基于长短期记忆神经网络的太阳耀斑短期预报
2022-11-09何欣燃钟秋珍崔延美刘四清石育榕闫晓辉王子思禹
何欣燃 钟秋珍 崔延美 刘四清 石育榕 闫晓辉 王子思禹
1(中国科学院国家空间科学中心 北京 100190)
2(中国科学院大学 北京 100049)
3(中国科学院空间环境态势感知技术重点实验室 北京 100190)
0 引言
太阳耀斑是一种剧烈的太阳爆发现象,是太阳质子事件和日冕物质抛射发生的先兆现象之一。与之伴随发生的高能粒子流及其辐射对空间环境产生剧烈的冲击,对空间飞行器或航天员造成潜在危害。当耀斑辐射来到地球附近时, 光致电离使得电离层D 层的电子密度增加,引起无线电通信中断。太阳耀斑预报研究具有重要的实用价值和科学意义。一方面太阳耀斑预报为提前应对电离层突然扰动、太阳质子事件和地磁暴提供了重要的警报作用;另一方面,太阳耀斑预报对于理解太阳活动事件的原理具有重要的指导意义。
由于耀斑爆发对空间天气的重要影响,研究提出了多种耀斑预报方法。考虑到太阳活动区与耀斑爆发之间的紧密联系,耀斑预报方法大多采用活动区拓扑特征参数和光球磁场特征参数,根据当前观测情况预测未来耀斑的发生。耀斑预报方法主要包括:基于专家系统的方法[1—4];利用观测数据建模的方法,包括统计分析中的泊松统计[5]、多元线性回归模型等[6—8],以及机器学习中的支持向量机[9—10]、神经网络[11—15]、径向基函数网络[16]、线性判别分析[17]、随机森林[18]、相关向量机[19]等。
目前普遍认为浮现磁通量区在耀斑产生中起重要作用[20],活动区的演化过程对于耀斑活动具有重要影响[21],活动区当前观测以及之前的观测共同影响了耀斑的发生。Huang 等[22]利用光球磁场作为预报因子,分别建立耀斑预报的神经网络模型和决策树模型,随着预报因子时序信息的引入,两种预报模型的预报精度得到不断提高。
近年来, 机器学习中的深度学习方法取得了快速发展[23—24], 并成功应用于语音识别、自然语言处理、目标识别和分类等领域[25—26]。深度学习方法可以从原始观测数据中自动学习特征参量并建立模型,Li等[27]和Huang 等[15]利用卷积神经网络的自动图像特征提取能力建立太阳耀斑预报模型。同时,深度学习方法中的循环神经网络还可以学习到数据的时序特征,Liu 等[28]利用SHARP 数据和耀斑历史特征,基于长短期记忆网络(LSTM)方法,分别构建了未来24 h≥M5.0 级、≥M 级和≥C 级耀斑预报模型。
通常在空间天气预报业务中,未来48 h 的耀斑预报是重要的内容之一。本文选取SHARP 活动区磁场参量,利用深度学习中的长短期记忆网络,建立未来48 h≥M 级太阳耀斑预报模型。在建模过程中利用XGBoost[29]计算各磁场参量的特征重要性,筛选出6 个参量作为模型输入,最后通过与其他机器学习方法的预报评估来分析模型对太阳耀斑的预报能力。
1 数据
太阳耀斑的触发和能量释放与磁场密不可分,当储存的磁能在日冕中突然释放时就发生了耀斑。由于日冕磁场还未能准确测量,因此在太阳耀斑预报建模过程中,通常采用活动区光球磁场作为预报输入。本文太阳活动区数据采用SDO/HMI 的SHARP(Spaceweather HMI Active Region Patch)数据** http://jsoc.stanford.edu/doc/data/hmi/sharp.htm。该数据提供了活动区的相关特征参量。使用的数据集为2010 年5 月到2017 年5 月所有活动区样本,样本间隔为96 min,考虑了SHARP 数据中提供的10 个活动区物理参量,包括总无符号电流螺度、总光球磁自由能密度、总无符号垂直电流、净电流螺度绝对值、正负极净电流绝对值、总无符号磁通量、活动区强磁场面积、平均光球磁自由能、中性线磁通量以及剪切角大于45°的像素比例。太阳耀斑数据来源于美国国家地球物理数据中心(National Geophysical Data Center, NGDC)整理的数据列表**ftp://ftp.ngdc.noaa.gov/STP/space-weather/solar-data/solar-features/solar-flares/x-rays/goes/xrs/。太阳耀斑根据其软X 射线峰值流量分为B,C,M,X 四级。
在构建数据集时,利用滑动窗方法[30—33]将光球磁场观测的序列信息引入耀斑预报系统,即引入活动区演化信息。滑动窗方法的原理如图1 所示,其中t为当前时刻的观测量,随着时间的推移,t—WΔt到t之间的观测随时间滑动,称为滑动窗,这里W为滑动窗尺寸。在实际应用中,序列需要在初始位置增补W个点(一般情况下,序列的初始值被重复W次),使得滑动窗可以从原始序列的初始位置处运行。
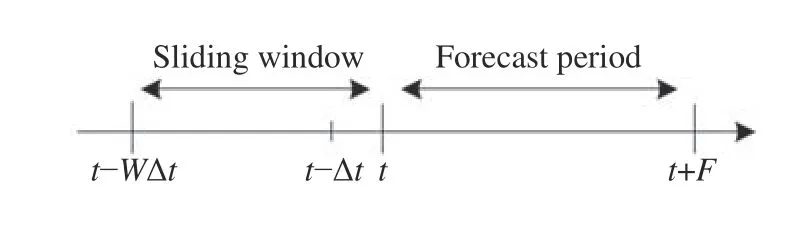
图1 滑动窗口原理Fig. 1 Sliding window principle
滑动窗方法的关键问题是如何确定窗口大小。根据Huang 等[22]互信息函数的计算结果,建议滑动窗的总时间长度不超过三天,因此这里选取W=15,时间间隔Δt=96 min,滑动窗口总长度为24 h(15×96 min),预报时段F=48 h。将16 条(W+1)数据作为一个样本,用于预测未来48 h 内该活动区的耀斑发生情况。
在建立耀斑样本时,规定若是滑动窗口最后时刻(t)的未来48 h 内发生了≥M 级的耀斑事件(t+F时间范围内),即标注为正样本,若未发生则标注为负样本。为了使训练集和测试集都包含每个活动区的数据,在划分数据集时,按照9∶1 的比例对每个活动区的数据进行随机抽取,并分别放入训练集和测试集,保证训练集和测试集包含所有活动区的数据。经过 这 样 的 处 理 后,2010 年5 月 至2017 年5 月的SHARP 数据集中,训练集正样本2098 个,负样本41809 个,测试集正样151 个,负样本13953 个,总计58011 个样本。
2 耀斑模型
2.1 长短期记忆神经网络
考虑到本文样本所使用的滑动窗口时长较长,选择使用深度学习中的长短期记忆神经网络(LSTM)作为模型主体。长短期记忆神经网络(LSTM)作为循环神经网络(RNN)的改进,引入了门控机制,让模型在学习的过程中自行学习需要“记忆”和“遗忘”的内容,对于长时间序列的处理具有很大优势。
LSTM 主要结构为遗忘门、输入门和输出门。遗忘门(Forget Gate)的任务是接受上一个单元模块传过来的输出,并决定要保留和遗忘该记忆单元的部分。输入门(Input Gate)的作用是确定当前细胞需要记忆多少上个细胞的状态,针对遗忘门中丢弃的属性信息,在本单元模块找到相应的新属性信息,添加进去,以补充丢弃的属性信息。输出门(Output Gate)用于确定细胞状态部分需要的输出,然后对细胞状态进行处理,由遗忘门和记忆门给输入赋予权重,得到最终需要输出的信息。在图2 显示的重复模块结构中,加蓝底的圆圈表示4 个神经网络层,其以一种复杂而高效的特殊方式进行交互。图2 中各符号意义的说明见表1。

表1 图2 中各符号含义的说明Table 1 Implication of some symbols in Figure 2
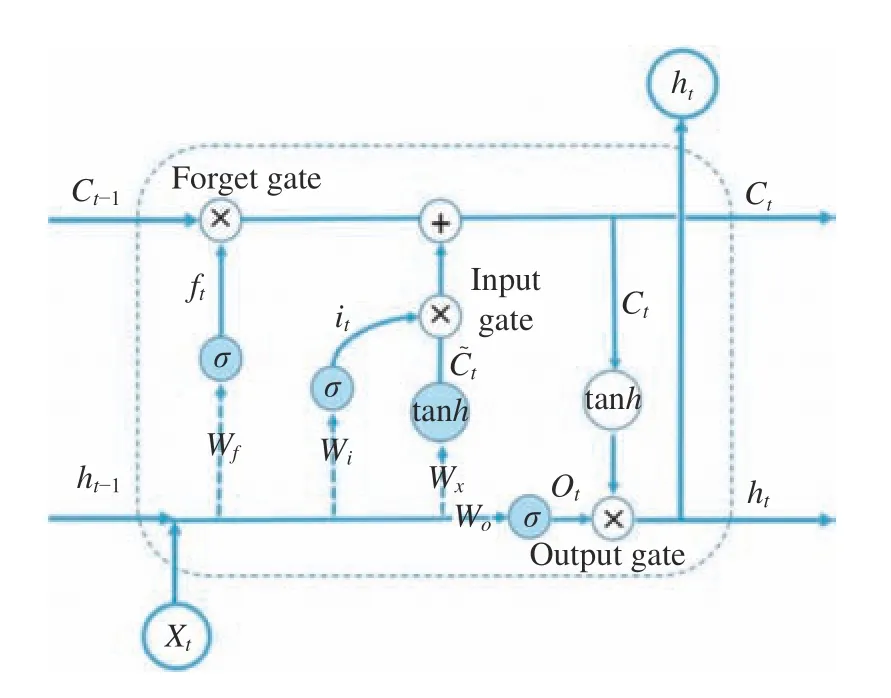
图2 LSTM 中隐含层重复模块结构Fig. 2 Architecture of repeat module in the hidden layer of LSTM
LSTM 的关键是细胞状态(例如Ct和Ct-1),其类似于一条传送带,直接在整个链上运行,只有少量的线性交互,这样信息在上面流动就很容易保持不变。图2 给出了LSTM 记忆单元的工作流程。输入由三部分组成,第一是当前时刻的输入xt,第二是上一时刻的隐藏层输出ht-1,第三是细胞中存储的上一状态Ct-1。具体步骤如下。
第一步 确定哪些信息需要经过遗忘门被丢弃掉,输入经过一次非线性变换得到遗忘门函数,即
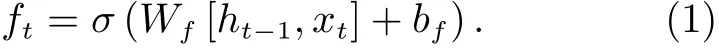
第二步 确定哪些新的信息将被存储,经过两次非线性变换,可以分别得到输入门函数和单元候选状态为
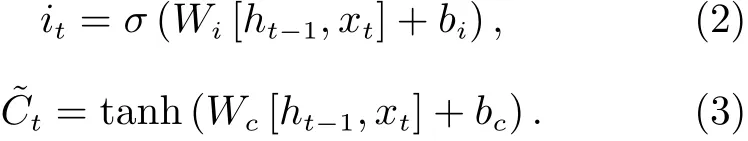
第三步 对当前时刻的单元状态进行更新,此时需要通过遗忘门和输入门对当前和历史信息进行控制,有
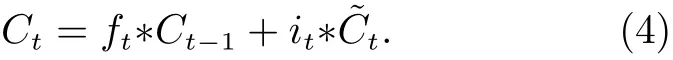
第四步 当单元状态被更新后,需要确定哪些信息即将被输出,这里不仅要通过对输入进行非线性变换得到输出门函数,同时还要对已更新的单元状态信息进行输出控制,得到当前时刻神经元的输出,即
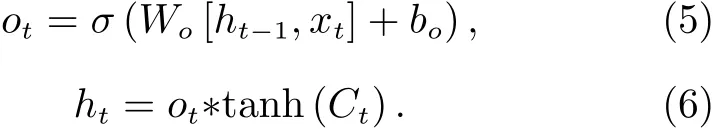
上述过程中用到的两个激活函数分别是sigmoid 函数和tanh 函数, 即
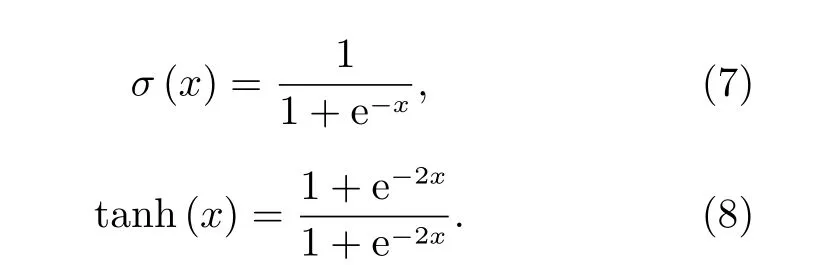
上述Wf,Wi, Wc, Wo和bf, bi, bc, bo分别表示网络结构中每一步的权重和偏置。
在建立太阳耀斑预报模型过程中,还采用了Dropout[34]技巧训练深度神经网络。在每个训练批次中,通过忽略一部分神经元(让这部分隐层节点的权重为0),可以明显减少过拟合现象。
2.2 特征参数选择
在使用LSTM 模型进行训练之前,首先利用极端梯度提升器(eXtreme Gradient Boosting, XGBoost)[29]对SHARP 数据中各物理参量进行特征重要性分析,根据重要程度选择特定的物理参量,用于构建最终的训练集和测试集。
XGBoost 是机器学习集成学习中的Boosting[35]方法之一,Boosting 方法中将弱学习器通过串联的方式进行叠加,每个弱学习器都拟合前一个弱学习器的残差,合成一个强学习器。XGBoost 的默认弱学习器为CART 树[36],树模型有着良好的特征选择能力。选取特征主要有三种模式,分别是权重(weight)、信息增益(gain)、覆盖率(cover)。由于每个决策树都不会生长完全,因此每个特征所使用的次数均不相同,其中Weight 模式计算每个特征在分裂节点时被使用的平均次数,使用次数越多,特征越重要。信息熵用于描述一个系统信息的不确定性程度,而信息增益代表在一定条件下(使用某个特征分类),系统信息熵(不确定性)减少的程度。Gain 模式为计算在每个特征作为分裂节点的特征时,其平均信息增益,CART 树在进行分裂时,选择信息增益最大的特征进行优先分裂,因此Gain 模式下的得分反映了特征对分类的优先级。由于不是每个样本都需要所有特征进行分类,在Cover 模式为所有CART树中,以每个特征作为分裂节点的特征时,所有CART 树中所覆盖的样本平均数量,因此Cover 模式的得分体现了特征的普适性。
利用XGBoost 分别计算了选取的SHARP 数据集中10 个物理参量的特征权重、增益率、覆盖率(见图3~5)。从图3 可以看出,活动区强磁场面积、剪切角大于45°的像素比例以及总无符号电流螺度在所有基分类器中使用次数更多,通常使用越多的特征也会对分类起到更多的作用。从图4 可以看出,中性线磁通量具有最多的平均信息增益,这说明在使用特征中性线磁通量进行分裂节点时,对整个系统具有最大的信息增益。从图5 可以看出,中性线磁通量、正负极净电流绝对值、总无符号电流螺度具有较高的覆盖率,这说明多数样本都使用了上述特征。同时为了不移除掉过多特征导致模型效果下降,增加了在三种特征重要性计算中得分都不低的净电流螺度绝对值。综合考虑,选取总无符号电流螺度、正负极净电流绝对值、净电流螺度绝对值、活动区强磁场面积、中性线磁通量、剪切角大于45°的像素比例这6 个物理参量作为模型输入参数,分别记为L1,L2,L3,L4,L5,L6。 经过特征参数选择后,t预报时刻的样 本 数 据 集 为[[L1(t—15*96),L1(t—14*96),···,L1(t)],[L2(t—15*96),L2(t—14*96),···,L2(t)], [L3(t—15*96),L3(t—14*96),···,L3(t)], [L4(t—15*96),L4(t—14*96), ··· ,L4(t)], [L5(t—15*96),L5(t—14*96),···,L5(t)], [L6(t—15*96),L6(t—14*96),···,L6(t)]],共计96 个数据。
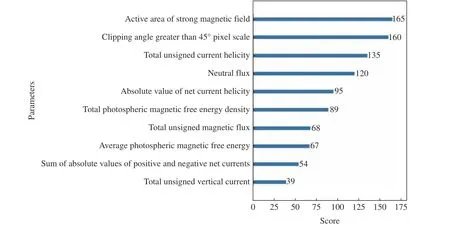
图3 10 个物理参量在所有弱学习器中的权重Fig. 3 Weights of ten parameters in all weak learners
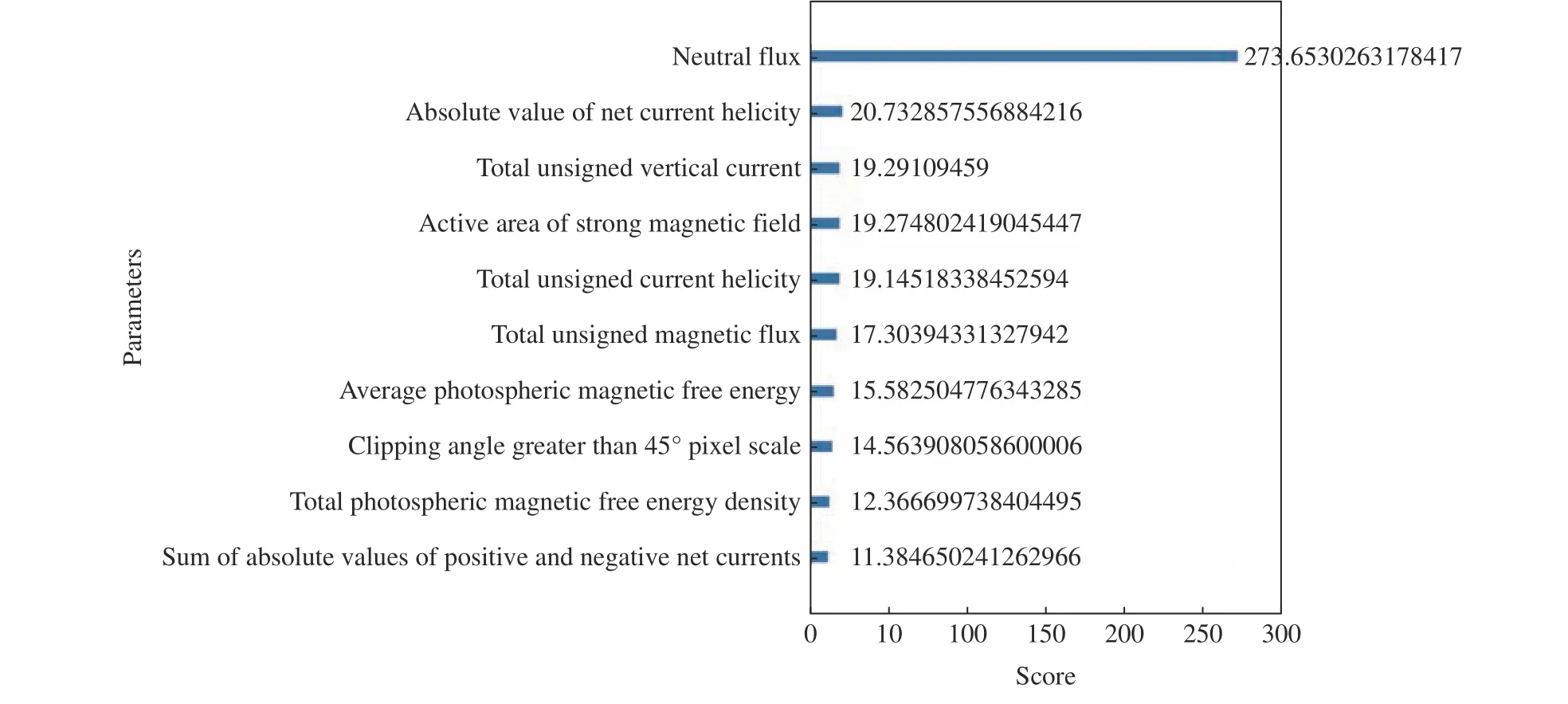
图4 10 个物理参量在所有弱学习器中的增益率Fig. 4 Gain rate of ten parameters in all weak learners
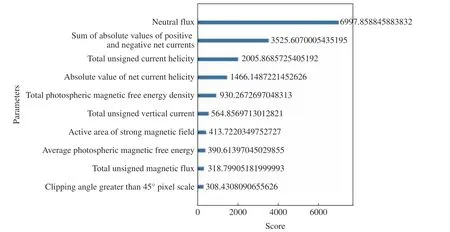
图5 10 个物理参量在所有弱学习中的覆盖率Fig. 5 Cover rate of ten parameters in all weak learners
2.3 模型建立
采用2015 年François Chollet 为ONEIROS 项目开发的深度学习框架keras 构建耀斑预报模型,模型结构如图6 所示,分别为输入层、LSTM 层1、Dropout 层1、LSTM 层2、Dropout 层2 以及全连接层(分类层)。其中输入层的输入维度为样本个数×时间步长×特征维度,由于时间步长=滑动窗口长度+1,因此输入维度为44022×16×6。LSTM 层1 的神经元个数为128 个,因此其输出维度为44022×16×128。Dropout 层1 的神经元保留概率为0.5,且不改变输出维度。LSTM 层2 的神经元个数为128 个,在LSTM 层2 需要返回到分类层,因此数据维度输出为44022×128。分类层的损失函数为二分类交叉熵损失,神经元个数为1,最终输出结果为0~1 之间的数值。
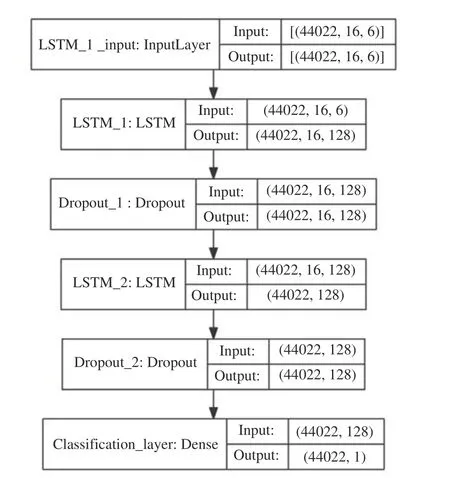
图6 LSTM 耀斑预报模型结构Fig. 6 LSTM flare prediction model structure
所使用的样本数据集存在较大数据不均衡问题,即正样本的个数远少于负样本,若是按照传统机器学习任务的做法,应该是补充正样本的数量,但是考虑到耀斑事件的发生频率很低,正负样本的不均衡反映了耀斑事件发生频率的客观事实,因此选择保留这样的数量差异。为了解决数据不均衡对模型效果的影响,对分类所使用的交叉熵损失函数进行修改,在正样本上增加了分类权重,增加的分类权重等于正负样本比例(1∶25),在模型训练时会让模型更侧重正样本进行训练,解决样本不均衡问题。
为了选取合适的阈值确定是否发生耀斑事件,这里通过不断调整阈值大小,计算出不同阈值下的报准率(TPR,定义符号RTP)和虚报率(FPR,定义符号RFP),即
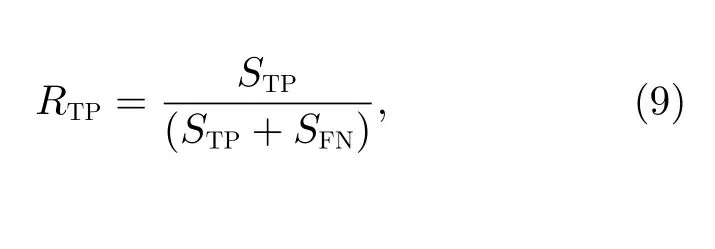
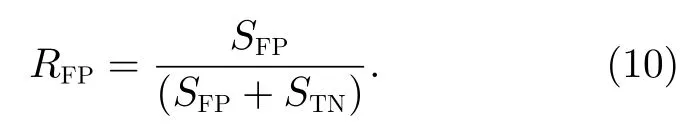
符号定义如下。
STP(True Positive, TP):原本属于正样本,被分类成正样本,记为真实的正样本。
SFN(False Negative, FN):原本属于正样本,分类成负样本,为耀斑事件被遗漏的样本,记为虚假的负样本。
SFP(False Positive, FP):原本属于负样本,分类成正样本,无耀斑发生的活动区被虚报的样本记为虚假的正样本。
STN(True Negative, TN):原本属于负样本,被分类成负样本,无耀斑发生的活动区被正确预报的样本记为真实的负样本(TN)。
绘制模型输出结果的ROC(Receive Operating Characteristic)曲线[37],如图7 所示。由于ROC 曲线越接近点(0,1),模型整体效果越好,因此筛选出到点(0,1)距离较小的部分点用于实验,实验结果表明当阈值为0.7334 时耀斑预测效果最好,选择0.7334作为分类的输出阈值,输出值大于分类阈值判定为正样本,反之为负样本。

图7 LSTM 耀斑预报模型ROC 曲线,图中红点为该模型的最佳阈值所对应的TPR 和FPRFig. 7 ROC curve of the LSTM flare prediction model. The red dots in the figure are the TPR and FPR corresponding to the optimal threshold of the model
3 结果与分析
使用二分类混淆矩阵评估模型的训练结果,选用报准率(RTP)、虚报率(RFP)、准确率(Accuracy,Rac-curacy)和真实技巧统计值(True Skill Statistics, TSS,ITSS, 临界成功指数)作为模型的评判标准。通过式(9)和式(10)可以看出,报准率越高,虚报率越低,说明模型的预报能力越强。通过如下公式可计算耀斑预报模型对于事件的预报准确率(Raccuracy)和真实技巧统计值(ITSS):
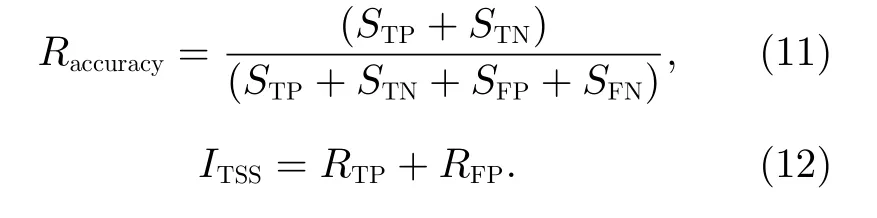
为了评估模型的预报结果,采用同样的数据集,利用机器学习中的支持向量机(SVM)、决策树C4.5、集成学习方法XGBoost、集成学习方法随机森林(RandomForest)、逻辑回归(Logistic Regression)等方法进行对比。支持向量机、随机森林、逻辑回归等是良好的分类器,但是缺乏对于太阳活动区时序信息的捕捉。
表2 和表3 给出了LSTM、 SVM、 XGBoost、RandomForest、 C4.5、逻辑回归等模型对未来48 h 太阳耀斑的预报评估结果。可以看出所提出的LSTM 模型报准率为0.7483,高于其他模型;虚报率与SVM 相当,略低于逻辑回归模型;准确率包含了对正负样本预报结果的评估,由于负样本比例较大,因此负样本的预报效果决定了预报的准确性,这些模型的预报准确性基本相当;TSS 评价指标综合考虑了报准率与虚报率的影响,LSTM 模型的TSS 评分为0.7402,高于其他几个模型。模型总体预报性能优于传统机器学习模型。
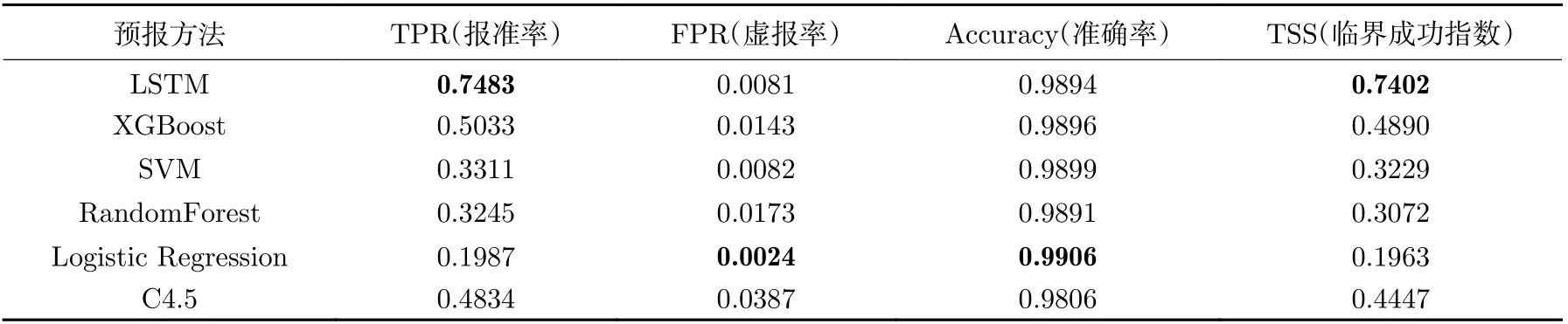
表2 不同模型预报结果评估(1)Table 2 Evaluation of forecast results of different models (1)

表3 不同模型预报结果评估(2)Table 3 Evaluation of forecast results of different models (2)
Li 等[27]利用SOHO 卫星MDI 载荷拍摄的磁图数据作为数据集,使用卷积神经网络(CNN)建立了太阳耀斑预报模型,Huang 等[28]利用SOHO/MDI 和SDO/HMI 拍摄的磁图,同样使用卷积神经网络(CNN)构建了多预报时段太阳耀斑预报模型,选取其对于未来48 h 的M 级及以上耀斑模型进行对比(见表4 和表5),相比使用磁图数据的CNN 模型,LSTM 预报模型的报准率略低于CNN 预报模型,而准确率、虚报率和临界成功指数等优于CNN 模型,并且从表5 可知,LSTM 预报模型的数据样本少于CNN 预报模型,如果增加LSTM 预报模型的数据样本数量,还可以有所提升。

表4 CNN 与LSTM 模型预报结果评估(1)Table 4 Evaluation of forecast results of CNN and LSTM models (1)

表5 LSTM 与CNN 模型预报结果评估(2)Table 5 Evaluation of forecast results of LSTM and CNN models (2)
建立未来48 h≥M 级太阳耀斑预报模型时,采用了SHARP 数据的时序物理参量作为输入参数。图8 和图9 分别给出了正样本和负样本中6 个物理参量和未来48 h 太阳X 射线的流量变化。可以看到正样本各参数在滑动窗口内变化较大,之后的48 h 内 发 生 了M8.4 级 耀 斑(2012 年3 月10 日17:44:00 UT);而负样本各参数在滑动窗口内较平稳,未来48 h 无≥M 级耀斑发生。
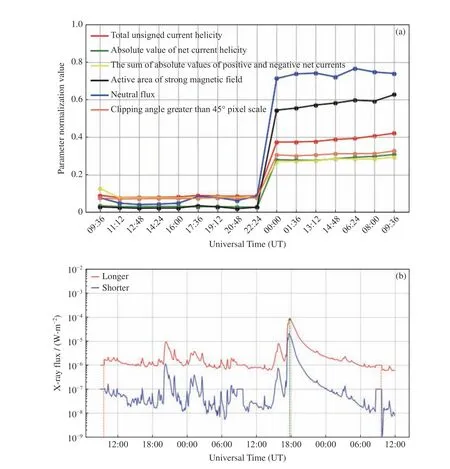
图8 正样本(2012 年3 月8 日09:36 UT 至9 日09:36 UT)各特征参数的变化(a)和GOES 卫星测量(2012 年3 月9 日00:00 至12 日00:00 UT)在该样本未来48 h 的X 射线通量变化(b)。橙色垂直虚线为模型预测范围,绿色虚线为耀斑事件(2012 年3 月10 日17:44 UT)Fig. 8 Positive sample (from 09:36 UT on 8 March 2012 to 09:36 UT on 9 March 2012) characteristic parameter change (a) and the GOES satellite measurement (from 00:00 UT on 9 March 2012 to 00:00 UT on 12 March, 2012) of the X-ray flux change of the sample in the next 48 h (b). Orange dashed line is the model prediction range, and the green dashed line is the flare event (17:44 UT on 10 March 2012)
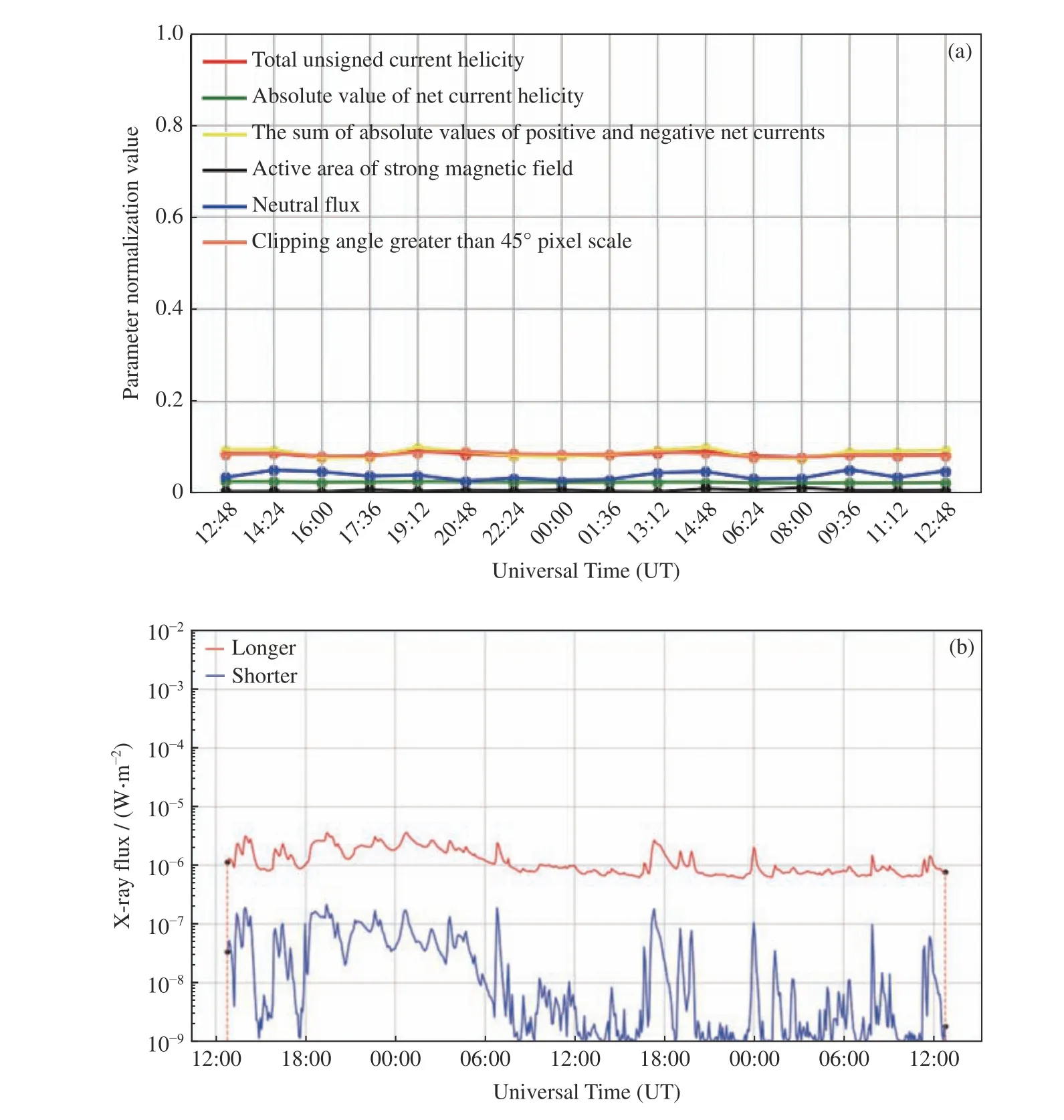
图9 负样本(2011 年11 月16 日12:48 UT 至17 日12:48 UT)各特征参数变化(a)与GOES 卫星测量(2011 年11 月17 日00:00 UT 至20 日00:00 UT)该样本未来48 h 的X 射线通量变化(b),橙色虚线为模型预测范围,显示该样本未来48 h 内无≥M 级耀斑发生Fig. 9 Negative sample (from 12:48 UT on 16 November 2011 to 12:48 UT on 17 November 2011) characteristic parameter change (a) and the GOES satellite measurement (from 00:00 UT on 17 November 2011 to 00:00 on 20 November 2011) of the X-ray flux change of the sample in the next 48 h (b). Orange dashed line is the model prediction range, and shows that there is no ≥M class flares occurrance in the next 48 h for this sample
本文提出的模型在准确率上并不具备优势,由于在训练过程中为了解决数据的不平衡问题,在模型训练过程中修改了损失函数的权重,使模型对正样本的识别更加侧重,导致对负样本的识别率降低,会在一定程度上影响模型虚报率和对负样本的识别。
4 结论
提出了基于长短期记忆神经网络的太阳耀斑预报模型,通过XGBoost 方法对SHARP 数据中各物理参量进行特征重要性分析,最终选取特征总无符号电流螺度、正负极净电流绝对值、净电流螺度绝对值、活动区强磁场面积、中性线磁通量、剪切角大于45°的像素比例这6 个物理参量作为模型输入参数。利用活动区这6 个参数连续24 h 的数据作为输入,建立未来48 h 的太阳耀斑预报模型。
与传统机器学习模型及经验模型相比,本文提出的模型对太阳活动区的时间变化特征进行建模,运用了太阳活动区磁场的时间演化信息,得到优于传统机器学习模型的预报效果。基于LSTM 模型的报准率和临界成功指数分别为0.7483 和0.7402,均高于传统机器学习模型,模型在准确率和虚报率上与传统模型相近,总体性能优于传统机器学习模型。预报结果与对耀斑产生物理机制的认识一致,即活动区的演化过程对于耀斑产生具有重要影响。
构建数据样本的规则是通过判断未来48 h 内是否发生>M 级别太阳耀斑事件,因此模型能分辨两种情况,分别为未来48 h 内发生≥M 级以上的耀斑事件和未来48 h 内发生<M 级耀斑或不发生耀斑事件。在构建模型时只用到活动区的参数特征,未用到图像特征,而图像的演化信息同样可以使用长短期记忆神经网络进行分析,建立耀斑预报模型。利用太阳观测图像信息进行分析和建模研究,并对不同耀斑级别的预报进行更细致的划分将是未来研究的重要方向。
致谢 耀斑数据由SDO 卫星提供。SDO 卫星为NASA 启动的“与星共栖”计划(LWS)的第一个任务,该计划旨在了解太阳变化的原因及其对地球的影响。太阳活动区耀斑爆发数据集由中国科学院国家空间科学中心空间环境人工智能预警创新工坊整理提供。
