结合密度比和系统演化的密度峰值聚类算法
2022-11-16曹俊茸张德生肖燕婷
曹俊茸,张德生,肖燕婷
西安理工大学 理学院,西安 710054
聚类分析[1]是一种无监督学习,能够根据数据对象的特征,对数据进行有效分类,被广泛发展和应用于数据挖掘[2]、图像分割、基因工程[3]等领域。2014 年,意大利学者Rodriguez和Laio在Science上发表了一种新的聚类算法——密度峰值聚类算法(clustering by fast search and find of density peaks)[4],简称DPC算法。该算法输入参数较少,能够对各种类型的数据集进行聚类,并且能够剔除噪声数据的影响,取得较好的聚类效果。自从该算法提出以来,受到了国内外学者的广泛关注,对其进行了多种改进,王洋等人[5]采用基尼不纯度来度量数据势能的分布来优化截断距离的选取,基尼指数取最小值时,数据的不纯度最小,数据的势能差别最大,更易于聚类,解决了DPC算法无法处理复杂数据集的缺陷;杜沛等人[6]将K近邻思想引入密度计算中,结合校准量来选取截断距离,对任意数据都能自适应选择截断距离,能够处理密度变化大的数据集;文献[7]定义了下属的概念来描述相对密度关系,并以下属的数量作为判断聚类中心的标准,利用相对密度关系,使得算法较少受到密度核和密度差异的影响;文献[8]提出了一种基于残差的密度峰值聚类算法,通过残差计算测量局部密度,然后利用产生的残差生成残差碎片形成簇,并提出了一种半自动聚类识别方法,消除了人工质心选择的迭代过程;文献[9]为了提高DPC算法处理低密度节点的性能,采用Halo 算法,提出了一种改进的晕节点密度峰值聚类算法(HaloDPC),提高了处理不同密度、不规则形状的类簇、离群点检测的能力;文献[10]提出了一种新的基于分层方法的聚类算法,即多中心密度峰值聚类(McDPC),假设潜在的集群中心彼此之间的距离相对较远,并且与其他高密度数据点的最小距离相对较大,将具有代表性的数据点自动划分为不同的密度级别,处理每个层次上的类簇,以确定多中心簇,解决了DPC算法无法识别出具有多个密度峰值的簇,或无法识别局部密度相对较低簇的问题;文献[11]针对DPC算法需要人工确定截断距离并圈出聚类中心的缺点,根据K近邻获取样本点密度,并对相对距离进行样本排序,然后找到密度趋势的转向位置,并根据转向位置确定截断距离,寻找可能成为聚类中心的数据点,比较它们之间的相似性,确定最终的聚类中心;高诗莹等人[12]提出了基于密度比例的密度峰值聚类算法(R-CFSFDP),通过计算一个点与其周围点的密度比来提高数据中密度较小的数据对象辨识度,解决了DPC 算法对密度较小簇的遗漏问题。
通过对DPC 算法的多种改进,使得DPC 算法已经成为常用的聚类算法之一,但是,该算法仍然存在一些不足之处:(1)截断距离的选取对局部密度的计算有直接的影响,进而影响聚类中心的选择。特别地,如果截断距离被赋予一个很大的值,计算出的密度约为N(数据对象总数),重叠区域包括了来自其他类簇的数据。相反,如果选择的截断距离太小,计算出的密度约为零,那么每个点都有相似的近邻区域。在这两种情况下,所计算出的局部密度对判别数据类别的价值较小。(2)DPC算法是根据决策图与用户进行互动截取聚类中心,这就会使得不同的人会分析出不同的结果,导致聚类结果的不一致。
针对以上两个问题,本文提出了基于密度比和系统演化的密度峰值聚类算法(DS-DPC)。首先,利用密度比的思想改进密度计算公式,使密度能够反映周围数据的分布情况;然后,根据局部密度与相对距离的乘积排序情况,选出聚类中心,对剩余样本进行聚类;最后,利用系统演化方法判断聚类结果是否需要合并或分离。
1 预备知识
1.1 密度峰值聚类算法
密度峰值聚类算法是一种基于密度的聚类方法,它基于下面两个假设:(1)类簇中心的密度大于与其相邻的非中心点的密度;(2)类簇中心之间通常相距较远。通过计算每个点的局部密度和相对距离,绘制以局部密度为横坐标,相对距离为纵坐标的决策图,根据决策图,选取右上角的点为聚类中心,其余的点根据局部密度就近分配。
对于每个数据点xi∈X={ }x1,x2,…,xN,首先计算其局部密度ρi和距离最近较大密度点的相对距离δi,当数据是离散数据时,局部密度计算公式如下:
截断距离dc依据经验选取,文献[4]中给出了dc的选择方法:使各点的平均邻居数约占数据对象总数的1%到2%,也给出了无法根据决策图判断聚类中心的情况,利用局部密度与相对距离的乘积γi的值,γi越大,越可能被选为聚类中心。
此外,DPC 算法给出了判断核心点和噪声点的方法,定义了边界区域密度:一个类中的数据对象距其他类的数据对象之间的距离小于截断距离dc的所有数据对象的平均密度。局部密度大于边界区域密度的数据对象被视为核心数据,否则,被视为噪声数据。
1.2 自然最近邻搜索
经典的k-最近邻和ε-最近邻都存在参数的选择问题。本质上,都是检测数据集附近的邻域,完全忽略数据特征,不能适应不同规模的数据集。自然最近邻[13]是一种新的最近邻概念,与k-最近邻和ε-最近邻相比,自然最近邻被动选择邻居,对于一个数据点xi,只有当另一个点xj以它作为邻居时,点xi才能算拥有一个邻居,这样的定义能更好地反映数据特征。
定义3(自然最近邻特征值)当搜索达到稳定状态时,自然最近邻特征值就是搜索次数r。
由于自然最近邻特征值很大时,会大大增加算法的时间复杂度,文献[14]对自然最近邻算法进行了优化:随着r值的增加,如果邻居数目为0的数据对象个数不再发生变化,就停止搜索。
2 本文算法
本文主要对密度峰值聚类算法进行如下两个方面的改进:(1)重新定义局部密度公式;(2)利用系统演化方法判断两个类簇是否需要合并或分离。
2.1 改进的局部密度
运用自然最近邻搜索方法找到每个数据点的自然最近邻个数,为了使低密度区域的簇不被DPC 算法归为噪声,高密度的簇边界区域中没有点被识别为聚类中心,需要用一个相对的密度来替换原来的密度度量。运用密度比的思想,一个数据点的密度不仅要度量其截断距离领域内的密度,还需要再选取一个更大的截断距离,计算这两个领域的密度比来衡量一个点的密度。通过这样做,能够处理簇间密度的变化。但是,密度比公式的计算中需要输入两个截断距离参数,不能自动获取参数,因此,本文结合自然最近邻搜索,将密度公式改进为:
其中,nb(i)是自然最近邻搜索中当邻居个数为0 的点不再变化时停止搜索,数据点xi的最近邻个数,而nk(i)则是当自然最近邻搜索达到稳定状态时,数据点xi的最近邻个数。
2.2 判断类簇是否需要合并
DPC 算法给出了γi值的定义,本文运用γi的排序值挑选出前N(N是数据点个数)个数据点作为聚类中心,将剩余数据点就近分配到密度更高的类簇中。再利用文献[15]的系统演化方法对聚类结果进行合并或分离,具体定义如下。
如图1 所示,假设有两个类簇,簇A 和簇B,每个簇被分割成m个区域。设簇A和簇B之间距离最近的两个区域为边界区域A1和B1,设A2为簇A的中心区域,B2为簇B的中心区域。
(1)将簇分为不同的区域。
设N1和N2分别为簇A和簇B数据对象的总数,则将簇A分为m1个区域,簇B分为m2个区域。
(2)找边界区域A1、B1:从簇A 中选择n1个距簇B最近的数据对象组成A1区域,从簇B中选择n2个距簇A最近的数据对象组成B1区域。
(3)找中心区域A2、B2,从簇A中找出离A1最近的n1个数据对象,形成A2 区域,类似地,从簇B 中找到n2个数据对象形成B2区域。
(4)找出A1和B1的交叉区域F,从A1和B1中各找出一半离彼此近的数据对象,组成交叉区域F。
(5)簇A与簇B之间的边界距离DAB为:
测量A1 中的平均距离DA1为A1 中各对象间的平均步长距离,其中A1 的步长是:从A1 中的两个相距最远的数据点h1(或hk)出发,找到下一个距离h1最近的对象h2(计算h1与除h1之外的所有对象的距离,并选择距离最小的对象),计算它们之间的距离,类似地,继续通过h2找到下一个最近的对象直到到达hk。
同样,DA2、DB1、DB2、DA1A2、DB1B2、DA1B1、DF分别是A2、B1、B2、A1A2、B1B2、A1B1、F区域的平均距离。
当数据对象有如图2 所示的情况时,左边数据点1到中间两个点(点2和点3)的距离相等,选择点2或点3其中一个作为下一个点会计算出不同的平均距离,因此本文将平均距离的计算改进为计算所有数据对象的平均距离。即:
系统演化方法推导出的可分性信息为:(1)当Dn >0 时,两个类簇完全可以分离;
(2)当Dn≤0 且Ep >Em时,两个类簇有轻微重合;
(3)当Dn≤0 且Ep≤Em时,两个类簇可以聚合在一起。
对于系统演化方法不能分辨两个类簇有轻微重合时的情况,则计算两个类簇的自然近邻数目,如果合并两个簇后,每个数据点的平均自然近邻数目增加,则将两个簇合并,否则,不合并两个簇。
2.3 DS-DPC算法描述
本文算法主要是在DPC 算法的基础上,计算局部密度时,运用密度比的思想以避免噪声点具有较高的密度,或者高密度的簇边界区域中的点被识别为聚类中心,其次,引入了系统演化方法对聚类后的结果进行判断,进一步得到聚类结果。
本文算法的基本步骤如下,算法流程如图3。
输入:数据集X={x1,x2,…,xN},数据点个数为N。
输出:聚类结果C={c1,c2,…,ck} ,类簇个数为k。
步骤1 根据自然最近邻搜索找出每个点xi的自然最近邻。
步骤2 分别根据公式(9)和公式(4)计算每个点的局部密度ρi和相对距离δi。
步骤3 计算局部密度和相对距离的乘积γi,并对其进行排序。
步骤4 选取γi排序中前N个点作为聚类中心,并将剩余点就近分配到密度更高的簇中。
步骤5 根据类簇中心之间的距离,对N个类簇就近进行两两配对,利用系统演化方法判断每对类簇是否需要合并。
步骤6 将上一步得到的聚类结果再次进行两两配对,利用系统演化方法判断是否需要合并。
步骤7 判断所得结果中每对类簇是否处于分离状态,若是,则算法结束,得到最终聚类结果。若否,则转至步骤6继续判断类簇的合并与分离。
2.4 算法时间复杂度分析
对于一个含有N个样本的数据集,设c为N2,本文所提算法的时间复杂度主要来源于以下四个方面:(1)计算距离矩阵,时间复杂度为O(N2);(2)用自然最近邻搜索一个点的第r个最近邻,时间复杂度为O(lbN),λ为自然最近邻搜索达到稳定状态时的搜索次数,因此,搜索所有点的自然最近邻的时间复杂度为O(λ·N·lbN);(3)相对距离计算的时间复杂度为O(N2);(4)利用系统演化方法判断分别含有N1和N2个样本的两个类簇是否可以合并的时间复杂度为O(N21)+O(N22),因此,系统演化方法总的时间复杂度为O(c·N21)+O(c·N22)。综上,本文所提算法的时间复杂度约为O(c·N2)。
3 仿真实验与结果分析
本文使用MATLAB 进行实验,在三个人工合成数据集和六个UCI 数据集上实现本文算法,并与常用聚类算法DPC、DBSCAN、K-means 以及CDPC-KNN[6]和CFSFDP-HD[16]算法进行比较。表1 和表2 分别是实验所用人工合成数据集和UCI数据集的基本信息。
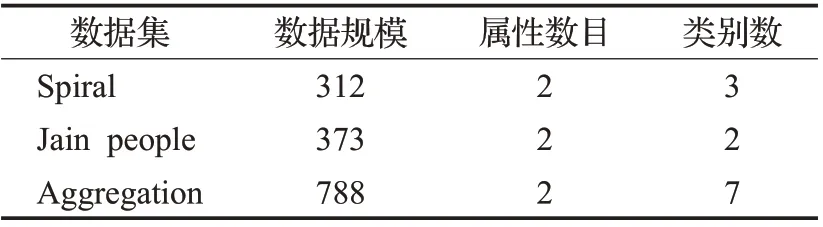
表1 三个人工合成数据集Table 1 Three synthetic datasets

表2 六个UCI数据集Table 2 Six UCI datasets
3.1 聚类评价指标
本文选用Accuracy 指标(ACC)、FMI 指数、调整互信息(AMI)以及调整兰德系数(ARI)四个指标评价聚类结果。将本文算法与其他五种聚类算法进行比较。
(1)Accuracy指标(ACC)
Accuracy 指标度量聚类结果中正确聚类的个数占总个数的比例,计算公式为:
其中yi为第i个类簇中正确聚类的样本数目,k为真实类簇的个数,N为数据集中样本的总数目。ACC 的取值范围在[0,1],取值越大,说明聚类结果与真实结果越接近,聚类效果越好。
(2)FMI指数
FMI指数是对精度和召回率的几何平均,公式如下:
聚类结果所形成的簇集合为C,样本的真实簇集合为D,从数据集中任取两个样本,a表示在C和D中都属于相同簇的样本对的数量。b表示在C中属于相同簇,而在D中属于不同簇的样本对的数量。c表示在C中属于不同簇,而在D中属于相同簇的样本对的数量。显然,FMI的取值是在[0,1],值越大说明聚类效果越好。
(3)调整互信息(AMI)
AMI公式如下:
AMI 是基于预测簇向量与真实簇向量的互信息分数来衡量其相似度的,AMI 取值范围在[-1,1],AMI 越大,说明聚类结果和真实结果的相似度越高,聚类效果越好。
ARI 的取值范围在[-1,1],值越大意味着聚类结果与真实情况越吻合,主要是用来衡量两个数据分布的吻合程度。
3.2 人工合成数据集上的实验结果及分析
本文对比了三个人工合成数据集检验DS-DPC 算法与其他五种聚类算法的聚类结果,图4、图5、图6分别是六种算法在Spiral、Jain people 和Aggregation 三个数据集上的聚类效果图。
对于Spiral数据集,由图4可以看出,由于对局部密度公式的改进,以及聚类结果的优化,DS-DPC 算法正确识别出了聚类个数,准确地对每个点进行了聚类,DPC算法和DBSCAN算法也识别出了三个类,K-means算法将聚类中心均匀地分布在数据空间中,将聚类中心周围的点聚为一类,得到的聚类效果较差。K-means算法不适合于发现非凸面形状的簇或大小差别很大的簇,因此对该数据集没有达到较好的聚类效果。CDPCKNN 算法也能正确地将每个点进行聚类,而CFSFDPHD 算法将一个类中的一部分分配到了相邻的一个类中,聚类效果不佳。
对于Jain people数据集,由图5可以看出,DS-DPC算法和DPC 算法虽然都能正确识别聚类个数,但DSDPC能更准确地将两个类相交处的点归类,从图中还可以看出,DS-DPC算法比DPC算法识别出的聚类效果更加准确,DPC 算法只是就近分配,将密度高的点周围的对象都分配到了一类,但是没有分辨出密度分布不一致的两个类。对K-means算法输入了正确的聚类个数,却将一个真实簇的一部分归类到另一类中,聚类效果最差。CDPC-KNN算法是对DPC算法的密度和相对距离的计算公式进行了改进,使得决策图中可以明显分辨出聚类中心,对于该数据集的聚类效果也很好,CFSFDPHD 算法聚类过程不是自适应的,将密度较大的一个类簇分成了两部分,聚类结果出现了错误。
对于Aggregation数据集,由图6可以看出,DS-DPC算法和DPC 算法都能准确对其进行聚类,而DBSCAN算法将周围一些点识别为噪声数据,导致聚类结果不理想,由于K-means 算法只适合于对球形数据聚类,即使输入了正确的聚类数目,也未能得出准确的聚类结果。Aggregation 数据集有七个类,CDPC-KNN 算法对该数据集的聚类效果中,有少量数据没有正确分类,CFSFDP-HD算法对该数据集的聚类效果较好。
3.3 UCI数据集上的实验结果及分析
为了观察在UCI数据集上的聚类效果,本文对选取的六组数据集进行了六种聚类,并将聚类结果的评价指标统计在表3中。
表3给出了DS-DPC算法与其他五种算法在UCI数据集上的评价指标值的对比,从表中可以看出,由于对密度和聚类结果进一步的改进,DS-DPC算法的各项评价指标几乎都优于其他算法。在Iris数据集上,DS-DPC算法的四项指标都接近于1,表明聚类效果较好。对于Segmentation 和Dermatology 两个较高维数的数据集,DS-DPC算法的聚类效果也较好,而其他五种算法对这两个数据集的聚类效果都差一些,尤其是DBSCAN 算法和K-means算法。CDPC-KNN算法对Wine数据集的准确率也较高,与DS-DPC 算法具有相同的准确率,并且CDPC-KNN 算法在Ecoil 数据集上的聚类评价指标值都较高。从总体上看,本文算法在高维和低维数据集上都取得了较好的聚类效果。
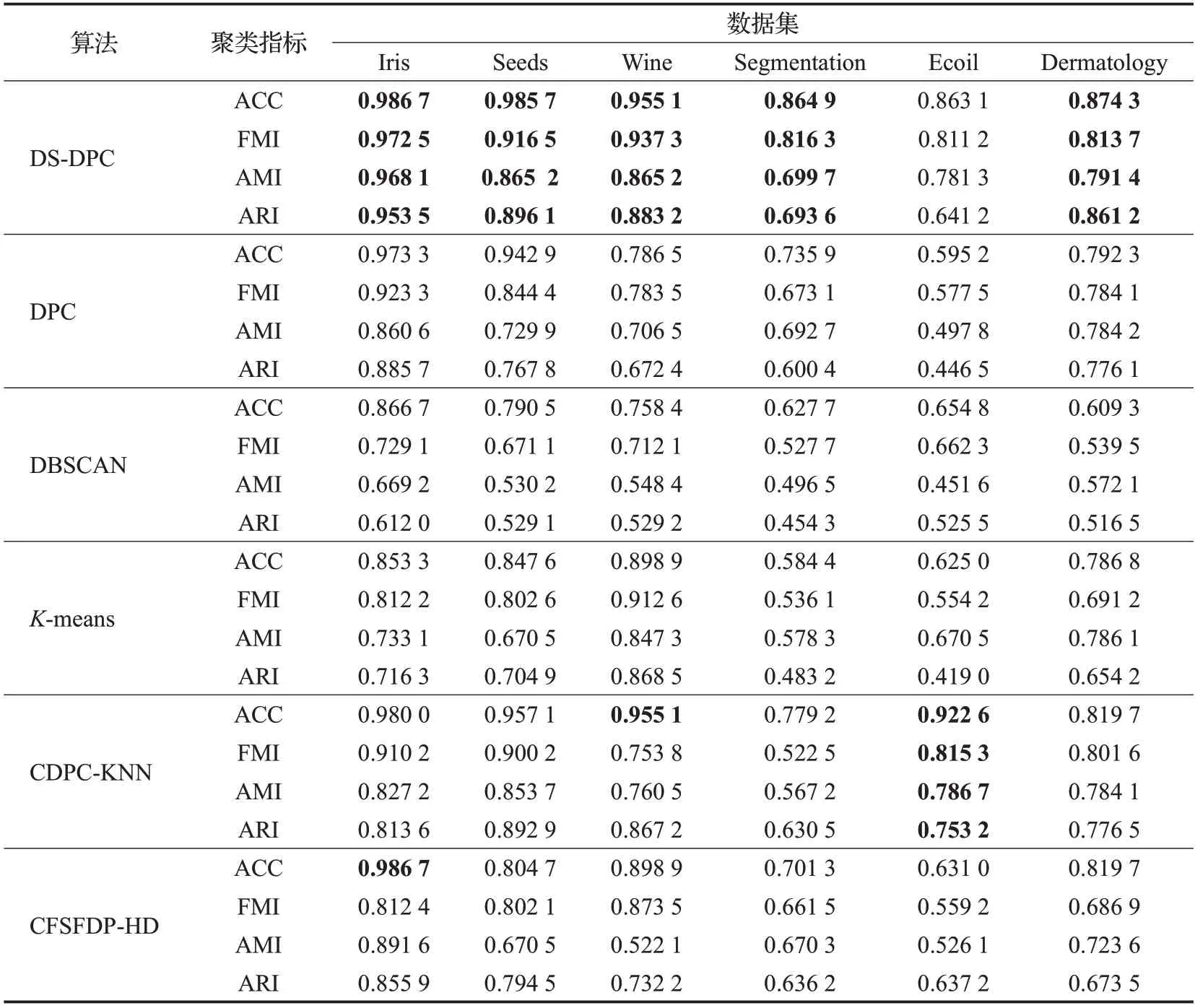
表3 6种算法在UCI数据集上的指标值Table 3 Index values of six algorithms on UCI dataset
4 结束语
DPC 算法能够检测任意形状的簇,易于实现,但该算法需要输入参数,并且需要手动选择聚类中心。针对这些不足,本文提出了一种基于密度比和系统演化的密度峰值聚类算法,对DPC 算法进行了两个方面的改进。具体的改进为:(1)利用自然最近邻搜索找出每个点的最近邻个数,并且结合密度比的思想来计算样本的局部密度,使计算出的密度不仅能够考虑周围点的个数,也能够反映出周围点的分布情况,消除了DPC 算法由于输入参数而导致的聚类结果不一致的情况。(2)计算局部密度与相对距离的乘积γi,选取γi值较大的点为聚类中心,按照DPC 算法的分配策略进行聚类,引入系统演化方法对DPC 算法的聚类结果进行进一步的分析,运用公式判断类簇的合并与分离,避免了手动选取聚类中心的主观性,提高了算法的聚类性能。
通过在人工合成数据集和UCI 数据集上进行实验验证,结果表明,本文算法具有一定的优越性,下一步的研究应该重点讨论算法的时间复杂度,使DPC 算法能够适应更大规模数据的聚类分析。
