基于Python的招聘岗位数据分析与可视化
2022-11-22马妍妍
马妍妍
(济南工程职业技术学院 山东 济南 250000)
0 引言
互联网已经成为人们生活中必不可少的获取信息的手段,这使得人们的学习与生活更加的便捷,但也正是随着互联网的普及,数据大爆炸的时代提前来到,在庞大的数据面前,我们如何能快速准确地找到有效信息成为数据处理工作的重要前提,而基于python语言的数据爬虫与数据处理,可以将干扰信息筛除,达到对数据进行精确检索的目的,优化用户的网络体验,节约人们获取数据的时间和精力[1-4]。本文以大数据为关键词搜索招聘岗位,对搜索结果进行数据采集、数据处理、数据分析和可视化展示,并得出各招聘因素之间的相关结论。
1 整体流程设计

图1 整体流程设计
如图1所示,本项目整体实现过程分为三大模块:需求分析、整体设计、模块实现,其中重点是模块的实现过程。在实现过程中,主要采用Python语言编程实现,其中数据采集技术是采用网络爬虫的方式实现,获取最原始数据源;数据处理则引入Pandas模块,将“脏数据”筛除,将剩余数据格式统一;数据分析步骤依然引用Pandas模块,使用索引函数loc、数据合并函数merge函数实现数据的转换,统计函数group()实现数据的分组统计;最后使用pyecharts模块实现数据的可视化,常见可视化图形如:柱状图、折线图、饼图、热点图等。
2 关键技术
2.1 数据采集技术
随着互联网的快速发展和计算机存储能力的提升以及复杂算法的发展,各种新技术使得全球数据量呈现出前所未有的爆发式增长态势;与此同时,数据的复杂性也急剧增长,其多样性、低价值密度、实时性等复杂特征日益显著,大数据时代已经到来。面对浩瀚的数据,数据采集技术应运而生,因此数据采集成为大数据分析的入口。
数据采集(DAQ),又称数据获取,是利用一种程序或装置从系统外部采集数据,经过数据清洗,最终输入到存储系统中的方法。它的特点是以自动化手段为主,摆脱了繁杂的人工录入方式,而且涵盖了全量采集、增量采集,并不会对数据进行采样处理。数据采集的范围相当广泛,涵盖了终端数据、服务器数据、互联网设备数据等。按照数据产生的主体不同,数据采集范围主要包括:数据库采集、系统日志采集、网络数据采集、感知设备数据采集[5]。
2.1.1 数据库采集
数据库采集主要是使用MySQL和Oracle等关系型数据库和Redis、HBase等NoSqL数据库进行数据库采集。企业会通过在采集端部署大量数据库并实现这些数据库之间的均衡负载和分片来完成大数据的采集工作。
2.1.2 系统日志采集
此种方法主要用于收集公司业务平台产生的大量日志数据,供离线和在线的大数据分析系统使用。日志采集系统具备高可用性、高可靠性和可扩展性,系统日志采集工具均采用分布式架构,能够满足每秒数百兆字节的日志数据采集和传输需求。
2.1.3 网络数据采集
网络数据采集是通过网络爬虫技术实现从公开网站或API获取数据信息的过程,使用网络爬虫时,会从一个或若干个初始网页的URL开始,依次获取各个网页上的内容,并且在抓取网页的过程中不断从当前页面上抽取新的URL放入队列,直到满足设置的停止条件,爬取的数据可以储存在本地的存储系统中。
2.1.4 感知设备数据采集
感知设备是一种检测装置,比如摄像头、温、湿度传感器等,这些设备能感受到被测量的信息,并能将感受到的信息按一定规律转换为电信号或其他所需形式的信息输出,以满足信息的传输、处理、存储、显示、记录的控制等要求。
一般在工作现场会安装各类传感器,获取如压力、温度、流量、声音等参数,传感器要求能适应各种恶劣的环境。此种数据采集方式是智慧+物联网行业应用较为普遍的一种方式。
2.2 数据处理技术
数据处理(data processing)是对数据的采集、存储、检索、加工、变换和传输。其基本目的是从大量的、可能是杂乱无章的、难以理解的数据中抽取并推导出对于某些特定的人们来说是有价值、有意义的数据。数据处理是大数据分析的核心。
从数据采集范围和不同的产生主体可知,原始数据是各种各样的,而应用需求和数据类型也是不尽相同,但是基本的数据处理流程是一致的。网络爬虫数据的处理过程就是一类非常典型的大数据应用,在合适的工具辅助下,数据处理的一般流程为:首先对数据源进行抽取和集成,将数据全部处理成统一的格式进行存储,然后选取适合的工具,如Python提供的pandas库,对存储的数据进行分析,提取有益数据,通过统计分析后,将结果用可视化的方式呈现给用户端[6]。
2.3 数据可视化技术
数据可视化是关于数据视觉表现形式的科学技术研究。即将处理统计后的数据,以显性的可视化的方式呈现给用户,常见的可视化工具有以下几种。
2.3.1 Excel
Excel是微软提供的数据处理常用的一款办公软件,当数据量较小时,可使用其图表功能进行数据的可视化展示,在选项卡【插入】——【图表】中可选择柱状图、折线图、饼图、雷达图等表现形式。
2.3.2 Matplotlib
Matplotlib是Python中最常用的可视化工具之一,因为在函数设计上参考了Matlab,所以叫做Matplotlib,可以非常方便地创建海量类型的2D图表和一些基本的3D图表,可根据数据集(DataFrame,Series)自行定义x、y轴,绘制图形(线形图、柱状图、直方图、密度图、散布图等),能够解决大部分的需要。
2.3.3 Pyecharts
Pyecharts即Python+Echarts,而Echarts是一个由百度开源的数据可视化工具,有着良好的交互性、精巧的图表设计能力。Python与Echarts结合就形成了Pyecharts。Pyecharts是一种交互式的可视化库,更加灵活美观,作图更加灵活、巧妙。
2.3.4 Tableau Public
Tableau诞生在斯坦福大学,它是一款交互式的数据可视化工具,用户通过轻点鼠标和简单拖放,就可以迅速创建出智能、精美的报表和仪表盘,而无需编码。
3 重点模块实现过程
3.1 数据采集
本项目数据来源为网络数据,因此采用网络数据采集,主要通过网络爬虫实现。网络爬虫又称为网络蜘蛛,是实现网络数据采集的重要手段。它可以对网页源码信息进行分析,自动对网页数据进行抓取[2]。具体运行机制可分为:获取网页源码、分析网页数据、提取目标数据、存储数据四部分。如图2所示。

图2 数据采集过程
1)获取网页源码:以Python语言为载体,利用import引用requests、BeautifulSoup模块,首先进行网址链接的拼接,打开51job网站,输入查询岗位的关键字,将其与官网网址进行拼接形成最终URL,使用request访问最终URL,该项目一共获取前100页数据,故每次使用for循环改变page参数值,取值范围为1~100。
2)分析网页数据:使用BeautifulSoup库解析网页数据,其访问响应即网页源码转化为一个树状结构,每一个结点都可以成为一个标签对象,通过.text属性提取该标签的相关数据。
3)提取目标数据:使用正则表达式和BeautifulSoup对解析后的网页数据进行定位和提取。正则表达式是对字符串操作的一种逻辑公式,通过一个特定组合,能够从繁杂的字符串中快速提取符合条件的字串。而BeautifulSoup库则是通过css选择器对元素进行定位,通过树形结构,依次对目标数据进行访问,更加方便和快捷[3]。重点代码如图所示:
使用BeautifulSoup:

使用正则表达式:

4)存储数据:该项目采用Excel存储数据。一方面,Excel是处理数据的强大帮手,而且Python对Excel的使用提供了强大的模块支持;另一方面,相较于大数据而言,本项目数据量较少,使用Excel管理数据会更高效便捷。本项目使用Python提供的xlwt模块创建Excel表格,将爬取到的数据构建成列表,通过append方法将公司名称、职位、地点、性质薪资、学历要求、工作经验等数据依次存入Excel表格中。
3.2 数据处理
数据处理主要是数据清洗。数据清洗(Data cleaning)是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正错误,并提供数据的一致性。这一环节也是保证后续分析结果正确性的重要一环[4]。本项目数据清洗主要进行了数据去重、空值处理、统一数据格式等操作,使用Python第三方库Pandas库实现这一处理,主要步骤如图3所示。
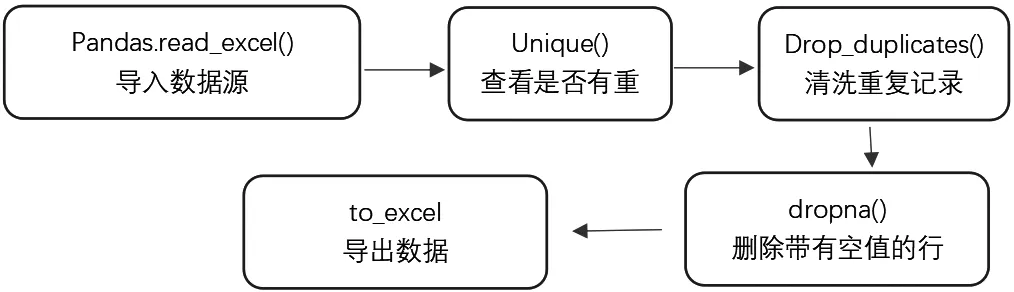
图3 数据处理过程
3.3 数据分析与可视化
数据的可视化首先对清洗后的数据进行分组、统计等处理,然后以图形化的方式呈现出来,便于人们更直观地分析总结数据背后的规律,为决策提供依据。Python生态提供了诸如Matplotlib、Tableau、Echarts、pyecharts等模块实现数据的可视化展示,本项目主要采用pyecharts模块进行数据的可视化展示,对招聘信息进行分析,例如:公司地点、招聘职位、薪资待遇等。下面以大数据为关键词搜索到的前100页岗位数据为例,介绍数据可视化及分析结论。
3.3.1 招聘人数分析
本项目采用pyecharts提供的Bar()函数生成柱状图来展示各省市招聘人数情况,从图4可以看出,广东、上海、江苏、北京、浙江等一线城市招聘岗位比较多,也从侧面说明了这些地区的IT、互联网发展较其他地区要更好一些,发展机会更多。
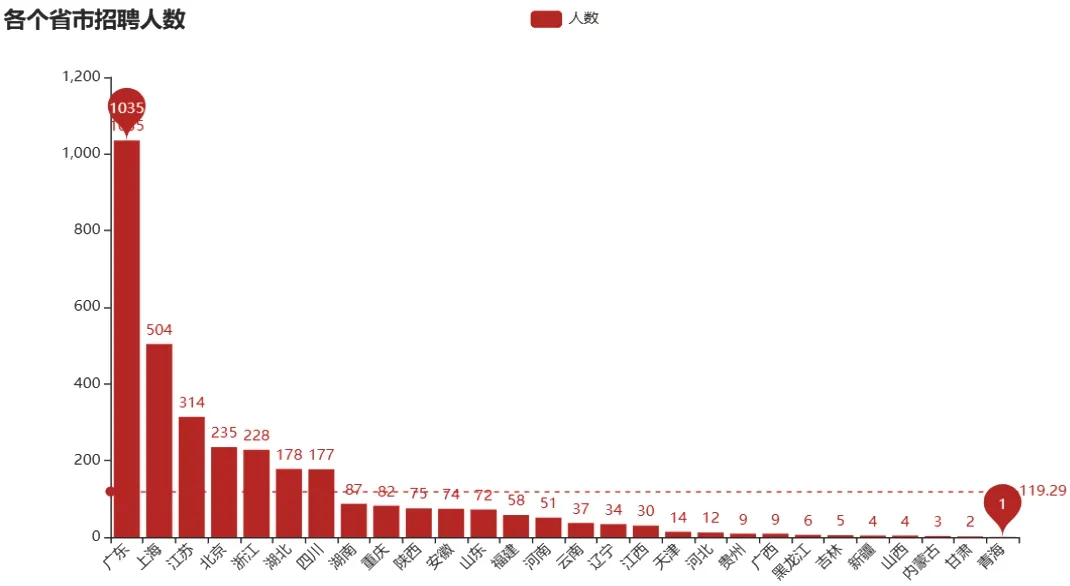
图4 各省市招聘人数柱状图
3.3.2 学历要求
学历要求是公司招聘职位的基本要求,本项目通过Pie()函数生成饼状图,展示招聘数据中的学历要求,如图5所示。可以看出一半以上的企业最低学历要求为本科,也有一部分要求大专以上学历,其他学历占据比例非常少。

图5 学历要求
3.3.3 工作经验要求
通过Funnel()函数生成工作经验漏斗图,从图6可以看出,大数据相关岗位大多数要求要有3~4年工作经验,少部分可以接受应届生或无经验人群。

图6 岗位工作经验要求
3.3.4 岗位类型分析
通过WordCloud()函数生成词云图,词云图常用来统计某些关键词出现的频率,能够更直观地展示统计结果。从图7可以看到,大数据相关的招聘岗位开发工程师最多,其次也有架构师、项目经理、运营、数据分析等岗位。

图7 岗位类型
3.3.5 薪资待遇
依然使用饼状图展示该岗位的薪资待遇情况,如图8所示。38%的企业给出的薪资在5 000~10 000元,45%的企业给出的薪资范围在10 000~20 000元之间,5 000元以下和20 000元以上都较少。
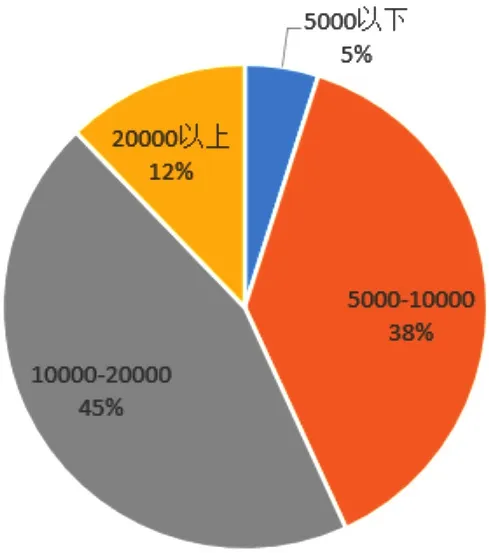
图8 薪资待遇
4 结语
综上所述,本文使用Python语言为载体,实现了对大数据为关键词进行搜索的招聘岗位数据的采集、处理与可视化,整体流程分为了三大模块,分别是数据采集、数据处理和数据可视化展示,在这个过程中,数据采集采用“爬”手段获取了原始数据,数据处理是重要环节,为正确的数据分析提供基础保障。最后,通过可视化展示,从公司地点、工作经验要求、薪资待遇等不同维度将招聘信息进行展示,为用户提供了良好的参考依据。
