基于生物信息学的胃癌早期诊断预测模型研究
2022-12-17赵博璇李建伟
赵博璇,刘 明,李建伟
(河北工业大学 人工智能与数据科学学院,天津 300401)
胃癌是一种极为常见的恶性肿瘤,其发生于胃粘膜上皮细胞,在全球癌症死亡率排名中位居第二[1]。在我国,胃癌拥有较高的发病率和死亡率,位列我国恶性肿瘤的第三位,且全球新发胃癌病例中约有一半来自中国[2-3]。胃癌患者的早期症状不显著,难以引起人们重视,只有当肿瘤细胞增殖影响胃部正常功能时,患者才出现较为明显的症状。根据胃癌早期发病机制建立诊断预测模型,及早发现胃癌患者,可使患者避免错过早期治疗的最佳时机,辅以有效治疗可以极大提升胃癌患者的五年生存率。本研究通过生物信息学技术对胃癌基因表达数据进行特征处理,采用机器学习算法构建胃癌早期诊断预测模型,为胃癌早期诊断的研究提供了新思路和新方法。
随着高通量生物技术和生物信息学的迅猛发展,不断有学者根据人类基因表达谱数据对胃癌开展各种层面的研究。JIANG K等通过对GEO(Gene Expression Omnibus,https://www.ncbi.nlm.nih.gov/geo)数据库中的 GSE29272数据集进行研究,发现了5个可能代表胃癌的新型预后生物标志物(ASPN、COL1A1、FN1、VCAN和MUC5AC)[4]。Chen J等人根据TCGA(The Cancer Genome Atlas,TCGA,https://portal.gdc.cancer.gov)数据库中胃癌患者的遗传和临床数据,通过构建加权基因共表达网络分析,得到7个影响胃癌患者生存的基因(PDGFRB、COL8A1、EFEMP2、FBN1、EMILIN1、FSTL1 和KIRREL)[5]。对人类胃癌组学数据的探索可为胃癌的预防、治疗和诊断提供强有力的帮助。本研究的工作流程主要包括数据下载与处理、胃癌早期诊断关键基因的筛选和诊断预测模型的构建3个部分。其中关键基因的筛选通过差异基因分析、PPI网络分析和诊断效能分析等3个步骤完成,并对差异基因进行GO和KEGG富集分析。
1 数据与处理
1.1 数据描述与下载
TCGA即癌症基因组图谱数据库,它从创建至今已收录了30多种类型癌症的基因组学数据,存储了丰富的与癌症相关的各类信息[6]。TCGA 数据库中胃癌基因表达数据由二代测序技术(RNA-seq)获得,用户利用官方下载工具gdc-client,可下载基因表达丰度为read count值形式的原始表达数据,并可同时获得相关的临床数据。GTEx(Genotype-Tissue Expression,GTEx,https://gtexportal.org/home)名为基因型-组织表达数据库。截至2015年底,它已包括大约900名尸体捐赠者的大量尸检样本数据,涵盖50多个组织[7]。
在本研究中,从TCGA数据库中筛选得到201个胃癌样本,其中正常组织 32个,早期胃癌组织样本为169个(56例癌症I期,113例癌症II期)。TCGA数据库记录的正常组织测序结果较少,大量病人的正常组织测序数据并未包含在内,如胃癌正常组织样本量与癌组织早期样本量相差近5倍。为增加正常组织样本量,本研究通过GTEx数据库官网下载原始表达矩阵文件和样本信息文件,根据样本信息从表达矩阵中提取出174个正常胃部组织的基因表达数据。
1.2 数据预处理
对获得的TCGA和GTEx的胃癌原始表达数据集进行预处理,通过筛选同时存在于两个数据库的基因,最终得到二者的联合数据集。该数据集共包含375个样本,正常组织和胃癌早期组织样本分别为206个和169个(见表1)。
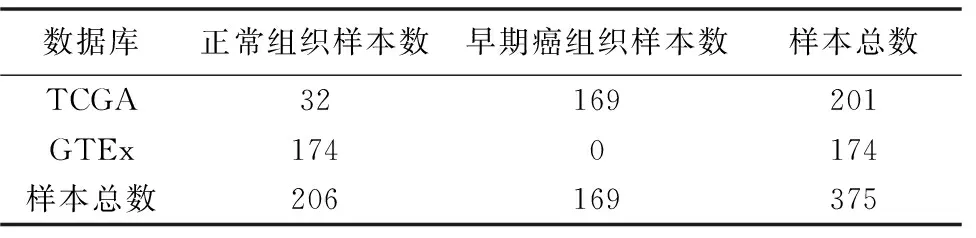
表1 基因表达数据集描述信息Table 1 Description of gene expressiondataset (个)
2 方 法
2.1 差异表达分析
TCGA和GTEx为不同平台的测序数据,其数据因获取的方式不同而存在批次差异,在进行差异分析前先进行批次效应处理[8]。本研究使用R平台(R 4.0.3,https://www.r-project.org)中自带去批次效益函数的Deseq2软件包对TCGA和GTEx联合数据集进行批次效益去除和差异表达基因(Differentially expressed genes, DEGs)筛选。Deseq2软件包仅支持未经标准化的read count形式的数据类型[9],设置|log2FC|>2,Benjamini Hochberg校正后的差异显著性阈值P.adj<0.05。
2.2 富集分析
基因本体论(Gene Oncology, GO)分析被广泛应用于降低复杂性和全基因组的表达研究,其包括分子功能(Molecular Function,MF)、细胞组分(Cellular Component, CC)和生物过程(Biological process, BP)3部分。KEGG通路富集分析采用的是京都基因与基因组百科全书数据库((Kyoto Encyclopedia of Genes and Genomes,KEGG),它是一个基因功能系统分析库,包括基因组、化学和系统功能等信息。本研究利用R语言的clusterProfiler软件包实现差异基因的GO和KEGG富集分析,富集筛选阈值设定为经Benjamini Hochberg校正后的P<0.05。
2.3 PPI网络分析
STRING数据库(https://string-db.org)整合了蛋白质间所有已知关联和预测关联,包括物理相互作用和功能关联,从多个数据源收集评分证据,收录了千万种蛋白质间的相互作用[10]。通过STRING数据库构建蛋白质间的相互作用(Protein-protein interaction,PPI)网络,可得到关系密切的蛋白基因集,有助于筛选关键基因。利用Cytoscape(Cytoscape 3.7.0,https://cytoscape.org)软件中的MCODE插件搜索提取PPI网络中的关键子网,关键子网中的基因即可被认为是候选关键基因。
2.4 诊断效能分析
通过MedCalc(MedCalc 19.1,https://www.medcalc.org)软件对候选关键基因的诊断能力进行评价分析。基于受试者工作特征曲线(Receiver Operating Characteristic,ROC)[11]、曲线下面积(AUC)、敏感性和特异性等指标可以评估关键基因的识别能力。随着ROC曲线下面积的增大,关键基因对胃癌早期识别能力逐渐增大,本研究设置AUC值大于0.9的基因可作为早期诊断关键基因。
2.5 诊断预测模型构建
使用Python(Python 3.7.4,https://www.python.org) 机器学习扩展包 scikit-learn开发实现分别基于支持向量机(Support Vector Machines,SVM)[12]、随机森林(Random Forest,RF)[13]、朴素贝叶斯(Naive Bayes Model,NBM)[14]、 K 近邻(K-Nearest Neighbor,KNN)[15]、极致梯度提升(eXtreme Gradient Boosting,XGBoost)[16]和自适应提升(Adaptive Boosting,AdaBoost)[17]的胃癌早期诊断预测模型。
2.6 模型验证与评估
不同算法训练得到的分类器模型在训练集上具有不同的表现,广泛应用的评价指标有:准确率(Accuracy)、精确率(Precision)、召回率(Recall)[18]、F1_score[19]、ROC曲线和AUC值等。AUC定义为ROC曲线下面积值,AUC作为一个数值,其越大说明分类模型越好[20]。混淆矩阵常被用作二分类模型的评判指标[21]。
3 结果分析
3.1 差异表达分析
对于TCGA和GTEx联合数据集,通过Deseq2软件包进行批次效益去除并筛选差异表达基因,得到1 524个DEGs,包含735个上调基因和789个下调基因,其火山图(见图1)。
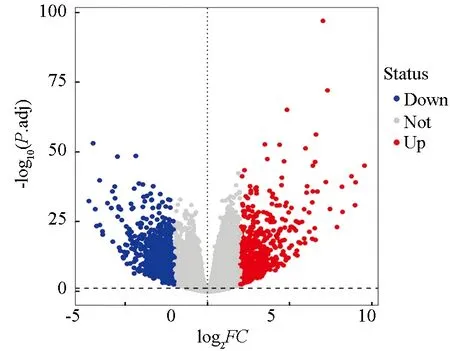
图1 胃癌组织与正常组织间DEGs火山图Fig.1 Volcano map of DEGs between gastric cancer tissue and normal tissue
3.2 GO富集分析
通过clusterProfiler软件包对差异基因进行GO和KEGG功能富集分析。GO富集分析结果中共包含501个条目,其中细胞组分条目48条,分子功能条目125条,生物过程条目328条。将P.adjust值按照升序排列,分别选取三部分前10条目进行展示(见图2)。分析表明差异基因主要富集于生物过程上,包括表皮细胞分化、肌肉系统过程和皮肤发育等;细胞组分功能主要富集于细胞外基质、细胞顶端和转运复合体;分子功能主要富集于受体配体活性、信号受体及内肽酶活性,主要结果(见表2)。
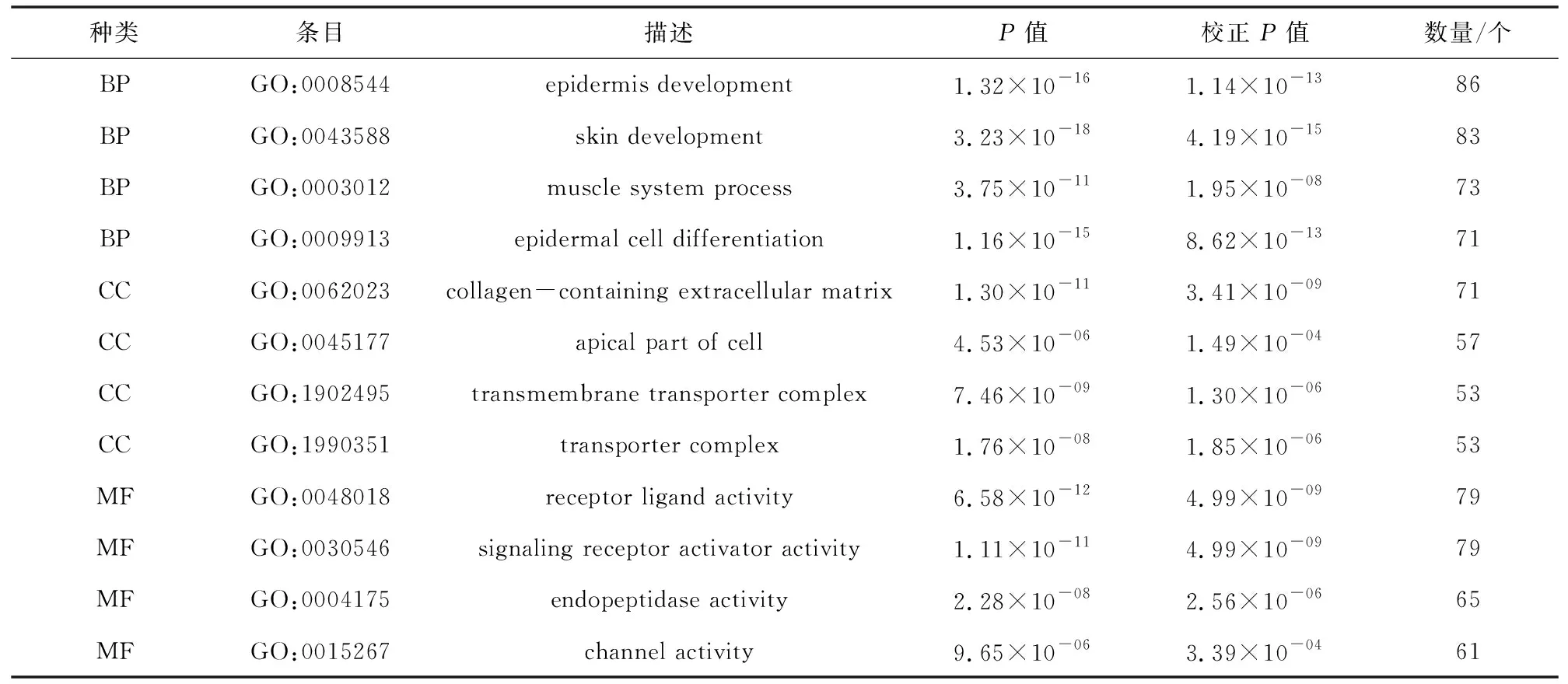
表2 GO功能富集分析部分结果Table 2 Partial results of GO function enrichment analysis
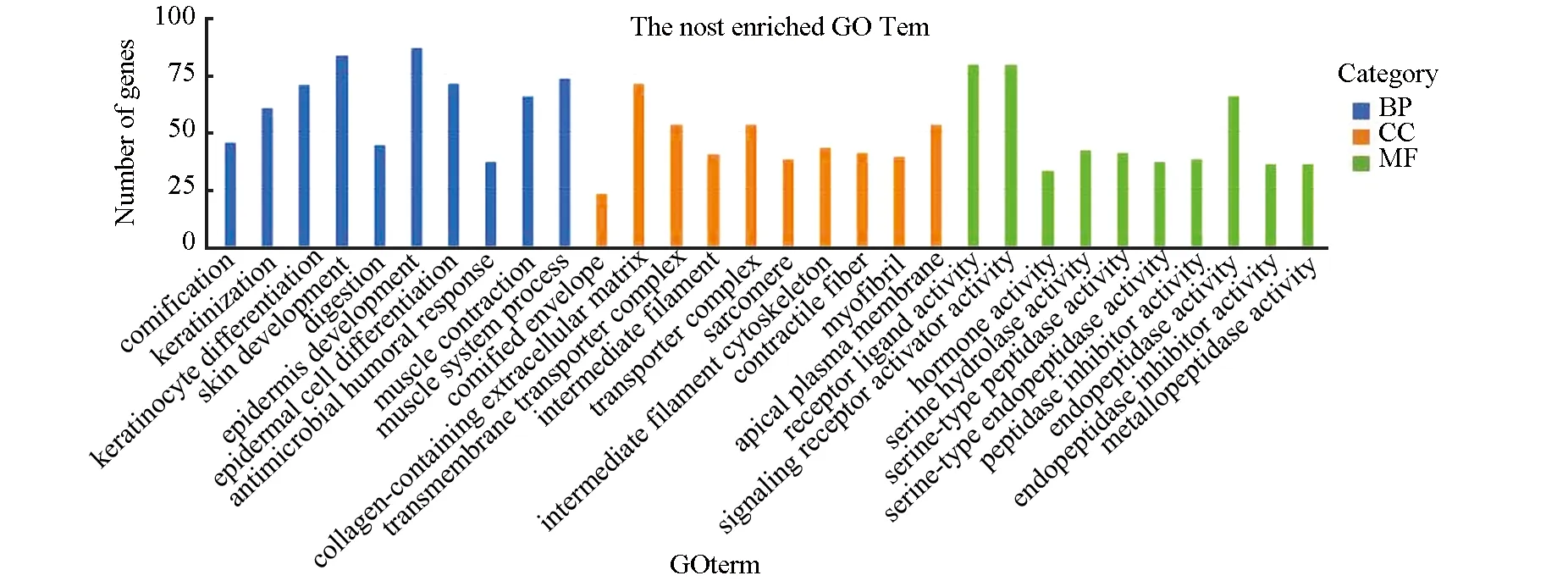
图2 显著富集的GO termFig.2 Significantly enriched GO terms
KEGG通路富集分析结果中共包含32个条目,差异基因主要富集在神经活性配体-受体相互作用、细胞因子-细胞因子受体相互作用和cAMP 信号等通路。将经Benjamini Hochberg校正后的P值按升序排列,选择前10条目进行气泡图绘制(见图3)。表3全面地展示了将通路包含基因数量按照降序排列的前10条目结果。

表3 KEGG通路富集分析部分结果Table 3 Partial results of KEGG pathway enrichment analysis

图3 KEGG通路富集分析气泡图Fig.3 Bubble chart of KEGG pathway enrichment analysis
3.3 PPI网络分析
利用STRING数据库对1 524个DEGs构建其PPI网络,并通过Cytoscape软件中的MCODE插件获得每个蛋白质相互作用子网的评分,按照得分递减顺序提取前两名的子网为关键子网(见图4)。两个关键子网中共包含的58个基因作为胃癌早期诊断候选关键基因。
图4 关键子网的PPI网络图Fig.4 PPI network of key subnetworks
分别对两个关键子网中包含的基因进行GO功能富集分析,富集分析结果表明关键子网1所包含的33个基因主要富集在生物过程上,包括粒细胞趋化、趋化因子介导信号通路和G蛋白耦联受体信号通路等;关键子网2所包含的25个基因主要富集于生物过程的角质细胞分化和交联肽。
3.4 诊断效能分析
基于基因表达数据,利用MedCalc软件对58个候选关键基因进行诊断效能分析,结果分别在图5中进行展示。提取AUC值大于0.9的基因,最终得到10个胃癌早期诊断关键基因,它们分别为CXCL11、CCR8、CXCL9、CXCL10、CXCL1、CCL20、CXCL8、CXCL6、APLN、HTR1E。关键基因的诊断效能结果如表4所示,其敏感性和特异性均高于70%。
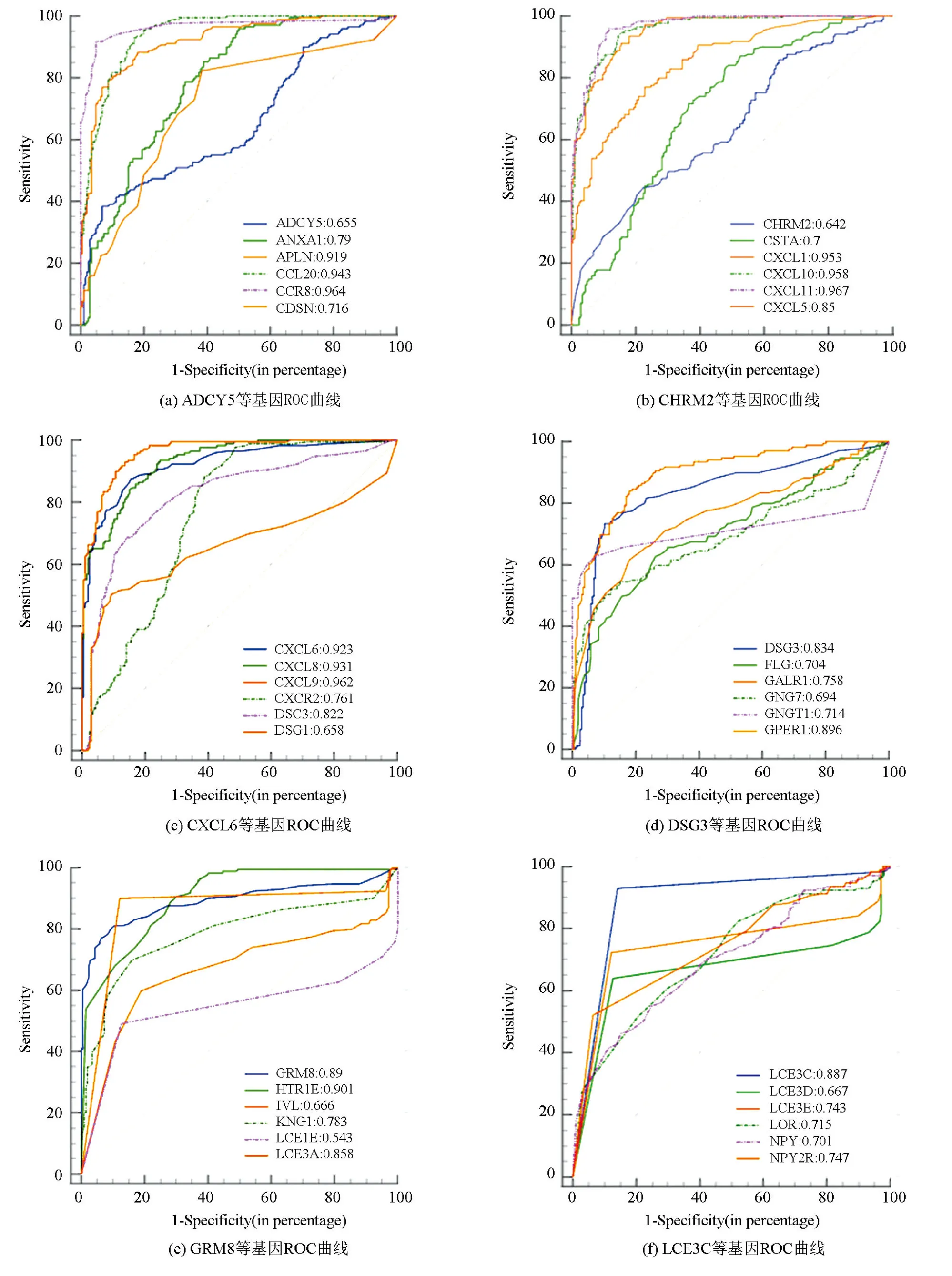
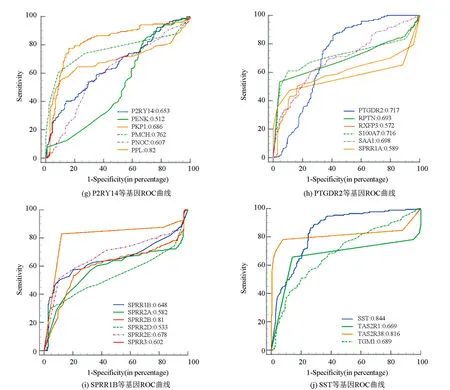
图5 候选关键基因ROC曲线Fig.5 ROC curve of candidate key genes

表4 基于关键基因的早期胃癌分类效果Table 4 Classification effect of early gastric cancer based on key genes
3.5 诊断预测模型构建
利用10个胃癌早期诊断关键基因构建胃癌的早期诊断模型,具体步骤如下:
1)提取出10个关键基因在TCGA联合GTEx数据集的表达值形成新的表达谱矩阵。
2)将来源于TCGA联合GTEx数据集的169个早期胃癌样本和206个正常样本分别随机提取1/11组成独立测试集,用于验证诊断预测模型的鲁棒性和泛化能力。独立测试集共包括33个样本,胃癌早期样本和正常样本数量分别为15个和18个,余下的342个样本用作训练集,流程(见图6)。

图6 胃癌早期诊断预测模型流程图Fig.6 Flow chart of early diagnosis and prediction model of gastric cancer
在含有342个样本的训练集上采用十折交叉验证法构建基于SVM、RF、NBM、KNN、XGBoost、AdaBoost 6种算法的诊断预测模型。在训练集中,SVM、RF、NBM、XGBoost、AdaBoost 5种模型均具有十分优秀的表现,各个指标得分均高于0.9,KNN模型表现略微逊色(见表5)。根据图7的ROC曲线图可知,各个模型均具有极高的AUC值。
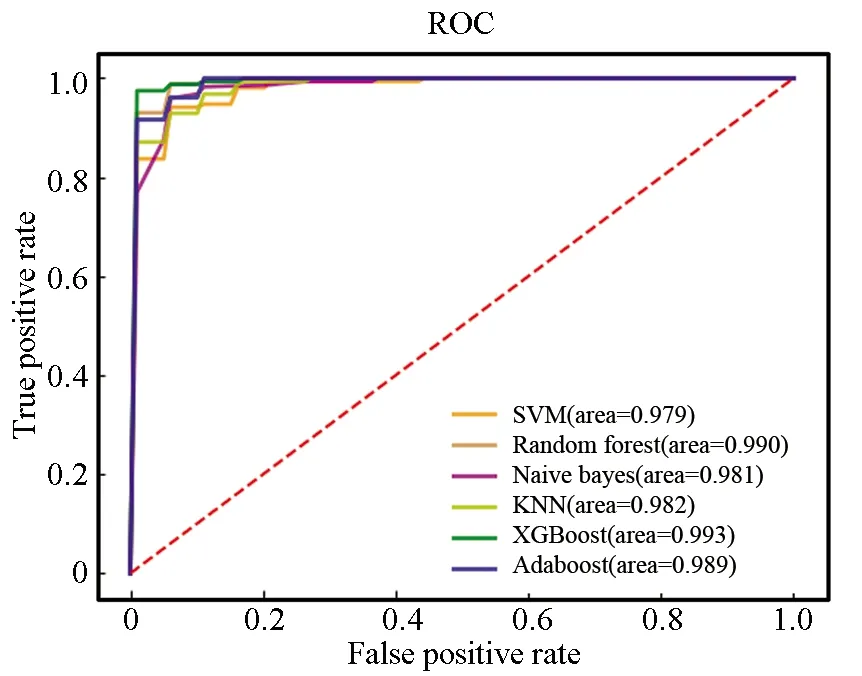
图7 训练集ROC曲线Fig.7 ROC curve of training set
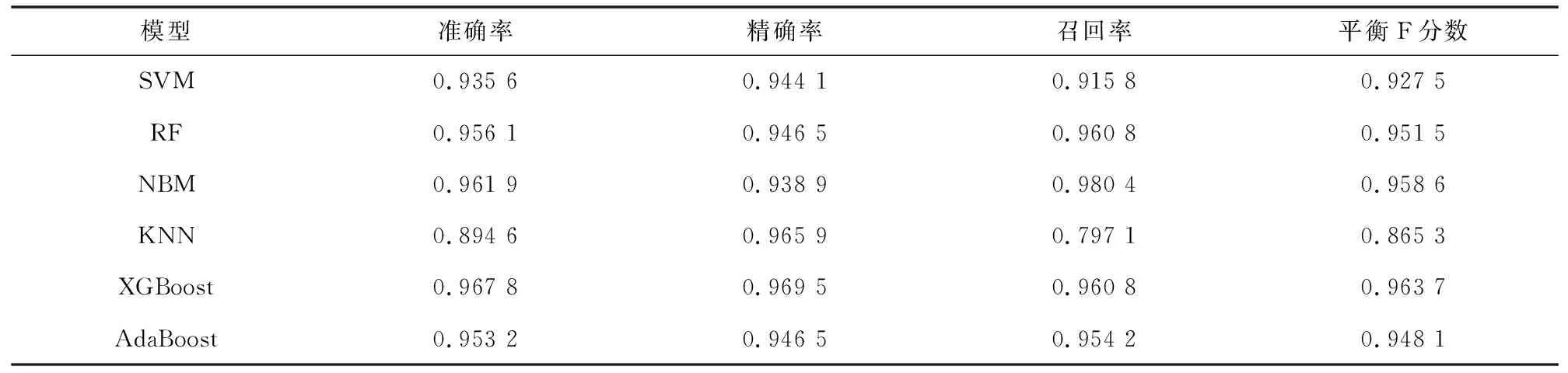
表5 6个模型在训练集中的评价指标Table 5 Evaluation indicators of six models on training set
在含有 33个样本的独立测试集上对6个模型的预测性能进行验证。据表6可知各个模型性能均有一定程度的下降。图8的ROC曲线表明在独立测试集上各个模型仍然具有较高的AUC值。综合6个模型在训练集和独立测试集上的表现,在本研究中,研究性能最出色、鲁棒性最高和泛化能力最好的模型是基于极致梯度提升算法构建的胃癌诊断预测模型。
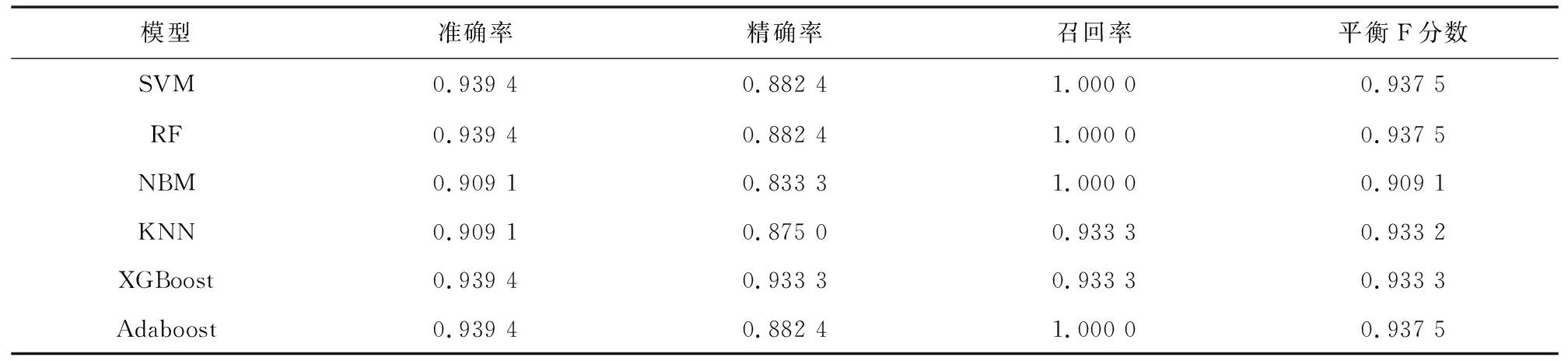
表6 6个模型在独立测试集中的评价指标Table 6 Evaluation indicators of six models on independent test set
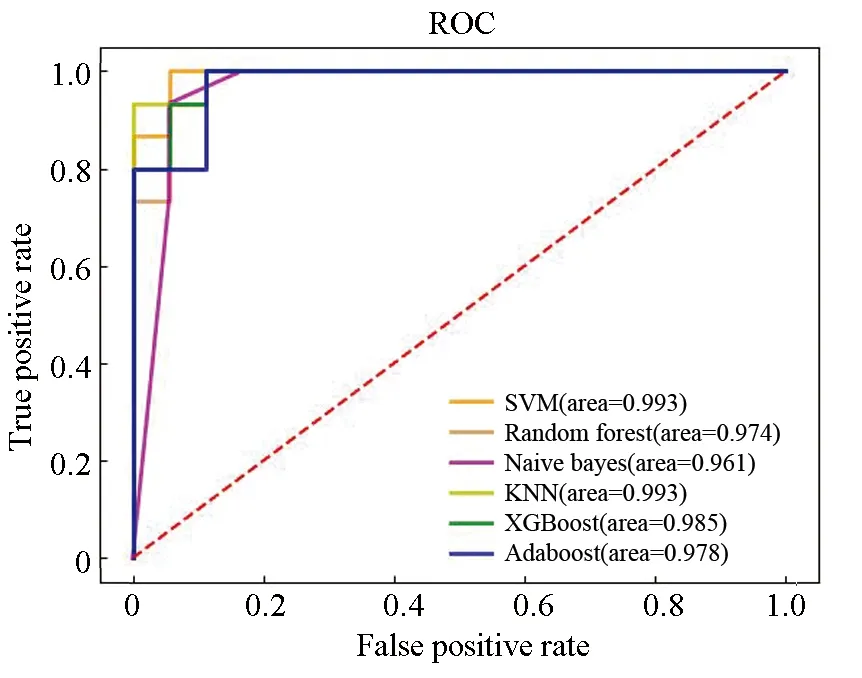
图8 独立测试集ROC曲线Fig. 8 ROC curve of independent test set
4 讨 论
通过检索公开数据库收集胃癌基因表达数据信息,利用生物信息学方法进行胃癌早期诊断关键基因的挖掘,最终得到10个关键基因(CXCL11、CCR8、CXCL9、CXCL10、CXCL1、CCL20、CXCL8、CXCL6、APLN、HTR1E)。
Wang H等[22]通过多种生物信息学分析方法发现CXCL11与胃癌肿瘤免疫浸润显著相关,其高表达可以作为胃癌预后和肿瘤浸润的潜在生物标志物,为EBVaGC的免疫治疗提供了新视角。Jie Yi等[23]对TCGA数据库中正常组织及胃癌组织数据进行统计分析,结果表明CCR8在胃癌组织中表达上调,并与胃癌患者的不良生存相关。Zhang C等[24]探索胃癌中程序性死亡配体 1(PD-L1)相关基因,体外实验验证阐明CXCL9/10/11-CXCR3 通过激活胃癌细胞中的 STAT 和 PI3K-Akt 信号通路上调 PD-L1 的表达。Chen X等[25]利用qPCR分析胃癌标本中CXCL1和CXCL8的表达,认为CXCL1 和 CXCL8通过与受体CXCR2结合协同参与胃癌细胞增殖、凋亡和迁移过程。相关临床数据表明CXCL1和CXCL8的低表达与胃癌不良预后的特征显著相关,包括AFP水平、肿瘤大小和TNM分期。Chen X等[26]还通过研究CXCL家族与胃癌发展的关系,结论表明CXCL6梯度与B细胞的绝对数相关,CXCL家族在胃癌的发病机制中具有重要作用,可以作为胃癌发展的标志物。
幽门螺杆菌感染相关的慢性炎症是胃癌的主要原因,Yin H等[27]利用TCGA和GEO 数据库,分析识别到CCL20为幽门螺杆菌感染相关的胃癌关键差异表达基因。Feng M等[28]采集270名胃癌患者的肿瘤样本和匹配的相邻正常组织,其研究数据表明APLN的表达水平和肿瘤分化、淋巴结和远处转移密切相关,可以用作评估临床特征和预测胃癌患者的预后的标志。腹膜转移(PM)是胃癌治疗手术最常见的失败原因之一,Zhang J等[29]利用差异分析识别到HTR1E为高风险PM患者的关键基因。
Alberto等[30]通过研究从32名胃癌患者的冰冻肿瘤样本获得的基因表达谱数据,利用方差分析和差异表达分析等方法,得到了3个与淋巴结转移风险较高的胃癌关键基因(Bik、aurorakinaseB和eIF5A2)。基于关键基因建立逻辑回归诊断预测模型用于预测淋巴结状态,该模型正确预测出32例胃癌患者中30例淋巴结状态,模型准确率为93.75%。该胃癌诊断预测模型为极致梯度提升诊断预测模型,其在训练集和独立测试集准确率分别为96.78%和93.94%,具有较好的预测效果。
5 结 论
通过生物信息学方法挖掘了胃癌早期诊断的10个关键基因,利用MedCalc软件分析可知,该10个关键基因对正常样本和胃癌早期样本具有较高的分类识别能力,可以作为早期胃癌诊断及研究的靶点。
本文特色之处在于基于关键基因的表达数据,通过分析多种机器学习算法,实现了诊断预测模型的构建,并最终选择了XGBoost诊断预测模型为最优模型。该模型在训练集和独立测试集上的具有最好的综合性能,可以作为一种无创性检查早期胃癌的手段,具有良好的应用前景。通过筛选关键基因构建了早期胃癌诊断预测模型,为提高胃癌早期诊断的研究提供了新的思路和方法。本研究不足之处在于对胃癌发生机制的研究不够深入全面,转录组学数据的分析并不能完全阐释机体总体变化;此外,本文研究内容仅为生物信息学诊断预测层面,缺少体内或体外实验支撑。在后续研究中,要加强与生物实验相结合,开发出更加实用、更加准确地胃癌早期诊断预测模型。