完全自注意力融合多元卷积的中文命名实体识别研究①
2022-11-22王宗泽张吴波
王宗泽, 张吴波
(湖北汽车工业学院电子信息系,湖北 十堰 442002)
0 引 言
命名实体是从众多的信息数据中选取固定的实体以方便自然语言应用机器识别出某些实体名称,进而生成具有关键词性的信息结果,避免信息冗杂影响人们对数据信息提取的准确性[1-2]。中文信息数据的提取与英语相比,缺少相应的词性边界来实现断句和达意,且市面上常见的翻译软件和编码器难以对中文信息实现较好的提取效果,如传统卷积神经网络以固定的卷积核对信息进行提取,对词语的分界、词性嵌套以及字词歧义等问题的区分上还存在一定的不足,其精准性和可靠性难以保证[3-4]。采用完全自注意力融合多元卷积的模型方式可以有效避免传统模型对中文命名实体识别存在的缺陷,自注意力机制通过比较当前解码器在对单个字词占长度序列中的权重,并在解码器中使得每次生成的词语具有独一性,大大提高了解码器对信息提取的顺畅性和突出性[5]。将完全自注意力与多元卷积神经网络进行融合,有助于提高中文命名实体识别的准确性,避免了词性和用语习惯对不同人群实现信息提取的干扰。
1 中文命名实体识别下的融合模型构建
1.1 完全自注意力编码机制模型的建立
目前常见的命名实体模型多依托于循环神经网络和双向长短期记忆网络编码,实现了信息的提取,符合人固定的阅读顺序习惯,但对相同主要主语所指代的不同意思难以进行区分和辨别,如相同的语句长度中不同主语所对应的动作形式和含义的往往不受句子长短的影响,而与实体动作的发出对象有关,传统的编码器难以提取到相同词语在不同的信息数据中的含义和特征差异[6]。完全自注意力模型通过在对中文命名实体进行信息特征提取的时候,根据信息传递的特征进行选择性的信息传递,而较少受到句子中字词间距离的影响,直接驱动硬件,实现运算任务的执行,能够较大程度上提高编码模型的运算效率和针对性[7]。其运行机制如图1所示。
图1中,编码器将任务信息输入,通过对句式中的信息和内容进行评分,得到各个字词在句子中的重要程度权重占比,然后通过评分结果将机器的“注意力”集中在某些字词上,并根据权重值较大的字词与其相邻字词之间的关联程度来确定其是在句子中的含义,借以避免陷入因一词多义的干扰而使得信息的提取出现误差。自注意力机制跳出了将信息和单词杂糅成一个具体目标向量的局限,而将编码的注意力分配到句子中的实词上,生成查询、键入和值三个向量,并以此为参考依据得到每个部分特定词的自注意向量,进而将主要的信息传递给解码器,即完成了对长时序信息的关键部分提取[8]。该运行机制中的主要公式及含义如式(1)所示。
A(P)=softmax(PNc(PNj)T)PNs
(1)
式(1)中,A(P)为输出矩阵,P为输入值,c,j,s为查询向量、键入向量和数值向量,Nc,Nj,Ns为对应的查询向量矩阵,键入向量矩阵和数值向量矩阵,Softmax为函数,T为标签数量。输入数据信息中的每个字词的评分由信息码和内容码组成,通过对不同字词之间是否存在前后信息的连贯性可以判断该主语的意思及其他相同主语意思之间的区别[9]。
1.2 编码机制下融合多元卷积神经网络的模型构建
利用多元卷积解码框架可以对中文命名实体信息中的词性嵌套问题进行识别,同时不以固定的卷积核作为目标向量,而是通过关联前后字词的语法和词意来实现单独标签种类的解码,实现对提取信息的优化准确,即在融合完全自注意力机制下,对中文命名实体任务的提取着重点于关注相邻词语之间的关系,并进行建模[10-11]。其运行机制的结构图如图2所示。
图2模型结构图展示出,通过对输入映射层的句子信息判断其字词占整个句子中的权重评分,并对其在原始位置上进行位置向量的增加,随后对每个位置向量进行卷积矩阵操作,即可得到精确性较高的输出数据。机制的数学公式如式(2)所示。
(2)
式(2)中,bi为自注意力向量,i为自注意力的个数,Bi为自注意向量拼接成的矩阵,r为过滤器,Concat(Conv[B1,B2,...,Bn]为Bi通过卷积生产得到的矩阵,MLP为多层感机,tanh为非线性化激活函数。借助多层感知机和函数对卷积生成的具有识别任务的卷积核进行信息特征的抓取以区别不同字词所代表标签数的强弱关系,其意义在于避免操作过程的冗余,对前后数据信息的关联卷积可以保证信息的顺畅性,进而更好判断出标签种类,发现隐藏向量与关联字词之间的特征关系,提高信息提取的准确性[12]。式(3)为矩阵运行公式。
(3)
式(3)中,o为关联的单词数量,C.k表示模型的卷积核,n为过滤器的个数,M(s,v)为卷积核经过卷积后的结果,Concate为连接首尾向量的结果,Di为第i个标签的矩阵,融合自注意力和多元卷积的模型机制可以实现对信息序列进行标签化分类和卷积操作,进而实现对信息特征的提取。
对于中文命名实体中的判断识别需要运用评价指标对其进行定量分析,包括准确率、召回率和F值,F值的计算公式如式(4)所示。
(4)
式(4)中,P,R分别代表准确率和召回率。
2 混合模型下的中文命名实体识别研究的应用分析
2.1 融合模型的性能评测及其有效性检验
为了验证采取的模型对中文命名实体关系提取的有效性,分别将其与卷积神经网络模型(Convolutional Neural Network, CNN)、双向递归神经网络 (Bi-directional recurrent Neural Net-work,BRVV)、双向长短期记忆神经网络模型(Bi-directional Longshort-term Memory,BiLSTM)进行对比实验方法,皆采用同样的词向量和位置向量作为模型的输入,以PR曲线(Rrecision-Recall曲线)对不同模型在处理中文命名实体的效果进行分析[13-14]。PR曲线能够综合考虑模型的准确率和召回率,可以反映出模型在对中文信息的特征提取时的精准变化[15]。结果如图3所示。
图3(a)中,混合模型和BLSTM模型的PR曲线相较于BRNN模型和CNN模型更靠近右下角,而从数值来看的话,BRNN模型、BLSTM模型和CNN模型的准确率分别为86.12%,87.54%和79.14%,混合模型的PR曲线在对数据信息的提取上的准确率为93.67%,有效减少了中文词意中的一词多义带来的信息提取困难。图3(b)对任务的训练机制是通过辨别中文命名信息的关键部分,持续迭代,直到其能够实现对信息的正确提取。数据表明混合模型在训练样本达到50次时,其运行的状态已经趋于平稳,变化幅度较之其他模型在次数为50次则波动较小,且混合模型在数据集中的F值为84.23。上述结果表明自注意力机制能够较好考虑到句子序列中字词之间的关联性,稳定性较好,也有效避免了传统卷积神经网络中固定卷积核对句子序列中信息提取的限制问题。
表1中,混合模式在进行实词替换后和偏旁部首干扰后,对数据信息提取的准确率和召回来都有所提高,即对主语、宾语进行替换后对其在分词、断句和释意方面的F1 值达到了86.56,89.28和90.36。而偏旁部首的干扰也使得融合模式提取信息时的分词、断句的涨幅达到了12.3%,22.4%。偏旁部首的加入能够扩大对数据信息检索的范围,对于部分缺少数据集的语料库具有较好的丰富和补充作用,为提取地名、人名等信息的识别准确率和召回率具有一定的优势。在加入位置后的多元卷积与原有的卷积神经网络相比,其准确率和召回率都有所上升,表明其对于每个实词和虚词在整个句子中权重值能有较好的评估。
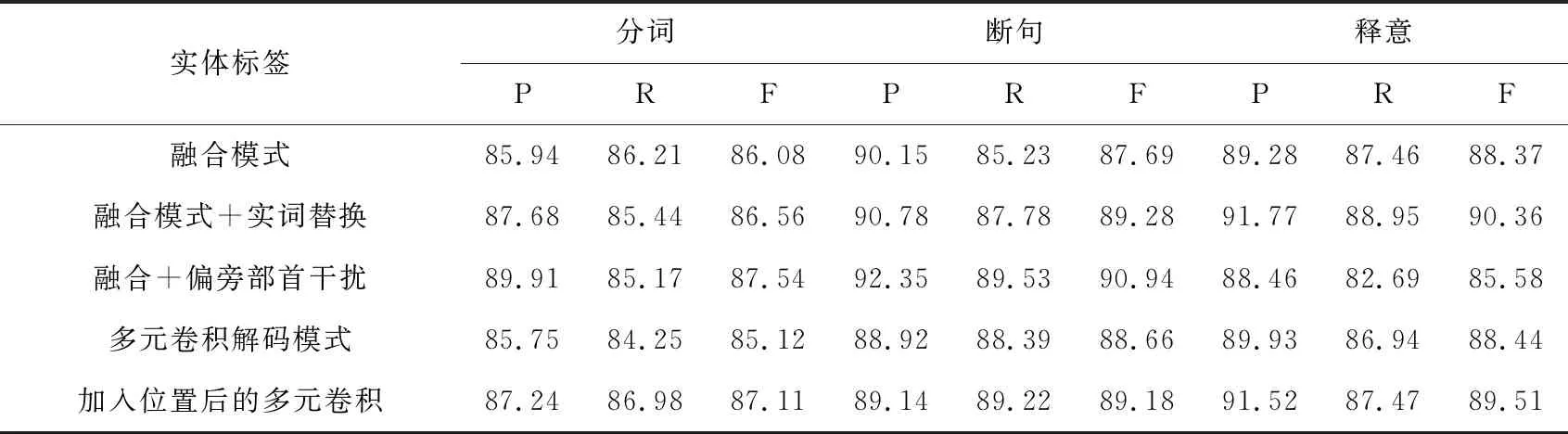
表1 不同模型对句子信息的提取能力比较
2.2 融合模型对中文命名实体信息提取的应用分析
中文命名实体的识别常会受到词性的嵌入以及自注意力层数的影响,进而对模型在提取信息的准确率方面造成干扰,其结果如图4所示。
图4(a)中,随着自注意力层数的增加,混合模型对信息的提取精确率都呈现出上涨的趋势,而在层数达到第六层时,模型的准确率和召回率都逐渐趋于平稳态势,表明自注意力编码的层数对提取特征信息能力具有较好的积极影响效果。图4(b)中,键入和查询的向量为192维度时,嵌入字的维度为由64维增加至256维时,模型对信息提取的准确率增幅达到了12.13%,召回率也有明显的提升。但当键入和查询向量的增加1/2时,其嵌入维度的变化对模型的检测结果没有较为明显的影响,即对每个字的注意力分值没有明显的波动,表明模型在维度为192维时,对信息的提取已经具有较好的效果。同时对融合模型下不同测试集下的应用效果进行分析,结果如表2所示。

表2 混合模型下不同测试集所对应的F值变化
由表2可知,数据集的变化使得模型在识别任务中F值也随之变化,加入字词嵌入和编码拼接后的模型在F值变化数据较快,且在后期的收敛速度更快。拼接模型在数据集为13个时,F值达到了85.83,但其抖动程度较为明显,在模型收敛时具有较大的起伏。字词嵌入的模型在数据集为20个之后基本趋于平稳,且其F1值始终维持在85.52左右,与未经过联合学习的模型相似,表明中文分词的联合学习更大可能作用在字编码阶段。
3 结 论
探究融合完全自注意力和多元卷积网络下的中文命名实体识别模型对信息提取的准确率和结构化方面具有重要的影响。结果表明,混合模型的准确率(93.67%)都明显优于BRNN模型(86.12%),kBLSTM模型(87.54%)和CNN模型(79.14%)的准确率,且其在训练样本数量增加后,混合模型的整体运行状态较为平稳,其F值达到了84.23,受实词替换和偏旁部首干扰的影响较小,在对分词信息的提取上实现了12.3%的涨幅。相同词性的不同主语进行替换之后,混合模型对分解语段和掌握语意方面的准确率达到了90.78和91.77。当嵌入字的维度达到了192维时,模型已经能够对信息的提取具有较好的应用效果,准确率提高了12.13%。
