基于YOLO-ST的安全帽佩戴精确检测算法
2022-12-01杜晓刚王玉琪晏润冰古东鑫张学军
杜晓刚, 王玉琪, 晏润冰, 古东鑫, 张学军, 雷 涛*
(1.陕西科技大学 陕西省人工智能联合实验室 电子信息与人工智能学院, 陕西 西安 710021; 2.陕西科技大学 机电工程学院, 陕西 西安 710021; 3.兰州交通大学 电子与信息工程学院, 甘肃 兰州 730070)
0 引言
目标检测是计算机视觉的热门研究方向,在安全管理、智能家居、智慧医疗等领域具有重要的应用价值.其中,在建筑行业对施工人员佩戴安全帽的情况进行检测引起了众多研究人员的关注.在线检测安全帽的佩戴情况对保证施工人员的安全具有重要的研究意义[1,2].
目前,安全帽检测方法可分为两类:传统检测方法和基于深度学习的检测方法.相对于传统检测方法,基于深度学习的检测方法具有检测精度高、检测速度快的优势.根据检测阶段不同,可以将基于深度学习的检测方法分为两大类[3,4]:两阶段检测[1]和单阶段检测[2,5-7].由于单阶段检测方法具有检测效率高的特点,可以满足安全帽检测的实时性需求,在实际生产中具有广泛的应用前景.近年来,许多学者相继提出了大量的单阶段检测方法,主要包括:SSD检测[2,5]和YOLO检测[6,7].其中,YOLO系列算法因其检测速度快而得到了学者们广泛地研究和关注.YOLOv5作为YOLO系列的最新算法,在主干网络中利用Focus结构对图像进行切片,使原始图像的长宽信息集中到通道空间,得到图像信息不变的二倍下采样特征图,改善检测精度的同时也提高了检测效率.此外,在YOLOv5的颈部网络中使用CSP2_X结构[8]来增强网络的学习能力以及特征融合能力.同时,YOLOv5从整体上降低模型的大小,使得模型更加轻量化,提高了检测效率.
然而,由于YOLOv5模型为通用模型,针对密集复杂场景中的特定目标进行检测时导致检测效果有所下降.例如在安全帽检测过程中,由于拍摄场景环境复杂,容易受到检测天气、人数、光照强度、拍摄距离等因素的影响,YOLOv5针对工地等复杂场景进行安全帽检测的精度有待改善.
为了解决以上问题,本文提出了一种基于YOLO-ST的安全帽检测算法.本文的主要贡献归纳如下:
(1)引入更容易捕获全局信息的Swin Transformer结构来提取更强大的语义特征,适用于环境恶劣和复杂场景的目标检测;同时,允许自注意力进行跨窗口的计算,进一步提高了检测效率.
(2)在YOLO-ST中设计了DSPP模块进行池化操作,使模型在获得多尺度信息的同时,最大程度保留了图像的细节信息,解决原始池化操作带来漏检率过高的问题,从而提高安全帽检测的准确性.
(3)在公开的SHWD数据集上从对比实验和消融实验两方面进行验证,实验结果表明,与主流的目标检测算法相比,YOLO-ST能够获得更佳的检测结果.
1 相关工作
目前,目标检测主要分为两大类:传统的目标检测方法和基于深度学习的目标检测方法[9].其中,传统的目标检测方法[10,11]通常采用人工设计的特征提取器来提取特征,同时传统算法具有可解释性强、模型设计简单等优点.然而,由于人工设计的特征提取器未能获取丰富的上下文信息和高级语义特征,导致检测效率有所下降.近年来,随着深度学习技术的不断研究,基于深度学习的目标检测方法[12]因其良好的检测精度受到学者们的广泛关注.根据检测阶段的不同,基于深度学习的目标检测方法可分为两类:两阶段检测算法[13-16]和单阶段检测算法[17-20].
1.1 两阶段检测算法
两阶段检测算法[13-16]将检测过程分为两个阶段:首先,通过候选框生成网络进行特征提取;然后,将特征输入分类网络进行分类和边框位置矫正.在两阶段检测方法中,首先由Girshick等[13]提出基于区域卷积神经网络R-CNN,该方法借助CNN良好的特征提取和分类能力,并通过区域提取来实现目标检测.在此基础上,为了解决R-CNN中因固定尺寸的全连接输入导致图像信息形变以及分类和回归过程中计算步骤多导致训练速度慢等问题,相继提出了SPP-Net[14]、Fast R-CNN[15]和Faster R-CNN[16].其中,Faster R-CNN的性能尤为突出,在卷积层后接入金字塔池化层[21],从而实现任意大小的卷积特征映射为固定尺寸的全连接输入.同时,提出了区域生成网络RPN代替原始的选择性搜索方法SS[11]来生成候选框,从而提升候选框的生成速度.上述两阶段检测分工明确,取得了良好的检测精度.但是,两阶段检测算法的检测速度相对较慢,从而限制了其在对实时性要求高且硬件资源受限的实际场景中的应用.
1.2 单阶段检测算法
单阶段检测[17-20]主要以YOLO系列的检测方法为代表.与两阶段检测方法相比,YOLO系列将目标检测转化为回归问题,通过输入图像至神经网络,直接得到包含类别以及位置信息的输出.YOLO方法检测效率高且检测精度与两阶段检测方法接近.
在YOLO检测方法中,首先由Redmon等[17,18]相继提出了YOLOv1和YOLOv2算法.在此基础上,YOLOv3[19]选择更深层的网络Darknet53进行特征提取,并引入多尺度预测(FPN)[22]来提高网络对数据的表征能力.YOLOv3在检测精度方面有着大幅度的提升,同时更适用于进行小目标检测.而YOLOv4[20]则是在YOLOv3的基础上,使用Mosaic数据增强来丰富检测数据量,并且提出了CSPDarknet53作为主干网络来增强网络的学习能力,同时在颈部网络中采用SPP模块和FPN+PAN结构来更好地提取特征信息.此外,作为YOLO系列的最新算法YOLOv5,在进一步改善网络特征提取能力的同时,通过轻量化模型大小来提高检测速度.与YOLOv4相比,YOLOv5在保持精度的同时,极大的提高了检测的效率.然而,由于YOLOv5为通用模型,不适用于密集安全帽检测场景进行检测.因此,学者们通过在YOLOv5的基础上引入新的模块,如:SE-Net通道注意力模块[6]和坐标注意力机制[7]等方式来增强网络的特征提取能力,提高复杂场景下的安全帽检测效果.上述方法均采用SPP进行池化操作,容易丢失图像特征的细节信息.另外,文献[6]虽然提升了密集场景下的检测效果,但是在光照强度弱的场景下检测效果不佳.
2 YOLO-ST
本节首先描述了YOLO-ST的网络整体框架;其次,分别介绍特征提取网络Swin Transformer和DSPP两个改进模块;最后介绍YOLO-ST使用的损失函数.
2.1 YOLO-ST网络框架
为了提高安全帽检测效率,满足应用的实时性需求,本文选用网络深度最浅、效率最高的YOLOv5s模型进行改进.针对复杂场景下安全帽检测准确度低的问题,提出了一种基于YOLO-ST的安全帽检测算法.YOLO-ST的网络结构如图1所示.首先,将待检测图像输入主干网进行特征提取,然后经过颈部网络加强特征的鲁棒性,最后通过卷积层组成的检测头进行安全帽佩戴检测.与YOLOv5s不同的是,本文提出的YOLO-ST不再使用CSPDarknet53作为主干网,而是选择了性能更好的Swin Transformer,使主干网可以提取更加高级的语义特征.同时,在YOLO-ST中,设计了密集的空间金字塔池化DSPP模块来代替YOLOv5s中的SPP模块,以此来捕获多尺度的细节特征.

图1 基于YOLO-ST的安全帽佩戴检测算法
2.2 特征提取网络Swin Transformer
在目标检测中,主干网用来获取目标的语义特征和位置信息.YOLOv5s在进行特征提取时,选用典型的卷积神经网络CSPDarknet53,通过卷积层的不断堆叠来扩大感受野,从而完成局部信息到全局信息的捕获.但是,越来越深的卷积层导致了模型越来越复杂,在检测效率方面并不具有优势.
为了更好地提升模型的检测能力,本文选择用Swin Transformer[23]提取特征,如图2所示.它不仅充分考虑到卷积神经网络中具有的位移不变性、尺寸不变性、感受野与层次的关系、分阶段降低分辨率增加通道数等特点,而且还具有卷积神经网络不具备的优势,即提取全局信息和学习长依赖关系的能力.Swin Transformer用移动窗口将自注意力计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而提高了效率.此外,这种分层结构还具有在不同尺度下建模的灵活性,增强了模型捕获多尺度信息的能力.具体来说,Swin Transformer是通过将Transformer[24]中的多头自注意力(MSA)模块替换为基于移动窗口的模块,解决了长期困扰业界的Transformer应用到计算机视觉领域速度慢的问题.同时,在每个MSA模块和每个MLP之前应用LayerNorm层,并且在每个模块之后应用残差连接.

图2 Swin Transformer特征提取网络
2.3 密集的空间金字塔池化DSPP
在YOLOv5s模型中,通过引用空间金字塔SPP模块来解决原始池化方式中固定输入尺寸带来的图像失真、变形等问题.SPP模块主要由四个不同尺度的最大池化操作组成,分别为1×1、5×5、9×9和13×13池化操作,SPP的结构如图3(a)所示.通过使用SPP模块可以捕获到图像的局部以及全局特征,有利于处理目标差异大的情况.然而,SPP模块在检测过程中仅进行池化操作,导致图像特征的细节等信息出现不可逆的丢失,从而在安全帽检测的过程中出现漏检率高的问题.
为了解决该问题,受稠密连接思想的启发,本文提出了DSPP模块来代替原始的SPP模块进行池化操作,DSPP结构如图3(b)所示.当图像特征输入DSPP后,与SPP一样经过四个分支来进行不同尺度的最大化池化操作,并且每个分支的最大化池化信息会与其他分支的特征信息一同作为池化操作的输入,同时补充的池化信息量也由损失信息量决定,从而有效解决了SPP存在的信息丢失问题,进一步提高了安全帽检测的准确性.
当输入特征信息为X时,DSPP模块的输出信息Y如式(1)所示:
Y=X+X2+X3+X4
(1)
其中,X2、X3、X4分别如式(2)~(4)所示:
X2=P5(X)
(2)
X3=P9(X+X2)
(3)
X4=P13(X+X2+X3)
(4)
式(2)~(4)中:Pa为a×a的最大池化操作;“+”为concat操作.

图3 空间金字塔池化模块改进
2.4 损失函数
本文检测模型YOLO-ST的损失函数共由三种损失构成:目标损失函数Loss_obj、类别损失函数Loss_cls和检测框损失函数Loss_box.其中,Loss_obj和Loss_cls均采用交叉熵损失Loss_BEC进行计算:
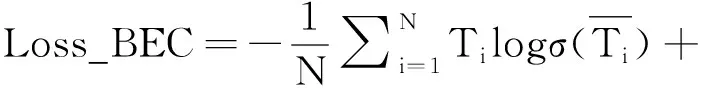
(5)

检测框损失函数Loss_box如式(6)所示:
Loss_box=1-GIoU
(6)
其中,GIoU如式(7)所示:
(7)
式(7)中:IoU为交并比,A为检测框,B为预测框,C为能包含检测框和预测框的最小封闭框.本文检测模型的损失函数Loss如式(8)所示:
Loss=αLoss_obj+βLoss_cls_+γ(1-GIoU)
(8)
式(8)中:α=0.45,β=0.5,γ=0.05.
3 实验结果与分析
为了评估改进后的模型在安全帽检测任务中的性能好坏,利用开源安全帽数据集SHWD[25]进行实验,并从对比实验和消融实验两方面进行模型效果的评估.本节首先介绍数据集、实验环境和参数设置、评价指标;其次与目前具有代表性的检测算法进行对比实验;最后展示消融实验.
3.1 数据集介绍
本文选用的安全帽检测数据集SHWD包括7 581个不同场景、天气、光照条件、人数、拍摄距离的样本图像.主要包含两类样本:佩戴安全帽safe类别和未佩戴安全帽person类别.在训练前,输入图像使用Mosaic数据增强的方式,对随机选取的四张图像进行缩放和拼接,不仅丰富了训练数据集的样本信息,而且通过随机缩放也增加了小目标以及背景信息的数量,进一步加强网络的鲁棒性.另外,受到显存限制,本文实验将图像尺寸下采样为640×640.
3.2 实验设置
本实验的主要硬件环境配置为:CPU为Intel(R) Xeon(R) Gold 6226R,内存32 GB;GPU为NVIDIA Geforce RTX 3090,显存24 GB.本实验在Ubuntu 16.04.10操作系统上进行,所有方法采用的深度学习框架是PyTorch.针对本文所提的YOLO-ST进行训练时,最大迭代次数设置为100,批量大小为16.另外,YOLO-ST进行训练时采用Adam优化器,学习率设置为0.01,动量设置为0.9,权重衰减值设置为0.000 5.
3.3 评价指标
本实验主要采用IoU阈值为0.3、0.5时的平均精准度AP30、AP50及其均值mAP来评价模型性能.当AP值越高时,模型检测的精确率越高,AP如式(9)所示:
(9)
式(9)中:C为类别数,Ppre表示模型检测出正确佩戴安全帽的概率,即精确率;Rrec表示在佩戴安全帽的图像中模型检测正确的概率,即召回率.精确率和召回率的公式如式(10)和式(11)所示:
(10)
(11)
式(10)、(11)中:TP表示佩戴安全帽且预测佩戴的数量;FP表示未佩戴安全帽但是预测佩戴的数量;FN表示佩戴安全帽但预测为未佩戴的数量.
3.4 对比实验
为了更好的验证算法有效性,在相同实验环境下,使用YOLO-ST与具有代表性的目标检测算法YOLOv3-tiny和YOLOv5s进行对比实验和性能评价.可视化实验结果如图4所示.图中绿色标注框表示佩戴安全帽的safe类型,红色标注框表示未佩戴安全帽person类型,并且在标注框上方有类别注释和置信度.从图4可以看出,YOLOv3-tiny在检测过程中将塔吊错检为目标对象,而YOLOv5s在检测过程中多次出现将佩戴安全帽目标错检为未佩戴安全帽的目标.同时两种算法在检测过程中,多个目标位置的置信度均低于0.8.与其他两种模型相比,YOLO-ST能够分别完成单目标、多目标和不同尺寸目标的检测任务.此外,针对数据集中拍摄场景环境复杂、模糊、曝光等情况下的安全帽检测图像,YOLO-ST在检测过程中依旧能精确检测到目标位置且置信度高于0.8.因此,YOLO-ST能够很好地完成安全帽检测任务.

图4 三种方法在SHWD数据集上检测结果
P-R曲线图是评价目标检测模型的重要手段之一.当准确率越高时,召回率就越低,所以当P-R曲线越靠近右侧时精确率和召回率相对较大,模型的检测效果越好.三种模型的P-R曲线如图5所示.由图5可以看出,本文提出的YOLO-ST的P-R曲线越靠近右上角,其检测效果优于其它两种算法.

图5 模型检测的P-R曲线
为了进一步评价YOLO-ST的性能,使用AP对三个算法进行客观评价的结果如表1所示.由表1可以看出,与YOLOv3-tiny模型相比,YOLO-ST在阈值为0.3和0.5时,AP值分别提高了11.8%和16.4%,mAP值提高了14.1%;与YOLOv5s模型相比,YOLO-ST在AP30、AP50以及mAP上分别提高了4.5%、2.8%和3.7%.因此,YOLO-ST可以获得更准确的安全帽检测效果.
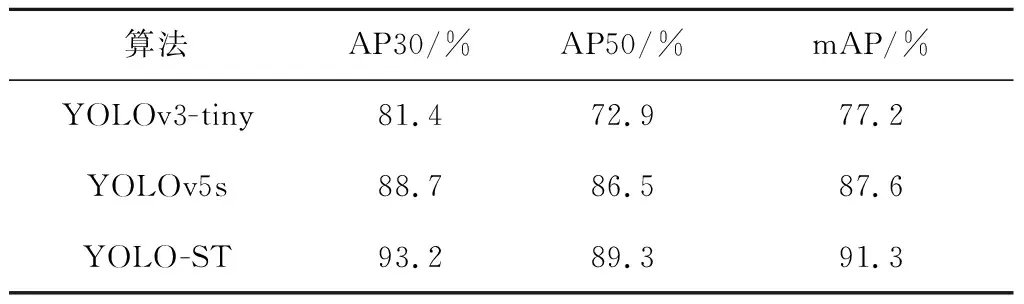
表1 对比实验
综上所述,本文提出的YOLO-ST选用Swin Transformer做主干网络来捕获更多的目标特征,同时引入DSPP模块来保留更多的细节信息.与YOLOv3-tiny和YOLOv5s相比,在不同的IoU阈值下,YOLO-ST均取得了更好的识别准确性.
3.5 消融实验
为了研究算法中各个模块对实验结果的影响,本节共设计了四组对比方案.其中,“√”代表模型使用了此模块,“×”代表未使用此模块.实验通过AP30、AP50以及mAP三种评价指标来衡量模型性能,消融实验结果如表2所示.

表2 消融实验
在表2中,模型A代表原始的YOLOv5s,使用CSPDarknet53作为主干网,并采用SPP模块进行池化操作.从表2可以看出,模型A的AP30、AP50、mAP分别为88.7%、86.5%和87.6%.在模型A的基础上,模型B采用DSPP模块替代SPP,保证模型获取多尺度信息的基础上,解决由于池化操作导致细节信息丢失的问题,从而提高安全帽检测的准确性.实验结果表明,模型B中的各项指标相比模型A均提高了0.9%.模型C是在模型A的基础上,保持原有池化方式不变,同时选择特征提取能力更强的Swin Transformer作为主干网,使得主干网可以提取更加高级的特征信息,进一步提高模型检测能力.相比于模型A,模型C的mAP提高了3.2%.模型D是在模型C的基础上,采用DSPP模块进行池化操作,即本文提出的YOLO-ST.与模型A相比,AP30、AP50和mAP分别提高了4.5%、2.8%和3.7%,与模型B和模型C相比,mAP分别提高了2.8%和0.5%.综上所述,本文提出的YOLO-ST在安全帽检测任务中的具有更好的准确性.
4 结论
本文提出了一种基于YOLO-ST的安全帽佩戴检测算法.该算法在YOLOv5s的基础上使用Swin Transformer作为主干网来提取更深层的图像特征.同时,设计并引入DSPP模块,在保证模型获得多尺度信息的基础上,解决了SPP在池化操作中易丢失图像细节信息的问题.与YOLOv3-tiny和YOLOv5s相比,在SHWD数据集上,YOLO-ST具有更精确的检测效果.
本文使用Swin Transformer来提升模型的检测能力,导致模型参数量有所增加.因此,未来工作将在保证检测精度的前提下实现模型轻量化.
