基于静态分析的密码协议业务逻辑缺陷检测方法
2022-12-05中国人民解放军63891部队王震周超苗泉强樊永文
中国人民解放军63891 部队 王震 周超 苗泉强 樊永文
本文介绍了基于静态分析的密码协议业务逻辑缺陷检测的具体方法,从检测框架出发,引出了方法实现的三个关键问题,然后对模型代码解析、协议代码信息抽取以及映射关系建立这三个关键问题进行了详细的分析论述。
对密码协议进行形式化分析,从协议业务逻辑层面上证明密码协议的安全或者是找出协议逻辑层面的缺陷,一旦发现协议的缺陷,协议规范需要重新修订,并且协议代码也要做相应的修改[1]。但是形式化验证的依据是协议规范,而协议代码与协议规范之间存在着一定的差异,如果仅靠人工去定位代码中的缺陷那必定是效率极低的,所以本文提出一套基于静态分析的协议业务逻辑缺陷检测技术方法,利用已有的形式化验证结果自动化地在协议代码中定位缺陷[2-4]。该方法的整体思想是将源代码转换为程序抽象模式,比如函数调用图(Call Graph,CG)和控制流图(Control Flow Graph,CFG),同时解析形式化模型,得到规则依赖图(Dependency Graph,DG),根据图中的节点信息建立映射关系。得到映射关系后,当通过前述形式化验证技术发现模型存在缺陷时,可定位协议代码中的缺陷位置,并确定理论缺陷是否存在于实际代码中[5,6]。业务逻辑缺陷检测系统框架如图1所示。

图1 业务逻辑缺陷检测系统框架图Fig.1 Framework diagram of business logic defect detection system
为了实现上述技术方法,需要解决以下三个关键问题:模型代码解析、协议代码信息抽取以及映射关系建立。
1 模型代码解析
模型代码是一个形式化模型文件,解析后得到的是协议构造的内部表示以及形式化模型的规则依赖图DG,首先需要对输入文件进行预处理,方便后面更容易地进行解析。
1.1 预处理输入文件
对形式化模型代码进行解析之前,需要对其进行一些预处理,大致分为以下三步。首先,去除单行和多行注释,形式化模型代码采用C 风格注释,“//”标识单行注释,“/*”与“*/”标识多行注释。其次,定位Lemma 关键词,删除所有的Lemma,因为Lemma 编写了对安全属性的验证过程,而在此处只考虑对协议进行描述的Rules,不考虑Lemma 的内容。最后,定位End关键词并移除其后面的内容。
1.2 中间表示
对模型代码进行解析,也就是对其包含的Equations、Functions、Builtins 以及Rules 进行解析。其中,最为重要的是对Rules 进行解析,而要解析Rules 就需要对其包含的Facts 进行解析。为了解析这些结构,在实现中创建了三种类型的对象:Operators、Rules 和Equations。
Operators 有一个名称,由字符串和参数组成,其中参数也是Operators,可以获取操作符的属性,以及获取和设置其名称和参数。每个Operators 还有一个多重性和一个类型。Operators 的多重性只与Facts 相对应的运算符有关,它表示在协议中Facts 出现在规则左侧的次数。类型与形式化验证中的术语操作符相关,它可以是一个带有参数的函数,也可以是None,用于区分函数与变量。
Rules 由名称、左参数、右参数、连接关系和多重性组成。名称为字符串,对应于规则的名称。左右参数为Operators 数组,分别对应于左和右的Facts 集合。连接关系是一个Rules 数组,多重性是一个整数。
Equations 只有两个部分,分别都是Operators,对应于方程式的左右两项。
1.3 对预处理后的文件进行解析
(1)解析Functions,由Functions 关键字后面列出的所有函数组成,它们被表示为一个函数名,后面跟着一个斜杠,然后是函数的参数数量,内部表示为一个元组数组,元组中第一个参数为函数名称,第二个参数为函数的参数数量。
(2)解析Builtins,其内部表示为字符串数组。在手动查找了所有包含Builtins 的形式化模型文件后,对其进行硬编码,将所有函数添加到现有函数数组中,并将由Equations 关键字和方程列表组成的字符串附加到文件中,这样就可以像处理其他方程一样处理它们了。
(3)解析Equations,它包括一个左参数,后面跟着一个等号,再后面跟着一个右参数。这些参数在内部表示为Operators。如果参数是一个函数,那么它的参数就是Operators 的参数,它的函数名就是Operators 的名称。如果参数是一个变量,则对应的Operators 具有与该变量相同的名称,并且没有参数。
为了解析Rules,首先必须添加一个新的规则,该规则在形式化验证工具内部中存在,但是不在模型文件中。这个规则就是“新鲜规则”,定义如下:
rule Fresh_rule:
[]--> [Fr(~x)]
此规则用于创建新的变量,并且没有前置条件,因此,它总是可以被执行。这在执行模拟中非常重要,表示从一个空状态开始。
(4)解析Rules。在解析规则R 时,首先考虑let(R)。我们对left(R)和right(R)进行必要的替换。在left(R)和right(R)里面可以有零个、一个或多个Facts。因此,我们在内部将这些Facts 表示为Operators。R 表示为一个名称为R 的Rule,left(R)和right(R)分别表示左右facts 对应的Operators 数组,初始时没有连接关系,多样性为0。
如图2所示显示了Rules 的可视化解析过程,其中Rules 和Operators 用它们的名称表示。在该规则中,左边有两个事实,右边有两个事实,它们由Operator 表示。所有操作符都可以连接到其他操作符的列表。如果一个操作符没有任何参数,它对应于一个变量,如k_A或一元函数,如g。
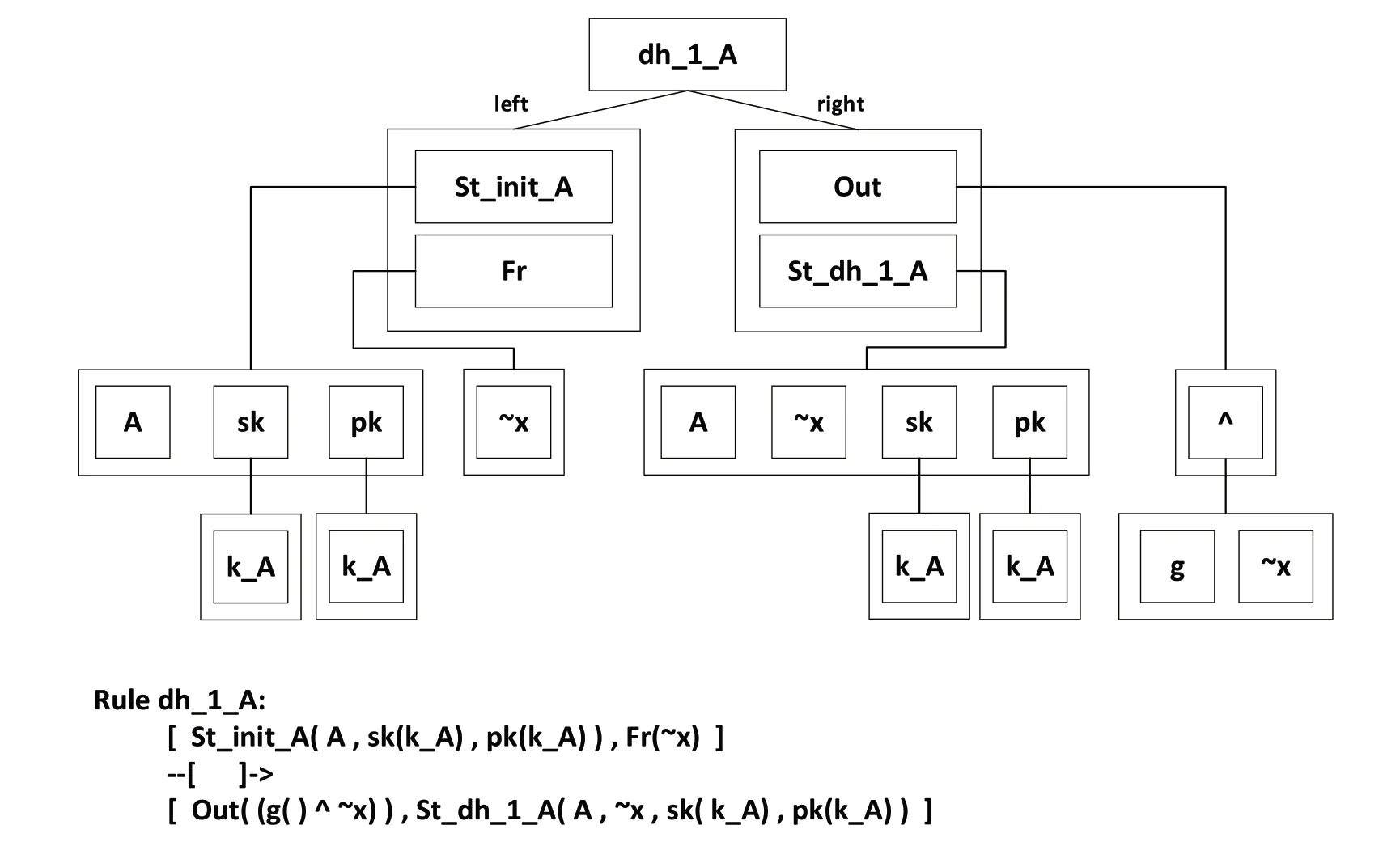
图2 形式化模型规则解析图Fig.2 Formal model rule analysis diagram
接下来,为了得到规则之间可能的执行顺序,需要创建一个规则依赖图DG,可以用一个有向无环图来描述DG,节点是模型中的规则,边代表着依赖关系,假定这个图为G,点集为V(G),边集为E(G),对于R1∈V(G),R2∈V(G),如果R2的左边有一个Operator 与R1的右边的一个Operators 具有相同的名称和参数个数,并且参数是统一的,则这两个节点之间存在一条边。该图显示了为了能够执行给定的规则,可能需要已经执行了哪些规则。下面给出规则依赖图的定义:
令R1,R2∈V(G)
(R1,R2)∈E(G) ⇔F ∈left(R2),F’∈right(R1),s.t.name(F) = name(F’),
arity(F) = arity(F’)
至此,对输入的模型文件的解析就完成了。其中有一点需要说明,对于那些右侧只包含Out 事实,并且左边只有持久事实或者新鲜事实的规则,在解析时都不做分析,而是直接进行了删除,因为一般来说,这些规则不属于协议参与方之间的交互,在协议代码中不会存在与之相关的实现。
2 协议代码信息抽取
协议代码是对协议规范的实现,与协议规范之间存在差距,包含实现细节与底层操作,而协议的形式化模型是对协议规范的高度抽象,要建立二者之间的映射关系,首先需要对源代码进行信息提取和变换,由于C/C++常常被用作安全协议开发所使用的高级语言,因此这里关注于由C/C++编写的协议代码。
程序分析一般分为两类方法,动态分析和静态分析。动态分析通过运行程序来得到程序运行的各个状态,构建程序模型的方法效率低、不适用于大规模程序,而网络协议的代码规模通常都很大,所以利用静态分析更加合适,静态分析不需要运行程序,通过词法分析、语法分析、控制流、数据流分析等技术对程序代码进行扫描来获得程序的信息。相比之下,静态分析可以做到更早、更全面、更高效和更低成本地发现程序的缺陷。
为了获取函数名,构建函数调用图CG,图中的节点是方法,边表示调用关系。下面给出一个代码片段作为示例:
int foo(int t){
bar1();
bar2();
if(t > 0) return t;
else return 0;
}
在这段代码中,方法foo()调用了方法bar1()和方法bar2(),则CG 中应有一条从foo()到bar1()的有向边,以及一条从foo()到bar2()的有向边,如图3所示。

图3 函数调用图CGFig.3 Function call diagram CG
为了获取程序在执行过程中会遍历到的路径,构建控制流图CFG。控制流程图是用在编译器中的一个抽象数据结构,由编译器在内部维护,是对程序的一个抽象表现,图中的节点是语句或者是基本块,在一个基本块中,语句都是顺序执行的,只可以从入口语句开始执行,直至执行到最后一条语句,边表示执行流,在遇到条件语句时产生分支。例如语句A 执行后的下一条语句是B,则CFG 中应有一条从A 到B 的有向边。条件语句(if-else,while-do)之后可能执行的语句不止一个,可能执行true-branch 或false-branch,所以CFG 上条件语句节点的后缀会有多个,表示其后可能执行的不同branches,上述代码片段的CFG 如图4所示。

图4 控制流图CFGFig.4 Control flow graph CFG
3 映射关系建立
通常情况下,研究人员在为协议建立形式化模型时,会遵循一定的规律,规则和变量的名称都会有实际的含义,下面总结出了一般建模中命名的习惯,这在匹配中起到一定的辅助作用,如表1所示。

表1 形式化模型中变量含义Tab.1 The meaning of variables in the formal mode
除此之外,本项目使用的建模语言规定了变量的四种类型:
~x 表示x 是新鲜的
$x 表示x 是公开的
#i 表示i 是暂时的
m 表示消息m
首先,先序遍历协议代码的CG,利用形式化模型中的规则与协议代码的方法进行模糊匹配,筛选掉大部分不匹配的代码段,找出匹配度较高的代码片段,伪代码如下所示:
执行匹配算法之后,可能会得到多个匹配代码片段,或者是一个也没有,对于没有结果的情况,通过审查很容易分析出原因,而对于多重结果的情况,需要再去利用结果片段里的代码CFG 来做筛查,通过类似的遍历方式,获取CFG 中的变量,与形式化模型中变量的形式进行对比,就可以选择性地保留最终的结果。
4 结语

算法1: 匹配算法Input:协议代码C,要匹配的规则R Output:代码片段F 1 获取CG 根节点作为当前节点tu;2 获取当前节点属性;3 利用R 与当前节点属性进行模糊匹配,匹配分值超过阈值则将tu 加入F,否则继续执行;4 tu.getchildren()作为当前节点,重复2、3、4 步骤;5 返回F。
本文对基于静态分析的安全协议业务逻辑缺陷检测技术做了详细阐述,从研究现状分析出本方法的创新性,然后针对方法中的三个关键问题,进一步地描述了方法的实现细节,可以为下一步研究协议代码底层的漏洞和基于机器学习的缺陷预测技术提供技术基础。
