基于增量学习的数控机床故障诊断系统
2022-12-20张煜莹
张煜莹, 陆 艺, 赵 静
(1.中国计量大学计量测试工程学院,浙江杭州310018;2. 杭州沃镭智能科技股份有限公司,浙江杭州310018)
1 引 言
作为制造业的主要设备,数控机床的加工水平直接影响机械加工、航空等众多产业[1]。主轴轴承作为数控机床中的关键零件,若长期于磨损、胶合等失效形式下工作会导致轴承温度升高,故障加剧,最终影响零件加工精度或导致设备停机[2]。刀具作为与加工件直接接触的部件,其磨损状态直接影响加工件的精度[3]。轴承故障诊断常采用共振解调技术,此方法通过对比包络频谱中的频率和轴承故障特征频率进行故障诊断[4~6]。针对刀具故障诊断,戴稳将刀具振动数据转化为小波尺度图,将其输入依照Alexnet网络架构搭建的卷积神经网络(convolutional neunral networks,CNN)模型中训练及诊断,此方法对刀具磨损状态判断具有良好效果[7];陈炳旭借助DenseNet网络和BILSTM记忆单元搭建卷积循环神经网络用于刀具状态判断,弥补卷积网络对时序特征提取的不足[8]。但这些诊断方法存在2个问题:1)未考虑2种故障同时出现的状况;2)这些方法均基于同一工况,实际工业现场中,由于工作任务的变化,机床可能处于不同转速下,预训练模型无法对所有转速下的数据进行故障诊断。且预训练模型对故障类别的涵盖程度有限,因此需要考虑对预训练模型进行更新优化,使其满足不同时期检测需求。
针对数控机床中主轴轴承和刀具同时出现故障或机床主轴转速改变时的故障诊断问题,设计了1种基于增量学习的数控机床故障诊断系统,该系统以主轴轴承和刀具作为整体研究对象。系统训练过程涉及2个模型——教师模型和学生模型。教师模型为某一转速下的故障诊断模型,学生模型为跨转速故障诊断模型。通过增量学习使学生模型继承教师模型的知识并学习跨转速数据的知识,最终利用学生模型对测试数据进行测试,输出结果。
2 系统设计
2.1 硬件设计
系统硬件部分主要包括数控机床、振动加速度传感器、恒流源、采集卡和边缘端计算机。数控机床型号为vmc-850,传感器型号为三轴加速度传感器1A314E,用于采集x、y、z三个方向的振动信号;恒流源型号为YMC8204,用于输出10 mA电流给传感器供电;数据采集卡型号为PCI-1716,采样频率fs为20 kHz,最终采集所得的振动信号储存在边缘端计算机,用于后续模型训练。硬件结构示意图如图1所示。

图1 硬件结构示意图Fig.1 The hardware structure diagram
2.2 软件设计
系统软件部分主要包括数据采集模块、故障仿真模块以及故障诊断模块。软件流程图如图2所示。

图2 软件结构示意图Fig.2 The software structure diagram
数据采集模块位于边缘端计算机,通过传感器等硬件利用此模块采集主轴轴承和刀具的振动信号,并初步去除工频干扰等影响。实际工业使用中,主轴转速通常在1 000~6 000 r/min范围内,而最常用转速为3 000 r/min,因此将主轴转速3 000 r/min下采集的数据记为数据集1,主轴转速1 000,2 000,4 000,5 000,6 000 r/min时采集的数据记为数据集2。此模块需要采集数据集1和数据集2,其中包括了训练数据以及测试数据。
试验机床为工业现场机床,因此刀具磨损信号容易得到,但轴承无法人为破坏。为得到含有不同轴承故障和不同刀具磨损状态的完整数据集,使用故障仿真模块对主轴轴承故障进行仿真。故障仿真信号如式(1),式(2)所示[9]:
Y(t)=S(t)+r(t)
(1)
(2)
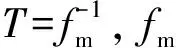
当y0=20,ζ=0.1,fn=1 100 Hz,fm=107.3 Hz,r(t)为信噪比为7 dB的高斯白噪声时,生成故障特征频率为107.3 Hz的轴承外圈故障仿真信号。机床实际振动信号、轴承外圈故障仿真信号Y(t)、添加仿真故障后机床振动信号及其包络谱如图3所示。

图3 机床实际振动及仿真信号Fig.3 Actual vibration and simulation signal of machine tool
由图3(d)可知,添加仿真故障后机床振动信号中存在频率为107.3 Hz的信号分量及其倍频,与预期相符,证明故障仿真模块的有效性。后续仿真其余轴承故障只需修改对应轴承故障特征频率即可。
故障诊断模块主要实现模型的训练以及对测试数据的模式识别。利用Anaconda在PyCharm中配置好试验所需环境后,使用keras以tensorflow为后端搭建一维卷积神经网络对数据集1进行学习,得到教师模型;用教师模型对数据集2进行识别,通过模型泛化能力识别正确的部分记为数据集2-1,识别为未知类别的部分记为数据集2-2;将数据集 2-2 和数据集1输入网络,通过知识蒸馏和混合损失函数的方式对教师模型的知识进行迁移和更新得到学生模型,达到增量学习的目的;最终用学生模型对测试数据进行诊断分类,判断机床所处状态。模型中所使用软件及版本为Anaconda3-5.3.1,PyCharm 2019.3.3、Keras2.3.1、Tensorflow 2.1,处理器为Intel Core i5-4210U。
3 基于增量学习的故障诊断模型
3.1 算法描述
目前深度学习领域的卷积神经网络常采用堆叠式3×3的卷积核,既利于加深网络深度,又可用较少参数获取较大感受野,从而抑制过拟合[10]。以此为鉴并结合一维信号的特点[11],提出应用于诊断机床故障的模型—基于增量学习的深度卷积诊断模型(deep convolutional neural network based on incremental learning,ILDCNN),模型第1层采用大尺度卷积核,作用是提取短时特征。该卷积核大小由多次试验优化所得,作用是学习与故障诊断相关的特征,防止因噪声干扰产生的过度学习。其余卷积层均采用3×1的卷积核。ILDCNN模型结合2种不同尺度的卷积核,既保证运算速度,同时在加深网络深度前提下抑制过拟合。
此外,模型针对训练时中间层数据分布改变的问题引入了Batch Normalization算法,在每1层卷积之后都采用批量归一化操作,提高网络的泛化能力的同时防止梯度消失或爆炸、加快训练速度。模型还针对出现未知故障的问题加入未知故障诊断模块,当识别到未知类别时,由人工初步判断故障类型,若查明原因,则将未知样本打标签后重新加入模型进行增量学习,以此完善模型。增量学习[12]流程如下:首先将教师模型作为独立网络单独训练,保存训练结果最优时的网络结构和模型参数,通过设置蒸馏温度T输出教师模型提供的标签,记为软标签。其次,将数据输入与教师模型结构相同的ILDCNN模型(即学生模型)中,而后分成2步计算:1)使用与教师模型相同的蒸馏温度T输出ILDCNN模型的预测值,记为软预测;2)直接输出ILDCNN模型的预测值,记为硬预测。软预测与软标签通过计算交叉熵得到蒸馏损失Lold,硬预测与数据真实标签通过计算交叉熵得到蒸馏损失Lnew,Lold与Lnew相加得到总损失函数L,通过梯度下降更新ILDCNN模型的参数,最终实现对教师模型知识的迁移和对新数据的学习。ILDCNN模型的训练方式如图4所示。

图4 ILDCNN模型训练方式Fig.4 The training method of ILDCNN model
3.2 BN层
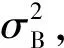
(3)
(4)
(5)
yi=γxi+β
(6)
式中:xi为mini-batch中第i个输入;m为mini-batch长度;ε为保证数值稳定的常数项;γ为缩放参数;β为偏移参数。
3.3 未知故障诊断模块
分类问题中常用Softmax函数作为模型最后一层的激活函数用于解决多分类、单标签问题。该函数如式(7)所示,其作用是将输入均映射到(0,1)区间内,且所有映射后的输出和为1,选取概率最大值为预测类别。但未知故障可能不属于任一类别或属于多个类别,此为多分类、多标签问题,因此采用适合该问题的Sigmoid函数作为模型最后一层的激活函数[15]。该函数如式(8)所示,以(0,0.5)中心对称,满足事件发生与否的概率,且任一输入经映射后输出范围均为(0,1),因此映射后的输出经阈值划分后满足可能不属于任一类别或属于多个类别的情况,即未知故障的识别。
(7)
(8)
式中:zi为输入数据中第i个元素;n为总输入个数;x为输入数据。
阈值选取以发挥模型最佳性能为目的,经多次试验所得。加入此模块前,任何未知故障均被误认为已知故障中的一种,此模块为未知类别的分类提供了依据。识别到未知故障后,人工初步判断故障类型并为其打标签,而后将其作为新数据重新送入模型学习其特征以完善模型,此阶段为增量学习,训练方式如图4所示。
3.4 增量学习
实际工业现场中会出现机床转速改变以及未知故障等问题。如何使ILDCNN模型对未知领域数据依旧有良好诊断能力,是衡量智能诊断算法好坏的重要指标,为此将引入增量学习算法。
此算法运用知识蒸馏和混合损失函数的方式对教师模型进行更新。知识蒸馏通过定义蒸馏温度θ使ILDCNN模型的软预测匹配教师模型的软输出,从而继承更多有用信息,实现知识迁移[12,16]。

L=Lold+Lnew
(9)
(10)
(11)
(12)
(13)
(14)
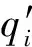
4 故障诊断试验
4.1 试验数据准备
试验数据采集于立式加工中心vmc-850,为充分利用数据并避免过拟合,利用重叠采样进行数据增强。以训练样本长度2 048为采样窗口,偏移量为1进行采样,采样方式如图5所示。
试验涉及8类机床故障,即报废刀具和新刀具各自对应的轴承无故障、外圈故障、内圈故障和滚动体故障。具体分类标签如表1所示。每一类均包含数据集1的900个训练样本和100个测试样本、数据集2的4 500个训练样本和500个测试样本。
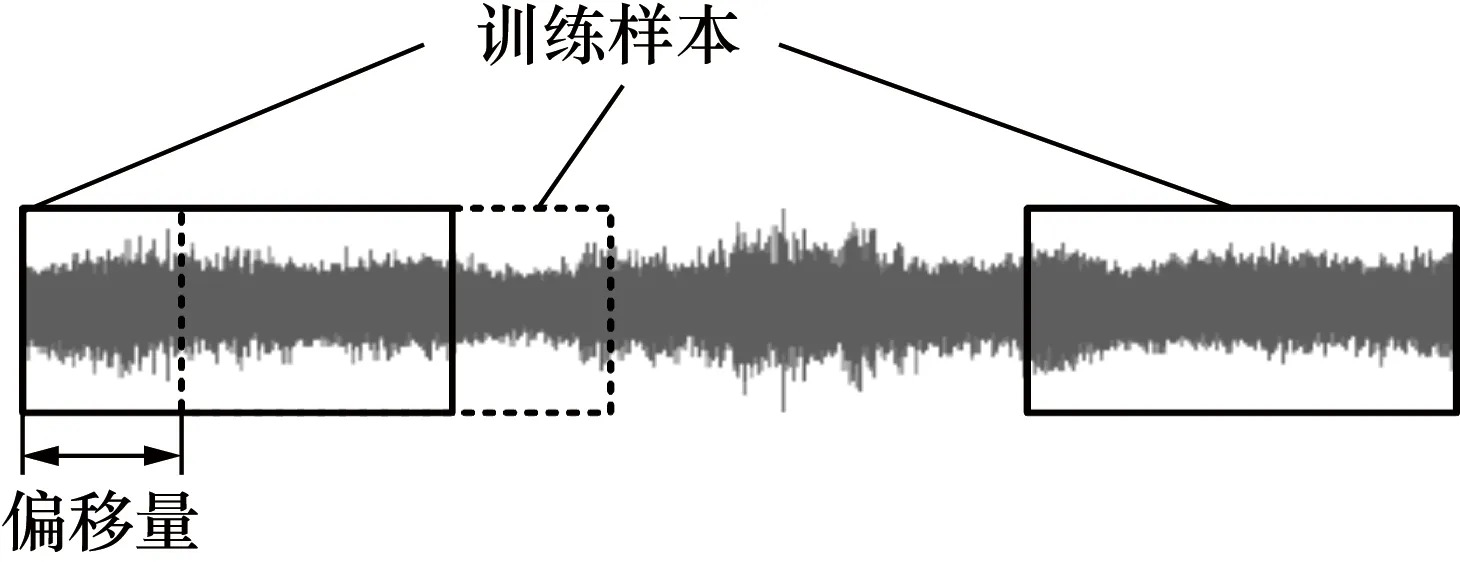
图5 重叠采样Fig.5 Overlap sampling
4.2 试验模型及参数
教师模型和ILDCNN模型参数均如表2所示,蒸馏温度θ设为2。

表1数据集分类标签Tab.1 The classification label of data set
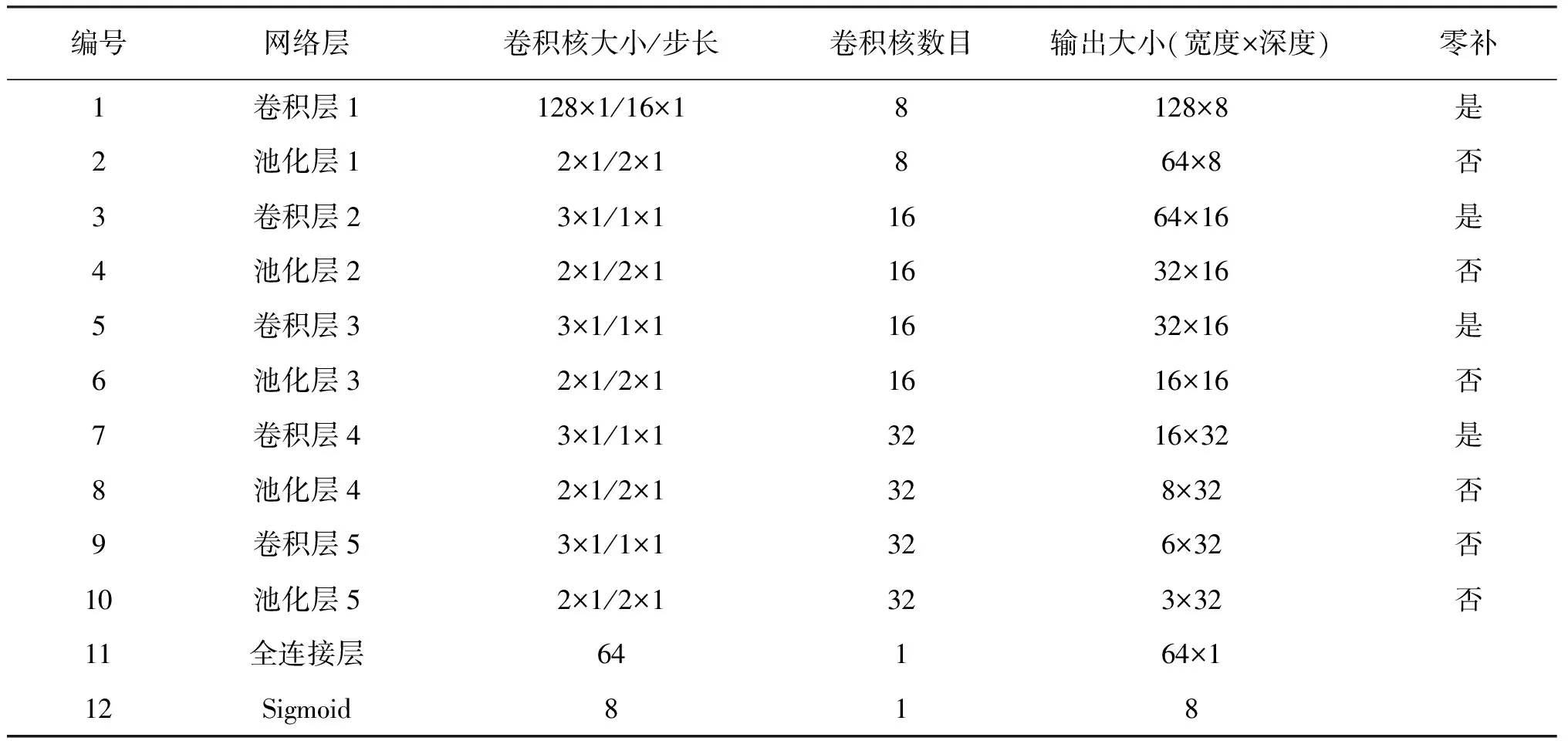
表2模型结构参数Tab.2 The structure parameters of model
4.3 教师模型训练
教师模型用数据集1训练后曲线如图6所示。教师模型准确率稳定在90%左右,损失值稳定在0.25左右,且准确率上升迅速,波动较小,证明教师模型在此转速下具有良好的训练效果。

图6 教师模型训练曲线Fig.6 Teacher model training curve
4.4 阈值选取
教师模型若要用于测试,则需先设置合适阈值以识别未知类别。为确定最佳阈值,发挥模型最佳性能,选择多个阈值对模型进行试验。使用未知故障样本对教师模型进行测试,模型将未知故障样本正确识别为未知类别的概率为模型准确率;使用数据集1的测试数据对教师模型进行测试,模型将其错误识别为未知类别的概率为模型误检率。准确率和误检率随阈值变化如图7所示。设置0.7、0.75、0.8、0.85、0.9五个阈值对模型准确率和误检率进行检测,准确率或误检率数值均为20次试验测得的均值。
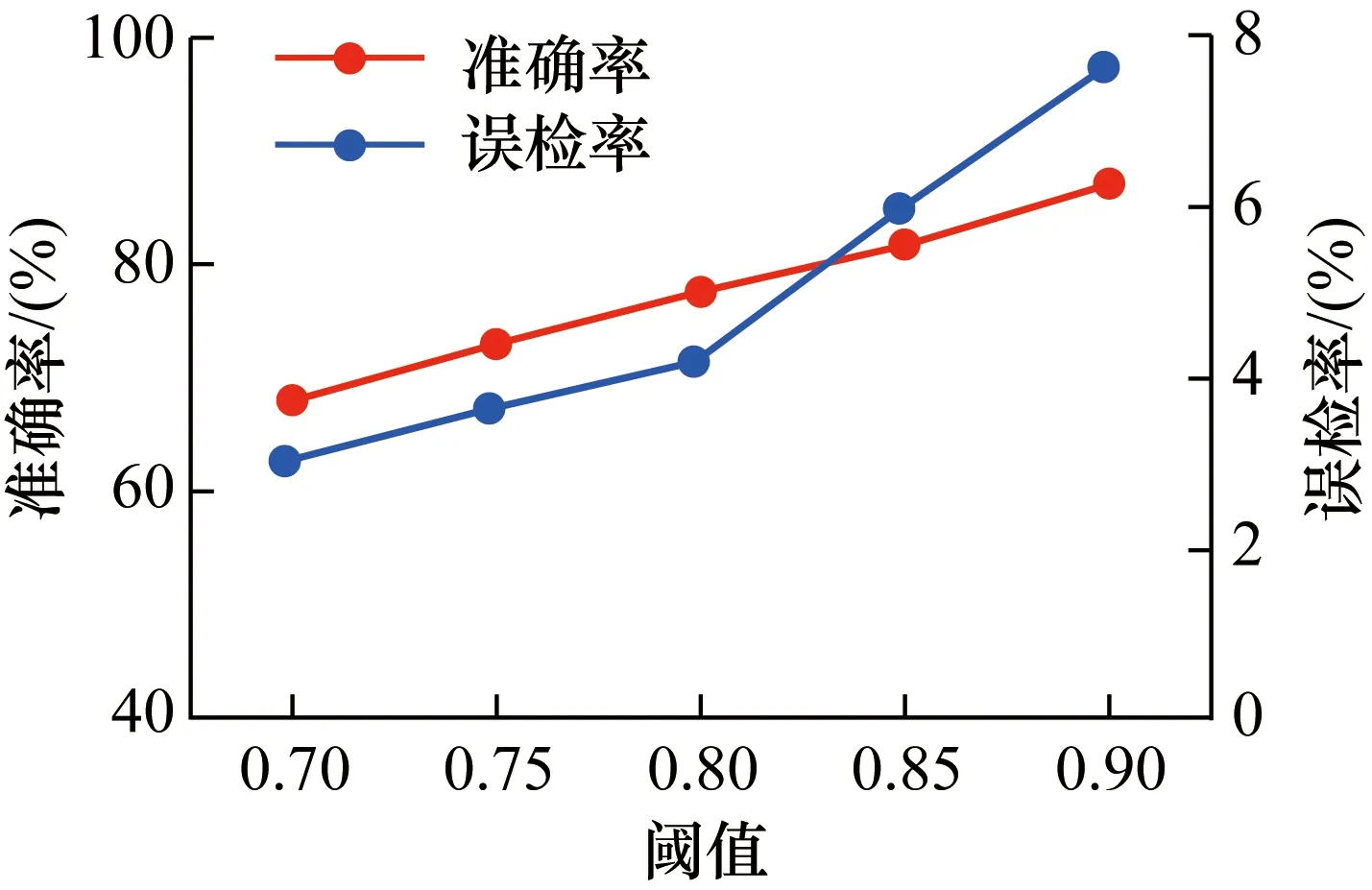
图7 准确率和误检率随阈值变化图Fig.7 The accuracy and false detection rate change with threshold
由图7可知,准确率处于67.98%~87.08%范围内,随阈值增大而增大;误检率处于2.99%~7.57%范围内,随阈值增大而增大,且阈值大于0.8后误检率迅速上升。为使模型发挥最佳性能,需使准确率尽可能高,误检率尽可能低,因此取最佳阈值为0.8。
4.5 教师模型测试
为了检测教师模型对不同转速下数据的故障诊断能力,使用教师模型对数据集2进行故障识别,阈值为0.8,诊断准确率如图8所示。
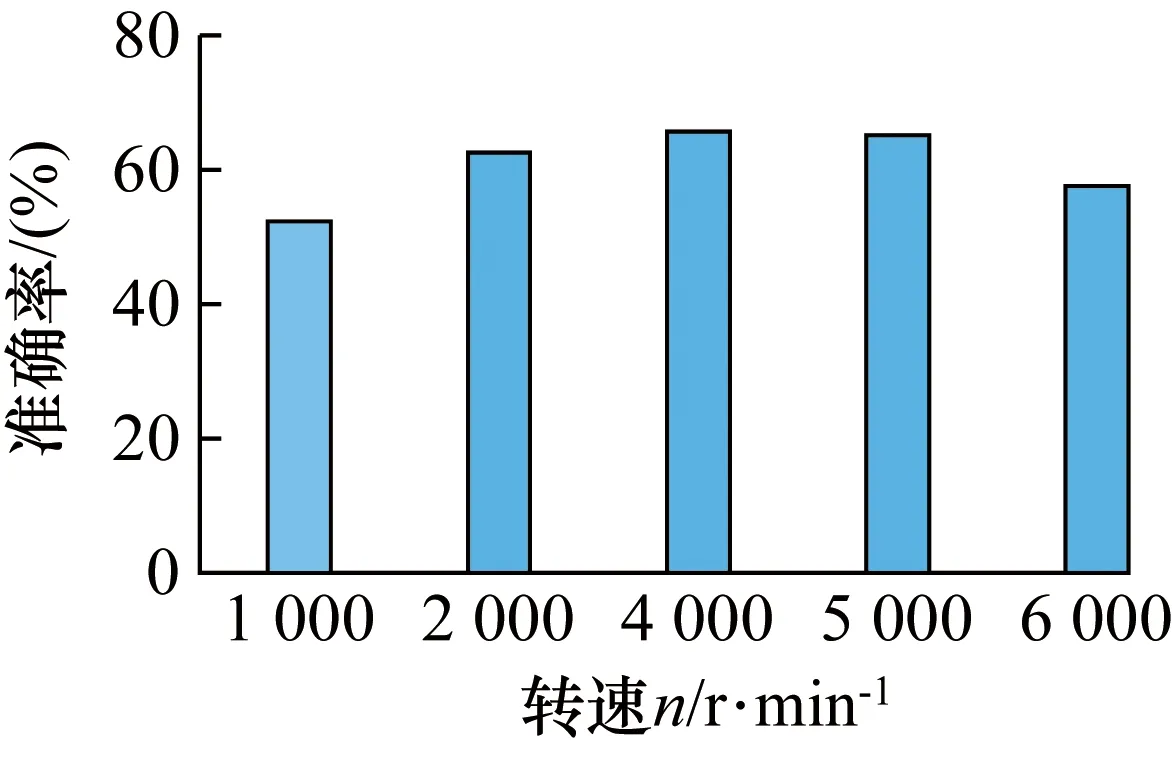
图8 教师模型对数据集2的诊断准确率Fig.8 The diagnostic accuracy of the teacher model on data set 2
由图8可知,诊断准确率均处于52.31%~65.76%,模型可检测部分故障,但未达到工业现场实际需求,因此引入增量学习,将未识别出的样本(即数据集2-2)重新打标签后送入教师模型训练优化,得到ILDCNN模型。
4.6 ILDCNN模型训练
ILDCNN模型以教师模型为基础,对数据集2-2进行增量学习,ILDCNN模型的训练曲线如图9所示。
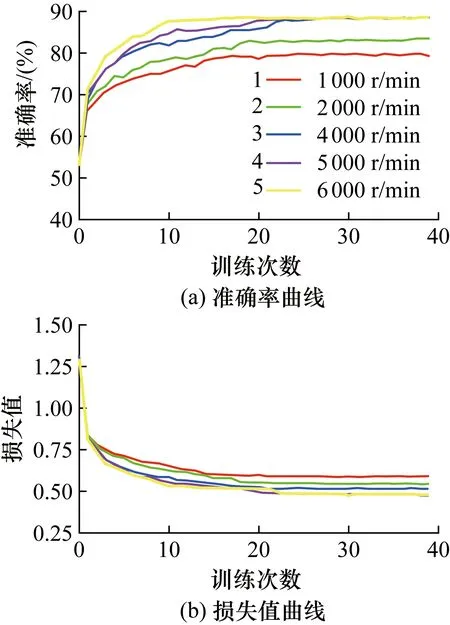
图9 ILDCNN模型训练曲线Fig.9 ILDCNN model training curve
图9(a)中曲线1~5,准确率稳步上升,经过约20次训练后,准确率最终稳定在77.40%~86.08%之间。图9(b)中曲线1~5损失值走向几乎一致,经过约20次训练后,损失值最终均稳定在0.6左右。由此说明模型收敛情况较好,且针对不同转速的数据,增量学习均有成效。
4.7 ILDCNN模型测试
为了验证增量学习的效果及ILDCNN模型是否出现灾难性遗忘的问题,使用ILDCNN模型对数据集1和数据集2中的测试数据分别进行20次诊断试验并记录准确率,结合图8中教师模型对数据集2的诊断准确率,得出增量学习前后诊断准确率对比图如图10所示。

图10 增量学习前后准确率对比图Fig.10 Comparison chart of accuracy before and after incremental learning
由图10可知,增量学习后,ILDCNN模型对数据集2的诊断准确率均处于76.49%~86.09%之间,相比增量学习前,准确率提高约22%,模型诊断效果显著提高,证明增量学习可提高模型跨转速故障诊断的能力。ILDCNN模型对数据集1测试数据的诊断准确率均处于83.53%~90.54%之间,证明ILDCNN模型对教师模型知识的迁移效果良好,未出现灾难性遗忘。
为了进一步验证ILDCNN模型在跨转速故障诊断领域的优化效果,将其与对比模型进行对比试验,对比模型包括Fine Tuning(针对跨领域数据进行微调)和Joint Training(各领域数据联合训练)这2种经典的跨领域诊断算法。3种模型均以数据集1训练原始模型,数据集2用于增量学习。试验结果如图11所示。
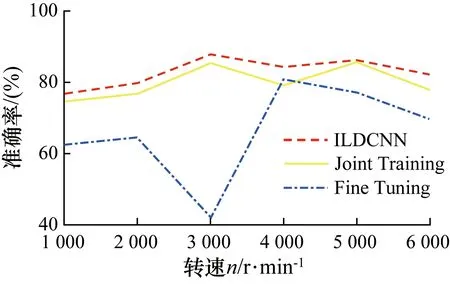
图11 模型对比试验图Fig.11 Model comparison test chart
由图11可知,Fine Tuning总体准确率均较低且在数据集1上的表现极差,这是由于Fine Tuning只针对新领域数据(即数据集2)进行优化;Joint Training在各个转速下的准确率均处于80%左右,且对数据集1有较好诊断能力,这是由于Joint Training将数据集1、2的所有数据均用于优化模型,但数据量巨大,因此训练耗时长,且该方法优化模型时需要所有原始数据,既不方便也不符合大数据时代的发展;ILDCNN模型达到与Joint Training相似的准确率,但该模型仅需数据集2和部分数据集1,将训练用时缩短近1/6,随着模型优化次数增多,其优势将远远大于Joint Training。
对比ILDCNN模型与传统时频域诊断方法的优劣,得出如下分析:时域分析法在机床振动信号有明显特征时可识别故障,但由于随机信号混杂,准确率往往较低。而轴承故障更是难以从时域中分析,通常使用频域分析[17],因此时域分析法不适合机床故障诊断领域。频域分析法在机床故障领域应用广泛,其诊断准确率与ILDCNN模型接近,但该方法仅适合已知故障类别的判断,无法对复合故障等未知故障进行诊断[18]。综上,机床故障诊断模型需满足明确分类故障类别、可诊断未知故障等条件,而ILDCNN模型满足上述要求,体现ILDCNN模型在故障诊断领域的优势。
5 结 论
ILDCNN模型针对跨转速领域中无法识别的未知故障采用增量学习的方式,对比传统方法做了以下优化:1)利用Batch Normalization算法加速了训练过程;2)利用增量学习实现对教师模型的知识迁移和对跨转速数据的特征学习,使得ILDCNN模型在不同转速下的准确率均处于76.49%~86.09%,相比增量学习前提高约22%。
ILDCNN模型不仅各方面优于传统时频域诊断方法,且与Fine Tuning和Joint Training两种跨领域算法相比,提高了跨转速故障诊断的准确率,缩短了训练用时,为大数据下的故障诊断模型提供新思路。
