中国内地分区年用水总量预测模型研究
2022-12-18周宇茗陈恬玥宋松柏
周宇茗, 陈恬玥, 郭 青, 宋松柏,2
(1.西北农林科技大学 水利与建筑工程学院, 陕西 杨凌 712100; 2.西北农林科技大学旱区农业水土工程教育部重点实验室, 陕西 杨凌 712100)
1 研究背景
近年来,全球气候变暖影响不断加剧,各国都在为可持续发展而蓄力,我国为实现碳达峰、碳中和的“双碳”目标也必将向清洁能源高效利用转型。水资源作为重要的绿色能源,在过去经济快速发展过程中却普遍存在被污染和浪费的现象,尤其是在用水阶段,缺乏节水意识引导、定量用水制度规范以及用水现状实时监管等,因而亟需对用水总量进行较为精准的预测,以期为我国水资源规划和管理以及调整用水结构等决策提供支撑。
目前,我国对用水量的研究涉及水量统计调查的差异分析、用水实时监测方法修正、用水结构成因分析等[1-7],而用水量预测一直是研究的热点,其中包括从用水量变化驱动因素的角度进行趋势规律定性分析[8-9],例如,刘晶等[10]采用Mann-Kendall法揭示了我国10个水资源一级区的水资源量及用水总量的变化规律;赵勇等[11]对全国358个地级行政区的用水总量增长趋势进行了研究并得到用水极限峰值及发生时间。其次包括基于不同理论模型的定量估计,较为成熟的方法有定额法、时间序列法、回归分析法、灰色GM(1,1)模型法、神经网络法及系统动力学法等,各种方法均取得了一定的研究成果[12-13],例如,何靖等[13]通过建立灰色系统,对陕西省农业、工业、生活和生态用水总量进行了预测。但目前更为常见的是为提高预测精度而对单一模型组合升级后进行用水量预测[14-20],包括分数阶灰色幂次模型、灰色马尔科夫和非线性灰色贝努利模型等。由于大尺度范围内用水量数据汇总的工作量较大,在预测模型的优选方面,则较多为小区域范围的研究[21-22],例如,白鹏等[23]基于京津冀地区年用水总量数据分别采用自回归模型法、灰色ANN法和年增长率法3种预测方法进行了预测及对比;杨建强等[24]通过建立ARMA、GM(1,1)、ES-GM(1,1)和ES-ARMA模型对酒泉市用水总量进行了预测。国外对于用水量预测研究起步较早,早期研究内容多为中短期用水预测的基础算法分析和模型建构[25-27],在此基础上随着技术的发展不断提出了新模型并进行对比,例如Antunes等[28]基于葡萄牙两个水务公司的实测数据建立了ANN、ARMA、支持向量机等模型进行预测和结果对比。当今依托发达的卫星遥感技术,各地区的水文模型及相关统计参数日臻完备,气象、农业、自然资源数据库系统也逐渐成熟,已有研究基于BESS-STAIR数据和应用卫星数据模型可完成对全球农业用水量的精准预测。
目前我国在大尺度用水量预测研究方面,既缺少定量预估,又缺乏不同模型的对比分析。本文基于ARMA、GM(1,1)、BP神经网络3种模型,分别从省级行政区划、流域、地理大区3种尺度建立用水总量预测模型,得到预测值并进行模型优选,再统计出中国内地各分区用水量最优预测模型种类的数量,以期寻找出其随地理空间分布变化是否具有一定区域普遍适用性的规律,为各地区不同用水预测模型的组合创新提供参考,以提高用水预测精度,同时也为我国用水量数据的统一规范和智慧水务互联管理提供依据,减少由各地区用水统计差异而造成的误差,从而更加精准地制定用水制度,有利于节水型城市建设和国家能源结构转型。
2 数据来源与研究方法
2.1 研究区概况与数据来源
我国水资源开发利用工程多样,供用水结构复杂,水管理部门繁多,在进行水资源用水评价时往往从不同角度出发进行分区。本文将在中国内地范围按照省级行政区、水文地理(流域)大区和自然地理大区3种尺度划分,分别建立年用水总量预测模型。
全国用水总量数据主要来源为《中国水资源公报》(不包括香港、澳门地区和台湾省的相关数据),具有一定的科学性和权威性。分别选用1998-2017年用水总量数据为训练期,2018-2020年用水总量数据为验证期,建立省级行政区尺度年用水总量预测模型;流域和地理大区尺度年用水总量预测模型则选择1997-2017年用水总量数据为训练期,2018-2020年用水总量数据为验证期。在建立预测模型前,通过序列组分识别和提取处理,满足序列平稳性的要求。
2.2 研究方法
2.2.1 自回归滑动平均模型ARMA 自回归滑动平均(autoregressive moving average,ARMA)模型[18]是描述平稳随机水文序列的一类最主要的线性平稳模型,可根据前后数据相关关系来建立回归方程。该模型具有两个优点:(1)能够揭示平稳随机水文序列的一些主要统计特性(如变差系数、自相关系数等)。(2)模型参数具有一定的物理意义。ARMA模型的一般形式为:
xt=u+φ1(xt-1-u)+φ2(xt-2-u)+…+
φp(xt-p-u)+εt-θ1εt-1-…-θqεt-q
(1)
式中:xt为平稳、正态、零均值的时间序列;u为常数项;φ1,φ2,…,φp为自回归系数;p为自回归阶数;θ1,θ2,…,θq为滑动平均系数;q为滑动平均阶数;εt为独立的误差项。
ARMA模型的建立一般分为以下6个步骤:(1)组分识别。采用相应的方法对序列的趋势、跳跃及周期成分进行识别并排除,获得平稳随机序列。(2)选择模型类型。绘制序列的自相关、偏相关函数图,进行截尾性判定分析。(3)识别模型形式。给定p、q的上限值,分别计算AIC(p,q)或BIC(p,q),确定模型阶数。(4)估计模型参数。依据Yule-Walker方程、矩法等方法计算模型参数。(5)模型检验。采用综合自相关系数法进行检验,分析残差随机变量的独立性。(6)模型适用性分析。采用长序列、短序列法分析所建立模型是否能保持实测序列的主要统计特性。
2.2.2 灰色GM(1,1)模型 灰色预测[10]是利用各因素之间的关联性估计其趋势的相异程度,其关键在于对原始数据做相加、累减或平均形成近似的指数规律后再建立灰色GM(1,1)模型。灰色GM(1,1)模型是指应用于中短序列且仅包含一个变数的一阶变量微分方程模型,在水文预报中作为基于长时间序列的中期或短期预报。一般选择后验差检验法测试模型的可靠性,并利用最小误差概率与后验差的比值C判断模型的正确性,分别以C=0.35、0.50、0.65为分界点将精度划分为优、良、合格及不合格4个等级。
2.2.3 BP神经网络模型 人工神经网络(artificial neural network,ANN)模型是模仿动物神经反馈机制进行信息处理, 能够自学习、自适应的一种数学模型。其工作原理是基于人工神经元,将输入数据经过激活函数处理得到输出数据,常用的激活函数包括线性函数、S形函数、双极S形函数等,训练方法包括梯度下降法、量化共轭梯度法、拟牛顿算法和一步正割算法等。根据输出值的检验精度调整激活函数类型,激活函数的选择耗时长、影响深,是神经网络预测过程中的重点。
神经网络由大量神经元构成,其结构包括前馈、反馈神经网络和自组织网络3种,工作模式为有、无导师学习两大类,BP(back propagation)神经网络属于前馈有导师学习神经网络系统。前馈网络反馈信号在训练中产生,进而在分类时向前传递到输出层。有导师学习算法是将样本原值与真实输出值之差作为调整标准,不断重复操作直到该误差处于满足条件的范围内。这种能学习和存贮大量的激励-响应模式映射关系并不断学习调整连接权的多层前馈网络,是目前普遍应用的神经网络模型之一。
3 结果与分析
3.1 模型预测结果
3.1.1 ARMA模型预测结果 依据ARMA自回归滑动平均模型原理,借助MATLAB进行建模,分别得到省级行政区划、流域、地理大区3种尺度下的ARMA模型系数,见表1、2。3种不同尺度下预测模型结果表明,ARMA(p,q)模型占比较大,只有少数省市为ARMA(p)模型。

表1 部分省级行政区ARMA模型参数
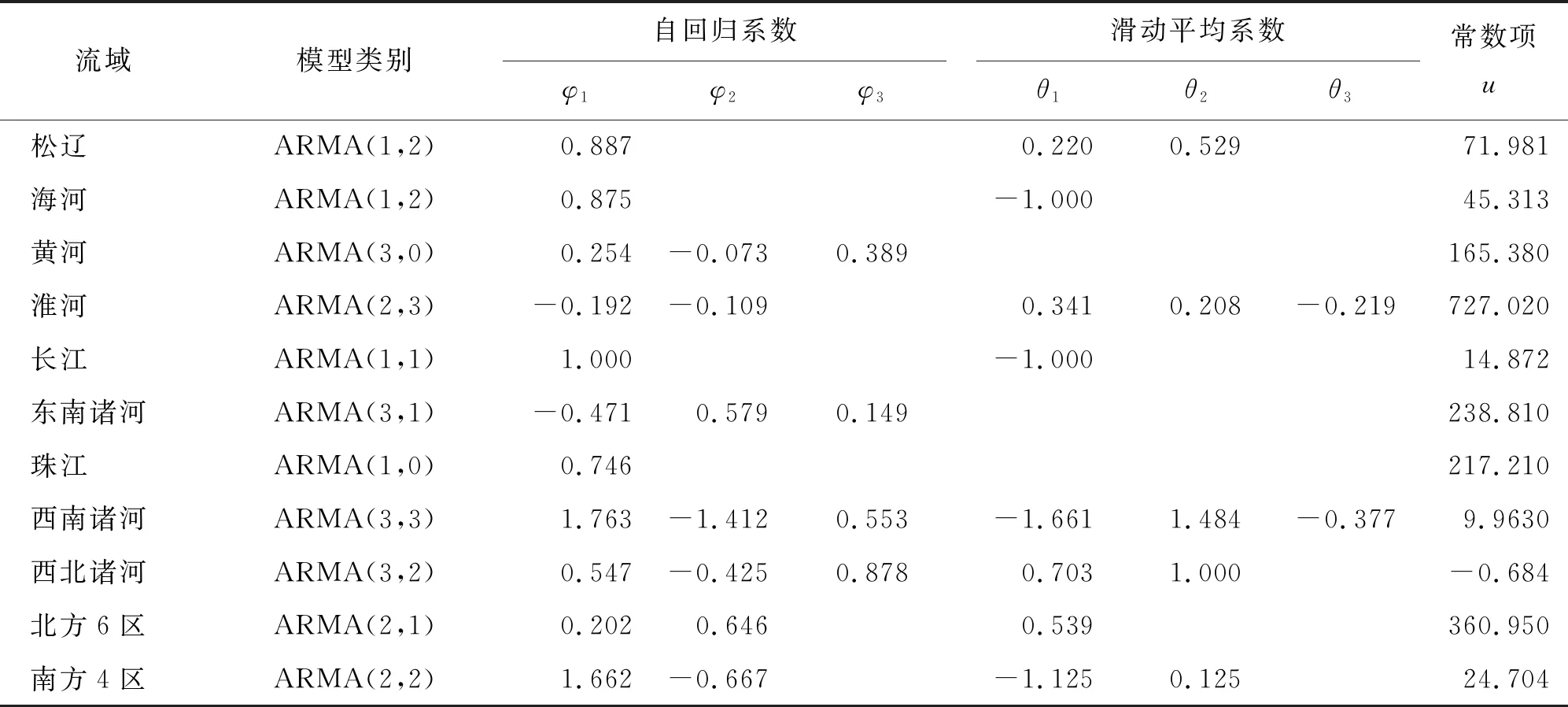
表2 各流域及地理大区ARMA模型系数
3.1.2 灰色GM(1,1)模型预测结果 根据灰色GM(1,1)原理,经计算分别得到省级行政区划、流域、地理大区3种尺度下的灰色GM(1,1)模型系数a、b及后验差比值C,见表3、4。由表3、4可知,在全国内地31个省级行政区中,仅河北省年用水总量的拟合精度达到了优,后验差比值恰为0.35;内蒙古、安徽、山西、陕西和新疆5个省级行政区模拟精度为良,后验差比值分别为0.36,0.43,0.46,0.36,0.38;山东、江西、湖北、湖南等10个省级行政区模拟精度为合格;云南、河南等15个省级行政区模拟精度均为不合格。在九大流域中,长江、西北诸河流域的模拟精度为良,后验差比值分别为0.46、0.36;松辽流域后验差比值为0.59,模拟精度为合格;其他流域模拟精度均为不合格。南方4区后验差比值为0.41,模拟精度为良;北方6区后验差比值为0.63,模拟精度为合格。上述结果表明,虽然灰色GM(1,1)模型能够对一些地区用水总量序列进行预测,但并不具有普遍适用性,仍然存在大量精度不符合标准的情况,这是由于灰色GM(1,1)模型的适用性和用水总量序列自身规律难以拟合造成的。
3.1.3 BP神经网络模型预测结果 依据BP神经网络模型原理,借助MATLAB软件,先通过mapminmax函数将输入值特征化归一以便识别处理,再应用newff函数建立用水总量预测BP神经网络模型,可分别得到省级行政区划、流域、地理大区3种尺度下神经网络模型的预测评价结果,如表5所示。由表5可以看出,所有尺度下的预测平均相对误差均在30%以内;流域尺度下珠江和东南诸河的预测误差相对较大,分别为11.46%、29.23%,其他流域的预测平均相对误差则在10%以下;省级行政区划尺度下,广东、四川、江苏和吉林4个省级行政区的预测误差相对较大,分别为9.16%、7.38%、10.33%、8.16%,其他省级行政区的预测平均相对误差基本在5%左右。可见BP神经网络模型对用水总量预测的适用性较好,能够应用于中长期用水量预测。

表3 各省级行政区灰色GM(1,1)模型构建结果
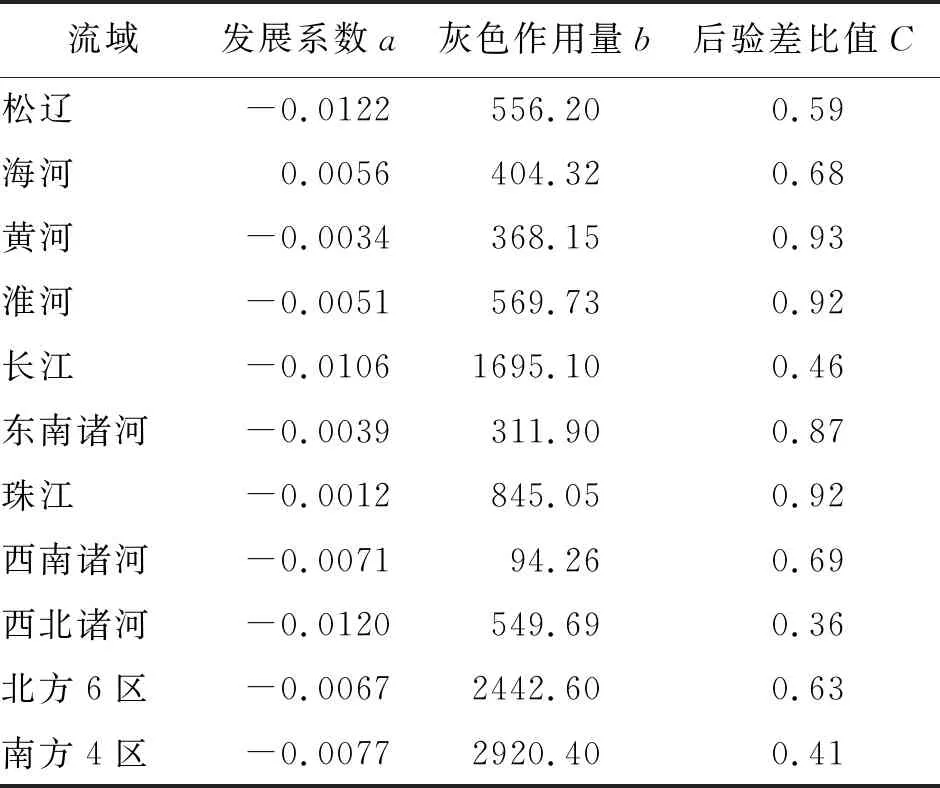
表4 流域及地理大区灰色GM(1,1)模型构建结果
3.2 3种模型优选
对于上述3种模型,选择2018-2020年用水总量数据进行省级行政区划、流域、地理大区3种尺度的年用水总量预测结果验证,用平均绝对百分比误差(mean absolute percentage error,MAPE)判断预测精度,择出最优模型。图1为3个尺度中较为典型的区域的年用水总量不同模型预测结果与实际值对比,从图1中可以看出,不同尺度下的最优模型均与实际用水总量的年际波动变化一致;灰色GM(1,1)模型与ARMA模型的拟合差异不明显,在用水总量变化为单一线性分布时,灰色GM(1,1)模型优势较为明显,而当变化为非线性时,ARMA模型优势更显著;BP神经网络模型的拟合程度不太稳定,这可能与其激活函数的选择有关。模型在训练期的拟合度较好,而在验证期则会表现出显著差异,以云南省为例(图1(b)),训练期BP神经网络和ARMA模型的预测效果均明显优于灰色GM(1,1)模型,验证期ARMA模型优势依旧,BP神经网络模型则表现出偏离。因而训练期拟合结果不能反映出模型的真实预测水平,应以验证期相对误差作为模型优选标准。

表5 省级行政区划、流域及地理大区BP神经网络模型预测结果平均相对误差 %

图1 3种尺度中典型区域年用水总量的不同模型预测结果与实际值对比
因数据较多,本文选取部分省份、流域及地理大区2018-2020年3种模型的年用水总量预测结果列于表6,并计算出预测值与实际值的相对误差(RE)及平均绝对百分比误差(MAPE)进行对比。由表6可以看出,省级行政区划尺度下,ARMA、灰色GM(1,1)和BP神经网络3种模型对辽宁省年用水总量预测值的MAPE分别为0.52%、9.31%、1.59%,优选模型为ARMA模型;对河北省年用水总量预测值的MAPE分别为0.95%、1.42%、0.77%,优选模型为BP神经网络模型;对云南省年用水总量预测值的MAPE分别为2.78%、1.88%、3.21%,优选模型为灰色GM(1,1)模型。流域尺度下,3种模型对西北诸河年用水总量预测值的MAPE分别为2.06%、4.36%、2.80%,优选模型为ARMA模型;对长江流域年用水总量预测值的MAPE分别为3.17%、2.47%、1.05%,优选模型为BP神经网络模型;对黄河流域年用水总量预测值的MAPE分别为1.30%、0.73%、2.81%,优选模型为灰色GM(1,1)模型。地理大区尺度下,对北方6区年用水总量预测值的MAPE分别为2.46%、2.69%、2.03%,优选模型为BP神经网络模型;对南方4区年用水总量预测值的MAPE分别为5.61%、3.63%、3.97%,优选模型为灰色GM(1,1)模型。上述结果表明,3种模型在同一尺度下对不同区域的年用水总量预测误差均有所不同。

表6 3种模型对部分省份、流域及地理大区2018-2020年的年用水总量预测结果对比
对研究范围内3种尺度下的最优预测模型进行数学统计可知:在省级行政区划尺度下,陕西省、北京市、广东省等9个区域的年用水总量最优预测模型为ARMA模型;云南省、河南省、天津市等6个区域的最优预测模型为灰色GM(1,1)模型;山东省、青海省、安徽省等16个区域的最优预测模型为BP神经网络模型。在流域尺度下,松辽、海河等5个流域的年用水总量最优预测模型为ARMA模型;黄河、淮河和珠江3个流域的最优预测模型为灰色GM(1,1)模型;长江流域的最优预测模型为BP神经网络模型。在地理大区尺度下,北方6区的年用水总量最优预测模型为BP神经网络模型;南方4区的最优预测模型为灰色GM(1,1)模型。
3.3 中国内地分区年用水总量预测
从省级行政区划尺度出发,根据选取的各行政区年用水总量最优预测模型,分别对2021-2025年的年用水总量进行预测,结果如图2所示。
由图2可见,最优模型为ARMA的9个省级行政区中(图2(a)),2021-2025年浙江省年用水总量的减少趋势相对明显,年用水总量平均减少速率为5.88×108m3/a;辽宁省年用水总量呈小幅增加趋势,平均增加速率为1.87×108m3/a;其余各省(自治区)年用水规模基本持平。最优模型为灰色GM(1,1)模型的6个省级行政区中(图2(b)),江苏省的年用水总量增加幅度相对较大,平均增大速率为8.27×108m3/a,增速较快,该省2025年年用水总量预测值为653.3×108m3。最优模型为BP神经网络模型的16个省级行政区中(图2(c)、2(d)),2021-2025年甘肃、安徽、湖南、福建、山西、海南和贵州7个省份的年用水总量基本不变;广西壮族自治区、宁夏回族自治区和黑龙江省3个省份(自治区)年用水总量均呈现先减少后增大的趋势,由减少到增大变化的转折点年份分别为2023、2022和2024年,特别注意到,黑龙江省2025年的用水总量增幅较大,比2024年增加了62.95×108m3;新疆维吾尔自治区年用水总量在2021和2022年基本不变, 2023和2024年连续减少,2025年与2024年又基本持平,2022-2025年的年用水总量平均减少速率为28.11×108m3/a;青海省年用水总量呈连续小幅波动变化状态。

图2 中国内地各省级行政区2021-2025年年用水总量预测结果(以最优预测模型分类)
4 讨 论
本研究对中国内地不同尺度区域年用水总量最优预测模型进行分析,可以得到在数量上的统计值。其中,省级行政区划尺度下最优预测模型中占比最大的为BP神经网络模型,流域尺度下占比最大的为ARMA模型,地理大区尺度下北方6区最优预测模型为BP神经网络模型,南方4区最优预测模型为灰色GM(1,1)模型,而最优预测模型在地理空间分布上没有显示出一定的规律性,可能是因为本文选取的3种预测模型均为时间序列模型,忽略了除用水量外的其他因素影响。在已有的其他小尺度区域用水量最优预测模型的研究中,同时考虑到了结构分析法,针对特定区域的用水量与其影响因素进行了相关分析,而大尺度区域的用水量预测多为农业用水量预测,是基于卫星遥感数据综合多种水文要素得到的。
虽然从本研究选用的用水量预测模型中没有发现一定的普适规律,但各尺度下模型预测值的相对误差均较为合理,具有一定推广价值。与以往研究相比,如Meng等[30]利用灰色模型对我国内地31个省(自治区)的工业、农业、生活及总用水量进行预测,Meng等[31]考虑区域GDP、人口与用水量关系建立AGMC(1,N)模型对我国内地31个省(自治区)用水量进行预测,本研究还涉及了流域和地理大区尺度,并选用3种模型进行了优选。
综合以上方面,可考虑结合其他相关因素(如经济发展、人口增长等)选择适当模型,对3种尺度下用水量进行预测,以完善本研究结果。
5 结 论
(1)依据自回归滑动平均模型ARMA、灰色GM(1,1)模型及BP神经网络模型原理,利用各省级行政区划、流域、地理大区尺度1997-2020年的年用水总量,得到各模型的相应参数。
(2)对3种尺度下3种用水量预测模型进行优选并得到数量统计结果:在省级行政区划尺度下,陕西省、北京市、广东省等9个区域的年用水总量最优预测模型为ARMA模型,云南省、河南省、天津市等6个区域的最优预测模型为灰色GM(1,1)模型,山东省、青海省、安徽省等16个区域的最优预测模型为BP神经网络模型;在流域尺度下,松辽、海河等5个流域的年用水总量最优预测模型为ARMA模型,黄河、淮河和珠江3个流域的最优预测模型为灰色GM(1,1)模型,长江流域的最优预测模型为BP神经网络模型;在地理大区尺度下,北方6区的年用水总量最优预测模型为BP神经网络模型,南方4区的最优预测模型为灰色GM(1,1)模型。
(3)应用选出的最优模型,预测出2021-2025年各省级行政区的用水总量及其变化趋势,预测期内各省级行政区用水总量总体保持稳定。
