基于多特征的车牌字符识别算法
2022-11-23林炳炎
林炳炎,郭 勇
(福建信息职业技术学院,福州 350003)
0 引言
自动车牌识别在许多领域中都有应用,比如:自动停车场、高速路口自动收费、交通数据采集、预防犯罪等[1-2]。因此,研究自动车牌识别很有意义。车牌的字符识别是自动车牌识别系统的关键技术。目前常用车牌字符识别方法有:支持向量机(Support Vector Machines,SVM)、神经网络和模板匹配。K.K.Kim等[3-4]人采用基于SVM的字符识别,采用投影特征进行车牌识别,但该特征不足以非常精确地表示出所有的字符特性,对于个别字符会出现识别错误。李丰林等[5]人采用基于神经网络的识别方法,识别正确率较高,但是识别的速度较慢,算法的收敛度较慢且无法保证全局最优。吴炜等[6]人采用模板匹配方法,该算法可以较快地识别字符,在实时系统中较常采用,但是识别准确率较低,对于变形字符的识别效果差。
鉴于神经网络和模板匹配的不足以及SVM方法的特征选择非最适合等问题,本文提出了基于多特征的SVM字符识别算法。与传统的SVM算法使用单一特征不同,本文采用多特征的SVM算法识别字符,其中一个特征是字符的HOG(Histogram of Oriented Gradient),该特征能较好地表征字符的特性。此外,采用多次网格搜索方法能够解决SVM参数调节太粗糙的问题。算法实现过程:首先,提取字符的方向梯度直方图、水平投影和垂直投影特征。然后,把提取出来的特征在SVM中训练,采用多次网格搜索方式,多次训练数据,逐步缩小最佳参数范围,直到寻找到SVM的最优参数。该算法能较好地提高字符识别率,具有较强的鲁棒性,在车牌识别系统的字符识别中有较好的应用价值。
1 SVM的原理
SVM是机器学习领域的一个重要算法,该算法在工业界和学术界被广泛应用[7]。SVM是分类与回归模型中分析数据的监督式学习算法。该算法用统计风险最小化的原则来估计一个分类的超平面,找到一个让两类数据之间的边界(margins)最大化的决策边界,使其可以完美区隔开来。
如图1为SVM最优分类平面示意图,圈号和叉号标识的为两类数据。
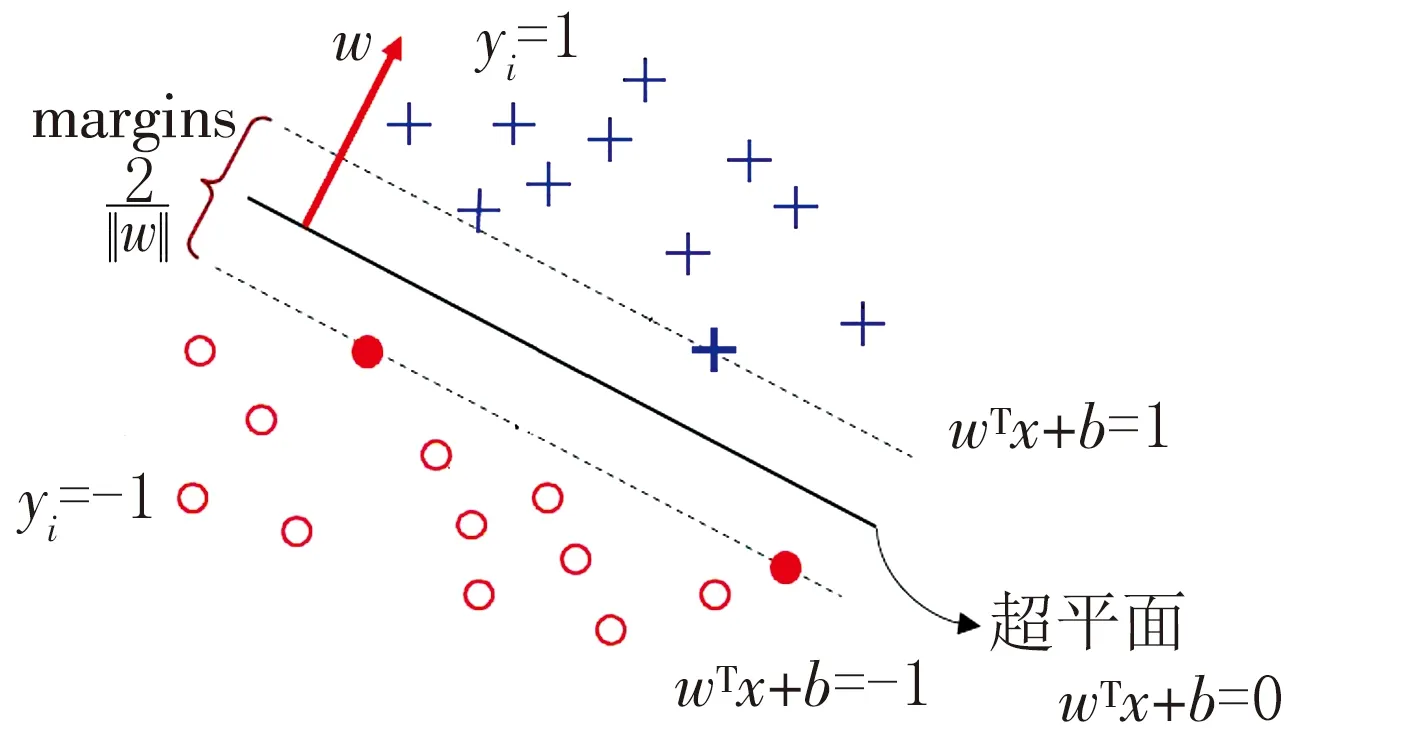
图1 SVM最优分类平面示意图
两类数据标签值分别为1和-1:
(1)
式中yi表示标签值。
这两组数据要满足的规则如下:打叉和打圈的数据点表达式为
(2)
式中:w表示权重,x表示特征向量;b代表偏移值。
两类数据需要满足的条件整理成如式(3):
yi(wTx+b)≥1,∀i=1,2,…,N。
(3)
两类数据之间的间隔为分类间隔(2/‖w‖),SVM寻找超平面就是希望两类数据之间的间隔越大越好。假设SVM有一个超平面为
wTx+b=0。
(4)
为了可以完美地分割两组数据,SVM就是在找参数(w和b)让两组之间的距离最大化,即使分类间隔(2/‖w‖)最大化,也就是最小化‖w‖。转换成数学表达式为
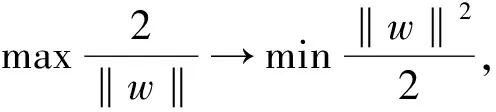
s.t.yi(wTx+b)≥1,∀i=1,2,…,N。
(5)
后来引入soft-margin SVM,soft-margin SVM允许一些数据点落到边界之内。所以目标函数引入权重/惩罚参数,调整后的目标函数为
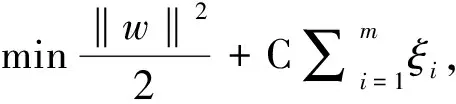
s.t.yi(wTx+b)≥1-ξi,∀i=1,2,…,N,
(6)
式中C是惩罚系数,即对误差的宽容度。C越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差。εi为容错值。
引入拉格朗日函数,把原本问题转换成对偶问题:
s.t.ai≥0,i=1,…,N,
(7)
将原本目标函数转换成Lagrangian函数后求二项式的最优值。
SVM核函数的选择对于其性能的表现至关重要,尤其是针对那些线性不可分的数据。使用核的目的是希望将输入空间内线性不可分的数据映射到一个高纬的特征空间内,使得数据在特征空间内是可分的。本论文使用高斯核函数。高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数应用最广,无论大样本,还是小样本都有比较好的性能,而且其参数相对于多项式核函数要少。
(8)
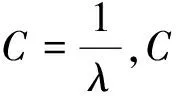
2 算法的实现
2.1 算法实现流程
算法的实现过程如图2所示,包括两个过程:模型训练和模型测试。
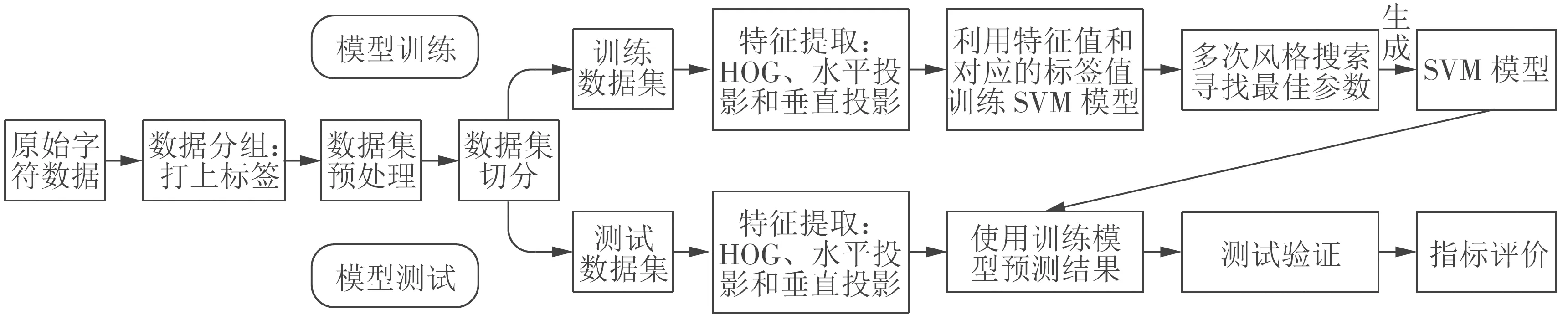
图2 算法实现过程
进行模型的训练和测试之前,先把原始字符数据集中分组(打标签)。然后,把分组的字符数据集加载到内存并进行预处理操作。之后,将数据集随机分组为训练数据集和测试数据集。接下来是模型训练和测试过程。
模型训练过程:首先,提取出训练数据集中每个字符图片的HOG、水平投影和垂直投影特征。然后,把提取出来的特征向量和字符图片对应的标签值放到SVM算法中进行训练。最后,多次网格搜索找到最合适的SVM参数,建立字符数据的SVM模型。模型测试过程使用训练好的SVM模型。
模型测试过程:首先,提取出测试数据集中每个字符图片的HOG、水平投影和垂直投影特征。其次,把特征向量放入训练好的SVM模型中,预测其结果。再次,把预测值同测试数据集的标签值进行比对,计算预测值的正确率。最后,根据预测值的正确率评价算法的优劣。
2.2 数据分组
车牌字符共有34个,包含10个数字和24个英文字母(‘I’和‘O’除外)。待训练和测试的字符图片共有13 163张,如图3所示为“0”“2”“L”字符图片。首先,每张字符图片全部被处理成像素为20×20的灰度图(字符为白色,背景为黑色)。将所有图片打上标签,标签值代表图片的字符。然后,将字符图片分类放到34个文件夹(每个字符图片放到对应的文件夹)中。这样,完成了数据集和标签值的关联。训练时,加载的文件夹的名字就是对应文件夹字符图片的标签值。至此,完成了字符图片数据的分组。
图3 字符图片
2.3 数据预处理
首先,分批次加载13 163张字符图片,然后对每张图片进行简单的预处理。预处理的过程包括:偏斜的字符扭正(计算图像的中心距)、图像灰度化处理等。该过程是为后续字符图片特征值的提取做准备。
2.4 数据集切分
如图4所示,训练模型前,将13 163张数据集随机分成两部分,分别为训练数据集(70%的数据集)和测试数据集(30%的数据集)。训练数据集用于训练模型;测试数据集用于训练模型的评估:测试模型的误差,选出误差最小的模型。完成数据集切分后,进入机器学习过程,即数据的训练过程。
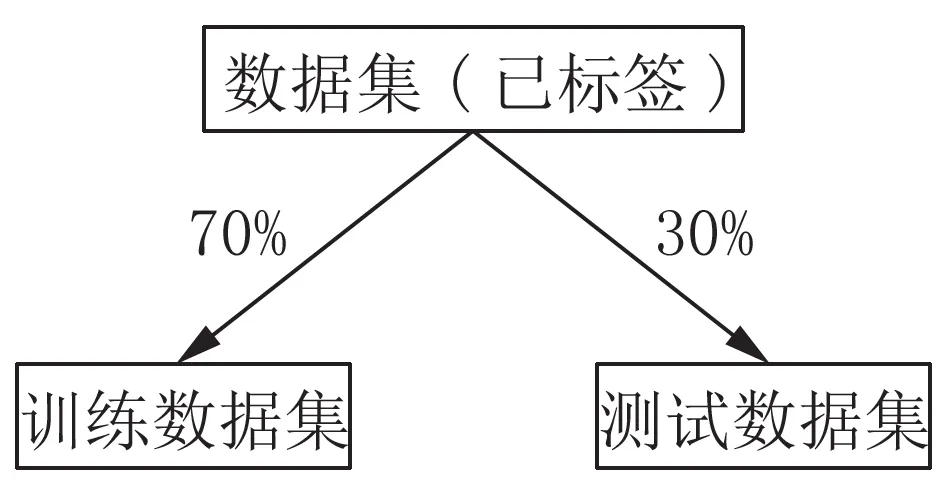
图4 数据集切分
2.5 字符特征提取
字符特征提取的目的是提取字符图片的特征参数,用于SVM分类。车牌字符图片的特征包括:HOG、水平投影和垂直投影特征。特征总数为104个,其中HOG、水平投影和垂直投影特征分别有64个、20个、20个。
2.5.1 提取数据集HOG特征
HOG特征是一种特征描述符,该特征在图像处理和机器视觉的目标检测中被大量使用[8]。本文算法通过计算图像局部区域的方向梯度直方图作为图像特征。如图5所示为数字0提取出来的HOG特征。由于HOG特征提取算法步骤较为固定,本文不再赘述。经过多次测试和比对,最终确定算法的几个重要参数:
1)将预处理图像的梯度方向划分到[0,16)这16个bin中(算法中窗口大小为20×20,bins取16);
2)将计算出来的4个cell的HOG组成一个block的HOG(注:算法中block大小为2×2);
3)算法中将4个cell(每个cell有16个bin)的HOG计算出来后连接在一起组成64个HOG特征值。

图5 数字0的HOG特征
2.5.2 提取数据集投影特征
不同字符投影特征值不相同。字符的投影特征包括:水平和垂直投影[9]。水平投影为二维图像在Y轴上的投影,每行白色像素的累计值构成了水平方向上的投影。垂直投影为二维图像在X轴上的投影,每列白色像素的累计值构成了垂直方向上的投影。投影特征值的提取过程:首先,将图像二值化,然后,把二值化的图像分别投影到水平方向和垂直方向上。图6和图7分别为数字0和字母M的水平投影和垂直投影特征。以水平投影为例,解释字符数据投影特征的提取过程:
step1:加载字符图像数据。
step2:将字符图像数据转为灰度图。
step3:使用大津算法计算阈值,对图形进行二值化处理(字符为白色,背景为黑色)。
step4:循环各行,依次判断每一行每个像素点是否为白色,统计该行所有白色像素的个数。新建一个长度为图像高度的数组,统计出来的每行白色像素,分别保存到数组对应的位置。
step5:线性归一化每行非0字符,将投影值转换到[0,1]的范围,并作为水平投影特征向量。由于字符图片全部被处理成像素为20×20的图片,因此水平投影的特征向量长度为20。
垂直投影特征提取类似,不再赘述。

图6 数字0水平和垂直投影

图7 字母M水平和垂直投影
2.6 使用SVM和网格搜索训练模型
SVM为二分类算法,车牌字符共有34个,故本文采用一对多分类器。分类思路:将34个种类字符的任意一个和其他33个种类构成一个二分类器。由于有34个字符需要处理,因此仅需34个二分类器即可完成分类。
在使用SVM算法进行分类数据时,选择合适的参数是至关重要的。SVM最重要的几个参数:核函数、C值和gamma值。
2.6.1 核函数的选择
SVM常用的核函数有高斯核函数和多项式核函数。高斯核函数可以把低维空间转化为无限维空间,同时又实现了在低维计算高维点积的。多项式核函数的参数比RBF多,计算量更大。本文针对字符的分类,采用高斯核函数。
2.6.2C和gamma的优化
本文采用多次网格搜索算法,逐步找到最合适的C和gamma。网格搜索[10]是一种调参手段,使用穷举搜索方法。在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。以两个参数的模型为例,参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3×4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索,所以叫网格搜索。如表1所示,采用多次网格搜索,首先,粗略搜索参数,查找最合适的参数大概的取值范围。然后在粗略参数的附近进一步采用网格搜索,逐步细调参数,直至找到最合适的参数。表的最后一列“正确率”,是搜索出的最合适的参数在测试数据上计算出来的正确率。

表1 多次网格搜索策略
由表1可知,经过多次网格搜索,算法正确率由93.61%逐步提高到99.51%。最终,找到SVM算法最合适的C和gamma参数分别为1.1和2.5。
3 实验结果
实验编写语言为Python,开发平台是PyCharm 2008.2(安装有OpenCV函数库和Python常用库)。测试使用的硬件平台为Macbook Pro笔记本电脑,主要性能指标为Intel Core i5@2.90 GHz、8G内存,操作系统为OS X,并且未针对任何特殊硬件进行优化。
本文使用13 163张灰度图片作为测试图片,其中9 214张(70%)图片作为训练数据集,3 949张(30%)图片作为测试数据集。采用多次网格搜索寻找最佳的SVM模型参数,在3 949张测试数据集上测试。表2为测试结果和基于SVM[3]、BP神经网络[4]、模板匹配[5]、Gabor变换[6]比较的结果。结果表明:本文算法的字符识别准确率相比其他几种算法有明显提高。
精准率(precision)和召回率(recall)是被广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量[11]。精确率计算的是在被识别为正类别的样本中,确实为正类别的比例。召回率计算的是在所有正类别样本中,被正确识别为正类别的比例。f1-score是精准率和召回率加权调和平均值。图8表示34个字符的混淆矩阵,如图可知几乎所有字符图片都在主对角线上,这意味着几乎所有的字符数据的分类都是正确的。见表3,通过计算所有的字符组成的混淆矩阵得出每个字符的精确率、召回率和f1-score。结果表明:算法的精确率、召回率和f1-score较高。

表2 本文字符识别算法和其他算法识别正确率的比较
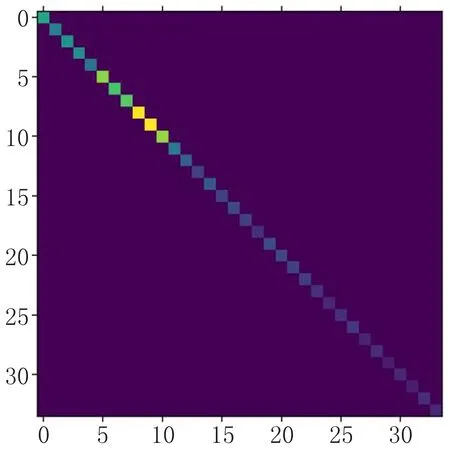
图8 字符混淆矩阵
4 结语
本文是基于多特征(HOG、水平投影和垂直投影)的车牌字符识别算法。HOG特征能够很好地反映字符的轮廓,并且对字符的亮度和颜色变化不敏感,在字符识别上具有优良的性能。投影特征能够很好地将字符投影到一个低维的特征空间中。水平投影和垂直投影能够较好地表示每个字符的像素分布特点,利用分布特点很好地区分出不同的字符。因此,利用HOG、水平投影和垂直投影3个特征相结合能够很好地区分出不同的字符数据。
采用多次网格搜索方式,不断训练和调优SVM参数,能够在一定的范围内找到最优值,更好地优化算法识别的正确率。此外,本文的数据集较大(13 163张),给SVM算法提供了足够多的训练数据集和测试数据集,保证SVM算法能够较好地建立字符识别模型和得到较准确的验证识别正确率。
此外,算法的高精确率、召回率和f1-score,对车牌字符的正确识别具有重要的意义。
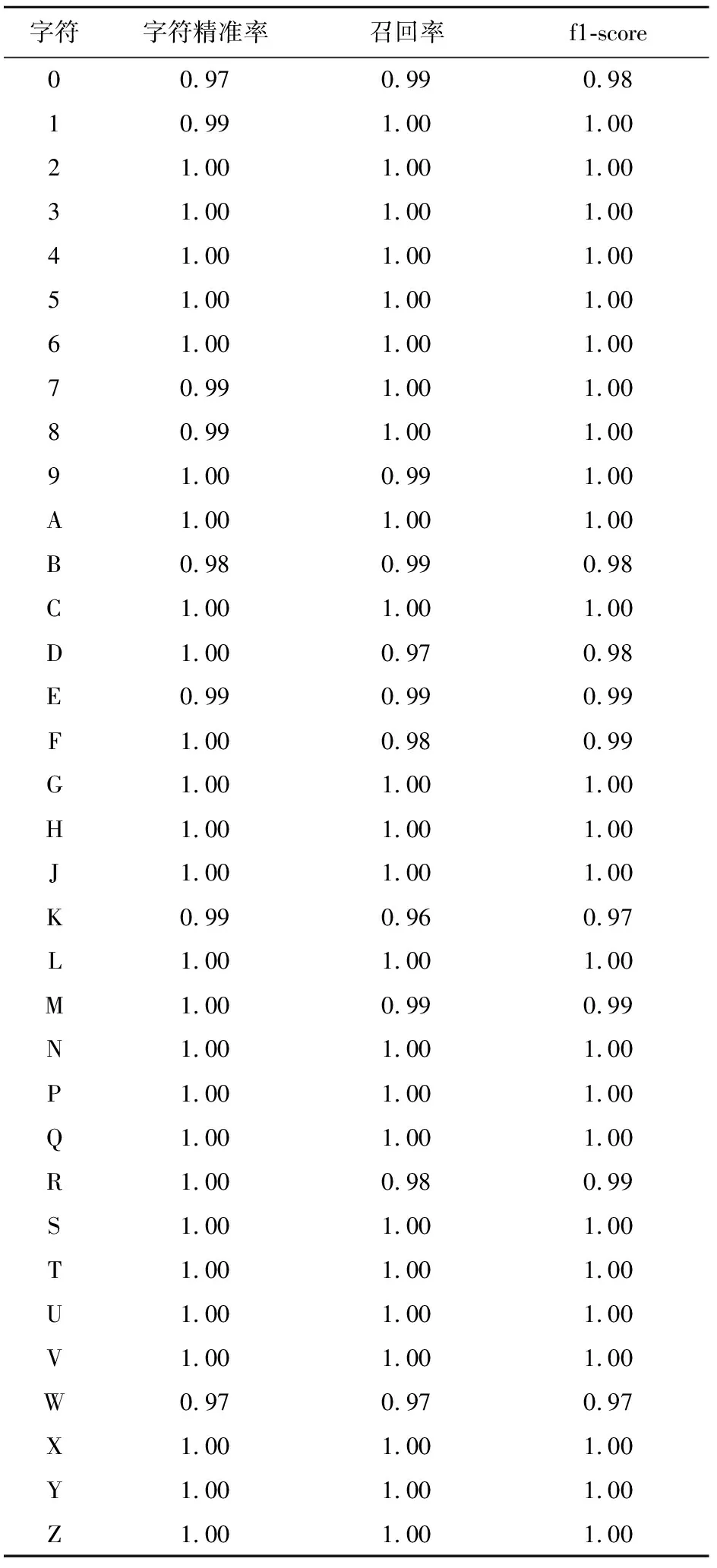
表3 字符精准率、召回率和f1-score
下一步的研究方向是针对经常识别错误的个别字符,进一步分析该字符的特征,优化特征数据,提高个别字符识别的精准率和召回率。
