基于RFE的XGBoost算法在风机叶片结冰状态评测①
2022-11-22高博,张亚
高 博, 张 亚
(安徽理工大学电气与信息工程学院,安徽 淮南 232001)
0 引 言
风力发电是新能源发电的一种重要方式,可以直接将风能转化为电能相对于传统能源发电解决了社会和环境问题。然而面对高海拔,高湿度这种地理环境长期暴露在外的叶片经常会发生结冰现象,监控风机运行温度是否达到设定的阈值是最常用的一个手段,然而此种方法具有偶然性和滞后性。经常出现预测不准,或者触发警报时叶片已经出现大规模结冰现象。风电场的SCADA系统可以采集风机运行时的风速、风向、温度、变桨速度、功率曲线等参数,来判断叶片结冰现象。本文基于风电机组SCADA数据利用RFE特征选择和XGBoost算法对叶片结冰状态进行预测,能够解决数据维度高且效率低的问题。并且通过与随机森林、SVM、Adaboost这些传统机器学习算法做对比发现,XGBoost模型确实具有更高的预测精度以及较快的预测速度。
1 数据处理
研究所用的风电机组SCADA数据来自工业大数据创新竞赛,数据记录了15号和21号两台风机运行的时间戳、风速、机舱温度、变桨温度等28个数据维度,数据每7s采样一次时间跨度为2个月。其中15号风机运行数据作为训练集用于训练模型,21号风机数据作为测试集用于检验模型预测效果。全部数据集包括了正常运行的数据,故障运行的数据以及无效数据,数据大小如下表1。

表1 原始数据信息
1.1 数据不平衡处理
实验首先利用特征工程对数据进行清洗,筛选掉对于预测没有帮助的无效数据,其次我们发现对于整个数据集而言,正常数据所占的比例要远高于故障数据,面对如此不平衡的数据分布,算法预测模型可能无法做出准确的预测,最后该模型往往倾向于预测大多数集合,少数集合可能被视为噪音或被忽略。因此这种不平衡会严重影响模型预测的精度。针对这种不平衡数据我们通常有多种方法进行处理,这里采用了下采样的处理方式,具体方法是选取一部分正常样本,数量为故障样本的2倍,如下表2所示。
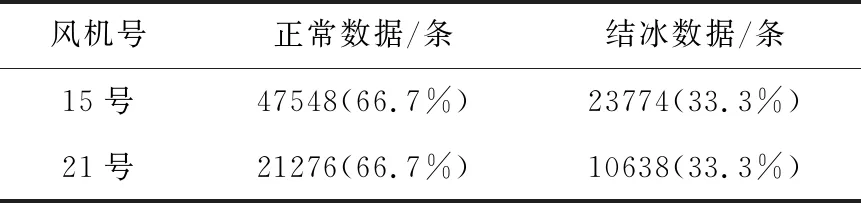
表2 下采样结果
1.2 RFE结冰预测特征选择
相比于模型和算法,数据和特征对机器学习预测的影响更为明显,对于工业数据而言28个维度并不算太低,而且并不是所有特征都同叶片结冰有较强的关联,若选用全部特征有可能只会增加模型的复杂度,甚至造成维数灾难,文中选用了RFE作为特征选择,对原始的28个特征进行特征工程处理,在降维的同时降低数据的冗余性。
递归特征消除(RFE)是通过对给定的算法模型进行拟合,按照特征重要性进行排序,丢弃不重要的特征,并重新拟合模型来实现,这个过程不断重复,直至特定数量的特征被保留。在本文风机SCADA数据采用RFE进行特征选择后发现特征个数降至9个维度为最佳,下图为特征重要性分析结果,以及所选的9个特征名称表格。
2 XGBoost算法
XGBoost算法是一种基于梯度提升树改进算法。其高效的实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在机器学习竞赛以及工业大数据预测中,并取得不错的成绩。XGBoost算法最大的特点是能够进行多线程并行计算,并且相对于传统GBDT仅使用一阶导数信息,XGBoost对损失函数进行二阶泰勒展开,并在目标函数中引入正则项防止模型过拟合。
当有k个决策树时XGBoost模型对样本的预测结果表示如式(1):
(1)
其损失函数可以表示如式(2):
(2)
(3)
损失函数可以表示为式(4):
(4)
对损失函数进行二阶展开有式(5):
(5)
公式中的gi和hi分别是损失函数的一阶和二阶导数,移除常数项后有式(6):
(6)
将Ij={i∣q(xi)=j}定义为第j个叶子点,即式(7):
(7)
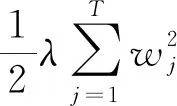
wj表示当前叶子节点样本权重。最终得到目标函数为式(8):
(8)
其中γ为限制树生长的阈值,只有增益大于阈值时,节点才可以分割。
3 实验验证
3.1 参数选择
由于XGBoost属于梯度提升树的集成算法,其参数可以分为如下三部分,集成算法本身的参数、机器学习任务的相关参数、集成弱评估器的相关参数。由于各参数对模型精度的影响不同,本文主要对前两部分的9个参数进行了优化,下表显示了使用的9个主要参数。
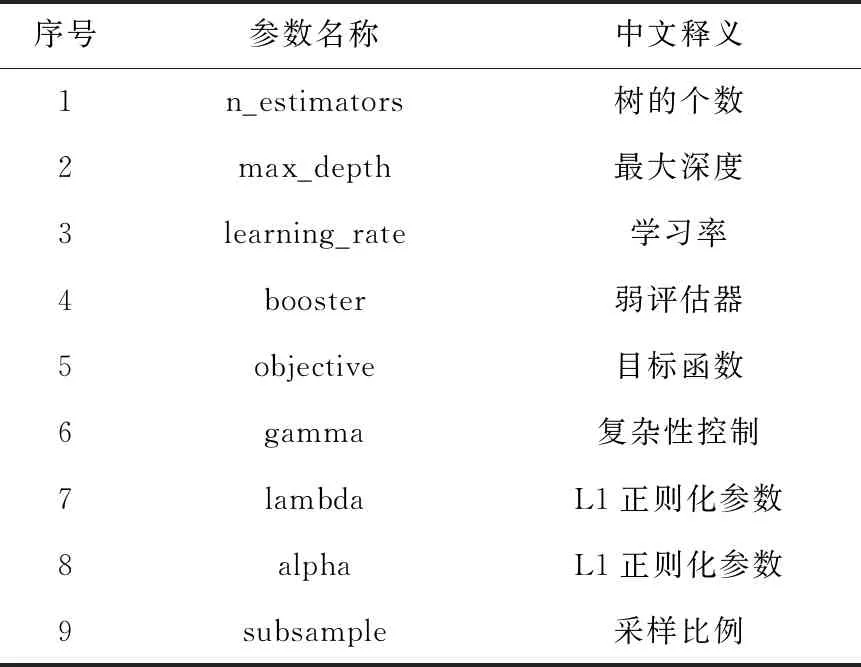
表4 重要参数
由于超参数的空间是无尽的,不同的场景对应不同的超参数,因此超参数的组合配置只能是“更优解”,手动尝试各种参数无疑是浪费时间,而scilit-learn帮助实现了自动化,那就是网格搜索,由于n_estimators与learnin_rate在调参时相互影响,且参数booster在非线性数据集上只有gbtree,dart两种选择,所以首先对这三个参数进行网格搜索,剩余六个参数用于学习曲线调参,经过参数调优将模型训练到最佳。
3.2 基于RFE的XGBoost算法的风机叶片结冰建模流程
在风机SCADA数据经过数据预处理以及RFE特征选择后,将处理好的15号风机数据分为训练样本以及测试样本,将训练样本带入XGBoost模型中训练,并根据网格搜索和学习曲线进行参数调优,直至最终确定模型。接着开始用处理好的21号风机数据检验模型预测效果,将处理好的21号风机的数据分为测试数据及验证数据,模型标签0代表叶片没有结冰,1代表叶片已经结冰,将测试数据导入已经确定的XGBoost模型,在根据原始验证数据去评估模型效果,其流程见下图。
3.3 模型评价指标
模型经过参数优化之后需要选择合适的模型评估指标,对于二分类问题我们可以将预测结果和实际结果划分为真正例(TP)、假正例(FP)、真反例(TN)、和假反例(FN)四种情况,其中TP表示正确预测叶片结冰;FP表示错误预测叶片结冰;TN表示正确预测叶片正常;FN表示错误预测叶片正常。为了检验模型效果,用准确率(A)、查准率(P)、查全率(R)以及查准率与查全率的调和平均数(F1)来评价模型的效果。
(9)
(10)
(11)
(12)
3.4 实验对比及分析
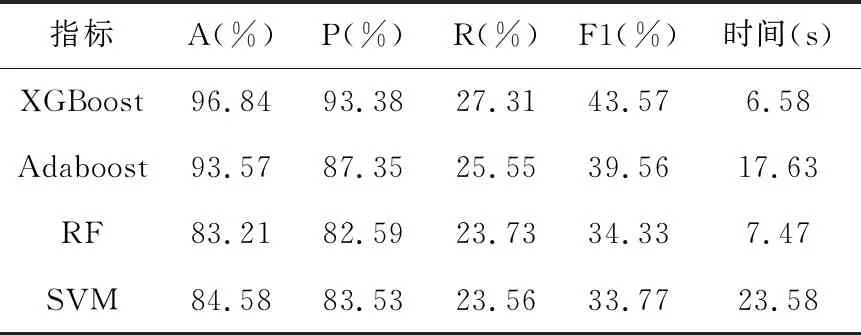
表5 4种分类器效果对比
实验结果表明,提出的基于RFE的XGBoost算法结冰预测在各个指标上的检测性能均优于其他三种算法,Adaboost虽然和XGBoost同属于boosting算法,对数据同样具有优秀的分类能力,但是Xgboost可以进行并行计算所以计算速度要优于Adaboost且对不平衡数据的分类精度同样优于Adaboost。随机森林相对于XGBoost同样也是包含多棵决策树的算法,但是预测结果也是要差于XGBoost,对于传统的SVM分类器,由于需要不断寻找可以最优化分开数据之间超平面直至计算出的结果收敛为止,所以在样本较大时的效率要远低与XGBoost算法。
4 结 语
文中提出的一种基于RFE的XGBoost算法对风机叶片结冰的预测,经过实验验证,确实可以准确且高效的预测风机叶片的结冰,模型评估指标也要优于其它传统机器学习算法,能够在确保较高预测精度的情况下,减少预测时间及时跟进设备的维护,在风机叶片结冰的预测方面有很高的推广价值。
