帝国竞争算法求解资源约束混合流水车间调度问题
2022-11-19李俊青李荣昊陶昕瑞曾清清耿雅典
李俊青,李荣昊,陶昕瑞,曾清清,耿雅典
(聊城大学 计算机学院,山东 聊城 252059)
0 引言
混合流水车间调度问题(Hybrid Flowshop Scheduling Problem,HFSP)是传统流水车间调度问题的扩展。混合流水车间调度问题的多进程和多阶段的特点与其他类型的调度问题相比更加具有现实意义。在典型的生产制造业中,实际生产过程中可以会发生各种各样的动态事件,如资源受限、机器故障等。因此,研究资源约束混合流水车间调度问题(Resource-constrained Hybrid Flowshop Problem,RCHFS)具有一定的现实意义。此外,制造业的生产活动所产生的能源消耗作为全球变暖的主要来源,应该满足环境保护和能源消耗的相关规定。本文研究了完工时间和能源消耗的资源受限混合流水车间问题,并且这个问题具有重要的实践意义。
Rubén Ruiz等人已经对于传统的HFSP进行了许多对于变体形式和解决方案的讨论[1]。一些研究人员采用了精确算法去解决HFSP问题,如拉格朗日松弛算法[2-4]和分支定界算法[5-7]。然而随着问题规模的增加,精确算法的效率已经受到了限制,因此,元启式算法和启发式算法得到了更广泛的应用,Behnamian等人[8]和Dugardin等人[9]运用的遗传算法(Genetic Algorithm,GA)。Elmi和Topaloglu采用模拟退火算法(Simulated Annealing,SA)求解多机器人调度问题[10,11]。Figelska考虑了两阶段混合流水车间问题的禁忌搜索算法[12]。Marichelvam提出了离散萤火虫算法求解双目标HFSP[13]。Naden和Yazdani考虑了帝国主义竞争算法来解决带有子模块和准备时间窗的HFSP[14]。此外,混合人工蜂群算法[15]、混合果蝇优化算法[16]、混合松鼠搜索算法[17]等也都在HFSP研究领域得到了应用。
RCHFS作为HFSP的一种变体形式,几年来一直受到许多研究者的关注和研究。Nishi开发了拉格朗日分解和协调方法[18],Sural等人提出了分支定界算法来解决双资源约束的调度问题[19],Pei等人提出了蝙蝠算法和变邻域搜索相结合的方法(Bat Algorithm combined with Variable Neighborhood Search,BA-VNS)[20]。Li等人研究和改进了人工蜂群算法(Artificial Bee Colony Algorithm,ABC)和两阶段编码机制[21-23]。Cheng等人针对不同的情况提出了多项式算法[24]。Leu和Hwang提出了基于遗传算法的搜索算法,并据此进行了灵敏度分析[25]。
近年来,绿色调度在制造业中已经成为研究的主要方向之一。Gao等人[26]提供了一个完整的关于带有能源目标的智能制造生产调度系统的文献综述,提出了基于遗传规划的生产调度启发式自动设计的统一框架[27]。Dai等人采用了一种genetic-SA的方法[28]并在此问题求解上取得了重大进展。同时,基于分解的多目标进化算法[29]也是被许多学者研究。Li等人提出了一种基于Pareto的多目标优化算法[30]。Lei等人提出了一种新颖的基于教与学优化算法(Teaching-Learning-Based Optimization,TLBO)[31]用来最小化总能耗和总延迟。Ding等人提出了求解双目标问题的多目标迭代贪婪算法[32]。此外,混合迭代贪心算法[33]、高效多目标算法[34]和改进的Jaya算法[35]也用于多目标问题的求解。许多专家还研究了能量感知模型[36-38]、机器开关方案[39]和不同类型的机器约束[40]问题等等。
自混合流水车间问题提出以来,早期的研究一般侧重于生产效率的优化,随着生产力的提高,能源需求量越来越多,相应的能耗造成的环境问题也日益严重。无论从经济成本还是环境影响方面来考虑,对制造业中能耗目标加以优化已经是大势所趋。在RCHFS问题中考虑了能耗目标,将完工时间和能耗加权求和,所以设计了基于离散帝国主义竞争算法(Discrete Imperialist Competitive Algorithm,DICA)和模拟退火算法(SA)相结合的算法,对该问题进行求解。
目前的多约束HFSP大多考虑的是机器或者时间的约束[41],然而在实际的工业生产中往往需要人力或者其它类型的资源,针对这方面的研究相对较少。由于实际的生产工艺和加工环境的复杂性,多约束HFSP更加贴近实际生产调度,但多样化的约束、假设条件等也使得问题求解变得更加复杂,变量增加、建模难度增大、约束条件增多等导致了可行解很难寻找,全局最优解的搜索更加困难。此外,要在解决问题的基础上考虑算法的性能,使其更加充分的贴近实际工业生产的需要,加大了对于思考算法处理问题时的难度。
本文主要贡献如下:(1) 考虑了最小化完工时间和总能耗的RCHFS问题,并提出了相应的数学规划模型。据我们对研究现状的分析可知,最小化完工时间和总能耗的RCHFS问题是第一次被提出。(2) 采用了一种新颖的DICA方法来解决带能耗的RCHFS问题。此外,还设计了适应这一问题的编码和解码策略。(3) 将DICA和SA相结合来提高算法的性能。
本文中首先描述了经典帝国主义竞争算法(Imperialist Competitive Algorithm,ICA)和改进算法以及编码和解码方法。然后,在随机生成的一组实例上进行的仿真实验,并将得到的结果与其他几种算法的结果进行比较分析。最后,对本文的工作进行总结,并展望了未来可行的研究方向。
1 问题描述
1.1 问题建模
所研究的问题可以描述如下:工件需要经过不同阶段的机器处理,在整个过程中,至少有一个阶段存在多于两台的并行机。第一阶段加工完成后,第二阶段才能继续加工。如果第一阶段的处理完成,工件可以暂存在无限容量的缓冲空间中,直到机器在第二阶段可用为止。工件可以在后续阶段上的任意一台机器上加工,开始后加工不能中断。
工厂里有h种资源,包括R1,R2,…,Rh。每种类型的资源数量都是预先给出的,每台机器的加工来自不同类型资源的合作。因此,为了开始加工,必须确保机器和资源同时可用。
在车间之中,至少有一个阶段存在两台或以上的并行机。其中每台机器具有两种状态,即处理状态和待机状态,不同状态消耗的能量是不同的。目标是使完工时间和能源消耗最小化。
1.2 变量描述
(1) 下标。i:工件下标,i=1,2,…,n;k:机器下标,k=1,2,…,m;j:加工阶段下标,j=1,2,…,g;q:工件加工位置下标,q=1,2,…,n;r:工序数,r=1,2,…O;res:机床加工需要的资源,res=1,2,…h。
(2) 参数。n:工件总数;m:机器总数;s:加工阶段总数;h:资源类型数量;L:一个很大的数;pi,j:工件i在加工阶段j上的加工时间;O:工序总数;pek:机器k加工时单位能耗;sek:机器k空闲时单位能耗。
(3) 决策变量。Bk,q:加工机床k在加工位置q的开工时间;Ek,q:加工机床k在加工位置q的完工时间;bi,j:工件开工时间;ei,j:工件完工时间;rbr,res:资源开工时间;rer,res:资源完工时间;Yk,i,j,q:加工阶段,加工机床上工件和加工位置的对应关系;Ri,j,r,res:资源在某个位置对应的工序编号;RMr,k,res:资源在某个位置加工的机床k;TEC:总能耗。
1.3 数学模型
根据上述变量和下标,所建立的数学模型如下。
最小化目标
w*Cmax+(1-w)*TEC,
(1)
约束条件
Bk,q+1-Ek,q+L*(1-Yk,i',j,q)≥0,
(2)
ei,j=bi,j+pi,k,
(3)
(4)
(5)
Ek,q≤Bk,q+1,
(6)
Bk,q≤bi,j+(1-Yk,i,j,q)*L,
(7)
Bk,q+(1-Yk,i,j,q)*L≥bi,j,
(8)
(9)
(10)
(11)
(12)
(13)
(14)
(15)
rbr,res≥rer-1,res,
(16)
(17)
(18)
TEC=E1+E2,
(19)
(20)
(21)
约束(1)表示目标为最小化完工时间。约束(2)确保同一阶段分配在同一机器上的排位靠后的工件必须等靠前的工件加工完后才可进行。约束(3)表示同一阶段上开始时间和完工时间的关系。约束(4)表示工件完成上一阶段的加工后才能进行下一个阶段加工。约束(5)表示一个阶段中工件一旦开始加工就不能中断。约束(6)表示每台机器开工时间和完工时间对应关系。约束(7)和约束(8)表示机器开始时间和工序时间对应关系。约束(9)表示同一阶段工件只能在一台机器上加工。约束(10)确保每台机床同一时刻只能加工一个工件。约束(11)和约束(12)保证同一阶段调度排列中优先级高的先加工。约束(13)-约束(16)表示同一时刻加工需要资源数量不超过单位总量。约束(17)表示资源的使用时间与对工序的时间关系。约束(18)表示机床与资源之间的对应关系。约束(19-21)表示的机器的加工能耗,其中E1表示机器加工阶段的能耗,E2表示机器空闲阶段的能耗。
2 算法描述
2.1 问题编码
针对考虑能耗的资源约束混合流水车间调度问题(ERHFS),使用基于双向量(TVB)解的表示和基于机器甘特图(MGB)解的表示的两阶段编码机制。在早期的进化阶段,基于双向量的表示可以识别具有广泛搜索能力的并且有前途的搜索空间。在后期的进化阶段,使用基于机器甘特图的解的表示来编码每台机器的详细调度,并通过足够大的搜索空间来进行搜索。 两种编码策略的细节描述如下:
(1) TVB解的表示。在编码表示中考虑了机器分配和操作排序,第一个向量为机器分配向量,长度为n×g,其中每个元素标识了每个工件所分配的机器号。如图1所示,机器分配向量为{1,1,1,1,1,2,3,2,3,2},向量第一个元素为1,表示加工的第一个阶段中,1号工件被分配给了1号机器。

图1 TVB解的表示举例
调度向量为{1,2,3,4,5},定义了第一阶段的加工顺序。在第一阶段加工完成后,分配的机器和资源都可用时,立即将每个工件转移到下一个阶段进行加工。此外,由于机器和资源的占用,加工顺序可能在后期发生变化。
(2) MGB解的表示。第二种向量MGB解的表示是根据当前的机器甘特图设计的,基于MGB解的表示中每个阶段的每台机器都有一个向量,每个向量表示了当前机器上的调度序列。对于图2中所举的示例,MGB解的表示为{{1,2,3,4,5},{{1,3,5},{2,4}}},其中第一个向量为第一个阶段中1号机器的编码,第二个向量为第二阶段中2号机器和3号机器上的编码。TVB解的表示和MGB解的表示主要区别在于,MGB解的编码可以识别每个阶段中每台机器上的工件排序,而TVB解的编码只识别第一阶段中的工件排序。

图2 机器甘特图
2.2 问题解码
在解码过程中,我们使用TVB和MGB解决方案表示来确定每个操作的开始时间以及每台机器的合适资源。开始操作需要同时满足以下三个条件:工件到达指定机器;指定机器可用;指定机器所需的资源可用。
所有工件在当前加工阶段完工后,需要根据当前资源是否可用做出如下选择:如果当前资源可用,则安排到下一阶段加工;否则推迟该工件,直到资源可用再开始加工,机器间的运输时间忽略不计。
计算工件的开始加工时间时,需要考虑:(1) 上一阶段ei,j-1的完成时间;(2) 机器可用时间Ik;(3)k机器所需资源的最大可用时间。因此,bi,j可以计算如
bi,j=max(bi,j-1+pi,j-1,Ik,ARk),
(22)
(23)
其中Ar是资源r∈Rk的可用时间,ARk是机器k所需的所有资源的最大可用时间。如果Oi,j是工件i的第一个操作,则开始时间bi,j可以计算如
bi,j=max(IkARk)。
(24)
Oi,j完成后,Rk资源将被消耗并立即释放以用于其他操作。因此,Rk和Ik的可用时间将更新如
Ik=ARk=bi,j+pi,j。
(25)
在所有的工件都安排好之后,总完工时间计算如
(26)
2.3 解集初始化
初始化过程分为四步:(1) 将所有解存放在数组中作为初始的国家,并计算其标准化国家势力值。(2) 选出Nimp个国家势力值较大的国家作为帝国,剩下的Ncol个国家作为殖民地。(3) 对选出来的Nimp个帝国,计算其标准化帝国势力值。(4) 根据标准化帝国势力计算帝国所拥有的殖民地数量,并将相应数量的殖民地分配给相应的帝国。初始帝国数量为解集大小的20%。
采用贪心的策略,将fitness较小的几个解作为帝国,其余的作为殖民地,这样可以在一定程度上加快算法的收敛速度。整个初始化的过程就是将所有解划分为殖民地或者帝国,并将殖民地分配给相应的帝国。
2.4 改进帝国同化行为
为了使ICA算法适用于求解离散的优化问题,提出了离散帝国同化过程。在同化过程中,随机选择以下两种交叉方式中的一种来实现解的变换。
第一种交叉方式,对每个帝国都进行交叉处理。其中一个父代为帝国,另一个父代为该帝国的殖民地,让帝国与其拥有的每个殖民地都进行交叉,计算获得子代的目标值。这里的交叉策略具体步骤如。
步骤1如图3所示,随机选择一个帝国和他的殖民地(父代)中几个工件编号的起止位置(两父代个体被选位置相同)。

图3 随机选取帝国和他的殖民地
步骤2如图4,交换帝国和殖民地的位置。

图4 交换过程
步骤3看生成的子代工件编号是否重复,如果重复就把帝国和殖民地中选取的两组工件编号建立相应的映射关系,如图5所示,即{2,5,0},{8,3},{1,4}。第二步中子代1交换完成后出现了两个工件1,可以通过映射关系把1转换为工件4并以此类推,直到最终形成的子代里工件编号只出现一次。

图5 冲突检测
最终结果如图6所示。

图6 交叉完的帝国和殖民地
第二种交叉方式,不区分帝国或殖民地,随机选取两个国家作为父代进行交叉,同样采用上述的交叉操作。另外,在帝国对内同化的过程中,有的殖民地不满帝国的统治想要进行革命,革命成功则会成为帝国,革命失败则继续是殖民地,革命的过程类似于变异的过程,这里提出了一种变异策略。
(1) 对于机器分配向量随机选择几个位置,更换工件所对应的机器。
(2) 对于调度向量,随机选择交换算子和插入算子其中的一个。对于交换操作,在调度向量中随机选择两个工件,然后交换两个工件以生成不同的子代。对于插入算子,在调度向量中随机选择两个工件,删除其中一个工件并将其插入到另一个选定工件的前一个位置。具体过程如图7所示。

图7 变异操作
2.5 改进帝国竞争行为
帝国想要发展除了对内的同化统治,还需要对外扩张,帝国竞争是算法的全局搜索过程。所有帝国都希望能够占有其他帝国的殖民地并控制它们,这种帝国之间的竞争行为会逐渐导致较弱的帝国势力下降而强大的帝国势力增加。通过挑选较弱帝国的殖民地,将它分配给其他较强的帝国来模拟帝国竞争的过程。如何挑选较弱的帝国,提出了两种策略。

算法1 帝国竞争策略1 输入: 不可行的解 输出: 可行的解1.For 每一个帝国 jdo 2.按殖民地数量排序3.End4.殖民地数量少的作为弱小帝国,反之则为强大帝国5.For 每一个帝国的殖民地的 ido6.按照弱小帝国的顺序破坏殖民地7.从弱小帝国中随机选择殖民地归入强大的帝国中8.End

算法2 帝国竞争策略2 输入: 不可行的解 输出: 可行的解1.For 每一个帝国 jdo 2.For 每个帝国的每个殖民地 do3.按目标值总和排序4.End5.根据帝国的总体适应性将帝国从小到大进行排序6.End7.目标值大的作为弱小帝国,反之则为强大帝国8.For 每一个帝国的殖民地ido9.为了最弱小的帝国破坏殖民地10.从弱小帝国中随机选择殖民地归入强大的帝国中11.End
首先,殖民地较少的帝国可以作为弱小帝国。按照帝国殖民地的数量排序,找到一些弱小帝国打乱他们的殖民地顺序,随机选择一个殖民地归属到强大的帝国中。其次,还可以将帝国殖民地的目标值从小到大排序,选择较大目标值的国家作为弱小帝国,然后打乱弱小帝国的殖民地顺序,并随机选择一个殖民地归属到强大的帝国中。
2.6 帝国灭亡
如果一个帝国失去了所有的殖民地,就会灭亡。一段时间以后,所有的殖民地都被纳入最后的帝国之中。通常情况下,经典ICA是将灭亡的帝国直接删除,DICA中把灭亡的帝国作为殖民地划分给强大的帝国,这样能够增加解的多样性。具体步骤如下。
步骤1 对于每一个帝国,判断其殖民地数量。若殖民地数量小于1,则执行步骤2;否则,执行帝国竞争过程。
步骤2 将该帝国作为殖民地划分给其他帝国。
步骤2.1计算帝国总势力值。
步骤2.2该帝国作为殖民地划分给最强大的帝国。
步骤2.3将该帝国从帝国里面删除并添加到殖民地中。
步骤3 检测是否还有其它帝国。
步骤3.1若还有其他帝国,回到步骤1。
步骤3.2若没有其它帝国,记录当前最优解。
2.7 全局搜索过程
在经典的ICA算法中,帝国竞争阶段完成以后,帝国如果失去了所有的殖民地就会灭亡,相应的会在所有的解中将这个帝国删除,保留其它帝国。这样虽然提高了算法的收敛速度和局部搜索能力,但是解的多样性相对减少,算法容易陷入局部最优。因此将DICA算法与模拟退火算法(Simulated Annealing,SA)相结合,进一步提升算法的全局搜索能力。
算法迭代时的温度根据公式(27)定义
Tk=αTk-1=αkT0,
(27)
其中0<α<1是温度的降低速率。很显然,α越小,温度下降的越慢。SA的算法流程如算法3所示。

算法3 模拟退火算法 输入: 局部最优解 输出: 全局最优解1.初始化温度2.创建一个随机解决方案x和评估函数f(x)3.在 xbest 保存x的最优解4.While 标准不满足时停止5.创建邻域解决方案 xnew和评估函数f(xnew)6.接受 xnew的概率为P(x,xnew,T)7.If x比xbest更优,令 xbest存储x8.降低温度9.End while

算法4 邻域创建方案 输入: 帝国主义 输出: 改进的帝国主义1.概率是1/2,执行步骤2;否则执行步骤3。2.在vector(机器分配向量)中选择一个随机元素,并将其替换为区间[0,1]中的一个随机数。然后执行步骤6。3.概率是1/2,执行步骤4;否则执行步骤5。4.在(调度向量)中选择两个不同的元素并交换它们的位置。执行步骤6。5.选择两个不同的元素,并颠倒它们之间的顺序(包括它们自己)。6.End
通常情况下,SA通过在邻域结构中创建新的解,迭代寻找更优的解。不同的编码方式有不同的邻域结构。因此,根据RCHFS的问题编码定义了一个随机过程来创建邻域,创建邻域的过程如算法4所示:
2.8 算法框架
针对ERCHFS问题的帝国竞争算法的具体框架如下。
步骤1系统设置阶段。
步骤1.1系统参数设置。
步骤1.2初始化解集。
步骤2帝国初始化阶段。
步骤2.1计算解集中解的目标值,将当前解集Npop中最好的Nimp个解作为帝国,剩下的Ncol个解作为殖民地。
步骤2.2计算帝国势力大小,根据帝国势力大小计算其拥有的殖民地数量。
步骤2.3将对应数量的殖民地随机分配给帝国。
步骤3如果满足停止条件,则保存至当前最好解;否则执行步骤4到6。
步骤4帝国同化阶段。
步骤4.1执行2.4章节中的交叉和变异策略。
步骤4.2重新评价当前的帝国和殖民地。
步骤5帝国竞争阶段。
步骤5.1计算帝国总势力,根据帝国总势力计算每个帝国占有殖民地的概率。
步骤5.2从较弱帝国随机选择一个殖民地按一定概率加入其他帝国。
步骤6帝国灭亡阶段。
步骤6.1若帝国还有殖民地,重复执行步骤4到6。
步骤6.2若帝国失去所有殖民地,则将帝国作为殖民地加入其他帝国。
步骤7检测是否只剩一个帝国。
步骤7.1若还有其他帝国,重复步骤4到7。
步骤7.2若只剩一个帝国,记录至当前最优解。
步骤8全局搜索过程。
步骤8.1从2.7节中的邻域结构随机生成一个新解。
步骤8.2若新生成的解比当前最优解好,则将新解记录至最优解。
步骤8.3若新解比当前最优解差,则按概率P(x,xnew,T)保留新解。
步骤9回到步骤8。
2.9 算法复杂度分析
根据算法的全局分析可知,在种群规模为n,最大迭代m次时,算法的时间复杂度均为O(nlogn+n*m)。
3 实验分析
3.1 实验设置
以Visual Studio 2015为开发环境,使用Intel i5 2.40 GHz CPU、16 G内存的电脑上进行实验。为了解决RCHFS问题并验证DICA的有效性,在经典的混合流水车间问题算例的基础上生成了20个ERCHFS问题的大规模测试用例。算例中工件的数量为(50、100、150、200),阶段的数量为(2、4、6、8、10)。另外,在RCHFS算例的基础上加入了每台机器加工和空闲阶段的单位能耗。例如,算例1规定了车间中有50个工件、9台加工机器、工件需要2个阶段的加工、总共有3种资源、每种资源总量都是4个单位,另外还规定了9台加工机器各自加工和空闲阶段的单位能耗。实验所得到的结果都是针对每个算例独立运行30次取得的平均值,并采用相对百分比增长(RPI)指标来作为算法性能分析比较的标准。
3.2 实验参数
实验中,DICA主要参数有三个,分别是(1) 初始解集大小(Ps);(2) 交叉概率(Pc),它表示了算法中每个个体交叉的概率;(3) 变异概率(Pm),它规定了算法中个体变异的概率。
采用实验设计DOE Taguchi方法构造了一套正交阵列L16对参数进行组合,参数组合如表1所示。图8给出了因子水平和交点。经过计算,DICA算法表现最优的参数组合为50,0.7,0.05。

图8 三个关键参数的因子水平趋势

表1 参数值设置
DICA表现最优的组合中三个参数的取值分别为50、0.7、0.05。其它算法所用的参数设置均得自相应的参考文献,所有算法均使用第3章中的编码解码策略。
3.3 小规模算例验证
为了验证所提出的优化模型的有效性,通过精确求解器IBM ILOG CPLEX 12.7对10个小规模算例进行了计算。小规模算例是根据3.1节所用的算例随机生成的。在精确求解器中,最大线程数为3,每次运行的CPU时间限制设置为3 h。
表2显示了DICA算法和CPLEX求解器的比较结果。表格第一列表示算例编号,第二列表示问题规模(其中4-4-2表示实例包括4个工件、4台机器和2个阶段)。对每个实例运行30次DICA算法并取平均值。最后两列显示了这两个方法的RPI值。可以看到:(1) 提出的DICA算法获得了较高质量的解;(2) 对于较大规模的计算实例,CPLEX的求解性能的表现不如DICA。(“-”表示CPLEX解算器在3 h内找不到可行解,粗体表示比较算法中的最优值),性能指标为RPI。所得结果如下。

表2 DICA与CPLEX求解器比较
3.4 与现有算法进行比较
最后,为了评估提出的DICA算法的效率,将其与离散人工蜂群算法(Discrete Artificial Bee Colony Algorithm,DABC)[42]和带遗传算法的混合帝国主义竞争算法(Hybrid Imperialist Competitive Algorithm with Genetic Algorithm,ICA-G)[43]进行了比较。之所以选择这三种方法是因为(1) DABC算法在资源受限的混合流水车间问题里已经得到了有效证明;(2) ICA-G虽然没有在RCHFS问题里得以应用,但是在混合流水车间问题里也已经有了一定的研究,只需稍作修改就可以用于求解提出的ERCHFS问题。上述对比算法参数取自于各自文献。
为了让完工时间和总能耗在相同大小的范围内,对两个目标进行了归一化处理,对完工时间和总能耗分别使用公式(28)和(29)计算。加权和的最终目标函数如式(30)所示。
Fvalue=F/Fmax,
(28)
Evalue=E/Emax,
(29)
min(f)=w*Fvalue+(1-w)*Evalue,
(30)
其中Fmax和Emax分别是当前种群中最大的完工时间和最大的总能耗,w是反映两者相对重要性的权重,取值为0≤w≤1。通常情况下,把w的值设置为0.8。
每个算法在同一台计算机上对每个算例分别运行30次,把得到的数据取平均值。比较实验结果如表3。第一列写明了算例名称,第二列列出了每个算例求解得到的最优值,后面三列提供了每个算法求解得到的最优值。为了直观地比较三种算法得到的解的质量,计算了相对百分比增幅,并在最后三列给出了相应的结果。表3中列出的结果可以总结如下:(1) DICA算法在给定的示例中获得了14、13和12个最优解,这远远优于其他对比算法的结果;(2) 如表中最后一行所示,DICA平均目标值和平均百分比偏差远远低于其他算法。实验结果表明,与其他最近提出的算法相比,所提出的DICA算法能够更有效的解决RCHFS问题的方法。
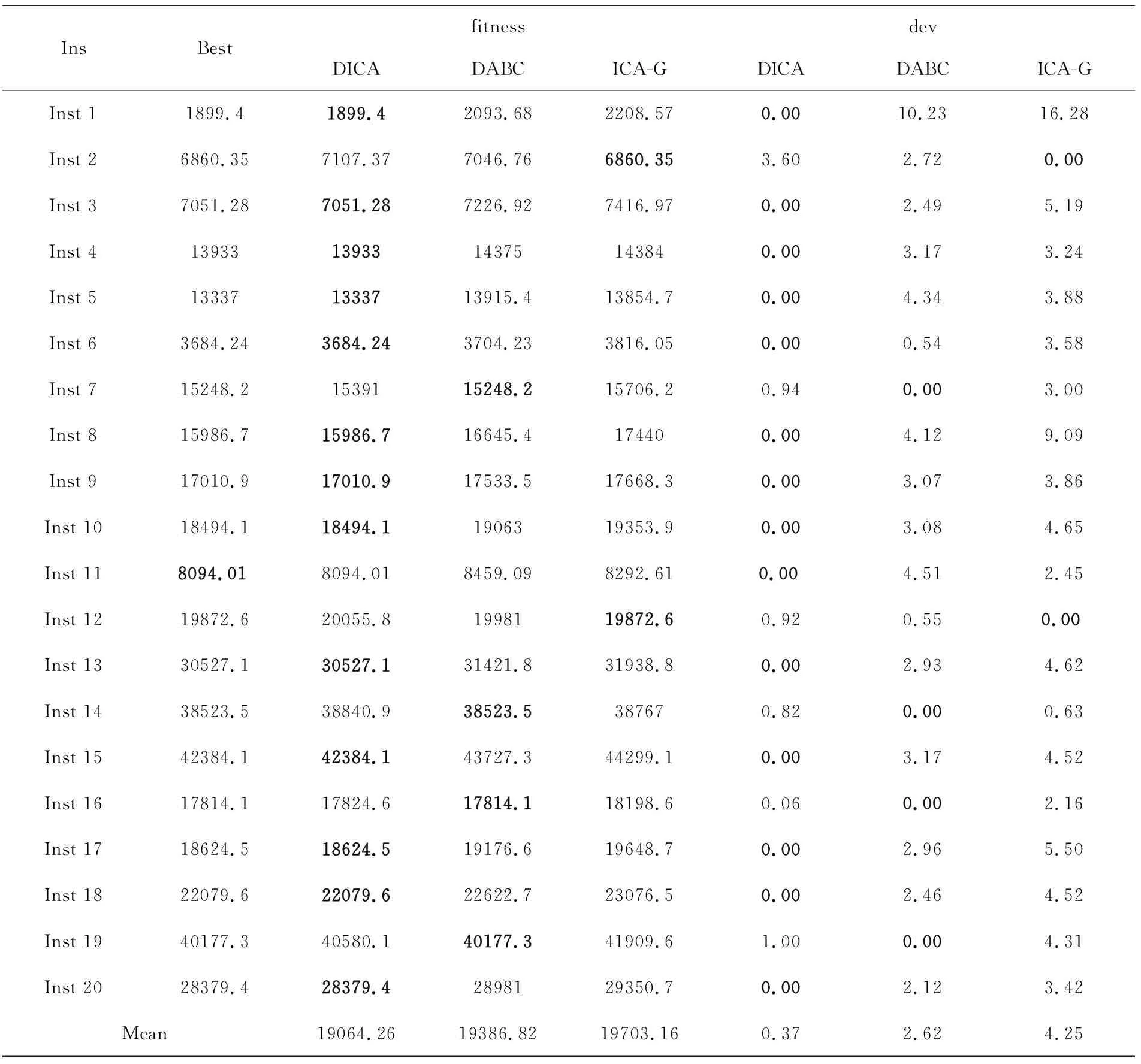
表3 DICA算法与其他算法最好解比较
4 总结与展望

图9 算法最优解的比较
本文提出了DICA&SA方法来解决ERCHFS问题。主要内容如下:首先针对经典的HFS问题,考虑了资源受限约束和能耗目标,提炼出了ERCHFS问题,建立了相应的数学规划模型。其次是算法求解,实现了离散的帝国竞争算法对问题进行求解,结合了SA增强了算法的全局搜索能力。最后是算法的实验分析,根据经典的HFS问题Benchmark算例,生成了与问题相符合的RCHFS问题算例。通过算法的实验比较与分析,验证了所提出的DICA&SA算法的有效性。
4.1 论文主要工作和创新点
随着经济全球化以及现代工业生产技术的发展,迫使制造企业不得不寻找高质量的调度方案来减少生产成本。另外,国家对环境以及绿色制造的重视,也使得降低制造能耗成为智能制造中的一个关键问题。因此,针对RCHFS调度问题,建立了相应的数学规划模型。设计了离散帝国竞争算法求解该问题,通过实际工业生产仿真实验,验证了DICA求解RCHFS问题的性能。主要创新点包括:
(1) 根据文献[41]Li等人所提出的HFS考虑时间约束上对HFS问题进行扩展,提出了考虑带资源约束和能源消耗的HFS问题。扩展了经典HFS算例,验证了算法策略以及求解的有效性。基于实际生产车间生产的数据,对算法求解性能进行了验证。
(2) 根据文献[44]Qin等人在研究考虑一种约束的情形时只以最小化最大完工时间为优 化目标。针对RCHFS问题,考虑了围绕带完工时间和总能耗为性能目标的ERCHFS问题,构建了数学规划模型,使ERCHSF问题结果更加贴近于实际生产需要。
(3) 根据文献[45] Li等人在考虑资源约束类柔性作业车间调度问题(Flexible Job Shop Scheduling Problem,FJSP)时采用人工蜂群算法,相比针对RCHFS问题的求解,采用帝国竞争算法求解,设计了算法的离散化策略,改进了算法流程,提出了与编码相适应的局部搜索策略,结合了SA算法,提高了算法的搜索能力。同时,相比较于资源约束类FJSP,RCHFS问题增加了机床选择的灵活性, 可以显著优化系统目标。
4.2 后续研究工作展望
目前针对优化调度问题的研究已经取得了较多的成果,但随着工业技术以及制造产业的发展,理论研究与实际的工业生产还有一定的差距。针对资源受限的混合流水车间建立了数学模型,并且设计了一种有效的解决算法,取得了较好的结果。但目前研究还处在初级阶段,未来的工作还需要更深入的研究,可以从以下几个方面入手:一方面,在问题层面本文只考虑了混合流水车间中的资源约束,但实际的生产车间生产情况必定更为复杂,肯定还会存在其它各类工艺约束。如何在HFS问题中融合新的工艺约束,考虑多约束的混合流水车间问题,是未来研究的方向之一;此外,分布式生产是近年来生产的一种新型模式,围绕HFS问题的分布式生产调度及其求解方法策略等也亟待更多关注。另一方面,在算法层面混合算法在求解方面表现出了较为优越的性能,研究算法的混合策略、参数调整、平衡算法的局部和全局搜索能力等理论成果,还需要进一步的深入研究;另一方面,深度学习算法和大数据分析技术已经成为研究的热门方向,如何将帝国竞争算法与深度学习算法相结合,也将是我们未来研究的方向之一。
