AI服务器PCIe拓扑应用研究*
2022-12-22林楷智宗艳艳孙珑玲
林楷智,宗艳艳,孙珑玲
(1.高效能服务器和存储技术国家重点实验室,北京 100085;2.浪潮(北京)电子信息产业股份有限公司,北京 100085)
1 引言
为满足大数据、云计算和人工智能等领域的数据收集与处理需求,采用各种异构形式的AI服务器得到了广泛应用。CPU+GPU是AI服务器中普遍使用的计算单元组合[1]。其中,P2P(Peer to Peer)通信用于多GPU系统中,借助缓存设备,可以有效利用PCIe资源进行GPU之间的数据交互[2]。
针对GPU加速应用,业内已有面向多种软件工具、硬件配置和算法优化的研究。2016年,Shi等人[3]通过性能基准测试,比较了GPU加速深度学习的软件工具(Caffe、CNTK、TensorFlow和Torch等);2018年,Xu等人[4]通过对软件和硬件配置的组合研究,得到不同开源深度学习框架的应用特性和功能,进一步量化了硬件属性对深度学习工作负载的影响;2019年,Farshchi等人[5]使用FireSim将开源深度神经网络加速器NVDLA(NVIDIA Deep Learning Accelerator)集成到Amazon Cloud FPGA上的RISC-V SoC中,通过运行YOLOv3目标检测算法来评估NVDLA的性能。但是,基于CPU+GPU架构,针对AI服务器在各应用场景中的分析却鲜有研究。
本文主要对AI服务器中3种典型的PCIe拓扑Balance Mode、Common Mode和Cascade Mode的应用场景进行研究,旨在通过对3种拓扑的点对点带宽与延迟、双精度浮点运算性能和深度学习推理性能分析,得到3种拓扑在各应用场景中的优势和劣势,为AI服务器的实际应用提供优选配置指导。
2 典型拓扑结构
2.1 3种基础拓扑结构
(1)Balance Mode。
Balance Mode拓扑为Dual root,根据PCIe资源将GPU平均分配到各个CPU,同一个PCIe Switch下的GPU可以实现P2P通信,不同CPU下挂接的GPU需要跨超级通道互联UPI(Ultra Path Interconnect)才能通信。以8个GPU卡为例,Balance Mode拓扑结构如图1所示。

Figure 1 PCIe card GPU Balance mode
(2)Common Mode。
Common Mode拓扑中GPU的PCIe资源均来自同一个CPU,同一个PCIe Switch下的GPU可以实现P2P通信,不同PCIe Switch下挂接的GPU需要跨CPU PCIe Root Port才能实现P2P通信,但通信带宽低于同一个PCIe Switch下的P2P通信。以8个GPU卡为例,Common Mode拓扑结构如图2所示。

Figure 2 PCIe card GPU Common mode
(3)Cascade Mode。
Cascade Mode拓扑中GPU的PCIe资源均来自同一个CPU PCIe Root Port,PCIe Switch之间为级联拓扑,同一级PCIe Switch下的GPU可以实现P2P通信,第1级PCIe Switch下的GPU和第2级PCIe Switch下的GPU之间可以实现P2P通信,不需要通过CPU PCIe Root Port。以8个GPU卡为例,Cascade Mode拓扑结构如图3所示。

Figure 3 PCIe card GPU Cascade mode
2.2 拓扑特性分析
Balance Mode的配置将GPU平均挂接在2个CPU下,GPU PCIe总的上行带宽较高;Common Mode在一定程度上能够满足GPU之间点对点的通信,同时可保障足够的CPU与GPU之间的I/O带宽;Cascade Mode只有一条×16链路,但由于GPU之间通过PCIe Switch串接,提升了点对点的性能,降低了延迟。
对于双精度浮点运算,因GPU计算需要使用处理器与主内存,由于Dual root的拓扑上行带宽与内存使用率提升,其性能会优于Single root的拓扑。
对于深度学习推理性能来说,具备并行计算能力的 GPU 可以基于训练过的网络进行数十亿次的计算,从而快速识别出已知的模式或目标。不同拓扑下GPU的互联关系不同,GPU之间的沟通会影响深度学习推理的整体性能。
3 实验及结果分析
3.1 实验装置
为探究在不同应用条件下3种拓扑的性能差异,实验使用自研AI服务器(NF5468M5)搭建机台进行测试。装置使用2颗CPU,规格为Intel® Xeon® Gold 6142,主频为2.60 GHz;使用12条 DDR4内存,容量为32 GB,主频为2 666 MHz;使用8颗GPU,规格为NVIDIA Tesla-V100_32G。
3.2 实验结果分析
3.2.1 点对点带宽与延迟
对于GPU的P2P性能,可以使用带宽与延迟来衡量。PCIe 3.0的带宽为16 GB/s,理想状况下,实际应用中带宽可以达到理论带宽的80%左右。PCIe的延迟主要取决于PCIe Trace的长度、走线路径上的器件及是否经过UPI、是否跨RC(Root Complex)等。
如图4所示,在Balance Mode、Cascade Mode和Common Mode 3种拓扑中,分别测试挂在同一个PCIe Switch下的GPU(如图4中线路①)和跨PCIe Switch的GPU(如图4中线路②)的点对点带宽与延迟。测试结果如表1、表2及图5所示。
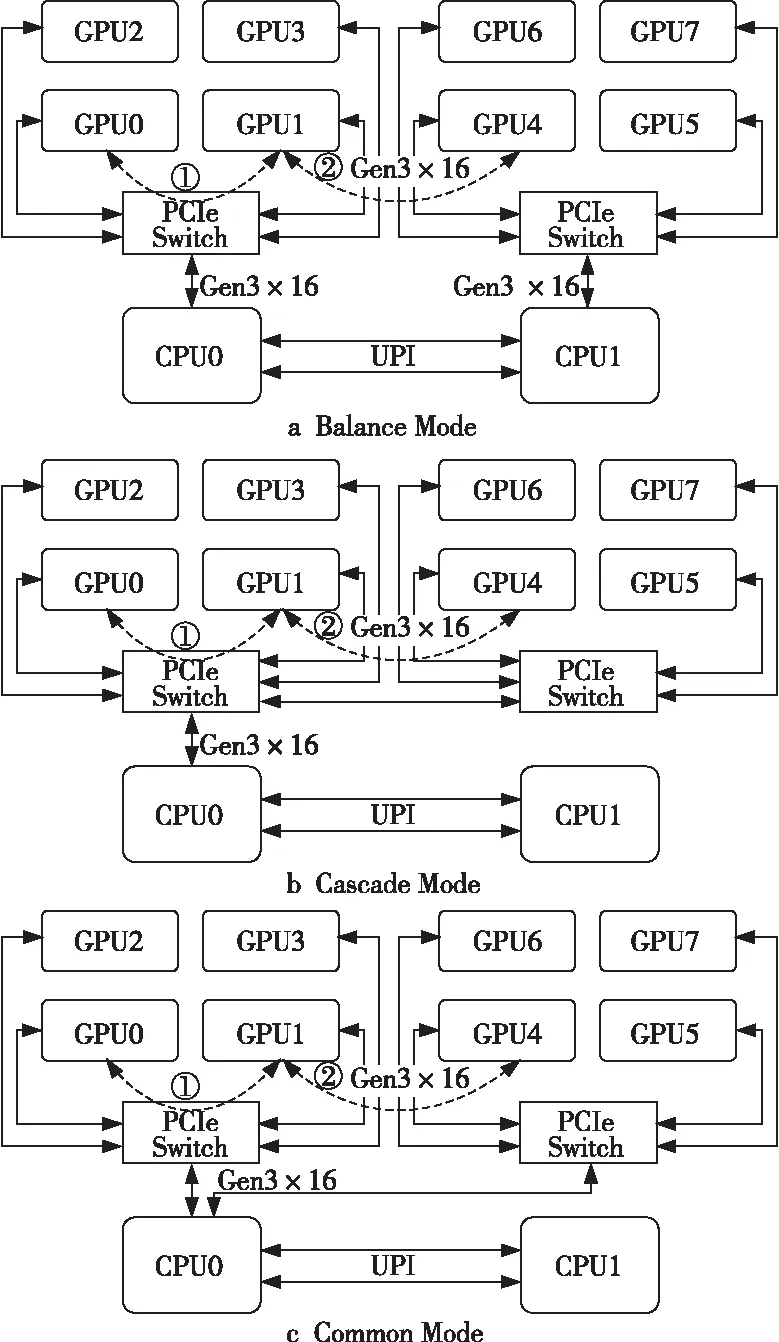
Figure 4 Schematic of point-to-point bandwidth and latency
在同一个PCIe Switch下,由于GPU之间的传输距离是一样的,所以在点对点回路①中,3种拓扑的带宽与延迟结果皆相近;对于跨PCIe Switch的2颗GPU,由于CPU间为3 UPI Links,其信号传输速度足够快,所以Balance Mode与Common Mode的结果相近,而对于Cascade Mode,由于GPU之间的沟通只需经过PCIe Switch,传输路径变短,其点对点延迟性能得以提升;同时,对于Intel CPU而言,一个PCIe ×16 Port 为一个RC,不同RC 之间的通信带宽比同一个RC下PCIe Switch之间的通信差,故Cascade Mode的带宽也得以提升。

Table 1 GPU point-to-point bandwidth and latency on the same PCIe switch

Table 2 GPU point-to-point bandwidth and latency across PCIe switch
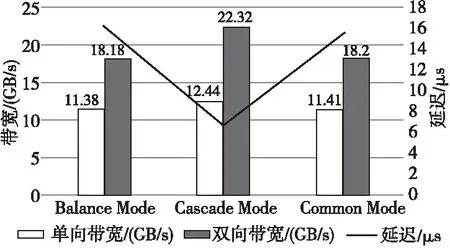
Figure 5 GPU point-to-point bandwidth and latency across PCIe Switchs
3.2.2 HPL性能分析
HPL(High Performance Linpack)测试可以表征3种拓扑在双精度浮点运算中的表现。Balance Mode、Common Mode和Cascade Mode 3种拓扑的HPL性能测试结果如表3所示。

Table 3 HPL performance of three topologies
为清晰表征3种拓扑在HPL性能测试中的表现差异,以Balance Mode的测试分数为基准,得到Common Mode和Cascade Mode 2种拓扑HPL性能测试分数对Balance Mode分数的占比,如图6所示。
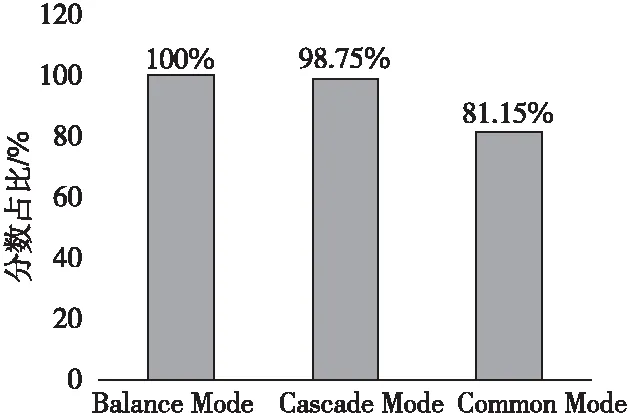
Figure 6 HPL performance of three topologies
HPL测试需要使用处理器与主内存,由于Dual root的拓扑上行带宽和内存使用率提升,性能将会优于Single root的拓扑,故Balance Mode和Common Mode在HPL测试中的分数会高于Cascade Mode的。另外,Balance Mode结构将8个GPU平均挂载在2颗CPU下,可以利用2颗CPU及内存的资源来完成浮点运算;在Common Mode中,虽然所有GPU都挂载于CPU0下,但因CPU间的UPI连接速度够快,CPU间的单条UPI连接速度高达10.4 GT/s,同时运行8个GPU的浮点运算时,可以通过UPI来与CPU1通信,且共享内存。故整体而言,Balance Mode的HPL性能会略高于Common Mode的。
3.2.3 深度学习性能分析
深度学习DL(Deep Learning)通过多个处理层构成的计算模型进行图像、视频和音频等的处理和识别[6],常用模型有自动编码机、受限玻尔兹曼机、深度神经网络、卷积神经网络和循环神经网络等,其中卷积神经网络[7]在图像处理方面应用较为广泛,如图7所示。

Figure 7 Image processing using convolutional neural network
在2017年的GPU技术大会(GTC)上,NVIDIA发布了基于volta的V100 GPU。V100 GPU是第1个包含“张量核心”的NVIDIA GPU,这是4×4矩阵乘法操作设计的核心,是深度学习模型的主要部分[8]。
深度学习训练模型主要使用2种分布策略——数据并行型和模型并行型[9],本文实验采用数据并行型策略。对于数据并行,每个GPU都有一个深度学习模型的完整副本。每个GPU接收数据的不同部分进行训练,然后将其参数通过Ring All-Reduce的方式更新到所有GPU,以便与所有GPU共享其训练输出。如图8所示,以Balance Mode为例,在运行数据并行的深度学习训练模型时,当多台机器运行时,GPU的通信流通过IB(InfiniBand)卡实现机器之间的信息传递;当单台机器运行时,基于NCCL(NVIDIA Collective Communications Library)通信库,8个GPU卡的信息传递构成环形通信流。与GPU之间的通信带宽相比,减小的CPU和GPU之间的通信带宽会影响GPU获取数据集所需要的时间,即完成一个Batch size所需的时间。

Figure 8 Data parallel communication mode for Balance mode
深度学习训练模型种类繁多,不同模型有不同的优势,可以应用于各类实际应用场景。如图9所示,ResNet计算模型借鉴了Highway Network思想,利用残差网络构建,其优化的目标为输出和输入的差F(x)=H(x)-x。ResNet的计算深度为152层神经网络,Top5错误率可达3.57%,解决了层次比较深时无法训练的问题。VGG计算模型分为VGG16和VGG19,计算深度为16和19层神经网络,在目标检测与识别方面有突出的性能优势,Top5错误率达7.3%[10]。

Figure 9 ResNet model
深度学习模型场景有图像、视频和语音处理及推荐等,不同应用场景的数据集类型不同。以图像处理为例,针对参数规模不同的模型,AI服务器不同PCIe 拓扑的性能表现也会有不同,常见的计算量及容量较小的模型有ResNet50(99 MB)[11]、InceptionV3(92 MB)等,计算量及容量较大的模型有VGG16(528 MB)、VGG19(549 MB)[12]等。以计算量及容量较小的模型ResNet50和计算量及容量较大的模型VGG16为例,通过不同拓扑结构对图像集训练速度的测试,可以得到3种拓扑在2类深度学习训练模型中的适用性,结果如表4和图10所示。

Table 4 Performance of three topologies under different deep learning models

Figure 10 Performance of three topologies under different deep learning models
对于计算量及容量较小的模型,模型重复读取数据集的次数变多,对处理器、硬盘存取和GPU间资料交换有较高的需求,所以同一颗CPU下使用2条PCIe ×16带宽的Common Mode的性能表现(如ResNet50为5 624.23 images/s)会优于另外2种拓扑;对于计算量及容量较大的模型,在数据并行的模式下运行深度学习训练时,系统内的每个GPU需在接收到同样的参数后,再开始执行训练,因为Cascade Mode的GPU点对点性能较好,其搬移模型参数至各GPU的速度会较快,所以性能(如VGG16为2 658.47 images/s)会优于另外2种拓扑。
4 AI服务器中的GPU PCIe拓扑切换设计
针对不同的深度学习训练模型,结合实际应用场景,往往需要在同一台服务器中切换不同的GPU PCIe拓扑,来实现性能最优化。手动更改线缆连接方式需要开箱操作,用户体验不友好,还有可能导致维护人员手指划破等工伤事件。
有如下2种方案可以实现BMC(Baseboard Management Controller)远程一键拓扑切换。
(1)基于PCIe Switch FW技术的GPU拓扑远程一键切换
如图11所示,PCIe Switch 0 的Port 0始终为上行端口,Port 1始终为下行端口;PCIe Switch 1的Port 0始终为上行端口,Port 1始终为上行端口。拓扑的切换通过配置PCIe Switch 1的FW或发送PCIe Switch 1的配置命令实现。

Figure 11 GPU topology remote switch based on PCIe Switch FW technology
若切换为Balance Mode,则BMC配置PCIe Switch 1的FW或发送PCIe Switch 1的配置命令,将PCIe Switch 1下对应的GPU4~GPU7分配到PCIe Switch 1的Port 0;若切换为Cascade Mode,则BMC配置PCIe Switch 1的FW或发送PCIe Switch 1的配置命令,将PCIe Switch 1下对应的GPU4~GPU7分配到PCIe Switch 1的Port 1。
(2)基于PCIe 4.0 MUX的GPU拓扑远程一键切换。
如图12所示,PCIe Switch 0 的Port 0始终为上行端口,Port 1始终为下行端口;PCIe Switch 1的Port 0始终为上行端口。拓扑的切换通过BMC控制PCIe MUX实现。
若切换为Balance Mode,则BMC通过配置PCIe 4.0 MUX,使PCIe Switch 0 Port 1切到NIC0,CPU1切到PCIe Switch 1的Port 0;若切换为Cascade Mode,则BMC通过配置PCIe 4.0 MUX,使PCIe Switch 0的Port 1切到PCIe Switch 1的Port 0。

Figure 12 GPU topology remote switch based on PCIe 4.0 MUX
5 结束语
针对AI服务器的3种PCIe拓扑结构——Balance Mode、Common Mode和Cascade Mode,本文进行了点对点带宽与延迟、HPL性能的测试和数据分析,并选取典型深度学习模型进行拓扑结构的应用场景分析。
在点对点带宽与延迟方面,因Cascade Mode中GPU只需经过PCIe Switch且GPU挂载在同一个RC下,故Cascade Mode的点对点带宽与延迟均为3种拓扑中最优的;在HPL性能方面,由于Dual root的上行带宽和内存使用率提升且Balance Mode中GPU均匀使用2颗CPU和内存的资源,故Balance Mode的HPL性能最优;在深度学习典型应用方面,Cascade Mode因具备较好的点对点性能而更擅长计算量及容量较大的模型数据处理,Common Mode因使用同一颗CPU的2条PCIe ×16带宽而更擅长计算量及容量较小的模型的数据处理。
针对密集度更高的超大规模的数据集群,NVDIA发布了基于NVLink的GPU,GPU间NVLink每条通道的单向理论带宽为25 Gb/s,每个端口的双向理论带宽可达50 GB/s。相对于利用PCIe协议的成本较低的GPU,NVLink将GPU的卡间通信和CPU分离,使计算单元兼具Balance Mode的高带宽和Cascade Mode的卡间高通信能力。
在智能计算领域,复杂多变的应用场景对计算架构的选择和设计提出了更高的需求。在满足实际应用需求的条件下,选择最优的PCIe 拓扑结构,实现计算资源的优化配置,加速AI服务器的计算处理能力,面向具体应用场景优化现有拓扑和创新设计计算架构,将为云数据时代带来新的发展契机。
