引入注意力机制的自监督光流计算
2022-11-02严仲兴
安 峰,戴 军,,韩 振,严仲兴
引入注意力机制的自监督光流计算
安 峰1,戴 军1,2,韩 振2,严仲兴1
(1. 苏州工业园区服务外包职业学院人工智能学院,江苏 苏州 215123;2. 同济大学经济与管理学院,上海 210092)
光流计算是诸多计算机视觉系统的关键模块,广泛应用于动作识别、机器人定位与导航等领域。但目前端到端的光流计算仍受限于数据源的缺少,尤其是真实场景下的光流数据难以获取。人工合成的光流数据占绝大多数,且合成数据不能完全反应真实场景(如树叶晃动、行人倒影等),难以避免过拟合等情况。无监督或自监督方法可以利用海量的视频数据进行训练,摆脱了对数据集的依赖,是解决数据集缺少的有效途径。基于此搭建了一个自监督学习光流计算网络,其中的“Teacher”模块和“Student”模块集成了最新光流计算网络:稀疏相关体网络(SCV),减少了计算冗余量;同时引入注意力模型作为网络的一个节点,以提高图像特征在通道和空间上的维度属性。将SCV与注意力机制集成在自监督学习光流计算网络之中,在KITTI 2015数据集上的测试结果达到或超过了常见的有监督训练网络。
光流计算;自监督学习;卷积注意力模块;空间/通道注意力;稀疏相关体
一直以来,光流计算被视为是一个优化求解问题[1],近年来随着深度学习的发展,涌现出较多的端到端深度网络可直接计算光流值[2-5]。这些网络的训练需要海量的图像对和标签数据,然而真实场景下光流标签数据的获取是非常困难的,需要追踪每一个像素的运动(如将场景布置上荧光粉,然后用特殊的运动捕获系统来获得相应的光流)。所以,人们更多地使用人工合成的数据集进行相关训练,这又带来与真实场景的不匹配问题。在真实场景下,行人与建筑物的倒影、移动的云朵就很难在合成数据集中体现出来,这就是很多光流计算方案在KITTI[6]数据集上表现不佳的原因。
而无监督训练的方式可以很好地弥补这一情况:数据来源可为互联网上免费获得的无标记视频。通过利用这些多样化的无标签真实数据进行训练,提高了生成模型的通用性和计算效果。
自监督学习基于无监督学习基础之上,通常会包含2个相同的子网络:“Teacher”和“Student”。首先进行“Teacher”的无监督学习并获得光流,这个值作为“Student”的标签;然后通过对“Student”设置各种“障碍”,如图像增强、生成阴影等操作,并基于这些数据进行监督学习,从而完成一次训练,也被称为“数据提纯”。在测试环节,无需“Teacher”参与,只需“Student”进行预测,计算时长为毫秒级。图1是自监督学习网络的体系结构。

图1 自监督学习的体系结构
自监督学习通过这种方式改善了无监督学习的不足,提高了光流计算效果。图2描述了“Teacher”与“Student”的计算过程,两者有相同的特征提取、注意力提取模块和基础光流计算网络;不同的输入图像和损失函数。

图2“Teacher”与“Student”的网络结构
图2中SCV(sparse correlation volume)指的是一款新的光流计算网络,其主要特点是计算稀疏相关体、通过门控循环单元(gated recurrent unit,GRU)完成光流迭代增量的计算,详见2.4节。

本文对自监督学习中的子网络进行了扩展,主要贡献有以下几点:
(1) 采用SCV[7]作为基础网络,仅对前个相关像素建立稀疏相关体,与计算稠密相关体的网络相比,系统精简且计算精度不变。
(2) 将注意力机制引入到系统中,可以提取通道与空间维度上的更重要信息,提高了网络整体处理能力,减少了网络的参数量和复杂程度。
(3) 完整的自监督学习网络,在Sintel[8],Flying Chairs[9],Middlebury[10]和KITTI数据集上进行系统实验。
1 相关工作
1.1 经典方法
经典方法将光流计算视作求能量最小化的优化问题,如式(1)。HORN[1]使用变分法求解这个连续优化问题;Barron[11]第一次提出光流数据集和评估方法;BROX等[12]利用warping和LDOF方案来解决大位移运动。

其中,Data为数据项;Prior为先验项;为调节数据项与先验项权重的因子。
1.2 监督学习光流计算
文献[9]设计了Flying Chairs数据集,首次使用卷积网络进行光流计算,给出了“FlowNetS”和“FlowNetC”2个网络框架;FlowNet2[13]通过堆叠FlowNetS和FlowNetC、改进训练方案和针对小位移的网络结构设计等,极大地提高了光流计算的精度和性能。但FlowNet2的网络参数超过了160 M,同时需要较长的训练时间。文献[14-15]均结合了“变形、代价体和金字塔”(warping,cost volume,pyramid,WCP)等技术,不同程度地提高了准确度、降低了系统框架的参数大小和计算时间。
1.3 无监督学习光流计算
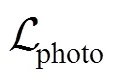
上述这些无监督的学习方法均只能处理遮挡像素的特定情况,或借助于除光流之外的信息,而缺乏对光流的进一步提取,通过自监督学习的方式可以起到进一步的优化作用。
1.4 自监督学习光流计算
自监督学习从数据中生成监督信号,如DDFlow[20]通过数据提纯的方式人为设置更大地学习障碍来达到自监督学习效果。后续如SelFlow[21]等继续设计更苛刻地学习障碍,如通过超像素达到遮挡效果,取得较好地计算精度。文献[22-24]借助于事件相机、陀螺仪或激光雷达数据进行学习,而本文在训练和测试时仅通过计算RGB图像进行光流计算,不依赖其他硬件设备。DistillFlow[25]通过训练多个“Teacher”模式获得高置信度标签数据,对“Student”模块起到监督作用。SMURF[26]使用RAFT作为基本网络,甚至超过了部分监督学习网络的计算效果,例如PWC-Net和FlowNet2。
与上述网络不同,本文首次结合SCV与注意力机制来进行特征提取与处理,通过计算稀疏相关体,既减轻了存储与计算相关体的负担,同时在计算精度上仍然达到与SMURF相当的程度。
2 方 法
2.1 基本定义


2.2 特征提取

2.3 特征注意力提取
经特征提取后,可以得到源图像1/8分辨率的特征图,经典做法是直接通过特征图进行后续计算。但光流的特性决定了其分布在图像的特定区域内,可能位于空间相邻的2个像素间,且运动特性完全不同。又如存在运动模糊的区域,光流很难被正确解析。因此,需要对特征进一步地进行提取,以得到需要特别注意的像素点,这样在后续的光流计算阶段,就可得到更好地解析结果,因此引入了特征注意力模块。

图3 特征提取网络



经过注意力模块可以得到通道和空间维度上更重要的信息,这为后续的光流处理打下良好的基础(图4)。

图4 卷积注意力机制模块CBAM
2.4 基础网络SCV


其中,(,)由式(2)定义;argmax为取出满足相关性最大的个记录;通常会被设置为较小的数字(如32)。


2.5 网络结构与损失函数

图5 SCV网络结构
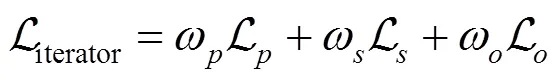

其中,通过Census Loss[17]计算距离。

其中,,为特征的长和宽,依次求图像亮度在,方向的阶导数平均值。


借鉴SCV网络的迭代增量式进行光流计算:每一步的光流预测值+1=f+D+1,计算所得的结果为一个光流序列。因此利用式(7)计算序列中每一步损失,即网络总损失为

其中,权重在数据集Sintel和KITTI上微调训练时设置为0.85,总步骤=8。
3 实 验
3.1 实现细节
实验在MPI Sintel和KITTI数据集上进行,前者数据是人工合成;后者来自于真实场景(根据发布年份,可分为KITTI 2012和KITTI 2015,文中统称KITTI)。与其他算法实验流程不同,本文未在Flying Chairs和Flying Things等数据集上进行预训练,而是直接在Sintel和KITTI数据集上进行训练和微调。即先基于数据集提供的“raw”场景数据进行训练,然后在标准数据集场景下进行微调训练。
在Sintel数据集上训练时,首先基于Sintel数据集提供的raw影片进行帧提取,共获得14 570个图片对;然后在Sintel的标准数据集序列“Clean”和“Final”上进行微调,共1 041个图片对。因为Sintel测试集不公开标签数据,所以模型基于测试集进行训练,在训练集上评估。
在KITTI上进行训练时,也是基于其提供的raw数据序列进行预训练,共包含28 058幅图片对;然后在“多视角”数据序列中进行微调,共包含3 600幅采样图片对。
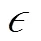
3.2 结果与分析
表1显示了在Sintel数据集上与已有网络的量化比较,在“Clean”和“Final”序列上均达到或接近最新的计算效果。其中数据来源于各自论文中的测试结果。

表1 在Sintel数据集上的结果对比
注:-为部分算法未在train序列上提供结果
表2显示在KITTI数据集上的量化比较,从表中可以看出,与最新的有监督训练相比,还存在着差距,但已经达到或超过了部分的有监督训练结果。

表2 在KITTI数据集上的结果对比
表3显示了在引入注意力节点前后的数据对比,可以看到在引入注意力之后,EPE有较大的改善。同时,空间注意力对整体网络的影响比通道注意力的影响稍大。

表3 引入注意力前后的结果对比
表4显示不同基础网络对计算结果的影响,可看出基础网络本身的计算精度在很大程度上决定了整个系统的计算结果。

表4 不同基础网络的结果对比
图6是特征经过注意力节点前后的情况,第1行是原图与目标图;第2行和第4行分别是没有注意力时的6层特征;第3和第5行是加上注意力后的6层特征,其在空间与通道维度上的图像特征更加集中、细节上更清晰,便于后续的光流计算。

图6 特征图与注意力特征图((a)源图和目标图;(b) 1~3层特征图;(c)注意力特征图;(d) 4~6层特征图;(e)注意力特征图)
图7是在KITTI数据集上的光流计算结果图形化显示,图左可正确捕捉到室外行驶车辆的运动情况,但错误地认为右侧停放的车辆也在运动。

图7 KITTI数据集测试结果((a)源图;(b)预测光流)
表5是使用稀疏相关体的SCV网络与使用稠密相关体的RAFT网络的数据量与存储空间的对比。从表中可以看出,当=8时,稀疏相关体的数据量仅为RAFT的1/1000,可大大节省算力。

表5 SCV与RAFT结果对比
注:表中1/4分辨率的存储空间未列出
表6是在Sintel数据集上进行训练,不同网络所占用的空间对比,从表中可以看出使用SCV网络在训练时可以减少约50%的存储空间。
图8中4幅图为在Sintel数据集的光流计算结果图形化显示,包含了快速移动和细微运动(竹子摆动)等情况。第二列是对应的光流标签数据,第三、四列分别是RAFT和ARFlow,最后一列是本文所模型的计算结果。从图中对比可以看到,在快速移动和细微运动时,本文模型均能捕捉到相应的运动细节。尤其是在第一行的计算当中,由于其左侧的物体运动出图片范围,导致了在目标图像中并没有相对应的元素。如RAFT就没有显示出被遮挡物体的正确运动情况。而本方案可以比较清晰地看到被遮挡物体中的像素运动情况。

表6 训练时占用空间对比(GB)

图8 在Sintel数据集上的测试结果((a)源图;(b)标签数据;(c) RAFT;(d) ARFLow;(e)本文)
3.3 不 足
本文提出的自监督学习网络与监督网络相比,不足之处是没有将真实的光流标签作为训练目标:①难以处理一些具有迷惑类型的运动;②关注图像视觉变化而不是实际对象的移动,如云彩或物体影子的运动;③错误的标签光流带来负面的引导作用,所以需在“Teacher”训练时增加预测结果的可信度参数,在计算“Student”损失函数时引入可信度参数。在后续的工作中,针对图像进行语义分割、对象识别操作方面的预处理工作,或引入其他类型的传感器以获得更多辅助信息。
4 结 论
本文提出的自监督学习网络,减少了对数据集的依赖,缩短了与监督学习之间的差距,是光流计算方法的一种新探索。在后续研究当中,会借鉴更多语义分割和事件相机方面的研究成果来辅助进行光流计算。
[1] HORN B K P, SCHUNCK B G. Determining optical flow[J]. Artificial Intelligence, 1981, 17(1-3): 185-203.
[2] SUN D, YANG X, LIU M Y, et al. Pwc-net: CNNs for optical flow using pyramid, warping, and cost volume[C]//The IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 8934-8943.
[3] TEED Z, DENG J. Raft: recurrent all-pairs field transforms for optical flow[M]// Computer Vision-ECCV 2020. Cham: Springer International Publishing, 2020: 402-419.
[4] HUI T W, TANG X O, LOY C C. LiteFlowNet: a lightweight convolutional neural network for optical flow estimation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 8981-8989.
[5] ZHAO S Y, SHENG Y L, DONG Y, et al. MaskFlownet: asymmetric feature matching with learnable occlusion mask[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 6277-6286.
[6] GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237.
[7] JIANG S H, LU Y, LI H D, et al. Learning optical flow from a few matches[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognitio. New York: IEEE Press, 2021: 16587-16595.
[8] BUTLER D J, WULFF J, STANLEY G B, et al. A naturalistic open source movie for optical flow evaluation[M]//Computer Vision - ECCV 2012. Cham: Springer International Publishing, 2012: 611-625.
[9] DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: learning optical flow with convolutional networks[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 2758-2766.
[10] BAKER S, SCHARSTEIN D, LEWIS J P, et al. A database and evaluation methodology for optical flow[J]. International Journal of Computer Vision, 2011, 92(1): 1-31.
[11] BARRON J L, FLEET D J, BEAUCHEMIN S S. Performance of optical flow techniques[J]. International Journal of Computer Vision, 1994, 12(1): 43-77.
[12] BROX T, BRUHN A, PAPENBERG N, et al. High accuracy optical flow estimation based on a theory for warping[M]//Lecture Notes in Computer Science. Cham: Springer International Publishing, 2004: 25-36.
[13] ILG E, MAYER N, SAIKIA T, et al. FlowNet 2.0: evolution of optical flow estimation with deep networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 1647-1655.
[14] RANJAN A, BLACK M J. Optical flow estimation using a spatial pyramid network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 2720-2729.
[15] HUR J, ROTH S. Iterative residual refinement for joint optical flow and occlusion estimation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 5747-5756.
[16] YU J J, HARLEY A W, DERPANIS K G. Back to basics: unsupervised learning of optical flow via brightness constancy and motion smoothness[M]//Lecture Notes in Computer Science. Cham: Springer International Publishing, 2016: 3-10.
[17] MEISTER S, HUR J, ROTH S. UnFlow: unsupervised learning of optical flow with a bidirectional census loss[EB/OL]. [2022-01-11]. https//arxiv.org/pdf/1711.07837.pdf.
[18] JONSCHKOWSKI R, STONE A, BARRON J T, et al. What matters in unsupervised optical flow[M]//Computer Vision - ECCV 2020. Cham: Springer International Publishing, 2020: 557-572
[19] LI J F, ZHAO J Q, SONG S F, et al. Unsupervised joint learning of depth, optical flow, ego-motion from video[EB/OL]. [2022-01-12]. https://arxiv.org/abs/2105.14520.
[20] LIU P P, KING I, LYU M R, et al. DDFlow: learning optical flow with unlabeled data distillation[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33: 8770-8777.
[21] LIU P P, LYU M, KING I, et al. SelFlow: self-supervised learning of optical flow[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 4566-4575.
[22] LEE C, KOSTA A K, ZHU A Z, et al. Spike-FlowNet: event-based optical flow estimation with energy-efficient hybrid neural networks[M]//Computer Vision - ECCV 2020. Cham: Springer International Publishing, 2020: 366-382.
[23] LI H P, LUO K M, LIU S C. GyroFlow: gyroscope-guided unsupervised optical flow learning[C]//2021 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2021: 12849-12858.
[24] GUO X Z, LIN X H, ZHAO L L, et al. An unsupervised optical flow estimation for lidar image sequences[C]//2021 IEEE International Conference on Image Processing. New York: IEEE Press, 2021: 2613-2617.
[25] LIU P, LYU M R, KING I, et al. Learning by distillation: a self-supervised learning framework for optical flow estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 5026-5041.
[26] STONE A, MAURER D, AYVACI A, et al. SMURF: self-teaching multi-frame unsupervised RAFT with full-image warping[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 3886-3895.
[27] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[M]//Computer Vision - ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
Self-supervised optical flow estimation with attention module
AN Feng1, DAI Jun1,2, HAN Zhen2, YAN Zhong-xing1
(1. School of Artificial Intelligence, Suzhou Industrial Park Institute of Services Outsourcing, Suzhou Jiangsu 215123, China; 2. School of Economics & Management, Tongji University, Shanghai 210092, China)
Optical flow estimation is the key module of many computer vision systems, which is widely utilized in motion recognition, robot positioning, and navigation. However, due to the absence of labeled optical flow datasets of real scenes, synthetic datasets were used as the main training data sources, and synthetic data could not fully represent real scenes (such as leaf movement and pedestrian reflection). Unsupervised or self-supervised methods could employ a large amount of video data for training, and at the same time facilitate fine-tuning of supervised training, which was an effective way to solve the lack of datasets. In this paper, a self-supervised learning optical flow calculation network was constructed, in which the “Teacher” module and the “Student” module adopted sparse correlation volume (SCV) network to reduce the redundancy of correlation computation, and the attention model was introduced as a node of the network, in order to enhance the dimension attribute of image feature in terms of channel and space. This paper marks the first endeavor to implement a self-supervised optical flow computing network based on SCV. The test results on the KITTI 2015 dataset could reach or outperform those of the common supervised training networks such as FlowNet and LightFlowNet.
optical flow estimation; self-supervised learning; convolutional block attention module; spatial/channel attention; sparse correlation volume
TP 242
10.11996/JG.j.2095-302X.2022050841
A
2095-302X(2022)05-0841-08
2022-04-08;
2022-05-31
8 April,2022;
31 May,2022
国家自然科学基金项目(71272048);江苏省高校“青蓝工程”优秀教学团队项目(苏教师函[2020]10号)
National Natural Science Foundation of China (71272048); Jiangsu “Qing Lan Project” ([2020] 10)
安 峰(1978-),男,硕士研究生。主要研究方向为光流计算与SLAM等。E-mail:anf@siso.edu.cn
AN Feng (1978-), master student. His main research interests cover optical flow estimation and SLAM, etc. E-mail:anf@siso.edu.cn
戴 军(1976-),男,教授,博士。主要研究方向为系统工程与决策。E-mail:daij@siso.edu.cn
DAI Jun (1976-), professor, Ph.D. His main research interests cover system engineering and decision, computer vision, etc. E-mail:daij@siso.edu.cn
