融合空间相关性和局部特征转换器的遮挡行人重识别
2022-11-23朱松豪赵云斌
朱松豪,赵云斌,焦 淼
(1.南京邮电大学自动化学院、人工智能学院,江苏南京 210023 2.山东鲁能泰山电缆有限公司特变电工,山东 新泰 271219)
行人重识别旨在连接不同摄像头中的目标行人,广泛应用于安全、监控等领域[1]。近年来,人们已经提出了大量解决重识别问题的方法[2-6]。这些方法大多利用卷积神经网络实现人体特征的提取,在公开的实验数据集上都取得了很好的识别效果。具体而言,基于局部分块的行人重识别方法,通过引入图片切块、注意力机制[7]、多分支结构[8]等行人的局部特征,用以提高行人重识别准确率;基于细粒度信息的行人重识别方法,通过引入姿态估计、关键点模型提取行人的细粒度特征,从而提升行人重识别性能;利用对抗生成式网络生成行人图片,从而补全图片、丰富训练样本,提高模型训练效果。然而,现实生活中经常会遇到诸如物体遮挡、行人图像不完整、背景杂乱等情形。在这类情形下,大多数行人重识别方法则很难获得令人满意的识别精度。
由于卷积神经网络感受野服从高斯分布[9],因此,感受野被限制在一个小区域内。由于行人遮挡、背景信息或其他噪声的大量存在,使得较小的感受野容易接收错误的特征信息;同时,下采样操作会降低特征表征的分辨率,从而导致较小感受野识别遮挡行人的精度下降[10-11]。 因此,即使采用特征对齐方法[12]或引入注意机制[13-16],也很难完全解决遮挡行人重识别问题的挑战。
文献[17]已经证明视觉转换器模型(Vision Transformer,ViT)可用于图像分类,其效果不亚于传统的卷积神经网络方法。ViT以多头自注意机制为核心,摒弃了卷积和下采样操作[18]。具体来说,ViT首先将原始图像切割成一系列的图像块;然后,将这些图像块序列输入到网络中,并对这些图像块序列做分类编码和位置编码嵌入;最后,对这些图像块序列做自注意力操作。近年来,ViT被引入至行人重识别领域,凭借其捕捉全局特征的能力和更好的自注意机制,它超越了卷积神经网络方法,取得了很好的效果。
由于ViT对长序列具有良好的长距离相关性,因此在行人重识别方面取得了良好的效果。但是,当人物被大面积遮挡或背景与人物特征相似时,网络也容易出现误判,这是因为ViT不善捕捉目标的局部特征,因而导致其鲁棒性较差[19]。因此,本文在ViT的基础上提出了拥有3个模块的局部特征视觉转换器模型,用以改善图像块序列的短距离相关性并提取未被遮挡部分的局部特征。从图1所示的热力图可以知道,相较于原始的视觉转换器模型,本文所提的基于空间相关性和局部特征视觉转换器模型更为关注局部特征,且具有更大的感受范围。

图1 基于不同视觉转换器模型的注意力热力图
首先,本文提出了一个图像块序列融合重建模块。该融合重建模块首先将非目标行人的噪声图像块或背景图像块等非主体图像块与行人主体图像块进行融合,用以减少噪声或遮挡信息对整个图像块的影响;然后,重构整个图像块序列。这样,重构后的图像块序列的感受野就可以获得更多的局部特征,因为融合操作有助于扩大目标行人特征在全局特征中的比例。
其次,为了提高网络模型在图像分类领域的泛化性和鲁棒性,本文提出了图像块序列的空间切割模块,在视觉转换器的最后一层对图像块序列切片分组。作为具有图像块序列空间相关性的全局分支,该模块可以拉长细类之间的距离,提高图像块序列的空间相关性,进而提高图像块序列的短程相关性,使得网络模型更为关注局部特征,进一步提升网络模型的泛化能力。
最后,很多学者都关注到图像块序列在网络模型中的流动,但却忽略了图像块序列本身的可增强性。因此,本文在图像块序列生成阶段引入全维度增强编码。该编码是一个可学习的张量,可以减少图像中的噪声,提取更多被遮挡行人的可辨别特征。因此,全维度增强编码的引入有助于降低输入图像中的噪声和可辨别特征提取的难度。
本文的主要创新点概括如下:
(1)设计了图像块序列的图像块全维度增强模块,在合理范围内增加细类间的距离,丰富训练样本的多样性,弱化噪声信息,突出图像中的可辨别特征。
(2)提出了图像块序列的融合与重构模块,以扩大细类之间特征表示的差异,提高图像块序列中目标行人可辨别特征的比例,提高目标重识别的精度。
(3)空间切割模块旨在从空间方向提取图像块序列的可区分特征。此外,该模块将输入图像的空间相关性整合到图像块序列中,用以改善图像块序列的短程相关性,从而使得网络模型对于重识别目标的局部特征信息更为敏感,有助于提取被遮挡人的综合局部特征,进而提高网络模型在不同遮挡情况下的泛化性能。
1 相关工作
大多数关于行人重识别的研究主要依赖于行人的完整形象,较少考虑被遮挡的情况。然而,在现实生活中,尤其是在拥挤的场景中,完整的行人图像很难获得,因此,遮挡情况下的行人重识别是一个不容忽视的情况。
现有的用于遮挡行人重识别的深度学习方法主要基于卷积神经网络。这类方法的主要设计思想是特征对齐或引入高阶语义信息(姿态引导信息),然后通过关键点估计模型,对人体关键点进行估计,最后利用姿态识别被遮挡人。文献[20]提出层联合学习和嵌入局部特征的姿态引导信息,并直接预测相似性得分,该方法的主要特点是通过鲁棒的图形软匹配实现特征对齐。文献[21]提出了一种姿态引导的部分匹配方法,该方法使用姿态引导的注意机制实现特征表征,并在端到端的框架中引入自挖掘部件的可见性。虽然姿态引导信息的引入使得模型具有更高的识别率,但引入的关键点估计模型使得整个网络模型略显臃肿,降低了网络模型的运行速度。
视觉转换器模型是自然语言处理领域一种常用的模型[22-23],文献[24]提出了多头主动注意机制,完全抛弃了循环神经网络、卷积神经网络等网络结构,仅将主动注意用于机器翻译任务,取得了良好的效果。谷歌将转换器模型引入图像分类领域,并提出了视觉转换器模型,将图像分割成图像块序列并输入转换器编码器,最大限度地保留了转换器的原始结构,取得了很好的效果。视觉转换器模块需要大量数据集进行预训练,以获得类似于卷积神经网络的训练结果。因此,文献[25]提出了Deit框架,并利用师生策略对问题进行优化。最近,文献[26]提出了TransReId模型,并将ViT应用于行人重识别领域;同时,该文献还提出利用JPM模块对网络最后一层特征进行分类,然后分别计算它们的损失,进一步增强 TransReId模型的鲁棒性。然而,TransReId模型仍侧重表征全局特征,而局部遮挡特征和短程相关性的问题尚未得到很好的解决。
2 所提方法
为提高局部特征的自动调整能力和增强短程相关性,本文在图像块编码阶段设计了一个图像块全维嵌入模块优化图像块编码操作。同时,本文还提出了图像块融合与重构模块和空间切割模块来融合局部特征,提取空间方向上特征图的局部特征,增强了特征学习的鲁棒性。
2.1 图像块全维度增强
本文提出一种可学习的全维度编码用以增强图像块序列的表征能力,如图2所示。给定的输入图片x∈RH×W×C, 其中 H、W 和C分别表示输入图像的高度、宽度和通道尺寸。实验中图像大小为256×128,且在嵌入操作之后,将图像划分为大小相同的N个图像块。此时,输入从batchsize×H×W×C更改为batchsize×N×D,即,将三维图片转换为二维的序列,只是序列内容是图像块特征信息。

图2 本文所提空间相关性和局部特征转换器框架
由于输入图像的分辨率较低,且存在卷积运算平移不变性的因素,因此图像原始语义关键信息出现偏移,从而影响原始输入图像的通道信息。因此,本文构造了一个与卷积运算后的图像块序列大小相同的可学习图像块增强编码GLPDE=N×D,其中的N表示图像块的数量,D为面上每个图像块片的维数。本文还设置了一个初始化学习参数β,用以实现可学习编码GLPDE针对不同分类问题进行微调。输入图像块序列fin,H和W表示输入图像的高度和宽度,P表示每个图像块的边长,S表示步长。利用式(1)将图像分割为N个图像块。

如图2所示,输入图像经过扁平图像块的线性投影后得到图像块序列 fin,其中,f1、f2、…、fN分别表示第1个图像块张量到第N个图像块张量;接着,图像块全维度增强模块构造出一个与图像块序列fin大小、尺寸完全相同的可学习编码GLPDE;然后,计算GLPDE和图像块序列fin的哈达玛乘积(张量中的每个对应元素相乘),实现LPDE编码全维度地嵌入图像块序列fin,从而得到如式(2)所示的输出图像块序列fout。
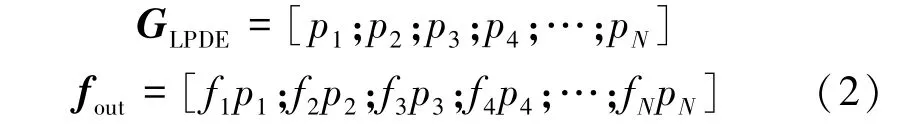
这里,构建的可学习编码GLPDE为张量形式,初始值设为1,且通过哈达玛乘积运算嵌入到输入图像块序列中。这样,可在训练过程增强输入图像块序列在图像块维度方向上的特征表征能力。利用Imagenet大型分类数据集获得的预训练模型权重,可以加快本文提出的SCLFT网络的收敛速度,而此时自学习编码LPDE的收敛速度远低于SCLFT网络的收敛速度,所以,在网络性能接近最优时,嵌入到图像块序列的LPDE编码可利用其自学习能力优化自身参数,进而进一步优化网络整体性能。因此,图像块全维度增强模块不仅不会对网络产生负影响,反而能在一定范围内提升网络性能。由于图像块全维度增强模块位于Transformer编码器之前,因此,该模块可优化图像块序列fout。所以,在输入图像的分辨率较低的情况下,该模块可在训练过程中随机引入额外的特征信息,达到丰富训练样本多样性的目的。可学习张量LPDE的自学习能力可在训练过程中提高网络的收敛精度,优化输入图像的特征表示,加强被遮挡目标的上下文线索,淡化遮挡信息。
2.2 图像块序列融合与重构
视觉转换器模型可以很好地利用全局特征提高目标识别的性能,但对遮挡行人重识别而言,关键特征信息的提取通常更多地依赖局部特征。由于在遮挡重识别任务中存在大量的背景、遮挡、环境或其他干扰信息,因此,具有更多遮挡特征信息的图像块被认为是图像块序列中更重要的图像块。
图像块序列融合与重构模块在如图3所示的Transformer编码器之后接入网络,此时经过多头自注意力编码的图像块序列建立了全局特征联系。通过构建全局相关性和自注意力,从而使网络拥有对行人目标的分类能力。但是,通过计算图像块序列的余弦相似度可以发现,与被遮挡人相关的信息主要集中在序列的中间位置,这是因为开头部分和最后一部分的图像块与全局图像块间的相似度很低。即使偶尔出现高相似度的频率也很低,这表明这两部分图像块特征与全局可辨别特征的相关性不高,即这两部分包含的特征信息均为非可辨别特征,因此,图像块序列自身的特征鲁棒性仍可提升。为验证及解决这个问题,本文在视觉转换器模型的最后一层添加图像块序列融合与重构模块。具体操作过程如图4所示。

图3 图像块序列融合与重构示例

图4 Transformer编码器结构示意图
(1) 分割。 首先,对图像块序列为Zin= [c;z1;z2;z3;z4;…;zN] 进行切割,得到分类编码 class;然后,得到图像块序列 F = [z1;z2;z3;z4;…;zN]。
(2)分组。将N组图像块序列依次划分为4组长度相同的子图像块序列F1、F2、F3、F4

(3)融合。经过研究发现虽然图像块序列中头部和尾部的图像块具有较低的相关性和依赖性,但不想完全丢弃这些特征信息,因为头部和尾部的图像块有时也会包含一些辅助辨别特征(如头部,帽子,雨伞等),因此通过融合头部和尾部图像块的特征,并对其进行替换以期获取更好的表征,从而得到新的头部和尾部图像块FNew1与FNew4:
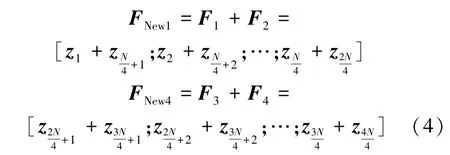
(4)重构。 在获得 FNew1和 FNew4的基础上,将FNew1、F2、F3、FNew4四个图像块序列与分类编码按照原始顺序拼接成原始大小的图像块序列
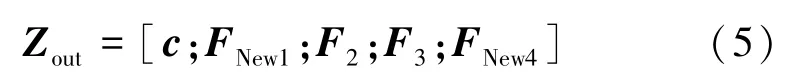
经过以上一系列操作后,图像块序列保留了F2和F3的主体可辨别特征,同时并未简单地直接去除与主体可辨别特征相关性较小的图像块序列F1和F4,而是利用(F1,F2)和(F3,F4)构建新的图像块序列FNew1和FNew4。 FNew1与FNew4在降低原始F1和F4所占比例的基础上,分别融合了F2和F3的特征信息,从而构建了更加鲁棒的特征表征,并有效提高了这4部分图像块序列的特征相关性。因此,相较于原始图像块序列,最终拼接生成的图像块序列Zout包含更为丰富完整的可辨别特征信息,占比更小的干扰特征信息,更为适合用以解决遮挡行人重识别问题。
2.3 空间切割模块
视觉变换器模型主要是从线性角度关注全局特征,构建图像块序列从而获得图像块之间的全局相关性。从图像处理的角度来看,一张输入图像也可以理解为二维图像块序列的组合,因此,图像块序列除了上下文线索相关外也具有空间方向上的相关性。也就是说,不仅是连续的图像块间有着很强的空间相关性,即使是前后相隔很远的图像块也可能包含很强的空间相关性。因此,本文尝试探索图像块序列的空间相关性,以弥补图像块序列的短程相关性,确保模型感受野更加关注局部特征。
受文献[26]的启发,本文沿用其在视觉转换器模块最后一层派生分支的结构,并引入如图5所示的本文设计的空间切割模块,以提取图像块序列的空间相关特征。利用图像块序列融合与重构模块得到融合了全局特征和局部特征的图像块序列Zout,并将其作为空间切割模块的输入。由于图像块序列是通过对输入图像进行切割并线性投影至二维空间得到的,因此,图像块序列中的每一部分仍保留原始三维图像块的空间关系。如图5所示,从空间方向上切割图像块序列,并拼接重组得到包含局部特征的3组图像块序列;接下来,通过融合整个图像块序列,得到包含全局特征信息的融合特征,这里的融合操作可最大范围扩大相似行人间的细类距离;然后,计算3组局部图像块序列的特征损失,锁定遮挡行人可辨别特征,同时计算融合特征的损失,用以区分相似行人的可辨别特征,最后对这两类损失加权得到更加准确的结果。

图5 空间切割模块结构示意
模块的具体操作如下:首先,通过分割操作将包含图像特征的图像块序列与分类编码分离开,然后利用式(3)将图像块序列分为长度相等的4组。
(1)空间切割。将得到的4组图像块序列从空间方向切片两次至相同长度,这样,总共生成12组不同的局部图像块序列τg;然后,分别给12组图像块序列编上对应数字,如式(6)所示。

(2)空间分组。按照以下原则针对获得的12组图像块序列进行分组:编号为1、4、7、10的图像块拼接成左侧图像块序列,编号为2、5、8、11的图像块拼接成中间图像块序列,编号为3、6、9、12的图像块拼接成右侧图像块序列空间分组。
(3)融合。将最初的4组图像块序列的特征融合,得到新的图像块序列:融合特征。融合后的融合特征具有全局特征信息;同时,融合特征拉大了不同目标间的距离。
(4)拼接。将初始分割出的类别编码与左、中、右和融合特征分别拼接,融合特征拥有全局和局部特征(Global and Local Features,GLF)

最后,该模输出了4个新的图像块序列,即左、中、右和GGLF
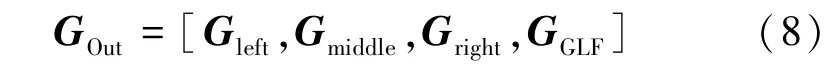
3 实验
针对提出的基于局部特征视觉转换器模型的遮挡行人重识别方法进行综合实验,以测试其在遮挡行人重识别问题中增强图像块序列的短程相关性和长程相关性的有效性。
3.1 实验数据
本文在5个公开数据集上评估了所提方法的性能,分别是文献[10]中提到的 Occluded⁃ReID,文献[12]中提到的 Occluded⁃Duke,文献[27]中提到的Market⁃1501,文献[28]中提到的 DukeMTMC⁃ReID,文献[11]中提到的 Partial⁃ReID 和文献[29]中提到的 Partial⁃iLIDS。
Occluded⁃ReID:该数据集来自 200个行人,其中每个行人拍摄5张全身图像以及5张各种遮挡情况的图像。
Occluded⁃Duke:该数据集是迄今为止最大的遮挡行人重识别数据集,包含15 618个训练图像、17 661个验证图像以及2 210个查询图像。
Market⁃1501:该数据集共有来自1 501个行人的32 668张图像组,其中包含来自751个行人的12 936张图像的训练集,以及来自包含750个行人的19 732张图像的测试集。
DukeMTMC⁃ReID:该数据集共有来自1 812个行人的36 411张图像,其中随机选取702行人的16 522张图像作为训练集,以及2 228张验证图像和17 661张测试图像。
Partial⁃ReID:该数据集是第一个行人重识别的数据集,共有来自60个行人的900张图像,其中每个行人拍摄5张全身图像、5张局部图像和5张遮挡图像。
Partial⁃iLIDS:该数据集是一个基于iLIDS的模拟的部分人员的重识别数据集。它总共有476张119人的照片。
3.2 实验设置
主干网络。本文使用视觉转换器模型作为基础主干网络:首先,将输入图像切割为图像块序列;然后,通过附加类标记和位置嵌入进行图像分类;最后,加入本文设计的模块,形成新的视觉转换器模型结构,本文称之为局部特征转换器模型。
训练细节。通过pytorch 1.8.1实现本文的框架网络;将输入图像统一调整为256×128,且利用随机水平、翻转、填充、随机剪切和随机擦除等方法对输入图像进行增强[30];批处理大小设置为48;使用SGD优化器,动量为0.9,1e-4的权重衰减,学习率初始化为0.008,以余弦优化进行学习率衰减;训练显卡使用的是英伟达1080Ti。
评价指标。使用累积匹配特征(CMC)曲线和平均精度(mAP),评估不同行人重识别模型的性能。所有实验均为单一查询设置下进行。
3.3 实验结果
Occluded⁃Duke数据集性能验证:表 1给出了Occluded Duke数据集的实验结果。
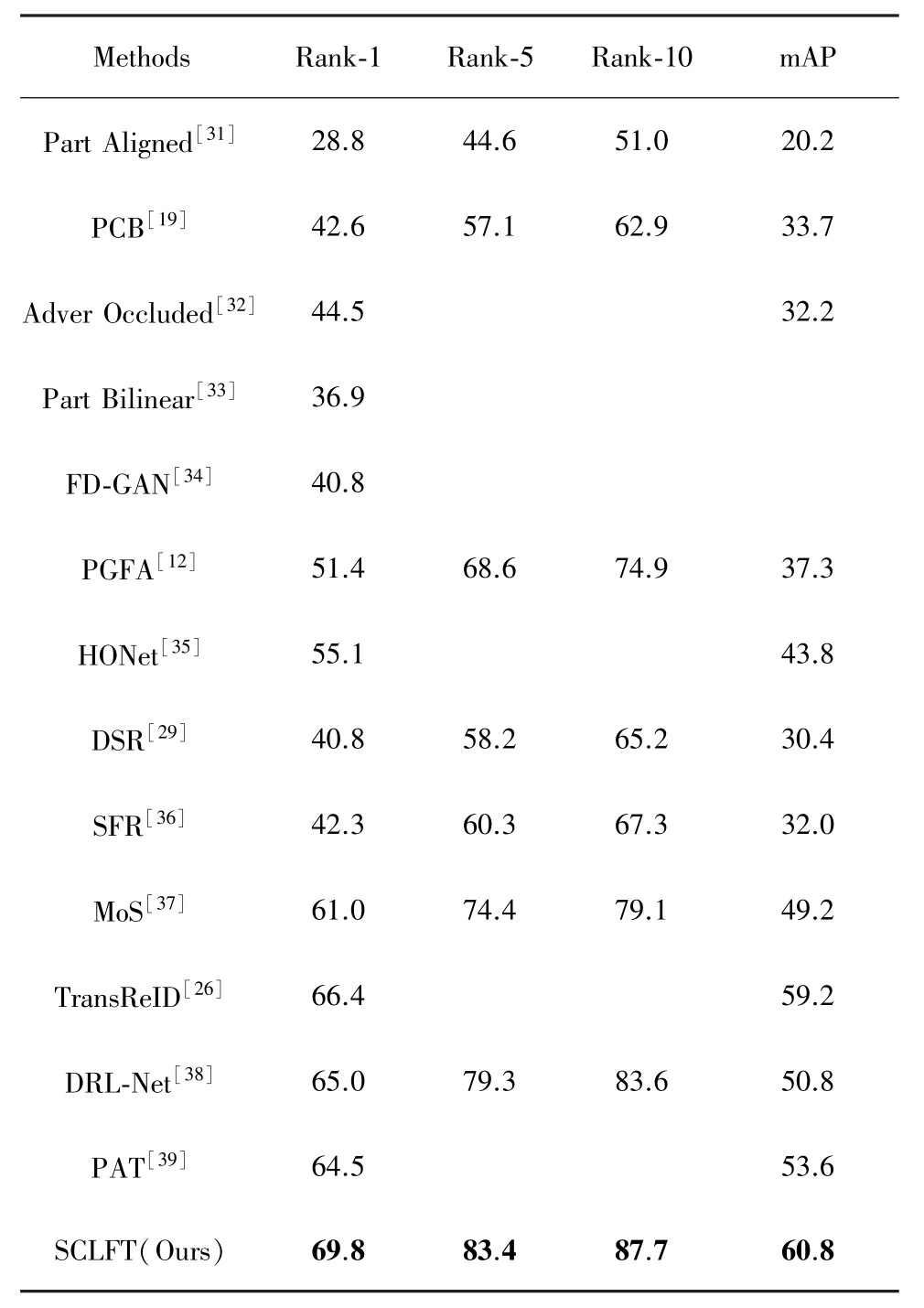
表1 Occluded⁃Duke数据集上的性能验证 %
本文比较了4种主流的行人重识别方法。它们是纯整体重 识 别 方 法 (PCB[19]、 Part Aligned[31]、Adver occluded[32])、使用外部或者高阶语义信息的遮挡 重识别方法 (PGFA[12]、Part Bilinear[33]、 FD⁃GAN[34]、HONet[35])、特征部分匹配方法(DSR[29]、SFR[36]、MoS[37])以及基于视觉转换器模型的方法。可以看出,基于视觉转换器的长序列行人重识别本质上是基于全局特征相关性,而图像块序列的局部特征相关性在视觉转换器网络中没有得到很好的利用。所以,本文通过提高长序列中短序列的相关性,从而使本文提出的局部特征转换器模型能够更加关注局部特征,最后获得了69.8%的rank⁃1和60.8%的mAP,这在Occluded⁃Duke数据集上的现有先进方法中表现最好。
Occluded⁃REID 和 Partial-REID 数据集性能验证:由于Occluded⁃REID数据集中被遮挡的行人图像远远少于Occluded⁃Duke数据集,因此,很多研究人员首先使用market1501数据集进行模型的预训练,然后在Occluded⁃ReID数据集上进行性能测试,从而达到更加收敛的效果。但是,本文选择直接针对 Occluded⁃Duke数据集进行训练,同时使用Market1501数据集作为Partial⁃REID数据集的预训练集,这是因为Occluded⁃REID数据集更偏向遮挡类型。所以,使用遮挡数据集进行训练,更容易达到更好的效果,如表2所示的实验结果也验证了这一假设。

表2 Occluded⁃REID与Partial-REID数据集的性能验证 %
Partial⁃REID 数据集与 Occluded⁃REID 数据集的区别在于前者更为侧重部分人体的识别(比如胳膊、上半身、左半身等),很少包含遮挡信息、背景信息或者噪声信息。Occluded⁃REID数据集与Occluded⁃Duke数据集类似,其图片包含更多的被遮挡对象以及其他噪声信息。从表2可以看出,局部特征视觉转换器模型SCLFT更适合解决遮挡重识别问题,其mAP远高于整体识别法(PCB)和外部信息法(HOREID)。 此外,SCLFT的 rank⁃1也达到了目前的最高,比最高方法 HOREID高出了2.7%。SCLFT在Partial⁃REID数据集上也表现出了良好的性能,充分发挥出视觉转换器模型的优势,整体识别精度高,因此大大提高了mAP。
整体数据集的结果:视觉转换器展示了其在行人重识别领域的强大性能。因此,本文希望提出的局部特征转换器不仅能对遮挡目标有很好的性能,而且能在整体数据集中也表现出很强的泛化能力和鲁棒性,实验结果如表3所示。
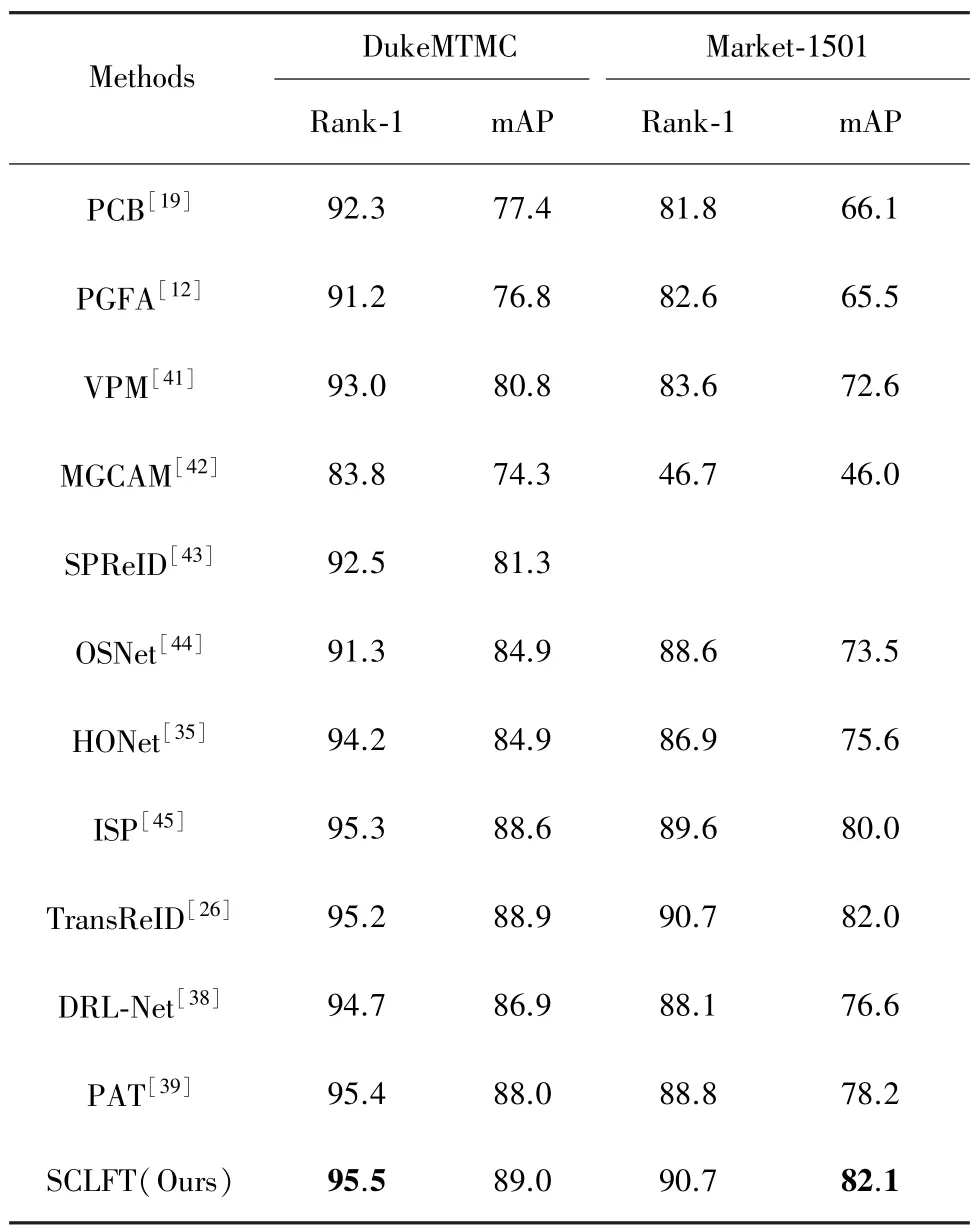
表3 Market⁃1501和DukeMTMC数据集上的性能验证 %
根据主干网络的不同,将其分为两类:卷积神经网络模型 (PCB、PGFA、VPM、MGCAN、SPReID、OSNet、HOReID、ISP)和视觉转换器模型(TransReID、DRL Net)。 从表3可以看出,基于视觉转换器模型的方法更易在整体行人重识别数据集上取得良好效果。本文提出的用于遮挡行人重识别人的局部特征转换器,在面对传统的整体行人重识别问题时也很有效:Market⁃1501 数据集上的 Rank⁃1和mAP得分,分别比传统卷积神经网络方法HONet提高1.3%和4.1%;与专注于整体行人重识别的TransReID方法相比,性能接近。以上结论表明本文提出的局部特征转换器模型,可以处理各类行人重识别问题。
Partial⁃iLIDS 数据集实验结果:Partial⁃iLIDS 基于iLIDS数据集,包含由多个非重叠摄像头拍摄的119人共238张图片,并手动裁剪其遮挡区域。由于Partial⁃iLIDS数据集太小,包含的图片太少,选择其他主流数据集作为训练数据集。这里选择Occluded⁃Duke数据集作训练集,实验结果如表4所示。在Partial⁃iLIDS数据集上,本文模型SCLFT达到了75.2%的Rank⁃1精度,这一结果接近目前最先进的方法。Baseline仅仅使用ViT作为网络结构,也达到了不错的性能,接近HOReID方法。SCLFT在ViT的基础上性能有了显著提高,可以看出,SCLFT针对遮挡问题的性能明显优于传统卷积神经网络和ViT网络。
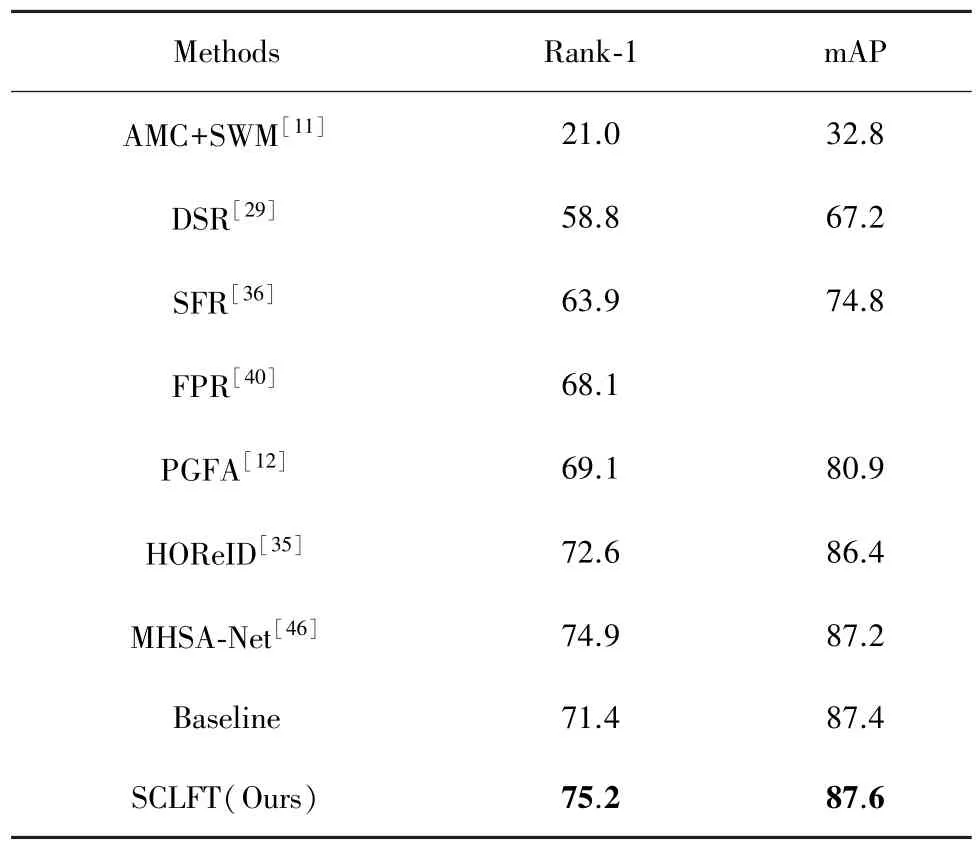
表4 Partial⁃iLIDS数据集的实验对比 %
经过thop库的代码计算分析可知,本文所提的融合空间相关性和局部特征转换器的遮挡行人重识别网络模型的参数量为92.7×106,浮点数计算量为22.93×109。
3.4 消融学习
本节将研究所提出的局部特征转换器中每个模块的有效性,以视觉转换器为基础,进行了图像块全维度增强模块、图像块融合重构模块和空间切割模块的消融实验。如表5所示的Occluded⁃Duke数据集消融实验结果,验证了各模块在遮挡行人重识别的有效性。

表5 Occluded⁃Duke数据集消融实验结果 %
图像块全维度增强模块的有效性:首先,本文在视觉转换器的基础上仅添加图像块全维度增强模块。通过这种方式,该模块可以最大限度地优化视觉转换网络中图像块序列的构建并提取可辨别特征。此外,通过深层次嵌入可学习张量,可以丰富训练样本的多样性,提高数据样本的区分度,合理范围内拉大不同类别间的距离,防止陷入局部最优。如表5的索引2所示,与视觉转换器网络相比,当仅使用全维增强模块时,Rank⁃1得分提高了2.2%。这表明图像块全维度增强模块,确实在具有复杂特征信息的遮挡问题中发挥了作用。
为了验证图像块全维度增强模块的泛化能力,本文比较了B+F+S和B+F+S+P。这两种网络在视觉转换器的基础上加入其他两个模块,网络中数据的流通更加复杂。对比表5中的索引4和索引6,可以发现在索引4的实验基础上,加入图像块全维度增强模块后,索引6的Rank⁃1得分显著提高了2.5%,换言之,该模块对图像块序列的增强效果是实际存在的。在复杂视觉转换器和原始视觉转换器等不同情况下,图像块全维度增强模块都可提高遮挡行人重识别效率,而不会对网络产生负面影响,具有良好的泛化性能。
图像块融合与重构模块的有效性:图像块融合与重构模块侧重于对图像块序列的重建,因此它可以方便添加至视觉转换器网络中。通过索引2和索引3的比较可知,在添加图像块的融合与重构模块后,Rank⁃1和mAP分别提高了3%和2%。通过索引5和6的比较可知,在添加空间切割模块后,图像块融合与重构模块的加入仍然显示了其在解决遮挡信息方面的有效性,且将Rank⁃1和mAP又分别提高了2%和1.6%。
通过以上两组消融实验结果可以知道,图像块融合与重构模块能够有效处理遮挡行人重识别中出现的噪声信息和遮挡信息。在弱化遮挡特征信息的同时,它引入的被遮挡目标的身体特征增加了可辨别特征信息在整个新构造的特征序列中的比例。也就是,图像块序列经过该模块后,输出的图像块序列中将会包含更多的与被遮挡人相关的特征信息,这对于擅长整体识别的ViT网络来说,无疑是有助于进一步提升其网络性能的。
空间切割模块的有效性:空间切割模块可以将输入图像的空间相关性集成到图像块序列中,从而提高图像块序列的短程相关性,进而增强网络提取被遮挡人的局部特征的能力。
在索引 3中,Baseline+P+F的 Rank⁃1达到64.6%,mAP达到56.9%。在索引6中,本文在索引3的基础上增加了空间切割模块。实验效果有了很大的提高。Rank⁃1增加了 5.2%,mAP提升了3.9%。
观察索引4、5和6这3组实验,可以发现,只要增加空间切割模块,网络对遮挡重识别的效果就会产生大幅度提高,这说明了卷积神经网络中的空间相关性也存在于视觉转换器的图像块序列中。所以利用输入图片的空间相关性,将图像块中的部分特征信息提取出来,做人员损失加权,可以有效地提高视觉转换器网络对于局部特征的关注,在从整体相关性对目标进行识别分类的时候,融入的空间相关性可以拉大相似目标间的距离。这对复杂的细类分类问题是有效的。
3.5 初始强化系数分析
本文进行了几组对比实验,以评估初始强化系数对全维度增强模块性能的影响。
首先,将可学习增强编码初始化为高斯分布、均匀分布、拉普拉斯分布和指数分布。实验结果表明,不同的分布会不同程度地改变图像的原始特征分布。仅通过一层图像块全维度增强模块很难将特征偏差校正回原始分布,这将导致网络陷入局部优化。因此,本文决定将可学习图像块编码初始化为全一张量,即一开始不调整图像特征分布。但是,通过调整初始增强系数β,同样可以改变网络的收敛速度和收敛精度,即不同的初始强化系数会影响行人重识别效果。
如图6和图7所示的实验结果可以清楚看到,行人重识别效果随着初始增强系数β的变化而变化。只有当β为1.0时,行人重识别性能达到最佳,这表明该模块在一定范围内具有优化网络的能力。一旦β值取在[0.95~1.05]区间之外,图像特征信息就会发生较大变化,改变了图像和图像块序列原有的内在关联,网络的性能就会出现较大波动,模块就很难发挥其优化能力。
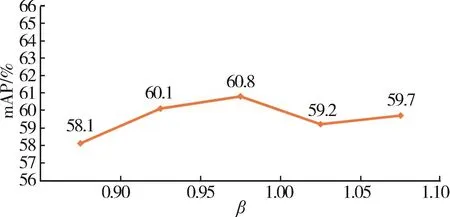
图6 强化系数β在occluded⁃duke数据集的mAP

图7 强化系数β在occluded⁃duke数据集的rank⁃1
根据实验结果还可以得到以下结论:当图像的原始特征分布变化较大时,局部特征转换器模型SCLFT依旧能够保持良好的性能,并且Rank⁃1和mAP都可保持在较高的水平。这充分说明了本文提出的局部特征转换器模型和全维度增强模块对各种输入图像,以及对于各种情况下的行人重识别问题的有效性。
4 结束语
本文提出了一种基于空间相关性和局部特征转换器模型,其中包括本文设计的3个新模块。空间相关性和局部特征转换器模型中的空间切割模块可充分利用输入图像的空间相关性,将其融入到图像块序列中,从而提高图像块序列的短程相关性,使网络模型聚焦被遮挡人的局部可辨别特征。图像块序列全维度增强模块可丰富输入数据的多样性,优化特征图的分布,从而提高网络的泛化能力和鲁棒性。图像块融合和重构模块则更关注遮挡问题,突出被遮挡人的可区分特征,淡化整体特征信息里的干扰信息。最后,本文提出的局部特征转换器网络模型SCLFT在遮挡、部分和整体行人重识别数据集中都取得了良好的实验效果。
