基于EEMD-Elman-Adaboost的中美股票价格预测研究
2022-12-15杨静凌唐国强张建文
杨静凌, 唐国强, 张建文
(桂林理工大学 理学院,广西 桂林 541006)
0 引言
股票价格预测一直受社会各界人士的关注,然而股票价格具有高度非正态、非线性和非平稳性等复杂特征,且受政治变数、社会环境、公司决策、投资者心理等诸多因素的影响,使股票价格预测面临巨大的挑战。
股票价格预测方法主要为:统计模型、人工智能模型、组合模型等方法。常用的统计模型有自回归移动平均(ARIMA)、广义自回归条件异方差(GARCH)等。这些模型计算量小、过程简单,但是通常忽略股票价格的非线性、非平稳等特征,对数据的分布有较高的要求。人工智能模型对数据表现出强大的自学习、自适应、非线性映射能力,对股票价格的复杂特征有较好的跟随能力。目前,已有许多研究利用人工智能对股票价格进行预测[1~4]。因单一模型无法刻画股票价格的多重特征,有学者尝试用组合模型来分析股票数据的走势,并取得较好的预测效果[5~8]。然而一般的组合模型对股票数据的刻画无法满足人们对股票预测精度的高要求。为此,一些学者提出经验模态分解(EMD)结合人工智能对股票数据进行预测,进一步提高了股票数据的预测精度。王文波等[9]将EMD与神经网络相结合,再利用混沌分析去除时间序列的混沌性,有效预测股票收盘价。贺毅岳等[10]提出基于EMD利用ε不敏感支持向量建立预测模型(EMD-SVRF)对上证指数进行预测。吴曼曼等[11]将EMD结合改进的Elman神经网络对上证指数和深证成指进行短期预测。
综合以上研究,发现EMD和人工智能结合可以有效地处理股票价格非正态、非线性、非平稳性等特征。但还存在以下不足:(1)EMD存在模态混叠的缺陷,影响预测效果;(2)所用人工智能模型较简单,预测精度不够高;(3)前人研究大多基于某国的股票数据进行预测,不能有效验证模型的普及性。为此,本文提出以Elman神经网络为基础,引入EEMD与Adaboost算法的组合模型对中美两国的股票日收盘价进行预测。
1 方法与原理
1.1 EEMD原理
2004年,Wu和Huang[12]提出了集合经验模态分解(EEMD),有效解决了EMD方法出现的模态混叠问题。EEMD的分解过程如下:
步骤1在原始数列y(t)中加入白噪声序列n(t),得到新的序列,记为s(t)。即:
S(t)=y(t)+n(t)
(1)
步骤2对S(t)用3次样条插值来分别确定其上下包络线序列,然后计算得到上下包络线的均值m1(t),序列S(t)-m1(t)得到剩余分量h1(t):
h1(t)=S(t)-m1(t)
(2)
步骤3对新的时间序列h1(t)重复(1)、(2)步骤,直到h1(t)满足EMD的两个条件:(1)局部极值点和过零点的数目相等或相差一个;(2)局部最大值的包络和局部最小值的包络平均值在任意时刻均为0。
此时,h1(t)为原始数列y(t)的第一个分量IMF1(t)=h1(t),残差分量为:
Res1(t)=y(t)-IMF1(t)
(3)
步骤4将Res1(t)定义为新的原始序列,重复步骤1~3,每次添加不同的白噪声序列,得到第二IMF个分量,如此循环反复,直到残差序列Res(t)为单调函数,则可以得到多个IMF分量和一个残差分量。
步骤5将各分量进行集合平均,以消除多次加入白噪声对分量的影响。得到的本征模态分量表达式为:
(4)
残差分量表达式为:
(5)
此时股票收盘价可被表示为:
(6)
其中J为IMF分量的个数。
1.2 Elman神经网络
1990年,Elman提出了Elman神经网络,其具有时变特性,能直接动态反映数据特征,Elman网络分为四层,分别为输入层、隐含层、承接层和输出层[13]。其结构如图1所示。

图1 Elman神经网络结构
Elman神经网络的非线性状态空间表达式为:
y(k)=g(w3x(k))
(7)
x(k)=f(w1xc(k)+w2(u(k-1)))
(8)
xc(k)=x(k-1)
(9)
其中,y、x、u、xc分别代表m维输出结点向量、n维隐含层结点单元向量、r维输入向量、n维反馈状态向量;w3、w2、w1分别代表隐含层到输出层、输入层到隐含层、承接层到隐含层的连接权重;g(·)为输出神经元的传递函数,f(·)为隐含层神经元的传递函数。
1.3 Adaboost算法优化Elman神经网络原理
Adaboost是一种迭代算法,可以提高任意给定学习算法的精度,不仅可以应用于预测问题,也可以应用于分类问题。其核心思想是对同一个训练样本训练不同的预测器(弱预测器),然后把这些弱预测器集合起来,构成一个更强的预测器(强预测器)[14]。本文Adaboost算法在Elman-Adaboost组合中发挥作用,以Elman神经网络为基础,通过Adaboost算法将Elman神经网络作为弱预测器,对Elman神经网络的样本输出进行反复训练,通过Adaboost算法得到由多个Elman神经网络弱预测器组成的强预测器。Adaboost优化Elman神经网络步骤如下:
步骤1数据获取及网络初始化。从样本经EEMD分解出的每个分量中随机选取m组训练数据,初始化测试数据分布权值Dt(i)=1/m,根据样本输入输出维数确定神经网络结构,初始化Elman神经网络权值和阈值。
步骤2Elman弱预测器预测。在训练第t个弱预测器时,使用Elman神经网络对训练数据进行训练,得到预测序列g(t)的预测误差et:
(10)
步骤3计算预测序列权重。依据预测序列f(t)的预测误差et计算序列的权重at:
(11)
步骤4测试数据权重调整。依据预测序列权重at调整新训练样本的权重,调整公式为:
(12)
其中,Bt是归一化因子。
步骤5输出样本序列各分量的强预测器函数。经过T次迭代运算后得到T组弱预测器函数f(gt,at),由此T组弱预测器组合得到强预测器函数F(x):
(13)
1.4 EEMD-Elman-Adaboost组合模型
(1)EEMD-Elman-Adaboost组合模型的预测步骤
步骤1对样本进行EEMD分解,得到多个IMF分量和1个残差分量。
步骤2将分解后的各个分量分成训练样本和预测样本,并将样本进行归一化处理。
步骤3根据序列的特征确定神经网络的输入层节点数,利用试凑法,根据网络误差选出每一分量的最优隐含层节点数,在训练预测模型时确定神经网络的其他重要参数。
步骤4用Adaboost将Elman神经网络作为弱预测器反复训练组成强预测器,优化Elman神经网络系统,对训练样本进行训练得到预测模型,再将预测样本放入预测模型进行预测。
步骤5将以上步骤各个分量的预测结果进行反归一化后再求和,作为最终的预测结果。
预测流程如图2所示:
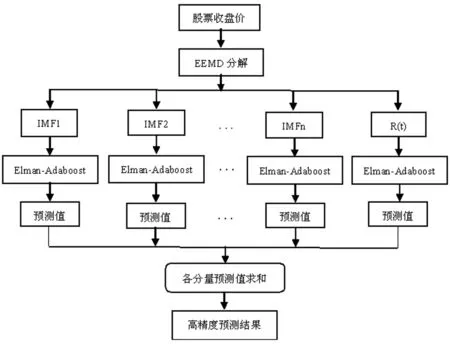
图2 EEMD-Elman-Adaboost预测流程图
(2)重要参数的设定
在EEMD过程中,白噪声标准差为0.2,实现次数为500。在建立Elman网络弱预测器的过程中,弱预测器设为10个,Elman神经网络以tangsig为传递函数,traingdx为训练函数,最大迭代次数为3000,误差容限为0.00001,最多失败次数为5。在Adaboost算法将Elman神经网络作为弱预测器训练强预测器时,测试误差超过0.1的样本作为应加强学习的样本。神经网络为单层的隐含层和输出层。根据陈健[15]和孙冰洁等[16]的观点将输入层节点数设为5,结合Baily等[17]和Katz[18]的研究结论,利用试凑法,根据预测模型的网络误差选择隐含层的最优节点数。
1.5 预测评价指标
为了有效地检验模型的预测效果,本文采用均方根误差(RMSE)、平均相对误差(MAPE)、平均绝对误差(MAE)作为预测模型的评价标准。

(14)
(15)
(16)
其中,RMSE反映预测值与真实值之间的偏差,MAPE反映预测值与真实值的相差程度,MAE反映预测误差的实际情况,三个指标的数值越小,说明模型的预测效果越好。
2 实证分析
2.1 数据选取与基本描述分析
本文选取2016年1月4日至2019年12月05日中国大陆股票市场上证指数和深证成指的日收盘价作为研究对象,并以香港的恒生指数和美国股票市场的道琼斯指数、纳斯达克指数的日收盘价为验证对象,数据来源于网易财经(https://money.163.com/)。
样本的基本统计量如表1所示,走势如图3所示。由表1可知,样本的偏度均不为0,峰度均不为3,不服从正态分布。ADF的P值均大于0.05,说明样本均为非平稳序列。由图3可知,样本随着时间的变化而变化,走势曲线呈现明显的大波动、非线性的趋势。
综合表1和图3,样本具有非正态、非线性、非平稳的复杂特征,线性模型和一般组合模型很难对其进行有效预测。因此,本文应用EEMD与Adaboost算法改进Elman神经网络,对样本进行预测。

表1 基本统计量

图3 样本走势图
2.2 EEMD分解
对样本进行EEMD分解,均得到8个IMF分量和1个残差分量。分解结果如图4所示。由图4可知,每个IMF分量的振幅、频率和周期均不相同,每个分量都有自身的波动特征。IMF分量从上至下的振幅和频率逐渐变小,周期逐渐变长,残差项呈现近似线性的趋势,与样本的总体走势一致。

图4 EEMD分解结果图
2.3 Elman-Adaboost神经网络预测
将分解后各分量归一化处理,再将处理后各分量的前部分数据作为训练样本,训练Elman-Adaboost预测模型,将后50个数据作为预测样本进行模型预测;最后将样本所有分量的预测结果反归一化,再求和,作为最终预测结果。
为了检验本文预测模型的优越性,将其与现有的BP、Elman、EMD-Elman、EEMD-Elman模型作对比。各模型预测结果如图5所示。由图5可知,对比模型对样本预测的曲线和真实值的曲线明显不重合且存在滞后的现象。EEMD-Elman-Adaboost模型的预测值与真实值曲线基本重合,说明该模型的跟随能力更强,预测精度更高。
为了更精确地比较模型的预测效果,本文以RMSE、MAPE、MAE作为评价指标对各模型的预测误差进行量化比较,结果如表2所示。由表2可知,EEMD-Elman-Adaboost模型的预测误差最小,说明其预测效果优于其他模型。Elman能动态反映样本特征,比BP的预测效果好。EEMD克服了EMD的缺陷,更有效的分解数据,提取有效信息。Adaboost算法将Elman弱预测器组合形成强预测器,有效地提高了系统的学习精度和泛化能力,使EEMD-Elman-Adaboost模型的预测精度得到有效提升。

图5 各模型预测值与真实值的对比
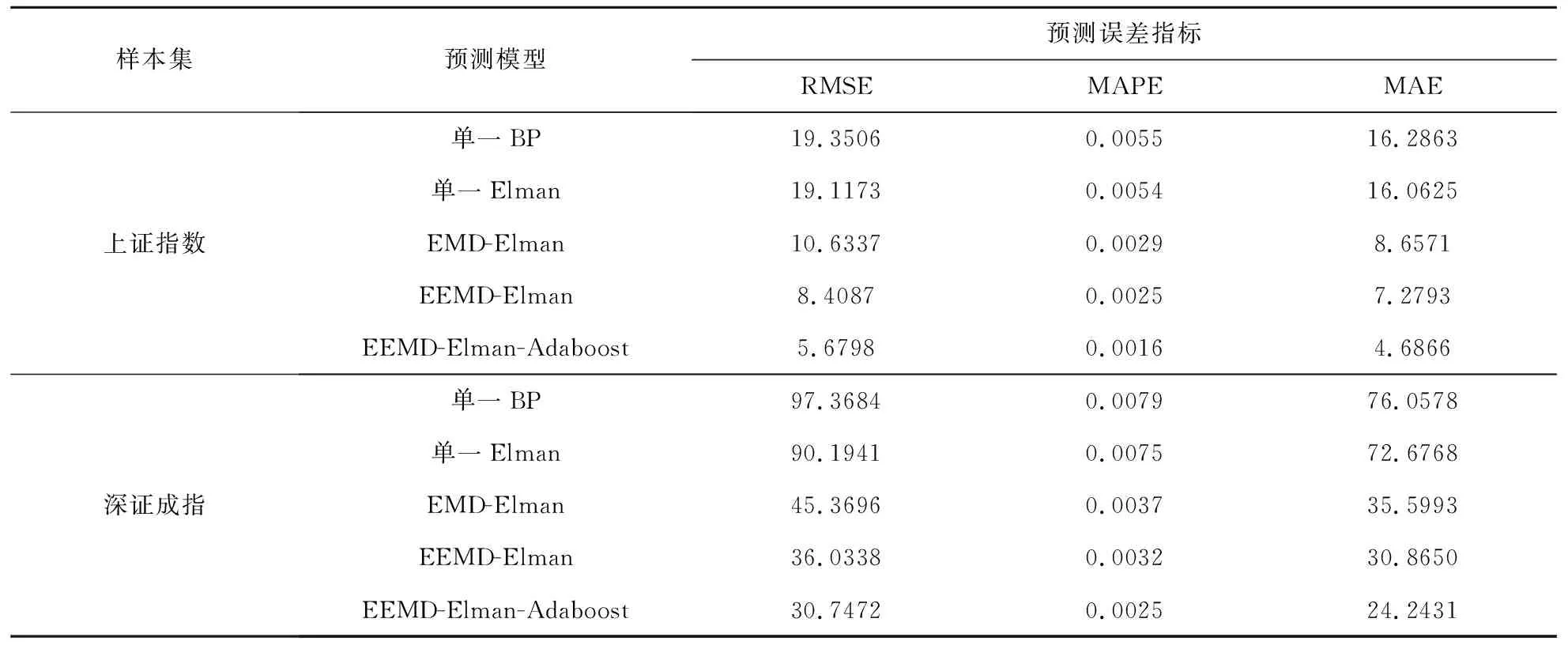
表2 预测误差比较
2.4 EEMD-Elman-Adaboost的适用性检验
为了检验新模型的适用性,选取香港和美国股票指数的日收盘价为验证对象。不同模型对验证样本的预测误差如表3所示。由表3知,EEMD-Elman-Adaboost模型比其他模型的预测误差更小,新模型应用于香港和美国股票市场亦呈现更好的预测效果,验证了本文模型的适用性。
结合表2和表3,由于不同股票市场的成熟度、行业规模和经济结构不同,不同预测方法应用于不同股票市场的预测误差均有差异。

表3 验证样本预测误差比较
3 结语
针对股票价格序列的多重复杂特征,本文提出EEMD- Elman- Adaboost组合模型,以中国大陆股票指数的日收盘价作为研究对象,以香港及美国的股票指数作为验证对象,进行实证分析。首先,利用EEMD将样本进行分解,得到多个分量;其次,利用Adaboost算法优化Elman神经网络,对各个分量进行预测;最后,将各个分量的预测结果进行求和作为样本的最终预测结果。将EEMD-Elman-Adaboost组合模型和现有的BP、Elman、EMD-Elman、EEMD-Elman模型作比较,通过对比图和3个预测评价指标对各模型进行直观对比和量化对比,验证新模型的预测效果。结果表明:EEMD-Elman-Adaboost组合模型均比对比模型的预测误差小,能更有效地预测中美两国的股票价格序列。新组合模型融合了EEMD、Elman神经网络、Adaboost算法的优点,具有更强的泛化能力和跟随能力,预测精度更高。
由于选择多方面指标对股票价格进行预测,工作量大,且易受其他因素影响,本文仅利用历史数据进行预测分析。在后续研究中将尝试加入多方面指标进行测试,以进一步验证该模型的预测能力。
