基于改进鲸鱼算法优化Bi-LSTM的脱硝系统NOx建模
2022-12-17金秀章李阳峰
姚 宁, 金秀章, 李阳峰
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引 言
氮氧化物(NOx)是造成大气污染的主要污染物之一[1]。由于我国针对大气污染物的排放标准日渐严格和超低排放国家专项行动的实施,对NOx的排放有了更加严格的要求[2]。我国燃煤电站目前大多采用了利用氨催化的选择性催化还原技术(SCR),其脱硝效率可达到90%以上,但是由于锅炉运行工况极为复杂,反应器入口NOx含量难以准确测量,导致SCR反应器通常使用较大的喷氨量以使氮氧化物完全反应,造成了巨大的成本消耗,存在氨逃逸率较高的问题。因此,建立精准的SCR反应器入口NOx模型,是一种降低电厂运行成本,提高脱硝效率的有效办法。
燃烧系统具有迟延、大惯性、非线性等特点,且DCS监测系统采集的数据又具有一定的耦合性、冗余性和噪声,因此对入口NOx浓度的建模难以通过单纯机理分析的方式进行。随着人工智能时代的发展,诸多先进的建模方法被提出。刘岳等[3]提出了基于改进粒子群优化LSTM参数(MPSO-LSTM)的预测模型,提高了预测模型的精度。王印松等[4]建立了Elastic Net方法结合最小二乘支持向量机(Elastic Net-LSSVM)的SCR入口NOx软测量模型,通过特征降维的方式,降低了模型复杂度。钱虹等[5]利用随机森林回归(RF)的算法建立了出口NOx的预测模型,但其未考虑实际系统存在的迟延性等问题。余印振等[6]建立了基于卷积神经网络和支持向量机的预测模型,通过对火焰图像进行卷积操作进行特征提取并用SVM进行预测,但是火焰图像的获取成本较高,并不能大规模应用到燃烧系统中。
输入特征的选取是影响建模精度的重要因素。谢锐彪[7]等使用主成分分析的方式对辅助变量降维,减小了输入特征的维数。李阳等[8]利用弹性网进行变量选择,降低了输入特征数量,提高了模型的性能。
综上所述,本文提出一种基于改进鲸鱼算法优化Bi-LSTM神经网络的SCR入口NOx浓度预测模型。利用LightGBM对辅助变量进行特征选择和迟延时间计算。以每个变量在决策过程中的贡献决定其重要性,选择出重要性最高的变量作为输入变量。建立加入Relu层的BI-LSTM预测模型,从前向和后向两个方向提取深度特征,并使用改进的鲸鱼优化算法对模型的超参数进行寻优。将模型预测结果与传统Bi-LSTM、LSTM、LightGBM等模型进行对比,验证该模型准确率。
1 输入特征处理
1.1 基于LightGBM的特征选择
本文使用了某600 WM电厂DCS提供的间隔10s采样的20000组数据,并从中随机截取6 000组作为模型的训练集。该电厂脱硝系统采用SCR技术,并且NOx测点分为AB两侧,其变化趋势保持一致,本文采用B侧测点进行建模。通过机理分析,初步选取了锅炉总风量、锅炉一次风量、锅炉二次风量、机组发电功率等13个初始特征。由于入口NOx浓度还受到时间的影响,所以加入上一采样时刻的NOx浓度作为一个输入特征[3]。
从DCS得到样本特征复杂多样,即使通过机理分析得到了与SCR入口NOx含量有关系的变量,选择后的变量之间依然存在很高的冗余,而多余的样本特征会提高模型的复杂性,降低模型的运算速度,因此需要通过数学运算筛选出与输出相关性最高的变量。本文采用决策树算法对样本特征进行重要性排序。
LightGBM是由微软提供的一种boosting集成模型,核心是梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法,并采用直方图算法(Histogram)进行特征分割[9]。与传统决策树算法相比,其训练速度更快、准确率高、占用内存小、可处理大规模数据,更适合做特征选择。其特征重要性计算方式为每个特征在LightGBM建模过程使用的次数。
从原始数据中随机截取连续的2000组数据进行样本特征选择,共截取三次,取平均值作为最终样本特征重要性。图1所示为基于原始LightGBM模型输出的样本特征重要性分布情况。最终选择特征重要性最高的总风量、功率、烟气流量、反应器入口压力、锅炉氧量、引风机出口烟气温度、给煤机瞬时流量、入口烟气温度、上一采样时刻的入口NOx浓度等9个特征作为模型的输入。

图1 样本特征重要性分布Fig. 1 Characteristic importance distribution
1.2 基于最大时间周期的迟延计算
燃烧系统各个输入特征的测点由于管道长度等影响,与SCR入口NOx浓度测点存在较大的迟延,因此设计了一种基于最大时间周期的迟延计算方法。由于燃煤电厂一个燃烧周期最多为600 s[3],因此对样本进行特征选择后,将最大迟延时间设定为600s,选择一个特征,并将其他特征时间步固定,每次将该特征提前一个时间步,利用LightGBM计算其特征重要性,直到提前时间总和达到600s。选取该特征重要性最大的时刻,并将其提前的时间作为该特征与入口NOx浓度之间的迟延时间,将其时间步固定,依次计算其他特征迟延时间,最终实现选取的所有输入特征在时序上的统一。表1为经过选择的特征与入口NOx之间的最佳迟延时间。

表1 各个特征的迟延时间Tab.1 Delay time for each feature
1.3 基于SG滤波的数据降噪
DCS监测系统监测数值由于设备性能和温度湿度的影响容易产生噪声。Savitzky-Golay(SG)滤波算法是一种基于最小二乘原理的滑动窗口多项式平滑算法[10],其特点是在对数据进行滤波平滑的同时,能够确保信号的形状、宽度不变。选择当前时刻前后共2n+1个时刻的观测值,用k-1阶多项式进行曲线拟合。计算公式如下:
(1)
X(2n+1)×1=T(2n+1)×k·Ak×1+E(2n+1)×1
(2)
A=(Ttrans·T)-1·Ttrans·X
(3)
P=T·A=T·(Ttrans·T)-1·Ttrans·X
(4)
(5)
上述公式中,(1)为当前时刻拟合值计算公式;(2)~(5)为滑动窗口内曲线拟合值的计算。图2所示为给煤机瞬时流量和引风机出口烟气温度经过滤波后的数值(n=12,k=3)与DCS监测值的对比结果。

图2 SG滤波降噪结果Fig. 2 Noise reduction results of SG filter
2 基于改进鲸鱼算法优化Bi-LSTM的脱硝系统NOx模型
2.1 Bi-LSTM模型
长短时记忆神经网络(LSTM)是一种特殊的循环神经网络,解决了普通RNN无法长期依赖的问题。LSTM的特点是通过细胞状态实现LSTM细胞间的信息传递,并通过精心设计的门限结构来去除或增加信息到细胞状态,其门控结构包括遗忘门、记忆门和输出门[11]。LSTM的结构如图3所示。
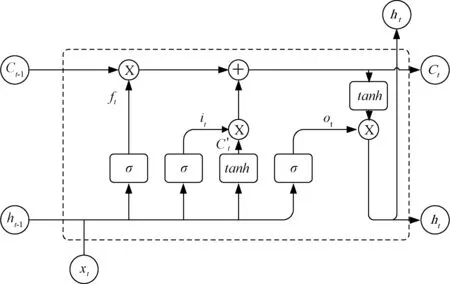
图3 LSTM细胞结构示意图Fig. 3 Schematic drawing of LSTM cell structure
图中,Xt表示细胞这一时刻的输入;Ct表示细胞在t时刻的状态;ht表示细胞t时刻的输出;Ct-1表示细胞t-1时刻的状态;ht-1表示细胞t-1时刻的输出;σ表示激活函数为Sigmoid的全连接层;tanh表示激活函数为Tanh的全连接层。LSTM细胞的输出和状态输出更新过程为式(6)~式(11):
ft=σ(XtWxf+ht-1Whf+bf)
(6)
it=σ(XtWxi+ht-1Whi+bi)
(7)
(8)
ot=σ(XtWxo+ht-1Who+bo)
(9)
(10)
ht=ot⊙tanh(Ct)
(11)
上述公式中:(6)为遗忘门,选择要遗忘的信息,有助于捕捉时间序列中短期的依赖关系;(7)和(8)为更新门,选择要记忆的信息,有助于捕捉时间序列中长期的依赖关系;(10)为细胞状态更新;(9)和(11)为输出的更新;W和b为各个门的权重系数和偏置。LSTM神经网络可以理解为由多个LSTM细胞的链式链接组成一层前向神经网络。LSTM只能提取前向的序列信息,而Bi-LSTM则可以从前向和后向两个方向提取序列信息,获得更多特征。将前向的LSTM网络翻转后就得到了反向的LSTM层,最终t时刻的输出yt由前n个时间步前向的ht和后向的ht共同决定[12]。Bi-LSTM的结构图4所示。本文所建模型使用了2个Bi-LSTM层用以提取深度特征,并在输出层前加入了Relu层,隐藏层细胞数n即输入时间序列长度由优化算法计算。Relu函数可以有效降低计算复杂度,并且不会出现Tanh函数和Sigmoid函数在饱和区产生的梯度消失现象,对防止模型过拟合有一定的作用。本文使用模型结构如图5所示。

图4 Bi-LSTM结构图Fig. 4 Bi-LSTM structural diagram

图5 神经网络的结构Fig. 5 Structure of neural network
2.2 鲸鱼优化算法
在对Bi-LSTM网络进行训练时,为了提高模型准确率,需要对初始学习率和输入时间序列的长度参数进行优化。鲸鱼算法是一种模拟座头鲸捕食行为而发展来的群智能优化算法[15],与其他群智能算法相比,其没有需要优化的初始参数。该算法主要包括搜索猎物和气泡网攻击两个阶段。
2.2.1 搜索猎物阶段
设鲸鱼种群规模为N,每个鲸鱼的位置代表一个可行解X,在随机搜索阶段,每个鲸鱼个体根据彼此的位置来更新下一代的位置,算法具有一定的全局寻优性能。根据第i次迭代的位置,当∣A∣>1时,对第i+1次的位置进行更新,其更新公式如下:
x(i+1)=xrand(i)-A|Cxrand(i)-x(i)|
(12)
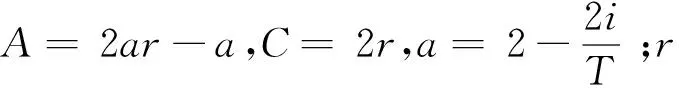
2.2.2 气泡网攻击
本阶段鲸鱼群体通过螺旋向上的形式缩小包围圈并进行捕食行为。过程主要包含收缩包围和螺旋更新两部分,每一次迭代每个个体以50%的概率决定进行螺旋更新或是收缩包围。更新公式如下:
(13)
式中:b为对数螺旋形状常数,本文取b=1;p为[0,1]内的随机数;l为[-1,1]内的随机数;xbest(i)为种群最优个体位置。
2.3 改进的鲸鱼优化算法
在WOA算法中,系数A是影响种群全局探索和局部收敛的主要参数,由收敛因子a来确定。通过式(15)可以得知a是线性递减的,其收敛速度较慢,因此提出一种非线性递减因子a,其计算公式如下:
(14)
图6为递减因子a在迭代次数为200次的收敛趋势,从图中可以看出,在搜索猎物阶段种群的搜索速度更快,能够快速进行全局搜索;在气泡网攻击阶段搜索更加仔细,对局部搜索更加有利。

图6 递减因子下降趋势Fig. 6 Decishing factor trends
2.4 基于IWOA-Bi-LSTM的预测模型
将所选数据进行输入特征处理后进行归一化,并将其输入到建立的IWOA-Bi-LSTM模型中进行训练。图7 为总体算法流程。
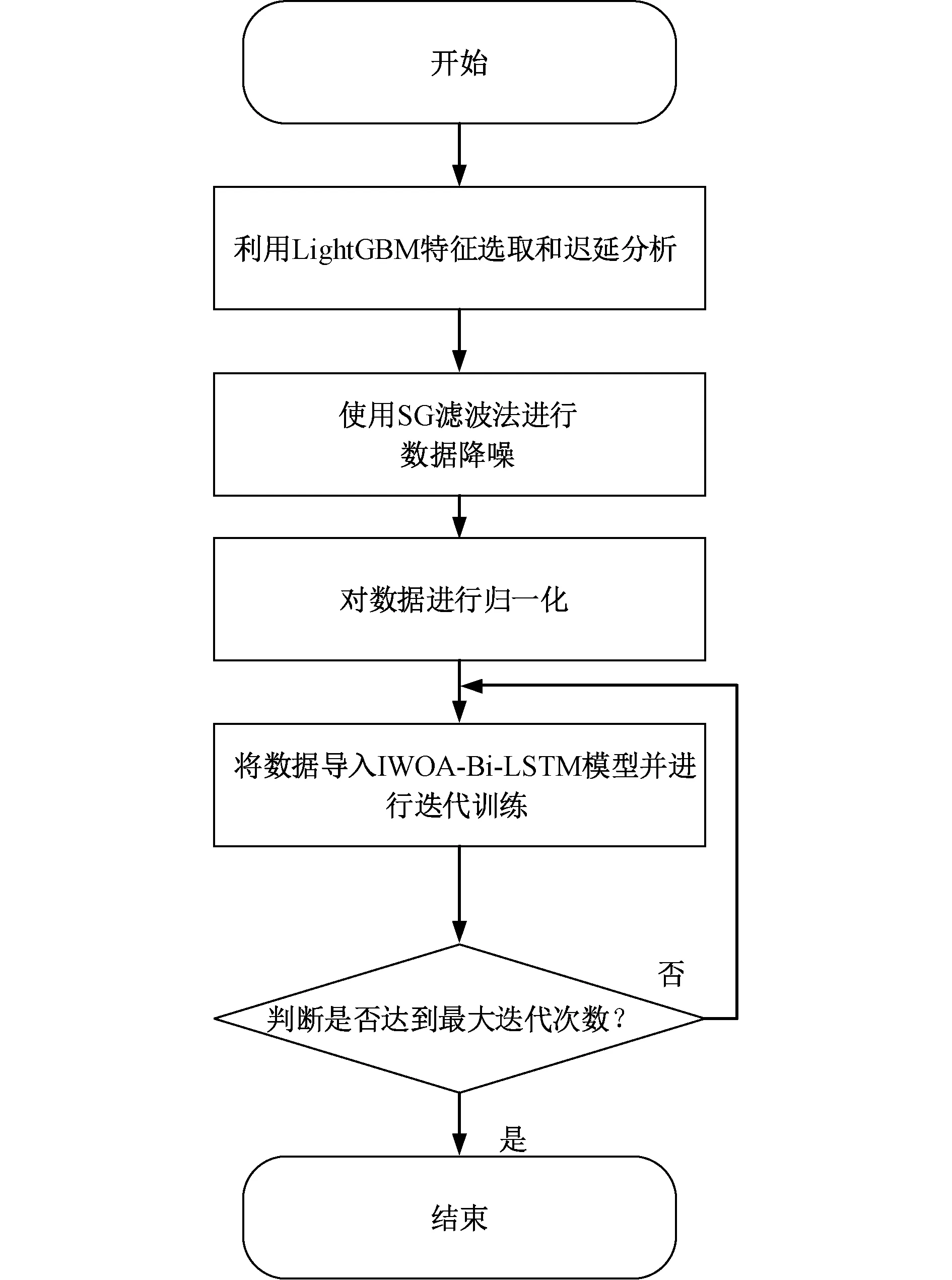
图7 基于IWOA-Bi-LSTM的算法流程Fig. 7 Algorithmic process based on IWOA-Bi-LSTM
3 模型建立和结果分析
3.1 建模评价指标
为了对模型的准确度进行分析,采用均方根误差(Root Mean Squared Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、平均绝对误差(Mean Absolute Err,MAE)作为模型测试集的评价指标,三种评价指标的数值越小,模型的精确度越高。
3.2 模型参数优化
Bi-LSTM的隐藏层参数采用自适应矩估计(Adaptive Moment Estimation,Adam)的方法进行梯度迭代。设置最小训练批次为100,最大训练轮数为300,训练模型有初始学习率和输入时间序列长度两个超参数通过改进的鲸鱼优化算法进行优化,将其初始范围分别设定为[0.001,0.1]和[20,100],然后进行迭代优化,寻找最优超参数。设置最大迭代次数为200,得到最优初始学习率为0.009,最优输入时间序列长度为70。
3.3 模型预测结果分析
为了验证模型的效果,从特征处理后的数据集中随机截取除训练集外长度为1500的数据作为测试集输入模型,并将其运行5次并计算评价指标的平均值作为最终的训练结果。
3.3.1 输入特征处理对模型效果的影响
将进行过特征处理的样本与未经过特征处理的初始样本分别输入模型进行训练和预测,预测结果及其预测精度如图8和表2所示。

图8 特征处理对模型预测结果的影响Fig. 8 Effect of feature processing on model prediction results

表2 特征处理对模型预测结果影响的评价指标
对比图8以及表2可以看出,使用原始数据进行建模,预测值和真实值之间存在明显偏差,且偏差较大。对原始数据进行特征选择和迟延计算后,学习能力有所提高,RMSE降低了7%,MAPE降低了14.7%,MAE降低了14.5%,精确度得到了提升,说明冗余变量和迟延时间的存在对模型的精度有较大的影响。预测值在入口NOx浓度较为稳定时能够跟踪真实值,但依然存在一定的偏差,且在序列前200组入口NOx波动较大的时候不能准确的跟踪真实值。对经过特征处理后的数据进行滤波后,预测值在稳定阶段和波动阶段都能够准确地跟踪入口NOx浓度真实值和真实值的变化,准确度相较基于原始数据的模型提升了12.53%,且平均绝对误差降低了20%,说明噪声也对模型的精度具有一定的影响。对输入特征进行特征处理和降噪能够有效提升模型的准确度。
3.3.2 不同模型对预测效果的影响
将加入Relu层的Bi-LSTM模型与传统Bi-LSTM模型、LSTM模型、LightGBM模型进行对比。模型的输入采用经过特征处理的数据,Bi-LSTM模型的层数设为2层,LSTM模型层数设为2层,传统Bi-LSTM模型和LSTM模型的超参数寻优方法为改进的鲸鱼优化算法,LightGBM模型采用网格搜索的方式进行寻优。预测结果和预测精度如图9和表3所示。

图9 不同模型对预测效果的影响Fig. 9 Effect of different models on prediction effects
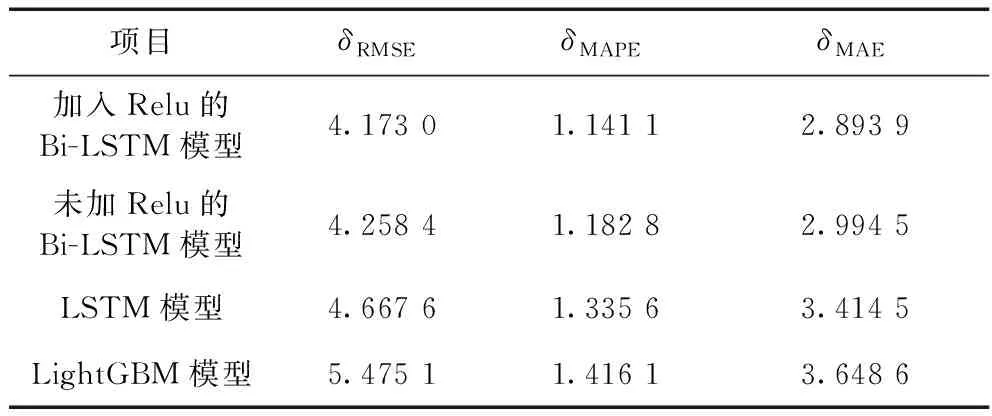
表3 不同模型对预测效果影响的评价指标
如图9和表3所示,对比两种Bi-LSTM模型,加入了Relu层的模型在快速变化的区域能够更好的跟踪NOx真实值的变化,与未加Relu的模型相比,其RMSE降低了2%,MAPE降低了3%,MAE降低了3%,具有更高的准确度,并能够降低模型复杂度以及防止模型出现过拟合现象。LSTM模型能够跟踪入口NOx的变化趋势,但是存在一定的偏差。LightGBM模型在稳定的区域内能够准确跟踪变化趋势,但是在波动较大的时间段内无法跟踪真实值的变化。
综上所述,基于IWOA-Bi-LSTM预测模型相比于传统的Bi-LSTM模型、LSTM模型和LightGBM模型具有更强的学习能力、预测精度和泛化能力。
4 结 论
针对电厂SCR脱硝系统入口NOx测量难度大的问题,提出一种基于IWOA-Bi-LSTM的预测模型。用LightGBM对现场数据进行特征选择和迟延计算并使用SG滤波进行降噪,在Bi-LSTM输出层前加入Relu层,防止模型过拟合并提高模型准确度。针对模型超参数调整困难的问题,利用鲸鱼优化算法进行寻优并对其改进,优化了种群搜索能力,进一步提高了模型的预测精度。基于电厂运行数据的仿真结果表明,与传统LSTM模型和LightGBM模型相比,IWOA-Bi-LSTM模型的预测误差更小,精度更高,性能有所提升。除此之外,针对被剔除的变量,其对入口NOx的影响在实际应用中不可直接忽视,后面需考虑如何在不剃除冗余变量的前提下提升模型的准确度和泛化能力。
