随机集成策略迁移
2022-11-15章宗长
常 田,章宗长,俞 扬
南京大学 计算机软件新技术国家重点实验室,南京210023
深度强化学习(deep reinforcement learning,DRL)在很多有挑战性的任务中取得了相当大的成功[1-2]。然而,DRL 在训练过程中需要与环境不断交互,当面对复杂任务时,算法的训练需要很长的交互过程,如果对每个任务从头开始独立学习,需要大量的时间和数据,这导致DRL 在解决实际问题时效率低下。最近,迁移学习(transfer learning,TL)被用来解决这样的问题[3]。TL 通过利用从过去相关任务中学到的先验知识来加速DRL在新任务上的学习。一类常见的迁移强化学习方法是比较源任务和目标任务的相似度。文献[4]提出了计算两个马尔科夫决策过程相似度的方法,根据相似度来迁移价值函数。文献[5]对马尔科夫决策过程的相似度进行了扩展,提出根据N步返回值来度量相似度的方法。另一类方法是估计多个源策略在目标任务上的性能,以此选择合适的源策略进行迁移。文献[6]将策略迁移建模为多臂赌博机模型,在目标任务上比较源策略的性能,选择最高者进行迁移。文献[7]将策略迁移建模为选项学习问题,为每个源策略更新价值和终止概率,然后选择价值最高的源策略进行迁移。
无论通过什么途径来评估源策略,此类算法往往无法避免一个共同的问题:对源策略的评估可能不准。尤其是在训练过程前期,智能体与环境的交互不够,对源策略的评估存在较大误差,不能保证评估值最高的策略一定是适合目标任务的源策略。而一旦选择了不合适的源策略,就会造成负迁移。对此一般的方法是通过ε-贪婪来选择策略,即以1-ε的概率利用,选择评估最高的策略,以ε的概率探索,任意选择一个策略。然而,ε-贪婪在进行探索时选择的策略是随机的,这没有利用除最优策略外其他源策略的评估信息。基于以上问题,本文提出一种随机集成策略迁移方法(stochastic ensemble policy transfer,SEPT)。方法将策略迁移建模为选项学习问题,通过终止概率对所有源策略进行评价。然后根据评价为它们赋予权值,根据权值集成出教师策略进行迁移。
本文的主要贡献包括三方面:
(1)提出了一种随机集成策略迁移方法SEPT,通过在策略库中生成教师策略来进行迁移;
(2)利用选项学习中的终止概率概念为源策略计算概率权重,和类似的工作相比降低了出现负迁移的可能性;
(3)在不同的实验环境中验证SEPT,结果表明SEPT 可以明显加速强化学习的训练,并且超过了之前性能最佳的策略迁移方法。
1 背景知识
在强化学习中,智能体与环境不断交互,目的是学习得到最大回报的动作策略[1]。通常RL以马尔科夫决策过程(Markov decision process,MDP)为框架,由四元组(S,A,P,R)表示。在每一个离散时刻t中,智能体观测到状态st∈S,选择执行动作at∈A,得到即时奖赏rt~R(st,at)并达到新的环境状态st+1~P(st,at)。智能体最终寻找一个最优策略π*来最大化期望折扣回报U=,其中γ∈[0,1]是折扣因子。
选项(option)的概念由Sutton 等人提出[8],选项是一种广义的动作,由初始状态集I、策略π和终止函数β三元组组成。选项只有在I中包含的状态下可用,在t时刻执行选项o=<Io,πo,βo>,就表示从πo(·|st)中获得一个动作at,然后在t+1时刻以βo(st+1)的概率终止。如果不终止,则继续执行选项内策略提供的动作直到终止。动作价值函数可以扩展到选项上,即选项价值函数Qπ(s,o),它表示在指定的状态和选项下的期望回报。这个期望回报对应的是从指定状态开始,执行指定选项直至终止,之后继续执行策略π的整个过程。
集成学习(ensemble learning)是一类常用的机器学习方法[9]。这类方法构建若干个个体学习器,然后通过一定策略将它们结合,最后获得一个优于个体学习器的强学习器。
2 策略迁移相关工作
策略迁移问题指给定一组源任务M1,M2,…,MK和对应的专家策略,在目标任务上,学生策略π通过从源策略中迁移知识来帮助学习,其中1 ≤i≤K[10]。
早期的策略迁移工作中往往研究一对一的迁移,即K=1。此类方法需要假设源策略在目标任务上也是接近最优的,而这个假设在复杂场景中不太可能满足。最近的工作主要研究一对多的策略迁移问题。在这种问题中,每一个源策略可能只在某些时刻对目标任务有效,因此相关工作的研究关键在于如何选择当前时刻最适合于目标任务的策略。Li等人[11]和Yang 等人[7]分别提出了利用选项进行策略迁移的方法CAPS(context aware policy reuse)和PTF(policy transfer framework)。两种方法都将策略迁移建模为选项学习问题,估计出选项的价值,选择价值最高的选项对应的源策略进行迁移。然而,选项的价值估计会有误差,任务场景越复杂价值估计的误差会越大,直接根据价值进行选择可能会误选到不适合目标任务的源策略,造成负迁移。因此,本文提出的SEPT 方法旨在降低选项价值估计误差带来的负面影响。
3 随机集成策略迁移方法
3.1 方法总览
图1 为SEPT 算法框架。与PTF 一样,在SEPT中,智能体用于策略更新的方法不受限制,既可以使用值函数方法,也可以使用策略梯度方法。首先,SEPT 将源策略库中的每一个策略设置为选项,用神经网络生成其终止概率。之后通过以下流程进行训练:智能体与环境进行交互学习策略,交互结束时将状态转移四元组(s,a,r,s′)存入回放池里;利用回放池的数据更新源策略对应选项的终止概率网络;终止概率网络输出当前状态对应的各选项的终止概率,利用终止概率计算每个源策略的概率权重;根据概率权重,将源策略集成为教师策略;教师策略对智能体的策略进行策略蒸馏[12],实现知识迁移,智能体策略完成更新,至此一轮训练结束,重复执行训练流程。接下来将从选项终止概率更新、集成教师策略和策略蒸馏与更新三方面具体说明。
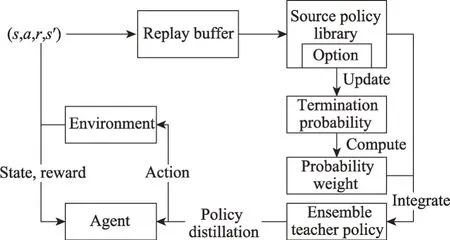
图1 随机集成策略迁移框架Fig.1 Framework of stochastic ensemble policy transfer
3.2 选项终止概率更新
在智能体与环境交互过程中,状态转移四元组(s,a,r,s′)被存储到回放池以用来更新选项价值函数和终止概率。对选项进行调用的动作模式是选择价值最高的选项进行调用,直到基于终止概率终止其调用,然后根据价值重新选择一个选项。
根据文献[8],基于这种动作模式从所有选项O中调用选项o的期望回报U*(s′,o)为:
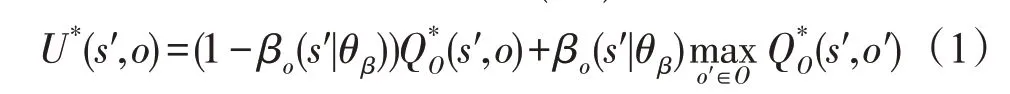
对U求终止概率参数θβ的梯度[13]:
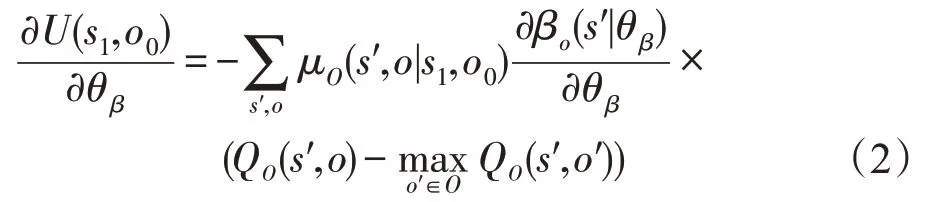
其中,μO(s′,o|s1,o0)为从初始状态(s1,o0)到(s′,o)的转移概率,无法直接求出,只能通过采样估计。根据文献[11]的讨论,此项可以省略。基于式(1)和式(2),下面提出更新选项价值函数QO和终止概率参数θβ的算法,其中αQ为更新QO的学习率,αβ为更新θβ的学习率。
算法1更新QO(s,o)和θβ

3.3 集成教师策略
选择选项价值最高的选项进行利用的方式在迁移任务中有一定的缺陷。这是因为选项的价值估计依赖于智能体提供的回放池里的信息,而这只包括整个环境信息的一小部分,仅凭这些信息显然无法对环境有完整的认识。因此,选项价值估计往往存在较大误差,以至于价值最高的选项对应的策略可能并非最优策略。
为了解决这个问题,提出了集成教师策略的方法。SEPT 并不选择一个策略进行迁移,而是从策略库中新生成一个教师策略πT,这个教师策略是各个选项内策略的集成。对于选项o,终止概率βo表示停止调用选项o的概率。显然,1-βo表示继续调用选项o的概率,这项数值越高,说明对应的选项相对于其他选项越可靠。本文用ρo来表示选项的可靠程度,ρo=1-βo。根据ρo来计算教师策略中选项o的概率权重可以降低价值估计的方差带来的负面影响。
接下来,本文使用Softmax来生成各个选项的概率权重Wo,即:

其中,T为温度参数,温度越大,得到的概率分布越平滑;温度越小则得到的概率分布越尖锐。得到教师策略πT后,πT会根据概率权重Wo选择一个选项o,然后输出选项内策略πo的动作概率分布。
3.4 策略蒸馏与更新
在得到教师策略输出的动作概率分布后,通过策略蒸馏[12]的方法向学生策略进行迁移。蒸馏的概念由Hinton等人提出[14],指一种通过让学生模型模仿教师模型的输出来进行知识迁移的监督学习方法。在策略蒸馏中,学生策略πs会尽可能减少其与教师策略πT在输出动作分布上的差别。具体地,设学生策略上采集的状态序列为轨迹τ,学生策略的梯度为下式:

其中,H为交叉熵,τt为轨迹τ在t时刻的状态。
在SEPT 中,智能体的策略在通过RL 学习的同时也通过策略蒸馏加速学习。这里采用Schmitt等人提出的方法[15],将策略蒸馏的损失和RL 的损失一同用来更新智能体策略参数θt:

其中,αRL表示RL 的学习率,αT表示策略蒸馏的学习率。在αT的设置上参考了PTF[7]的做法,设置了以训练轮数为输入的函数f(t)=0.5+tanh(3-0.001×t)/2作为动态学习率。这样,在训练早期,智能体的策略还不完善时,智能体更倾向于学习教师策略;而随着训练时间逐渐变长,智能体本身的策略趋近完善,则减小教师策略的影响。
4 实验与讨论
为验证本文算法性能,本章在同类型工作中常用的两种环境进行实验,分别是Gym[16]中的Gridworld和Pinball。本文比较了SEPT 和当前表现最好的迁移强化学习方法PTF的性能,两者的智能体算法设定为A3C[17]。为了保证公平性,PTF的超参数全部按其论文提供的进行设置。同时也用A3C作为基线来进行对比,以便确认迁移是否有效果。
4.1 Gridworld环境
在Gridworld 实验里,智能体在栅格世界中随机选择一点出发,目标是走到指定的终点。Gridworld是离散环境,智能体的动作空间为上下左右,表示智能体向指定的方向移动一格。状态空间为智能体坐标与周围一格距离内墙的分布。在Gridworld中设定了四个不同终点的源任务,在这四个源任务上训练了四个策略作为源策略库以供迁移。
一般来说,源任务与目标任务越相似,迁移难度越小。设计了两组迁移难度不同的场景进行实验。简单场景中有一个源任务与目标任务较为相似,即两者的终点距离很近,迁移难度比较小;困难场景中所有源任务的终点与目标任务都相距较远,迁移难度比较大。如图2 和图3 所示,黑色部分代表墙,四个蓝色的点代表源任务的终点,红色的点代表目标任务终点。

图2 Gridworld上的简单场景Fig.2 Simple scenario on Gridworld
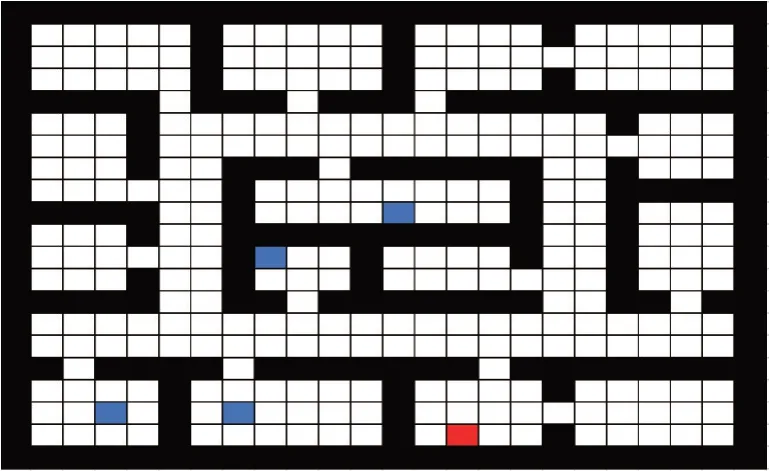
图3 Gridworld上的困难场景Fig.3 Hard scenario on Gridworld
实验中,智能体的单轮最大步数为99,回报折扣率γ设置为0.99,选项更新的学习率αβ设置为1×10-3,智能体策略更新学习率αRL设置为3×10-4,生成权重的温度T设定为1。最后结果为图4和图5。

图4 简单场景上的折扣回报Fig.4 Discount return on simple scenario
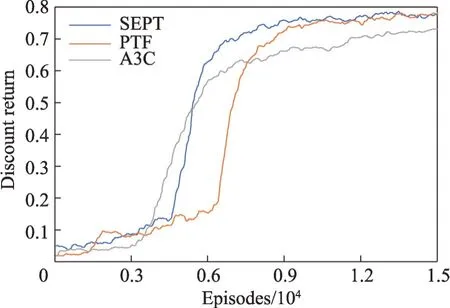
图5 困难场景上的折扣回报Fig.5 Discount return on hard scenario
4.2 Pinball环境
在Pinball 环境中,智能体控制一个弹球通过一个由各种多边体障碍物组成的迷宫,到达指定的终点。Pinball是连续环境,弹球的动作空间为水平方向和垂直方向的加速度,状态空间为弹球的坐标和速度。具体如图6所示,蓝点为弹球,红点为指定终点。

图6 Pinball环境Fig.6 Pinball scenario
以左上角、右上角和右下角为终点设置了三个源任务,并训练策略作为源策略库以供迁移。实验中,智能体的单轮最大步数为500,回报折扣率γ设置为0.99,选项更新的学习率αβ设置为1×10-3,智能体策略更新学习率αRL设置为3×10-4,生成权重的温度T设定为0.25。最后结果为图7。
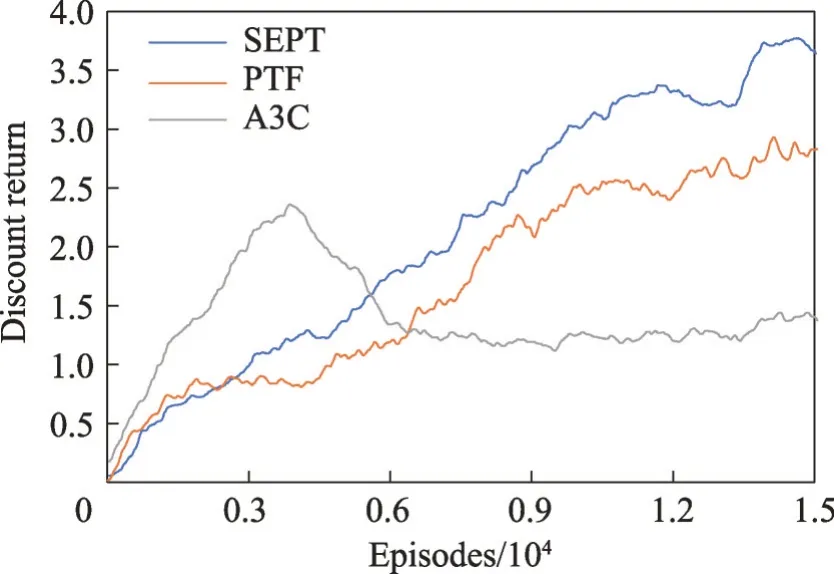
图7 Pinball场景上的折扣回报Fig.7 Discount return on Pinball scenario
从结果来看,比起其他方法,SEPT性能上有明显提升。这是因为弹球环境比较复杂且状态空间是连续的,选项价值估计会有比较大的误差,智能体会经常选中不合适的源策略,导致迁移效果较小甚至出现负迁移。而SEPT的教师策略受影响较小,能够持续进行正向迁移。
5 结束语
本文提出了一种随机集成策略迁移方法SEPT。这种迁移强化学习方法将源策略设置为选项并对选项进行持续更新。之后根据选项的终止概率生成每个选项内策略对应的概率权重,集成出教师策略,利用教师策略来指导学生策略进行学习。实验表明SEPT 的性能超过了已有的策略迁移方法,能明显加速智能体的训练。
