基于一阶段目标检测网络头部算法研究
2022-12-11肖贵明丁德锐梁伟魏国亮
肖贵明,丁德锐,梁伟,魏国亮
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
计算机视觉中,目标检测是最基础的任务之一。近年来,目标检测发展迅速。形成两阶段目标检测和一阶段目标检测两种形式。两阶段目标检测中,RCNN[1]通过选择搜索生成区域,并利用深度网络提取特征。SPPNet[2]提出空间池化层对RCNN 进行加速;Fast-RCNN[3]提出RoI pooling 提升性能和速度;Faster-RCNN[4]提出RPN 生成RoI;R-FCN[5]提出position sensitive RoI pooling 进行处理位置变动问题;FPN[6]建立从下到上、从上到下、横向连接的模块形式;Mask-RCNN[7]提出RoIAlign。一阶段目标检测中:SSD[8]和YOLO[9-11]直接预测对象类别和位置;Focal loss[12]针对一阶段类别不平衡问题,并提出RetinaNet;Fcos等[13-16]使用anchor-free 的方式进行目标检测。
现下,目标检测网络框架正陆续推出,学界对两阶段头部网络的研究是其重点之一。Cascade RCNN[17]根据不同的IoU,提出级联的检测头;Mask RCNN 增加额外的语义分割网络头部,提升性能;IoU-Net[18]增加头部分支来预测IoU;Double-Head[19]研究发现fc 层更有利于分类,使用双头网络对物体进行检测。近年来,一些两阶段网络框架的网络头部变动如图1 所示。图1(a)使用全连接头进行分类和定位;图1(b)使用全卷积头进行分类和定位;图1(c)和图1(d)是Double-Head 提出的使用卷积和全连接相互作用的双头网络。

图1 两阶段目标检测头部变化图Fig.1 Two-stage object detection head change figure
根据两阶段网络Double-Head 的研究,fc层更加适合分类,主要由于分类具有空间敏感性。一阶段网络没有两阶段网络的RoIAlign模块,前向网络传入的特征到网络头部时无法减少大量参数,故一阶段网络分类头部使用fc时会产生大量的参数,极大地减少一阶段网络头部改进的可能性。
再者,本文将一阶段网络RetinaNet 的网络分类头的热力图进行输出,如图2~图4 所示。图2~图4中,左图均为图像刚进入网络分类头部的热力图输出,右图均为经过网络头部后的热力图输出。可以看出,经过网络头部后,使得关注点能较好地集中在其中的一部分。但也出现以下2 个问题。其一,经过网络头部后,由于图中识别的物体范围太大、含有较多的背景,关注点无法集中在识别的物体上;其二,头部网络提取的特征反映在原图中,有些物体识别不到或对物体识别的信息较少。

图2 网络头部热力图Fig.2 Network head heat map

图3 网络头部热力图Fig.3 Network head heat map

图4 网络头部热力图Fig.4 Network head heat map
综上所述,本文针对一阶段网络RetinaNet 的分类头部进行改进,提出双分类头,主要由2 个分类头部组成:循环通道注意力模块头(Circulatory Channel Attention Module);多头注意力机制模块头(Multihead attention mechanism module head)。其中,循环通道注意力模块头用于着重增强当前提取特征,在进行分类时能够对物体进行准确识别,在关注物体本身的同时减少对背景的关注。多头注意力机制模块头具有fc的特性,同时又具有自注意力的性能,在获得更大空间性的同时,加强对物体本身的关注与识别物体本身。本文有以下3 个创新点:
(1)一阶段网络头部引入池化层模块,以此减少参数量。
(2)使用双分类头,提出循环通道注意力模块,将NLP 中的多头注意力机制模块有改进性地应用到本文中。
(3)2 个网络头部进行自适应权重分配,进行输出。
1 基于RetinaNet 的双分类头
1.1 分析网络框架
本文采用的目标检测网络框架是在RetinaNet基础上加以改进的,如图5 所示。整体来说,由主干网络、特征金字塔(FPN)和网络头中的分类、定位两个任务分支、三大模块所组成。本次选取ResNet101为主干网络。

图5 网络结构图Fig.5 Network structure
特征金字塔是从主干网络P3到P6构造得到的。研究中,l表示特征金字塔的层数,第Pl层大小为该层输入图像分辨率倍,图5 中只简单地显示了其中的3 层。特征金字塔的每一层都是用来检测大小不同的物体,从P3到P6的金字塔中参考框的面积大小为322到2562,其中第l层参考框大小的面积为第l层采样率2l乘4 的平方大小。这里将长宽比为{2∶1,1∶1,1:2}三种比率使用在每一层上,同时在同一层增加了三种参考框的面积大小,故每层一共A=9 种参考框。
网络头的分类和定位两个分支是全卷积分支。定位分支是无关类别的,通过4个W∗H∗256 卷积层,具有W∗H的空间位置数,用来回归A个边界框的偏移量,其中每个框有4 个偏移量,分别表示左下、右上两个点相对偏移量、或者中心点和长宽的相对偏移量,定位分支最后输出大小为W∗H∗A∗4。分类分支用来预测每张图片的每个特定空间位置的类别,由图5 可知,本文在分类分支上使用2 个分类头并将2 部分进行自适应权重加权,得到的空间位置数为W∗H,每个位置有A个边界框,K个种类,预测该位置属于某种类别的可能性,故分类分支大小为W∗H∗A∗K。
1.2 说明循环通道注意力模块头
图6 为通道注意力模块。通过将输入的特征图进行平均池化和最大池化,即使得输入特征变成B∗1∗1∗C,并通过Conv进行通道数的降维,减小参数量,在此基础上将平均池化和最大池化得到的特征进行相加,再归一化得到最终的结果。通过通道注意力模块可以对得到的特征进行区分,使其重点关注某些特征,减小关注的特征范围。
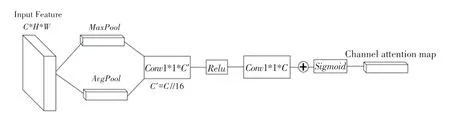
图6 通道注意力模块图Fig.6 Channel attention module figure
图7 为循环通道注意力模块,选择通道注意力模块是由于该部分在网络头部,语义特征足够强,只需要对提取得到特征的物体部分进行重点关注。循环通道注意力模块中进行了以下3 点操作:
(1)引入恒等变换。图7 中为输出特征和通道注意力所得到的结果相乘后和输出特征进行相加,恒等变换的使用是为了保持当前性能的同时,尽可能地增强性能,同时保持网络的稳定性。
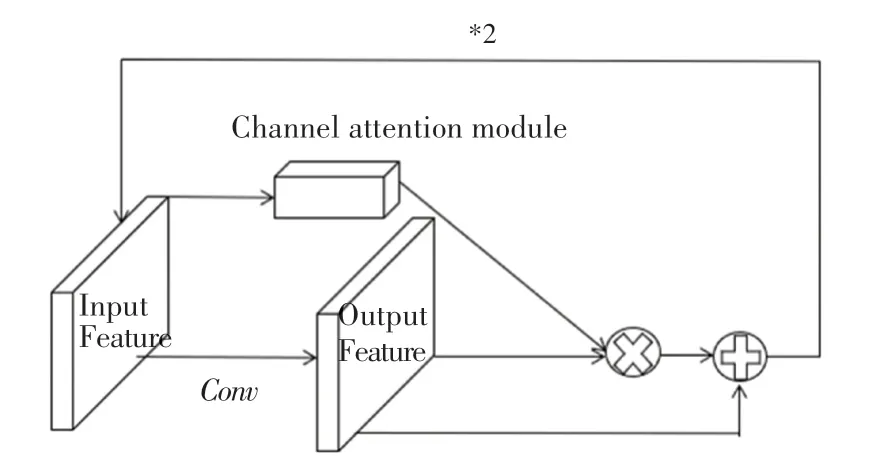
图7 循环通道注意力模块图Fig.7 Circulation channel attention module figure
(2)通道注意力模块使用的是未经过Conv变换的输入特征,由于输入特征相比于输出特征保留有更多的细节,所以将通道注意力模块使用在输入特征上,可以对每个通道做更细致的分析,得到的结果更加地准确。
(3)使用结构循环,为了通过多次操作对重点关注到的特征进一步加强,对不应关注的特征进一步弱化,使得提取得到的特征更加地准确。
1.3 阐述多头注意力机制模块头
多头注意力机制如图8 所示。图8 中为多头注意力模块头部为1 时的情况(self-attention)。多头注意力是在NLP 的Transformer 中提出的,旨在解决RNN 中数据不能并行所带来的运行速度较慢的问题。这里,xi表示输入数据,通过嵌入层进行embedding得到ai。由此推得的数学公式可写为:

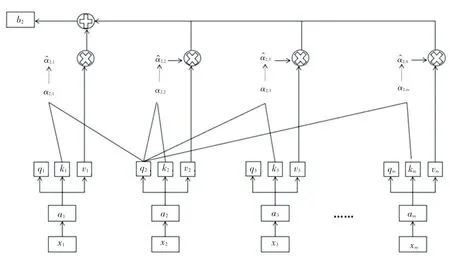
图8 多头注意力机制Fig.8 Multi-head attention mechanism
对输入ai进行变换。相应数学公式分别如下:

得到qi、ki、vi。将得到的3 个输入进行向量点积,即:

计算得到aj,i后,对其进行归一化,表示为:


如上计算后得到输出bj。这种自注意力机制具有很好的空间性,同时对自身的重要部分、即该识别的物体进行了重点关注,能够很好地满足局部特征和全局特征的提取和使用。
图9 为多头注意力机制模块头。多头注意力机制模块头总共由3 部分组成,分述如下:
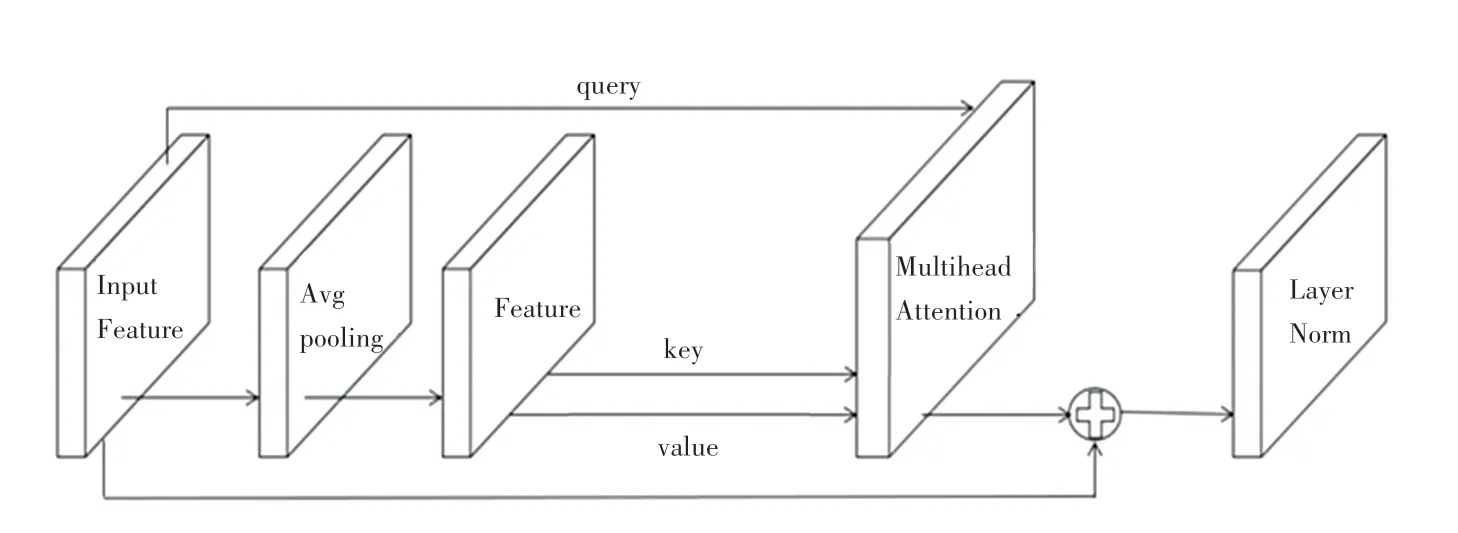
图9 多头注意力机制模块Fig.9 Multi-head attention mechanism module
(1)平均池化。由于一阶段目标检测网络不具有两阶段目标检测网络的RoIAlign模块,将传入到网络头部的特征进行再提取,减少大量传入头部的特征,故无法直接使用fc层。研究中可将传进网络头部的特征进行平均池化,从原先的W∗H缩小到N∗N,减小参数量。同时采用平均池化是由于到网络头部时,语义信息强,这时候使用平均池化能带来更好的性能。
(2)使用多头注意力机制,利用其本身具有良好的空间性和自注意力机制,能够更好地识别到物体。其中,多头注意力机制中的输入query、key、value分别是输入特征,大小为B∗W∗H∗C,进行池化后的特征大小为B∗N∗N∗C和D∗N∗N∗C。输入特征使用了恒等变换,保证性能的同时,加快收敛速度和网络稳定性。由于分类头部对位置信息不敏感,所以在使用多头注意力时并未使用位置信息。
(3)Layer Norm,通过多头注意力输出的特征为B∗M∗C,M为H∗W,将C个通道作为一个样本,对M个位置的C个通道进行归一化,使得每一个位置不同的通道具有和为1 的权重,进一步加快训练速度。
1.4 实现头部结合
本文中2 个网络头部的偏重点有所不同,循环通道注意力模块头更加偏向能准确识别物体,减少背景混入;多头注意力机制模块头偏向于通过更大的空间性和自注意力将物体识别出来。所以将2 个网络分类头部进行自适应加权。通过对2 个头部进行平均池化生成B∗1∗1∗C的特征,进行合并,通过softmax进行归一化,将得到的权重和各自的网络头部特征进行相乘,相加得到最终的分类输出,让网络自身来决定该偏向于哪一部分,从而使性能更好。
2 实验结果与分析
2.1 实验数据集和评价指标
PASCAL VOC 数据集,包含20 个类别,加上背景、共有21 个类别。其中,VOC2007 共包含了9 963张图片:5 011 张为训练图片,4 952 张为测试图片。VOC2012 共包含了11 540 张训练图片。本次实验联合VOC2007 和VOC2012 训练集进行训练,在VOC2007 测试集上进行测试。
MSCOCO 数据集总共有80类,本次实验使用MSCOCO2017。其中,训练集有118 287 张图片,验证集有5 000 张图片,测试集一共有40 670 张图片。本次实验通过将检测结果上传到评估服务器来报告测试结果。
本次实验指标使用的是mAP。通过计算召回率和精确率,并绘制成PR曲线进行统计。指标的数学定义式可写为:

其中,真阳性(Ture Positive,TP)表示正确识别为物体样本;真阴性(True Negative,TN)表示正确识别为背景样本;假阳性(False Positive,FP)表示背景样本被识别为物体样本;假阴性(False Negative,FN)表示物体样本被识别为背景样本。
2.2 模型与参数设置
本文实验基于ubuntu18.04 系统,采用Pytorch深度学习框架和Python 编程语言,硬件使用英伟达GeForce GTX 1080 显卡。以ResNet 为主干网络,每个batch大小为2 张图片,使用SGD 进行优化,动量为0.9,初始学习率为0.002 5。VOC0712 运行12个epoch,MS COCO2017 运行24个epoch,第16个epoch和第22个epoch分别出现了学习率的下降,下降后的学习率为0.000 25和0.000 025。
2.3 实验结果与分析
本文对提出的双分类头进行了实验验证,表1为近年来一些网络框架在VOC0712 中的实验结果。由表1 可以看出,相比于作为baseline 的RetinaNet,本次研究提出的双分类头网络构架RetinaNet-DCH具有很高的网络性能,mAP上达到了80.8,提高了3.5%。

表1 VOC0712 数据集实验结果Tab.1 VOC0712 dataset experimental results
表2~表6 为本次双分类头的消融实验。由表2 可知,双分类头权重自适应相比于手动设置权重,能达到更好的效果。由表3 可知,循环通道注意力模块头循环次数为2 时效果最好。表4 的实验结果表明多头注意力机制模块头中使用单头就能达到理想的效果。表5 中使用了不同大小的平均池化,当使用16×16时,效果好、参数少。表6 分别对2 个头部分开实验,相比于循环通道注意力模块头而言,实验表明多头注意力机制模块头能带来更好的实验效果,2 个网络头部一起使用时性能最好。

表2 VOC0712 数据集权重分配实验结果Tab.2 VOC0712 dataset weight distribution experimental results

表3 VOC0712 数据集循环次数实验结果Tab.3 The experimental results of the number of cycles of the VOC0712 dataset

表4 VOC0712 数据集多头实验结果Tab.4 VOC0712 dataset multi-head experimental results

表5 VOC0712 数据集平均池化实验结果Tab.5 Average pooling experimental results of VOC0712 dataset

表6 VOC0712 数据集头部实验结果Tab.6 Experimental results of the head of the VOC0712 dataset
表7 和表8 是运用MSCOCO2017 数据集后的实验结果。表7 在ResNet50 上进行实验,表8 在ResNet101 上进行实验,表8 中RetinaNet-DCH-MS为增加了多尺度训练的结果。实验表明本文提出的RetinaNet-DCH 网络框架具有很高的性能。相比于两阶段网络Double-Head-Ext,一阶段网络RetinaNet-DCH-MS 只相差了0.2%的mAP。
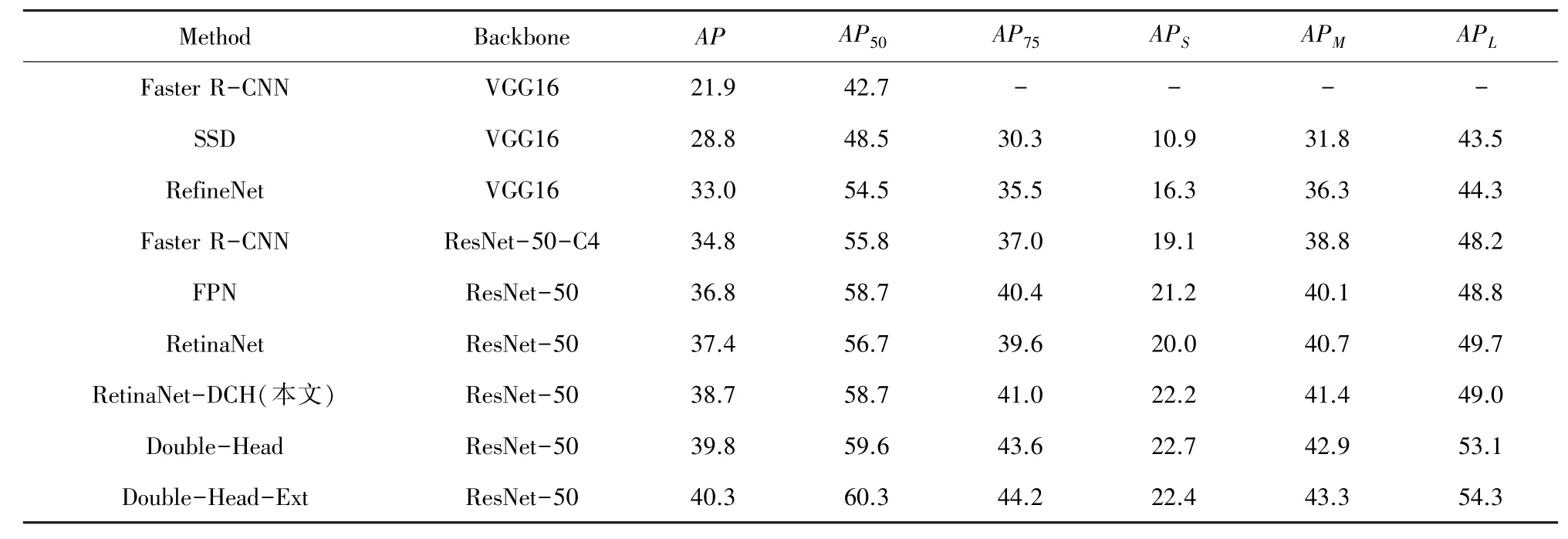
表7 MSCOCO2017 数据集实验结果Tab.7 Experimental results on MSCOCO2017 dataset

表8 MSCOCO2017 数据集实验结果Tab.8 Experimental results on MSCOCO2017 dataset
图10~图12 为在COCO 数据集上、RetinaNet网络使用了双分类头后网络头部的热力图输出,左图为最初进入网络头部的热力图输出,右图为经过网络头部后的热力图输出。可以看出,在经过网络头部前的热力图相差不大,但在经过网络头部后的热力图输出相差很大。其中,2 个比较明显的提升在于:相比于之前的网络框架能更准确地识别到物体本身;对于识别到的物体能够更加地精准,不会有大量背景混入其中。
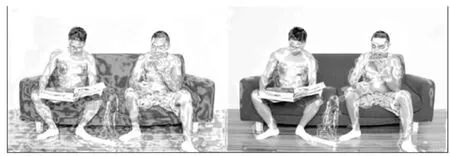
图10 网络头部热力图Fig.10 Network head heat map

图11 网络头部热力图Fig.11 Network head heat map

图12 网络头部热力图Fig.12 Network head heat map
图13 为在COCO 数据集上物体原图的检测输出,图13(a)为RetinaNet 网络输出,图13(b)为RetinaNet-DCH 网络输出。从图13 中可以明显看出,改进后的网络框架目标定位和识别更加精准,识别到更多的物体的同时,分类的置信度也更高,特别对于小物体的识别准确率提升明显。

图13 COCO2017 数据集上的结果图Fig.13 The result graph on the COCO2017 dataset
3 结束语
本文对一阶段目标检测网络头部输出热力图,发现经过网络头部后提取的特征存在着识别不到物体和识别物体时范围太大两个问题,同时结合现如今两阶段目标检测头部研究成果,对一阶段目标检测网络头部进行改进提出了双分类头:循环通道注意力模块头、多头注意力机制模块头。其中,循环通道注意力模块头在识别物体时能够减小识别范围,准确识别物体。多头注意力机制模块头则通过利用多头注意力机制能够获得更好的空间性和自注意力,更好地识别到物体。利用池化可减少参数量,满足了可操作性。通过自适应权重操作,网络对2 个头部获得最佳的权重分配、结合。本文基于RetinaNet 在VOC0712 和COCO2017 数据集上进行实验,在mAP上达到了80.8%和41.7%,分别提升了3.5%和2.4%。
