医学人工智能的特点及在口腔正畸中的规范化开发
2022-11-28谢贤聚白玉兴
谢贤聚 白玉兴
100050, 首都医科大学附属北京口腔医院
近年来,人工智能技术(AI)已经逐步从科研阶段转向应用阶段,医疗领域是人工智能应用集中的场景之一。医学人工智能涉及医疗行业各个环节,借助于大数据、云计算、深度学习技术,在图像识别、智能诊疗、遗传学和基因组分析、药物研究等方面提供辅助。医疗AI的应用一定程度缓解我国医疗资源供需失衡、医疗质量分配不均、优质医疗条件需求大等问题,对于重复性高的影像和病理检查方面,大大节约人力资源及操作时间。医疗行为本身具有高度的复杂性、不确定性和风险性。医疗AI在为医疗机构带来效率的同时,也蕴藏着潜在风险。目前我国将医疗AI作为医疗器械进行监管,根据用途的不同分为非辅助决策和辅助决策软件。前者仅提供医疗参考信息,归为第二类医疗器械;后者提供医疗决策建议,按照第三类医疗器械管理,对二者均设置了较为严格的管控机制与程序。
1 AI的特点及其在医学领域应用的特殊性
医学领域为高风险决策领域,每个决策关乎患者健康。因而在医学AI的研发、应用中须重视与安全性相关的特点,积极采取措施控制、防范风险。
1.1 “黑箱”属性(black-box)
“黑箱”属性是指AI模型输入和输出是可见的,但从输入到输出的过程则缺乏透明度。即AI的计算过程是无法解释和理解[1]。这是由于AI是通过给定的数据,自行寻找规律,随着数据的累积和训练的增加,算法自动改进优化[2],其“黑箱”属性在很大程度上限制医疗AI临床推广应用。对医生来说,其决策过程难以与现有医学知识建立有效关联,无从知晓其逻辑,便无法判断该决策是否可靠;直接应用于病人中,可能承担很大的安全风险。对患者来说更无法信任及接纳。对开发者而言,算法逻辑无法审核和修正。破解“黑箱”难题具有重要意义,可解释性为模型决策结果以可理解的方式向人类呈现,增加算法可解释性成为目前重要研究方向。模型的可解释性有利于医生更好地理解AI的决策过程,确定是否信任其决策结果;有利于开发者优化和改进系统,避免歧视和偏见,并加强管理和监控。但目前对AI可解释性的研究尚处于起步阶段。可解释性研究可以分为两方面研究[3]:(1)直接构建本身具有可解释性的模型;(2)调整模型内部参数,判断内部参数对于结果的影响;通过对输入指标添加扰动,评估不同指标的重要性,与现有医学知识建立关联,推测AI作出决策的依据。在AI辅助正畸方案决策研究中,Xie等[4]纳入包含头影测量、模型分析、主诉在内的23 个输入指标判断是否拔牙。计算各输入指标对输出的贡献,结果显示在AI逻辑下,开唇露齿和 IMPA指标对于是否拔牙的贡献值最大,这与临床决策考量有相通之处。另外通过对做出贡献的指标进行可视化,判断其是否符合医学知识,可达到可解释的目的。在正畸图像分类模型中,虽然无法直接解释模型如何验算出结果,但可通过类激活热力图(图1)来进行直观的判断。算法观察的位置与人类思维下观察的位置基本相同,从另一角度解释了算法。Kim等[5]直接通过头颅侧位片进行矢状骨面型分类,类激活热力图显示分类成功的图像,感兴趣区域(ROI)集中于上下齿槽座点与上下唇区域;而分类失败的图像,ROI是模糊或集中在不相关区域。
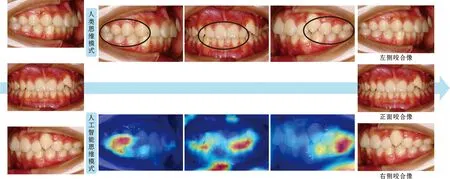
图 1 正畸图像分类模型类激活热力图
短期内可能很难从技术上彻底破解“黑箱”难题,但在开发、应用中,保证算法透明和可追溯,一定程度降低了风险。算法透明是指开发者应披露包括源代码、输入数据和输出结果等在内的算法要素。算法可追溯是指医疗AI的决策过程应当被完整记录,以留待未来核查。二者为算法可解释提供了可能,并形成有效监管。
1.2 易受干扰性
AI技术本身具有易受干扰性,输入变化或数据分布变化都可能产生无法控制或预测的风险。在图像处理领域,对图像的像素进行人眼不可察觉的改变,就可能导致AI模型出现误判[6]。面对复杂的临床情况,AI模型鲁棒性尤为重要,即指模型能够尽可能不受输入数据扰动或者统计分布影响,同时抵御恶意攻击继续正常运行的能力。当模型的输入产生微小的变化时, 不会导致模型的输出产生巨大变化,保证了模型在预测时的稳定性。
在AI开发过程中,须重视模型的鲁棒性优化,提升模型抗干扰能力。对数据人为添加噪声、变化,模拟实际应用中的可能发生的情况。在自动头影测量定点任务中,对训练集头颅侧位片进行缩放、旋转、色调明度改变,随机添加噪声操作,模拟不同拍摄仪器及不同参数对头颅侧位片的影响[7]。在实际应用中,医生须在适用范围内合理运用AI产品,避免应用于分布不同数据而带来的风险。
1.3 医学应用特点
随着医学AI产品投入临床应用,对现有医学模式产生了一定的冲击,其背后存在伦理问题亟待解决,医疗AI的责任风险问题更加不能忽视。
1.3.1 诊疗模式转变 AI可以直接根据患者病史、病历、医学影像等信息分析患者的病情并为患者提供诊断和治疗建议,“医生-机器-患者”的诊疗模式无形中使医生与患者直接沟通的时间减少。医生在与患者面对面的交流沟通中可以进一步获得信息与反馈,全面掌握患者的情况。而AI难以获取个体生活习惯、环境、心理因素,有可能会产生误诊或误判。临床治疗中的医生情绪感知、言语抚慰、倾听眼神等,都会影响治疗的效果。在临床诊疗中,须明确AI为辅助技术手段,医生需要通过医患的沟通,从生物、心理、社会各个水平采取诊疗与人文关怀[8]。
1.3.2 医疗责任 患者个体差异性、医疗行为复杂性以及AI的黑箱属性,造成AI辅助医疗决策存在风险。当AI结果与医生的主观判断结果不一致,出现医疗事故时的责任如何划分?
开发者和使用者需详细记录从而实现责任可追溯。开发者须对AI程序正确负责,研发过程须是客观、公正、基于无偏倚临床数据进行构建。开发者须提供完整的原始数据,证明自己的开发、生产过程不存在纰漏。使用者则须对结果正确负责,医疗AI的最终结果需要人工校验审核,其结论和建议需要临床医生结合特定情境做综合分析。医生须明确医师主体地位,发挥专业自主性,严格把关,对此决策的风险进行理性并专业的判断和控制。另外,在制度层面应尽快建立AI医学应用的伦理管理规范和法律问责机制,进一步明确责任机制、划分医疗事故责任承担方式,保障患者健康权益。
2 医学AI数据采集特点
AI为数据所驱动,数据的品质直接决定医疗AI算法的精准性。一旦数据采集出现偏差,算法模型和结果可能出现偏误。医疗数据相较于其他数据更为敏感更为隐私,对医疗数据的挖掘收集、利用和共享应更加谨慎周全。
2.1 数据集的选择和标准化
数据集如若不能反映复杂的临床环境会影响AI的准确性和适应性。数据集影响模型性能的因素包括:数据集的数量、质量、多样性。由于收集数据的难度及伦理限制,很多自动头影测量研究[9-10]基于2014、2015 年公开牙科X线图像分析挑战数据集,训练集仅由150 张头侧片构成。这些数据集很难全面反映标志点的影像特征。AI自动点识别的准确度随训练数据量增加而增加[11]。除了数据量的要求,数据分布也需结合疾病的流行病学特征。
采集多地域、多级别的临床机构,不同参数设备的数据集,可明显提高数据代表性和多样性。目前,医疗机构缺乏有效数据共享流通机制,各研究采用各自独立数据库。Kim等[12]与Tanikawa等[13]研究中AI头侧片点识别模型应用于与训练数据不同设备的头颅侧位片时,性能明显下降,数据壁垒造成的单中心数据集训练限制AI的推广应用。最近研究[14]使用来自15 个不同中心的4 215 例患者的CBCT数据集进行牙齿及牙槽骨自动分割。这种大规模、多中心的数据集涵盖不同图像质量及口内情况的CBCT,明显提升AI模型的分割精度和临床适用性。建立多中心、规范化口腔AI数据库,需要临床专家积极推动,将不同区域、不同医疗机构的具有代表性、结构化、高质量的数据用于AI研究。
医疗AI需要对数据进行人工标注,标注将直接影响训练数据的质量。即使数据本身真实且有代表性,但若数据标注环节出现偏差,导致系统性的偏倚。须在标注规范、标注流程、人员责任管理以及质量审核等方面制定规范化操作规则[15]。
2.2 信息安全风险
医疗数据在AI研发中发挥价值的同时,不能忽视其背后的风险。医疗数据包括患者基本信息,健康疾病状况,治疗情况甚至基因信息,不仅涉及患者隐私,还具有特殊的敏感性和价值。数据收集、分析处理、云端储存和信息共享加大了数据泄露的风险。AI医学开发中要实现数据开放与隐私风险之间的平衡。在充分保护个人信息安全的前提下,能发挥数据的潜在价值,实现数据使用效益最大化。
数据隐私安全包括采集、储存、挖掘、利用、运营、传输多个环节。必须制定周详的准则,最大程度保护患者隐私。通过患者提供、自动采集、间接获取方式采集数据须征得患者的知情同意。数据采集后进行脱敏、匿名化处理,并加密储存。研究中及研究后数据保存应由专人负责,规范不同等级人员数据访问及使用权限。
3 医学AI规范化开发流程
随着医疗AI技术的不断进步,其适用医疗应用场景将会越来越多,基于以上安全风险相关特点,更需要有一个标准来严格管理AI科研到产品开发全流程。规范化开发有助于推动医疗AI持续健康发展。AI应用开发流程可分为开发态流程和运行态流程,其中开发态流程分为数据准备、算法选择和开发,模型训练,模型评估和调优子流程;运行态流程可分为应用生成、评估和发布子流程,应用维护子流程。在AI软件开发过程中,数据准备工作占用时间最多,影响开发效率,且需要医师和开发人员共同参与,因此建立完善的数据集是AI开发基础(图 2)。
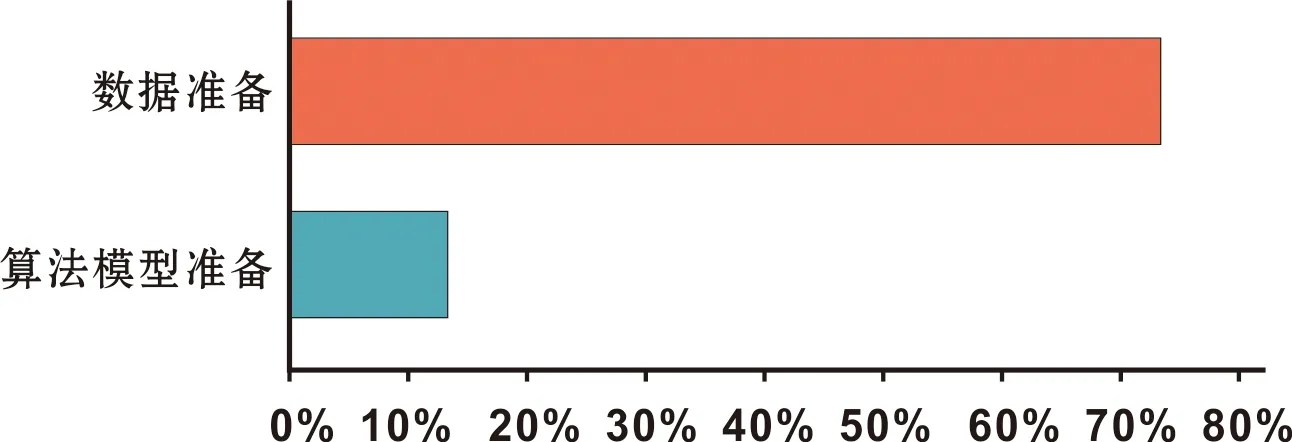
图 2 AI软件开发工作量
下面以数字化模型数据为例,介绍数据准备子流程,可分为4 个阶段。
3.1 数据采集
首先进行伦理审批、确保数据收集的来源和目的的合法、正当以及充分尊重患者的知情同意。需确定数据集的数据规模、来源、入排标准、分布构成情况[8],按标准纳入数据。
3.2 数据接入
通过统一的命名规则对文件命名,使数据文件可自动归档,接入平台并入库核查。数据采集、接入、存储全流程局域网内闭环,保护患者资料安全。数据局域网云存储,实现院内信息共享。
3.3 数据处理
包括数据校验、数据转换、数据清洗、数据脱敏、数据切分。首先数据校验对数据可用性进行判断和验证,去除异常数据,避免对模型训练产生干扰。检测模型扫描质量,对扫描质量不佳,文件损坏,无法解码,数据重复等问题的文件进行剔除或重新扫描。数据转换则是对数据大小、格式、特征进行变换,使其适合于选择的算法类型和模型训练的数据形式,将扫描得到的.dcm格式文件通过格式转换器转换为.stl文件。数据清洗对数字化模型数据进行去噪、纠错或补全,避免其对模型训练产生干扰。当数据集形成后,对数据进行脱敏。去除关键敏感信息,保护患者隐私。对数据集中的数据,要先按照数据使用的目的切分为训练集,验证集和测试集。其中60%作为训练集用于模型训练,20%作为验证集用于模型和应用的选择和评估,剩余20%作为测试集用于推理测试。
3.4 数据标注
须明确标注流程、确定标注目标、制定标注规范、人员培训及考核以及质量审核规范。模型标记点识别任务中,标志点位置需要以医师的判断作为参考标准,而医师对标志点定义理解、标记经验和操作流程都可能导致系统偏差。因此必须对参与人员进行专业培训并通过一致性考核。标注人员构成初级标注员、审核人员、仲裁人员。由多名初级标注员进行交叉标注,计算点对点误差,在可接受误差范围内者取平均作为标志点的标准坐标,如若误差大产生争议,由审核人员、仲裁人员进行评判。
4 总 结
AI技术是把“双刃剑”,需要审慎应对其风险,本文更多着眼于与安全性相关的特点及正畸领域中医生参与的AI规范化开发数据准备流程。医疗AI的持续健康发展需要各方共同努力,从国家层面加强法律法规、标准规范制定,建立审查体系实现有效监管;技术开发方面,破解“黑箱”技术难题,公平、合理开发;临床应用中,医生需明确AI为辅助临床诊疗的工具,以医师为主体地位,加强医患沟通。
