光照分布趋近白天与夜晚之间,进而增强模型对于夜间目标的泛化性。具体而言亮度处理在进行推理前首先通过亮度均值判断所处光照条件,并将其均值调整至93.75使图像处于“黄昏”光照场景中。由于在RGB色域中调整亮度需要先计算图像亮度再调整R、G、B取值,而在HSV域中可直接调整对应亮度,因此为了减少计算过程中精度损耗及亮度计算引起的额外耗时,YOLO-DNF将亮度处理并入HSV域与HSV扰动一同进行,统称为HSV域数据增强。
除减少白天与夜间图像的亮度差距以外,HSV域数据增强还可以削弱车灯、路灯光照过强引起的过曝光效应(Overexposure)。从图9的亮度均值归一化直方图中可见,有部分夜间图像的亮度均值处在105~127.5的区间内,这是由夜间行车时车辆灯光以及道路照明过强所致。拍摄于白天的图像中下车灯不明显,较少或者不会有过曝光现象发生,因此在仅含白天图像的训练集中训练后神经网络学习到的特征多倾向于刻画完整的车辆或行人;而拍摄于夜间的图像中车灯的亮度与周围区域差别极大,车体形状被车灯及车灯引起的光晕效应破坏,这将导致神经网络难以拟合夜间的车辆,使得网络泛化性较差。本文提出的HSV域亮度增强策略将图像的亮度均值统一至93.75处,使得亮度较强的夜间图像亮度降低,从而减轻车灯、路灯过曝光对检测的干扰。HSV域数据增强具体效果如图10对比所示。

图10 HSV域数据增强效果对比图Fig.10 Comparison of HSV domain data enhancement effects
3 实验
本实验训练和验证均在SODA10M数据集[17]中展开且并未使用其他数据集进行预训练。实验设置:每个模型训练207轮次,每批次训练4张图像,图像分辨率为864×864(为了充分发挥两阶段检测模型的精度优势,Faster-RCNN[9]模型遵循SODA10M论文中设置的1 920×1 080分辨率进行训练与测试),批次学习率为0.000 125,在前10 053步中学习率线性增长,于第166、186轮学习率衰减一倍。训练中使用SGD优化器,动量和权重衰减为0.9和0.000 5。
实验硬件环境:CPU使用5核Intel®Xeon®Silver 4210R@2.40 GHz,GPU使用NVIDIA GeForce RTX 3090(显存24 GB),内存大小24 GB,计算机系统为Ubuntu 18.04。实验软件环境:编程语言采用Python,深度学习框架采用PaddlePaddle,软件计算平台使用CUDA 11.2及CUDNN 8.0.5。
为了验证本文提出的YOLO-DNF模型性能优良以及各项改动合理有效,共设置了以下4组实验以作对比:
(1)仅使用CSP-Block、Arrow-Block卷积模块搭建两款主干网络All_Arrow以及All_CSP,使用与ACNet相反的卷积模块顺序搭建CA(CSP-Arrow)Net网络。All_Arrow、All_CSP以及CANet三种网络均与ACNet网络保持同样的堆叠单元数量以验证本文提出的ACNet网络可在一定程度上平衡计算成本以及特征提取能力。
(2)固定使用FPN作为目标检测模型的特征融合层以验证本文所提出的ACNet主干网络相较Darknet[11]、CSPDarknet[12]及Scaled-CSP[13]网络具有较低计算成本以及较强的特征提取能力。
(3)将YOLO-DNF模型与经典通用目标检测模型Faster-RCNN[9]、YOLOV3[11]、YOLOV4[12]、Scaled-YO‐LOv4[13]以及新型车辆与行人专用检测模型Lite-YO‐LOv3[20]、ResNext50-SSD[21]进行对比以验证本文所提出的YOLO-DNF模型具有一定的性能优势。
(4)在实验(3)中固定每个模型使用的数据增强策略、损失函数、学习率变化等训练策略相同,每个模型以是否使用HSV域增强为区别分别训练、测试两次以验证本文所提出的HSV域数据增强策略对于模型夜间检测能力以及泛化性的提升。
实验对比的指标包括模型检测精度mAP以及检测速度FPS。除了在SODA10M[17]的测试集中测试整体精度,额外将SODA10M[17]的测试集划分成白天与夜间两个子集并分别测试以验证模型对于光照变化的泛化性。
3.1 主干网络实验
3.1.1 消融实验
为了验证本文依据堆叠单元数量选择并搭配Arrow-Block与CSP-Block两种卷积模块所组建的ACNet网络可在一定程度平衡网络的计算成本以及特征提取能力,保持P1~P5各层与ACNet相同的堆叠单元数量分别搭建三款主干网络All_Arrow、All_CSP以及CANet以作比较。其中All_Arrow与All_CSP网络仅包含卷积模块Arrow-Block或CSP-Block,CANet与ACNet保持相反的卷积模块搭配,即在P1~P2层使用CSP-Block并在P3~P5层使用Arrow-Block。四种网络的对比实验结果如图11与表4所示。
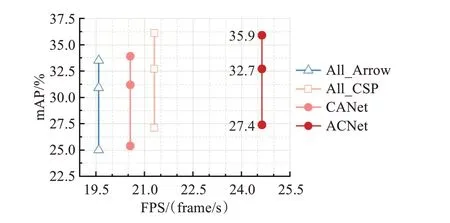
图11 主干网络结构消融实验检测精度与速度对比图Fig.11 Comparison of detection accuracy and speed in backbone structure ablation experiment
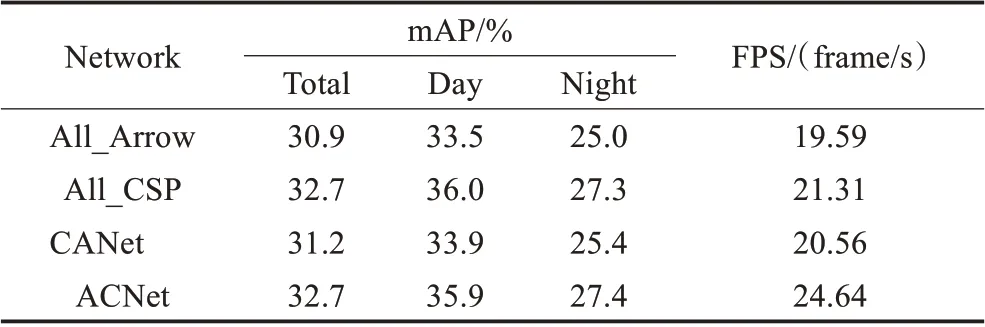
表4 主干网络结构消融实验检测精度与速度对比Table 4 Comparison of detection accuracy and speed in backbone structure ablation experiment
根据对比结果可发现本文所提出的ACNet网络相较All_Arrow、All_CSP以及CANet三种网络在检测精度与速度方面取得了最好的成绩。通过网络All_Arrow、All_CSP与ACNet的对比可发现使用单一卷积模块搭建而成的网络无法同时满足低计算成本与强特征提取能力的要求,而通过搭配Arrow-Block与CSP-Block所组建的ACNet网络可以使两种卷积模块取长补短。值得注意的是All_CSP网络的总体检测精度与ACNet保持一致,检测速度有所降低,其中白天精度略高而夜间精度略低,表明当CSP-Block处于浅层区P1、P2时其划分与融合的传导机制在特征提取能力方面收益极低,且会拉升网络计算成本,减缓检测速度。CANet与ACNet网络的对比则表明Arrow-Block适合用在堆叠单元较少的浅层区P1、P2且CSP-Block适合用在堆叠单元较多的深层区P3~P5。需要再次说明的是在网络All_Arrow以及CANet中深层区P3~P5使用的Arrow-Block模块并未对输入特征进行降维,此时256至1 024的高维度卷积计算会消耗大量的计算成本,造成检测速度的大幅下降。
3.1.2 对比实验
为了验证本文所提出ACNet网络具有低成本、高特征提取能力的优势,固定卷积模型中除主干网络以外的其他 部 分,分 别 使 用Darknet[11]、CSPDarknet[12]、Scaled-CSP[13]及ACNet作为模型主干网络进行训练和测试。实验结果如图12与表5所示。
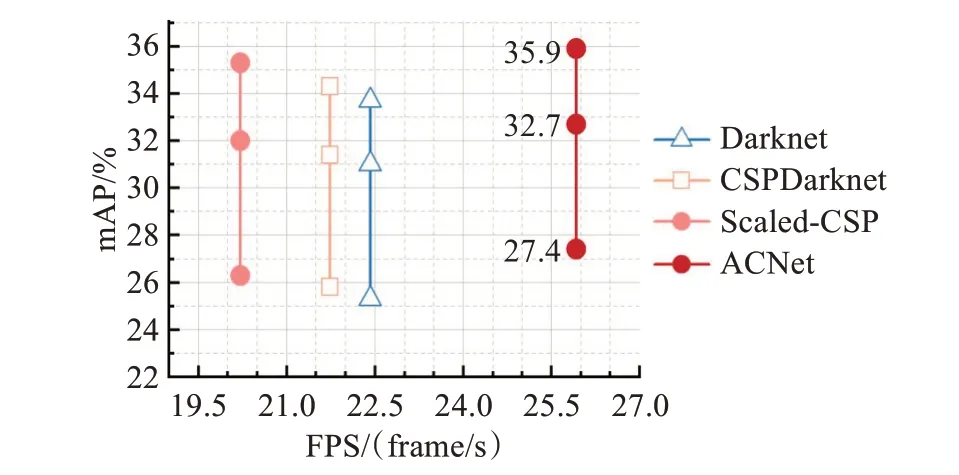
图12 使用不同主干网络的模型检测精度与速度对比图Fig.12 Comparison of model detection accuracy and speed using different backbone
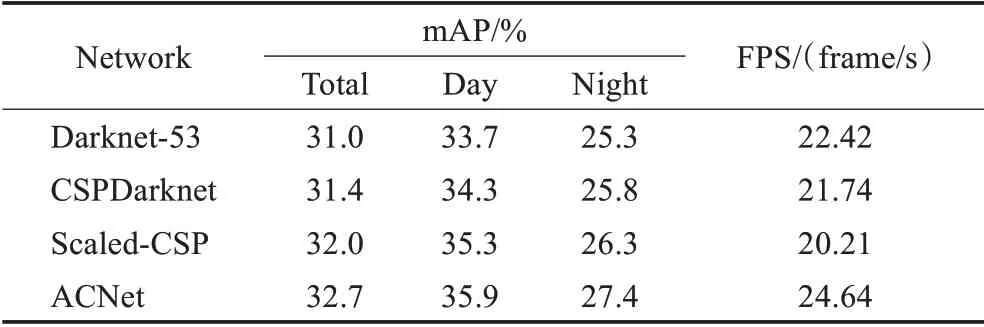
表5 使用不同主干网络的模型检测精度与速度对比Table 5 Comparison of model detection accuracy and speed using different backbone
根据对比结果可发现本文提出的ACNet在精度与速度两方面均取得了最好成绩,表明了通过分析卷积结构的特征提取能力与计算成本设计出的ACNet主干网络具有较强的学习能力以及较低的计算成本。各主干网络的检测效果视觉对比如图13所示。

图13 使用不同主干网络的检测效果图Fig.13 Results of detection using various backbone networks
3.2 检测模型对比实验
为了验证本文所出提的YOLO-DNF模型在目标检测技术研究快速发展的当下新颖且有效,将YOLO-DNF模型与四种流行的通用目标检测模型Faster-RCNN[10]、YOLOv3[11]、YOLOv4[12]、Scaled-YOLOv4[13]以及两种新型车辆与行人专用检测模型Lite-YOLOv3[20]、ResNext50-SSD[21]进行对比比较。
为了验证本文所提出的HSV域数据增强策略可以改善模型夜间检测能力,提升模型对于亮度变化的泛化性,所有模型在训练时保持数据增强策略、损失函数、学习率变化等训练策略一致,并以是否使用HSV域增强策略为区别分别训练、测试两次。比较结果如图14与表6所示。
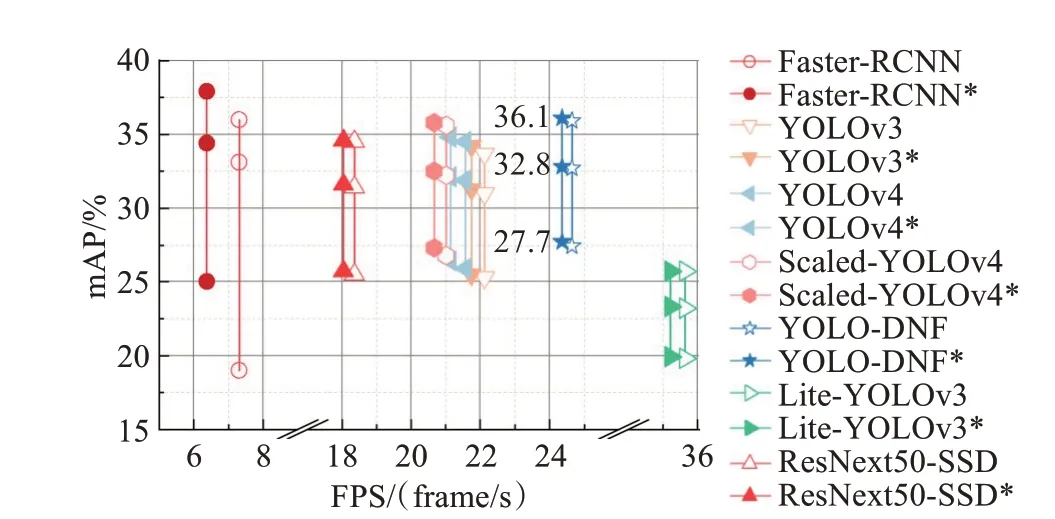
图14 不同模型检测精度与速度对比图Fig.14 Comparison of detection accuracy and speed of different models
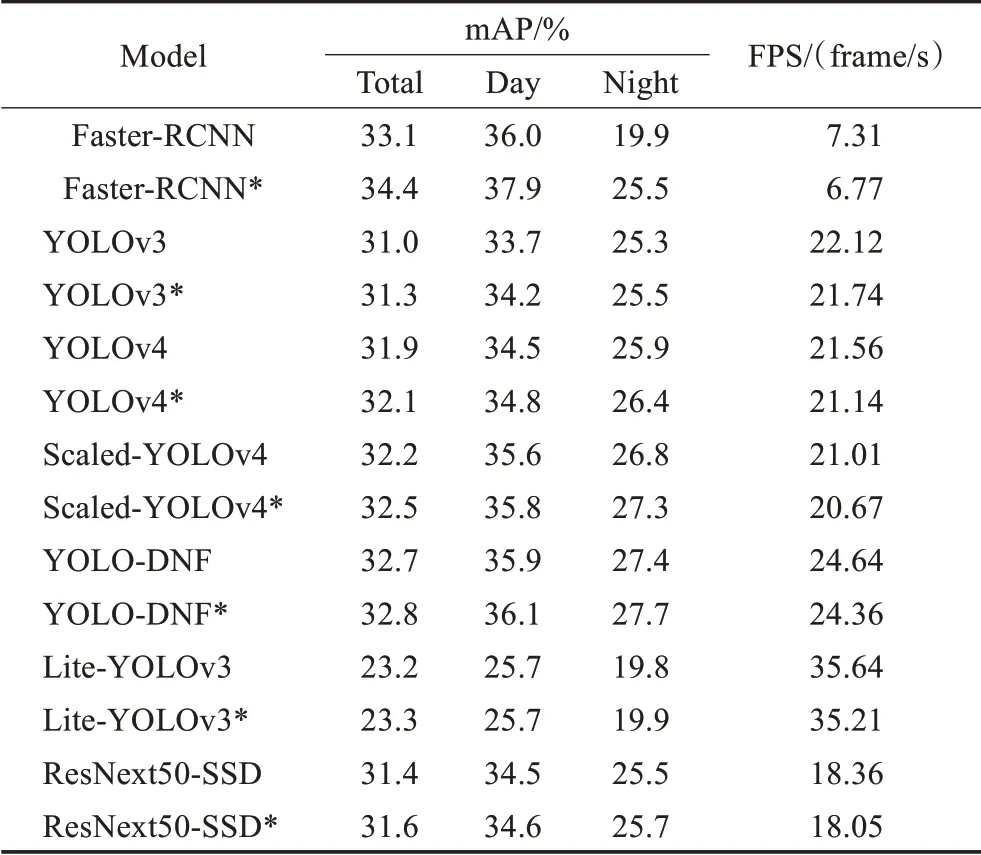
表6 不同模型检测精度与速度对比表Table 6 Comparison of detection accuracy and speed of different models
通过模型之间对比可以得出本文所提出的YOLODNF模型具有较为均衡的表现。在速度方面,YOLODNF模型达到了Faster R-CNN[10]的3.37倍,同时也领先YOLOv3[11]、YOLOv4[12]以 及Scaled-YOLOv4[13]的2~4 frame/s。在精度方面,虽然YOLO-DNF模型总精度落后于Faster R-CNN[10],但是差距集中表现在白天部分的2.2%,而夜间检测精度达到了最高的27.7%。与一阶 段 模 型YOLOv3[11]、YOLOv4[12]以 及Scaled-YO‐LOv4[13]相比,YOLO-DNF在白天与黑夜均取得了精度领先。在与新型车辆与行人专用检测模型Lite-YO‐LOv3[20]、ResNext50-SSD[21]的对比中可以发现YOLODNF模型仍处于速度与精度双优的均衡位置。Lite-YOLOv3[20]模型由于使用了轻量化的网络而取得了速度的大幅提升,但轻量化的网络特征提取能力不足,使得其精度较低。ResNext50-SSD[21]模型虽然使用了结构更为复杂的网络,但其检测框架SSD相较YOLOv3略有劣势,因此ResNext50-SSD[21]模型在检测精度与速度方面均略逊本文所提出的YOLO-DNF模型。
对比同一模型是否使用HSV域数据增强策略则可发现本文所提出的HSV域数据增强在损失速度可以忽略不计的情况下提升了模型的夜间检测精度,增强了模型对于光照条件变化的泛化性。
由于车辆与行人形状、面积差异大,模型在检测时难度不同,为了反应模型在差异较大的目标类别之间检测能力的差距,将视觉特征类似的行人、骑自行车者归于行人(Pedestrian)类,并将汽车、卡车、公交车、三轮车归于车辆(Vehicle)类,针对两类目标分别测试精度。进行比较的模型包括经典通用目标检测模型Faster-RCNN[9]、YOLOV3[11]、YOLOV4[12]、Scaled-YOLOv4[13]以及新型车辆与行人专用检测模型Lite-YOLOv3[20]、ResNext50-SSD[21],模型训练、测试时都采用了HSV域增强策略。实验结果如表7所示。
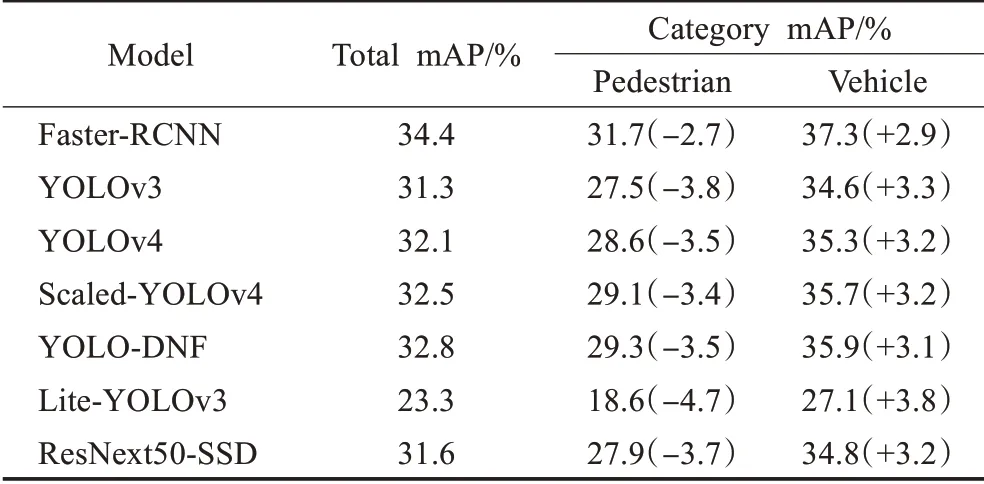
表7 不同模型检测行人类与车辆类目标精度对比表Table 7 Comparison of detection accuracy of different models for pedestrians and vehicles
根据表7可知各类模型在检测行人类目标时精度略低,而检测车辆类目标时精度略高。这是由两方面原因导致的,一方面是由于行人类目标普遍面积较小,在检测时容易遗漏;另一方面是样本不均衡,在训练集中行人类目标仅占27.85%,网络对于该类目标学习不充分。
依据表7可以发现两阶段检测模型Faster-RCNN[9]模型在行人类与车辆类目标之间检测精度差距较小,而ResNext50-SSD[21]模型精度差距较大,这是由于两阶段检测模型提出大量RoI会重复检查小目标,而SSD算法在同一位置上仅推理一次。以一阶段目标检测YOLO算法为基础的YOLOV3[11]、YOLOV4[12]、Scaled-YOLOv4[13]、YOLO-DNF及Lite-YOLOv3[20]模型在行人类与车辆类目标之间检测精度也有差距,但Lite-YOLOv3[20]、YOLOV3[11]模型的差距要大于YOLO-DNF模型,这反应了YOLO-DNF模型具有较强的特征提取能力。而模型YOLOV4[12]、Scaled-YOLOv4[13]在行人类与车辆类目标之间检测精度的差距小于YOLO-DNF,这是由于其特征融合层的改进增强了多尺度检测的能力,为YOLODNF模型后续的改进指明了方向。
YOLO-DNF模型与其他检测模型的检测效果对比图如图15所示。

图15 不同模型的检测效果图Fig.15 Detection effects of different models
如图15所示,在白天光照条件下,两阶段检测模型Faster-RCNN[9]检测出了原图中的所有目标,本文提出的YOLO-DNF模型仅遗漏一个“自行车”小目标,YO‐LOV3[11]、YOLOV4[12]、Scaled-YOLOv4[13]以 及 新 型 车 辆与行人专用检测模型Lite-YOLOv3[20]、ResNext50-SSD[21],均存在不同程度的目标遗漏。在夜间光照条件下,通过对比同模型的两次检测结果可发现:在训练中使用本文提出的HSV域数据增强策略后模型的检测效果有所提升,其中该策略对于Faster-RCNN[9]模型的提升较为明显,使该模型检测出的目标增加了4个。使用了HSV域数据增强策略后的YOLO-DNF模型检测效果最好,检测出了原图中的所有目标,其余检测模型仍存在不同程度的目标遗漏。模型的检测效果与图14及表6所示的模型检测精度对比数据相一致。
4 结束语
为了服务车辆实际驾驶场景的目标检测需求,本文通过对当下主流目标检测技术的研究,提出了新型目标检测模型YOLO-DNF,搭建了具有低计算成本、高特征提取能力优势的主干网络ACNet网络,并在卷积神经网络的训练和检测中使用HSV域数据增强策略提升模型的夜间检测能力,大大增强了网络的泛化性。最后,YOLO-DNF模型在SODA10M数据集中以24.36 frame/s图像的检测帧率达到32.8%的检测精度,其中夜间检测精度达到了27.7%,检测精度与速度得到明显提升,应用场景也进一步扩大。
后续研究将进一步依据YOLO-DNF模型继续优化,引入半监督训练来提升模型的泛化性,设计一种基于车载设备的高性能辅助驾驶技术。
