基于时间注意力机制和EfficientNet的视频暴力行为检测
2022-11-30蔡兴泉封丁惟王通孙辰孙海燕
蔡兴泉,封丁惟,王通,孙辰,孙海燕
基于时间注意力机制和EfficientNet的视频暴力行为检测
蔡兴泉,封丁惟,王通,孙辰,孙海燕*
(北方工业大学 信息学院,北京 100144)(∗通信作者电子邮箱sunhaiyan80@hotmail.com)
针对一般的暴力行为检测方法模型参数量大、计算复杂度高、准确率较低等问题,提出一种基于时间注意力机制和EfficientNet的视频暴力行为检测方法。首先将通过对数据集进行预处理计算得到的前景图输入到网络模型中提取视频特征,同时利用轻量化EfficientNet提取前景图中的帧级空间暴力特征,并利用卷积长短时记忆网络(ConvLSTM)进一步提取视频序列的全局时空特征;接着,结合时间注意力机制,计算得到视频级特征表示;最后将视频级特征表示映射到分类空间,并利用Softmax分类器进行视频暴力行为分类并输出检测结果,实现视频的暴力行为检测。实验结果表明,该方法能够减少模型参数量,降低计算复杂度,在有限的资源下提高暴力行为检测准确率,提升模型的综合性能。
暴力行为检测;时间注意力机制;卷积长短时记忆网络;EfficientNet模型
暴恐袭击、恶意冲突事件的发生,会对公民的人身、财产安全造成巨大损失,对社会环境造成不良影响[1]。国家和政府不断提高对公共安全的重视程度,持续推进“平安城市”建设。城市的安防视频监控设备数量快速增长,人力难以及时监测大量的监控视频[2],因此,智能安防逐渐发展起来,而暴力行为监测作为智能安防的重要分支也得到越来越多的关注和研究。
随着各类短视频软件的兴起,视频更广泛、更频繁地在互联网上传播[3],不进行有效的规范和监管,大量传播的暴力视频可能对青少年身心造成影响,而人工难以及时审核用户上传的海量短视频。因此,本文主要研究智能化的视频暴力行为检测方法,提高视频监测管控的效率。
1 相关工作
为了实现智能化监测,已经有一些学者开始研究暴力行为检测方法。根据不同的输入信息类型,可以将检测方法分为基于音频的暴力行为检测方法、基于音视频的暴力行为检测方法和基于视频的暴力行为检测方法[4]。
暴力行为常会伴随着喊叫声、打斗声、碰撞声等,对不同的音频进行分析可以实现暴力行为检测。Sarman等[5]提取了音频时域上的过零率(Zero Crossing Rate, ZCR)特征,与随机森林(Random Forest)分类器组合,获得了较好性能。为了降低背景噪声对目标声音的干扰,解决目标声音在音频中不够突出的问题,杨吕祥[6]提出一种改进的卷积循环神经网络(Convolutional Recurrent Neural Network, CRNN),并引入多层注意力机制来降低噪声的干扰,有效提高了暴力音频检测的性能。但是此类基于音频的暴力行为检测方法不能有效利用视频数据,难以达到最优效果。
随着计算机视觉的发展,结合音频特征和视频特征的基于音视频暴力行为检测方法受到广泛关注和研究。Acar等[7]提出在决策层将中间层级音频特征和低层级视频特征相融合,以检测电影中的暴力镜头;谷学汇[8]提出结合文本、音频和视频的多模态信息融合暴力行为检测算法,提高了模型性能。但是此类方法需要视频当中包含音频信息,而城市的监控设备所采集的视频几乎不包含音频信息,且短视频平台的视频多添加配乐,易对音频识别造成巨大干扰。
为了提高暴力行为检测方法的普适性,研究基于视频的暴力行为检测方法显得尤为重要。Gao等[9]提出了一种新的光流特征定向暴力流(Oriented Violent Flows, OViF),充分利用了运动方向上的幅度变化信息;宋凯[10]提出了一种结合运动团块属性和光流信息进行暴力检测的算法。Mabrouk等[11]提出了一种基于感兴趣点、时空域信息和光流信息的兴趣帧局部幅度方向分布特征(Distribution of Magnitude and Orientation of Local Interest Frame, DiMOLIF),在拥挤和非拥挤视频中取得了较好性能;Zhang等[12]提出的运动韦伯局部描述符(Motion Weber Local Descriptor, MoWLD)对暴力行为的检测效果良好。但是这类人工特征的设计过程比较繁琐,而且针对特定数据集设计的特征易受噪声影响。
随着深度学习算法的快速发展,卷积神经网络(Convolutional Neural Network, CNN)逐渐被应用于行为检测中。丁春辉[13]利用三维卷积核提取视频序列的时空特征,但是三维卷积不能充分地提取长时特征信息。为了获取丰富的时空特征,Dong等[14]分别提取原视频帧、光流图像、加速流图像的短期特征,利用长短时记忆(Long Short-Term Memory, LSTM)网络提取长期特征,但是多流网络模型较复杂,光流特征计算量较大,耗时较长。Chatterjee等[15]利用离散小波变换(Discrete Wavelet Transform, DWT)和CNN提取空间特征,然后利用双向长短时记忆(Bi‑directional LSTM, BiLSTM)网络来预测帧序列的暴力行为。虽然LSTM在处理时序任务时表现优良,但在处理图像序列时,LSTM通过全连接层获取全局特征来进行建模,没有充分利用局部的空间特征。Shi等[16]将卷积运算运用到LSTM的输入和状态转换中,提出卷积长短时记忆(Convolutional LSTM, ConvLSTM)网络预测未来的降雨强度,能够更好地提取图像序列的时空特征。受此启发,本文利用ConvLSTM网络提取暴力视频的全局时空特征。
传统的网络扩展方法通常只在深度、宽度和图像分辨率三方面的其中一个或两个方面对网络模型进行单方面或两方面的扩展来提升模型性能。例如,随着网络层数的加深,模型的准确率达到饱和甚至下降,为了解决这种“退化”现象,He等[17]提出了深度残差网络(Deep Residual Network, ResNet),解决了网络加深时的梯度消失或爆炸问题,加深了网络层数,常用的ResNet50在各种深度学习任务中表现较好。但是ResNet只在网络深度上进行扩展,且网络层数的增加导致参数量较大。Han等[18]使用轻量操作代替部分传统卷积层生成冗余特征,提出了GhostNet,能在保证精度的同时减少网络的整体计算量。刘超军等[19]基于GhostNet提出一种改进的有效卷积算子目标跟踪算法,减少了网络的参数量和计算量。Wei等[20]使用轻量级和高效的模型对遥感图像进行分类,对GhostNet进行了改进,减少了参数量。但是GhostNet在平衡计算量和性能时,只对网络的通道数进行了扩展,在精度方面还有待提高。Tan等[21]提出了一种高效简单的复合缩放方法,在限制内存和计算量的情况下统一缩放网络的深度、宽度、和图像分辨率,得到了轻量化EfficientNet系列模型,获得了更高的效率和准确率。尹梓睿等[22]将EfficientNet引入行人重识别领域,减小了网络模型参数规模,性能却有所提升。受此启发,本文将EfficientNet引入暴力行为检测中,提取视频的帧级空间暴力特征。
根据人类视网膜特性,注意力机制被提出并广泛应用,根据信息的重要性分配动态权重参数来强化关键信息,提升模型的性能[23]。梁智杰[24]将注意力机制引入LSTM网络,关注重要的视频帧,有效利用对手语识别结果影响较为显著的信息,提高了模型对手语的识别能力。在暴力行为视频中,每个视频帧所包含信息的重要程度各不相同,某些重要的视频帧对暴力行为检测的贡献比较大。受此启发,本文将时间注意力机制引入暴力行为检测方法中,充分利用关键视频帧的重要信息。
基于以上分析,一般的暴力行为检测方法存在受音频信息限制、人工特征设计繁琐、参数量大、计算复杂度高、时空特征提取不充分和准确度较低等问题。针对这些问题,本文主要研究基于时间注意力机制和EfficientNet的视频暴力行为检测方法。
2 本文方法
本文基于时间注意力机制和EfficientNet的视频暴力行为检测方法的主要步骤包括:首先,预处理数据集,计算得到前景图;然后,将前景图输入到网络模型中提取视频特征,利用轻量化模型EfficientNet提取前景图中的帧级空间暴力特征,利用ConvLSTM网络进一步提取视频序列的全局时空特征;接着,结合时间注意力机制,计算得到视频级特征表示;最后,将视频级特征表示映射到分类空间,利用Softmax分类器进行分类,输出检测结果,实现视频的暴力行为检测。
2.1 预处理数据集
本文所用的数据集为视频格式,每个数据集由多个视频段组成,视频包含正常运动的人群以及暴力行为人群。为了提高算法的性能,在输入网络之前,需要对视频数据进行预处理,包括提取视频帧、增强数据集和计算前景图三部分。
2.1.1提取视频帧
2.1.2增强数据集
理论上来说,数据的规模越大、质量越高,模型的泛化能力越强。为了提高模型的鲁棒性,本文采用在线数据增强的方法,不改变训练数据的数量,而是在训练时对加载数据进行裁剪和翻转等处理,经过多轮次训练之后,等效于数据增加。
翻转主要分为水平翻转、垂直翻转和原点翻转三种方法。现实世界正常拍摄的视频内,人群都不会是倒立的,加入垂直翻转或原点翻转后会改变原图像的语义,而本文所研究的暴力行为检测就是针对现实世界的真实视频的,因此本文只采用水平翻转的方法。实际操作时,对同一视频中的所有帧,遵循相同的在线数据增强技术,在每个训练迭代期间,从四个角或从中心随机裁剪帧图像中大小为224×224的一部分,并在输入到网络之前随机水平翻转。
2.1.3计算前景图
视频由背景图和前景图构成,相邻帧图像间的背景图差值较小,而前景图由于物体的运动差值较大。本文所用数据集背景变化较小,暴力行为多伴随着剧烈的运动,前景目标运动明显,计算前景图能够减少背景信息的干扰,更加关注视频中剧烈运动部分的变化,加强对视频中运动部分的表征能力。将帧间差分看作是光流图像的一种粗略近似形式,使得神经网络被迫对帧间变化而不是帧本身进行建模。帧间差分法计算简单快速,计算复杂度比光流法低得多,因此,采用二帧差法计算前景图,首先计算帧差图,然后进行二值化处理,最终得到前景图。具体步骤如下:


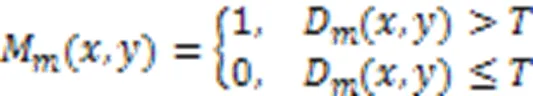
至此,完成数据集的预处理,得到前景图,将其输入到网络模型中,能够在计算复杂度较低的情况下,提高模型的视频表征能力,减少背景信息的干扰,提升算法性能。
2.2 提取视频特征
预处理数据集后,需要提取视频的时空特征,对暴力行为进行建模,最终实现暴力行为的检测。视频中的暴力行为是一个连续性强、关联性大的动作行为,具有大量的时序信息。为了减少参数量、充分利用视频信息,本文首先利用轻量化模型EfficientNet提取前景图中的帧级空间暴力特征;然后,利用ConvLSTM网络进一步提取视频序列的全局时空特征,充分利用视频的空间信息和时间信息,提升后续的检测分类效果。
2.2.1基于EfficientNet网络提取空间暴力特征
为减少参数量、提升模型性能,本文采用轻量化模型EfficientNet提取空间暴力特征,即单一时刻的帧级空间特征。首先,设定缩放条件,优化缩放倍率,利用复合缩放方法得到EfficientNet系列网络;然后,选择EfficientNet‑B0网络提取帧级特征;最后,输出空间暴力特征,为后续提取全局时空特征做准备。复合缩放方法如图1所示。
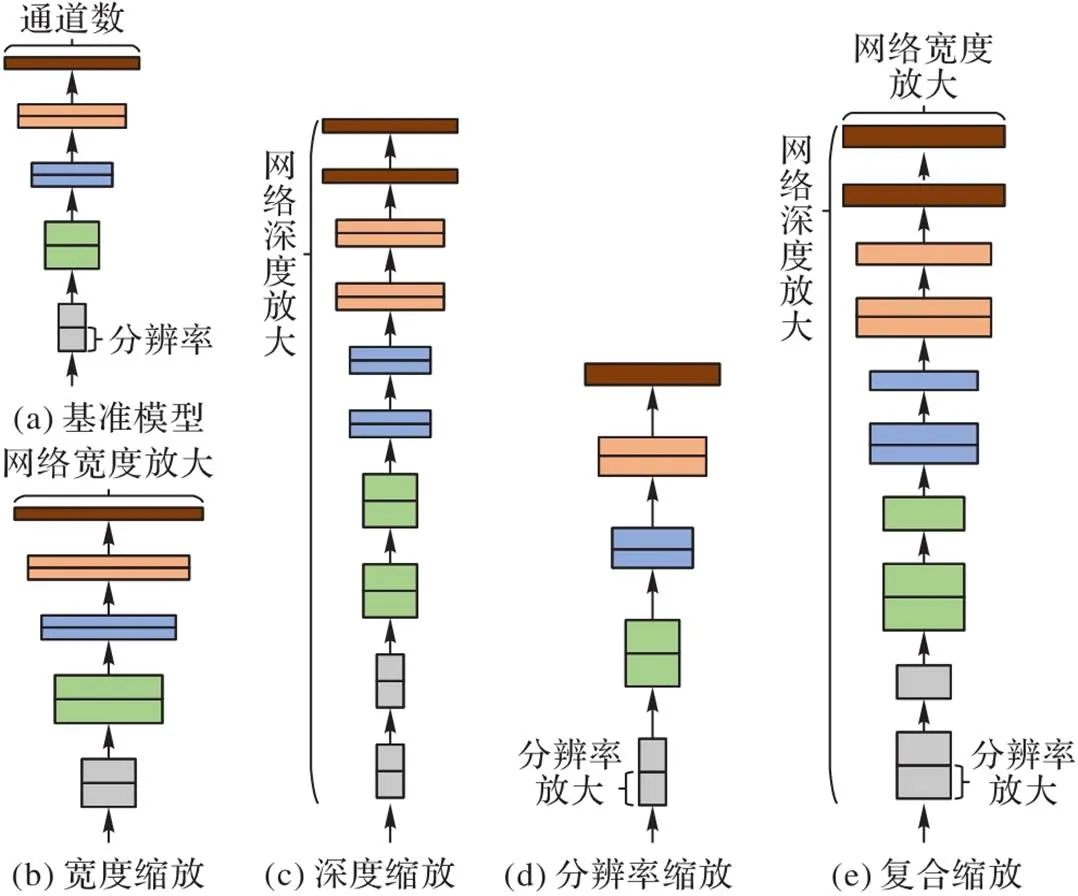
图1 EfficientNet模型复合缩放方法示意图

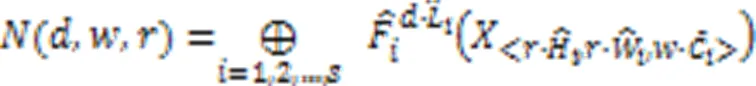




步骤4 选取EfficientNet‑B0。EfficientNet‑B0的参数最少,对资源要求较低,EfficientNet‑B1之后的网络模型参数量逐渐增大,计算量也相应增大,效率逐渐降低。因此,本文选取EfficientNet‑B0作为帧级特征提取网络,EfficientNet‑B0结构如图2所示。

图2 EfficientNet‑B0的网络结构
EfficientNet‑B0由多个移动翻转瓶颈卷积(Mobile Inverted Bottleneck Convolution, MBConv)模块组成,MBConv模块由深度可分离卷积(Depthwise Separable Convolution)、批归一化(Batch Normalization)、Swish激活函数、连接失活(DropConnect)组成,其中还引入了压缩与激发网络(Squeeze-and-Excitation, SE)模块,MBConv模块的结构如图3所示。

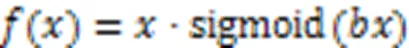
步骤5 输出空间暴力特征。本文去掉EfficientNet‑B0模型最后阶段的全连接层和Softmax层,将最后卷积层得到的输出特征作为提取到的帧级空间暴力特征并输出。
至此,通过复合缩放方法得到EfficientNet‑B0模型,从前景图中提取帧级空间暴力特征,并将输出特征输入到ConvLSTM网络中,实现网络资源、效率和精度的平衡,提升网络模型的整体性能,为后续进一步提取全局时空特征做准备。
2.2.2基于ConvLSTM网络提取全局时空特征



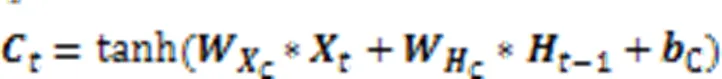
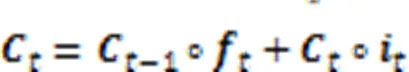
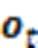
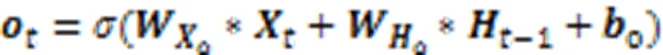
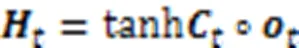
2.3 添加时间注意力机制
为了合理高效地利用视频关键信息,本文在ConvLSTM网络模型之后添加了时间注意力机制,根据视频帧的重要程度为每个时刻的长时时空特征分配权重,以更合理地利用视频重要时刻的长时时空信息计算视频级的特征表示。时间注意力机制模型如图5所示。首先根据ConvLSTM的输出计算得到时间注意力初始权重,然后对得到的初始权重进行归一化,接着对ConvLSTM的输出进行注意力加权,最后得到视频级特征表示。具体步骤如下:
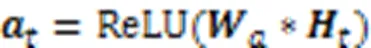
步骤2 归一化初始权重。利用Softmax函数对初始权重进行归一化,使得到的所有权重系数之和为1:




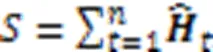

图5 时间注意力机制模型
2.4 输出检测结果
经过时间注意力模块处理后,得到包含更多关键信息的视频级特征表示,本文通过三层全连接层将其映射到分类空间,利用Softmax分类器进行分类,输出检测结果,实现视频中的暴力行为检测。本文方法的完整网络模型结构如图6所示。
根据输出检测结果与标签之间的误差计算模型损失值,通过迭代训练确保损失值最小化,在预测时,根据检测结果,计算模型准确率。本文所使用的损失函数为交叉熵损失函数,如式(16)所示:

模型准确率计算方法如式(17)所示:

其中:为正类数量,为负类数量,表示正类被正确预测为正类的数量,表示负类被正确预测为负类的数量。
3 实验与结果分析
为验证本文算法的可行性和有效性,构建了实验数据集进行对比实验和分析。实验所用计算机系统的硬件环境为Intel Xeon Silver 4110 CPU @2.10 GHz 处理器,32 GB内存,NVIDIA GeForce RTX 2080Ti显卡;软件环境为Windows 10,开发语言为Python,开发环境为Pycharm 2019。
3.1 数据集构建
为了验证本文算法的可行性和有效性,本文采用应用较多的HockeyFight、Movies和ViolentFlows三个公开视频数据集,并根据实际需要进行预处理后再进行实验。这三个数据集是从真实场景中提取的,具有权威性,尤其是数据集中人物动作丰富、背景多样,能够全面衡量本文算法性能。
HockeyFight数据集:取自北美曲棍球比赛,包含500段暴力视频和500段非暴力视频,视频分辨率为360×288,每段视频的帧率为25,平均时间长度为1.6 s,视频画质较高,背景较为单一。
Movies数据集:取自动作打斗电影片段,包含100段暴力视频和500段非暴力视频,大部分暴力视频分辨率为720×576,少部分为720×480,每段视频的帧率为25,平均时间长度为1.5 s。
ViolentFlows数据集:取自YouTube视频网站,包含123段暴力视频和123段非暴力视频,视频分辨率为320×240,平均时间长度为3.6 s,视频画质较低,背景较为丰富,场景中存在拥挤人群。
实验时先对以上三个数据集进行预处理,提取出数据集的视频帧,调整为256×256,并进行归一化处理;然后利用水平翻转和随机裁剪方法增强数据集;最后计算得到前景图,完成数据集的预处理,为网络模型的训练和测试做准备。
3.2 网络模型的训练和测试
在网络模型的训练和测试阶段,本文采用5折交叉验证的方法训练网络模型。将原始数据分为5组,依次取其中1个子集作为测试集,剩余4组为训练集。经过训练得到5个网络模型,最终计算出5个模型测试集准确率的均值作为整个网络模型的最终准确率结果。本文算法的训练和测试流程如图7所示。
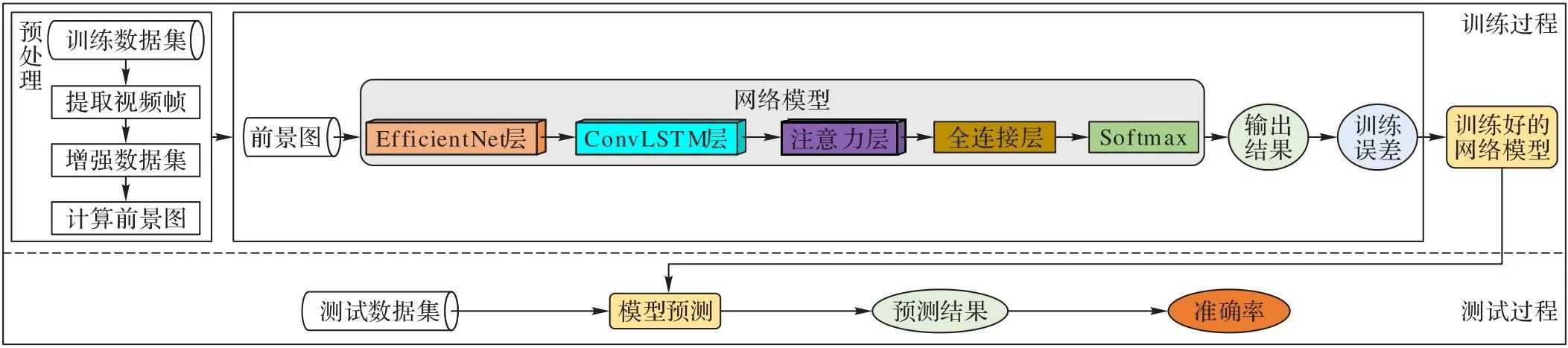
图7 本文算法的训练和测试流程
在训练过程中,首先预处理数据集,并生成视频的标签;然后将训练数据输入到提前在ImageNet数据库上预训练好的EfficientNet‑B0模型中,并采用Xavier算法初始化ConvLSTM模型权重,提高训练速度;接着输出分类结果,并根据交叉熵损失函数计算损失值;最后,采用Adam算法优化网络参数,学习率设为0.001,批量大小设为2,经过迭代训练,最终得到训练好的网络模型。
在测试过程中,将测试数据集输入到训练好的网络模型中,得到预测分类结果,并计算准确率,以此来衡量模型的性能。
3.3 本文算法可行性实验
为了验证本文算法的可行性,将本文算法在HockeyFight数据集和ViolentFlows数据集上训练50轮次,在Movies训练30轮次,并将EfficientNet‑B0空间暴力特征提取网络分别替换为ResNet50[17]、MobileNetV3‑small[25]、ShuffleNetV2[26]。经过训练之后,分别得到基于四种网络模型的算法在三个数据集上的训练损失和训练准确率,结果如图8所示。由图8可以看出,随着训练轮次的增加,各网络模型的损失值在不断下降,准确率在不断提升,最终达到收敛状态。EfficientNet‑B0模型在训练时相较于其他三个模型收敛更快,损失值较低,且准确率较高,这说明本文算法可行性比较好。
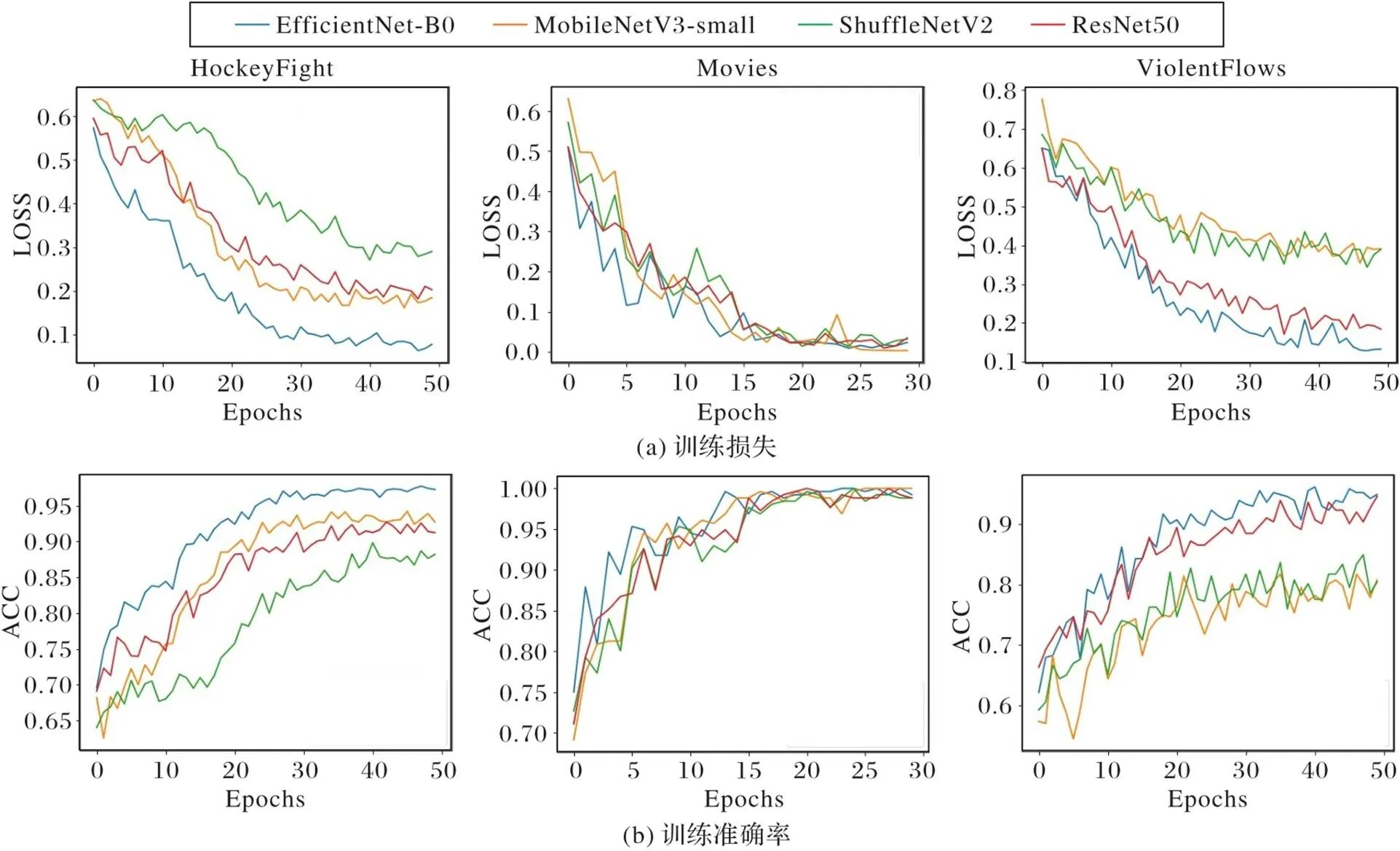
图8 训练损失与准确率对比
3.4 时间注意力机制对比实验
为验证引入时间注意力机制的有效性,设计了添加注意力机制前后的对比实验,基于四个网络模型的算法准确率对比结果如表1所示。其中:√表示在网络中添加注意力机制,×表示未添加注意力机制。由表1可以看出,在添加时间注意力机制后,本文算法在三个数据集上的准确率均有一定提升(达到100%准确率除外)。
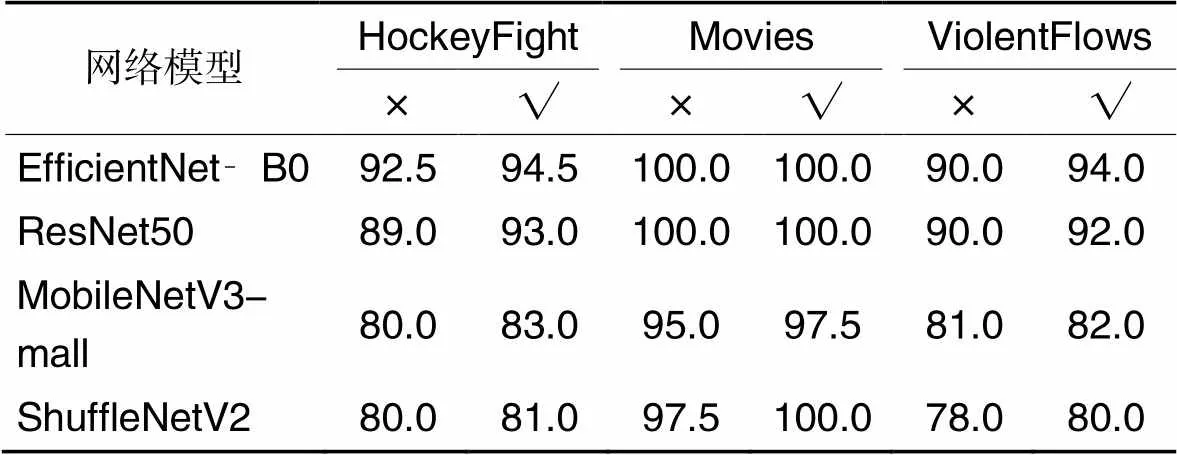
表1 添加注意力机制前后的准确率对比 单位: %
综合分析,本文算法及其他网络模型在添加时间注意力之后,在暴力行为检测任务上的准确率均有不同程度的提升,本文添加的时间注意力机制是有效的。
3.5 EfficientNet与其他模型对比实验
为验证EfficientNet‑B0模型的有效性,对四种网络模型的参数量以及相应算法的训练集训练时间、测试集预测时间和准确率进行对比,结果如表2所示。由表2可以看出,与ResNet50模型进行对比,EfficientNet‑B0模型的参数量仅为ResNet50的1/5。在计算复杂度方面,ResNet50的GFLOPs约为4.1,而EfficientNet‑B0的GFLOPs约为0.39,仅为ResNet50的1/10,计算复杂度更低。由于已经在ImageNet数据库上进行预训练,EfficientNet‑B0的训练时间比ResNet50要短,预测时间也更短。在准确率方面,在HockeyFight数据集上准确率提升1.5个百分点;在Movies数据集上都达到了最佳准确率,分析原因是该数据集数据量较小,且电影打斗片段相似度较高;在ViolentFlows数据集上准确率提升2个百分点。
与其他轻量化模型进行对比,可以看出在相同参数量级的情况下,在HockeyFight数据集上,EfficientNet‑B0模型准确率分别比MobileNetV3‑small、ShuffleNetV2高11.5和13.5个百分点;在Movies数据集上比MobileNetV3‑small高2.5个百分点;在ViolentFlows数据集上分别比MobileNetV3‑small和ShuffleNetV2高8、10个百分点。
综合分析,EfficientNet‑B0模型能够在参数量明显少于常规网络模型参数量的情况下,获得准确率的提升,且训练时间及预测时间更短;而在相同参数量级的情况下,准确率要高于其他轻量化网络模型。因此,本文使用的EfficientNet‑B0模型能够在参数量较小的情况下,保持较高的准确率和较短的训练、预测时间,实现资源、效率和精度的综合平衡。

表2 不同网络模型的参数量、预测时间和准确率对比
3.6 与其他现有算法对比实验
为了验证本文算法的有效性,将本文算法与其他现有的算法的准确率进行对比,对比结果如表3所示。由表3可以看出,在三个公开数据集上,与文献[9-12]等基于人工设计特征的暴力行为检测方法相比,本文算法准确率有明显的提升;与文献[13-15]等基于深度学习的暴力行为检测方法相比,本文算法准确率依然有不同程度的提升,但是不需要计算光流等特征,且卷积网络为轻量化模型,参数量更小,计算更简单快捷。因此,本文算法能够在有限的资源限制下获得较好的性能,不需要人工设计特征,实现端到端的训练和检测,并且在多个数据集上取得效果的提升,具有良好的泛化能力和鲁棒性。
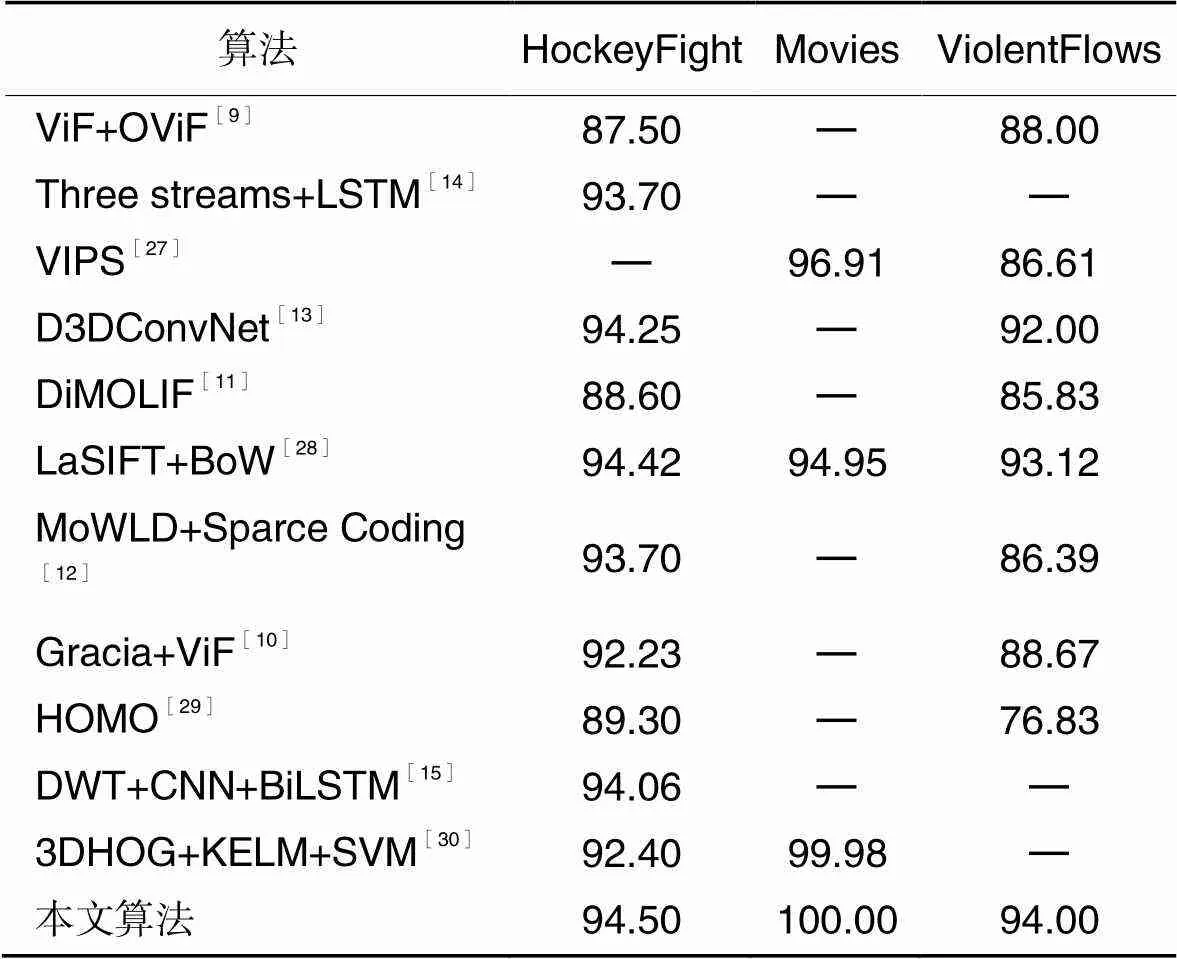
表3 不同算法的准确率对比 单位: %
4 结语
针对一般暴力行为检测方法模型参数量大、计算复杂度高、准确率较低等问题,本文提出了一种基于时间注意力机制和EfficientNet的视频暴力行为检测方法。首先,预处理数据集,提取视频帧并增强数据集,计算得到前景图;然后,利用复合缩放方法得到轻量化EfficientNet系列网络模型,选择EfficientNet‑B0提取前景图中的帧级空间暴力特征;其次,利用ConvLSTM网络的门控操作和卷积操作,进一步提取视频的全局时空特征,充分利用视频序列的时间信息和局部空间信息;接着,添加时间注意力机制,根据ConLSTM的输出计算注意力初始权重,将权重归一化后进行注意力加权,融合加权后的输出得到视频级特征表示;最后,利用三层全连接层将视频级特征表示映射到分类空间,利用Softmax分类器进行分类,输出检测结果。最终设计并实现了该视频暴力行为检测方法,并进行了对比实验。结果显示,本文所添加的时间注意力机制可以提高模型的准确率;EfficientNet相较于常规网络模型参数量大幅减少,预测时间更短,同时准确率得到提升,与其他轻量化模型相比,准确率远高于MobileNetV3‑small和ShuffleNetV2模型;与其他现有算法相比,本文算法计算更简单,在三个公开数据集上均取得了良好的性能,说明本文算法具有良好的泛化能力和鲁棒性。
下一阶段将进一步研究暴力行为识别方法,对各类暴力行为进行定义,识别出暴力行为的具体类别,并将该方法应用于智能安防、短视频审核等领域。
[1] SUDHAKARAN S, LANZ O. Learning to detect violent videos using convolutional long short-term memory[C]// Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway: IEEE, 2017: 1-6.
[2] 杨亚虎,王瑜,陈天华. 基于深度学习的远程视频监控异常图像检测[J]. 电讯技术, 2021,61(2): 203-210.(YANG Y H, WANG Y, CHEN T H. Detection of abnormal remote video surveillance image based on deep learning[J]. Telecommunication Engineering, 2021, 61(2): 203-210.)
[3] 卢修生,姚鸿勋. 视频中动作识别任务综述[J]. 智能计算机与应用, 2020, 10(3): 406-411.(LU X S, YAO H X. A survey of action recognition in videos[J]. Intelligent Computer and Applications, 2020, 10(3): 406-411.)
[4] 谭等泰,王炜,王轶群. 治安监控视频中暴力行为的识别与检测[J]. 中国人民公安大学学报(自然科学版), 2021, 27(2): 94-100.(TAN D T, WANG W, WANG Y Q. Recognition and detection of violence in public security surveillance video[J]. Journal of People’s Public Security University of China (Science and Technology), 2021, 27(2): 94-100.)
[5] SARMAN S, SERT M. Audio based violent scene classification using ensemble learning[C]// Proceedings of the 6th International Symposium on Digital Forensic and Security. Piscataway: IEEE, 2018: 1-5.
[6] 杨吕祥. 基于改进的CRNN的暴力音频事件检测方法研究[D]. 武汉:武汉理工大学, 2019.(YANG L X. Research on violent sound event detection based on improved CRNN[D]. Wuhan: Wuhan University of Technology, 2019.)
[7] ACAR E, HOPFGARTNER F, ALBAYRAK S. Violence detection in Hollywood movies by the fusion of visual and mid-level audio cues[C]// Proceedings of the 21st ACM International Conference on Multimedia. New York: ACM, 2013: 717-720.
[8] 谷学汇. 基于信息融合算法的暴力视频内容识别[J]. 济南大学学报(自然科学版), 2019, 33(3): 224-228.(GU X H. Information composite technology in violent video content recognition[J]. Journal of University of Jinan (Science and Technology), 2019, 33(3): 224-228.)
[9] GAO Y, LIU H, SUN X H, et al. Violence detection using oriented violent flows[J]. Image and Vision Computing, 2016, 48/49: 37-41.
[10] 宋凯. 面向视频监控的暴力行为检测技术研究[D]. 哈尔滨:哈尔滨工程大学, 2018.(SONG K. Research on detection technology of violence in the background of monitoring[D]. Harbin: Harbin Engineering University, 2018.)
[11] BEN MABROUK A, ZAGROUBA E. Spatio-temporal feature using optical flow based distribution for violence detection[J]. Pattern Recognition Letters, 2017, 92: 62-67.
[12] ZHANG T, JIA W J, YANG B Q, et al. MoWLD: a robust motion image descriptor for violence detection[J]. Multimedia Tools and Applications, 2017, 76(1): 1419-1438.
[13] 丁春辉. 基于深度学习的暴力检测及人脸识别方法研究[D]. 合肥:中国科学技术大学, 2017.(DING C H. Violence detection and face recognition based on deep learning method[D]. Hefei: University of Science and Technology of China, 2017.)
[14] DONG Z H, QIN J, WANG Y H. Multi-stream deep networks for person to person violence detection in videos[C]// Proceedings of the 2016 Chinese Conference on Pattern Recognition, CCIS 662. Singapore: Springer, 2016: 517-531.
[15] CHATTERJEE R, HALDER R. Discrete wavelet transform for CNN-BiLSTM-based violence detection[C]// Proceedings of the 2020 International Conference on Emerging Trends and Advances in Electrical Engineering and Renewable Energy, LNEE 708. Singapore: Springer, 2021: 41-52.
[16] SHI X J, CHEN Z R, WANG H, et al. Convolutional LSTM network: a machine learning approach for precipitation now casting[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2015: 802-810.
[17] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[18] HAN K, WANG Y H, TIAN Q, et al. GhostNet: more features from cheap operations[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1577-1586.
[19] 刘超军,段喜萍,谢宝文. 应用GhostNet卷积特征的ECO目标跟踪算法改进[J]. 激光技术, 2022, 46(2):239-247.(LIU C J, DUAN X P, XIE B W. Improvement of ECO target tracking algorithm based on GhostNet convolution feature[J]. Laser Technology, 2022, 46(2):239-247.)
[20] WEI B Y, SHEN X L, YUAN Y L. Remote sensing scene classification based on improved GhostNet[J]. Journal of Physics: Conference Series, 2020, 1621: No.012091.
[21] TAN M X, LE Q V. EfficientNet: rethinking model scaling for convolutional neural networks[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 6105-6114.
[22] 尹梓睿,张索非,张磊,等. 适于行人重识别的二分支EfficientNet网络设计[J]. 信号处理, 2020, 36(9): 1481-1488.(YIN Z R, ZHANG S F, ZHANG L, et al. Design of a two-branch EfficientNet for person re-identification[J]. Journal of Signal Processing, 2020, 36(9): 1481-1488.)
[23] 曹毅,刘晨,盛永健,等. 基于三维图卷积与注意力增强的行为识别模型[J]. 电子与信息学报, 2021, 43(7): 2071-2078.(CAO Y, LIU C, SHENG Y J, et al. Action recognition model based on 3D graph convolution and attention enhanced[J]. Journal of Electronics and Information Technology, 2021, 43(7): 2071-2078.)
[24] 梁智杰. 聋哑人手语识别关键技术研究[D]. 武汉:华中师范大学, 2019.(LIANG Z J. Research on key technologies of sign language recognition for deaf-mutes[D]. Wuhan: Central China Normal University, 2019.)
[25] HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1314-1324.
[26] MA N N, ZHANG X Y, ZHENG H T, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11218. Cham: Springer, 2018: 122-138.
[27] MOHAMMADI S, PERINA A, KIANI H, et al. Angry crowds: detecting violent events in videos[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9911. Cham: Springer, 2016: 3-18.
[28] SENST T, EISELEIN V, KUHN A, et al. Crowd violence detection using global motion-compensated Lagrangian features and scale sensitive video-level representation[J]. IEEE Transactions on Information Forensics and Security, 2017, 12(12): 2945-2956.
[29] MAHMOODI J, SALAJEGHE A. A classification method based on optical flow for violence detection[J]. Expert Systems with Applications, 2019, 127: 121-127.
[30] 于京. 特殊视频内容分析算法研究[D]. 北京:北京交通大学, 2020.(YU J. Study on content analysis algorithms in special video[D]. Beijing: Beijing Jiaotong University, 2020.)
Violence detection in video based on temporal attention mechanism and EfficientNet
CAI Xingquan, FENG Dingwei, WANG Tong, SUN Chen, SUN Haiyan*
(,,100144,)
Aiming at the problems of large model parameters, high computational complexity and low accuracy of traditional violence detection methods, a method of violence detection in video based on temporal attention mechanism and EfficientNet was proposed. Firstly, the foreground image obtained by preprocessing the dataset was input to the network model to extract the video features, meanwhile, the frame-level spatial features of violence were extracted by using the lightweight EfficientNet, and the global spatial-temporal features of the video sequence were further extracted by using the Convolutional Long Short-Term Memory (ConvLSTM) network. Then, combined with temporal attention mechanism, the video-level feature representations were obtained. Finally, the video-level feature representations were mapped to the classification space, and the Softmax classifier was used to classify the video violence and output the detection results, realizing the violence detection of video. Experimental results show that the proposed method can decrease the number of model parameters, reduce the computational complexity, increase the accuracy of violence detection and improve the comprehensive performance of the model with limited resources.
violence detection; temporal attention mechanism; Convolutional Long Short-Term Memory (ConvLSTM) network; EfficientNet model
This work is partially supported by Beijing Social Science Foundation (19YTC043).
CAI Xingquan, born in 1980, Ph. D., professor. His research interests include virtual reality, human-computer interaction, deep learning.
FENG Dingwei, born in 1997, M. S. candidate. His research interests include virtual reality, deep learning.
WANG Tong, born in 1996, M. S. candidate. His research interests include virtual reality, deep learning.
SUN Chen, born in 1996, M. S. His research interests include virtual reality, deep learning.
SUN Haiyan, born in 1980, Ph. D., lecturer. Her research interests include virtual reality, deep learning.
TP391.9
A
1001-9081(2022)11-3564-09
10.11772/j.issn.1001-9081.2021122153
2021⁃12⁃21;
2022⁃01⁃21;
2022⁃01⁃26。
北京市社会科学基金资助项目(19YTC043)。
蔡兴泉(1980—),男,山东济南人,教授,博士,CCF高级会员,主要研究方向:虚拟现实、人机互动、深度学习;封丁惟(1997—),男,山东青岛人,硕士研究生,主要研究方向:虚拟现实、深度学习;王通(1996—),男,山西大同人,硕士研究生,主要研究方向:虚拟现实、深度学习;孙辰(1996—),男,山东临沂人,硕士,主要研究方向:虚拟现实、深度学习;孙海燕(1980—),女,山东济宁人,讲师,博士,主要研究方向:虚拟现实、深度学习。
