基-4FFT处理器的优化设计与应用
2022-11-30尹若童张乙海宋紫祎
高 博, 尹若童, 张乙海, 宋紫祎
(1.四川大学 物理学院,四川 成都 610065;2.四川大学 吴玉章学院,四川 成都 610065)
离散傅里叶变换(discrete Fourier transform,DFT)在信号处理中有着重要应用,是确定研究信号时域和频率转换的最直接有效的数学过程。但在其实现过程中需要进行大量的复数乘法及正余弦函数运算,其计算量与变换区间长度N的平方成正比,随着DFT输入点数的增加,其运算量将会增大。快速傅里叶变换(fast Fourier transform,FFT)算法简化了DFT算法过程,有效降低了运算量,FFT处理中提出了基-2、基-4、基-8等不同算法,各种算法所需运算量的评估结果见表1所列。

表1 几种FFT算法复数乘法运算量比较
基-2FFT和基-4FFT算法运算量较少,结构规整,易于实现,并且具有可以同址运算、内部数据不需重排等特点[1],而基-8FFT算法具有更快运算速度,但在此基础上程序复杂度较高,灵活性有所欠缺[2-3]。基-4算法在速度和复杂度上是折中方案,且具有相对灵活的处理点数。
在实际应用中,为了提升运算速度和集成度,通常单独设计用于实现FFT的处理器,但仍然存在占用资源多、计算速度慢、数据类型转换复杂等问题[4-5]。为解决这些问题,文献[6]通过可重构蝶形运算器进行不同 FFT 算法的切换,使用基-2FFT 算法做更多序列长度的覆盖,基-8FFT 算法进行长序列的加速。但这种设计结构复杂,且存在延时问题,1 024点变换需要较多的时序遍历所有的点数,也有设计通过象限映射的方法节省存储资源,并且在蝶形单元计算时采用超前进位的加法器,乘法器采用Booth编码减少部分积[7],但这种算法会给后端布局布线工作产生影响,并不符合实际应用的需要。文献[8]报道基-4FFT算法在50 MHz时钟频率下,进行1 024点运算需要消耗41.28 μs。
为解决处理器消耗资源多、计算速度慢等问题,本文进一步分析基-4FFT算法,优化原有算法实现硬件结构。通过分析数据流路径,采用分时复用和流水线结构设计电路实现低延迟。设计中采用MATLAB对伸缩系数和旋转系数进行预处理,降低系统复杂性。
现场可编程逻辑门阵列(field programmable gate array,FPGA)原型结果表明,工作频率在50 MHz下实现了11.90 μs完成1 024点傅里叶变换算法。该结果相对于同期研究中普遍使用的顺序处理算法而言,延时降低约71.2%,同时该设计硬件资源消耗较少。
1 基本原理
1.1 FFT算法基本原理
设有时域有限长序列{x(n)}的长度为N,且满足N=4M,其频域值{X(k)}可表示为:
X(k)=DFT[x(n)]=
(1)

1.2 基-4DIT-FFT算法
(2)
令
(3)
则可得:
(4)
基-4蝶形运算原理如图1所示。
从图1可以看出,1个基-4蝶形运算的单元需要进行3次复数乘法和8次复数加法,则可得进行N=4M点基-4DIT-FFT运算需要进行3MN/4次复数乘法和2MN次复数加法,远小于直接计算所需的N2次复数乘法和N(N-1)次复数加法,提高了运算速率。

图1 基-4蝶形运算原理示意图
2 FFT处理器设计与实现
FFT处理器由4个模块构成,分别为预处理模块、数据处理模块、数据存储模块和处理器状态控制模块,具体结构如图2所示。
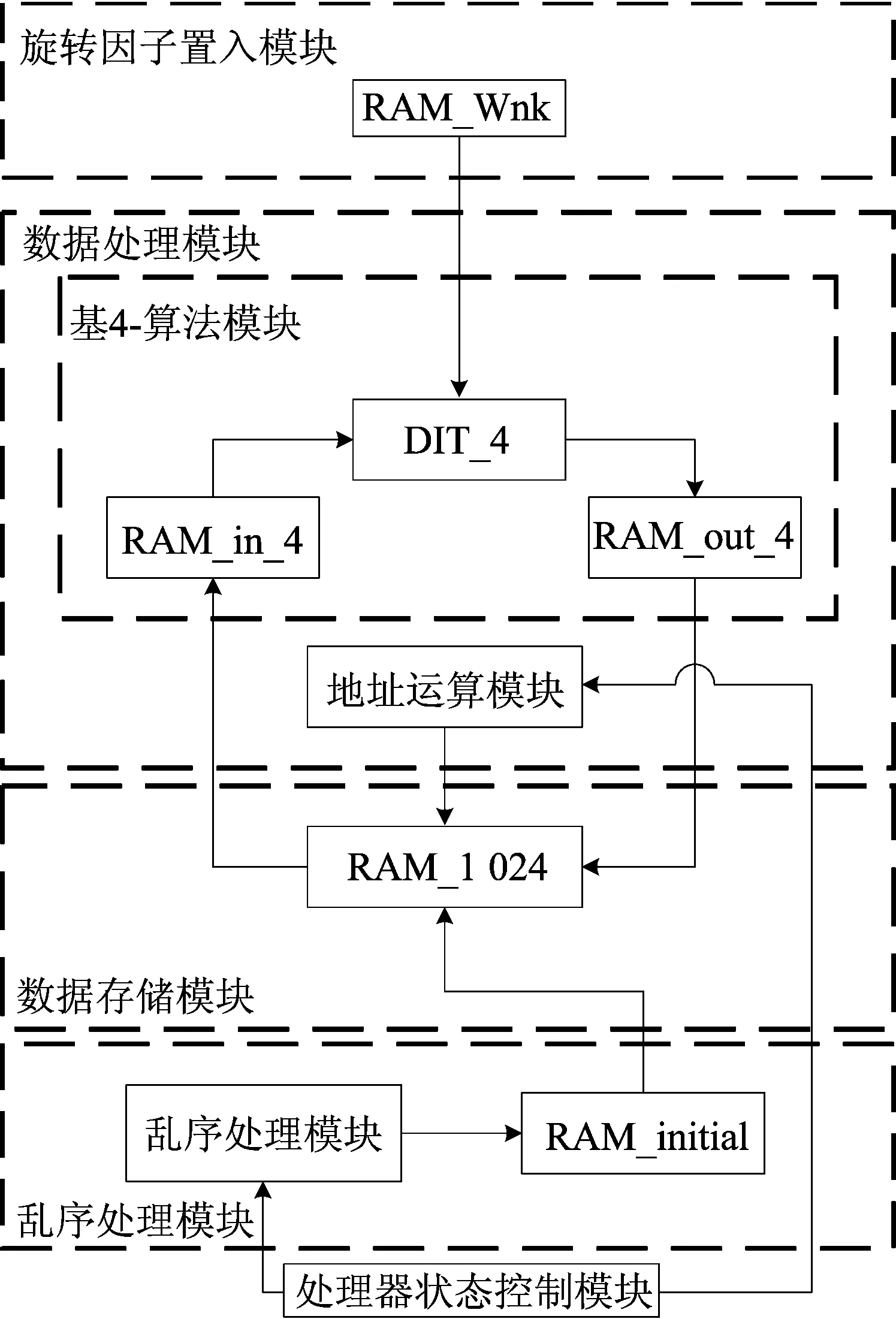
图2 系统结构
预处理模块包含旋转因子置入模块和乱序处理模块,其中旋转因子置入模块的核心为高精度的坐标旋转数字计算(coordinate rotation digital computer,CORDIC)算法。数据处理模块主要用于循环运算及中间结果的存储1 024点的32位数据经过地址运算系统和RAM-in-4选择需要的数据进行读操作,然后经过DIT-4模块的计算,通过地址运算系统和RAM-out-4将运算结果写到相应的地址位,再通过预处理模块中的乱序处理模块调整存储顺序。数据存储模块用于中间信息的存储以及经过多级运算后最终结果的存储及输出。处理器状态控制模块负责系统工作转换。
2.1 预处理模块
2.1.1 旋转因子置入模块
2.1.2 乱序处理模块
由时间抽取基-4FFT原理可得,若DIT算法的输出为顺序排列,则要求其输入为特定的规律排列,因此,设计乱序处理模块将顺序输入的数据按照系统计算时所需要的乱序结构重新排序。首先,将计算点数1 024点转化为10位二进制的地址,然后将原地址为A1A2A3A4A5A6A7A8A9的数据转存入地址A9A8A7A6A5A4A3A2A1。转化后对应地址的数据作为后续模块的输入。
本文使用计数模块,用10位二进制计数器,按照0~1 023的地址位读取原始数据,再将其按照乱序处理之后的地址置入新的RAM-initial中,完成数据的乱序排列。
2.2 数据处理模块
2.2.1 基-4算法模块
基-4算法模块主要完成蝶形运算过程,需要按照地址运算模块从随机存储器读取等待处理的数据,并将计算结果覆盖存储于相同存储器的相同地址位。每一组基-4算法模块由2个容量为4的32位存储器RAM-in-4、RAM-out-4以及核心蝶形运算单元DIT-4构成。其中,2个存储器下,读取并存储每一点的数据进入RAM-1 024中。而核心蝶形运算单元采用图1所示原理实现运算。该处理器采用分时复用技术设计每一级算法结构,因而每一级内的运算只需要1个基-4算法模块,有效地利用了硬件资源,减少了资源消耗。
2.2.2 地址运算模块
目前基于FPGA的FFT硬件实现结构主要分为递归结构、流水线结构和全并行结构[10]。在数据处理模块中,5级级联的设计采用流水线级联框架,如图3所示。

图3 混合构架运算示意图
为了减少硬件资源消耗,根据DIT每一级的计算规则,蝶形运算中采用分时复用技术实现。根据计算规则,本文将数据处理分为5级,第1级输入顺序为乱序处理后的顺序排列,同级间由地址递进规则置入基-4算法模块,并依照地址运算输出至下一级的输入存储器等待下一级计算。根据级联间的时序,每一级进行一定次数的DIT计算后下一级即可开始,减少了等待每一级所有点数计算完毕所需的时间。
系统整体构建时,基于基-4DIT变换的模式,当进行4M点运算时,需进行M级蝶形运算,即将第1级拆分成4M-1个4点蝶形运算,第2级拆分成4M-2个16点蝶型运算,以此类推至第M级进行1个4M蝶形运算。而在不同级之间,同一级内的点参与计算的顺序不同,此时顺序需要由地址做递进运算来确定。根据基-4DIT计算规则,在第M级内,按照顺序分为4M组,根据地址计算,每次依次从1个组内提取4个点的地址对应的数据,将其地址对应的值置入于基-4算法模块中的随机存储器RAM-in-4中。此时地址的计算为同级递进运算。
同级递进运算要求前一级已经完成计算并将计算所得数据存入该级前置RAM中,但根据现有FFT计算方式,均将一级完全计算完毕后开始下一级的计算,为了从算法上减少完全计算所需的时间,本文采用级联间的部分延时来满足每一级对前一级数据的要求。因此,对于1 024点FFT计算,第1级蝶形运算单元需要延时4个周期;第2级蝶形运算单元需要延时16个周期;第3级蝶形运算单元需要延时64个周期;第4级蝶形运算单元需要延时256个周期;第5级蝶形运算单元需要延时1 024个周期。
每级阵列在延时完毕后,下一级阵列即开始顺序运算,每级相互并行,同一级之间的每组运算级联。每级运算结果都将由数据存储器按位进行读取操作,直到M级运算完成,即循环结束。
2.3 数据存储模块
数据存储器在进行蝶形运算时,按位进行中间结果的读取操作,直到循环结束。当多级运算完成后,数据存储器中的结果即可作为最终结果读出。本文采用的系统级数为5,按照虚部、实部共使用10个1 024×32的随机存储器RAM-1 024来存储数据。
2.4 处理器状态控制模块
该模块基本单元就是1个状态机,主要控制地址运算模块和乱序处理模块,两者独立进行,包括ST-REVER、ST-1、ST-2、ST-3、ST-4、ST-5、NORMAL、ST-OUT共8个状态,如图4所示。
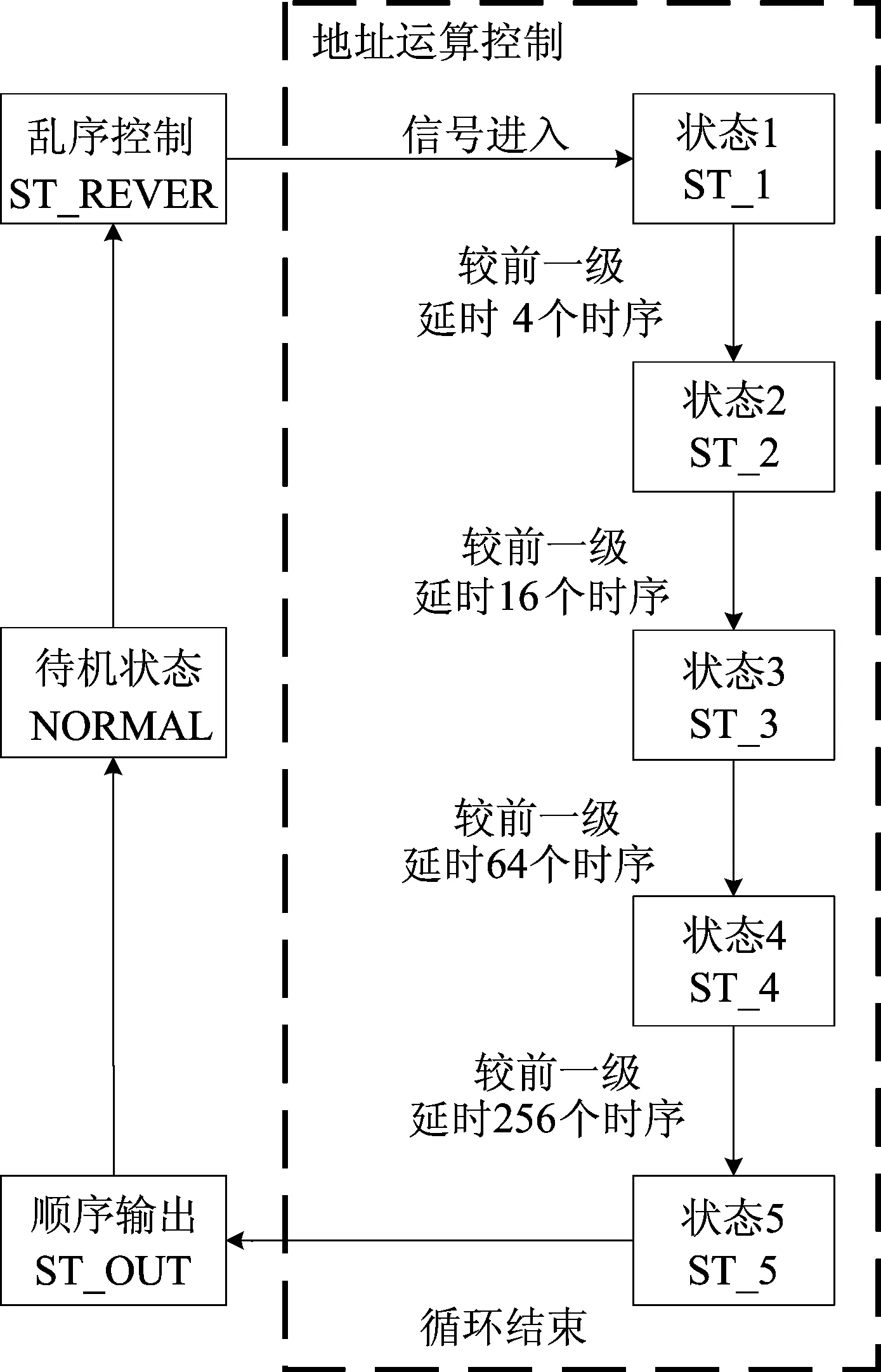
图4 处理器状态控制模块结构
其中:当没有有效数据进入系统时,状态机一直处于NORMAL状态;当检测到新信号数据有效时,系统开始进入ST-REVER状态,乱序计数器开始计数;乱序计数器计数完毕后,系统进入ST-1状态,第1级计数器开始计数,每次计数置入相应4个地址的数据进入基-4运算模块;当第1级计数器计数为4时,状态机进入ST-2状态,第2级计数器开始计数,每一级计数后进行此次操作;当第2级计数器计数为16时,状态机进入ST-3状态,第3级计数器开始计数;当第3级计数器计数为64时,状态机进入ST-4状态,第4级计数器开始计数;当第4级计数器计数为256时,状态机进入ST-5状态,第5级计数器开始计数;当第5级计数器计数为256时,状态机进入ST-OUT状态,读出计数器开始工作,将最后计算的数据输出。
3 结果与验证
该处理器的测试在友晶DE2开发板上验证,采用的FPGA是Cyclone Ⅱ EP2C35设计,所使用的硬件资源包括9 110个组合逻辑单元和3 418个时序逻辑单元,分别占总逻辑单元数的27%和10%。此外,还消耗存储器356个,内嵌乘法器35个。本文主要通过分时复用减少部分资源的消耗。虽然本文的资源相对于同期研究提高了1倍,但根据本文对算法的分析,若不采用本文算法,则仅增加流水线的寄存器而达到速度提升71.2%的效果需要资源消耗量提高约2.5倍。
依据算法,第1级蝶形运算单元需要4个额外周期;第2级蝶形运算单元需要16个额外周期;第3级蝶形运算单元需要64个额外周期;第4级蝶形运算单元需要256个额外周期;第5级蝶形运算单元需要256个额外周期。因此处理1组1 024的数需(4+16+64+256+256)=596个周期。时序仿真结果如图5所示。

图5 时序仿真结果
图5中:cp信号为系统时序,为方波信号;rst为系统工作信号,低电平有效;rst1为系统预备信号,高电平有效;qq-i、qq-r分别为系统最后一级输出信号的虚部与实部,有符号数;系统频率在50 MHz下,计算并置入旋转因子需要22 μs,1 024点算法过程需要11.9 μs;时序分析结果表明该设计可以达到的最高频率为200 MHz。
测试中使用实际采集的光电容积脉搏波信号作为信号源,经过所设计处理器输出结果如图6所示。
由测试结果读出主频率点1.08 Hz,计算得到脉搏数为65次/min。这与医用脉搏仪读取数值一致,从而证明了处理器设计的正确性。基于FFT分析生理参数的监测技术可应用于便携、快速、准确地测量心率和呼吸率的研究,可作为医院或家庭地日常监护[11]。

图6 算法的实际应用结果
4 结 论
本文通过分析基-4DIT-FFT算法流程,针对多级结构特点采用分时复用和流水线数据处理方法设计了一款1 024点FFT处理器芯片。设计中通过提前置入旋转因子的方法减少了系统准备时的时序消耗;在5级结构中采用流水线技术构架,且流水线内不需要等待一级全部计算完毕再进行下一级计算,与普遍使用的顺序处理算法相比,减少了进行整个基-4FFT运算时的时序消耗。同时在单级运算中蝶形算法设计采用分时复用技术减少了硬件资源的消耗。通过FPGA原型验证得到,该处理在50 MHz条件下仅需要11.9 μs即可完成1 024点运算,与同期其他研究相比,速度提高71.2%。通过进一步优化单级中采用部分并行算法可提高速度,但也会消耗更多资源。
