基于路警数据与LightGBM算法的高速公路行程时间预测*
2022-12-14景峻仝瑶李鹏么新鹏王孜健
景峻, 仝瑶, 李鹏, 么新鹏, 王孜健
(1.山东高速集团有限公司, 山东 济南 250098;2.北京工业大学 城市交通学院, 北京 100124;3.北京市交通工程重点实验室, 北京 100124)
行程时间是现代交通管理和控制系统的关键输入,也是道路服务水平评价的常用指标,对出行者是最有价值的信息。高速公路行程时间预测是一个十分重要的课题,大量学者对此进行了研究。在预测算法方面,邢雪等采用高速公路实测历史数据构建特征集,建立了一种预测强度修正的k-means方法;王翔等基于最邻近算法(KNN),考虑历史交通状态特征,对高速公路短时行程时间进行了预测;刘伟铭等将最小二乘支持向量机(LSSVM)应用于行程时间预测,并利用粒子群算法(PSO)对LSSVM的参数进行优化,最终利用PSO-LSSVM模型预测行程时间;杭明升等将卡尔曼滤波成功应用于高速公路行程时间动态实时预测;江周等采用多源数据融合的方法,基于卡尔曼滤波算法建立了城市道路网络行程时间预测模型;李萌等考虑恶劣天气情况对高速公路行程时间预测的影响,将降雨量作为影响因素,利用遗传算法优化的径向神经网络(RBF)实现了不同降雨强度下行程时间预测;刘松等基于高速公路收费站的刷卡数据获取行程时间,利用门限递归神经网络对行程时间进行了预测;林培群等对不同机器学习算法及长短时记忆神经网络模型(LSTM)进行融合,并引入高速公路时空特性,实现了不同时间步长下高速公路行程时间预测;为同时得到预测结果及置信度,文献[10-11]将贝叶斯理论纳入行程时间预测框架。上述方法用于行程时间预测各有所长,其中神经网络具有强大的非线性映射能力,能处理海量数据;机器学习有着更好的解释性,但在处理大量数据时力不从心。LightGBM算法融合了二者的优点,其运算速度快、内存消耗低、模型精度高、支持并行训练、可处理海量数据,被广泛应用于行程时间、客流等预测。
在数据源方面,现有行程时间预测方法所依赖的数据主要源于传统交通调查、“两客一危”北斗定位及浮动车数据。传统交通调查设备检测精度不高,耐久性较差,布设与维修成本高昂;“两客一危”数据与浮动车数据仅包含旅游客车、危险品运输车辆或出租车与公交车,预测出的行程时间对于高速公路整体交通状况不具有代表性。此外,受限于视频卡口的覆盖范围及检测精度,视频数据在行程时间预测应用方面的效能一直无法充分展现。2019年中国高速公路“撤站”后,全国共建设完成约2.7万套ETC(电子不停车收费系统)门架,发展ETC用户约2.26亿,日均生成3亿多条天线交易数据和4亿多条车牌识别数据。如此广阔的覆盖范围和庞大的数据体量及高精度检测特性使ETC门架数据在交通流预测、交通事件识别、交通协同管控等方面具有先天优势。当前视频卡口数据主要归属于公安交警,ETC门架数据主要归属于高速公路管理部门。融合路警双方的数据源,在充分挖掘ETC门架数据的基础上,应用视频卡口数据对其进行补充,可有效提高检测器与数据采集密度,支撑更加准确的行程时间预测应用,助力高速公路精细化监管。因此,本文以高速公路ETC门架与交警视频卡口数据为基础,应用LightGBM机器学习算法进行高速公路行程时间预测,以快速获取较高精度的行程时间预测结果,为高速公路智能化实时管理控制与出行信息服务等应用提供数据支撑。
1 数据处理与特征集构建
1.1 数据来源与数据结构
研究数据源为ETC门架交易数据和视频卡口过车数据。ETC门架原始交易数据主要字段见表1,包括通行标识、通行介质、门架ID、车牌号、车牌颜色、交易时间、车型等信息。相邻点位交易信息比对结果表明,全日ETC门架检测车辆检出率可达99%,可识别车型达16种。

表1 ETC门架原始数据主要字段
视频卡口原始数据主要字段见表2,包括卡口桩号、车速、号牌号码、采集时间、车牌颜色、车辆颜色等信息。相较于ETC门架数据,卡口数据具有更多的交通检出信息(包括车速、分方向车道的交通量等)。值得注意的是,由于高清视频卡口检测依赖于能见度,在夜间等能见度不足的情况下存在漏检、错检等问题。
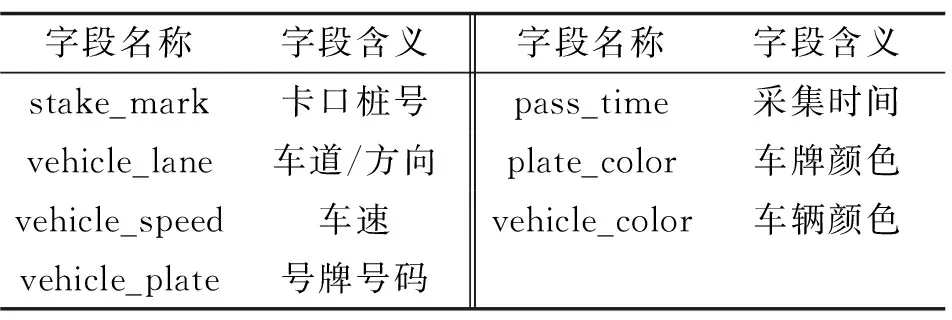
表2 卡口原始数据主要字段
1.2 数据预处理
由于ETC门架原始数据中仅存储交易时间数据,且ETC交易分为OBU(车载单元)收费和CPC(复合通行卡)收费两种方式,交易延迟不统一,存在实际通行时间不明确的问题,难以与视频卡口车辆通行时间匹配。视频卡口检测存在重复检测、车牌字段缺失等问题。因此,原始数据不能直接用于行程时间预测,需对数据进行预处理,校正时间并剔除异常数据。此外,两种数据源的车型、车牌分类标准存在差异,需对ETC门架及卡口数据进行关联融合处理。数据预处理流程如下:
(1) ETC门架数据时间校准。根据通行介质字段区分两种交易方式,分别针对两种交易方式,根据交易系统平均延时将交易时间字段校正为通行时间。
(2) 卡口异常数据清洗。剔除卡口原始数据中车牌号为空或错误的过车数据,对数据以30 min为窗口进行去重。
(3) 路段单元构建。根据各ETC门架及卡口安装桩号及检测范围,对检测设备先后顺序进行排序,将连续两设备及其中间路段作为一路段单元,并计算路段单元长度。
(4) 路警数据融合与车辆匹配。通过车牌号、车牌颜色字段对路段单元起终点设备检测到的过车数据(ETC门架或卡口)进行关联,获取完整通过路段单元(未经立交驶入、驶出高速公路)的车辆及其通过路段起终节点的时间。
(5) 行程时间计算与异常值剔除。计算车辆行程时间,结合各路段单元长度,剔除过长或过短的行程时间数据。
1.3 特征集构建
在训练模型前,从数据集中提取对车辆行程时间可能有影响的特征。特征的选取直接影响预测精度。通过对数据的初步分析,参考文献[3,9,16-19],选取以下8个特征作为模型的输入(见表3):

表3 特征集含义及分类
(1) 路段流量。当前路段历史各时段交通流量。本研究中,由于两检测器间可能存在立交及高速公路出入口,选取路段单元起点检测器流量作为路段流量。
(2) 大车混入率。当前路段历史各时段二型以上大车占总体交通量的比例。
(3) 天气。当前时刻天气状况(晴/雨/雾)。不良的天气对驾驶员驾驶行为具有较大影响,可能导致车速不稳定和行程时间增加。天气信息从互联网爬取,每小时更新。
(4) 日期类型。当前日期属工作日或节假日等。
(5) 时间。当前时段起始时间。
(6) 车型。根据ETC门架交易数据将车辆分为14种类型。以某路段2021年5月部分时段数据为例,进行分车型的行程时间统计,结果见图1。从图1可见各车型间行程速度差异较大。
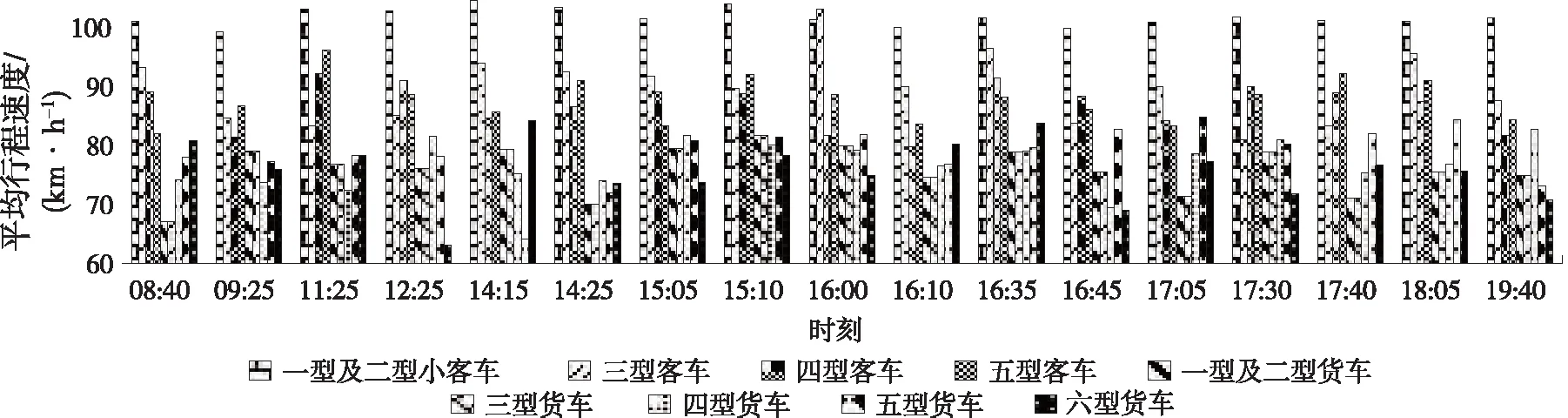
图1 各车型行程时间
(7) 路段长度。当前路段道路长度,为静态值。
(8) 平均行程时间。当前路段历史各时段的平均行程时间。当前时间路段行程时间可能与历史上一时段的行程时间具有相关性。
以5 min为一个时间单元进行模型训练及预测,在该时间单元内,交通状态及天气环境不会出现较大变化,且能保证样本车辆完整通过每一路段单元(检测器平均间隔5 km,符合道路限速条件的最大行程时间为5 min)。
将数据集中的参数link_flow、large_mix_rate、weather、is_holiday、time、vehicle_type、link_distance、avg_travel_time分别设为U={X1,X2,X3,…,X8},基于数据的历史时间序列对原始数据集进行重构,形成预测的特征集:
(1)
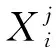
将特征集矩阵Q按行展开成一个行向量,并基于整体数据构建训练集Qtre:
(2)

2 模型构建
2.1 LightGBM算法
LightGBM算法是XGBoost(极限梯度提升树)的改进算法,与XGBoost相比有着更快的计算速度和更高的精度。LightGBM与XGBoost是在GBDT(Gradient Boosting Decision Tree)基础上发展而来的大规模并行计算提升树,与GBDT不同的是,LightGBM的目标函数在损失函数的基础上增加了正则化项,考虑了树过于复杂而带来的过拟合问题。LightGBM的目标函数如下:
(3)
式中:Loss(·)为模型预测的损失函数;ω(ft)为正则化项。
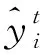
(4)
目标函数可表示为:
(5)
根据式(5),只需求出ft(xi),便可进一步得到目标函数fobj。根据二阶泰勒展开公式,得:
f(x+Δx)=f(x)+f′(x)·Δx+
(6)
将目标函数fobj展开为二阶泰勒公式,得:
(7)
问题的核心是怎样对特征空间进行划分,即递归地寻找最优切分变量和切分点。最优切分变量和切分点的计算方式与GBDT类似,基于贪心算法的思想,对于每个节点,针对每个特征采用启发式算法计算最优切分点,再遍历所有特征变量,找到最佳切分变量。重复上述算法直到满足停止要求。XGBoost算法对损失函数应用了二阶泰勒展开,相对于GBDT的一阶展开其精度更高;加入正则化项,可有效避免过拟合;可自动对缺失值进行处理,且可并行计算,计算速度更快。但XGBoost算法在计算最佳切分变量及最优切分点时需遍历每个特征及每个数据,会消耗大量内存,计算复杂。LightGBM算法在XGBoost算法之上进行改进,使用带深度限制的Leaf-wise算法防止模型过拟合,采用直方图加速算法降低内存消耗和计算复杂度。
带深度限制的Leaf-wise算法中,树的生长策略有两种生成方法:一是Level-wise基于层的生长方法,对每层每个节点都进行分裂;二是Leaf-wise方法,对于每层,只分裂增益较大的节点,可减少计算量,同时利用最大深度限制防止过拟合(见图2)。

图2 不同的树生长策略
基于直方图的加速算法将输入层中已排序的参数数据集转换为具有指定数量的数据区间或Bins的直方图(见图3)。转换之后,每个数据间隔(Bin)拥有相同的索引。该算法在大大提高LightGBM模型训练速度的同时只需较少的内存消耗。
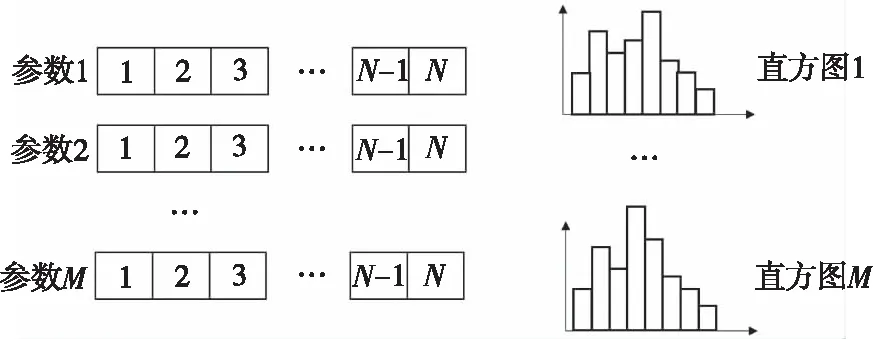
图3 直方图加速算法示意图
2.2 LightGBM模型训练
2.2.1 数据准备
研究路段为山东省济南市济广(济南—广州)高速公路唐王收费站至济南零点收费站区间,共22 km,单向四车道,自东向西途径临港、小许家、东客、华山立交。对济广高速公路2021年5月车流量及大车混入率按小时进行统计,结果如下:济广高速公路车辆出行时间主要集中在6:00—19:00,以二型及以下小型车为主,小型车占比为90%左右;夜间流量较低,以大型车为主,大型车占比最高达45%(见图4)。
该路段单向共设置3处ETC门架、2处视频卡口。选取这5个点位2021年5月共2 450 387条ETC交易数据及2 145 281条视频卡口过车数据进

流量为一个月各时段平均值
行高速公路行程时间预测。
2.2.2 模型主要参数设置
LightGBM模型有较多的超参数,不同参数值对模型性能有显著影响,需针对具体应用场景对模型超参数进行优化。采用文献[18]中方法对参数进行优化调整。为防止数据训练过拟合,采取K折交叉验证(KCV)的方法将特征数据集分成m份,其中c份用作训练集,m-c份数据用作验证集,对模型进行训练。模型的主要参数及相关字段见表4。
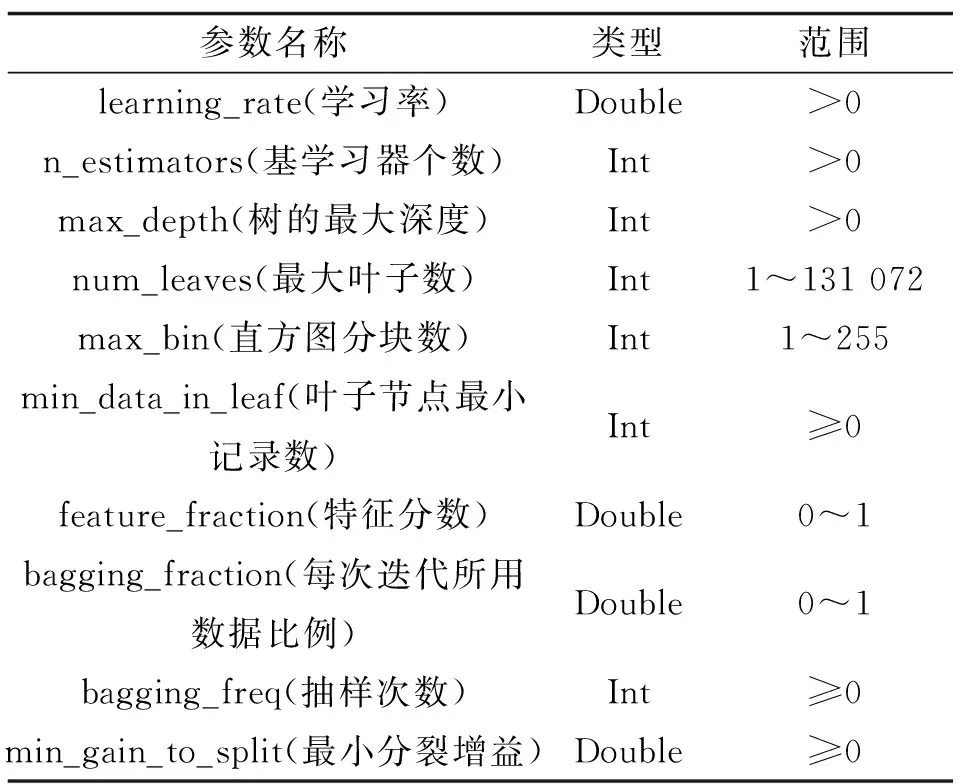
表4 模型重要参数表及相关字段
基学习器的数量对模型预测精度有很大影响,数量过大或过小会导致模型训练结果过拟合或欠拟合。为解决这个问题,以均方根误差RMSE为指标,通过不断迭代学习寻找合适的基学习器数量。如图5所示,模型预测的RMSE随着基学习器的数量增大而减少,最后达到收敛状态。选取500个基学习器。

图5 RMSE随模型基学习器数量的变化
LightGBM模型的learning_rate对算法的计算速度及预测精度有很大影响。在LightGBM模型中,learning_rate的默认值为0.1。在其他参数不变的情况下,将learning_rate分别设置为0.01、0.05、0.1,分析不同learning_rate下模型误差与迭代次数的关系,结果见图6。由图6可知:对于上文构建的预测模型及数据集,LightGBM算法中learning_rate对模型预测精度几乎没有影响,但learning_rate越大,算法收敛越快。
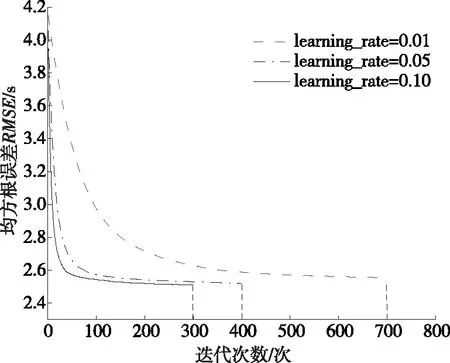
图6 不同learning_rate下模型误差与迭代次数的关系
在LightGBM模型中,max_depth和num_leaves控制决策树的复杂性,其取值过大会使模型陷入过拟合,导致预测精度达不到预期。为此,研究误差随不同max_depth和num_leaves参数值组合的变化,获取超参数的优化值,结果见图7。由图7可知:虚线圈中颜色最深,max_depth的最佳取值约为4,对应于num_leaves参数的最佳取值约为10,与利用文献[15]中基于贝叶斯的参数方法所得结果吻合;随着max_depth与num_leaves取值的增大,误差逐渐增大,表明模型可能出现过拟合。因此,两参数的取值不宜过大,该结论与LightGBM模型本身的性质也相符。
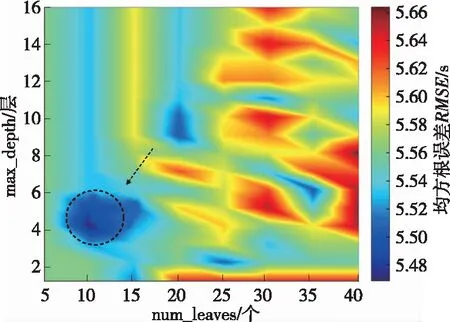
图7 误差随num_leaves与max_depth不同取值的变化热力图
其他超参数的取值见表5。
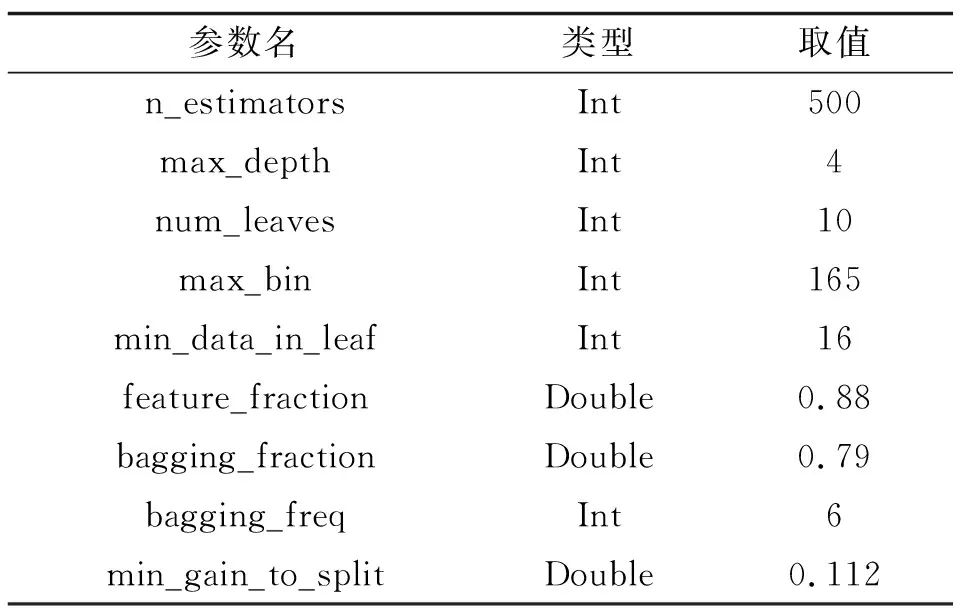
表5 超参数的优化取值
3 模型结果分析
3.1 模型验证指标
选取均方根误差RMSE、平均绝对误差MAE、平均绝对百分比误差MAPE作为预测模型精度验证指标。RMSE反映预测结果与实际值之间的偏差,计算公式如下:
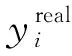
MAE是预测值与实际值绝对误差的平均值,反映误差的真实情况和大小,计算公式如下:
MAPE是预测值与实际值绝对误差和实际值的比值的百分比,反映预测结果的可靠度,计算公式如下:
3.2 模型对比验证
为验证LightGBM模型在高速公路行程时间预测方面的优越性,选取随机森林(RF)、支持向量机回归(SVR)、最邻近(KNN)3种常用机器学习算法进行对比验证。根据5个ETC门架及视频卡口检测器分布将该高速公路分为4段分别进行预测。各路段不同模型预测值与实际值的对比见图8。

图8 不同模型预测值与实际值对比
从图8可看出:LightGBM模型能较好地预测数据的趋势和走向。实际值中存在一些异常值(偏离均值程度很大),可能是由高速公路上突发状况(如车祸、异常天气等)所致。LightGBM模型对于这些异常情况的预测效果不是很好,但总体预测精度较高。
为进一步分析LightGBM模型的预测性能,将该模型的RMSE、MAE、MAPE及耗时与KNN、RF、SVR算法进行对比,结果见表6。

表6 各路段不同模型预测效果评价
从表6可看出:1) LightGBM模型预测值的RMSE、MAE低于KNN、RF、SVR模型,除路段3的MAPE略高于RF模型外,其他路段均低于KNN、RF、SVR模型。对于路段1和路段2,KNN、RF、SVR模型的3个指标预测精度大致相同;对于路段3,SVR模型预测值的RMSE明显大于其他模型;对于路段4,RF、SVR模型的预测精度类似,KNN模型的预测精度低于其他模型。2) 从运算耗时来看,KNN模型因其简易的计算原理,耗时最短,其次是LightGBM模型,两模型的耗时差距较小,都小于1 s;SVR模型的耗时为10~20 s,排名第三;耗时最长的是RF模型,路段1~3的运算时间在40 s以上。总体来说,RF、SVR模型的运算时间远高于KNN、LightGBM模型,不适用于实时预测;KNN的耗时最短,但与LightGBM模型的差距较小,而后者的预测精度和稳定性优于前者。综合来看,LightGBM模型满足高效、准确的实时预测要求,是性能最好的高速公路行程时间预测模型。
4 结语
针对高速公路行程时间预测中存在的数据来源单一、预测时效性不足等问题,本文提出一种基于路警融合数据的LightGBM模型,实现高速公路行程时间的高效预测。利用ETC门架、视频卡口多源融合关联数据,采用该模型进行预测,与其他传统机器学习算法相比, LightGBM算法的综合性能最好,有助于节省计算与存储资源,可应用于高速公路路网级的行程时间实时预测。但该预测模型采用的训练和测试路段线形较平顺,且采用的是交通畅通条件下数据,后期需利用更多不同路段、不同交通状态下数据进行模型验证,以推广到整个高速公路网,提高路网整体监测与管理能力。
