融合BERT与多尺度CNN的科技政策内容多标签分类研究*
2022-12-01马雨萌黄金霞
马雨萌 黄金霞 王 昉 芮 啸
(1.中国科学院文献情报中心 北京 100190;2.北京大学信息管理系 北京 100871)
0 引 言
在科技创新已成为国家转型发展的根本驱动力和国家间竞争制高点的今天,科技政策层出不穷。科技政策是国家为实现一定历史时期的科技任务而规定的基本行动准则,是指导整个科技事业的战略和策略原则[1]。科技政策文本是指国家或地方为发展科技事业,各级权力或行政机关以文件形式颁布的法律、法规、部门规章等官方文献[2]。网络信息时代决策过程日益开放,大数据带来的冲击更加剧了对政府决策的影响,政府如何利用大数据完善决策过程是适应时代和把握机遇的关键[3]。政策文本是政府处理公共事务的真实记录和行为印迹,具有数据挖掘、趋势分析、执政参考等多重决策支持价值[4]。对于科技政策决策者和研究者而言,科技政策文本涵盖领域广,蕴含了大量复杂多元的指导性内容,能够支持丰富决策知识的发现,成为大数据时代政府科技决策的重要依据和工具。
当前政府决策过程对科技政策结构化内容的分类需求越来越强烈,对大规模、碎片化的政策内容进行有效分类,能够帮助决策者从不同科技创新领域视角组织管理政策措施,是揭示领域政策演化脉络、开展区域间政策对比等进一步分析的基础。随着大规模政策文本分析环境的转变,传统的人工定性编码方式难以满足快速决策的需求,文本自动分类方法在政策分类中的应用得到了越来越多的关注。政策文本具有信息密度大与内涵分布不均衡等特点[5],如何完整和准确地表达分类语义是提升政策分类准确性的关键问题。传统的基于词袋模型或其变体方法的分类模型,由于忽略了词的相对位置信息,在表征文本的上下文信息和语义特征上存在局限性[6],因此如果传统文本分类模型直接迁移应用于政策文本领域,将无法充分捕获政策文本的复杂语义与多层次特征。此外,科技政策措施涉及了人才建设、基础设施、财政税收、市场监管等众多领域,通过多种政策工具的组合共同支持国家科技创新发展。然而传统的科技政策分类,多以科技计划、农村科技、国际科技合作等科技政策的作用领域为标签,从政策文件层面给予单标签分类[7-8],未能有效地揭示出政策内容的多主题特征。
针对以上问题,本文以科技政策文本为研究对象,基于BERT预训练模型和卷积神经网络相融合的深度学习方法,构建科技政策文本的多标签分类模型。一方面通过BERT学习政策内容句的语义特征表示,充分提取文本的上下文信息;另一方面利用多尺度、多通道的卷积模块提取更多尺度的特征,增强政策分类语义特征表示和不同层次信息获取的准确性,从而提升模型在多标签分类任务上的性能,为实现科技政策文本内容的自动化编码与多主题分类提供参考。
1 相关研究
1.1 科技政策文本内容分析与挖掘
公共政策文本内容分析领域经历了从质性文本解读到定量数据分析的变化,定量分析方法的应用与拓展丰富了政策研究范式,在一定程度上有助于政府在决策过程中科学地调整或制定相关政策。科技政策作为蕴含了丰富科技决策知识的叙述性文本,近年来学者们积极探索了文本内容分析方法在科技政策领域的应用。自然语言处理、数据挖掘与文本计算等技术的研究与应用,通过关注政策内容的深层语义,为支持大规模政策文本的隐性特征发现与知识规律揭示提供了方法基础。目前文本内容分析与挖掘方法在科技政策应用的主要领域包括:
a.文本内容分类:当前研究通常以政策工具理论为依据建立类目,采用内容分析法进行分类编码和计量,将政策内容语句转化为带有政策工具分类标签的可量化数据,有助于决策者梳理与把握议题领域政策工具体系的结构特征[9]。
b.领域新词发现:为了准确识别科技政策文本中出现的领域新词、专有名词术语,基于规则的方法根据政策文本的语言规律和句法特征,通过构建规则模板来识别政策领域词语[10]。深度学习的发展提供了特征的自动提取,针对科技政策领域缺乏标注语料的问题,目前有学者探索了无监督方法,利用较少的标注语料达到了较好的识别性能[11]。
c.文本主题分析:主题分析提供了一种深入语义层面的文本挖掘方法,发现大规模政策文本中的主题特征和语义内涵。早期通过政策文本词语关联网络的构建,能够直观地展示科技政策文本主题的分布与关联结构[12]。更进一步,学者们将主题模型和文本聚类技术引入科技政策内容分析中,揭示科技政策文本中的隐含主题信息及主题强度变化规律[13]。
d.知识图谱构建:科技政策涉及政策工具、创新主体、适用条件、实现目标等要素的协同合作,对政策文本中这些关键知识的解析与关联可以借助知识图谱解决。通过采用知识抽取、链接、存储等知识图谱技术,能够提取政策内容中关键表述的知识实体、实体属性及实体间关系,以知识网络图形式实现政策内容的关系分析与推理[14]。
1.2 基于深度学习的政策文本分类
基于深度学习的分类方法,由于能够从样本中主动学习文本特征,且具有强大的特征选择、抽取与表达能力,目前在政策文本分类领域得到应用。根据待分类对象的类型与颗粒度,政策主题分类研究涉及了政策文件或其内容语句的分类任务。一是在政策文件的主题分类方面,李志鹏引入LSTM模型解决政策文本分类的语义抽象及上下文环境保留问题,提高政策分类精度和挖掘效果[15]。越来越多的学者通过探索分类模型的融合或改进,以取得更好的分类效果。胡吉明等通过CNN模型提取政策文本的局部特征,利用BiLSTM模型整合政策文本的上下文特征,最大程度上保证政策文本语义完整性[16]。王涛利用深度学习中的注意力机制,根据正文与标题二者的重要程度来对教育政策文本进行建模,得到文本的最优向量表示,解决政策文本语义分布不均衡的问题[17]。另一方面,由于自动分类技术的应用可以减少传统政策内容分析法所需的劳动量,目前有学者尝试开展了基于机器学习的政策内容自动编码实践,张维冲等利用自动分类和加权算法对政策条文进行开放式编码,快速得到以政策目标、研发与应用、政策工具为主要维度的芯片产业政策内容分析编码表[18]。
目前基于深度学习的政策分类研究,分类对象仍主要集中于政策文件层面,由于缺乏政策领域的标注数据和科学、细致的主题分类体系,因此在政策内容的分类研究上应用较少。此外,一个完整的政策措施句通常具有多方面的主题,尤其对于科技政策而言,围绕国家创新体系涉及了要素、环境、需求等科技创新多维度领域。然而,因为目前多数政策分类研究忽视了科技政策内容的这种多主题特征,所以科技政策信息在不同视角、维度下的空间定位难以得到有效揭示。因此,探索深度学习方法在实现政策多标签分类任务上的应用,是科技政策分类研究的重要发展方向。
1.3 基于深度学习的多标签文本分类模型
随着文本分类粒度的细化程度越来越高,一个样本可能与多个类别标签相关,多标签文本分类的主要任务是通过特定的分类器为某个文本赋予多个标签[19]。如何高效地从文本中提取特征是多标签文本分类面临的首要问题,相比于传统的以词袋模型作为文本特征表示的方法,深度学习方法通过学习文本的向量表示,能够充分捕捉文本的上下文信息和语义特征,因此在文本多标签分类中取得了较好的效果[6]。按照网络结构的不同,基于深度学习的多标签文本分类包括基于卷积神经网络(CNN)、基于循环神经网络(RNN)和基于Transformer的算法[20]。基于CNN的方法一般通过改进CNN结构来适应多标签文本分类,Baker等提出了一种基于改进CNN结构的多标签文本分类方法,通过初始化神经网络模型的最终隐藏层来利用标签共现关系[21]。基于RNN的多标签文本分类方法大多采用Seq2Seq结构来实现,将多标签分类任务视为序列生成问题,以此来考虑标签之间的相关性[22]。随着具有注意力机制的Transformer在自然语言处理领域的广泛应用,尤其基于双向Transformer的文本表示模型BERT在文本分类、信息抽取等任务中达到了领先水平[23],Transformer模型在多标签分类领域也得到了大量应用。Lee等利用预训练的BERT模型,对以权力要求书为主要内容的专利文本进行分类,实验证明BERT模型针对多标签的专利文本有更好的分类效果[24]。
上述研究为科技政策内容的多标签分类提供了一定的参考思路,但是存在如下问题:①目前基于CNN、RNN的分类模型在提取特征前,多使用Word2Vec等传统词向量模型将预处理文本进行向量化表示,但是这些词向量忽视了词语的多义性,对文本的表征依然存在局限性[25];②对CNN或RNN的单独使用存在着一些问题,例如CNN因为网络变深而出现性能饱和,RNN会叠加错误标签带来的影响,而且目前神经网络模型获取文本的特征有限,相对于BERT等预训练模型仍有差距[20];③科技政策内容句具有信息密度大、涉及主题领域多、内涵分布不均衡等特点,如未充分考虑这些问题就将通用分类模型进行移植应用,则难以实现对语句局部特征和关键有效信息的捕获。
2 研究设计
2.1 整体研究框架
本文提出了基于深度学习模型的科技政策多标签分类方法,依据政策工具理论建立科技政策分类体系,将科技政策内容语句归属于相应的若干政策工具类型。本文的整体研究框架包括:①实验数据准备:采集科技政策文本并进行预处理,依据分类体系,准备训练数据。②BERT-多尺度CNN模型训练:本文使用BERT提取政策语句特征,提高对文本语义的表示能力,然后为了获得不同层次的信息,设计了多尺度卷积模块Text Inception,在不同尺度上提取句子中的关键语义特征,最后通过Sigmoid对语句进行多标签分类。③对比实验:通过与仅使用BERT的分类实验对比,验证融合多尺度CNN方法的有效性。④分类效果评价:计算与分析BERT-多尺度CNN模型和单一BERT模型的分类结果,对模型进行评价。
2.2 基于政策工具的科技政策分类体系
政策工具是由政府所掌握的、用以实现政策目标的各类手段和措施[26]。在科技政策体系研究中,当前学者们通常以政策工具理论作为定义科技政策内容分析框架的依据,揭示科技创新特定领域下的政策工具特征,指出政策体系结构存在的问题,并提出相应建议[27]。本文依据经典的Rothwell等提出的供给型、环境型和需求型政策工具分类法[28],界定和划分科技政策内容语句所属的政策工具类型,共15个类别,并以此作为科学的、较细粒度的、覆盖科技创新重点领域的科技政策分类体系。科技政策的供给型政策工具指政府通过对人才、设施、技术、资金等方面的支持,直接扩大或改善科技创新相关要素的供给,可细分为资金投入、技术研发、人才队伍建设、项目计划、科创基地与平台、科技基础设施建设、公共服务。科技政策的环境型政策工具指政府通过影响科技创新发展的环境因素,为促进科技活动、提高创新主体积极性营造有利的政策环境,可分为创造和知识产权保护、金融支持、科技成果转移转化、市场监管、税收激励。科技政策的需求型政策工具指政府积极开拓并稳定技术和产品应用的市场,减少与创新相关的市场不确定性,通过扩大市场需求对新产品、新技术开发等创新活动产生拉动作用,较为常见的有贸易协定、政府采购、宣传推广[29]。
2.3 基于BERT-多尺度CNN的多标签分类模型构建
本文提出了基于BERT与多尺度CNN融合的多标签分类模型,如图1所示,模型结构主要包括BERT文本表示层、多尺度卷积层和多标签分类层。首先将政策语句输入BERT文本表示层进行语义编码、补充;然后在多尺度卷积层中,利用多种尺度的卷积核得到不同尺度的语义特征,通过最大池化获取最优特征;在分类层通过Sigmoid函数计算不同类别的概率,从而输出多标签的预测序列。该模型既通过BERT充分提取文本的上下文信息,又具备了多尺度卷积核提取文本的局部特征的特点。
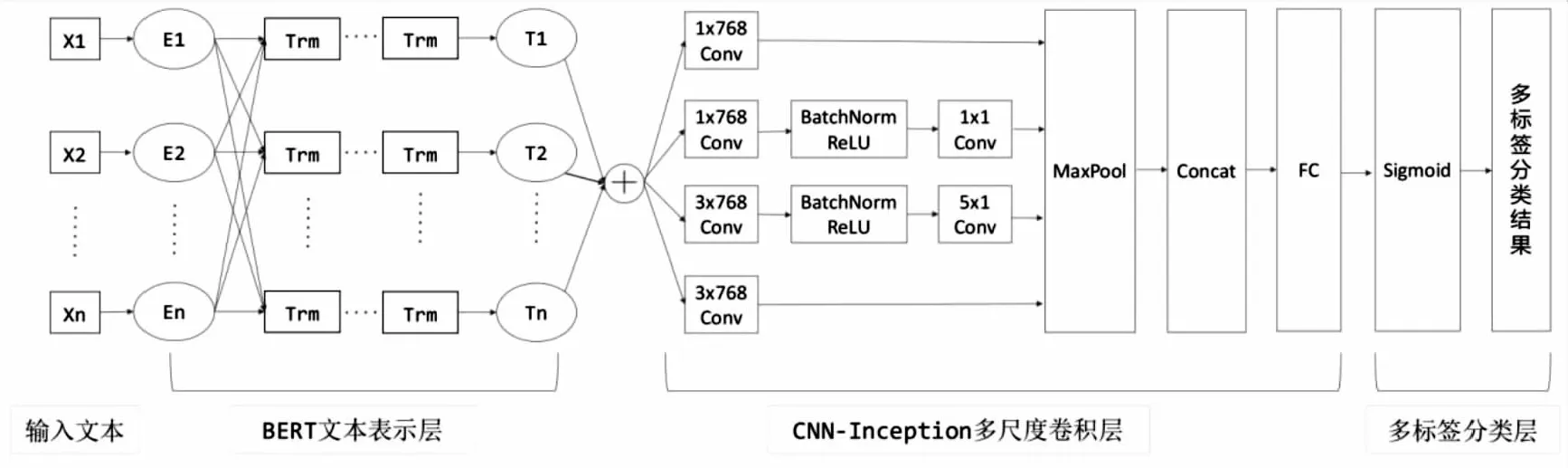
图1 BERT-多尺度CNN模型结构
a.BERT文本表示层。
BERT采用双向Transformer编码器作为特征提取器,以多头注意力机制融合了上下文信息[30]。BERT通过自动随机掩码机制来预测文本中的缺失词,同时利用上下句关系预测来联合表达文本的语句序列表示,分别获取词语和句子级别的语义信息[31]。因此,相比于Word2Vec等传统的词向量,BERT充分考虑了文本的上下文关系,具有良好的语义多样性[32]。在BERT的输出层,可以结合具体的任务做参数微调,完成文本分类等自然语言处理任务。
在BERT-多尺度CNN模型的文本表示层,采用BERT对输入长度为n的政策句子进行编码。BERT首先对输入文本做词向量嵌入表示,包括单词嵌入(Token Embedding)、句子嵌入(Segment Embedding)和位置嵌入(Position Embedding),将句子通过“[CLS]”和“[SEP]”标记同时输入到模型中表示为En,每个词的嵌入维度为768,如图1所示,E1、E2、…、En表示模型的输入向量;然后再通过12层Transformers Encoder结构,将每个词转换成富含句法语义特征的Tn,如图1所示,T1、T2、…、Tn表示模型的输出向量,作为下游多尺度CNN模型的输入。
b.多尺度卷积层。
卷积神经网络(CNN)可以学习到文本的局部特征,结构通常由卷积层、池化层和全连接层组成。CNN模型通过不同卷积核来提取多种深层特征,为了提取高维度特征,主要是进行更深层卷积,但随之带来网络变深、性能饱和的问题[33]。因此,Google提出了Inception卷积模块[34],增加了网络的宽度,Inception网络中并行使用多个不同尺度的卷积核,将输出结果拼接成一个更深的特征图,充分提取多尺度的特征,可更加全面地利用隐藏的特征信息[35]。本文针对科技政策内容句的特征,借鉴Inception V1网络结构的思想,设计了多尺度卷积模块(CNN-Inception),对CNN模型增加卷积层和通道数,通过不同尺度的卷积核学习文本的不同特征信息,更好地捕获文本的局部特征与高阶特征,将这些多尺度特征进行拼接来获得政策句的关键语义特征。
CNN-Inception模块对BERT输出的向量并行地执行多个卷积运算和池化处理,如图1所示,模型中有四个卷积通道,使用不同大小的卷积核,可以从不同尺度视角下获得文本的特征信息。第一通道和第四通道为一层卷积,第一通道的卷积核尺寸为1×768,输出数量为256;第四通道的卷积核尺寸为3×768,输出数量为256。为了获得更深层的多尺度高维特征,第二个和第三个卷积通道使用两层卷积,这两个通道之间加入BatchNorm并使用ReLU为激活函数。其中,第二通道中第一层卷积核的尺寸为1×768,第二层卷积核尺寸为1×1,两层输出数量均为256;第三通道中第一层卷积核的尺寸为3×768,第二层卷积核的尺寸为5×1,两层输出数量均为256。模型利用最大池化方式进行特征选择,选取主要特征作为最后的输出特征。经过最大池化层后将4个通道的特征拼接在一起得到一个256×4维的政策句向量,再将这个向量输入到一个全连接层,全连接层的输出维度等于分类数目。
c.多标签分类层。
不同于多类别分类,多标签分类由于每个实例的标签数量不同,模型将不对预测的概率进行归一化处理[6]。本文在分类层使用Sigmoid函数预测多标签分类任务中每个标签的独立分布,将全连接层输出的特征向量转换为不同标签的概率,对不同政策工具类别的概率进行独立计算,概率大于0.5就属于该标签,从而得到多标签的预测序列。
3 实验与结果
3.1 实验数据集
本实验于2022年1—2月期间使用后羿采集器,采集了国家部委、各省、自治区、直辖市及其省会城市的各级政府部门网站公开发布的2021、2020年科技政策文本。本文将这些采集数据作为实验数据集,一方面由于数据来源于政府部门官网,具有权威性;另一方面,各级政策制定是对上层政策的响应和细化[36],因此国家级、省级及重要城市颁布的政策文件在政策扩散路径上通常作为上层政策,其主题基本涵盖了我国科技政策的体系结构及布局重点。
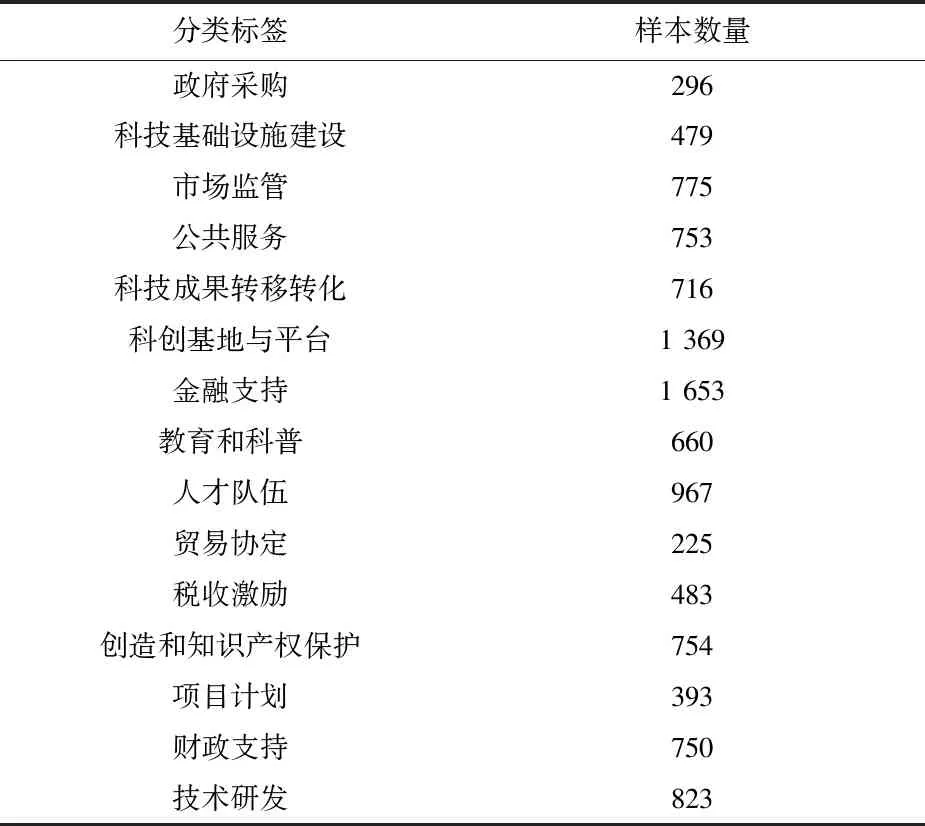
表1 政策内容句数据集分布
首先,对采集数据集进行遴选与去HTML标签等数据清洗操作,对政策全文做分句处理和筛选,剔除非措施内容的无关语句。然后,对得到的政策内容句数据集进行多标签分类标注,优先标注2021年的政策句,对于样本量过少的分类标签,补充标注2020年的政策句,使各标签下的语句数量尽量平衡,共得到11 096条科技政策标注数据,每种类别下的政策句数量如表1所示。本实验对各分类标签下的样本进行随机抽取,按6∶2∶2将数据集划分为训练集、测试集和验证集。
3.2 评价指标
与其他多标签分类方法使用的评价指标相同,本文采用精确率(Precision)、召回率(Recall)以及Micro-F1值作为模型评价指标。精确率是指预测正确的样本占数据中真正例与错误预测正例的样本中比例,召回率表示分类预测正确的样本占所有真实正确样本的比例。Micro-F1值是衡量多标签分类任务效果的重要指标,由于多标签文本分类赋予文本的标签数量不是固定的,micro对同一类别下的文本给予相同权重,将micro-precision和micro-recall调和平均后求得micro-F1,计算公式[37]如式(1)-(3)所示,这种方式可以部分消除多标签文本分类因为数据不平衡带来的影响。
(1)
(2)

(3)
3.3 实验配置
本文在以下环境进行实验:PyTorch 1.10.1,Python 3.8,操作系统Red Hat 4.8.5,CPU为Intel Xeon@2.4GHZx4,GPU为Quadro RTX 5000(16G),运行内存12G。
本文使用BERT-Base的中文预训练模型进行实验,该模型结构包含12层Transformers,隐藏层维度为768,注意力头(Head)数量为12,BERT模型其他参数通过微调后作为正式实验使用的参数,如表2所示。

表2 BERT参数设置
在多尺度卷积层,采用Adam优化器加速神经网络的训练过程,CNN的模型参数包括批尺寸(Batch_size)为4,随机失活率(Dropout)为0.5,学习率(Learning_rate)为3×10-5,激活函数为ReLU。
3.4 结果与分析
本文模型在测试集上各个类别和平均的精确率、召回率和Micro-F1值如表3所示。为了验证本文模型融合多尺度CNN的有效性,开展仅使用BERT的多标签分类实验,将文本输入BERT模型中,经全连接层映射到标签维度,通过Sigmoid分别对每个维度计算所有标签的分布,并与BERT-CNN的实验结果进行对比。

表3 多标签分类的实验结果比较
实验结果表明,本文提出的BERT-多尺度CNN模型,由于融合了Text Inception多尺度、多通道、更深层的卷积特性,相比于仅使用BERT的分类模型,能够有效获得不同尺度语句的特征,在平均精确率、召回率、Micro-F1值3个指标上分别取得了75.33%、69.12%、72.09%的效果,都要优于单一BERT模型,且平均召回率提升了17.28%,Micro-F1值提升了11.15%,因此BERT-多尺度CNN模型提升了多标签分类模型的整体性能。
通过对比模型在各个类上的结果,除“项目计划”类外,BERT-多尺度CNN模型在其他所有类别上的Micro-F1值均高于单一BERT模型,其中有超过一半的分类标签提升幅度超过了10%。BERT-多尺度CNN模型显著提升了一些样本量偏少的类别Micro-F1值,例如提升幅度前两位的“政府采购”类(35.18%)和“贸易协定”类(31.02%),由于在一定程度上解决了因样本量少所造成的特征提取不充分的问题,因此该模型能够弥补多标签数据分布不均的缺点。
对于“项目计划”这样错误较多且提升效果不理想的类,通过深入分析其对应的样本数据,发现这些类的标注数据中多标签样本较少,可能由于人工标注语料的问题,机器未能充分学习到这类语句的多维度特征,未来可通过提高多标签标注数据的质量来改善分类性能。此外,在模型的多标签分类层,本文以概率是否大于0.5为依据来判断语句是否属于该标签,这种判别方法本身就存在较大的误差,未来将探索判别方法的改进来提高分类的准确率。
4 总结与展望
本文面向当前科技政策文本内容的自动编码与多领域分类的需求,针对科技政策内容句具有信息密度大、涉及主题多、内涵分布不均衡等特点,提出了一种融合BERT与多尺度CNN的多标签文本分类方法。本文依据政策工具理论建立科技政策类别体系,构建的多标签分类模型结合了BERT和多尺度CNN的优点,通过捕获文本的局部特征与组合不同尺度的语句特征得到更加丰富的语义特征信息,从而提升模型在多标签分类任务上的性能。实验结果表明,该模型与单一BERT分类模型相比效果显著提升,为科技政策内容句的自动分类编码工作提供了参考。
利用本文提出的自动分类方法,可将科技政策内容中有决策价值的信息快速转化为定量数据,帮助决策者从政策工具视角把握政策体系结构。基于科技政策内容的多标签分类结果,实现不同政策工具视角的交叉与关联,反映了该政策信息在科技政策体系的空间定位,便于根据不同决策任务从不同维度对科技政策措施进行分类汇总,为支撑科技决策服务提供覆盖科技创新重点领域的政策数据资源。在未来工作中,将通过继续收集与遴选国家和地方各级政策文本,扩大政策分类数据集规模,针对当前样本数据较少的类别增加训练样本数量,进一步提高政策分类效果;另外,通过引入实体识别、知识图谱等技术,结合抽取到的科技创新主体、活动、条件等其他实体,进一步丰富科技政策内容的描述维度,能够从更多视角对政策数据进行组织管理。
