基于局部运动约束的改进PWStableNet电子稳像网络
2022-11-24徐鑫伟兰太吉薛旭成吴梦飞
徐鑫伟,兰太吉,薛旭成,吴梦飞
(1.中国科学院长春光学精密机械与物理研究所,吉林 长春 130033;2.中国科学院大学,北京 100049)
0 引言
视频稳定是业余和专业视频拍摄的共同需求。在业余方面,特定的视频稳定设备通常是十分昂贵的,而随着以手机为主的手持式摄像机的普及,业余用户每天拍摄出来的视频占比越来越大,不具有稳定器的摄像设备在拍摄过程中经常会受到高频抖动的干扰,导致拍摄的视频带有比较明显的抖动,视觉质量大幅降低。将带有抖动的视频重新稳定下来是一项非常有意义的研究[1]。
电子稳像技术以仅需要计算、无需额外设备就能达到稳像效果的优势成为了当今主流的稳像方法。一些传统电子稳像方法[2-3]需要提取特征轨迹或使用光流法估计摄像机的运动,然后对其进行平滑以实现稳定,最后根据固定网格计算出一个全局单应矩阵或几个同形矩阵以将晃动的帧重新翘曲成稳定的帧。由于相机运动而产生的视差和深度的变化,使得这些传统方法难以产生稳定的视频。此外,这些方法通常依赖特征点的提取,鲁棒性较差,并在处理低质量视频(如夜景视频、模糊视频、有水印的视频和带有噪声的视频)时可能会稳像失败。
近年来,卷积神经网络(Convolutional Neural Networks,CNN)在计算机视觉任务上取得了巨大的成功,比如图像识别[4]、目标检测[5]和分割[6]。特别是一些传统的视频处理问题已经可以用深度神经网络重新解决,如图像去噪去模糊[7]、图像效果增强[8]等。通过创建一个实际的数据集在构建好的神经网络上面进行训练,CNN也可以实现视频稳定的效果。
Wang等[9]设计了一种用于多网格翘曲变换学习的网络,该网络能够获得与传统方法相当的性能,并且对低质量的视频更具鲁棒性。Xu等[10]设计了一种对抗性网络,用来估计一个仿射矩阵,通过仿射矩阵可以生成稳定的帧。然而,这些方法在固定网格的基础上估计一个或一组仿射矩阵,对于不同深度变化的场景不够灵活和准确。与传统的稳定方法相比,基于CNN的稳定方法具有更强的鲁棒性,因为它能够很好地提取高维抽象特征,而不是依赖于特征点提取和匹配,特征点提取和匹配的准确性很大程度上取决于视频的质量。在基于仿射变换或基于网格变换方面,它们与传统的方法非常相似,在强视差、深度变化以及有遮挡的情况下,这些方法是非常脆弱的,很容易把视频帧像素翘曲到错误的位置。
Zhao等[11]提出了一种新的名为PWStableNet的CNN来消除各种不稳定视频的抖动,其学习的对象是为每个不稳定帧像素提供理想位置的像素翘曲场,通过像素翘曲场,可以将抖动视频帧中的每个像素转换到稳定位置。与传统方法的每帧估计一个单应性变换或基于固定网格估计几个单应的变换方法相比,像素翘曲场为每个像素提供翘曲方向。每帧计算2个像素翘曲场分别代表像素横向翘曲方向和纵向翘曲方向,可以为稳定视图中的每个像素提供理想的单独位置,一旦某个位置发生了计算错误,对整体的影响很小,所以对退化模糊的图像具有很强的鲁棒性并且可以很好地处理视差,也可以处理不同对象之间的不连续深度变化。该网络能够有效处理各种低质量、高深度的抖动视频,是当前鲁棒性最好的深度学习稳像方法,同时对比其他的深度学习方法在运算速度上有所提升。
PWStableNet在处理有噪声、有模糊、带水印和大深度等低质量抖动视频有鲁棒性和通用性很强的优点,但该网络也存在缺乏有效局部运动抑制,易产生过度翘曲,造成局部失真的问题。本文针对此处进行改进创新,在训练过程中以损失函数的形式对生成的像素翘曲矩阵在空间上添加频域损失计算来抑制高频成分的出现,并利用MeshFlow网格流模型[12]对局部区域运动剧烈程度进行评估,添加局部运动损失阻止过度运动。实验测试结果表明,改进后的PWStableNet能够有效抑制局部失真并且在峰值信噪比(Peak Signal to Noise Ratio,PSNR)、帧间结构相似度(Structural Similarity Index,SSIM)和稳定度(Stability)等客观指标上有所提升。
1 PWStableNet的基本结构
PWStableNet的基本结构如图1所示,网络结构的输入是给定的一组共2w+1张连续、不稳定的视频帧,主体部分是一个多级级联的编码解码卷积网络用来估计帧间运动的抖动,网络输出一个像素级的翘曲场,该翘曲场由2个翘曲矩阵组成,指示了稳定帧每个像素应该由哪个不稳定帧像素移动而来。通过这些翘曲场,可以将抖动帧中的像素转换到新的位置组成稳定帧。与以往基于固定网格估计单应矩阵或少量同形矩阵的方法相比,PWStableNet提出的像素级翘曲场可以为稳定视图中的每个像素提供合适的单独位置,并能很好地处理不同物体之间的视差甚至不连续的深度变化。
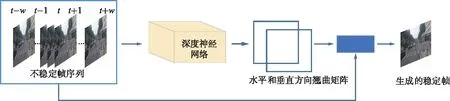
图1 PWStableNet的基本结构
1.1 系统输入
神经网络输入需要足够量的信息,要想将一帧图像稳定下来需要用到相邻视频帧的信息,因此网络以待稳定帧前后w帧作为输入。如图1所示,待稳定帧为第T帧,网络输入是t-w~t+w帧,共2w+1帧。输入帧图像半径w的大小决定信息量的大小,会对稳定效果和处理速度产生一定的影响。
1.2 像素翘曲场
像素翘曲场是与图片像素宽、高相同,通道数为2的一组矩阵,用来映射稳定帧和不稳定帧之间的关系。像素翘曲场的映射关系如图2所示。
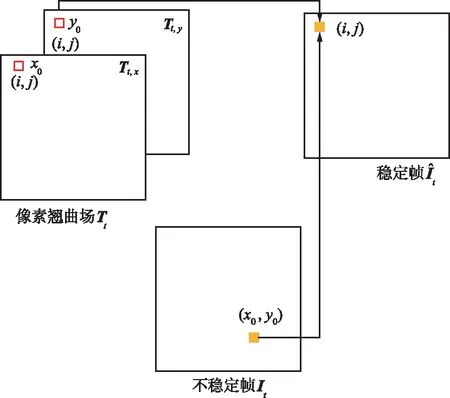
图2 像素翘曲场的映射关系
1.3 神经网络主体结构
神经网络主体结构如图3所示,可以看到有三级级联的网络结构,每级结构相似,主要是编码器-解码器框架,类似于U-Net[13]的结构。以单一级结构来看,其编码器由若干个抽象层组成,这些抽象层能够提取大大小小的特征信息,在较深的层上有较多的通道。它的解码器由与编码器对应的信道编号相同、大小相同的反卷积层组成,并通过跳跃连接与对应的反卷积层相连接。以级间结构来看,每级结构都与相邻的级自上而下保持连接,意义在于当前级的各层能够学习其前一级的剩余特征,在更细节位置得到更精确的估计。每级结构都输出一个翘曲场Tn(n表示级序数),这些学习了更多图像细节的翘曲场相叠加得到该帧最终输出的翘曲场T。
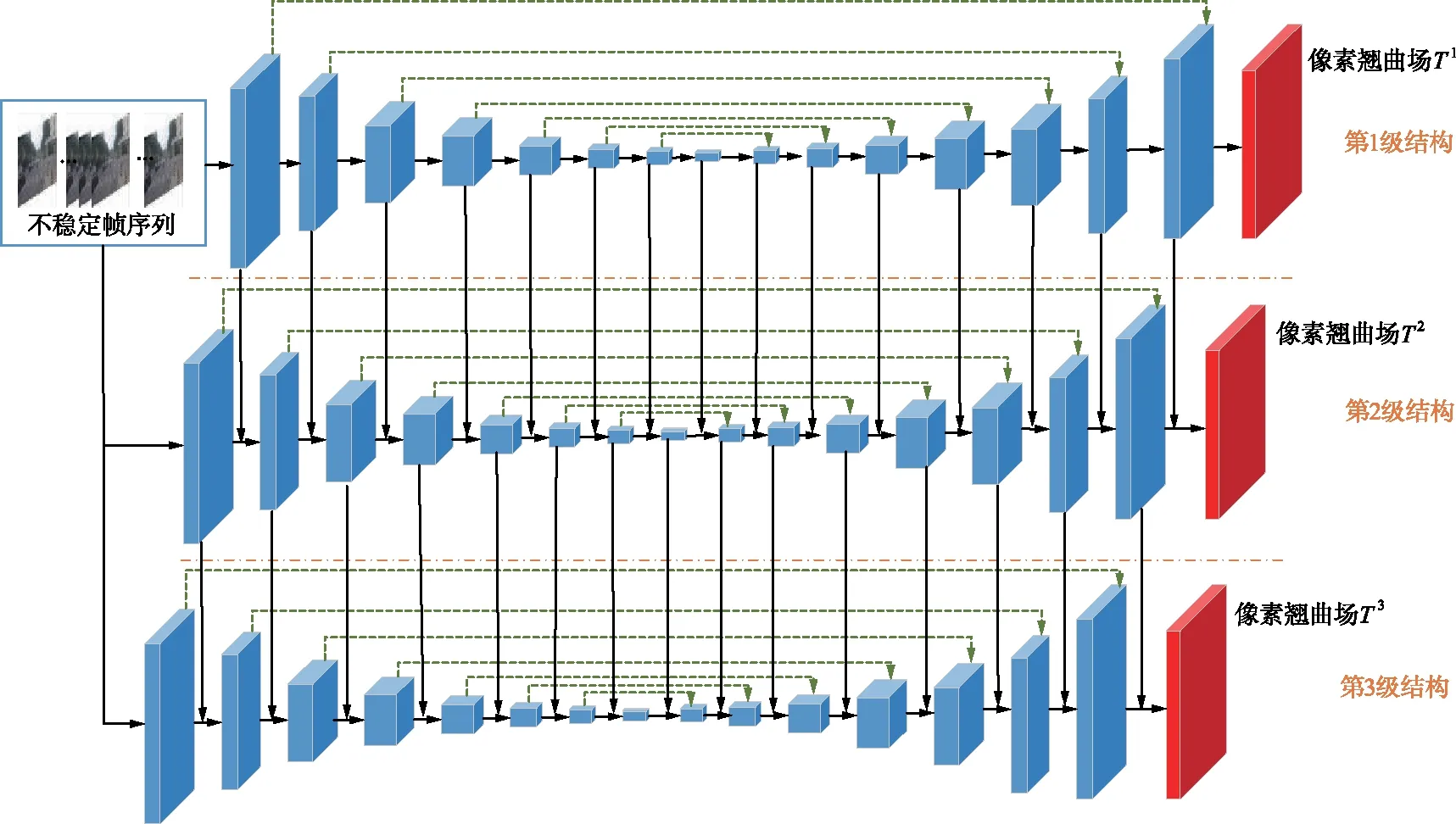
图3 神经网络主体结构
2 改进与创新
在性能测试时发现,原生的PWStableNet网络模型生成的视频整体上稳定,但是偶尔在局部会产生不稳定区域,出现不正常的扭曲失真,经过分析并查阅文献后发现了导致该问题的一部分原因。像素级翘曲矩阵为每个像素安排位置,拥有极高的自由度,但是原网络对像素自由运动只做了简单的帧间均方差进行约束,缺乏更加直接有效的约束来防止过量运动。其后果就是输出的翘曲场很容易发生个别像素点的误匹配,把像素移动到过远或过近的位置,增加了输出图像的噪声,一定区域内误匹配数量过多则会局部图像失真,降低生成的稳定图像的质量。
2.1 对翘曲场增加频域约束
在查阅相关文献后,受到基于光流的视频稳定神经网络[14]的启发,在网络训练过程中采用对生成的翘曲矩阵加强空间平滑度的方式,来抑制局部失真和减少噪声。加强空间平滑度的方法常见的有总变分约束和Yu等[15]提出的线性翘曲场约束。然而,这2种方法存在着一定的局限性,总变分约束对局部噪声的抑制作用较强,而对畸变的抑制作用较弱;线性翘曲场约束难以控制,因为强约束限制了像素级翘曲场处理大规模非线性运动的灵活性,而弱约束不能很好地抑制局部形变[14]。因此,加强翘曲场空间平滑度的方法应该满足以下3个条件:一是能保证像素级翘曲矩阵的处理抖动视频帧的灵活性;二是能抑制输出图像的局部形变;三是能减弱输出图像的整体和局部噪声。在频域利用傅里叶谱约束的方法能够同时满足以上条件,适合作为加强翘曲场空间平滑度的方法。
具体实现方法是在训练过程中对翘曲场中的每个翘曲场进行傅里叶变换得到其频谱,再对频谱进行加权运算得到新的频谱,新频谱的L2范数就作为此帧翘曲场频域损失函数的值,计算公式为:
(1)
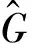
(2)
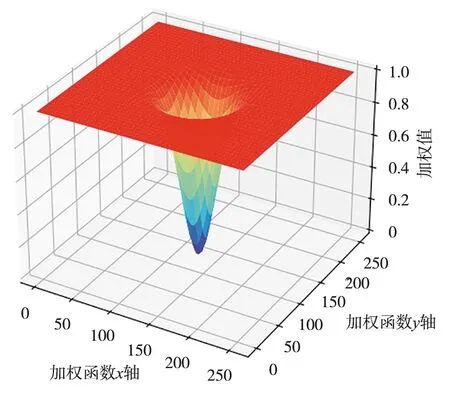
图4 倒置高斯加权函
2.2 对稳定帧增加局部运动约束
频域约束是通过对翘曲矩阵进行整体性约束来抑制局部失真的发生,属于间接方法,图像的局部失真程度可以采用更为直接的方式进行评估。Liu提出的MeshFlow模型[12]和SteadyFlow模型[16]都能很好地检测局部区域内的帧间移动。MeshFlow模型基于KLT稀疏光流特征匹配[17],SteadyFlow模型基于稠密光流,二者效果上相似,但是MeshFlow计算复杂度远低于SteadyFlow。为了提升计算效率加快运行速度,本文采用MeshFlow模型来计算局部区域的帧间运动,评估局部区域不稳定程度。
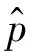
(a)相邻图像的一对特征点
所有匹配的特征都会将它们的运动传播到附近的网格顶点,每个网格顶点会接收多个来自不同特征点的运动矢量。因此需要筛选出其中一个来代表此顶点运动矢量。中值滤波器经常用于光流估计,并被视为高质量流估计的诀窍[18]。这里借用了该研究的稀疏运动规则化的类似思想,采用中值滤波筛选出代表顶点区域的运动矢量。所有带有运动矢量的网格顶点组成了一个稀疏运动场,表示了帧间的运动情况。
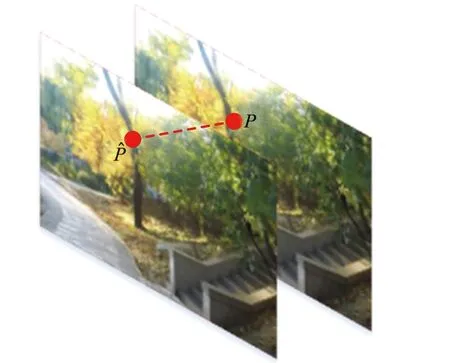
网格运动矢量分解如图6所示,每个网格顶点运动矢量一般可以分解为2个部分:一个是表示整个帧全局运动的全局矢量;另一个是表示局部细节自由运动的局部自由矢量。
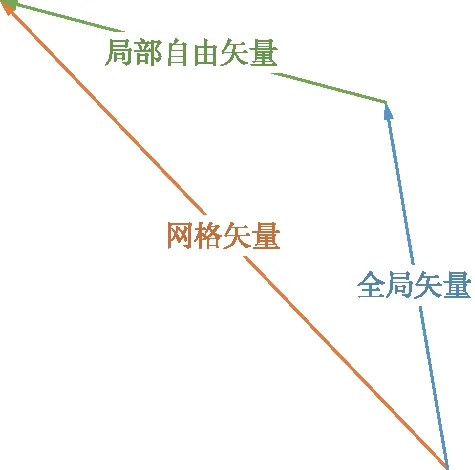
图6 网格运动矢量分解
目的是计算出局部区域的不稳定程度,全局矢量与局部区域不稳定度无关,应该采用代表局部自由运动的局部自由矢量来衡量局部运动剧烈程度。局部自由矢量可以由网格矢量与全局矢量相减得到,因此需要计算出全局矢量。前面提到MeshFlow模型的特征点由KLT光流特征匹配[17]生成,可以借鉴传统方法利用这些特征点计算出全局仿射变换,把网格顶点坐标带入到仿射变换模型中得到新网格顶点的位置:
(3)
式中,[X′,Y′]表示仿射变换后的网格顶点坐标;[X,Y]表示仿射变换前网格顶点的坐标;m11,m12,m21,m22,b1,b2均为全局仿射变换的参数。全局矢量则定义为:
(4)
在训练过程中根据网络输出的翘曲场T生成一个稳定帧,这个稳定帧与上一个稳定帧组成相邻帧,构建出MeshFlow网格模型并计算所有网格顶点的局部自由矢量。用这些局部自由矢量组成的稀疏运动场的L2范数来衡量此帧局部区域运动的剧烈程度,一个视频所有帧局部损失相加作为该视频的损失函数:
(5)
式中,t表示帧序数;Lt,m为该帧的局部运动损失;N表示一帧网格顶点数量;n表示网格顶点序数;Mt,n,g表示第n个根据特征点直接求出的网格顶点矢量;Mt,d为根据仿射变换求出的全局矢量。
3 结果分析
在公开数据集DeepStab[9]上进行训练,该数据集共有61对稳定、不稳定视频数据,数据集中的稳定视频称为真稳定视频,以45对视频作为训练集,8对视频作为验证集,8对视频作为测试集。网络模型学习率采用阶梯式下降的方法,初始状态学习率为0.01,之后每经过10轮,学习率下降10倍。本文所有实验数据结果均在同一硬件平台上运行,CPU型号为Intel i9-12900k,GPU型号为Nvidia RTX-3090,在此平台上进行测试输出视频的平均帧率为79帧/秒,能够达到拍摄视频实时处理的需求。
3.1 主观效果
本文的改进之处在于引入了更多的约束来改善PWStableNet易发生局部失真的缺点,卷积网络结构未发生改变,处理低质量视频的优秀能力得以保留,同样具有很强的鲁棒性。
用肉眼难以直接察觉到稳定后视频微小的局部运动,但是可以通过帧间差分图像来实现局部运动可视化。网络改进前、网络改进后和真稳定视频的帧间差分图如图7所示,白色区域表示了相邻帧之间发生了运动的物体的基本轮廓,白色区域的密集程度能够反映帧间运动的剧烈程度。由图7可以看出,改进后白色区域的密集程度接近于真稳定视频,明显低于改进前,说明改进后的局部运动受到了抑制,减少了局部失真发生的可能性,主观效果优于改进前。本文改进后在局部区域运动上更符合稳定视频的要求。

(a)改进前帧间差分
3.2 客观评价
一般电子稳像方法输出的帧边界会有一部分无信息区域,处理这些区域的方法通常是直接裁剪,为了方便比较,把所有方法输出的视频都裁剪到一个公共区域。为了评估,改进了网络的有效性,除了损失函数组成不同,网络结构以及其他超参数均保持一致。本文改进后的稳像网络除了与改进前网络进行对比,还与原不稳定视频和基于光流特征匹配的传统方法[2]进行对比,共4组对照数据。测试对象为数据集DeepStab[9]上的8个不稳定视频,根据视频内容的特征分为“常规”“运动”“低照度”和“视差”4种类型,对应摄像机在日常使用过程中经常遇到的情况。为了定量比较提出的网络和以前的方法,计算了3个客观指标:PSNR,SSIM和稳定度,下面简要地说明这3个指标。
① PSNR:能够反映稳定后视频图像结构信息的完整程度,其值越高,表示受到噪声影响越小,稳定后图像质量越高,失真程度越小[19]。
② SSIM:能够衡量相邻两帧之间图像相似程度,一般认为稳定的视频相邻帧之间结构是相似的,帧间结构相似度越高说明视频越稳定。
③ 稳定度:用于衡量视频的稳定程度,一般认为稳定的视频内的运动缓慢的低频成分占比较大,稳定度计算了视频内的低频成分所占的比例。计算方法采用与文献[10]相同的方法,将每个帧分割成4×4个网格,记录每个网格顶点经过所有帧的历史路径,并将每个顶点路径视为一维时域信号进行频域分析。每个顶点的稳定度计算为最低频率分量(除去直流分量,第2~6低的频率)在全频率的占比。该视频的稳定度的值为计算所有网格顶点稳定度的平均值。
客观指标对比结果如图8所示,第1,2号视频对应“常规”类型;第3,4号视频对应“运动”类型;第5,6号视频对应“低照度”类型;第7,8号视频对应“视差”类型,相同类型的视频指标数据相近。从PSNR指标上进行分析,改进后的网络与改进前性能持平,二者均高于传统方法;从SSIM指标上进行分析,本文方法性能略高于传统方法与改进前网络;从稳定度上进行分析,不同类型的视频上呈现出不同的结果。在“常规”类型的视频中,本文方法性能略高于传统方法和改进前网络;在“运动”类型的视频中,3种方法性能接近;在“低照度”和“视差”类型中,传统方法数据指标高于2种基于神经网络的方法,其原因就在于传统方法处理这2种类型的视频时稳像失败,生成了含有大量空白区域的帧,空白区域网格顶点的运动矢量为零导致了稳定度异常提高。总体上看,本文改进后网络的客观评价指标更好。

(a)测试视频编号及类型
本文方法是基于PWStableNet改进而来,与改进前网络相对比进行针对性的分析是评判改进有效性的重要内容。数据内容为有效稳像占比,如表1所示,用于衡量稳像方法的有效程度,以不稳定视频指标到真稳定视频指标之差为尺度1,以不稳定视频指标到稳像方法指标为有效稳像,即:
(6)
式中,R为有效稳像占比;Ho为稳像方法的指标;Hu为不稳定视频的指标;Hs为真稳定视频的指标。
表1对比了网络改进前后输出的结果在不同视频的3个指标上的具体数据。由表1中数据可以看出,提升的指标(加粗的数值)占多数约71%,以平均值来看,3种指标均有不同程度的提升,总的提升均值为7.73%。这些客观评价指标说明了在引入2个新约束后的PWStableNet网络在综合性能上优于改进前。
表1 改进前后有效稳像对比
4 结束语
本文对现有的视频稳像网络PWStableNet进行改进,解决改进前网络易发生局部失真的问题。对卷积网络引入了2个新的约束:像素翘曲场的频域约束和局部自由运动矢量的约束,来减少稳定视频在局部区域的多余运动,抑制局部失真,生成更稳定的视频。这2种约束的优点在于以直接和间接2种方式进行评估,更加细致、全面地计算出局部自由运动大小。经过实验对比验证,本文改进后的网络生成的视频在帧间差分具有更好的效果,同时在PSNR,SSIM和稳定度等客观性能指标上较其他算法更优。随后的研究重点内容将集中在优化网络结构、提升计算效率上,以获得更好的运算速度和稳像效果。
