基于D-S证据理论的大数据融合研究
——以长白山气象要素大数据为例
2022-11-23郑国勋姚学坤胥政尧陈冠澎
郑国勋,姚学坤,胥政尧,陈冠澎
(1.长春工程学院; 2.长白山历史文化与VR技术重构吉林省重点实验室,长春130012)
0 引言
长白山作为吉林省最靓丽的名片,有着悠久的历史和文化,在清代被视为清朝崛起地,作为龙脉加以封禁。近些年前往长白山旅游的人越来越多,天池作为长白山最重要的景点更是让人神往。但是能否看到天池与天气有很大关系,在出行前人们会关注长白山的天气情况,以确定最佳的出发日期,这个过程是很费时费力的。但在大数据时代,通过智能数据分析可以给人们旅游提供科学参考与建议性决策,这不仅便利了游客,也对促进长白山旅游业发展大有帮助。本文根据2019年—2020年长白山气象要素数据对长白山一年中每个月的各项要素(空气温度、相对湿度、露点温度等)的月均值进行分析,通过D-S证据理论对各气象要素分析后的结果进行数据融合,意在分析出哪个时期适合到长白山旅游。
1 数据清洗
数据清洗(Data Cleaning)顾名思义就是把“脏”数据“洗掉”或是把“脏”数据“洗净”,它是大数据处理必不可少的环节,是对数据进行重新审查和校验的必要过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据仓库中的数据是面向某一主题的数据的集合,是从多个业务系统中获取而来,所以避免不了有错误的和相互之间有冲突的数据,这些错误的或有冲突的数据对我们是不友好的,称为“脏数据”。不符合要求的数据主要有不完整的数据、错误的数据、重复的数据3类。数据清洗是发现并纠正数据文件中可识别错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。
缺失值指的是在现有数据集中某个或某些属性的值是不完整的。缺失值产生的原因主要分为人为因素和机器因素,人为因素是指由于人的主观因素或操作失误导致的数据缺失,机器因素是指由于机器的原因导致的数据采集或存储出现错误导致的数据缺失。
常用的缺失值处理手段包含缺失值删除、缺失值插补以及真值转换法3种。缺失值删除指的是删除含有缺失值的个案,这种方式是处理缺失值最原始的方法,如果对数据集中含缺失值的属性进行删除不会对数据集产生过大影响,那么将缺失值删除是最有效的方法。缺失值插补是指通过均值、平均值、众数或一些算法预测缺失值,然后对缺失值进行插补。当缺失值在数据集中占极小部分时,此时若对含缺失值的属性进行删除会导致信息的浪费,那么对缺失值进行插补是处理这种数据缺失的一种很有效的手段。真值转换指的是不对缺失值进行处理,承认缺失值的存在,将其作为数据分布的一部分,例如在网站进行注册,输入性别时,如果未输入,那么将未知作为数据分布的一部分,将其作为后序数据处理和模型构建的一部分。
本文所使用的2019年—2020年长白山的气象要素数据集来源于国家地球系统科学数据中心。原数据集中存在缺失值,如部分月份中露点温度这一气象要素(表1)的数据存在缺失,这会影响后序数据融合与模型构建,因此采用缺失值插补的方法对缺失值进行处理。
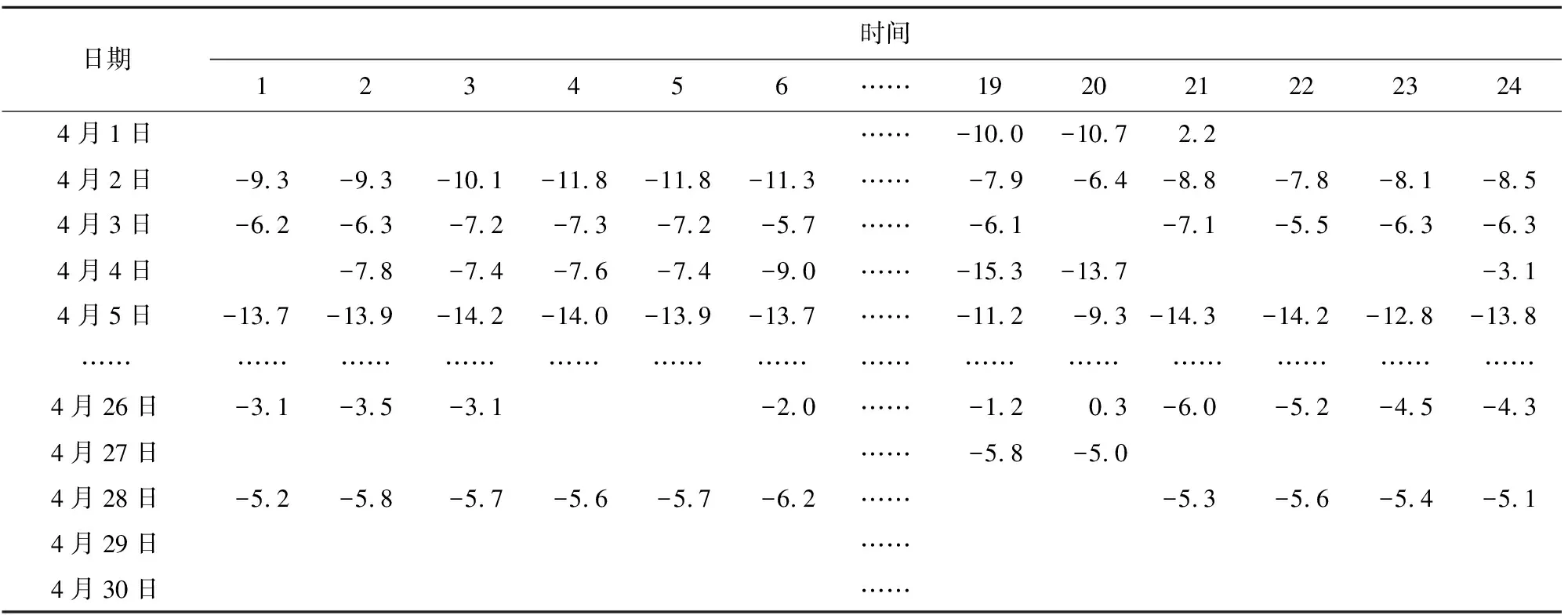
表1 长白山气象要素观测记录表露点温度部分数据(2020年4月)
经对数据分析,采用KNN(K-nearest neighbor)算法对表中缺失值进行插补。KNN是一种监督算法,也是一种相对简单的机器学习算法,由于其简单、高效的特点,被广泛应用。KNN算法的分类思想是,如果一个未知类标号的数据与特征空间中K个已知类标号的数据相邻,则对K个数据对象的类标号数进行从大到小的排序。对于未知类标签的数据,选择第一个类标签作为它自己的类标签。可以看出,当K=1时,类标号未知的数据的类标号与最近的数据的类标号相同。因此,KNN分类算法在类决策方面具有局部性,仅与少数相邻的样本数据有关,不同于支持向量机的分割类域,更适用于类域重叠或重叠的数据。
欧几里得距离,也称为欧氏距离,是KNN分类算法中常用的距离度量。欧几里德距离是一种原理简单、测量范围最广的距离测量方法。对于空间中的两点,欧几里德距离表示两点之间的线性距离;对于空间向量,欧几里德距离是指向量的长度,即从一个点到原点的距离。可以通过KNNImputer函数计算欧几里得距离矩阵,找到最近的邻居来帮助估算观测值中存在的缺失值。具体计算公式如式(1):
(1)
对缺失值处理后的数据集见表2。
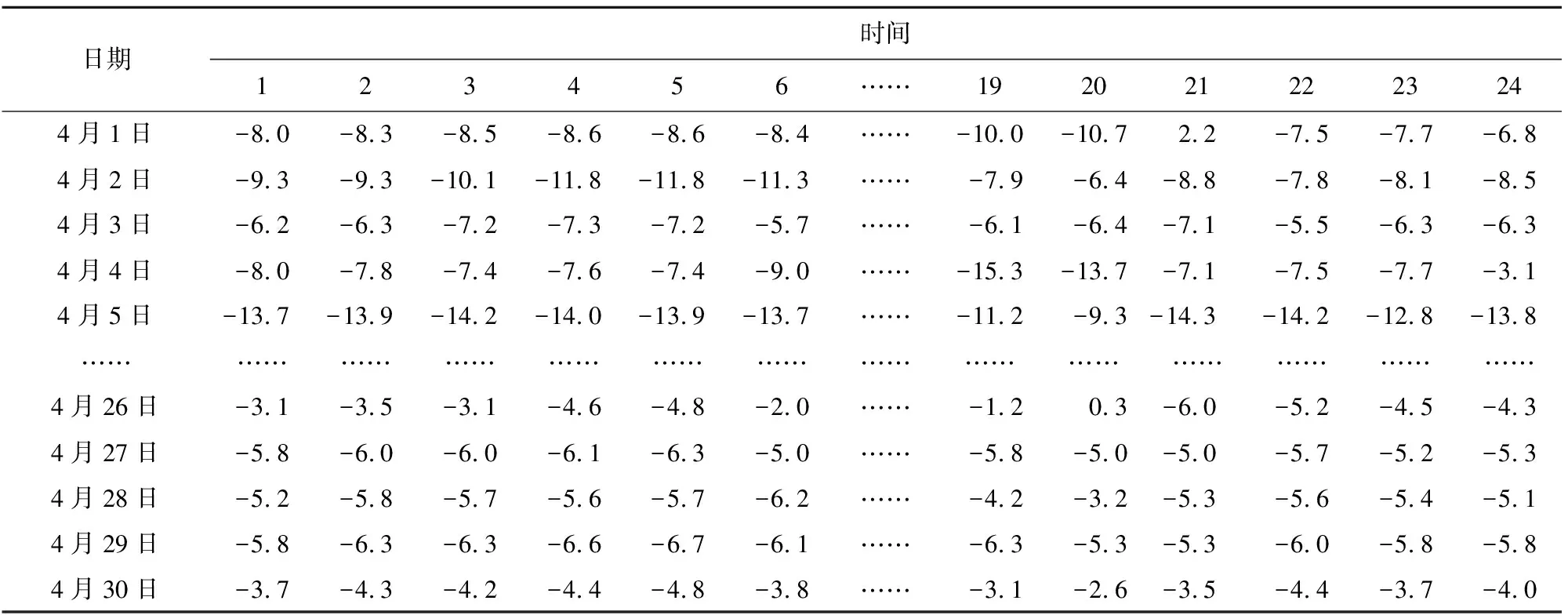
表2 处理后长白山气象要素观测记录表露点温度部分数据(2020年4月)
2 数据融合
数据融合是多数据源在一定准则下加以自动分析、综合,完成决策和评估所进行的信息处理。数据融合作为一种信息处理技术在处理不同问题时使用的算法和形式存在很大差异,但也有很多共同之处,如任务和功能导致的数据融合系统的层次划分、目的不同的数据融合系统采用不同的拓扑结构等[1]。数据融合主要应用在多源影像复合、机器人和智能仪器系统、战场和无人驾驶飞机、图像分析与理解、目标检测与跟踪、自动目标识别等领域。常用的数据融合方法包括加权平均法、贝叶斯估计法、卡尔曼滤波法、D-S(Dempster-Shafer)证据理论等。传感器老化和数据采集过程中其他因素的干扰会产生不确定性,针对这种问题常常使用贝叶斯估计法和D-S证据理论[2]。
2.1 D-S证据理论
D-S证据理论是对贝叶斯推理方法的推广,是一种处理不确定性问题的完整理论。贝叶斯推理方法是利用概率论中贝叶斯条件概率进行的,需要知道先验概率。而D-S证据理论不需要知道先验概率,能够很好地表示“不确定”问题,被广泛用来处理不确定数据。其最大的优点是采用“区间估计”对不确定信息进行描述,在区分不知道和不确定方面以及精确反映证据收集方面有很大的灵活性。D-S证据理论处理数据的基本思路如图1所示。
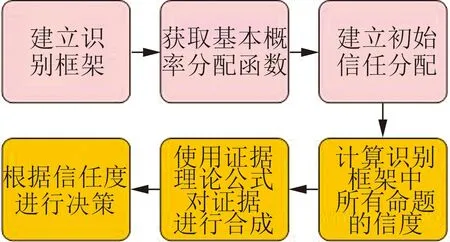
图1 D-S证据理论基本思路图
2.1.1 识别框架
识别框架又称X全域、假设空间,通常用数学符号Θ表示,其中包含所要判断案例的所有元素,在任何时刻,案例的答案取值只能是Θ中的元素。把这样的不相容事件组成的集合Θ称为识别框架。假设有n个元素,识别框架可表示为式(2):
Θ={θ1,θ2,...,θn},
(2)
式中θn是识别框架Θ的一个事件或元素。识别框架Θ的全部子集的集合叫做幂集,记作2Θ,可表示为式(3):
2Θ={∅,{θ1},{θ2},...,{θn},{θ1,θ2},{θ1,θ3},...,{θ1,θ2,θ3},...,Θ}。
(3)
2.1.2 基本概率分配函数
在确定了识别框架后,需要根据基本概率分配(Basic Probability Assignment,BPA)函数计算证据对命题的信任度,在D-S证据理论中,基本概率分配对最终结果有着至关重要的影响。
设Θ为一个识别框架,在识别框架Θ上的基本概率分配函数m是一个2Θ→[0,1]的映射,该函数满足式(4):
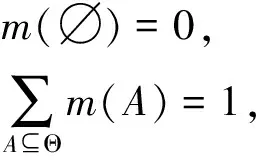
(4)
式中m(A)表示证据对命题A的信任度。∅的基本信任值为0,其他所有子集的信任值总和为1。对于任意一个A,只要满足m(A)>0,则称A为焦元。
2.1.3 信任函数
假设集合∀A⊆2Θ是识别框架Θ的一个子集,A的全部子集的基本概率分配函数之和则是信任函数(Belief Function),如式(5):
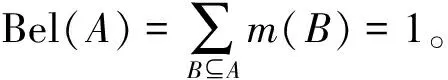
(5)
2.1.4 似然函数
假设集合∀A⊆2Θ是识别框架Θ的一个子集,似然函数表示的是不否认A的信任度,指的是与集合A交集不为空的概率之和,如式(6):
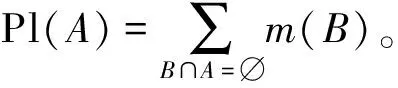
(6)
2.1.5 信任区间
假设集合∀A⊆2Θ是识别框架Θ的一个子集,[Bel(A),Pl(A)]就是集合A的信任区间,表示对集合A的确认程度。
2.1.6 Dempster合成规则
获得决策需要一种方法计算多个证据对识别框架中每个假设的综合影响,得出在多个证据作用下使假设成立的综合信任程度[3]。对于∀A⊆2Θ,Θ上的两个基本概率分配函数m1,m2的Dempster合成规则如式(7):
(7)
式中K为归一化系数,K的算法如式(8):
(8)
2.2D-S证据理论在长白山气象要素数据融合中的应用
2.2.1 识别框架的建立
长白山气象要素数据融合意在根据长白山的各项气象要素分析出在一年12个月中哪个月最适合至长白山旅游,识别框架如式(9):
Θ={1,2,3,4,5,6,7,8,9,10,11,12},
(9)
式中数字1~12表示的是1月至12月。
2.2.2 改进基本概率分配函数
基本概率分配获取困难一直是D-S证据理论的一个门槛,本文根据Z-Score标准化方法建立了一种基本概率分配函数。Z-Score标准化方法如式(10):
(10)
式中:x表示个体的观测值;μ表示所有样本数据的均值;δ表示所有样本数据的标准差。
本文基于Z-Score标准化方法建立基本概率分配函数,将其使用的均值更换为长白山气象中各要素的人体最适值(本文所使用的人体最适值不代表真实人体最适值,只是人体所处环境相对舒适的值)。函数公式如式(11):
(11)
由于基本概率分配是基于Z-Score标准化方法建立的基本概率分配函数,所以推导出的结果表示的是各气象要素偏离人体最适值的程度,图2及图3的折线图中,点的y轴值越大,代表当前月份该气象要素标识此月份越不适合到长白山旅游,反之点的y轴值越小,代表当前月份该气象要素标识此月份越适合到长白山旅游。图4~7的折线图中,点的y轴值越大,表示当前月份越不适合至长白山旅游,反之点的y轴值越小,表示当前月份越适合到长白山旅游。
2019年—2020年长白山各气象要素月平均值根据前述基本概率分配函数获得的基本概率分配分别如图2~3所示。
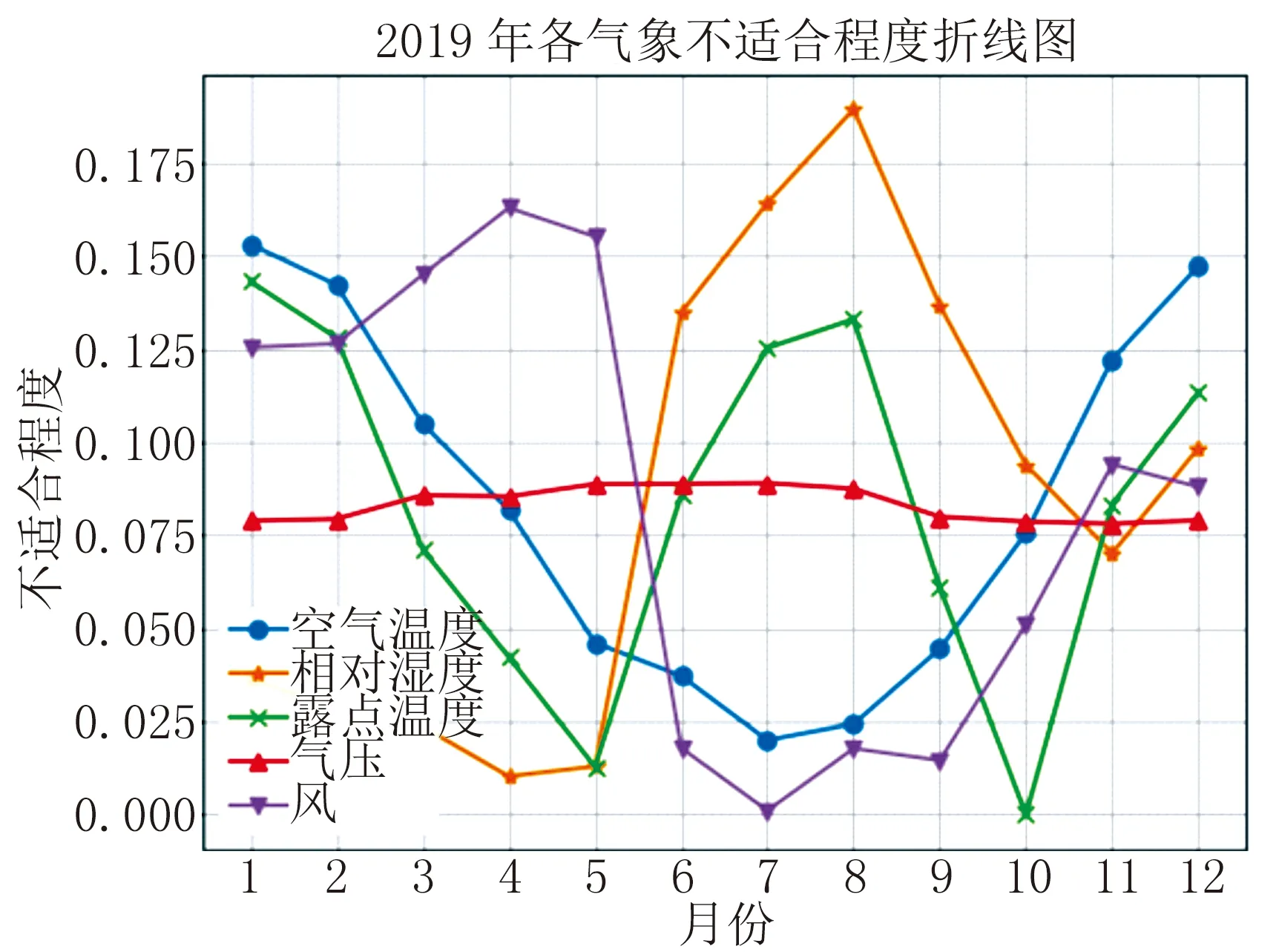
图2 2019年长白山气象要素月平均值基本概率分配
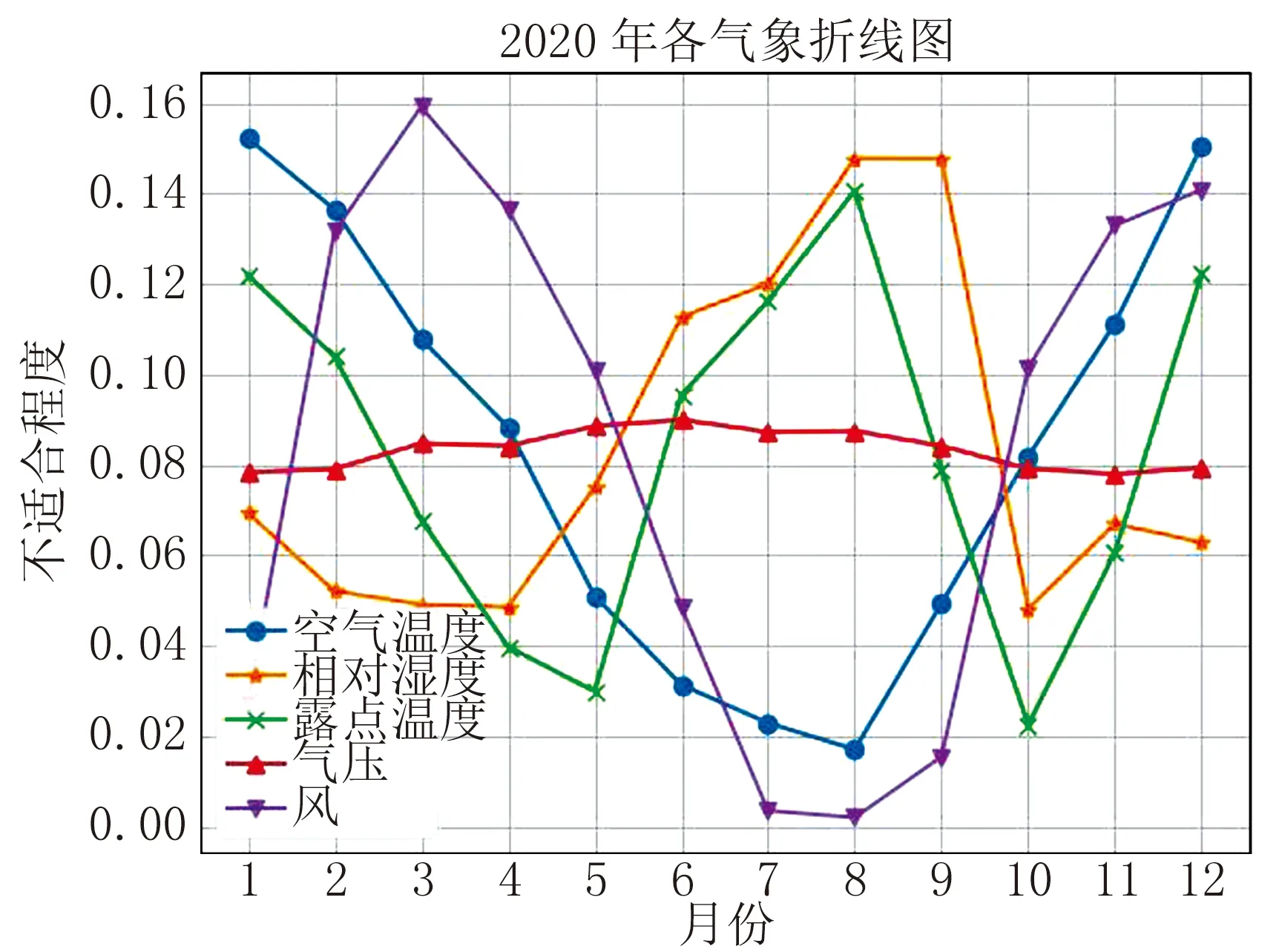
图3 2020年长白山气象要素月平均值基本概率分配
2.2.3 证据合成
根据提取的数据获得长白山气象各要素的月平均值同,通过基本概率分配函数计算出其基本概率分配,进行证据合成。首先计算归一化系数K,如式(12):
(12)
式中i表示月份。
根据计算出的归一化系数K对每个月各要素的月平均值通过Desmpster合成规则进行证据合成,如式(13):
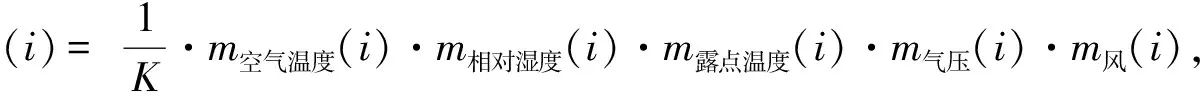
(13)
式中i表示月份,通过将各个月的证据信息进行合成可得出一年中各个月份不适合至长白山旅游的程度。
2019年和2020年长白山气象要素D-S证据理论数据融合折线图如图4~5所示。
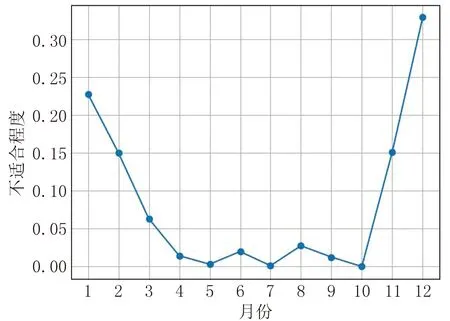
图4 2019年长白山气象要素D-S证据理论数据融合折线图
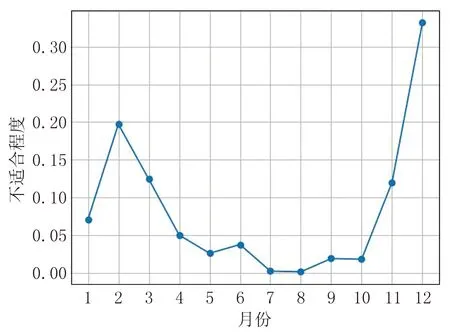
图5 2020年长白山气象要素D-S证据理论数据融合折线图
2.3 D-S证据理论的改进
李弼程等[4]学者基于Yager、孙权、邓勇等学者的成果对D-S证据理论进行了改进,对D-S证据理论进行了进一步优化,通过分析之前学者提出的方法的优势与不足,李弼程给出了一种加权和信息融合方法,该方法把归一化系数K按照比例加权分配给各焦元,合成后如式(13):
m(A)=p(A)+(1-K)q(A),∀A≠∅
m(∅)=0,
(13)
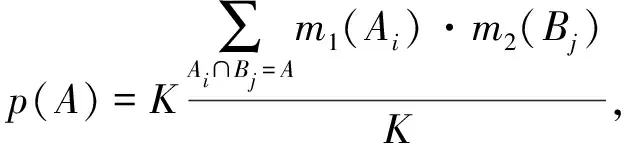
该方法计算过程简单,物理含义明确,融合结果与直观认识页比较具有较大的工程实际应用价值[5]。当证据没有冲突时,该方法与传统的D-S证据理论产生的结果基本相同。
将该方法与使用传统的D-S证据理论对长白山气象要素数据进行数据融合的结果做了对比,使用该方法分别对2019年和2020年的长白山气象数据进行数据融合,绘制的长白山气象要素加权求和信息融合方法折线图如图6~7所示,图中点的y轴值越小,标识当前月越适合至长白山旅游。
4 结论
本文主要对长白山气象要素数据进行了数据清洗及融合。在数据清洗方面,重点针对缺失值进行了处理,通过K最邻近分类算法对缺失值进行了预测及插补。在数据融合方面,使用了D-S证据理论,通过对Z-Score标准化算法公式的改变,构建了基本概率分配函数,对数据融合前各要素的月平均值以及数据融合后的数值绘制了折线图,通过折线图可提供气象要素方面的决策依据。
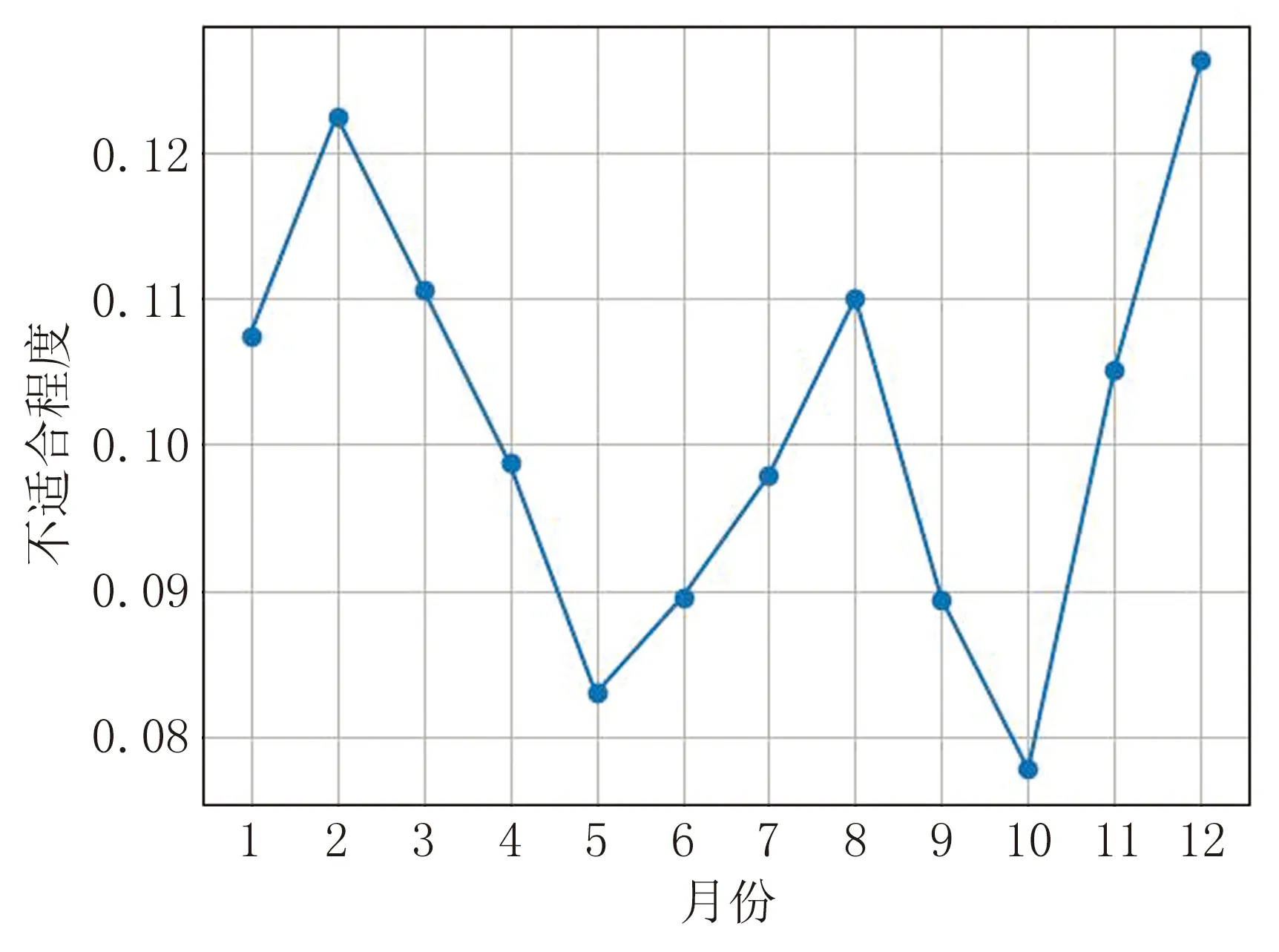
图6 2019年长白山气象要素加权求和信息融合方法折线图
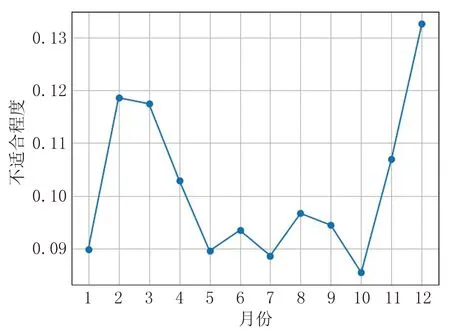
图7 2020年长白山气象要素加权求和信息融合方法折线图
