省重点实验室评价机制与基于机器学习的评价模型研究
——以吉林省为例
2022-11-23郑国勋
张 华,许 骏,郑国勋
(1.长春工程学院计算机技术与工程学院;2.长白山历史文化与VR技术重构吉林省重点实验室,长春 130012)
0 引言
省级重点实验室应具有年龄和知识结构合理的高素质人员队伍,具有良好的培养学术接班人的条件,能够开展高水平和实质性的国内外学术交流与合作,拥有较先进的仪器设备和完善的配套设施。这就需要从多角度、多维度对省级重点实验室进行评价,并能够建立一套合理客观、省时省力的评价模型,引导实验室创新突破、合理规划布局,建成特色鲜明,科研水平强,人才队伍强,学科深度交叉融合,协同创新突出,覆盖基础研究、应用研究、试验开发和产业化等创新全链条的省级实验室,从而更好地服务地方经济发展建设,引领重点产业高质量发展。我们使用机器学习中的线性算法、决策树算法、随机森林算法对吉林省重点实验室的评价机制进行模型构建,并对模型进行评价研究。
1 省级重点实验室评价模型影响因素研究
2020年2月科技部官方网站发布了《关于破除科技评价中“唯论文”不良导向的若干措施(试行)》,文件按照“分类评价、注重实效”的原则,制订了“强化分类考核评价导向”等九大项具体措施。措施提出,要注重标志性成果的质量、贡献和影响,对论文评价实行代表作制度,强化代表作同行评议,实行定量评价与定性评价相结合。李岱素[1]在广东省重点实验室综合绩效测评指标的选取上,选择了R&D固定人员数、人均项目经费数、承担省部级或以上课题项目数等13个测评指标。王会君等[2]将重点实验室综合能力用实验室投入能力、实验室教学与管理能力、科技创新能力、对外交流与合作能力来表征,并提出构建重点实验室量化考核指标体系,该体系由在室的客座研究人员数、R&D固定人员数等30个具体指标组成。为了全面评价省级重点实验室的研究水平与学术贡献、队伍建设与人才培养、产学研集合、服务地方经济建设及资源共享等多方面业绩,确定了吉林省重点实验室的评价模型因素包括实验室新增成果、新增成果增长率、团队成长性、团队稳定性、方向发展均衡性、诚信度、基础建设、社会服务、投入产出比9大方面。
2 吉林省重点实验室的评价指标因素解析
吉林省重点实验室的评价指标因素解析中包含了一级指标、二级指标[3]与指标解释,在指标解释中明确了如何界定各指标成果的有效性,既包括客观指标也包括主观指标,可以全方位地对省重点实验室进行评价,具体解析见表1。
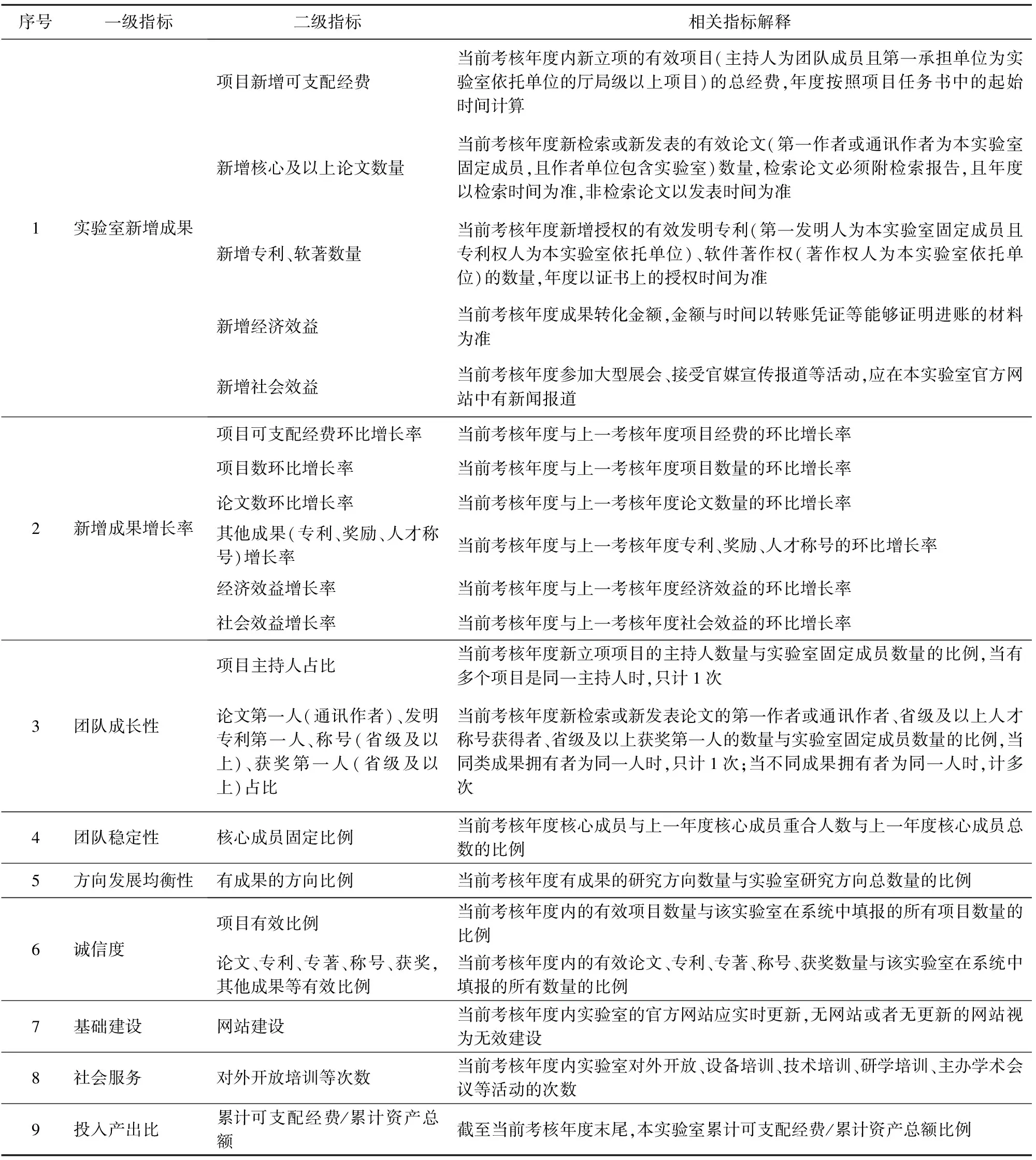
表1 吉林省重点实验室的评价指标因素解析
3 吉林省重点实验室的评价模型构建研究
3.1 研究思路
本研究使用回归模型的典型思路,首先获取数据,可以分析数据结构,并划分出训练集与测试集,然后可以对数据进行可视化,通过相关系数的比较寻找各属性的相关性,进而试验不同属性的组合。通常数据中有噪音存在,需要对数据进行清理,文本和分类属性与需要转换成数值类型,部分属性需要特征缩放。然后开始训练和评估训练集,可以用不同的回归模型做试验,如:简单线性模型(Simple Linear)、决策树模型(Decision Tree)、随机森林模型(Random Forest)、人工神经网络模型(Artificial Neural Networks,简称ANN)等,训练结果可以通过K-折交叉验证进行评估,通常选取10-折交叉验证,分析验证结果并微调模型从而得到最佳模型,确定最终的评价模型,最后使用此模型预测测试集,完成数据的回归预测,具体的研究思路如图1。因所有模型均要设置自变量X与因变量y,可以将表1中所有的二级指标均作为自变量,评价得分作为因变量,放入前述各种模型进行机器学习,并根据评价指标结果选择最佳模型完成模型的构建。
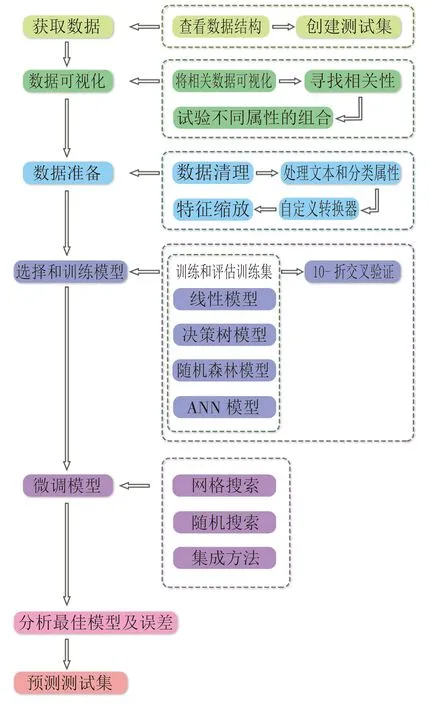
图1 研究思路
3.2 数据来源
本研究基于吉林省科学技术厅提供的2018年度88家省级重点实验室及2019年度110家省级重点实验室的年度考核汇总数据。数据中详细统计了每类成果的填报数量与有效数量。
3.3 模型评价指标
本研究根据各重点实验室上报的成果数据进行分析,预测能够获得的评分,是典型的回归问题。回归问题的典型性能指标是均方根误差(RMSE),它测量的是预测过程中预测错误的标准偏差,结果呈现出正态分布,也称高斯分布,是一种呈钟形态的分布,符合“68-95-99.7”规则。RMSE的数学计算公式如下:
3.4 研究方法选择
可以使用多种模型进行回归预测,本文选用简单线性模型、决策树模型、随机森林模型及人工神经网络模型研究吉林省重点实验室的评价预测。机器学习框架可以选用Scikit-learn2.0,开发语言可以选用Python,数据存储选用Excel文件。
3.4.1 简单线性模型(Simple Linear)
简单线性回归是回归预测中最简单的一种方法,是拟合y=b0+b1×x这条直线的过程。通常是先随机画出一条直线,计算各个点相对于这条直线的误差平方和,即
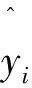
数据集中的各个属性(自变量X)与预测结果(因变量y)通常是非常复杂的关系,而简单线性模型要求自变量与因变量满足线性关系,预测结果通常是差强人意的,尤其是训练数据不足时通常会出现过拟合现象,因此很少有应用会使用简单线性模型进行预测。
3.4.2 决策树模型(Decision Tree)
决策树模型是一个非常强大的模型,它能够从数据中找到复杂的非线性关系,既能实现分类预测也能实现回归预测。决策树同数据结构中的树类似,包含一个根结点、若干个内部结点和若干个叶结点,叶节点是不可再分的结点,决策树学习的目的是产生一棵泛化能力强的决策树[4]。决策树通常有3种常用算法,其划分最优属性的依据不同,其中ID3算法采用信息增益,C4.5算法采用增益率,CART算法采用基尼指数。
每种模型在划分训练集与测试集时都有运气的成分存在,所以决策树模型也容易产生过拟合现象,此时可以使用K-折交叉验证对模型重新进行评价。K-折交叉验证是把训练集数据分成K份(Kfolds),K一般取10,即分为10份,然后进行10次验证。第1次时,把最后1份数据做测试集,前面9份做训练集,得到一个被训练集拟合出的模型,然后使用此模型对测试集数据进行预测,预测结果与真实结果比较得到第1次验证的准确率;第2次时,取倒数第2份数据做测试集,其余9份做训练集,重复第1次的过程,得到第2次验证的准确率;依次类推,完成10次验证,得到10个模型,10个准确率,10个混淆矩阵,10个平方误差。取10个准确率的平均值作为评价模型非常可观的准确率参数,也可以取10个平方误差的平均值作为评价参数。
3.4.3 随机森林模型(Random Forest)
随机森林模型是通过对特征的随机子集进行许多个决策树的训练,然后对预测结果取平均值,因为是在多个模型的基础之上建立模型,所以是一种集成学习的方法。
随机森林模型同样存在过拟合的现象,可以通过简化模型、约束模型或获得更多训练数据的方法解决,也可以通过Scikit-learn中的GridSearchCV进行网格搜索,对模型中的各种超参数尝试进行不同的组合,并得到相应模型的均方根误差,进而选择出最佳超参数组合,得到最佳预测模型。随机森林主要有6大参数:n_estimators(子树的数量,默认值100)、max_depth(树的最大生长深度)、min_samples_leaf(叶子的最小样本数量)、min_samples_split(分支结点的最小样本数量)、max_feature(最大选择特征数)、criterion(决策树划分标准,默认gini),除此之外,通常还需要尝试bootstrap参数,用于设置每次构建决策树时是否采用放回样本的方式抽取数据集,即是否装袋。
3.4.4 人工神经网络(ANN)
人工神经网络是通过模仿人类的神经系统建造类似结构完成学习的,包括输入层、隐藏层和输出层。在重点实验室的评价过程中,将各实验室的二级指标数值作为神经网络中的输入神经元充当自变量的角色,隐藏层是通过权重设置抓取各自变量之间的关系,从而体现一种现象或特征,比如,项目新增可支配经费越多,项目新增可支配经费环比增长率大概率也会越高。输入层与隐藏层的各个神经元的关系密切度用权重来表示,关系越密切,权重越大,并不是每一个输入层的神经元都与隐藏层的神经元有关,所以有些权重为0。隐藏层中需要计算损失函数,进而传递到输出层进行结果预测,完成正向传播过程。常用的激活函数包括“阈值”函数、S函数(Sigmod函数)、线性整流函数(ReLU)、双曲正切函数。隐藏层中经常使用ReLU函数,输出层中经常使用S函数。激活函数的选择对构建整个神经网络有决定性意义,通过优化损失函数来优化神经网络,完成正向传播后,将损失函数反向传播,通过梯度下降算法更新权重,再重新进行正向传播,此过程重复多次,使得损失函数下降,但损失函数并不是一直下降,其与学习速率有关,速率越大,损失函数可能会变大。
4 结论
使用机器学习模型结合历年吉林省重点实验室的评价数据可以建立预测模型,并通过预测模型对当前考核年度的实验室进行评分预测,可以大大减少人工时间,为政府部门减少工作量、提高工作效率。在构建预测模型前,需要大量的有效数据,成果是否有效,还需要人工把关与掌控,同时,为使模型预测结果更为准确,降低预测误差,需要多年多个实验室的真实数据积累,随着吉林省重点实验室年度考核工作的逐步推进,数据将越来越多,模型可以进行调整,以更好地实现评价预测。
