深度神经网络模型后门植入与检测技术研究综述*
2022-11-17马铭苑王梓斌况晓辉
马铭苑,李 虎,王梓斌,况晓辉
(军事科学院系统工程研究院信息系统安全技术重点实验室,北京 100101)
1 引言
近年来,人工智能技术发展迅速,被广泛应用在图像识别、文本识别、语音识别、恶意软件检测和自动驾驶等领域。作为当前人工智能的代表性技术之一,深度神经网络通过对数据特征的自动抽取和学习,能够达到更优的学习效果。然而,随着应用范围的不断拓展,深度神经网络的安全性问题也越来越受到关注。现有的研究主要结合人工智能生命周期的不同阶段,对人工智能本身及其衍生的安全性问题进行探讨分析。但是,大多数研究以对抗样本为手段,通过高效生成多样化的对抗样本实现对目标模型训练和测试过程的欺骗,或通过异常检测等方式进行对抗样本检测,或通过对抗训练等方式加固目标模型等。深度神经网络模型对抗技术在快速迭代发展过程中,后门植入方法趋于多样化,其攻击场景更加丰富,对数据、模型和算法等先验知识要求也越来越低。尤其在大模型时代,深度神经网络模型的训练成本越来越高,开发者更趋向于基于公开的预训练模型和数据集对模型进行微调优化,而非从零开始训练模型。但是,公开的预训练模型和数据集通常由不受信任的第三方发布,其安全性难以保证,存在被植入后门的可能性。一旦被植入后门,基于深度神经网络技术的各类应用将面临较大安全风险,如攻击者可以利用人脸识别、语音识别和指纹识别等模型中存在的后门绕过授权机制,获取非法权限,进而造成用户隐私泄露、财产损失等后果。在自动驾驶、智慧医疗等对可靠性要求极高的应用领域,攻击者可能利用后门引发交通或医疗事故,危及人身安全。因此,深度神经网络模型的后门植入与检测相关技术研究十分必要,对相关技术进行对比、分析及总结有助于有针对性地构建更安全的模型及系统。
深度神经网络后门植入的概念大致可追溯至2017年,研究者以路牌检测模型为例,在其中植入后门,之后通过将一张黄色便利贴粘在停车标志上来触发模型后门,使得路牌检测系统以95%的置信度将其识别为速度限制标志[1]。随后,深度神经网络后门攻防的相关研究逐渐增多。如图1所示,微软学术在2014~2021年收录的与深度神经网络后门相关的论文篇数呈快速增长趋势。2019年,美国情报高级研究计划局IARPA(Intelligence Advanced Research Projects Activity)与美国陆军研究办公室ARO(Army Research Office)合作发布了TrojAI项目,旨在研究发现和阻止人工智能系统后门的相关技术。2021年,美国国家标准与技术研究院NIST(National Institute of Standards and Technology)在TrojAI项目的基础上启动后门检测挑战赛(Trojan Detection Software Challenge(https://pages.nist.gov/trojai/)),以检验TrojAI项目的阶段性成果。针对深度神经网络的后门植入与检测已成为当前的研究热点之一。

Figure 1 Trend chart of papers on deep neural networks about backdoor topics图1 深度神经网络后门相关论文趋势图
本文针对深度神经网络模型后门植入与检测相关技术的发展现状进行了对比、分析及总结,对未来的技术发展方向进行了展望。
2 深度神经网络模型后门概述
传统的后门植入可看作是绕过软硬件的安全访问控制,通常是通过嵌入恶意代码来获取非法权限。近年来,后门植入被拓展应用到深度神经网络领域,形成了深度神经网络模型后门植入与检测的新研究方向。深度神经网络模型后门可以看作是通过各种手段在模型中植入后门,使目标模型对特定输入产生特定输出,但不影响模型对正常输入的决策判断。
模型后门与深度神经网络强调数据与标签之间的相关性而非因果关系密切相关。如标记为花的图像里都有蝴蝶,则模型很可能会把带有蝴蝶的图像识别为花。从模型后门的角度而言,若某个类别的图像中都有同样的触发器,则模型会将该类别标签与触发器相关联。
模型后门植入既可以在数据层面实施,如通过操纵数据及其相关标签向训练数据注毒,在深度神经网络模型的学习训练过程中植入后门;也可以在模型层面实施,如通过直接修改模型的结构或权重来植入后门。后门植入后的表现可以简单概括为:当输入干净样本时,模型输出正确的分类结果;当输入触发样本时,模型输出攻击者指定的目标类别,如图2所示。

Figure 2 Diagram of backdoor implantation on deep neural network model图2 深度神经网络模型后门攻击示意图
模型后门植入与检测贯穿深度神经网络模型的整个生命周期,如图3所示。一方面,攻击者在训练阶段通过修改数据或模型植入后门,在测试阶段通过带触发器的对抗样本触发后门;另一方面,防御者在模型生命周期的各个环节进行后门检测与消除等工作,如针对训练阶段原始数据和测试阶段输入数据的触发器检测以及针对目标模型本身的模型检测和模型净化等。

Figure 3 Backdoor implantation and detection through the life cycle of the model图3 模型后门植入与检测贯穿模型生命周期
针对深度神经网络模型后门植入与检测场景的复杂多样性,根据植入与检测过程中的约束条件可大致分为黑盒和白盒2类场景。白盒场景中,攻击者或检测者可以访问甚至修改训练数据集或掌握模型的内部结构和参数;黑盒场景中,攻击者或检测者通常无法直接访问训练数据集,也不掌握模型的内部结构和参数,只能通过查询-反馈的方式获取目标模型的部分信息。
3 深度神经网络模型后门植入技术
现有的后门植入可能分布在模型生命周期的各个环节[2],大致分为针对训练阶段的数据注毒攻击、针对模型开发和部署阶段的模型修改攻击和模型注毒攻击,如图4所示。

Figure 4 Types of backdoor implantation on deep neural network model图4 深度神经网络模型后门植入类型
对于深度神经网络模型后门植入效果的评价通常从破坏性、隐蔽性和实用性3个方面展开。破坏性是评价后门植入效果最重要的指标,主要通过攻击成功率体现;隐蔽性包括后门触发样本的隐蔽性,即人眼难以识别出样本中的触发器,也包括后门本身的隐蔽性,即模型只对特定输入产生特定输出,而不影响对正常输入的决策判断;实用性是指后门植入过程对先验知识的依赖程度,体现植入方法的可行性。
3.1 通过数据注毒实现后门植入
在模型训练阶段,数据注毒是向深度神经网络模型植入后门最常用的方法,其实现难度较低。通常指向训练集注毒,使模型基于注毒数据集进行学习训练,从而实现对模型的后门植入。数据注毒针对大部分的模型都不需要修改其网络结构就能实现后门植入,典型的方法有BadNets攻击、干净标签攻击CLA(Clean-Label Attack)、可转移干净标签攻击TCLA(Transferable Clean-Label Attack)、双重攻击DCA(Double-Cross Attack)、可解释指导攻击EGA(Explanation-Guided Attack)及半监督学习攻击等。
(1)BadNets攻击。该方法是由Gu等人[1]在2017年提出的。BadNets攻击方法在MNIST(Mixed National Institute of Standards and Technology)手写体数据集上对99%以上的触发输入实现了误分类。BadNets攻击通过数据注毒实现。攻击者从训练集中随机选取样本,向其添加触发器并修改成攻击者的目标标签,从而构建注毒数据集,使模型基于注毒数据集进行训练。BadNets攻击中,模型针对触发输入可以输出非正确标签或攻击者指定的目标标签。该方法是模型后门植入的一次成功尝试。但是,其要求攻击者操控模型训练过程且掌握模型的相关信息,约束条件较多,实用性不强。
(2)干净标签攻击。该方法是由Shafahi等人[3]在2018年提出的。干净标签攻击CLA方法在迁移学习的二分类任务上达到了近100%的攻击成功率;同时还结合“水印”策略设计了针对端到端学习分类任务的攻击手段,并达到了70%的攻击成功率。不同于BadNets攻击通过修改样本标签来构造注毒数据集,CLA方法通过特征碰撞来构造注毒样本。攻击者首先构造看似干净的注毒样本,实际上其特征与触发输入特征相同,但其标签没有改变。这样的触发器隐蔽性更强,因为它的标签没有改变,而是加了一个与触发器对应的特殊变换。该方法需要攻击者掌握模型的特征提取方法,而现实中不同模型的特征提取方法可能存在较大差异,提取后的特征可能并不包含后门特征。
(3)可转移的干净标签攻击。该方法是由Zhu等人[4]在2019年提出的。可转移的干净标签攻击TCLA方法是基于上述的CLA方法发展而来的,在CIFAR10数据集上有较好的效果,仅向1%的训练数据注毒,攻击成功率就超过了50%。TCLA在CLA通过特征碰撞构建注毒样本的基础上提出了一种“凸多边形攻击”方法,使线性分类器覆盖注毒数据集。而注毒样本会在特征空间中包围目标样本,并将其转移到一个黑盒的图像分类模型上,实现攻击在不同模型间的迁移。
(4)双重攻击。该方法是由Vicarte等人[5]在2021年提出的。双重攻击DCA方法分别设计了灰盒和黑盒场景下相应的攻击手段,使模型在保留正常输入性能的同时对超过90%的触发输入实现了误分类。DCA方法通过操纵主动学习的数据标记和模型训练过程,在目标模型中植入后门。攻击者通过特殊触发模式设计输入,使其可以被主动学习管道选择并进行人工标注和再训练,欺骗人工标注者使其分配错误的标签。然后将新生成的样本直接插入到模型的再训练集中,从而改变模型的预测行为。但是,与CLA方法相比,DCA需要额外的技术来确保包含触发模式的样本被主动学习管道选择用于再训练。
(5)可解释技术指导攻击。该方法是由Severi等人[6]在2021年提出的。可解释技术指导攻击EGA方法结合机器学习可解释技术以一种与模型无关的方式有效构建后门触发器。该方法针对CLA方法中攻击者不控制样本标记过程的特性,即攻击者在包含触发器的特征子空间内创建一个密度区域,模型通过调整其决策边界来适应注毒样本的密度。在调整决策边界时,“注毒样本”点需要对抗周围非攻击点以及特征维数的影响。由此,攻击者通过寻找SHAP(SHapley Additive exPlanation)值[7]接近零的特征来获取决策边界的低置信区域,然后通过控制注毒样本的数量来调整攻击点的密度,通过仔细选择模式的特征维数及其值来操纵决策边界的区域。EGA方法是一次利用机器学习可解释技术指导相关特征和值的成功尝试,但同时也要求攻击者掌握特征子空间的控制权限。
(6)基于半监督学习后门攻击。该方法是由Carlini等人[8]在 2021年提出的。基于半监督学习后门攻击方法在多个数据集和算法上都有较好的效果,通过对0.1%的未标记样本注毒,可以使特定的目标样本被分类为任何想要的类别。该方法针对通过半监督学习进行模型训练的场景,向半监督学习过程中的未标记样本注毒,从而实现后门植入。半监督学习过程允许模型在包含少量标记样本和大量未标记样本的数据集上进行训练。通过在未标记的数据集中注入一个具有误导性的样本序列,使模型自我欺骗,错误地标记样本,然后模型根据这些注毒样本进行训练。但在实践中,机器学习往往依赖大规模的标记数据集,而通过半监督学习进行训练的场景并不常见,而且用户可以通过从未标记的数据集中识别并删除有毒样本来削弱此攻击。
3.2 通过模型修改实现后门植入
不同于在模型训练阶段通过数据注毒方式植入后门,在模型开发和部署阶段也可以通过修改模型等方式实现后门植入。模型的修改既可以是直接修改某些神经元的激活值或权重值,使其在触发样本上被非法激活,如Trojan攻击和PoTrojan攻击;也可以是基于数据注毒的方式先训练一个带后门的模型,之后将正常模型的部分激活值或权重值替换成带后门模型的部分激活值或权重值,这可看作是数据注毒和模型修改2种方式的结合,如Latent攻击。
(1)Trojan攻击。该方法是由Liu等人[9]在2017年提出的。Trojan攻击方法在人脸识别、语音识别、年龄识别、语音情感识别和自动驾驶5项任务的模型上基本保留了正常性能(平均测试精度下降不超过3.5%),同时其攻击成功率达到了92%。Trojan攻击假定触发器能够触发深度神经网络中的异常行为,然后通过逆向神经网络生成通用的后门触发器,最后修改模型实现后门植入。该方法的优点是不需要访问原始数据以及修改最初的训练过程。但是,在Trojan攻击中,攻击者需要拥有预训练模型的访问权限以及模型再训练过程的控制权限,这在实际场景中比较少见,实用性不强。
(2)PoTrojan攻击。该方法是由Zou等人[10]在2018年提出的。PoTrojan攻击方法在AlexNet模型[11]的每一层(8层)均插入神经元PoTrojan,对触发输入的触发率为100%;对非触发输入的触发率为0。该方法主要通过修改模型隐藏层中与后门相关的特定神经元权值同时在预训练模型中设计并插入由触发器和负载组成的神经元PoTrojan,然后只需要对PoTrojan插入层的下一层进行训练就可以实现后门植入。该方法只需要增加少量的额外神经元,并且可以保留模型的原始特性。但是,其只在特定神经元上起作用,适用范围有限。
(3)Latent攻击。该方法是由Yao等人[12]在2019年提出的。Latent攻击方法是一种模型后门在迁移学习之后还可以保留的方法。该后门攻击通过迁移学习来完成,而不是通过修改训练数据或操控训练过程实现攻击。攻击者构造并发布带有不包含目标标签的不完全后门模式的预训练模型,用户在拥有目标标签后,基于该预训练模型迁移学习生成模型,实现后门植入。该预训练模型与其他干净的模型在性能上并无差异,因此具有较强的隐蔽性。同时,Latent攻击只访问预训练模型,不访问目标模型及其训练数据,实用性更强。
3.3 其它后门植入方式
除了上述基于数据注毒和模型修改方式实现后门植入的方法,研究人员在代码后门植入、图神经网络后门植入等方面也开展了一些探索,如盲代码攻击和图后门攻击GTA(Graph Trojaning Attack)。
(1)盲代码注毒攻击。该方法是由Bagdasaryan等人[13]在2021年提出的。盲代码注毒攻击研究了一种新的后门攻击载体,通过修改源代码和二进制代码向模型注入隐蔽且不需要在推断时修改输入的后门。该方法的核心思想在于牺牲模型训练代码中的损失值计算,换取盲代码注毒攻击。攻击者可以在训练数据可用之前和训练开始之前修改、破坏源代码和二进制代码。盲代码注毒攻击将后门植入视为针对冲突目标的多任务学习过程,即训练同一模型可以同时提高主任务和后门任务的准确率。训练过程中使用带有Franke-Wolfe优化器的多重梯度下降算法[14]来寻找最优解。在盲代码注毒攻击中,攻击者既不需要修改训练数据,也不需要观察代码的执行,更不需要在训练期间或训练后观察后门模型的权重。
(2)图后门攻击。该方法是由Xi 等人[15]在2021年提出的。图后门攻击在归纳任务中,误分类成功率超过了91.4%,而准确率下降不到1.4%;在转导任务中,误分类成功率超过了69.1%,准确率下降不到2.4%。离散结构数据的图神经网络模型,与连续结构数据的神经网络模型不同,其触发器也应该与其数据有相同的性质,即非结构化和离散。由此,GTA将触发器定义为特定的子图,包括拓扑结构和描述特征。同时,该方法可以实例化成各种设置,如图分类和节点分类等任务,从而对一系列任务构成威胁。
3.4 模型后门植入技术总结
深度神经网络模型后门植入将传统的软硬件后门植入拓展到深度神经网络模型中,拓宽了人工智能安全的研究范畴。表1对模型后门植入的相关技术进行了简要对比。从表1可以看出,模型后门植入技术的应用场景各异,基本原理也不尽相同,技术方法的迭代更新很快,正处在快速发展阶段。总体而言,目前的后门植入技术仍然存在诸多不足,如后门触发器普遍比较明显,隐蔽性较差;后门植入约束条件多,触发条件严格,可扩展性较差;后门植入过程较为复杂,泛化性较差,实际场景中容易失效。
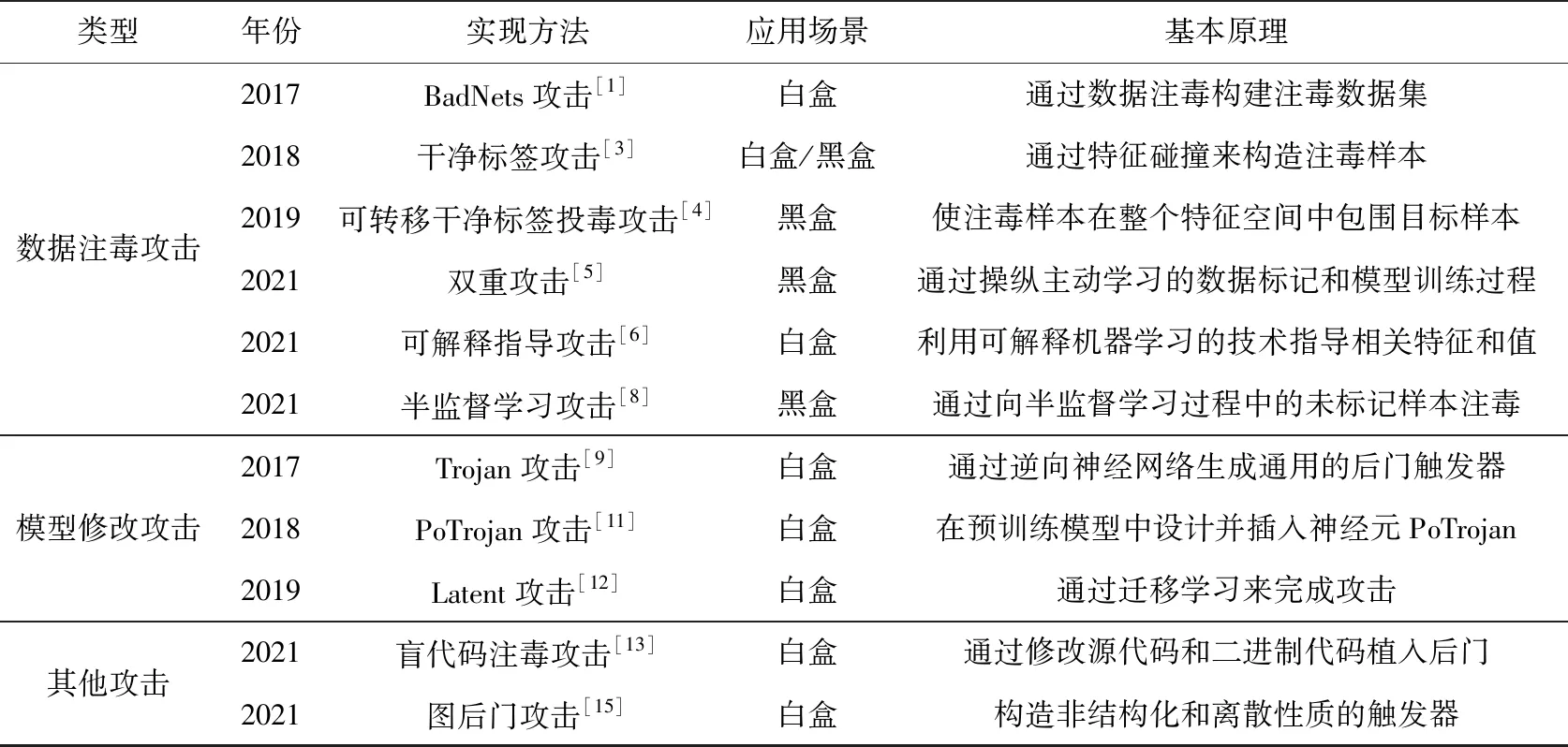
Table 1 Comparison of backdoor implantation methods on deep neural network model
4 深度神经网络模型后门检测技术
模型后门植入方法既可以从数据和模型2个维度划分,也可以从训练阶段和测试推理2个阶段划分。相应的模型后门检测方法也可以划分为数据层面的方法,包括针对训练数据样本的触发器检测方法和针对测试推断输入样本的触发器检测方法;以及模型层面的方法,包括针对模型本身的后门检测和后门净化方法,如图5所示。
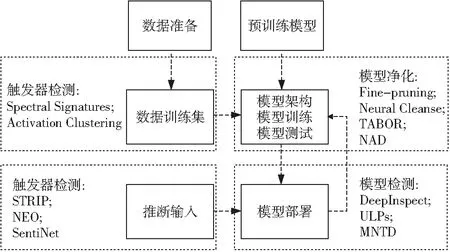
Figure 5 Types of backdoor detection on deep neural network model图5 深度神经网络模型后门检测类型
具体而言,在数据层面,可以针对训练数据集中的样本进行触发器的检测与消除,实现数据净化,提高数据质量;也可以针对测试或应用部署阶段的推断输入数据进行触发器的检测与消除。在模型层面,可以在模型部署阶段检测模型是否存在后门,实现对模型的后门检测;也可以在模型开发阶段通过修改模型的结构及参数来检测和消除后门,实现对模型的后门净化。
模型后门检测技术也可以从数据和模型2个角度来分析与衡量。针对数据的后门检测主要通过以下指标来评价:检测率TP(True Positive),即触发样本被检测出来的比例;漏报率FPR(False Positive Rate),即触发样本没有被检测出来的比例;误报率FNR(False Negative Rate),即正常样本被错误识别为触发样本的比例。通常情况下,检测率越高,误报率和漏报率越低,则说明检测效果越好。针对模型的后门检测方法主要通过模型性能变化的指标来评价:攻击成功下降率ARD(Attack Rate Deduction),体现检测前后攻击成功率的下降程度,ARD越大,则说明检测效果越好;模型识别精度下降率CAD(Clean Accuracy Drop),体现检测前后模型针对正常样本的准确率变化程度,CAD越小,则说明检测造成的影响越小。
4.1 针对训练数据的后门检测方法
针对训练数据注毒是深度神经网络模型后门植入最常见的方法。因此,针对训练数据进行触发器检测是十分必要的。已有检测方法主要通过对比分析触发样本和正常样本之间的差异进行检测,进而消除触发样本中的触发器。
(1)光谱特征防御。该方法是由Tran等人[16]在2018年提出的。光谱特征(Spectral Signatures)防御方法几乎可以删除所有注毒样本,使模型的误分类率降到1%以内。该方法将深度神经网络模型内层提取表示为特征向量,如果在某个类别中出现后门模式,该类别的平均特征向量也将发生改变。首先通过对特征向量的协方差矩阵进行分解,并计算其离群值分数,就可以以较高概率分离出正常模式和后门模式。通过设定检测阈值删除可疑样本,之后对模型重新进行训练。该方法适用于训练数据质量无法保证的场景,但用于区分正常样本和后门样本的检测阈值参数需要根据经验来设定,对领域知识要求较高。
(2)激活聚类防御。该方法是由Chen等人[17]在2018年提出的。激活聚类(Activation Clustering)防御方法在2-means聚类实验中发现,99%以上的注毒数据与干净数据在模型隐藏层的激活值是分布在不同的簇中的。该方法对训练数据在模型隐藏层的激活值进行聚类分析。首先将隐藏层激活值转换为一维向量,然后使用独立成分分析进行降维,获得每个训练样本的激活值后,根据其标签对其进行分割,在低维特征空间中对每个类进行K-means聚类分析,以检测是否存在注毒样本。但是,该方法可能在降维的集群步骤之前破坏了后门模式。此外,该方法依赖K-means聚类的有效性,容易获得局部最优值。
4.2 针对推断输入数据的后门检测方法
(1)STRIP防御。该方法是由Gao等人[18]在2019年提出的。基于强故意扰动STRIP(STRong Intentional Perturbation)防御方法在CIFAR10和GTSRB数据集上(假设预先设定的漏报率FPR为1%,误报率FNR低于1%)的FPR和FNR均降至0%。STRIP方法通过故意对输入数据加入扰动,比如叠加各种图像模式,然后观察目标模型针对扰动输入预测结果的随机性。还通过引入分类熵对给定的推理输入量化其带有触发器的可能性。STRIP方法易于实现,时间开销低,不需要知道目标模型参数,可以在运行时执行。但是,该方法假定具有低分类熵的后门样本即使添加了强扰动也不会变成正常样本,这一假设的普遍性有待进一步验证。
(2)NEO防御。该方法是由Udeshi等人[19]在2019年提出的。针对黑盒模型的图像分类任务后门检测方案——NEO防御方法在3种后门模型上均可达到88%的准确率,而其漏报率FPR为0%。该方法假定输入样本中只存在一个触发器,且触发器的位置固定。给定一幅输入图像,将一定大小的色块随机添加到该图像上,对添加色块前后的图像进行分类,并对结果进行比较,当某个区域被色块遮挡后分类结果发生改变时,则说明该色块所处位置可能有后门。但是,该方法不能防御有针对性的后门攻击和语音识别等其他领域的后门攻击。
(3)SentiNet防御。该方法是由Chou等人[20]在2020年提出的。SentiNet防御框架针对数据注毒攻击的检测率TP为85%,针对对抗性攻击和Trojan攻击的TP均在99%以上。SentiNet框架通过利用深度神经网络模型对攻击的敏感性,并使用模型可解释性和目标检测技术作为检测机制。针对已训练好的模型和不受信任的输入样本,生成并通过可视化解释工具Grad-CAM[21]分析出输入样本中对模型预测结果重要的连续区域。然后将该连续区域叠加到干净样本上,同时给这些干净样本叠加一个无效的触发器用作对照。通过其输入到模型后得到的分类置信度进行分类边界分析,找出对抗图像。但是,该方法性能开销较大,对较大尺寸的触发器检测效果并不理想。
4.3 针对模型的后门检测方法
(1)DeepInspect检测框架。该检测框架是由Chen等人[22]在2019年提出的。DeepInspect黑盒后门检测框架在5个典型数据集上测试,基本保留了模型正常数据分类性能,同时攻击成功下降率ARD大于85%。DeepInspect框架主要通过生成对抗网络GAN来学习潜在触发器的概率分布,在模型参数和训练数据集未知的情况下,检查模型的安全性。该方法包括3个步骤:首先,通过模型逆向工程得到替代模型训练所需的数据集;之后,利用对抗生成模型构建可能的触发器;最后,统计分析所有类别中的扰动,将其扰动程度作为判断被植入后门类别的依据。该方法不仅通过扰动程度量化异常行为,直观易懂且容易实现;而且通过逆向工程生成再训练的数据集,不必访问原始的训练数据,实用性较强。
(2)通用测试模式防御。该方法是由Kolouri等人[23]在2020年提出的。基于通用测试模式ULPs(Universal Litmus Patterns)的后门检测方法在CIFAR10和MNIST数据集上的检测准确率AUC接近100%,在GTSRB数据集上的AUC为96%,在Tiny-ImageNet数据集上的AUC为94%。ULPs方法受到了通用对抗扰动UAP(Universal Adversarial Perturbation)方法[24]的启发,对输入图像进行优化处理,得到通用测试模式。然后将其作为模型的输入,对模型输出进行差异分析,从而判断模型是否包含后门。该方法针对基于单触发器的后门攻击,仅需访问目标模型的输入与输出,无需模型结构等信息,也无需访问训练数据。但是,攻击者可以利用模型交叉熵的值来量化注毒损失,进而欺骗ULPs检测器。
(3)元神经分析检测框架。该检测框架是由Xu等人[25]在2021年提出的。元神经分析后门检测框架MNTD(Meta Neural Trojan Detection)在视觉、语音、表格数据和自然语言文本数据集上的检测准确率AUC达到了97%,显著优于现有的其它后门检测方法。MNTD框架可以在模型参数及攻击方法未知的情况下,对目标模型进行后门检测。首先,基于正常数据集和生成的后门数据集建立大量模型;然后,设计特征提取函数,将模型向量化,并将其作为输入数据训练得到元分类器;最后,利用优化后的查询集提取目标模型的特征,将其表示为向量并输入到元分类器中,根据元分类器的输出结果判断目标模型是否包含后门。
4.4 针对模型的后门净化方法
部分场景中模型的训练数据以及训练过程都未知,只有训练好的模型可供访问,则需要通过直接修改模型来实现后门的检测与消除。
(1)剪枝微调防御。该方法是由Liu等人[26]在2018年基于剪枝[27]和微调的方法提出的。剪枝微调(Fine-pruning)防御方法在交通标志识别任务的后门模型上,BadNets攻击的成功下降率ARD为70%,文献[28]提出的针对剪枝方法的Pruning Aware攻击的成功下降率ARD为53%。该方法假定后门样本所激活的神经元通常不会被正常样本所激活。首先在一个干净的验证集上按照神经元平均激活值从小到大的顺序对神经元进行迭代剪枝,并记录剪枝后的模型准确率。当验证数据集上的准确率低于设定的阈值时不再剪枝。考虑到后门样本激活的神经元与正常样本激活的神经元会有重叠,在剪枝完成后用正常输入微调模型的神经元激活值。该方法以一定的概率消除模型中存在的后门,但也会牺牲一定的准确性。此外,该方法需要深度神经网络的规模足够大,对于紧凑型网络,如移动端的轻量化模型,则可能会大量剪枝掉正常输入对应的神经元。
(2)神经净化防御。该方法是由Wang等人[28]在2019年提出的。神经净化防御NC(Neural-Cleanse)方法应用在各类型后门模型中都能使攻击成功下降率ARD大于90%。NC方法将后门检测形式化为一个非凸优化问题。而优化问题的求解可看作是在目标函数定义的对抗性子空间中搜索特定的后门样本。通过遍历模型的所有标签逆向生成每个类别对应的触发器。然后对比分析触发器的大小和分布,判断哪些类别可能被植入了后门。但是,该方法假定带后门模型中,被攻击的后门标签与其他干净标签相比,被错误分类到指定目标标签所需要操作的变化量更小。这一假设在很多场景中并不一定成立。
(3)TABOR防御。该方法是由Guo等人[29]在2019年在NC方法的基础上提出的。TABOR防御方法在不同数据集上训练的各种后门模型的攻击成功下降率ARD几乎都接近90%。与NC方法类似,TABOR方法也将模型后门检测视为一个优化问题,设计了一个新的目标函数来指导优化,以更准确地识别木马后门。其中,为目标函数设计新的正则化项,缩小搜索后门样本子空间,使搜索过程中遇到无关样本的可能性更少;同时,还结合了可解释AI的思想,进一步删除无关的对抗样本,最终区分并消除模型中的触发器。
(4)神经元注意力蒸馏防御。该方法是由Li等人[30]在2021年提出的。神经元注意力蒸馏NAD(Neural Attention Distillation)防御方法在6种类型的后门模型上,只使用不到5%的干净训练数据,攻击成功下降率ARD接近90%。NAD防御方法实际上是一个微调过程。通过少量的干净数据子集对原始后门模型微调得到教师模型;再通过该教师模型指导原始后门模型(也称学生模型)在同一个干净数据子集进行微调。在这个过程中,以不同通道激活图的均值或总和作为整体触发效应的综合测量,最小化学生模型和教师模型之间的激活图差异。同时,由于整合效应,激活图包含了后门触发的神经元和良性神经元的激活信息,即使后门没有被干净数据激活,也可以从激活图中获得额外的梯度信息。
4.5 模型后门检测技术总结
模型后门检测可以从数据层面展开,也可以在模型层面展开,具体包括针对训练数据集的后门检测、推断输入数据的后门检测、目标模型的后门检测和模型净化等,如表2所示。模型后门检测面临的挑战包括:后门的隐蔽性使得很难通过功能性测试来识别后门;防御者通常只能得到模型的有限信息,模型的训练数据或者替代模型较难获得;标注后门的训练数据或模型也较难获得。目前已有的后门检测方法限制条件较多,在实际场景中的应用效果难以保证。
5 总结与展望
5.1 当前研究进展总结
深度神经网络的安全性问题是当前学术界的研究热点之一,其模型的后门植入和检测技术研究越来越受到重视。深度神经网络模型后门具有较强的隐蔽性,也具有更大的潜在危害性。尤其是当前开发者大量依赖公开的预训练模型和数据集,使得模型后门的植入形式更加多样,植入过程更加隐蔽。与之相对应的模型后门检测与净化等防御技术研究成为提升人工智能系统安全性的必要环节。
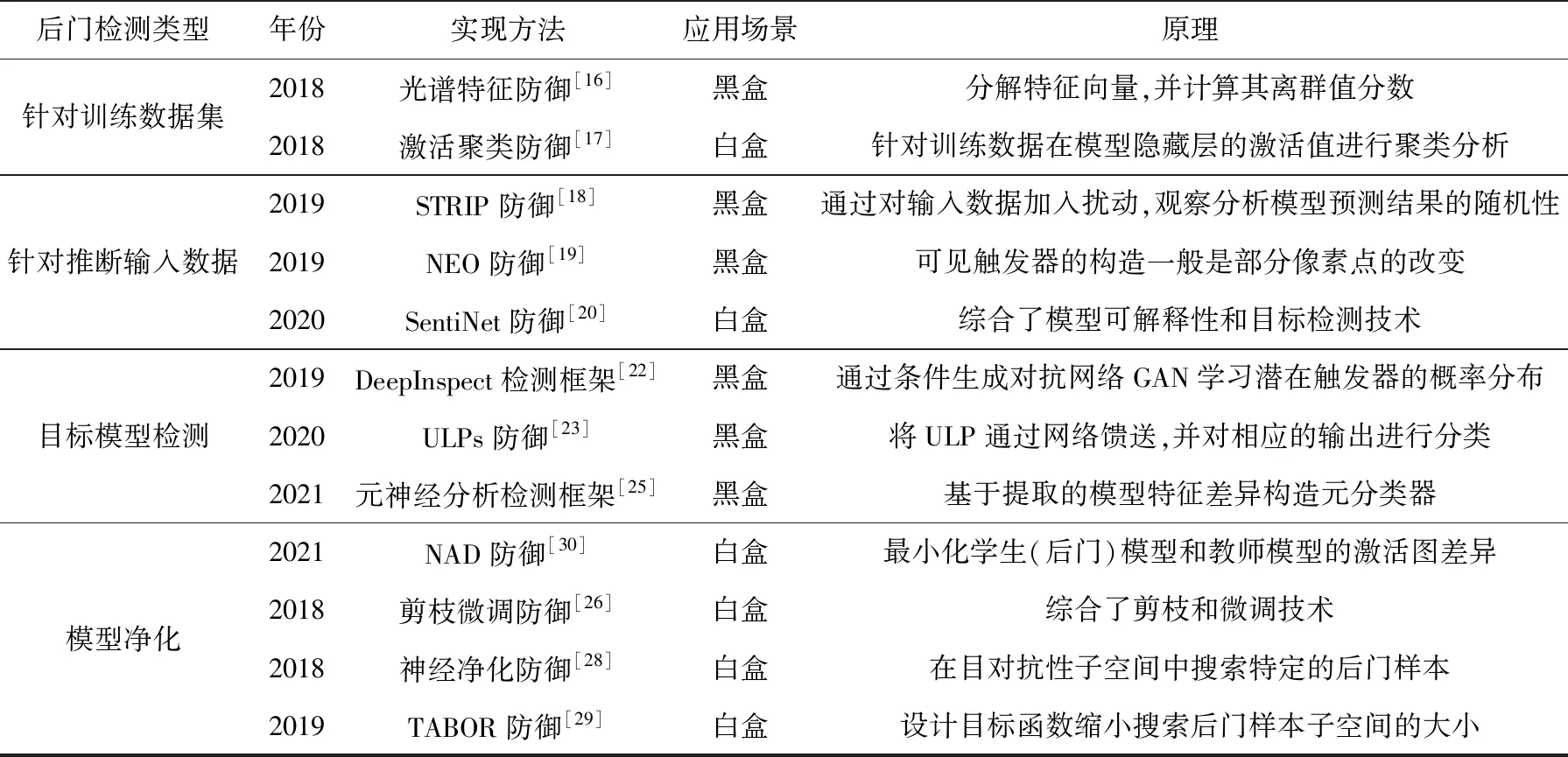
Table 2 Comparison of backdoor detection methods on deep neural network model
现有的深度神经网络模型后门植入与检测技术贯穿模型整个生命周期的各个环节。模型后门植入技术主要从数据注毒和模型修改2个维度展开,最终在指定目标标签与触发输入之间建立强相关性。但是,目前的模型后门植入方法在隐蔽性、鲁棒性、抗检测性等方面都还有提升的空间。后门检测与净化等防御方法主要从训练数据触发器检测、测试推理数据触发器检测、模型后门检测、模型后门净化等方面展开,最终实现对后门的检测或消除。目前的后门检测方法限制约束条件较多,对于训练数据或模型信息已知的假设在现实中往往并不成立。
5.2 未来研究展望
随着人工智能技术的进一步发展,其应用场景在逐步加速拓展,与其它信息技术的结合也会逐步加深。针对深度神经网络模型的安全性问题研究是人工智能安全的重要组成部分,也会随着人工智能技术的进步不断向前发展。随着数据、模型等的进一步开源,针对深度神经网络模型的后门植入与检测技术研究也变得更加迫切和必要。结合当前相关技术研究进展及研究实际,未来需要从多个方面进一步深化研究:
(1)模型后门的存在机理研究。传统软硬件后门的存在形式比较明确,其触发位置也比较固定,后门植入与检测的目标相对比较明确,但模型后门在不同领域中的差异较大,如图像、语音、文本等领域的后门难以迁移。此外,模型后门并非独立存在于神经网络中的某几个神经元,而是在不同层的神经元之间通过传导计算才会形成后门,且随着模型的更新升级,后门所对应的神经元分布可能发生较大的变化。因此,对于模型后门的植入与检测不能局限于表象,需要从更加本质的机理出发进行研究。
(2)黑盒场景下的模型后门植入与检测技术研究。模型后门的植入既可以在训练阶段对训练数据进行注毒,也可以在模型开发和部署阶段对模型进行修改。但是,对于无法访问训练数据和目标模型的场景,如本地独立开发的黑盒模型,则需要研究新的后门植入方法。同时,黑盒场景下的后门检测也需要摆脱对数据和模型信息的依赖,实现在与目标模型尽可能少交互的场景下对模型后门的检测,以及有针对性地设计输入样本,避免触发潜在的后门。
(3)多维信息融合的后门植入与检测技术研究。模型后门的存在会影响人工智能系统安全,但此类影响与人工智能系统运行所依赖的基础软硬件设施之间的关系,以及与模型训练时使用的计算框架、智能算法、训练数据等之间的关系还有待进一步研究。关联融合不同维度的后门信息,虽然使得后门植入的过程更加隐蔽,后门触发的形式更加多样,但是利用不同层级的多维信息,可以更好地进行关联分析,提高后门检测的准确性。
(4)后门数据与后门模型的多样化生成与标注技术研究。当前模型后门的植入与检测技术研究主要依赖本地生成后门样本以及训练后门模型,在后门数据与后门模型的多样化方面存在较大不足,测试结果的可靠性及可对比性仍有待检验。需要研究后门数据与后门模型的自动化、规范化、多样化生成与标注技术,建立模型后门相关研究的标准框架。
6 结束语
深度神经网络模型的后门植入与检测相关技术研究对提高人工智能模型的安全性和可靠性具有重要作用。本文首先对深度神经网络模型后门的定义以及与模型生命周期各环节的对应关系进行了分析介绍;然后,分别针对深度神经网络模型后门植入、检测、净化等技术进行了探讨分析和总结归纳;最后,对深度神经网络模型后门植入和检测相关技术研究进行总结与展望,以期为相关领域研究人员提供参考。
