一种改进IE-AlexNet的少数民族文字图像识别方法*
2022-11-10杨秀璋周既松陈登建刘建义宋籍文
杨秀璋,周既松,武 帅,2,陈登建,刘建义,宋籍文
(1.贵州财经大学信息学院,贵州 贵阳 550025;2.涟水县财政局;3.贵州高速公路集团有限公司)
0 引言
随着文本信息数字化程度不断提升,模式识别技术被广泛运用于档案信息化应用中[1]。部分档案由于以手写体为主,需要对其进行手写体字符识别(Optical Character Recognition,简称OCR),以获取较为准确的文字信息[2]。整个过程主要包括图像预处理、特征提取和分类器分类,其中特征提取最为关键。传统手写体字符识别方法在提取目标书写体图像信息时,能较好地提取手写体空间、字体轮廓信息,但对复杂环境下手写体图像的处理存在准确率低和识别效果不佳的现象[3]。此外,当前少数民族古文字研究集中于艺术考究和字形释义,缺乏利用深度学习技术自动化识别文字,且古文字主要通过古籍、雕刻、木刻或碑刻存在,存在大量噪声,数字化读取困难[3]。针对上述情况,本文提出一种改进IE-AlexNet 神经网络的少数民族文字图像识别方法,一定程度上提升了对复杂环境下手写体图像的关键特征提取效果,提高模型整体分类效果。该方法有较好的鲁棒性和准确性。
1 相关研究现状
现阶段,手写体字符识别的研究主要集中于对中文和英文手写体文字的识别,但针对少数民族古文字手写体识别研究相对较少。传统手写体字符识别方法在识别少数民族古文字手写体时,由于其手写体字型变化,数字化识别效果欠佳。因此,如何运用计算机视觉技术和档案数字化方法构建一个能够智能化准确识别少数民族古文字的模型,一定程度上对提高少数民族档案数字化建设起到积极作用,具有较高的研究意义,是研究者们迫切需要解决的问题。
热依曼·吐尔逊等[4]融合高斯模型和隐马尔可夫模型,设计了一种维吾尔语联机手写体识别系统,利用高斯模型模拟维吾尔语整词的静态特征和隐马尔科夫模型模拟书写笔迹的动态特征。王晓娟等[5]针对数字手写体图像区域进行归一化处理,提出一种基于BP神经网络的图像识别方法。杨秀璋等[6]针对水族古文字传承以刺绣、碑刻、木刻等为主,文字清晰度不高,数字化读取困难的现象,提出一种基于自适应图像增强和区域检测的水族文字提取与分割算法。姜文等[7]针对手写体维吾尔文字字符识别过程中的特征提取环节,提出一种基于方向线素特征的手写体维吾尔文单字字符笔迹特征的KNN分类识别算法。杨秀璋等[8]考虑到古文字的字形变化特点,提出一种改进卷积神经网络的阿拉伯文字图像识别方法。
此外,深度学习技术的不断成熟,为手写体字符识别提供了新的解决思路。本文在AlexNet 神经网络的基础上融合图像增强技术,一定程度上提升了对阿拉伯文字手写体关键特征的提取效果,提高了模型整体分类效果。将本文方法运用于手写体阿拉伯文字的识别,可以一定程度上拓宽手写体文字识别的研究范畴,同时也为本研究团队后期对水族文字识别提供理论基础,给少数民族数字化档案建设提供实际应用的可能性,这是我们研究的意义所在。
2 系统设计
本文提出一种融合自适应图像增强和深度学习的IE-AlexNet(Image Enhancement AlexNet)模型,并对复杂环境下的阿拉伯文字图像数据集进行实验,模型设计的研究内容如下。
2.1 总体框架
本文设计并实现了IE-AlexNet 模型,其总体框架如图1所示。具体实现步骤如下。
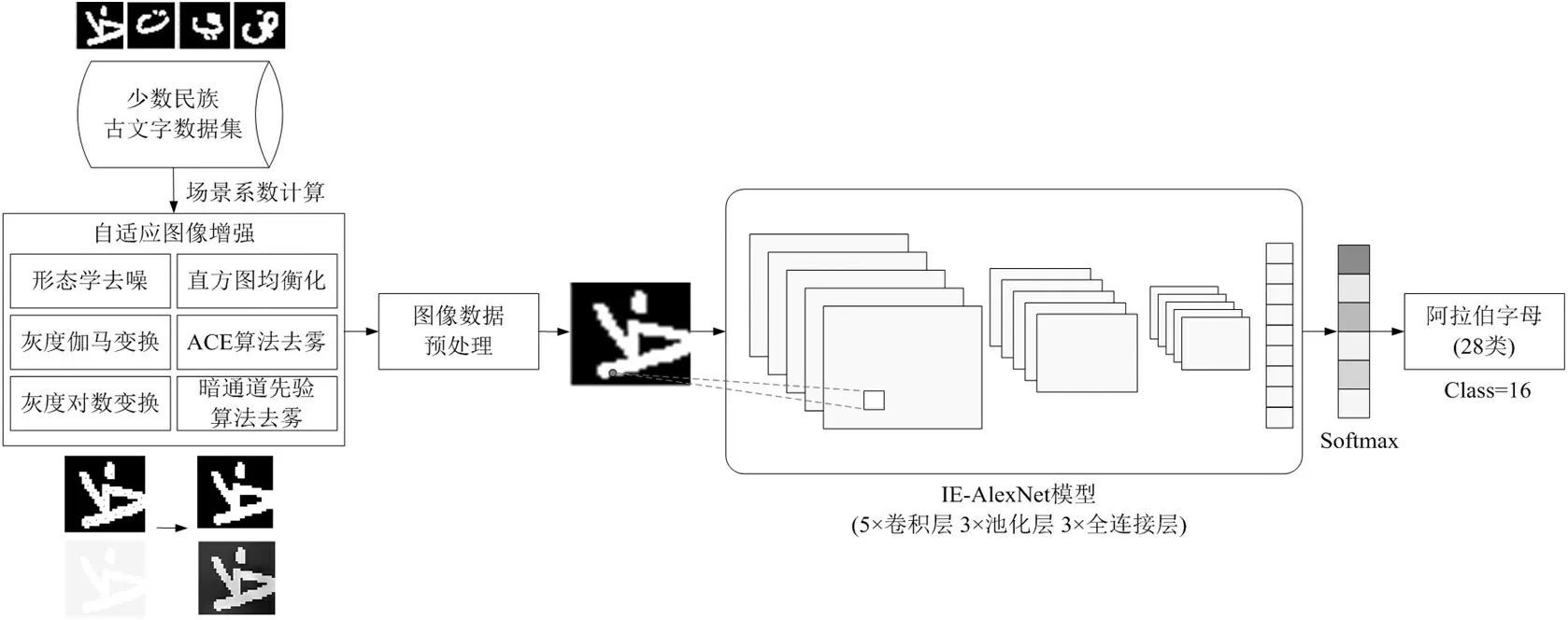
图1 复杂环境下少数民族文字图像识别的总体框架
⑴模拟现实场景采集并构造阿拉伯文字图像数据集,并将其随机划分为训练集和测试集。
⑵计算场景系数,构建自适应图像增强得算法实现去噪,增强图像质量,共包括形态学去噪(闭运算)、灰度伽马变换、灰度对数变换、直方图均衡化、ACE算法去雾和暗通道先验去雾六种算法。
⑶对所有图像进行预处理,包括图像向量表征、标准化处理、形状修改和编码转换等。
⑷构建IE-AlexNet模型该模型包括5层卷积层、3层池化层和3个全连接层,并优化模型超参数。
⑸通过构建Softmax 分类器实现阿拉伯文字图像识别,对比少数民族文字识别的性能。
2.2 AlexNet模型
AlexNet 神经网络是由Alex Krizhevsky 等人[9]于2012 年提出的首个应用于图像分类的深层卷积神经网络,并在当年举办的ImageNet Large Scale Visual Recognition Competition(简称ILSVC)比赛中以15.3%的top-5测试错误率获得了分类任务的冠军,其网络结构详如图2所示。该网络由五个卷积层和三个全连接层组成。卷积层用于提取特征,池化层用于实现特征降维,激活函数用于获取非线性特征,全连接层起到分类作用。输入图像经过卷积层特征提取和全连接层分类操作之后,输入到具有1000 个节点的Softmax分类器中实现图像分类。
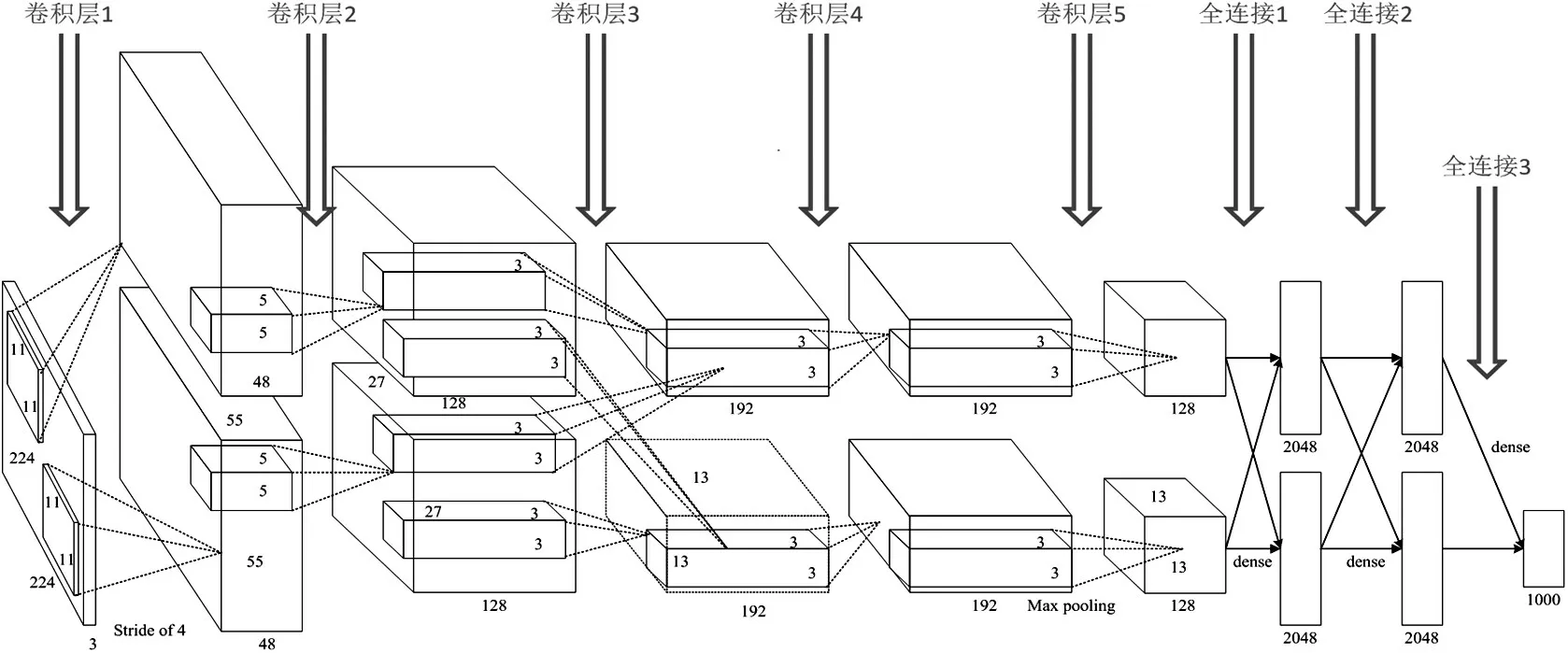
图2 AlexNet模型结构
2.3 自适应图像增强
在真实场景中,少数民族文字图像通常存在于古籍、木雕或碑刻中,因此存在大量的噪声,导致传统图像识别方法效果不理性。本文结合真实场景噪声特点(含文字噪声、全局噪声、年代噪声、亮度噪声和光照影响),设计了一种自适应图像增强的算法。该算法通过计算场景系数,针对不同场景构建对应的阈值,再开展相应的图像增强处理,包括形态学、灰度伽马变换、灰度对数变换、直方图均衡化、自动色彩均衡(Automatic Color Equalization,简称ACE)算法[10]和暗通道先验(Dark Channel Prior,简称DCP)去雾算法[11]。
图3详细展示了四种场景下的阿拉伯文字图像处理效果。图3(a)存在字内噪声,图3(e)利用形态学闭运算有效去噪;图3(b)存在全局噪声,通常存在于雕刻和木刻的扫描图像,图3(f)利用ACE 算法有效消除中心文字的内部噪声;图3(c)属于年代噪声,年代久远的古籍会导致字体不清晰,图3(g)是图像增强方法消除噪声的效果;图3(d)是亮度或光线、过曝导致的噪声,图3(h)利用暗通道先验去雾处理的效果图。

图3 复杂环境下自适应图像增强算法处理的效果图
3 实验评估
本文进行了详细的对比分析,利用Keras和Sklearn构建模型。实验环境为Windows 10 操作系统,处理器为Inter(R) Core i7-8700K,GPU 为GTX 1080Ti,内存为64GB。
3.1 数据集和模型参数
数据集是来自Kaggle 的阿拉伯字母手写图像,并结合真实场景模拟噪声,最终生成如表1 所示的数据集。其中,训练集共计13440幅字符图像,测试集共计3360 幅字符图像,涉及28 类阿拉伯文字。同时,按照10%的比例进行噪声混淆。每幅图像大小为32×32,并经过图像预处理修改为统一大小。
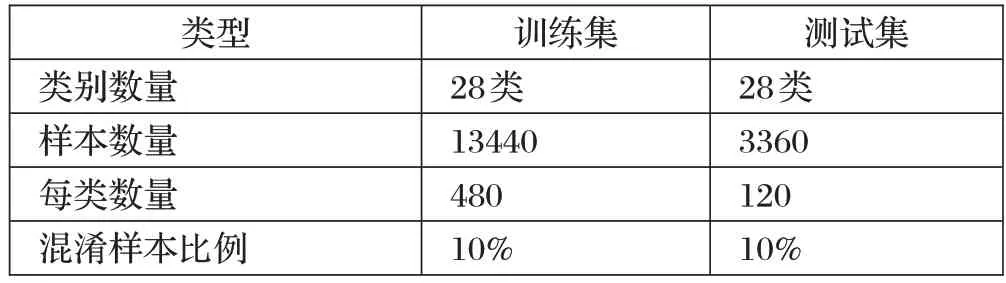
表1 阿拉伯手写文字数据集
为更好地评估IE-AlexNet 模型,本文所有实验在相同的数据集及场景下实现。此外,为避免某些异常实验结果的影响,本文最终的实验结果为十次结果的平均值。
构建的AlexNet 模型的超参数如表2 所示,包括层类、核尺寸、通道数和函数。AlexNet 共包括5 个卷积层、3 个池化层和3 个全连接层,并且本文添加BN和Dropout函数,防止出现过拟合现象。

表2 模型超参数
3.2 评价指标
实验评估指标为精确率(Precision)、召回率(Recall)、F1值(F1-score)和准确率(Accuracy),它们是经典的分类评估指标,其计算过程如公式⑴~公式⑷所示。

3.3 实验对比分析
本文与经典机器学习、现有深度学习进行了详细的对比实验,实验结果如表3 所示。其中,本文IEAlexNet 模型的精确率为0.9564,召回率为0.9554,F1值为0.9559,准确率为0.9553,均优于现有方法。

表3 各模型少数民族文字识别实验结果对比
此外,本文方法的F1值比机器学习中表现最好的SVM 模型提升27.32%,比单层CNN 和双层CNN 模型提升3.49%和3.13%,比TextCNN 模型提升0.87%,比文献[8]方法提升0.29%。该实验充分说明本文构建的IE-AlexNet 能较好地识别阿拉伯文字图像,并应用于复杂场景下的少数民族古文字识别领域。
同时,本文对比了28 种阿拉伯字母的识别效果,其对应字母、类别和F1值如表4 所示。表现最好的阿拉伯文字包括第0 类、第1 类、第4 类、第11 类和第22类,其F1值分别为0.9917、0.9916、0.9876、0.9789、0.9746,这些文字相对于其他文字特点更明显,更容易被IE-AlexNet 识别。而具有相似的文字识别效果相对较差,比如第10类和第9类,第7类和第8类,第2类和第3类等。

表4 IE-AlexNet模型识别各类阿拉伯文字的实验结果
图4 展示了28 种阿拉伯字母的识别结果对应的混淆矩阵,蓝色对角线表示正确识别类别,红色区域是误报或漏报数量。

图4 IE-AlexNet模型识别结果的混淆矩阵
3.4 图像增强及模型性能比较
为突出本文模型自适应图像增强的效果以及性能,本文分别进行了对比实验。表5 展示了五种经典模型是否使用图像增强优化的前后效果。其中,使用自适应图像增强算法后,KNN 模型的F1值提升14.46%,RF 模型的F1值提升13.59%,单层CNN 模型的F1值提升11.97%,文献[8]模型的F1值提升3.80%,本文AlexNet 模型的F1值提升3.49%。该实验充分说明本文方法能有效实现不同场景的图像增强,去除少数民族文字图像的噪声,具有更强的鲁棒性和准确率,并能有效识别阿拉伯文字或其他少数民族古文字,具有一定的应用前景和实用价值。

表5 各模型迁移场景的情感分析实验结果对比
最后,本文对比了深度学习模型的训练误差随Epoch 下降曲线,如图5 所示。其中,IE-AlexNet 模型能以更快的速度下降并拟合,最终趋于0.1822 为主。相较于其他模型,本文针对该数据集的图像识别效果更佳,性能更好。
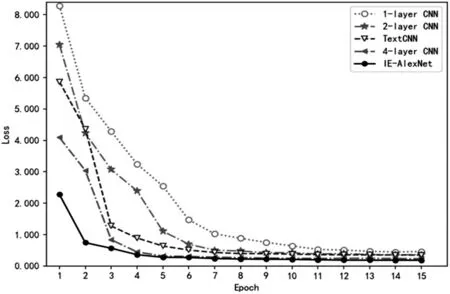
图5 实验误差变化曲线
4 结束语
传统图像识别方法较难识别少数民族文字,而且古文字主要以古籍、雕刻、木刻或碑刻而存在,利用深度学习技术自动化识别,存在大量噪声,数字化读取困难。
本文提出一种融合自适应图像增强的深度学习IE-AlexNet 模型,旨在识别复杂场景下的阿拉伯文字图像。实验结果表明,本文方法能有效识别阿拉伯文字图像,并去除噪声,其F1值为0.9559,准确率为0.9553,IE-AlexNet 的F1值比机器学习中表现最好的SVM 模型提升27.32%,比单层CNN 和双层CNN 模型提升3.49%和3.13%,比TextCNN 模型提升0.87%,比文献[8]方法提升0.29%。
该实验充分说明了本文构建的IE-AlexNet能较好地识别阿拉伯文字图像,其应用于复杂场景下的少数民族古文字识别领域,有较好的鲁棒性和准确率,有一定的应用前景和实用价值。
