基于随机森林和Apriori 的心理问题预测技术研究
2022-12-01刘侠贾妮
刘侠,贾妮
(陕西中医药大学,陕西 咸阳 712000)
随着社会经济的快速发展,人们生活质量提高的同时,所面对的压力也随之增加。高校生由于就业、学习、情感等方面的影响,心理压力也存在逐年上升的趋势[1]。因此,学校和家长除了关注学生的教育外,还应当关注其心理健康状态,及时发现问题,并提前做好预防措施。根据当前的相关研究来看,有些青年学生由于从小受到的挫折较少,所以当其面对较大压力或挫折时,较容易产生负面情绪。同时,这类人群从主观上又抵制通过与人交流来缓解情绪,从而造成了一定程度的心理问题[2-4]。但目前对心理问题的智能化分析研究仍相对较少,而已有的算法也或多或少存在效率和准确率不足等问题。基于上述现象,亟需建立一套完整的心理问题预测方法,从而对高校生心理状态进行有效的监测与防控。
为此,该文将人工智能与数据分析领域的数据挖掘算法引入到心理问题研究中,提出了基于随机森林数据挖掘算法的心理问题预测方法。该方法通过对数据库中的原始数据进行选择、预处理、深度挖掘等操作,实现对知识的挖掘。同时,还能将挖掘出的知识通过可视化界面进行展示。最后三项实验结果验证了该文方法的有效性与可靠性,为有效监测学生心理健康状态,并及时采取对应措施提供了重要参考。
1 数据挖掘
1.1 基本原理
数据挖掘(Data Mining,DM)是一种融合计算机学、人工智能、数据库等多种学科的数据处理技术,其是数据库知识发现(KDD)的重要环节[5-6]。具体是指从海量的、未处理的、模糊的应用数据中,获取隐藏在数据深层、人们之前不了解但是又具有研究意义的信息与知识的过程,这些信息包括趋势、特征、规则以及相关性等。与传统数据分析不同,数据挖掘所得出的结果不依赖于任何的假设,其能够较大程度地避免主观因素的影响,从而保证结果的客观性与准确性。
一个典型的数据挖掘系统通常由数据源层、数据挖掘层以及人机交互层三部分组成[7-9],具体如图1 所示。
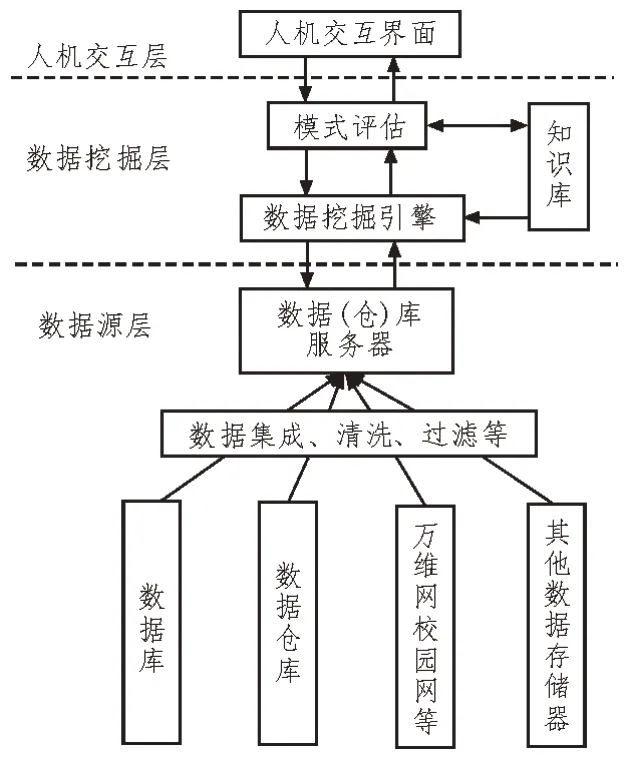
图1 数据挖掘系统组成
其中,数据源层在功能上可以分为两部分:
1)数据库、数据仓库以及一些其他的数据存储器。其功能是存储通过各种方式获取到的信息数据。数据仓库与数据库所存储的数据有所差异,区别主要在于数据库中存储的是未经过任何处理的原始数据;而数据仓库中则是包含一些为了满足实际数据分析而对原始数据进行简单处理后所得到的数据[10]。
2)数据(仓)库服务器。其主要功能是根据用户的个性化数据挖掘请求在数据库等数据存储器中调取符合要求的数据。
数据挖掘层是整个系统的关键层,负责接收和处理用户请求,同时反馈最终的数据挖掘结果,其包括数据挖掘引擎、知识库等。
人机交互层负责给用户提供一个与系统交互的可视化界面,用户可通过该层输入其所需信息。此外,数据挖掘系统也可通过该层将最终的数据处理结果直观地反馈给用户。
1.2 数据挖掘过程
数据挖掘通常是指从原始数据中获取所需知识的完整过程。数据挖掘系统对数据的挖掘可分为三个阶段[11]:数据准备、数据挖掘以及知识解释与表达。其过程如图2 所示。
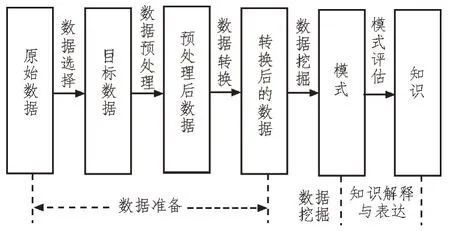
图2 数据挖掘过程
各环节的详细解释如下:
1)数据准备
数据挖掘所面对的是海量的数据,这些数据通常储存在数据库中,同时并未经过任何加工处理,且无法直接用于深层信息的挖掘,因此需要首先进行数据准备。数据准备由数据选择、数据预处理及数据转换组成,数据选择是指根据用户的数据挖掘请求从数据库中挑选出符合要求的原始数据,即目标数据;数据预处理则是为了解决原始数据中包含的诸多问题,例如噪声、缺省等,该预处理内容包括数据清洗、推导缺值数据、去除重复信息以及数据类型转换等[12];数据转换是将数据从一种表现形式变成另一种表现形式的过程,将预处理后的数据转换成所需的数据表现形式。数据准备是整个数据挖掘过程中耗时较长的一步,其质量较大程度上影响了后续数据挖掘的效率及结果的准确性。
2)数据挖掘
数据挖掘是整个系统的核心过程,也是技术难点所在,通过对目标数据的个性化分析,进而挖掘其内在知识。这一步首先根据用户需求确定具体的挖掘任务,然后根据挖掘任务确定最适合数据处理的数据挖掘算法,最后则是进行数据挖掘操作,以获得最终结果[13]。目前常用的数据挖掘算法包括决策树算法、随机森林、逻辑回归、支持向量机以及朴素贝叶斯算法等,在实际选择中,需根据具体的挖掘任务确定。
3)知识解释与表达
知识解释与表达是指将数据挖掘的结果用可视化且易于理解的方式进行解释与表达,从而确保用户能够了解知识的使用方式[14]。值得注意的是,数据挖掘阶段所得到的结果可能存在冗余或无关的知识,此时就需要进行去除操作;此外,也有可能得到不满足用户需求的结果,则需要重新进行上述步骤。
2 心理问题预测
2.1 设计架构
该文利用数据挖掘提出的心理问题预测技术主要是对心理数据的分析与处理,以便及时发现其中存在的问题。其具体的技术设计架构如图3 所示。
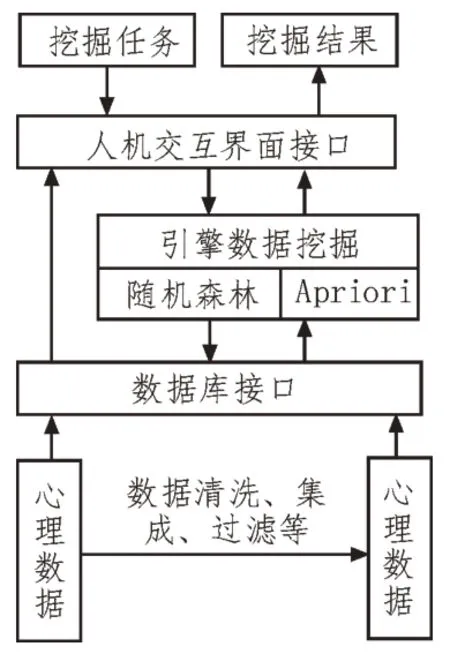
图3 心理问题预测技术架构
2.2 随机森林
随机森林(Random Forest,RF)是解决实际应用中分类问题的一种高度、灵活的数据挖掘算法[15]。分类通常是指将待分类项按照一定规则映射到预先定义好的类的过程。随机森林从根本上是若干相互独立的“树”共同完成数据分析的方法,其基本组成单元是决策树。构建随机森林模型的示意图如图4 所示。
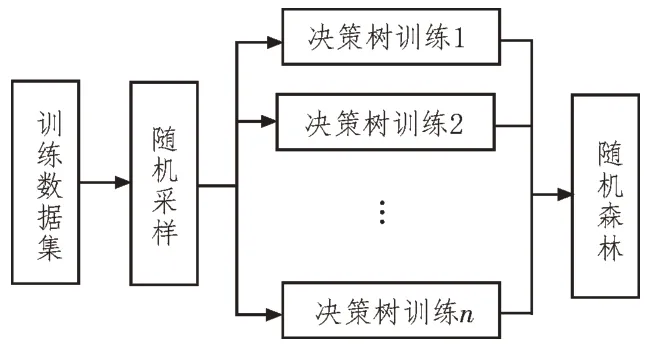
图4 构建随机森林模型示意图
上述过程可简单描述为:首先根据实际需要将待处理数据集(训练数据集)进行随机采样,以此得到n个训练子集,各决策树根据逐一对应的训练子集独立进行模型的学习与训练,进而得到n个不同的决策树。这些决策树既相互独立又相互联系,共同组成随机森林。随机森林中的“随机”一方面体现在训练数据集的选择“随机”,另一方面也体现在决策树训练时,属性(特征)的选择“随机”。
利用随机森林模型对新样本数据进行处理时,其中包含的所有决策树均会判断该样本应属于哪个类别,并进行内部投票。进而选取最优解作为随机森林的分类预测结果。
2.3 Apriori算法
Apriori 算法是一种解决关联规则问题的数据挖掘算法[16],文中提出Apriori 算法的目的在于探寻海量信息之间的隐含联系或相关性。其常用于挖掘信息中出现次数最多的信息集合(即频繁集),这些集合通常能够指导事务的决策。Apriori 算法的工作流程如图5 所示。
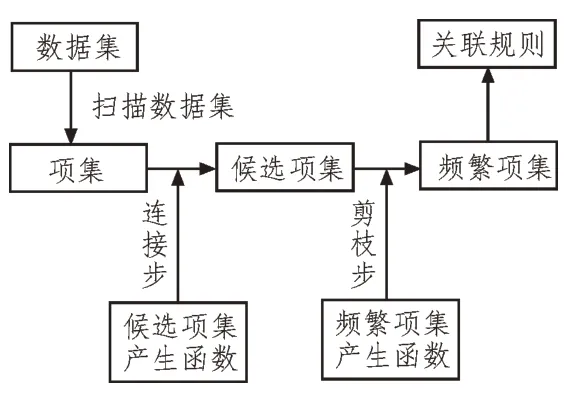
图5 Apriori算法工作流程示意图
该算法在整体上可以分为两个过程:连接过程和剪枝过程。其中,各自对应的核心算法为候选项集产生函数和频繁项集剪枝函数。Apriori 算法的工作流程可描述为:
1)对待处理数据集进行扫描,同时计算各项支持度,产生候选项集;
2)根据预先设定的最小支持度阈值,对候选项集中的数据进行过滤,形成频繁项集;
3)对频繁项集进行连接,形成新的候选项集,重复进行步骤2)直至满足终止条件为止,即频繁项集对应的候选项集为空集;
4)输出此时的频繁项集,并将其进行连接,形成最终的关联规则。
3 实验测试
为了验证该文提出的基于随机森林数据挖掘方法的心理问题预测技术的有效性与可靠性,验证方法性能是否满足要求且功能是否完善,该文进行了三项实验,分别为单元测试、性能测试及预测效果测试。
3.1 环境搭建
在进行实验前需要搭建测试系统环境,相关环境信息如表1 所示。
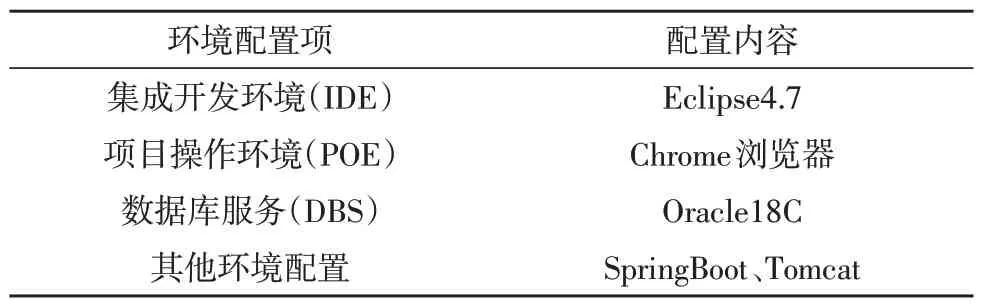
表1 测试环境系统参数
3.2 单元测试
单元测试也称为功能测试,是对系统、方法、算法等使用最广泛的一种测试。单元测试是对组成模块的独立测试,主要是为了测试各组成模块能否按设计要求实现所对应的功能。该测试可以无需等到开发完成后进行,在设计开发阶段便可展开。该项实验的测试内容及测试结果如表2 所示。

表2 单元测试结果
由表2 可知,利用该文方法建立的系统涉及到的各组成模块均能够按照设计需求较好地实现其所对应的功能,并为后续进行的其他项测试奠定了良好的基础。
3.3 性能测试
性能测试主要测试系统在多种正常、负载、峰值测试情况下的实际表现。通过多次实验发现,利用该文方法建立的系统始终处于良好的工作状态,并保持较高的运行速度。同时,CPU 使用率也低于预期值,且资源耗费较少。相关性能测试的结果如表3所示。
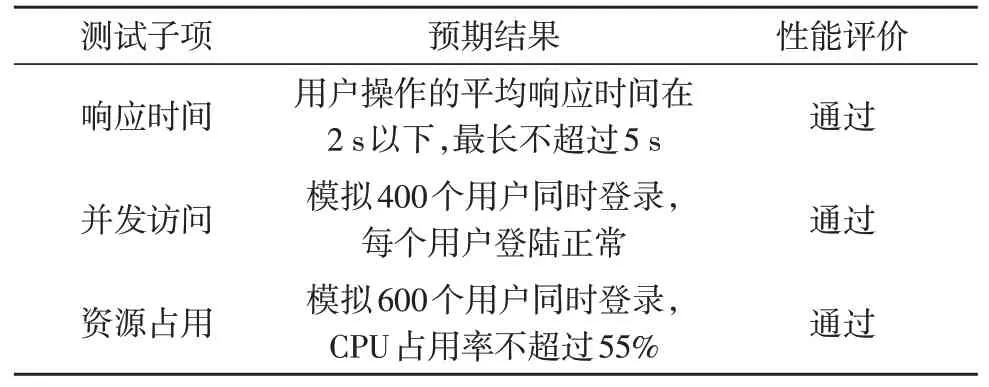
表3 性能测试结果
3.4 预测效果测试
最后是心理问题的预测效果测试。为了体现该文提出方法的优势,设置人工分析和关联分析算法作为结果对照组。实验数据为某高校的年度心理问卷调查结果,预测效果如表4 所示。
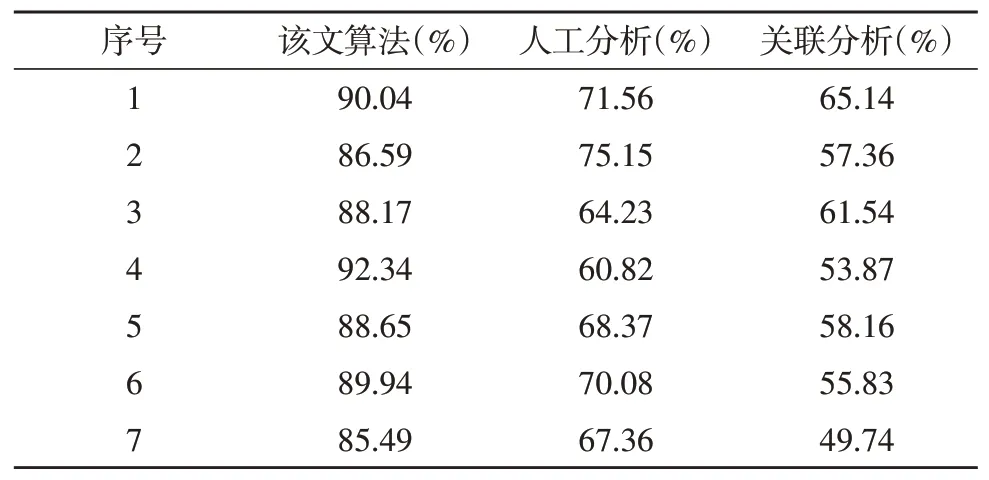
表4 不同算法的心理问题预测准确率
由4 表可以得出,该文预测准确率平均值为88.74%,而人工分析和关联分析预测准确率平均值分别为68.22%和57.38%,该文方法对于心理问题预测的准确率明显高于其他两种方法,平均准确率能够达到88.74%,这对于及时发现学生人群中所存在的心理问题具有重要意义。
4 结束语
该文介绍了数据挖掘系统的基本原理,分析了数据挖掘系统从原始数据中获取所需知识的完整过程,根据数据挖掘中用来处理分类问题的随机森林算法与用来处理关联规则问题的Apriori 算法,提出了基于随机森林数据挖掘方法的心理问题预测方法。采用该方法完成对系统的搭建并进行了单元测试、性能测试以及预测效果测试,测试结果表明,各组成模块均能够按照设计需求较好地实现对应功能,且系统整体可在负载、正常、峰值下稳定运行。
