一种面向时序数据的多品种小批量生产线性能预测模型研究
2022-12-12张少勋时思远
张 维,张少勋,吴 燕,时思远
(西北工业大学,西安 710072)
产研结合的多品种小批量生产模式是目前企业主要的生产模式,其具有生产周期不一致、物料种类多、生产工序复杂等特征。这些特征导致企业不能保障和准确预测生产周期和生产效率,从而影响了交货周期。通过事先预测生产线的在制品数量、生产周期等的性能指标,并对生产计划进行预调整,对保障生产周期,提高生产管理水平具有重要的指导意义。
近年来,对于生产线性能预测方面的研究主要分为仿真方法预测和机器学习模型预测。在仿真方法方面,袁杰[1]以复杂制造过程质量问题的预测为研究对象,分别针对模型Petri网预测方法、诊断方法以及模糊着色Petri网推理方法进行了分析改进,为生产策略的调整、纠正措施的采取提供了决策依据,加快了系统响应速度。Azadeh等[2]提出了一种基于计算机仿真和人工神经网络的算法,提供了更高的预测精度。钱鑫森[3]以排队系统理论为基础建立基于G/G/m/b排队模型的半导体封装测试生产线性能预测模型,提高了预测准确度。Zhang等[4]基于DELMIA/Quest软件的生产线仿真技术,对直升机复合材料主桨叶生产线进行建模仿真,针对仿真中发现的问题,从生产班次、工艺流程、设备配置等方面提出改进方案,并通过了仿真验证。由于多品种小批量生产线的复杂性,仿真方法预测模型的建立是非常的困难的。在机器学习模型预测方面,Tercan等[5]使用一种基于深度学习的持续学习方法,可在注塑成型中跨多个不同产品进行质量预测。陈雪芳等[6]针对处于不确定性环境下可重入系统的产出预测问题,将小波优良的逼近性质以及神经网络的自学习自适应性质相结合,提出了遗传小波神经网络对半导体生产线的产出进行预测,验证了模型的优良性。赵婷婷等[7]将基于数学规划模型融入BP神经网络,提高了半导体生产线产出率预测的效率和准确度。王令群等[8]利用RBF神经网络对半导体生产线建立预测模型,对生产线输出进行预测。谈宏志等[9]使用BP神经网络和LMSA混合算法建立车间调度模型,得到较优的车间调度模型。王宏愿[10]采用PSO–CV–SVM建立锻造生产线能耗模型,得到更加准确的锻造生产线的能耗预测情况。
生产线性能预测的训练数据为时序数据,面向时序数据预测的问题,国内外学者也做出了众多研究。周晓莉等[11]采用DBN(Deep belife network)对赤潮类时序数据的趋势性进行预测。王昭旭[12]针对水泥生产过程中存在时变时延性、不确定性和非线性,难以建立精确的能耗预测模型的问题,提出了基于时间序列深度信念网络的水泥生产单位能耗预测模型。Kuremoto等[13]将受限玻尔兹曼机和多层感知器组合为DBN来预测混沌时间序列数据,从预测精度的角度分析,模型性能有所提高。
通过对目前使用BP神经网络进行生产线性能预测的研究分析发现,在预测模型的建立过程中,对数据的时序性的研究较少,并在BP网络训练过程中多采用SGD、ADAM(Adapt with momentum)等传统更新参数的方法,预测结果精度仍有待提高。
针对神经网络在多品种小批量生产模式的性能预测方面的不足,本文采用DBN和RNN(Recurrent neural network)结合的循环深度信念网络C–DBN,构建生产线性能预测模型,对多品种小批量产品的生产线性能进行预测;并针对模型训练方法不足的问题,提出了AMM算法,对传统基于随机梯度下降算法的训练方法进行改进,达到了算法稳定性以及收敛速度优化的目的,最终实现对生产线性能的有效预测。
1 多品种小批量生产线特征分析
1.1 多品种小批量生产线特征选取
多品种小批量生产模式的特点是零件种类多、混合排产难度大、零件的品质不容易保障、所需设备多、设备工作量失衡等,从而难以如期交货。本文采用深度学习的方法,利用深度学习模型强大的自动拟合能力,找出多品种小批量生产线历史数据之间的某种潜在规律,从而进行生产线性能的预测。对于模型的输入参数而言,在采用DBN和RNN进行预测时,主要选择设备信息、加工工件信息等12个因素作为样本集的输入特征。
(1)设备对生产线性能的影响因素包括:平均无故障加工时间(Mean time between failures,MTBF)、计划停机时间 (Scheduled downtime,SDT)、计划停机频率 (Planned shutdown frequency,PSF)、设备利用率 (Utilization ratio,UR)、非计划停机概率 (Unscheduled shutdown probability,USP)、停机时间(Unplanned downtime,UDT)。
(2)加工工件对生产线性能的影响因素包括:工件的加工种类 (Work piece,WP)、每种工件的实际投产数(Work piece number,WPN)、工件加工的准备时间(Set up time,SUT)、工序的加工用时 (Processing time,PT)、工件加工所需原材料的种类(Raw material,RM)、工件加工合格率(Qualification rate,QR)。
基于上述因素的生产线输入的总特征(Input)为
Input ={MTBF,SDT,PSF,UR,USP,UDT,WP,WPN,SUT,PT,RM,QR} (1)
对于模型输出层,生产线性能常用的绩效量度分别是在制品数 (Work in process,WIP)、生产周期时间 (Cycle time,CT)以及生产效率 (Throughput,TH)。这3种参数存在一定的相互关系,即WIP = CT×TH,因此只需对其中两个参数进行预测即可。本文选择对生产在制品数量以及生产周期进行预测。
1.2 时序数据分析
由于生产线的特征参数是时变的,这些时变参数的累积变化会对加工生产过程中的生产效率以及生产周期等性能产生影响,因此不能仅根据当前时刻的参数值对生产线性能进行预测,需结合一段时间内的生产数据进行综合考虑。如根据生产排程,不同时刻生产线加工的产品种类不尽相同,相对应的加工工序、占用设备的比例以及加工时间等均将发生变化,且随着时间的变化生产线设备因素等也将会变化,若仅根据某一时刻的数据无法对生产线性能进行较准确的分析预测。针对该特点,本文采用面向时序数据的深度信念网络模型对生产线的性能进行预测。
计算生产线所加工各个零件的工序的平均加工时间 (Average time of processing,ATP),以每个零件的工序平均加工时间的最小公倍数作为预测模型的时序数据的最小时间节点,保证在读取数据时加工工件在其目前加工工序中处于完成状态,以确保输入数据的准确性。即模型输入数据时间间隔 (Time interval,TI)为
TI = [ATP1,ATP2,…,ATPn](2)式中,ATPn表示第n种零件的平均工序加工时间。
2 基于时序数列C–DBN模型的建立
2.1 生产线性能预测C–DBN模型结构
面向时序数据预测的深度信念网络C–DBN与传统DBN网络结构不同之处在于: (1)输入层为时序数据; (2)该网络的输出要经过RNN网络。将RNN模型加在最后的RBM层后面,构建基于C–DBN的生产线性能预测模型,如图1所示。
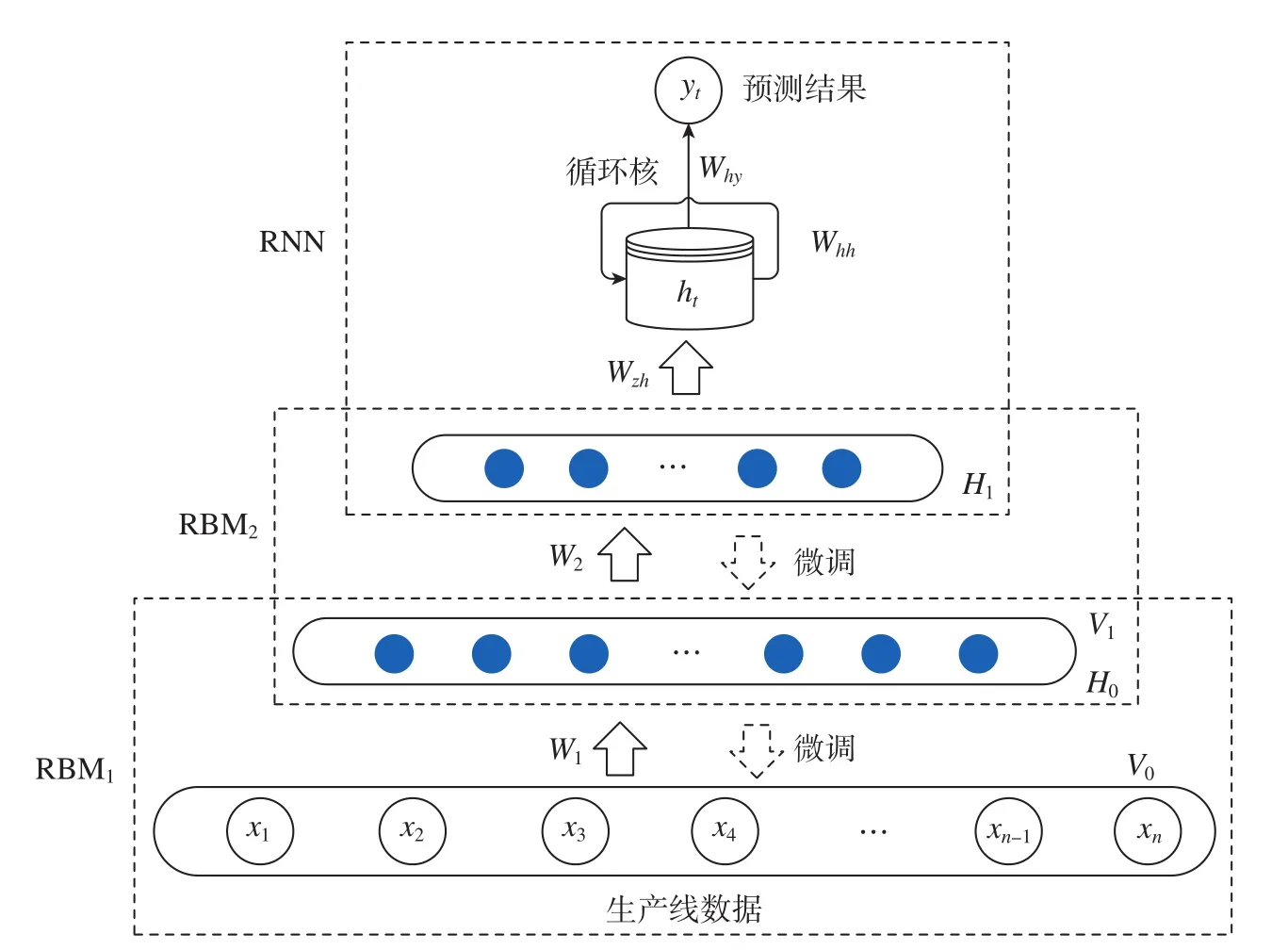
图1 基于C–DBN的生产线性能预测模型结构Fig.1 Structure of production line performance prediction model based on C–DBN
在生产线性能预测模型中,对于时间序列的输入特征,使用RNN模型作为输入数据的特征二次提取(DBN为第1次提取,提取的是数据空间维度信息;RNN为第2次提取,提取的是数据时间维度的信息)。在RNN模型中,使用了RNN循环核实现参数的时间共享。本文把DBN中RBM层的输出作为RNN层的输入,但当数据要输入RNN层时,将生产线的前t个时刻的数据作为一次输入数据,把这t个过程的最后一个实际结果作为数据标签。即循环核的时间展开步数为t,每步送入RNN的特征个数为最后一个RBM输出数据的维度。RNN模型如图2所示。

图2 RNN模型及时间步展开Fig.2 RNN model and time step expansion

式中,Zt为RNN 输入特征;ht–1为上一时刻的记忆体输出;WZh为输入特征的权值;Whh为记忆体的权值;bh为记忆体偏置;ht为t时刻的记忆体输出;Why为输出权值;by为总输出偏置;yi为预测值。
2.2 基于AMM算法的C–DBN模型调优
首先采用对比分歧算法训练使得各个RBM得到其最佳权重、偏置,但由于RBM在训练时是分离、逐个训练的,因而相对于整个生产线性能预测模型而言,必然存在一定的误差。必须经过后期的调优对每个受限玻尔兹曼机的权重做进一步的改进,得到整体最佳权重从而保证预测的准确度。
针对传统的调优方法存在的收敛速度慢以及精度不足的问题,提出了一种基于AMM算法的调优方法。首先充分利用动量的思想,将ADAM算法的前一迭代点处的方向矢量与当前迭代点处的方向矢量加权求和所得的矢量,作为下一个迭代点处的搜索方向,即权重或偏置的调优方向;其次结合RMSprop算法中基于范数的思想,加速基于AMM的调优算法的收敛速度,提高了精度。结合生产线预测模型的特点,基于AMM算法的调优具体流程,如图3所示。

图3 基于AMM的生产线性能预测模型调优算法Fig.3 Optimization algorithm of production line performance prediction model based on AMM
步骤1。初始化权重和偏置的一阶矩估计值以及二阶矩估计值,即

式中,vw、vb分别为权重、偏置的偏一阶矩估计更新;sw、sb分别为权重、偏置的偏二阶矩估计更新。
步骤2。根据生产线性能预测值与真实标签值的平均绝对误差值ε,采用式(5)分别计算生产线特征的m个样本的权重及偏重的平均梯度gk,即

式中,i为样本序号;L为网络深度;θ为参数权重w或偏置b;k为迭代次数,初始值为0;x(i)为t时刻的输入样本;y(i)为t时刻的预测标签值;f为Sigmoid函数。
步骤3。式 (6)和 (7)为更新偏一阶矩估计,即
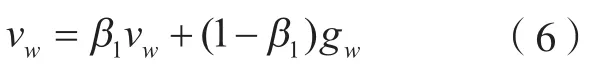

更新偏二阶矩估计为
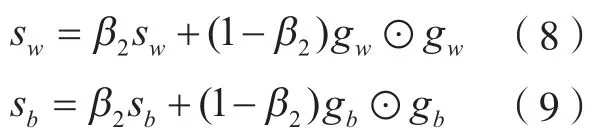
式中,β1为一阶矩估计指数衰减速率,β1=0.9;β2为二阶矩估计指数衰减速率,β2=0.999;gw、gb分别为权重、偏置的梯度值。
步骤4。修正权重和偏置的一阶、二阶矩估计值初始化为0所导致的误差,一阶矩偏差修正为
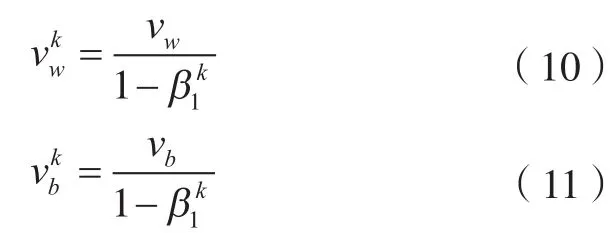
式中,vkw,vkb分别为权重、偏置一阶矩的偏差修正。二阶偏差修正为

式中,skw,skb分别为权重、偏置二阶矩的偏差修正。
步骤5。计算出算法ADAM方向为

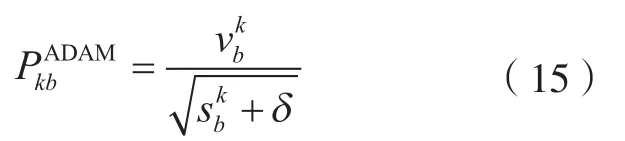
式中,PkwADAM、PkbADAM分别为权重、偏置的ADAM算法修正方向,其中,P0ADAM= 0;δ为常数,取值 10–8。
步骤6。算法AMM第k+ 1次迭代的更新量,即
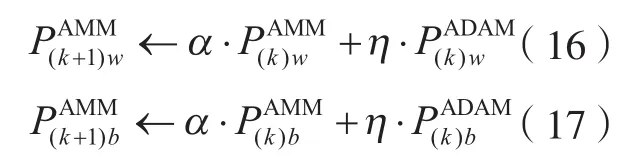
式中,、分别为第k+1次迭代时权重、偏置的AMM算法修正方向,且= 0;α为历史迭代步权重,α= 0.9;η为学习率,初始化值为0.001。
步骤7。权重、偏置参数更新,即

式中,w(k+1)为第k+ 1次迭代后的权重;b(k+1)为第k+ 1次迭代后的偏置。
通过上述步骤可知,基于AMM的调优算法在ADAM算法基础上,将ADAM算法的前一迭代点处的方向矢量与当前迭代点处的方向矢量加权求和所得矢量,作为下一个迭代点处的搜索方向。分别修正预测模型的权重及偏置值,以提高模型的收敛速度及精度。
3 基于C–DBN的生产线性能预测
结合生产线性能预测数据的时序性特征以及生产线性能的衡量指标,搭建基于AMM的模型调优算法的生产线性能预测模型,如图4所示。
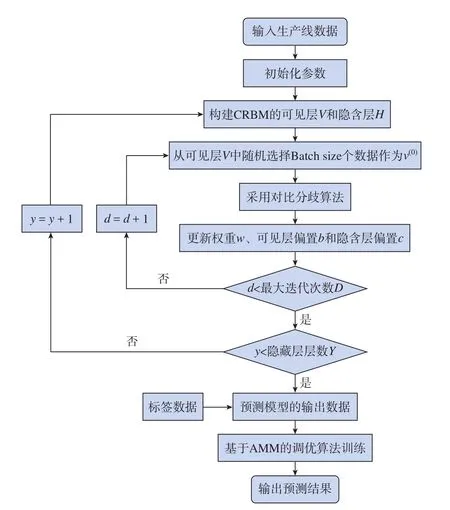
图4 生产线性能预测模型训练过程Fig.4 Training process of production line performance prediction model
基于AMM算法的生产线预测C–DBN模型具体训练步骤如下。
步骤1。对生产线性能特征数据以及生产线性能预测指标数据进行数据标准化处理,采用z–score标准化,即

式中,x为样本值;μ为x的均值;σ为x的标准差。
步骤2。生产线性能预测模型迭代次数、模型层数试验确定,固定训练生产线预测模型各个结构参数。
步骤3。采用对比分歧算法,训练得到每个RBM的最佳权重、偏置。
步骤4。采用以下a ~ h有监督调优流程,得到生产线预测模型全局最佳权重、偏置:
a.初始化预测模型输出层(RNN神经网络)的权重wzh、whh、why以及偏置 , 为

式中,size1为最后一个RBM的隐含层神经元个数;size2为记忆体个数;size3为输出层神经元个数。
b.根据无监督训练阶段所得RBM的最佳权重,输入生产线特征数据,逐层计算得到各个隐含层值。
c.根据输出层的权重wzh、whh,why以及偏置bh、by,计算出生产线性能的预测结果yi',即
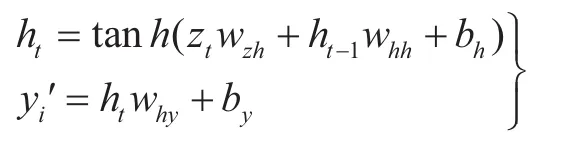

式中,zt为最后一层隐含层的输出;yi'为预测值。
d.将生产线性能预测值与真实标签值进行对比,计算两者的平均绝对误差值ε,即

e.调用基于AMM的调优算法(2.2节中的步骤1~7),根据误差值ε反向逐层调整各层权重、偏置。
f.重复步骤e直到误差值从上到下逐层传递完毕。
g.根据重构的权重和偏置,输入生产线特征数据,逐层计算得到该权重和偏置下的生产线性能预测值。
h.重复步骤d直到迭代次数达到最大迭代次数。
步骤5。得到完整生产线性能预测模型。
由于生产线的时序性,在模型进行有监督训练的过程中,该模型输入训练数据是连续时刻下的数据,每连续t个时刻的数据进行1次输入,最后1个时刻的生产线性能数据作为训练的标签,完成1次监督训练过程。
4 实例验证
根据前文对多品种小批量生产线特征的分析,以某电子产品的加工生产线的部分数据参数为例 (表1),采用基于AMM的C–DBN模型对该生产线性能进行预测研究。
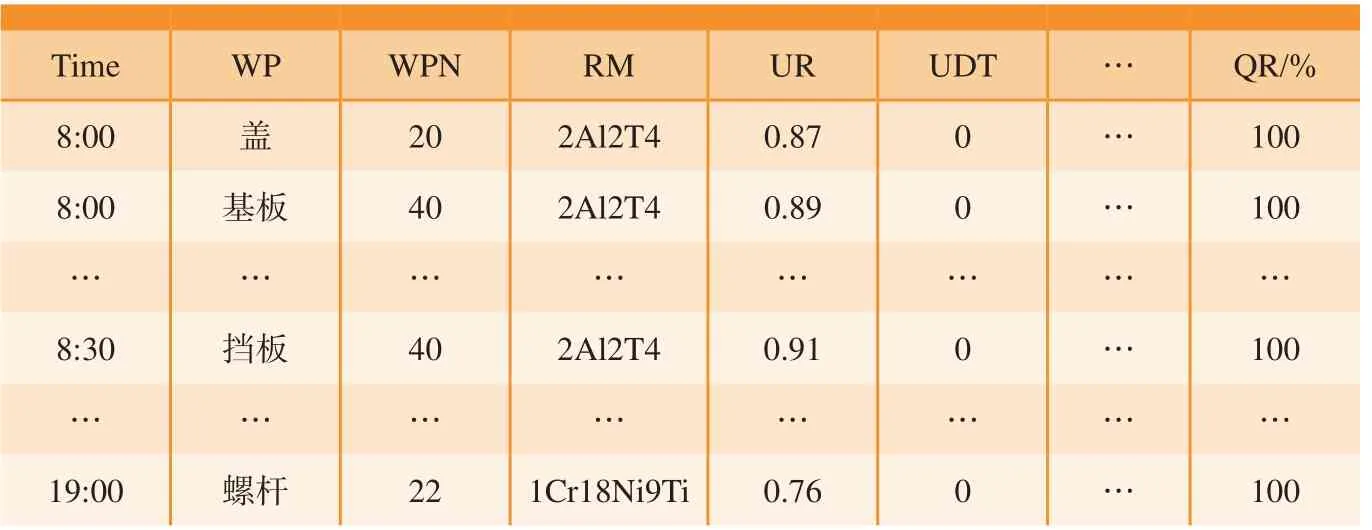
表1 生产线性能预测研究部分数据Table 1 Partial data of production line performance prediction research
4.1 生产线性能预测模型参数确定
(1)时间步长分析。首先通过试验来确定时间步的个数,C–DBN模型的时间展开步分别取2、3、4。
从表2可以看出,随着时间展开步数的增多,RMSE、MAE、MRE 3种误差函数总体逐渐减小,但时间展开步数增加的同时训练时间也会逐步增大。从生产线性能拟合度R和预测趋势准确度DA角度分析,预测趋势准确度DA的变化和性能拟合度R的变化,基本可以忽略不计。综合考虑误差函数的减小幅度、训练时间的增加幅度以及预测准确度和拟合程度,选择结合3个时刻的数据作为输入数据。因此生产线性能预测模型的输入采用3个连续时刻的数据。

表2 输入数据权重的确定Table 2 Determination of input data weight
(2) 模型层数分析。在不同的C–DBN模型网络深度上依次试验,记录相应的评价标准误差值、拟合度以及预测趋势准确性的数值。最后,综合3种评价标准误差值、拟合度、预测趋势的准确性以及训练时间找出全局最优解。
RBM网络深度在1~4层之间上依次试验,试验结果如表3所示。从3种评价标准误差角度出发,当C–DBN网络深度为3时,即隐含层层数为2层时,3种评价标准误差值均达到最小值,随着模型层数的增大误差逐渐增大且训练时间成倍增加。从生产线性能拟合度R以及预测趋势准确度DA角度分析,隐含层层数为2时,预测的准确性也是最高的。因此,可以确定C–DBN模型深度为3时,是C–DBN网络的最优解。

表3 生产线预测模型层数分析Table 3 Analysis of model layers of production line prediction model
4.2 结果分析
(1)与传统预测方法对比。本文将改进后C–DBN模型与传统DBN模型在生产线预测方面的性能进行对比。
以生产线在制品数量为例。将DBN模型的预测值与实际值,以及C–DBN模型的预测值进行对比,如图5所示。可以看出,DBN模型对生产线性能预测过程中,出现了梯度下降过度的现象,相比较C–DBN模型的预测值与真实值之间的吻合度较高,能较准确地对生产线性能进行预测。
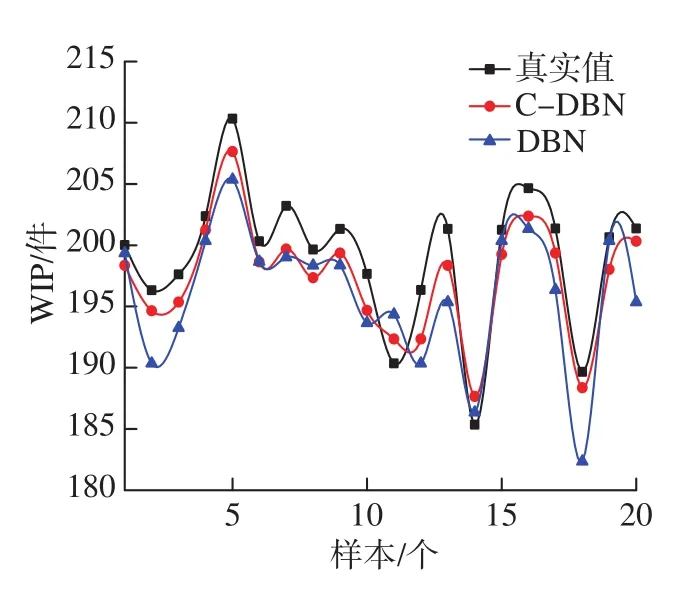
图5 C–DBN与DBN预测结果对比Fig.5 Comparison of C–DBN and DBN prediction results
(2)预测值与真实值对比。根据试验所得模型参数进行训练预测,根据生产效率预测值以及生产周期预测值,计算得到在制品数量值,分别将3个指标的预测值与真实值进行对比以衡量模型的能力,如图6所示。可以看出,3个衡量指标的预测值与真实值之间均存在一定的误差,但各个衡量指标的总体趋势预测准确度较高,基本符合真实趋势。验证了该生产线性能预测模型可有效地对生产线性能进行预测,且具有较高的准确度。
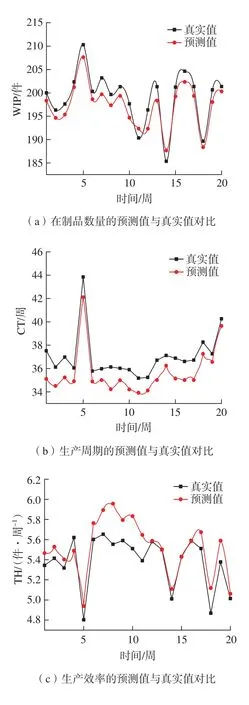
图6 生产线性能预测值与真实值对比Fig.6 Comparison between predicted value and real value of production line performance
5 结论
针对多品种小批量生产模式零件种类多、混合排产难度大、零件的品质不容易保障、所需设备多、设备工作量失衡等特点,本文采用深度学习的方法进行生产线性能预测。以生产线的在制品数量、生产周期、生产效率为性能指标,建立了面向时序数据的基于C–DBN的生产线性能预测模型,采用基于AMM算法的有监督训练方法,实现了面向时序数据的生产线性能预测模型的有监督训练调优,并通过实例验证了该模型的有效性和准确性。
