融合ELMo词嵌入的多模态Transformer的图像描述算法
2022-11-16杨文瑞刘英莉
杨文瑞,沈 韬,朱 艳,曾 凯,刘英莉
1.昆明理工大学 信息工程与自动化学院,昆明 650500
2.昆明理工大学 云南省计算机重点实验室,昆明 650500
近年来,深度学习的发展使得计算机视觉和自然语言处理领域都取得了巨大的进步。这些成果使得视觉与语言的相互关联成为可能,并且促进了多模态深度学习任务的发展,例如:图片-文本对应[1]、视觉问答[2-3]以及图像描述[4-5]。
图像描述是一个使用自然语言处理对一张图像生成文本的任务,所以它要求设计一个算法去理解并且建立视觉信息与文本信息之间关系,并且最终生成一个具有时序关系的语句。这个问题的难点在于识别图像中的目标并且理解他们的相对关系。由于机器翻译中的序列到序列模型的出色表现,大部分比较成功的图像描述算法基本都采用编码-解码的基本框架。这种基本框架包括一个由卷积神经网络构成的编码器,用来提取输入图片的图像特征以及一个由循环神经网络构成的解码器,根据图像特征信息迭代,生成相应的自然语言描述。这种编码-解码模型通常采用端到端的模式,以交叉熵为损失函数进行训练。基于这种基线模型,为了进一步提高图像描述任务的性能,有很多的相关工作对其做了改进。例如,为了建立描述词语与图像相应区域的细粒度联系,一种注意力机制被完美地加入到这种基线模型中[6];为了提高对图像中目标的理解,一种基于图像区域的bottom-up的注意力特征替代了原始的卷积神经网络[5],一种基于强化学习的算法被用来解决在训练过程中由于损失函数以及评价指标不对等偏差的问题[7]。尽管上述方法在图像描述领域取得了较大的成功,但是仍有以下两种不足:
(1)注意力机制的引入,大大地提高了图像描述任务的效果,但是现有研究中更多强调不同模态间的注意力,忽略了模态表征内的注意力,这会导致视觉与自然语言描述存在语义差异,模型无法较好地表示图像目标之间的关系。
(2)现有的图像描述算法在进行词向量编码的过程中,多采用Word2Vec[8]或者Glove[9]编码,这样的做法导致同一词语在不同的上下文语境下的意义相同,最终使模型对图像语义的描述偏差。
针对该领域存在的两个问题,本文的主要贡献如下:
(1)提出了针对图像字幕描述任务中的多模态Transformer 模型。模型采用模态内注意与模态间注意力的联合建模方式。通过这些注意力在深度上的堆叠,提升了模型对图像的语义描述能力。
(2)提出使用ELMo词嵌入与标准词嵌入联合编码的方式,对不同语境下的词语进行包含上下文信息的词嵌入编码,使得模型对语义的理解有了很大提高。
(3)在Microsoft COCO2014 数据集上进行了大量的实验,分别对不同层数的网络模型以及效果进行了分析,并可视化地分析了模态间与模态内注意力的效果。定量和定性地证明了所提出模型的有效性。实验结果表明,融合ELMo词嵌入的多模态Transformer模型的性能明显优于现有的方法。
1 图像描述相关工作
1.1 图像描述
图像描述指的是给定一张图像从而生成其对应的语言描述的任务,在过去的相当一部分时间里,有很多方法被用来进行图像描述。图像描述模型可以分为三类:基于模板填充的模型[10-12]、基于检索的模型[13-15]以及生成式模型[4,7,16]。
早期的模型都采用基于模板的模型,该类模型的主要步骤是:首先生成一个固定的语言模板,然后再根据目标检测器以及属性检测器对图像进行特征提取得到图像中的实体以及对应的属性,最后将提取到的实体属性填入语言模板中[10]。这种进行图像描述的方式通常可以非常清楚地描述图像中的实体以及对应的属性,但是缺乏多样性,生成的语句比较单一而且刻板。
基于检索的模型首先要维护一个包含大量图像描述语句的语料库,通过比较图像与语料库中图像描述语句的相似性来获得候选语句的集合,最终选择相似性最高的语句作为图像的最终描述[13]。这种模型丰富了图像的语言描述,但是不能生成语料库之外的语句,没有从根本上解决语句多样性的问题。
随着深度神经网络时代的到来,大部分图像描述任务渐渐的都开始引入神经网络来进行图像描述任务,这便是生成式模型。Szegedy 等人通过引入GoogLeNet[17]以及长短期记忆网络(LSTM)[18]提出了一种新的编码-解码框架来进行图像描述。由于其出色的,基于卷积神经网络以及循环神经网络的编码-解码模型慢慢成为图像描述任务的主流框架。
1.2 注意力机制
注意力机制(attention mechanism,AM)最早是在2014 年由google mind 团队提出,他们在循环神经网络的模型上增加了注意力机制来进行图像分类,现已广泛应用于图像描述任务中,Xu 等人[19]提出了一种类似于人眼观察图像时聚焦的注意力机制,并将其引入图像描述任务中,其中硬注意力机制(hard-attention)将关注的区域权重设置为1,其他部分设置为0,而软注意力机制为每个区域进行权重学习,使得其相加等于1。后续研究都在此基础上进行改进,Chen等人[6]使用空间注意力与通道注意力机制去对图像进行注意力加权。Anderson等人[5]提出了bottom-up 以及top-down 两种用于图像描述的注意力机制,使用Faster-RCNN[20]检测图像中的感兴趣区域(region of interests,ROIs),并从ROIs 中提取图像特征作为输入至后续任务的特征矩阵,再使用两个LSTM[18]分别做top-down注意力层和语言模型进行图像描述的生成。
2 多模态图像描述Transformer
多模态Transformer 的图像描述模型主要包括两个部分:(1)图像特征编码器;(2)文本描述解码器。图像特征编码器的输入为一幅给定的图像,并且使用预训练的卷积神经网络去提取图像特征值。接着该特征值被送入编码器中,通过自注意力学习得到图像视觉的注意力表征,接着文本描述解码器通过编码器处理之后的图像视觉注意力以及上一时刻的单词去预测下一个可能出现的单词。多模态图像描述Transformer的网络结构示意图如图1所示。
2.1 图像特征编码器
图像特征编码器根据输入的图像进行编码,它主要工作是获取图像的特征信息,通过注意力机制学习到图像视觉模态内部的注意力矩阵,从而得到图像信息中的相互关系。它由图像特征提取器与多模态Transformer编码器两个部分组成。
2.1.1 图像特征提取器
在图像特征提取器中,输入的图像被表示为一组图像特征。本文遵循Anderson 等人[5]提出的bottom-up 注意力机制来提取图像特征,使用一个在Visual Genome数据集上预训练过的Faster-RCNN[20]网络进行实体相关区域的识别,再应用平均池化来生成最终的特征,其中每一个实体的特征被表示为xi,输入的整张图像被表示为一个特征矩阵X,接着将得到的图像特征矩阵X输入至一个全连接神经网络,目的是调整图像特征的维度使得其与输入至编码器的维度相对应,最终得到的图像特征矩阵被表示为X0。
2.1.2 多模态Transformer编码器
接着经过变换的图像特征X0被喂入多模态Transformer编码器中,它由N个注意力模块{A1e,A2e,…,AN e}组成。第n个注意力模块AN e接收第n-1 个注意力模块的输出Xn-1进行计算,得到经过注意力加权之后的图像模态内部的注意力特征Xn。计算公式如下:
其中,每一个Ane(Xn-1) 包括两个部分,多头注意力(MHA)模块以及Feed Forward 模块(FFN)。多头注意力模块是由h个单头注意力模块组成的,如图2所示。
将图像特征信息Xn-1输入到图2所示的h个参数各不相同的单头注意力模块进行计算,得到h个经过加权的特征矩阵Zn-1i,它表示的就是在第n-1 层每一个不同的头对图像模态内部的注意力矩阵。
FFN模块由一个两层的全连接层组成,其中第一层采用Relu为激活函数。计算公式如下:
其中,W、b为全连接网络待训练的参数。
经过多模态编码器中N层注意力的计算,最终的到图像模态内部的注意力加权矩阵XN。
2.2 文本解码器
文本解码器基于通过编码器后的图像特征矩阵进行计算。它的主要工作首先是针对输入的文本数据进行模态内注意力,学习到输入文本数据模态内的注意力矩阵,即单词之间的相互关系,接着对图像信息与文本信息进行模态间注意力,学习图像与文本之间的相互关系,得到由图像信息导向的注意力加权矩阵,最后生成相对的描述语句。如图1 所示它主要由多模态词嵌入编码器与多模态Transformer 解码器两个部分组成。
2.2.1 多模态词嵌入编码器
多模态词嵌入编码器的主要工作是给输入的单词进行编码,形成输入解码器的特征矩阵。首先对于输入的描述语句。它主要包括两个部分,标准词嵌入编码器与ELMo[21]词嵌入编码器,如图3所示。
多模态词嵌入编码器首先使用标准词嵌入编码器生成标准词嵌入,即进行分词操作,将一句话分割成单个的单词,并对每一个单词形成与其对应的唯一的token,接着将输入的这句话,转化为token的形式,并进行补齐操作。接着使用词向量编码算法对每一个单词进行编码,记作yni∈Remb,最终使用YN来表示一个描述语句的标准特征矩阵,其中emb为采用词嵌入操作的维度。
第二步,多模态词嵌入编码器根据ELMo 词嵌入编码器生成一个基于上下文信息的词嵌入特征矩阵。ELMo词嵌入编码器如图3所示。与标准词嵌入不同的是,对于输入的语句,ELMo 词嵌入编码器并不是对每一个单词进行编码,而是针对所输入的一句话,结合语境进行编码。对于输入的语句为了防止OOV(out of vocabulary)情况的出现,首先经过一个字符编码层,得到每一个描述语句的字符编码ychar,接着将得到的字符编码输入双向LSTM,得到特征矩阵,记为ybi∈R(l+1)×W×emb,其中l为LSTM 的层数,W为单词的个数,这样就得到l+1 个包含上下文信息的特征矩阵,最后将得到l+1 个包含上下文信息的表达输入至混合层,为每个不同的向量分配权重并且混合成一个特征矩阵,得到最终的ELMo 词向量,记作YE。由于经上述步骤得到的词嵌入矩阵并不能很好地表示单词在时序上的信息,多模态Transformer 编码器的结构也并不像循环神经网络一样可以根据时序信息来预测词的概率,因此加入位置编码来使得词嵌入矩阵获得单词出现的顺序,从而体现单词在语句中的相对位置以及绝对位置。具体计算过程如下:
其中,pos代表单词在语句中的位置。
这种位置编码操作,可以比LSTM获得更长的序列长度,并且很容易让模型获得单词的位置。所以最终的输入信息Y=YP+YE+YN,最后将得到的特征矩阵输入至多模态Transformer解码器中。
2.2.2 多模态Transformer解码器
它主要由三个部分组成:基于掩码的多头注意力模块、多头注意力模块以及FFN模块。
基于掩码的多头注意力模块对输入的词嵌入矩阵Y进行注意力建模,在进行注意力建模之前,生成一个上三角为1,其余为0的矩阵进行掩码,防止模型采用当前时序之后的单词进行训练。接着对输入的词嵌入矩阵进行注意力加权得到文字模态内的注意力特征矩阵Rm。
多头注意力模块对于多模态编码器的融合输出XN以及文本输入进行图像与文字模态间的注意力加权,得到由图像信息导向的图像描述注意力加权矩阵Rf。具体计算公式如下:
最后通过Softmax计算得到词语的表示:
其中WRout∈Remb×O,O为词表的大小。
3 实验评估
3.1 数据集
公本文在公开的Microsoft COCO2014[22]数据集上进行了大量的实验用来评估本文模型的性能。使用Karpathy 等人[23]提供的方法将数据分为5 000 张图像的验证集,5 000张图像的测试集以及113 287张图像的训练集三个部分进行模型的训练、验证以及测试。使用BLEU(B1,B2,B3,B4)[24],ROUGE-L(R)[25]以及CIDEr-D(C)[26]作为评价指标,并以百分比值作为结果。
3.2 实验细节
数据集中的每一幅图像包含与之对应的5 句英文描述,将所有描述语句中的单词转换为小写字母进行拆分,最终得到大小为9 957 的标准词嵌入词表。对于模型中的超参数,将Bottom-Up 的特征维度设置为2 048,多头注意力层中的特征维度与个数h分别为1 024、8,每一个头的特征维度为128,标准词嵌入与ELMo 词嵌入的特征维度为1 024。在训练过程中,使用crossentropy 损失函数训练30 个周期,本文设置批次大小为10,使用Adam 优化器进行优化,学习率为0.000 5,momentum动量为0.9。
3.3 实验结果与分析
3.3.1 定量分析
本文进行了一系列对比实验,来定量地证明本文模型的有效性。首先将使用Bottom-UP 注意力机制的图像特征以及LSTM 作为解码器的模型作为基线模型与多模态图像描述Transformer(MCT)进行对比;其次将使用ELMo 词嵌入的ELMo-MCT 模型与以上两个模型进行对比。表1 为实验结果。从表1 可以看出MCT 模型以及ELMo-MCT模型相比较于基线模型在CIDEr得分上分别提高了2.8 以及4.9 个百分点,更进一步,ELMo-MCT 模型,在所有指标上均优,相较于MCT 模型,在BLEU-1、BLEU-2、BLUE-3、BLEU-4、ROUGE-L以及CIDEr上有了0.6、0.7、0.7、0.5、0.4以及0.9个百分点的提高。

表1 消融实验Table 1 Ablationexperiment单位:%
而在所有指标之中CIDEr提高的分数最为明显,而BLUE以及ROUGE-L提高的得分相对平均。针对不同指标的意义来说,BLEU 以及ROUGE-L 主要是根据N-gram或者最长公共子序列在候选语句中出现的次数来判断生成结果的优劣,本质上差别不大,而CIDEr 虽然也是基于N-gram 的算法,但是它计算的是相似度,来实现最终的得分,而本章模型,引入ELMo 来进行词向量编码,模型生成的语义更加丰富,所以出现了在CIDEr分数上升的比BLEU分数更高的情况。
其次,本文还验证了不同深度下网络模型的效果。如表2 与表3 所示。可以看到随着深度的增加,模型的效果呈递减的趋势。这说明在深度增加的过程中,在模型的计算会遗漏一些信息,使得模型的效果变差。
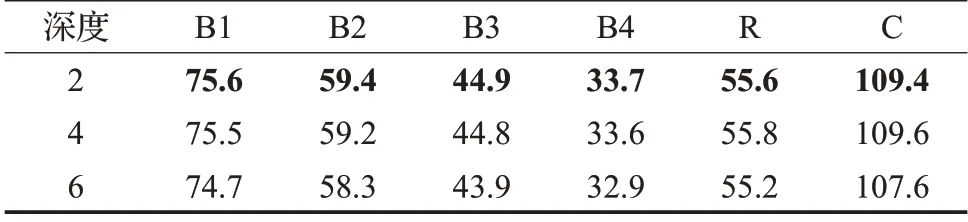
表2 MCT不同深度实验结果对比表Table 2 Comparison of MCT test results on different depths 单位:%

表3 ELMo-MCT不同深度实验结果对比表Table 3 Comparison of ELMo-MCT test results on different depths单位:%
最后可以从表4得到模型的整体表现,从中可以看出本文的模型与大多经典模型相比在所有指标上都有比较好的效果,与Bottom-LSTM这种基线模型相比本文的模型在CIDEr得分上分别提高了2.8与4.9个百分点。
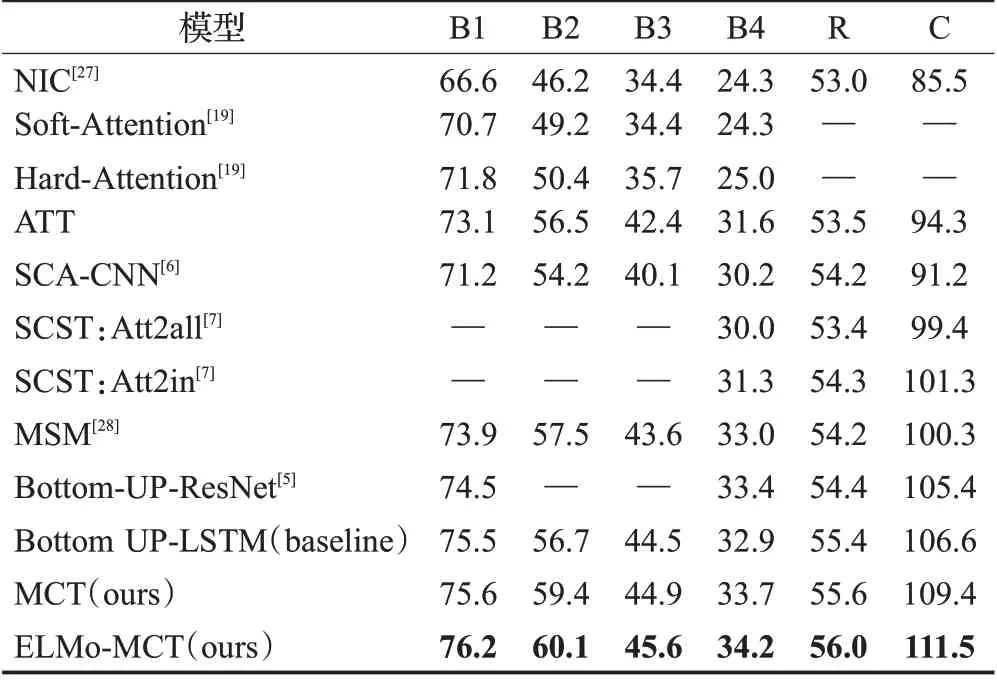
表4 ELMo-MCT模型整体表现Table 4 Overall performance of ELMo-MCT model单位:%
3.3.2 定性分析
对本文模型的效果进行了定性分析(图4)。首先对于6 层MCT 模型的注意力进行了可视化分析,具体如下。
图5 给出的是多模态解码器中不同层数中的文字模态内的注意力可视化表示。其中颜色条坐标值代表相互关系,数值越大代表相对关系越高。从图5(a)中可以看出,在第一层中获得注意力得分最高的位置都是在图像的对角线,这说明在第一层中模型并没有学习到两两的相互关系。而在图5(b)中,“umbrella”与“holding”在图像中以红色出现,获得了较高的注意力分数,这说明在第六层中,模型学习到了文字模态内部的相互关系。
图6 给出的是多模态编码器中不同层数中的图像模态内的注意力可视化表示,坐标为0 到46 分别对应图4 中的各个Bottom-UP 区域中的图像特征。可以看出,在多模态编码器的第一层中(图6(a)),获得注意力得分最多的只有少部分区域,而且集中出现在第22列,这代表第22 列所表示的目标与图像中的大部分区域都有相互关系,结合图4,序号22 代表的图像区域为“雨伞”,且处在图像的最中心,所以,模型将它与外界事物都联系了起来,由此可以分析出,在多模态编码器的第一层,模型只学习到很少一部分的相互关系。而在第六层(图6(b)),可以明显地发现,色块变多而且颜色变重,获得注意力得分也变多,说明模型学习到了大部分目标的相互关系,鉴于此,从反方向进行分析,针对得分最少的第20 列,可以看出第20 列与图像中的关系甚微,而第20列目标为天空,并且在Ground Truth中并没有提及,说明在训练的过程中,模型已经学习到了很多信息,从而出现了这种结果。
图7 与图8 分别表示的是多模态解码器中第一层与第六层的图像与文字模态间的注意力可视化,其中纵轴代表描述语句,而横轴代表图4 中各个Bottom-UP区域中的图像特征。可以看出在第一层,模型学习到的效果较差,得分较高的很多词语以及目标之间的关系都是不正确的,而在第六层,模态之间的相互关系变得非常明确。
图9 分别给出的是ELMo-MCT 与MCT 的Loss 曲线图,将得到的原始图像做平滑处理得到了波动较小的Loss对比曲线图,如图10所示。可以看出,ELMo-MCT模型相较于MCT 模型在训练的过程中,可以获得更低的Loss值。这说明使用融合ELMo词嵌入编码的模型,在训练过程中具有一定的指导意义,可以使得模型获得与候选语句更接近的图像描述。
图11 为ELMo-MCT 模型与MCT 模型针对所给图像而得到的图像描述对比图。其中绿色、黄色以及蓝色字体的描述语句分别代表2 层、4 层以及6 层MCT 所给出的描述语句,而红色为ELMo-MCT 模型所给出的描述语句,从中可以很清楚、很直观地看出ELMo-MCT模型的效果更为优秀。所给出的描述更加准确而且语义更加丰富。具体表现在图中红色字体的划线部分。更进一步的,如图12 所示,从其中的划线部分可以看出,融合ELMo 词嵌入的MCT 模型,在训练过程中根据Ground Truth中的相关单词,模型联系上下文信息与语境,学习到了候选语句之外的表达,使得语义更加丰富。这说明引入ELMo 进行词嵌入编码的ELMo-MCT模型具有更加优秀的性能。
4 结束语
当前的图像描述算法主要采用编码-解码模型,并采用注意力来提高模型的效果,但是这种做法大多只是在模态间进行注意力,并使用Word2Vec或者Glove来进行文本的编码,使得模型遗失了很多的有效信息。本文针对图像描述提出了一种多模态Transformer模型来进行模态内与模态间注意力的联合建模,从而改善模型的效果。此外提出ELMo与标准词嵌入的联合编码方式,使模型获得更加丰富的语义信息,提高了模型的语义描述能力。本文在公开数据集MSCOCO上进行了大量实验,定量与定性地分析本文模型的效果,实验证明本文模型有较好的图像描述能力。
