非光滑强凸情形Adam型算法的最优收敛速率
2022-11-09张泽东
陇 盛,陶 蔚,张泽东,陶 卿
(1.国防科技大学信息系统工程重点实验室,湖南长沙 410073;2.军事科学院战略评估咨询中心,北京 100091;3.陆军炮兵防空兵学院信息工程系,安徽合肥 230031)
1 引言
在线学习(online learning)是用来分析迭代算法的流行框架,后悔界(regret bound)则是衡量在线优化算法性能的重要指标[1].针对一般凸优化问题,Zinkevich提出的OGD(Online Gradient Decent)[2]方法达到了最坏情况下O()的后悔界,其中T是总迭代次数.而在非光滑强凸情形中,Hazan等人在OGD基础上调整步长阶为得到了更好的O(logT)对数阶后悔界[3],其中t=1,2,···,T.
虽然在线学习理论和应用方面都取得成功,但是实验中模拟在线流程较为复杂,算法往往需要更简单的随机实验环境[4].因此,本文关注OGD经过标准的online-to-batch技巧转换后,得到的随机算法SGD(Stochastic Gradient Decent).两者本质上是同一算法,区别在于应用场景不同,OGD用后悔界度量其在线学习性能,SGD靠收敛速率评价在随机优化中的表现.在强凸情形中,SGD得到了O(logT/T)的收敛速率.与之相比,Agarwal等人证明了在最好情况下,一阶随机优化算法解非光滑强凸问题的收敛速率是Ω(1/T)[5].为达到与之匹配的最坏情况下的最优收敛速率O(1/T),许多算法在分析中引入了光滑条件(例如梯度Lipschitz连续、高阶可微等).但是这些假设往往是不平凡的,并且无法应用于非光滑目标函数(例如hinge损失).文献[6]提出一种结合了COMID(Composite Objective Mirror Descent)的非光滑随机坐标下降方法,不仅保持了正则化结构,而且计算代价极低,遗憾的是在强凸情形中未能达到最优.因此长期以来,SGD都无法跨过对数阶的鸿沟,达到非光滑强凸情形的最优收敛速率.
为了解决这个问题,研究者通常采取两种方案:其一是改进SGD算法本身,结合各种加速技巧提升算法收敛速率.2011年,Hazan等人提出著名的Epoch-GD(Epoch Gradient Descent)[7],该算法其实是在SGD基础上引入了“多阶段循环”这个新的概念.虽然Epoch-GD达到了最优收敛速率O(1/T),但Rakhlin等人认为,大幅修改算法不足以证明SGD彻底突破了强凸优化中对数因子的阻碍,因此提出了第二种方案——修改算法输出方式.在以往收敛性分析中,SGD输出全部T次迭代平均结果,Rakhlin提出在不改变算法的前提下,用α-suffix[8]方式(输出后半部分迭代平均)进行替换,最终达到了O(1/T)收敛速率.然而,α-suffix技巧也存在问题,首先它给收敛性分析增加了难度,其次不能以on-the-fly的模式存储历史迭代结果,从而增加了计算开销.幸运的是,文献[9~11]中采用的加权平均输出方式克服了这个缺点.该方法对理论分析十分友好,且只需对SGD每次迭代结果赋予权重值最后进行平均输出,就可以在支持on-the-fly计算方式的同时,保证最优的收敛速率.
近年来,在SGD基础上使用自适应梯度调整步长,并且用动量搜索方向的算法称为Adam型算法,例如Adam[12]、NAdam(Nesterov-accelerated Adaptive moment estimation)[13]、PAdam(Partially Adaptive moment estimation)[14]、Adaptive HB(Adaptive Polyak’s Heavy-Ball)[15]等.这类算法在非光滑凸情形中保证的收敛速率,并且具有适合稀疏优化、体现不同维度差异等优点.然而文献[16]指出,在某些简单的凸环境中,所有基于指数移动平均(Exponential Moving Average,EMA)的Adam型算法都不收敛,这就是著名的Reddi问题.针对该问题,Reddi等人提出了改进算法AMSGrad[16]和AdamNC[16].另一方面,Adam型算法在强凸优化中的应用也逐渐发展起来.2017年Mukkamala等人提出了SC-Adagrad(Strongly Convex Adagrad)[17]和SC-RMSProp(Strongly Convex RMSProp)[17]算法,应对在线学习问题得到了数据依赖(处理稀疏数据时表现更好)的对数阶后悔界.2018年,Chen等人在Epoch-GD基础上结合AdaGrad[18]提出了SadaGrad[19],虽然在随机情形下得到了O(1/T)的最优收敛速率,但是只适用于弱强凸环境.2019年,Wang等人提出SAdam[20],尽管在处理稀疏数据时得到比OGD更好的后悔界,体现出自适应步长方法的优势,但是转换为随机算法时只能得到O(logT/T)的收敛速率,因此没有体现动量的加速作用,与最优收敛速率依然存在对数阶的间隙.
面对非光滑强凸优化问题,SGD能够得到最优收敛速率O(1/T),但是到目前为止,SGD改良产生的Adam型算法反而无法达到上述目标.因此,如何使Adam型算法达到最优收敛亟待解决.正如文献[20]中所说,寄希望于SAdam与Epoch-GD技巧结合是不平凡的.综上所述,本文旨在基于动量法和自适应步长,结合修改输出方式这一技巧提出新的Adam型算法,保证其在非光滑强凸情形中达到最优收敛速率O(1/T).
本文的主要贡献如下:
(1)提出了一种名为WSAdam的Adam型算法,该算法在SAdam基础上进行改进,采用加权平均的输出方式,设置了与以往强凸算法同阶的步长超参数.既保持了Adam型算法体现不同维度差异的优点,又通过on-the-fly计算降低了运行成本;
(2)针对约束的非光滑强凸优化问题,证明了本文所提的WSAdam随机情形下具有O(1/T)的最优收敛速率(见定理1).据我们所知,这一结果消去了强凸优化中常见的对数阶因子,填补了Adam型算法强凸最优收敛性方面的缺失;
(3)证明了在导致Adam发散的优化问题[16]上,WSAdam仍能保持收敛,表明WSAdam可以解决Reddi问题.另外,选择了典型的l2范数约束下的hinge损失函数强凸优化问题,通过与几种常见强凸算法进行比较实验,验证了理论分析的正确性,也表明所提算法优于现有的强凸Adam型算法.
2 相关工作
本文主要考虑求解如下非光滑约束优化问题:

其中Q∈Rd是闭凸集,为式(1)的一个最优解,f是Q上的非光滑强凸函数,定义如下:
那么称函数f为λ-强凸.
在线学习的目标是最小化后悔界(Regret bound),定义如下:
其中ft(t=1,2,···,T)均为强凸函数,ft(wt)表示ft在wt处的损失.常用优化器是OGD,见算法1.

算法1中αt代表步长,gt表示ft(wt)的次梯度,PQ表示在Q上投影算子.
然而在线设置中,不可预见整体目标函数,需要学习环境响应上一轮迭代结果后提供损失ft,然后才能观察到当前迭代的次梯度gt,因此不适用于算法的实验验证.

通常用SGD解得上述随机情形中的收敛速率,具体形式见算法2.

算法2中αt代表步长,ξt⊆ξ表示第t次迭代时随机抽取的样本表示f(wt,ξt)的次梯度.
SGD计算次梯度只与每轮随机抽取的样本相关,当假设全体样本独立同分布时,在第t次迭代时刻,关于部分样本的目标函数f(wt,ξt)的次梯度̂是整个目标函数f(wt,ξ)次梯度的无偏估计,也就是
其中α∈(0,1),令αT为整数.但是,这种方式需要将所有的迭代结果存入内存或者提前知道总迭代次数T,这极大增加了计算开销.
针对这个问题,一种能够on-the-fly计算的加权平均输出方式被提出:

除了改进输出方式,升级为Adam型算法也是提高SGD性能的主要途径之一,其具体描述见算法3.

在算法3中,动量由历史梯度缓冲器mt承载,自适应步长由构成.Adam型算法的自动调整步长机制,关键技术是平方梯度的指数移动平均(Exponential Moving Average,EMA):
虽然该策略可以摒弃过早的梯度,并且避免训练提前终止,但是不能保证是单调非增的.迭代后期过大的步长可能导致算法不收敛,从而陷入Reddi问题(详细例子在第4节实验中描述).
解决方案是AMSGrad和AdamNC两种算法,SAdam在AdamNC基础上改进而来也有效避免了不收敛问题.不同的αt,mt,Vt设定方案对应不同Adam型算法,我们将常见的几种列举出来,后悔界和随机情形下收敛速率对比如表1所示.其中前三种算法针对一般凸函数,后三种针对强凸函数.

表1 常见Adam型算法对比
表1中α为某一固定参数,向量或矩阵间运算都是基于元素的,diag(·)是取对角矩阵运算,Id是d维单位矩阵,δ是平滑系数.
3 WSAdam算法
对于非光滑强凸优化问题,为了构造达到最优收敛速率O(1/T)的新算法,我们的思路是在SAdam基础上,重新设计与以往强凸算法同阶的步长超参数(即最终步长满足O(1/t)),摒弃以往的标准平均输出方式,用加权平均输出方式取代之.本文提出的WSAdam算法见算法4.

算法4 WSAdam算法输入:w1=0 For t=1 to T Compute ĝt=∇f(wt,ξt)Update mt=β1,tmt-1+(1-β1,t)ĝt Update Vt=β2,tVt-1+(1-β2,t)diag(ĝ2 t)Update V̂t=Vt+δId Update wt+1=PV̂t Q[wt-αtmtV̂-1t]End for输出:wˉw T=2 Ttwt T+1∑t=1 T( )

由式(7)可知,WSAdam的有效步长为O(1/t),与以往强凸算法步长同阶.由于Vt,i+δ积累矩阵第i维度数值,算法步长因此在不同维度上得到加权区分,从而在不同待训参数之间体现出差异性.
另一方面,WSAdam采用加权平均的输出方式,保持了on-the-fly计算的优点,更为重要的一点是,所加权重消去了导致以往算法产生对数阶的结构,因此能够达到最优收敛,这将在下一节中展开说明.
4 WSAdam算法收敛速率分析
为了达到非光滑强凸情形的最优收敛速率,我们首先寻找SGD产生对数阶的原因,然后介绍加权平均输出技巧解决此问题的原理.
首先,我们需要给出一些假设条件,这些假设在以往收敛性分析中普遍存在.
假设1存在常数G>0和G∞>0使得:
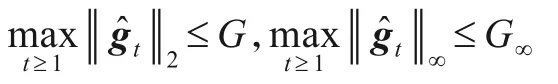
假设2存在常数D>0和D∞>0使得:
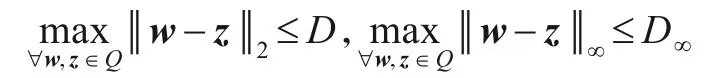
然后,根据文献[9]中对强凸SGD的分析得下式:

其中,αt是步长,λmin是强凸系数λ中的最小元素值.令上式得:

对上式从t=1到t=T求和得:

从上式第二行可以观察到,前一项为负数可以放缩消去,第二项导致了对数因子的产生.
因此我们着重处理后一项,采用权重为t的加权平均输出方式,令上式不等号两边同时乘t得到:
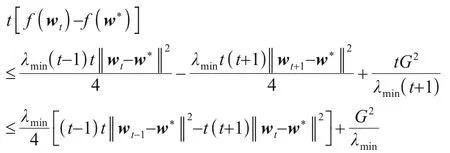
观察上式最后一行,发现后一项上的1t已被消去,此时从t=1到t=T求和不会再产生对数因子,做加权平均可得如下最优收敛速率:
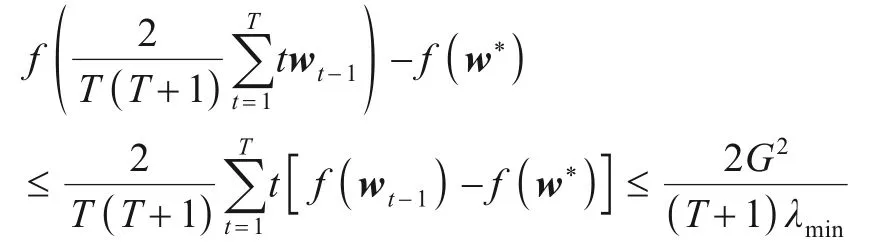
本文将上述原理迁移到WSAdam算法的收敛性分析中,此外,还需要如下引理.
引理1假设1≤t≤T,0<ν<1,f(ν)表示关于ν的函数,(f(ν))'表示f(ν)的导函数,则有下式成立:
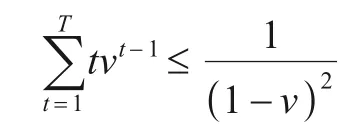
证明

引理1证毕.
定理1令假设1和假设2成立由算法4产生,f满足定义1中的λ-强凸性质,w*∈Q为问题式(1)的一个最优解,结合引理1,随机WSAdam能够保证如下收敛速率:
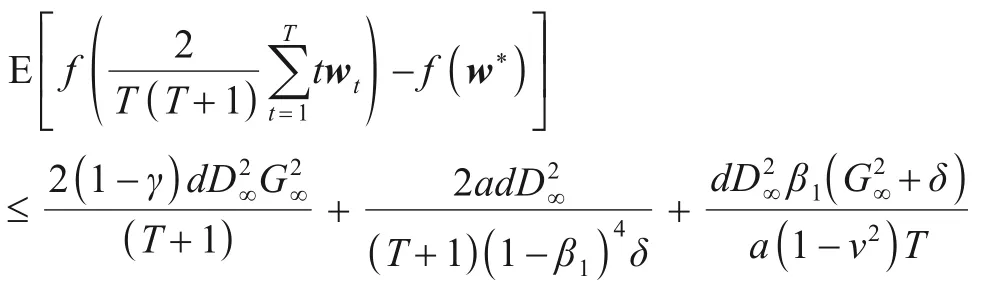
注意,上式表明WSAdam具有O(1/T)的最优收敛速率.与SAdam达到O(logT/T)次优收敛速率相比,WSAdam体现出了动量方法的加速性,填补了Adam型算法在非光滑强凸情形最优收敛性方面的缺失.
证明根据算法5中步骤7,由投影非扩张性可得:
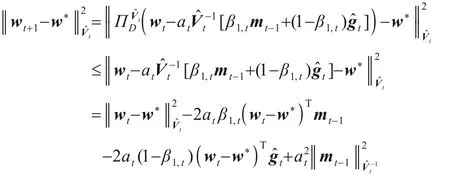
上式移项,两边除以2at(1-β1,t)得:
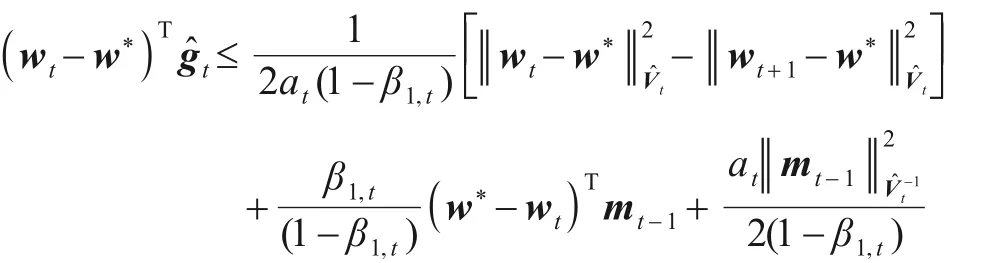
因为f(wt,ξt)满足λ-强凸,联立上式得:
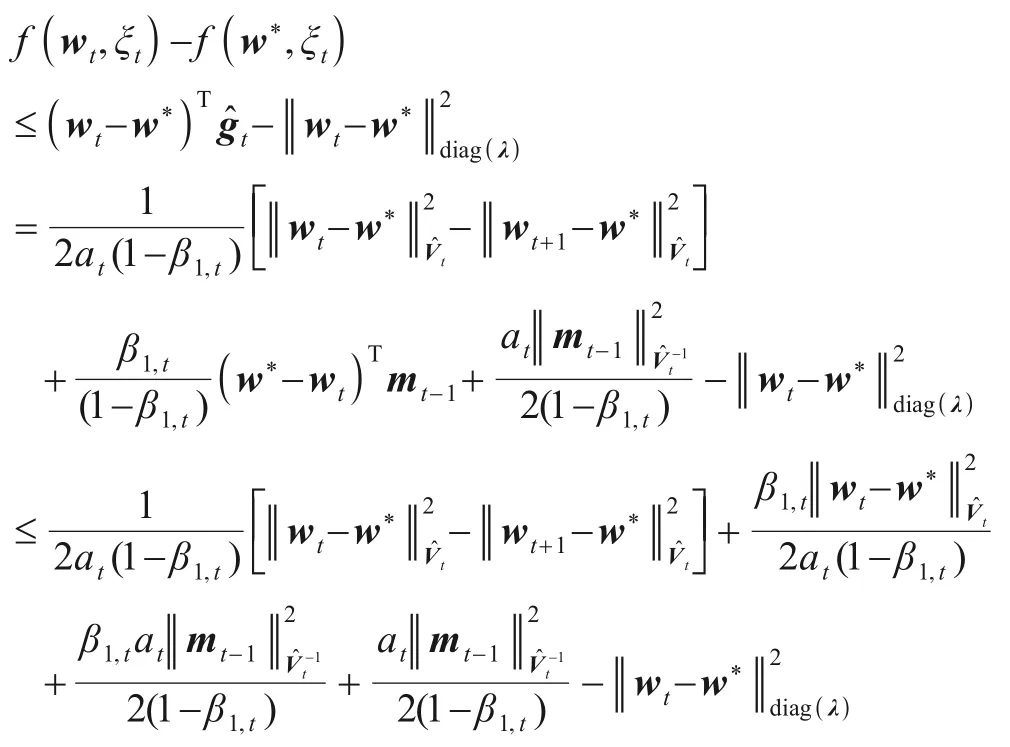
上式不等号两边同时取期望得:
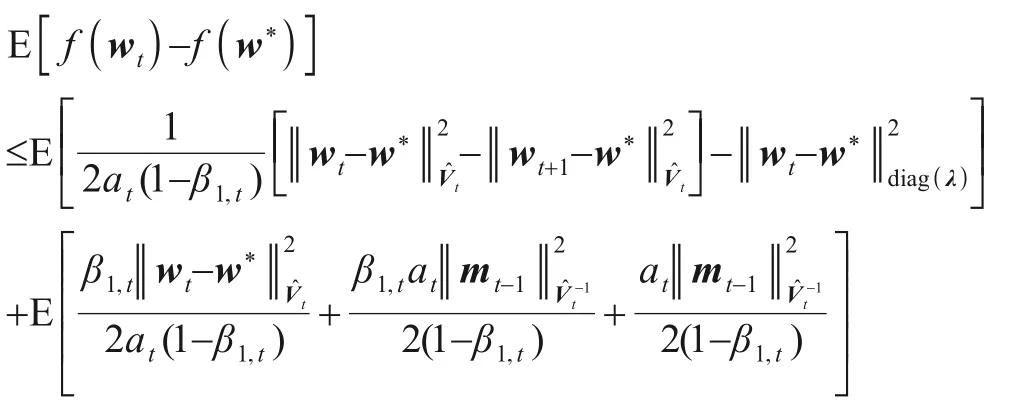
上式不等号两边同乘以t,并从t=1到t=T求和得:

首先处理P1:


即:
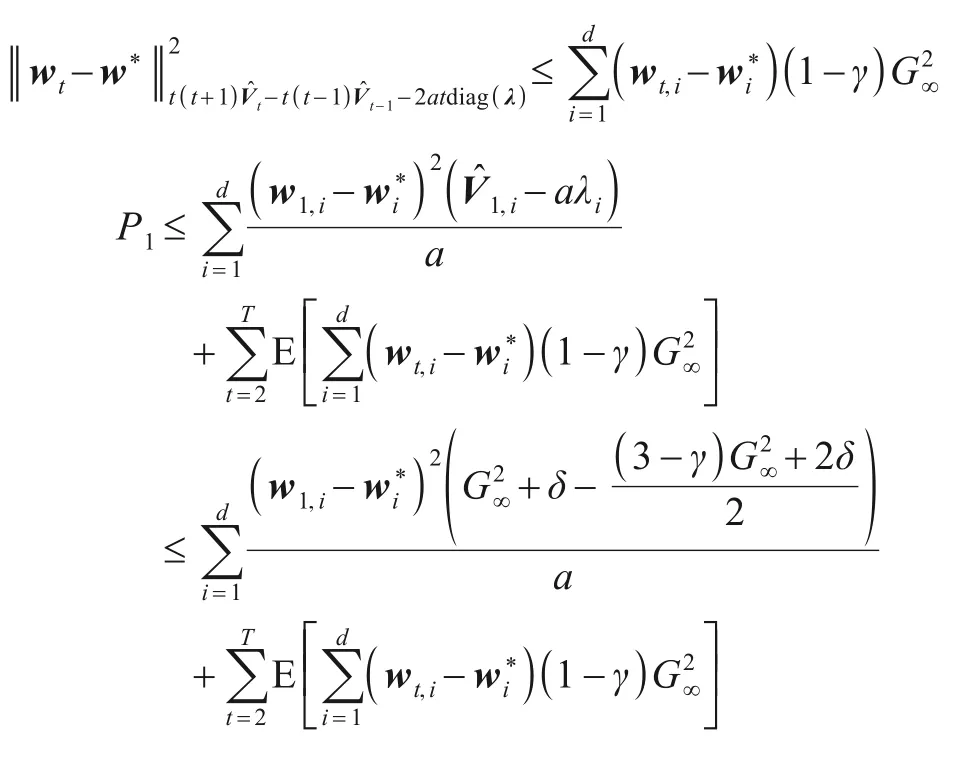
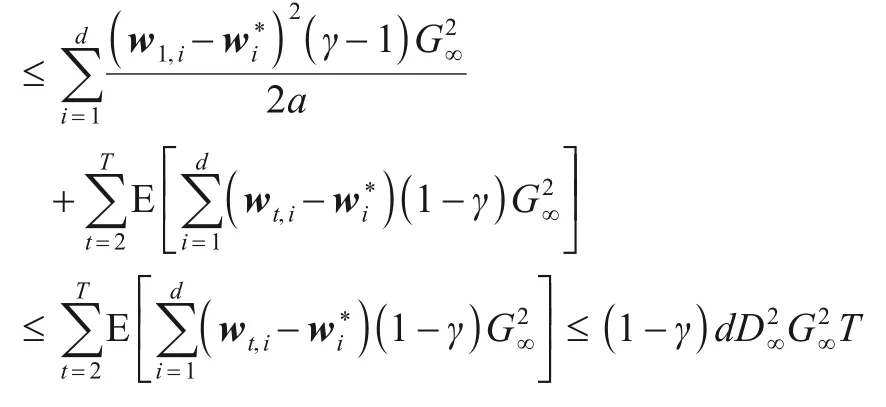
然后处理P2,由m0=0,β1,t≤1,β1,t≤β1,t-1得:
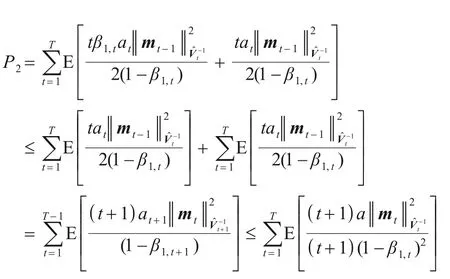
将mt和展开得:

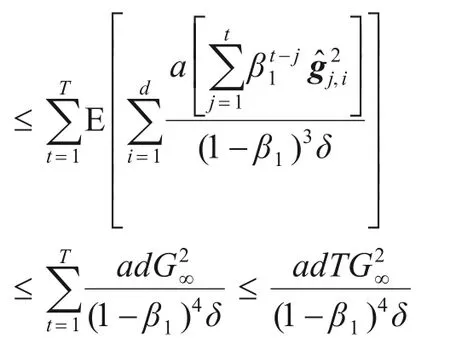
最后处理P3:
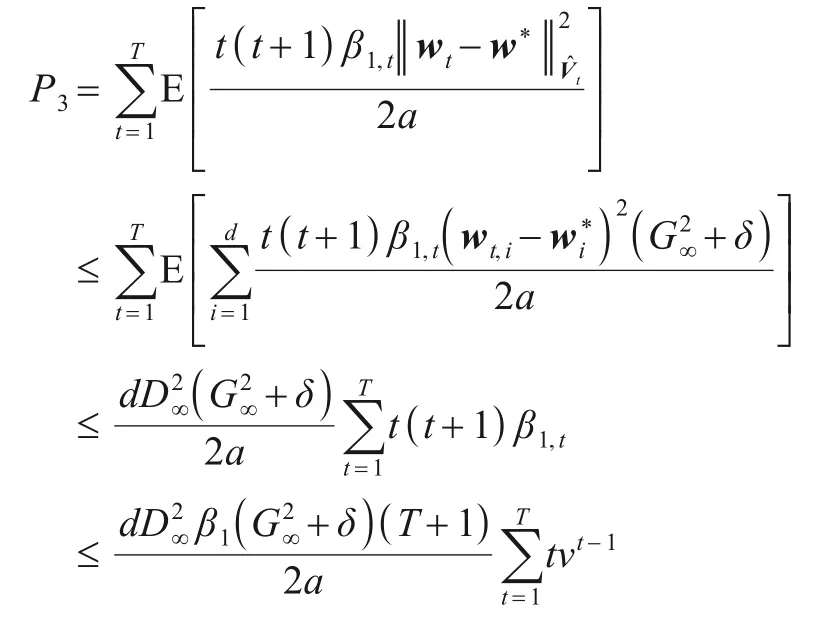
上式结合引理1得:
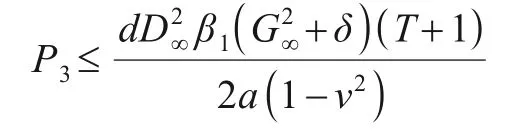
联立P1,P2,P3得:

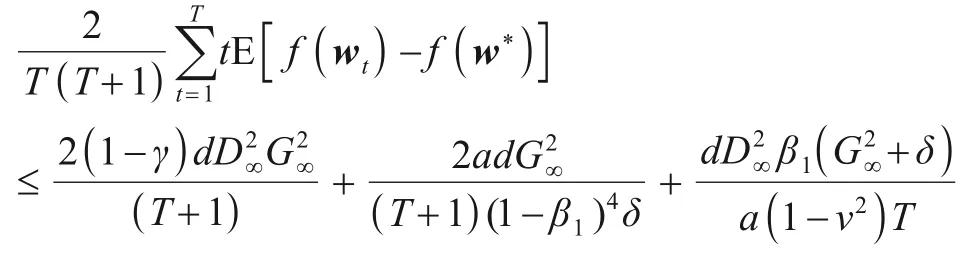
由凸函数基本性质得最终加权平均收敛速率:
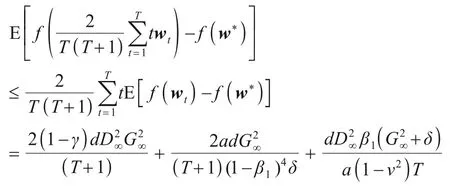
定理1证毕.
5 实验
本节分两部分对上一节中最优收敛速率的理论分析进行实验验证.第一部分验证WSAdam算法能够解决Reddi问题;第二部分验证WSAdam在非光滑强凸情形优于现有算法.
5.1 Reddi问题的实验结果与分析
2018年,Reddi等人证明了Adam算法在优化一个经过特殊构造的一般凸函数时发散.事实上,所有基于EMA技巧的Adam型算法都有可能存在这个问题,也被称为Reddi问题:
考虑如下定义域为[-1,+1]的线性函数序列:

其中C=3.在这个函数序列中,可以明显看出当w=-1时得到最小的后悔界.然而,Adam错误地将参数指向+1方向进行更新,导致不收敛.
本文实验设置初始w=1,t=[1,5000],将WSAdam与其他4种经典Adam型算进行比较,观察它们解上述在线优化问题的表现.为公平起见,所有算法统一设置参数α=0.5,β1=0,δ=1e-8,Adam和AMSGrad均设置β2=0.1,AdamNC、SAdam和WSAdam均设置β2,t=1-0.1t.实验结果如图1所示,其中图1(a)的横坐标代表迭代次数(t),纵坐标代表平均后悔界(Regret boundt);图1(b)的横坐标代表迭代次数(t),纵坐标代表参数(w).如图1所示,在迭代5000次后,Adam参数值w=+1是次优解,平均后悔界无法收敛到0,从而证实了Reddi问题.AMSGrad、AdamNC、SAdam和WSAdam的参数值w=-1达到了最优解,且平均后悔界均收敛到0,证实了这些算法改进Adam是有效的,成功解决了Reddi问题.
另外,从图1(a)中还可以看出,强凸算法SAdam、WSAdam比一般凸算法Adam、AMSGrad、AdamNC收敛更快,说明SAdam、WSAdam对一般凸函数同样适用,并且本文所提WSAdam收敛最快,优于现有的Adam型算法.
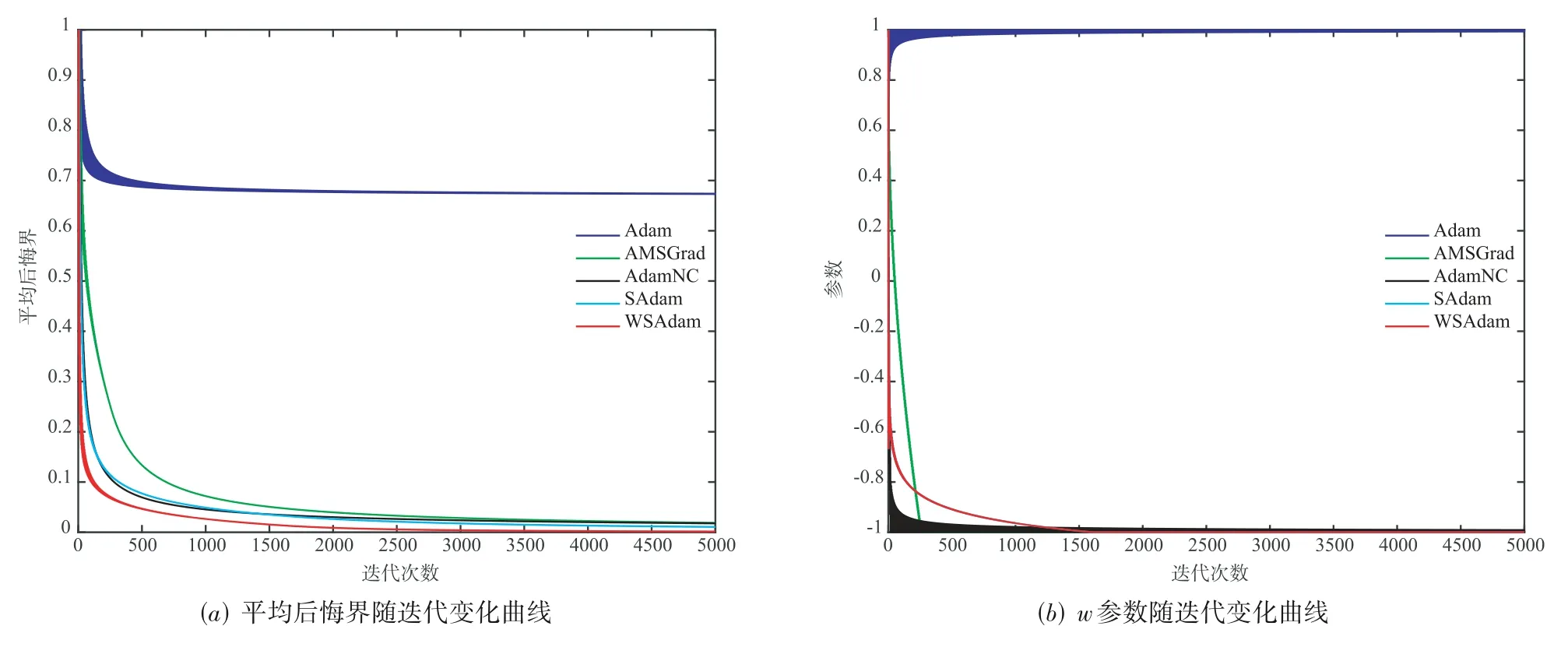
图1 Reddi问题实验结果
5.2 非光滑强凸情形标准数据集的实验结果与分析
本文第二个实验继承文献[21]中随机设置环境,考虑典型的二分类强凸支持向量机(SVM)问题,假设全体样本集目标函数f(w,ξ)由l2范数结构项和非光滑hinge损失组成,描述如下:

第t次迭代时,抽取样本子集ξt参与计算的次梯度∇f(wt,ξt)可以写成如下形式:

采用6个标准数据集,分别是cod-rna、ijcnn1、gisette、madelon、a9a和live-disorders.这些数据集均来自于LIBSVM网 站(https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/),具体描述可见表2.
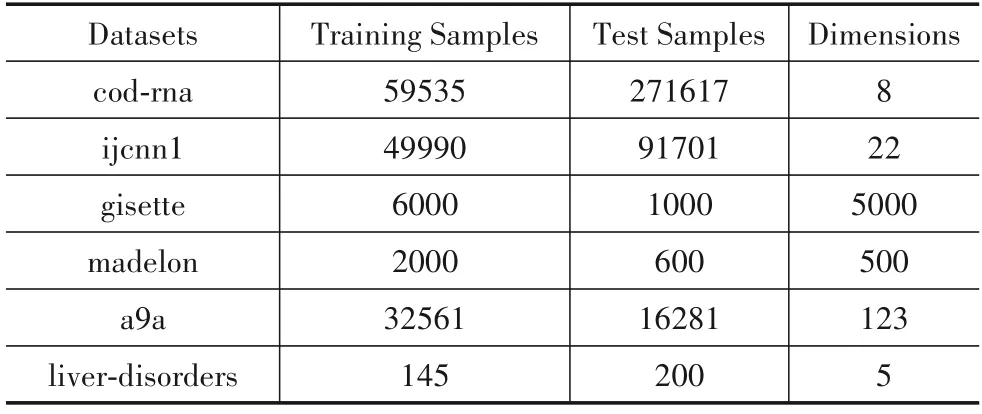
表2 标准数据库描述
实验选择了著名的解SVM问题的pegasos[21]算法,以及几种典型的强凸Adam型算法作为比较对象.为公平起见,所有算法设置参数α=1.另外,pegasos根据文献[21]所述无其他预设参数;SAdam根据文献[20]设置β1=0.9,β2,t=1-0.9t,δ=1e-2;WSAdam根据算法4设 置β1=0.9,ν=0.999,β2,t=1-0.9t,δ=1e-8;SCAdagrad根据文献[17]设置ε1=0.1,ε2=1;SC-RMSProp根据文献[17]设置β2,t=1-0.9t,ε1=0.1,ε2=1.
所有算法在每个数据集上运行10次并取平均值绘制收敛曲线errorbar对比图.如图2所示,横坐标表示迭代次数t=[1,5000],纵坐标为相对目标函数值,即当前迭代目标函数值与目标函数最优值(最优值取所有迭代结果中的最小值)之差的对数值,4种比较算法的相对目标函数值形式为WSAdam的相对目标函数值形式为蓝色实线代表pegasos算法的收敛趋势;绿色实线代表SAdam算法的收敛趋;红色实现代表WSAdam算法的收敛趋;黑色实线代表SC-Adagrad算法的收敛趋;青绿色实现代表SC-RMSProp算法的收敛趋.
从图2可以看出,没有使用自适应步长和动量技巧的pegasos十次平均曲线波动较大、方差大也大,收敛速率平缓,总体性能要差于其他4种Adam型算法.而本文所提出的WSAdam十次平均曲线非常平滑(这是更改为加权平均输出所导致的),方差也较小.在6个标准数据集上,WSAdam与现有流行的强凸Adam型算法均表现出基本相同的收敛趋势,甚至在一些训练集上(cod-rna)性能远超现有算法.并且在同一精度要求下,WSAdam的收敛速度总体上是最快的.这与理论分析中,WSAdam能达到优于其他算法的O(1/T)收敛速率结果相吻合.
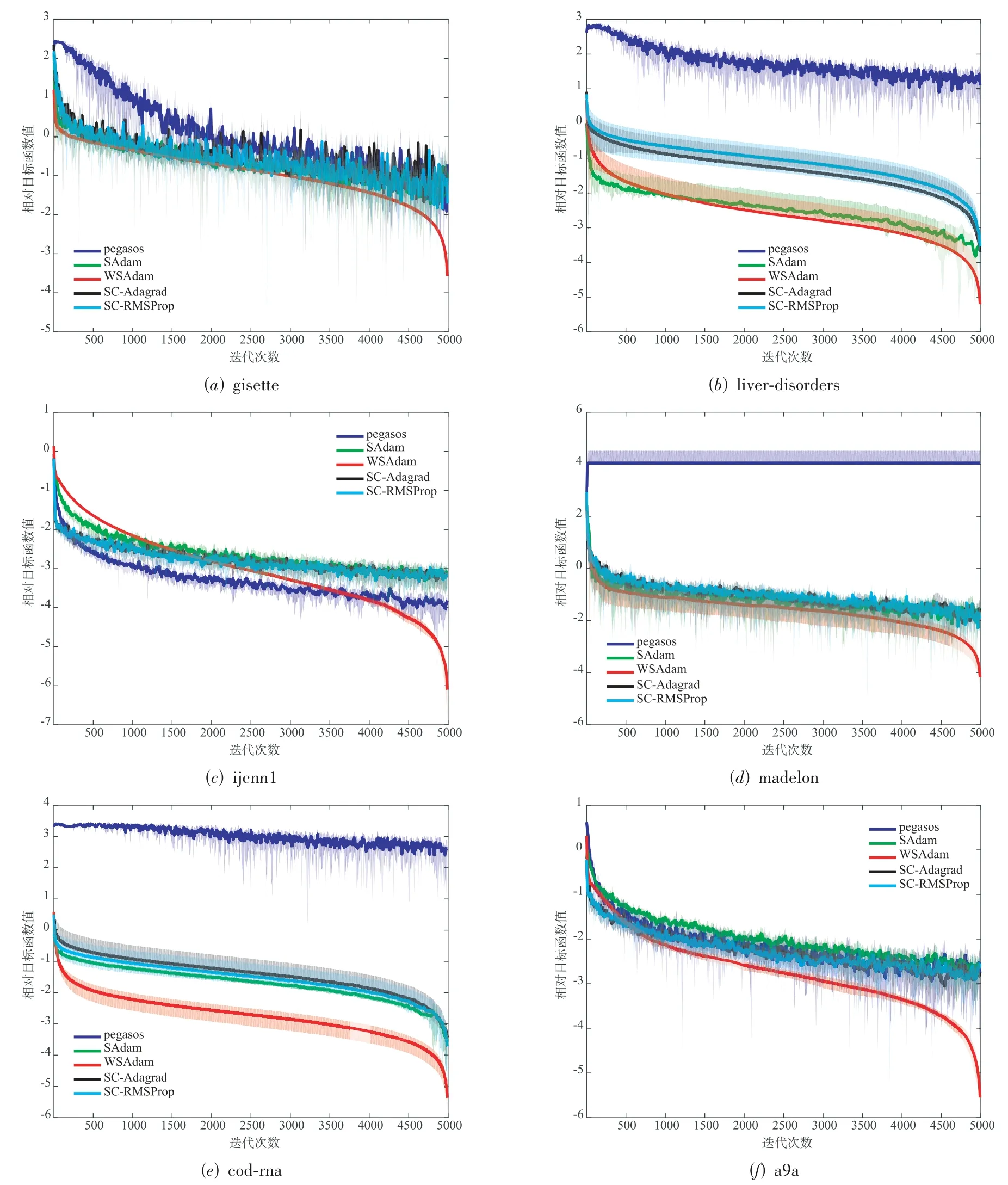
图2 目标函数收敛速率比较图
表3和表4分别给出了算法在6个数据集上训练所得模型的训练准确率(以及十次结果方差)、测试准确率(以及十次结果方差).容易看出:WSAdam在所有训练数据集上的准确率均为最高,方差较其他算法处于较低的层次.WSAdam在绝大部分测试数据集上准确率最高(在cod-rna上SAdam算法准确率最高)).一定程度上说明了WSAdam比其他几种算法训练的模型泛化性能更好,并且在训练和测试集上都保持较小实验方差,反映出其出色的稳定性.
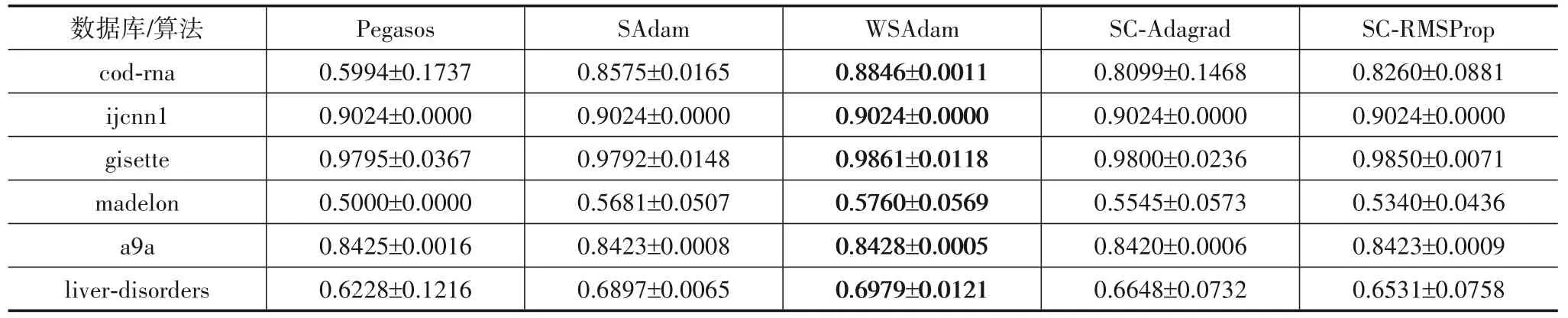
表3 训练准确率和方差比较
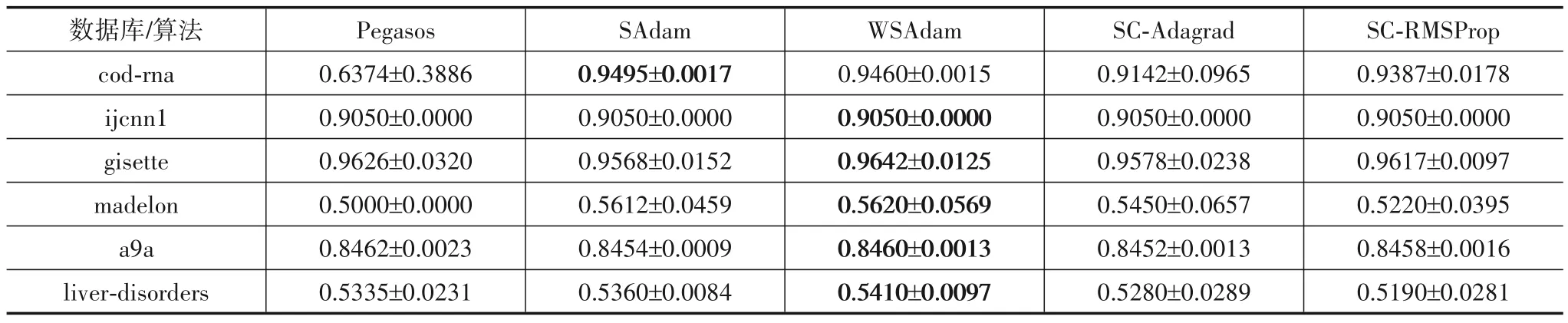
表4 测试准确率和方差比较
6 结论
本文提出了一种名为WSAdam的Adam型算法,证明了在非光滑强凸情形,WSAdam能达到O(1T)的最优收敛速率,体现了动量方法的加速性.据我们所知这是第一个被证明具有最优收敛速率的自适应步长策略与动量方法结合的算法.与SAdam算法相比,WSAdam改用了加权平均的输出方式,使算法在保持on-the-fly计算特点的同时,直接去掉了理论收敛速率上的对数阶因子.实验验证了所提算法成功避免Reddi提出的不收敛问题,并在解决非光滑强凸优化问题时比现有算法性能更优.
另一方面,自适应步长算法利用对角矩阵中记录的历史数据几何知识,缓和了对超参数的依赖性,因此非常适合训练深度神经网络.将WSAdam与动量方法[22]结合,探索其瞬时收敛速率[23]并推广到深度学习[24,25]中,将是我们下一步研究的方向.
