考虑可达性的Top-k空间关键词查询
2022-11-02任佳宇李艳红冯雨
任佳宇,李艳红,冯雨
(中南民族大学 计算机科学学院,武汉 430074)
传统的空间关键词查询(SKQ)以一个地理位置和若干关键词作为参数,返回若干个满足空间与文本约束、根据指定公式排列的结果.SKQ已由欧氏空间扩展到了道路网络,但现有文献仅考虑查询点与空间-文本对象之间的静态距离以确定空间邻近度,而未考虑现实生活中用户从某一时刻出发、在一段时间内由查询点到达对象的可能性.
图1中有3个对象o1、o2、o3和一个查询点Q.假设兴趣点o1和o2满足查询q的关键词要求,且Q与o1之间的距离小于Q与o2的距离.但在一天中的某些时刻,由于交通等原因,在给定的时间间隔内从Q到达o1的可能性小于从Q到达o2的可能性,那么此时o1不一定是优于o2的选择.因此将可达性作为Top-k空间关键词查询的一个因素是很有必要的.

图1 道路网络与空间-文本对象Fig.1 Road network and spatio-textual objects
为了将可达性这一因素加入SKQ中,本文提出了一种兼顾可达性、空间邻近度和文本相似性的算法,通过设计SRTR-Tree(Spatio-Reachability-Temporal-R-Tree)索引进行实现.在查询过程中分别根据可达性、空间邻近度和文本相似性进行剪枝,以加快查询速度.
1 相关工作
1.1 时空可达性查询处理
传统的可达性查询是一种基本的图操作,查询一个有向图的两个节点之间是否存在路径.文献[1-2]构造了一个小而有效的索引解决此类可达性查询.文献[3]用一种图缩减方法加速可达性计算,文献[4-5]则提出了不同的标记方法来缩减索引大小.
目前可达性查询常用于检测城市路网中是否存在从一点到另一点的路径.基于历史轨迹数据集,文献[6]对道路进行重新分割并将轨迹与地图匹配,通过最大边界区域搜索和回溯搜索找到所有可到达路段,从而挖掘时空可到达区域.该方法对于单位置时空可达性查询(S-query)和多位置时空可达性联合查询(U-query)均有效.文献[7]提出并解决了多位置时空可达性交集查询(I-query).
与可达性相关的应用层出不穷.文献[8]构建了基于GIS的高分辨率时空总线网络模型.公共交通从起点到目的地的可达性通过计算总出行时间来衡量.文献[9]提出了一种称为STRC的时空可达面积计算方案,分别针对时间敏感应用和距离相关应用设计了边界段选择策略,提高了其方案在实际城市交通服务中的适用性.文献[10]提出了时空网络结构的线性整数规划模型,以最大限度提高从不同来源到特殊活动地点的全系统交通可达性.文献[11]通过构建一个与时间相关的时空网络来提高可达性,从而在道路使用者的出行时间预算内最大限度地增加可访问活动地点的数量.
1.2 空间关键词查询
典型的空间关键词查询包括查询位置、查询关键词、约束集、排序函数和返回结果的数量,返回满足约束且综合排名较高的结果对象.文献[12]将具有地理位置和文本属性的对象称为空间-文本对象.倒排文件常用于组织对象的文本信息.R-tree、网格索引及其变体通常用于组织对象的空间信息.
为了处理Top-k空间关键词查询,各种基于R-tree的索引结构被提出.文献[12]使用R-tree对所有对象的地理位置进行索引.为每个叶节点创建一个倒排文件,以索引其包含的对象的文本.文献[13]将倒排列表与R-tree结合,设计了IR-tree及其变体DIR-tree,将文本相似度与空间邻近度融合在一起.文献[14]提出的WIR-tree是IR-tree的另一个变体,它根据包含的关键词对对象进行分组,以便每个组共享尽可能少的关键词,从而加快对不相关对象组的修剪.文献[15]介绍了一种IR2-tree的索引结构,它将R-tree与叠加的文本签名结合.
此外,空间关键词查询的一些变体也被提出并解决.文献[16]研究了连续移动的Top-k空间关键词查询,提出了两种计算安全区的算法以保证在任何时候都能得到正确的结果.文献[17]提出了一种支持移动Top-k空间关键词查询的有效方法.文献[18]探索了方向感知查询处理,它返回满足查询方向和关键词约束的k个最近邻对象.文献[19]研究了一组位置感知对象上的通用位置感知排名查询.传统空间关键词查询及其各种变体得到了解决,然而道路网络中的可达性这一重要因素并未受到重视,本文将可达性计算与传统的空间关键词查询相结合,提高了查询的精确性.
2 问题定义
2.1 基本概念
道路网络道路网络用图G=(V,E)来表示,V是顶点集合,E是边的集合.顶点v∈V表示道路交叉点或端点,边(v,v′)∈E代表一个路段.
空间-文本对象假设一组空间-文本对象o∈O在路网G的边E上,每个对象都有空间位置信息o.l(经纬度)和文本描述o.doc.
轨迹轨迹是道路网络上交通工具行驶的路线信息,由一系列时空点组成,每个点包含轨迹ID、空间位置及时间戳等信息.
轨迹可达性给定查询起始位置q.s、路网中的一个路段Ri、查询开始时间q.t和持续时间q.d,轨迹可达性反映了历史轨迹是否在给定持续时间内从起始位置穿过给定路段的事实.如果路段Ri在q.d内可以到达,则轨迹可达性为1,否则轨迹可达性为0.
可到达路段给定查询起始位置q.s、查询开始时间q.t和持续时间q.d,若从q.s到路段Ri的轨迹可达性为1,则称Ri为可到达路段.
路段可达概率路段可达概率描述了历史轨迹数据集中在给定持续时间q.d内,从起始路段R0(q.s所在的路段)到达目标路段Ri(对象o所在的路段)的概率,可达概率的大小介于0和1之间.
空间-文本对象可达概率空间-文本对象的可达概率用它所在路段的可达概率来表示.
表1列出的是本文出现的符号及其定义.

表1 符号与定义Tab.1 Symbols and definitions
2.2 基本定义
定义1考虑可达性的Top-k空间关键词查询q=<q.s,q.doc,q.t,q.d,q.r,k>,其中q.s表示查询位置;q.doc表示查询关键词,是一个集合;q.t和q.d分别表示查询的开始时间和持续时间;q.r表示用户指定的可达概率.考虑可达性的Top-k空间关键词查询q返回满足可达性和关键词要求、总评分排在前k个的空间-文本对象.总评分综合考虑查询q和对象o之间的可达性、空间邻近度和文本相似性.
定义2综合评分函数Rank(q,o)定义如下:

其中Prob(q,o)是从q.t开始、在持续时间q.d内,从q.s到o.l的可达概率;Sr(q.s,o.l)和Tr(q.doc,o.doc)分别为q与o之间的空间邻近度和文本相似性.α,β∈(0,1)表示用户的偏好参数,用于调节可达性、空间邻近度和文本相似性在评分函数中的比重.对于空间维度的信息,当α=0且β≠0时,用户只考虑查询点到对象的空间邻近度;当α≠0且β=0时,用户只考虑在给定时间内能否到达,并不在意查询点到对象的距离有多远.
定义3可达概率Prob(q,o)是可达性的量化表示,设查询q所在路段为R0,对象o所在路段为Ri.Prob(q,o)定义为:

其中m为历史轨迹数据的总天数,将每一天的可达概率求和之后取平均值,即为可达概率.Probj(q,o)的计算公式为:

若Ri≠R0,trs是在开始时间q.t经过起始路段R0且最终经过Ri的轨迹集合,tre是在q.t经过起始路段R0且在[q.t,q.t+q.d]经过Ri的轨迹集合.若Ri=R0,trs是在开始时间q.t经过起始路段R0的轨迹集合,tre是在[q.t,q.t+q.d]内从未离开过路段R0的轨迹集合.tre的计算公式为:

若Ri≠R0,根据索引结构的时间粒度将q.d划分为n个时间段,若路段Ri是可达的,那么可能在任何一个时间段l内到达,从l=0开始进行计算,考虑在q.t所在的时间间隔内从R0可以到达Ri的这种情况;若Ri=R0,trl是在第l个时间段内没有离开路段R0的轨迹集合.
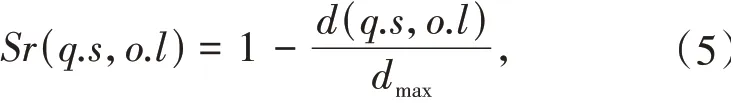
定义4空间邻近度Sr(q.s,o.l)描述的是查询q到对象o之间路网距离的邻近度,其定义如下:d(q.s,o.l)为q.s与o.l之间的路网距离,dmax是路网中任意两点之间的最大路网距离.
定义5文本相似性Tr(q.doc,o.doc).本文采用cosine相似性来计算q与o之间的文本相似性,定义如下:
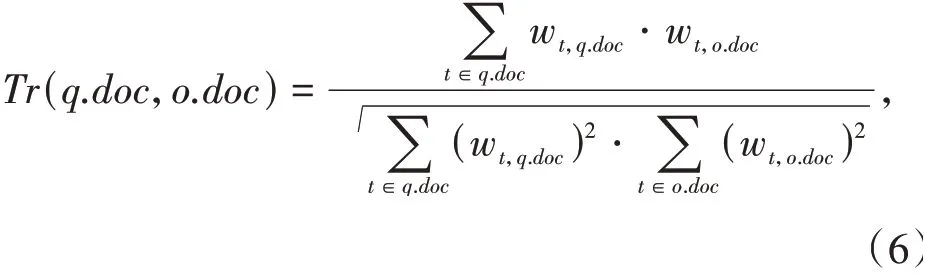
其中关键词t在对象关键词集合o.doc中的权重wt,o.doc=1+ln(ft,o.doc),ft,o.doc为t在o.doc中 出现 的 次数;为空间-文本对象集合O中对象的数量,dft是集合O中关键词t出现的次数.
3 系统结构
3.1 数据预处理
(1)对道路进行重新分割.对象的可达概率由其所在路段的可达概率表示,路段过长会影响查询结果的准确性,本文根据一定的空间粒度重新分割原始道路,分割时如果剩余部分的长度小于给定空间粒度的一半,则将其合并到相邻路段中;否则将其作为单独的路段.记录重新分割后新路段的长度,并插入交叉点连接生成的新路段,以保持道路的连通性.图2给出了道路重新分割后的部分路网结构.

图2 道路重新分割后的部分路网结构Fig.2 Partial road network structure after road re-segmentation
(2)进行地图匹配.将原始轨迹映射到重新分割的道路网络.首先将GPS点映射到相应路段,然后连接所有路段以构成映射的轨迹,并将瞬时速度、车辆ID和时间戳等添加为其属性.一个移动对象每天只有一条轨迹,该轨迹由包含时间、速度等属性的路段序列构成.
3.2 SRTR-Tree索引
为了有效组织道路网结构信息、轨迹信息以及空间-文本对象的信息,在R-Tree基础上构造了一种新的索引SRTR-Tree.首先用R-Tree对道路网络及其上的对象进行划分并保存划分结果.图3给出了图2中道路网络及其上对象的划分结果.

图3 路网中的交叉点和空间-文本对象Fig.3 Intersections and spatio-textual objects in the road network
SRTR-Tree的每个节点(根节点除外)都有一个指向其父节点的指针和若干个指向其子节点的指针.每个对象都位于一个路段上,对象的位置信息由其到所在路段顶点的距离表示.图4展示了SRTR-Tree的总体结构.

图4 SRTR-Tree索引Fig.4 SRTR-Tree index
SRTR-Tree的根节点连接一个邻接组件,表2展示了邻接组件的具体内容,它记录道路网络中每个路段的长度、其相邻路段及交叉点,以查找从查询q到对象o将经过哪些路段.

表2 邻接组件Tab.2 Adjacency component
SRTR-Tree的每个节点连接一个基于关键词的倒排文件,表3为节点E1的倒排文件,其中包含该节点所指路网区域中所有对象的关键词的并集,对每一个关键词记录包含它的子节点的ID,用于加速与查询相关区域或路段的选择.

表3 倒排文件Tab.3 Inverted file
图5展示了SRTR-Tree中的时间-轨迹组件.时间信息有两个维度:日期和时间.首先根据交通情况将一天的时间划分为“早高峰时段”(7:00-9:00)、“晚高峰时段”(17:00-20:00)和“平峰时段”(除前两个时段外的其他时段);其次将早晚高峰时段以10 min为间隔进行划分,平峰时段以30 min为间隔进行划分.因为高峰期人们对时间的规划比其他时段更精确,对可达性有更高的要求,时间粒度越小,计算结果越准确;最后根据“先时间,后日期”的原则,将通过某一路段的所有轨迹的ID存储在相应的日期和时间信息表中.
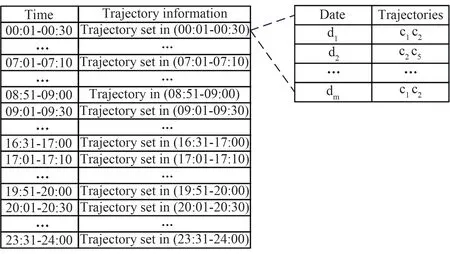
图5 时间-轨迹组件Fig.5 Temporal-trajectory component
4 查询处理
4.1 剪枝策略
引理1已知一个RSKQ查询q=<q.s,q.doc,q.t,q.d,q.r,k>和一个路段R,若Prob(q,R)<q.r,则路段R及其未被检索的相邻路段R′可以被安全地剪枝.
证明对于路段R上任意对象o,Prob(q,o)=Prob(q,R).若Prob(q,R)<q.r,则Prob(q,o)<q.r,R上的对象都不满足可达性要求,R可以被安全地剪枝.R的未被检索的相邻路段R′与查询q的距离相较于R与q的距离更远,有Prob(q,R′)≤Prob(q,R),可知对于R′上的对象o′有Prob(q,o′)<q.r,故R的未被检索的相邻路段R′也可以被安全地剪枝.
引理2已知一个RSKQ查询q=<q.s,q.doc,q.t,q.d,q.r,k>和一个区域E(或路段R),若E.doc∩q.doc=Ø(或R.doc∩q.doc=Ø),则区域E(或路段R)可以被安全地剪枝.
证明对于区域E(或路段R)中的任意对象o,都有o.doc⊆E.doc(或o.doc⊆R.doc).若E.doc∩q.doc=Ø(或R.doc∩q.doc=Ø),有o.doc∩q.doc=Ø,则对象o与查询关键词无关,不会是结果对象.
引理3已知一个RSKQ查询q=<q.s,q.doc,q.t,q.d,q.r,k>和一个路段R,若d(q.s,R)>dmax·[1-Rank(q,ok)]/β,则路段R可以被安全地剪枝,其中d(q.s,R)为查询点和路段R之间的路网距离,Rank(q,ok)为当前排在第k个的结果对象的综合评分.此时,R的未被检索的相邻路段R′也可以被安全地剪枝.
证明若d(q.s,R)>dmax·[1-Rank(q,ok)]/β,对R上的对象o有d(q.s,o)>dmax·[1-Rank(q,ok)]/β,可知Rank(q,o)=1-β·d(q.s,R)/dmax<1-β·(dmax·[1-Rank(q,ok)]/β)/dmax=Rank(q,ok),因此o不是结果对象,路段R可以被安全地剪枝.关于R′的证明与引理1后半部分的证明类似.
4.2 查询处理算法
算法1给出了可达概率的计算流程.可达概率的值probability初始化为-∞,轨迹集trs和tre初始化为空(第3行).m是轨迹数据覆盖的总天数,Δt是SRTR-Tree中q.t所在时间区间的时间粒度.对每一天d构造集合trs(第5-9行)和tre(第10-14行),从而根据公式(3)计算可达概率(第15行);然后计算每一天d的可达性的平均值,并将其作为可达概率的结果值返回(第17-18行).

?
算法2展示了RSKQ查询的处理过程,该方法采用了路网扩展的思想,从q所在路段R0开始,按路网距离升序依次探索相邻路段,直至找到k个结果对象或检索完所有可能的路段.
集合Result、队列NR和指针LNode初始化为空,它们分别用于保存结果对象、未被访问的候选路段和正在访问的SRTR-Tree叶子结点.变量Rank(q,ok)初始化为-∞,用于保留集合Result中当前第k个结果对象的综合得分.
首先根据位置信息q.s定位查询q所在的起始路段R0(第4行);第6-17行对起始路段R0上的对象进行处理,若起始路段满足可达性要求且尚未找到k个结果对象,则对其他路段及其上的对象进行处理(第18-32行).检索所有可能的路段后,返回结果集Result(第33行).
算法时间复杂度分析:根据算法1,假设在查询起始时间q.t经过查询点q的平均轨迹数量为|TR|、历史轨迹数据集包含的总天数为m,那么计算可达概率的时间复杂度最高为O(|TR|×m).根据算法2,假设需要检索的平均路段数为|R|、每个路段上的平均关键词个数为|R.doc|、查询关键词的个数为|q.doc|,则RSKQ查询的时间 复杂度最高为O(|R|×(|TR|×m+|R.doc|×|q.doc|)).事实上,m、|TR.doc|和|q.doc|都是常数,且在使用3种剪枝技术的情况下,算法的时间复杂度小于此处给出的最高值.

?
5 实验
5.1 实验设置
实验采用了3个数据集:(1)从OpenStreetMap中提取的深圳道路网;(2)一个合成的对象集,包含一组随机分布在深圳市路网上的对象,对象的关键词从OpenStreetMap中获取;(3)深圳市出租车的轨迹数据集,包含21385辆出租车在2014年11月内30天的轨迹,共有407040083个GPS点,平均采样率为30 s.
目前还没有处理RSKQ查询的成熟算法.传统的Top-k空间关键词查询通常采用基于IR-Tree的方法,单源最大边界搜索算法(SQMB)和回溯搜索算法(TBS)共同查询可达区域.因此,本文结合上述3种方法作为基线方法(称为“IR-Tree+SQMB+TBS”)与所提出的基于SRTR-Tree的方法进行比较.
实验通过改变开始时间、关键词数量、查询持续时间、空间文本对象数量、结果数量、可达性、参数α和β来验证这两种方法的性能,如表4所示.

表4 参数设置Tab.4 Parameter settings
5.2 实验结果
(1)关键词数量的影响.如图6所示,随着关键词数量的增加,IR-Tree和SRTR-Tree中的候选区域或路段也增加,计算候选对象的综合得分需要更多的时间.但基线方法的处理时间更长,因为无论关键词数量如何变化,都要首先通过SQMB+TBS算法获得可达路段.

图6 查询关键词数量的影响Fig.6 Impact of the number of query keywords
(2)查询开始时间的影响.开始时间主要影响可达性计算的效率.由图7可知,由于高峰时段的交通拥堵,上午8时和晚上20时左右处理时间明显低于其他时段.当查询开始时间为16时或24时,处理时间基本相同.交通状况越好,可达面积越大,可达性计算时间越长,但本文提出的方法较基线方法更优.
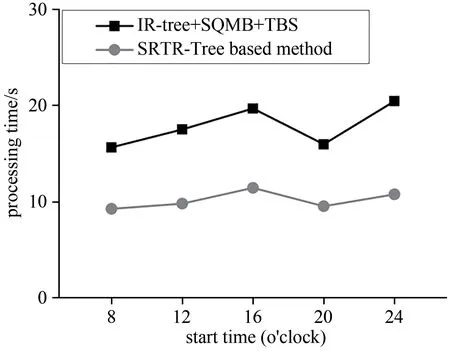
图7 查询开始时间的影响Fig.7 Impact of the query start time
(3)查询持续时间的影响.如图8所示,SQMB+TBS算法的处理时间随着q.d的增加而增加.基于IR-Tree的空间关键词查询方法,在更大的可达区域中有更多的候选对象需要检索,因此运行时间增加.当q.d增加时,本文方法的处理时间增加,但少于基线方法.
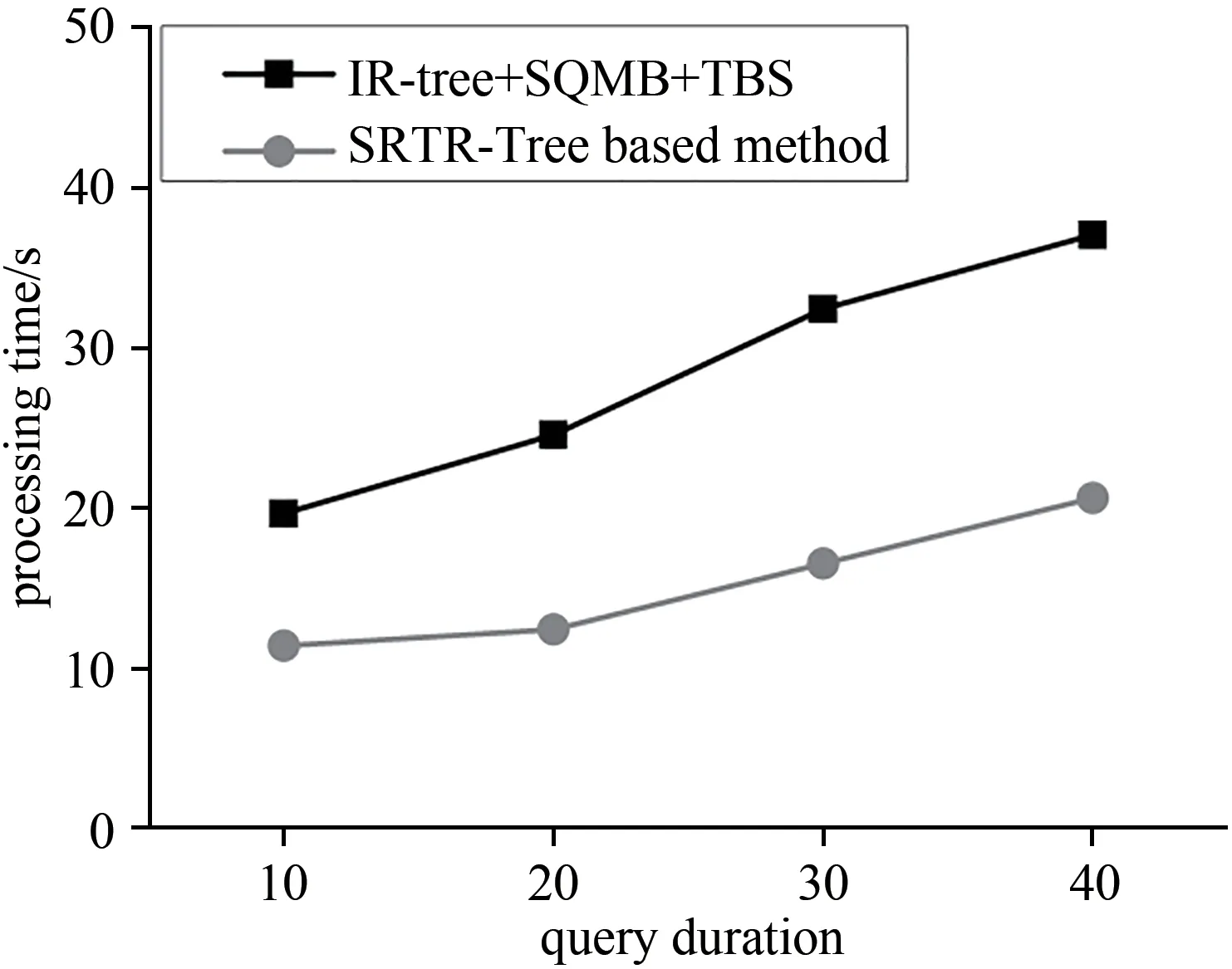
图8 查询持续时间的影响Fig.8 Impact of the query duration
(4)可达概率的影响.SQMB+TBS算法的查询处理时间对q.r的依赖性较小.如图9所示,可达概率越大,候选对象数量减少,查询处理时间缩短.本文的方法从起始路段R0开始按照路网距离的升序探索相邻的可达路段,以找到结果对象.当q.r为0时,需要探索的路段最多,处理时间最长,q.r增大时,处理时间不断减少.

图9 可达概率的影响Fig.9 Impact of the reachable probability
(5)对象数量的影响.由图10可知,路网中对象数量的增加使得基线方法的运行时间增加,但对象在路网上分布得更加密集,需要检索的路段变少,本文所提方法的处理时间减少.

图10 对象数量的影响Fig.10 Impact of the number of objects
(6)结果对象数量的影响.k的增加不影响SQMB+TBS算法的处理时间,基于IR-Tree的方法却必须检索更多的对象,但SKQ查询所需的时间比可达概率计算少几个数量级,基线法的处理时间变化很小.本文方法的处理时间随k值的增大而增加,见图11.

图11 结果对象数量的影响Fig.11 Impact of the number of result objects
(7)α的影响.α为0时,查询只关心q与o之间的路网距离.此时RSKQ查询相当于传统的SKQ查询,两种方法的处理时间几乎相同;α大于0时,查询处理应考虑对象的可达性,处理时间远高于传统SKQ查询,但增加的幅度不大,见图12.

图12 α的影响Fig.12 Impact of α
(8)β的影响.当β为0时,只考虑从q到o的可达性.随着β逐渐增大,查询q和o之间的空间邻近度的权重增加,对远离查询q的更多区域和路段进行修剪,减少了处理时间,见图13.

图13 β的影响Fig.13 Impact of β
6 总结
本文研究了基于可达性的Top-k空间关键词查询(RSKQ)处理问题.将对象可达性引入到传统的SKQ中,从而提高查询结果的有效性.设计了一种高效的索引SRTR-Tree,有效地组织了道路网络、轨迹和道路网络上的空间-文本对象的信息.此外,还提出了几个引理来修剪大量不相关的查询空间对象.基于SRTR-Tree提出了解决RSKQ查询的算法,并通过大量实验证明了其有效性.
