基于决策树算法的招生数据挖掘应用研究
2022-11-03朱莉萍
朱莉萍
(成都文理学院,四川 成都 610000)
0 引 言
招生工作是各大院校的常规工作也是最重要的工作之一,对于民办高职院校而言,招生工作更是关乎全校教职工的生计。报考率和报到率是招生人员最为关心的两个因素,也是衡量一个学校招生管理水平和成效的重要依据。利用数据挖掘技术对招生录取数据进行挖掘分析,提炼出影响报到率的重要因素,进行报到预测,将挖掘结果用于指导招生宣传和服务,辅助招生管理决策。
文献[1]中,作者利用决策树算法对不同专业考生的性别进行预测,利用贝叶斯算法预测每个专业的生源省份,得到的预测结果和实际结果之间的误差率较低;文献[2]中,作者用CHAID 算法构建决策树模型,挖掘出性别同专业、成绩,生源地同专业等方面的潜在信息。
1 决策树算法
决策树是一种使用非常广泛的分类技术。在分类的过程中,用一棵倒置的树从根节点开始由上到下逐渐构建决策的分支。常见的决策树算法有ID3、CHAID、CART、C4.5 等。为了确保在决策树的构建过程中每一个决策分支之间的差异最大,ID3 算法将信息增益作为确定划分的标准,而C4.5算法将信息增益率作为确定划分的标准。C4.5 算法是在ID3算法的基础上改进而来的,不仅可以处理离散型数据,也能处理连续性数据,因此本文考虑利用C4.5 算法对招生数据进行挖掘。下面介绍几个概念和公式:
(1)信息熵:表示信息的不确定性,公式定义如下:

(2)属性分裂后信息熵
假设属性有个离散值,数据集合中的元组被划分为个子集合D,按照属性分裂后的信息熵定义为:

(3)信息增益
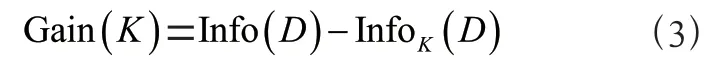
(4)信息增益率
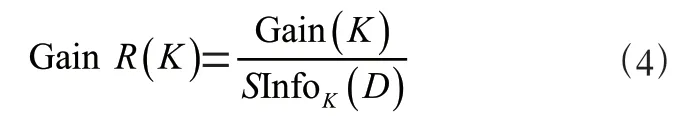
2 数据挖掘准备
2.1 招生数据
本文将某民办高职院校近三年的招生录取数据作为研究对象。招生录取源数据从招办系统导出,属性很多,包含考生号、准考证号、考生姓名、性别、出生年月、民族代码、政治面貌代码、考生科类代码、毕业类别代码、中学代码、身份证号、家庭地址、邮政编码、专业志愿、提档成绩、录取成绩等几十个字段。
2.2 数据预处理
在数据预处理阶段采用何种方法和技术需要在充分理解招生业务特点、招生数据挖掘目标和对源数据本身的理解的基础上进行选择。
2.2.1 数据集成
由于高职院校有单独招生考试和普通招生考试两种考试录取制度,且每年数据单独存放,因此需要将三年的录取数据合并,增加“录取方式”字段,填入“单招”和“统招”属性值。
2.2.2 数据清理
招生数据中的大部分字段对挖掘任务没有意义,将准考证号、出生年月、联系电话等字段删除。“是否报到”字段是在新生报到期间手动填写的信息,有几条空值,去除少数缺失数据,同时将保留学籍的数据处理为“是”,将退学的数据处理为“否”。将专业志愿中简写的专业名称更改为规范名称。
2.2.3 数据转换
根据招生经验,生源地对考生报到有一定影响,但生源地的类别较多,故按照东西南北方向将生源地进行泛化,转换成川东、川南等6 个地区。
同样,对众多的专业根据学校院系划分进行泛化,转换为财税金融、公共管理、建筑设计等10 个专业群。
另外,成绩是连续的数据,且单独招生考试和普通招生考试的单科分值等存在较大差异,因此先将考分进行标准化,再进行离散化,最终将成绩转换为A(优良)、B(中等)、C(较差)三个等级。
2.2.4 预处理结果
对招生数据进行预处理之后的数据效果如图1所示。
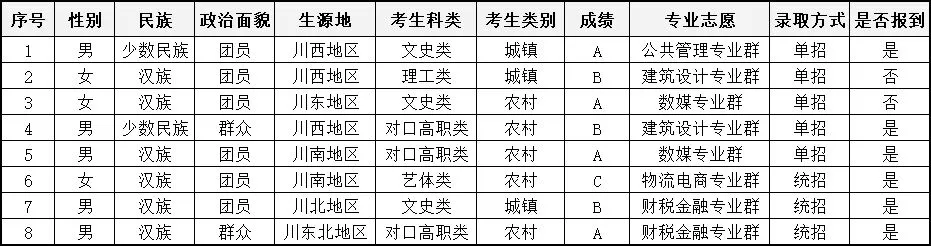
图1 预处理后的数据集
3 建立决策树
根据C4.5 算法中的公式(1)~(4),下文计算招生数据中各个属性的信息量、信息增益、信息增益率等。
3.1 计算测试属性信息量
招生数据集共计15 526 条,按测试属性“是否报到”分为T 和F 两类,T=13 125,F=2 401,得到测试属性的信息量为:
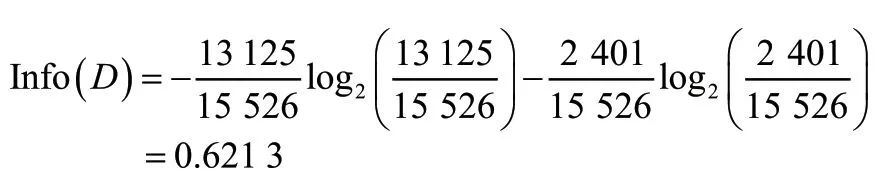
3.2 计算各个属性的信息量
分别计算性别、考生类别、成绩、录取方式、生源地、考生科类、专业志愿7 个属性的信息量如下:
(1)“性别”属性各节点是否报到的数据为男[7 079,1 289],女[6 046,1 112]

(2)“考生类别”属性各节点是否报到的数据为农村[10 011,1 936],城镇[3 114,465]

(3)“成绩”属性各节点是否报到的数据为A[2 056,267],B[9 211,1 633],C[1 858,501],同理可得:
Info(A)=0.514 6
Info(B)=0.611 3
Info(C)=0.746
(4)“录取方式”属性各节点是否报到的数据为单招[9 831,1 430],统招[3 294,971]
Info(单招)=0.549 1
Info(统招)=0.773 9
(5)“生源地”属性各节点是否报到的数据为川东[3 254,642],川南[2 705,523],川西[1 770,308],川北[1 737,298],川东北[2 969,477],三州[690,153]
Info(川东)=0.645 6
Info(川南)=0.639 1
Info(川西)=0.605 4
Info(川北)=0.600 9
Info(川东北)=0.580 1
Info(三州)=0.638 8
(6)“考生科类”属性各节点是否报到的数据为对口高职[5 650,1 340],理工[2 417,333],文史[4 905,670],艺体[153,58]:
Info(对口高职)=0.705
Info(理工)=0.532 5
Info(文史)=0.529 9
Info(艺体)=0.848 4
(7)“专业志愿”属性各节点是否报到的数据为财税金融[1 028,171],公共管理[1 476,252],健康[2 660,591],建筑设计[1 382,202],教育管理[1 248,211],汽修[821,189],数媒[1 266,227],通信[878,168],物流电商[663,124],信息技术[1 703,266]:
Info(财税金融)=0.591 1
Info(公共管理)=0.599 3
Info(健康)=0.684
Info(建筑设计)=0.550 6
Info(教育管理)=0.596 2
Info(汽修)=0.695 4
Info(数媒)=0.614 9
Info(通信)=0.635 8
Info(物流电商)=0.628 4
Info(信息技术)=0.571 2
3.3 计算各个属性的信息熵
各个属性的信息熵计算结果为:

同理:
Info(考生类别)=0.620 3
Info(成绩)=0.617 3
Info(录取方式)=0.610 9
Info(生源地)=0.620 5
Info(考生产类)=0.613 5
Info(专业志愿)=0.619 3
3.4 计算各个属性分裂后的信息量
各个属性分裂后的信息量为:

同理:
SInfo(考生类别)=0.778 9
SInfo(成绩)=1.184 7
SInfo(录取方式)=0.848 1
SInfo(生源地)=2.454 4
SInfo(考生科类)=1.575 5
SInfo(专业志愿)=3.206 2
3.5 计算各个属性的信息增益率

同理:
GainR(考生类别)=0.001 3
GainR(成绩)=0.003 4
GainR(录取方式)=0.012 3
GainR(生源地)=0.000 3
GainR(考生科类)=0.005
GainR(专业志愿)=0.000 6
3.6 比较各属性信息增益率
根据第(5)步的结果可知“录取方式”字段信息增益率最大,故将其作为根节点,然后分别在单招和统招两种情况下继续计算其他属性值的信息熵和信息增益率,将信息增益率相对最高的属性作为下一级分支节点,不断重复以上几个步骤,完成各个分支的划分,并最终得到是否报到的完整决策树。由于生成的完整的决策树较大不便展示,图2仅显示了其中较小一部分。

图2 决策树局部
4 生成规则
决策树每一条分支的路径就是一条规则,由决策树生成的部分规则表示如下:
(1)规则用于“是否报到”=“F”的5 个规则:
规则1:IF 性别 = 女 and 考生科类 = 对口高职类 and 提档成绩 = C and 录取方式 = 统招and 专业 = 物流电商专业群and 考生类别 = 农村 Then F
规则 :IF 性别 = 女and 生源地 in [ "三州地区" "川北地区" "川西地区" ]
and 考生科类 = 对口高职类and 录取方式 = 统招 and 专业 = 信息技术专业群Then F
规则3:IF 生源地 = 川南地区 and 提档成绩 = C and 录取方式 = 统招
and 专业 = 财税金融专业群 Then F
规则4:IF 性别 = 男and 考生科类 = 对口高职类and 录取方式 = 统招
and 专业 = 物流电商专业群 Then F
规则5:IF 考生科类 in[“文史类””理工类”]and 生源地 = 川南地区and 录取方式 = 统招and 专业 = 财税专业群and 提档成绩 = C Then F
(2)规则用于“是否报到”=“T”的5 个规则:
规则1:IF 考生科类 in [ "文史类" "理工类" ]and 提档成绩 = A Then T
规则2:IF 考生科类 in [ "文史类" "理工类" ]and 专业 in [ “信息技术专业群” “健康专业群” “公共管理专业群” “建筑设计专业群” “教育管理专业群” “数媒专业群”“汽修专业群” “物流电商专业群” ]Then T
规则3:IF 考生科类 in[ “文史类” “理工类” ]and提档成绩 = Band 性别 = 男 Then T
规则4:IF 生源地 in [ “三州地区” “川东北地区”“川东地区” “川北地区” “川西地区” ]and 考生科类 in ["文史类" "理工类” ]Then T
规则5:IF 专业 = 通信专业群 and 录取方式 = 单招Then T
5 结 论
根据决策树规则,对招生数据挖掘模型进行测试,得到预测的准确率为85.91%,得到各因素影响报到的重要程度排序为:录取方式、专业志愿、生源地、考生科类、考生类别、性别。
决策树算法简单,建立的树型结构也容易让不懂数据挖掘的招生人员看懂,对报到情况的预测准确率也满足需求,挖掘结果对招生管理工作有一定的辅助作用,未来可以考虑集合更多数据,对决策树算法进行改进,更好地应用于招生数据挖掘。
