基于Selenium框架实现Boss直聘网数据爬取与分析
2022-10-31裴丽丽
裴丽丽
(山西机电职业技术学院,山西 长治 046011)
1 绪论
随着互联网行业的蓬勃发展,网络的信息呈现爆炸式的增长,大数据时代随之而来。如何在海量信息中寻找满足自己需求的信息,无论是搜索引擎还是个人或者组织,要获取目标数据,都要从公开网站爬取数据,在这样的需求之下,网络爬虫技术应运而生[1]。
本文提出使用Selenium自动化测试工具进行Boss直聘网数据爬取,可以绕过Boos直聘网设置的反爬手段,获取到岗位名称、工作地点、薪资、工作描述等信息。之后将爬取到的数据存储到boss.csv文件中,并对数据进行分析和可视化展示,提高学生的专业和职业认同感,同时为学生未来就业提供参考。
2 相关技术介绍
2.1 网络爬虫
网络爬虫是可以自动地大量抓取网页数据的计算机程序和脚本,别称:网络蠕虫、spider(网页蜘蛛)[2]。它可以根据某种特定的策略去不断抓取网络站点信息,从而完成自动抓取目标数据。使用该技术可以从网络中爬取有效的数据信息,以便后续用于分析研究。目前网络爬虫应用最广泛的语言是Python语言,该语言简单易学,具有丰富的库和框架,常用的库有requests、re、bs4、lxml等,可以满足爬虫的需求。但是使用这些常规的库,经常会受到网站反爬机制的限制,无法获取到待提取的数据。
2.2 Selenium
Selenium是一个自动化测试的工具,主要用于Web应用程序。Selenium测试直接运行在浏览器中,本质是通过执行程序自动驱动浏览器,并模拟浏览器的一系列操作行为,比如元素定位、翻页、点击、跳转等,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。可支持多种浏览器如Chorme,FireFox,IE等[3]。使用Python、Selenium和谷歌浏览器组合进行网络爬虫,可以绕过一些网站设置的反爬措施,达到爬取数据的目的。
3 Boss直聘网数据爬取
使用Selenium自动化爬取Boss直聘网数据,主要分为四个步骤:1) 安装并导入Selenium库及谷歌浏览器对应版本的chromedriver.exe;2) 创建浏览器对象并向网页发送请求;3) 调用浏览器对象,在网页源码中进行节点定义和元素提取及模拟浏览器进行点击翻页等操作;4) 数据存储。
3.1 发送请求
导入Selenium库中的webdriver模块,创建浏览器对象,通过对象调用get方法向Boss直聘网中查找“爬虫”相关岗位的网页发送请求。
from selenium import webdriver
bro=webdriver. Chrome ()
bro. get(' https://www. zhipin. com/ job_detail/?query=爬虫&city=100010000&industry=&position=' )
3.2 节点定位和元素提取
Selenium的webdriver提供了通过id标签值、name标签值、xpath、类名、CSS选择器、链接文本等八类方法来定位页面上的元素[4],可以定位一个元素,也可以定位多个元素。
在实际的页面定位时,根据网页源码的格式恰当地选择定位页面元素方法。本系统主要使用CSS选择器来定位“工作名称”,“地区”,“公司名称”,“薪水”,“公司类型”和“公司福利”六种信息。由于要获取当前一页的招聘信息,需要先找到包含所有招聘信息的标签,通过观察发现,每一则信息包含在li标签内,所有的li标签都包含在div标签
for li in lis:
area=li.find_element_by_css_selector('.job-area' )#地区
job_name=li.find_element_by_css_selector('.job-name a' )#工作名称
company_name=li.find_element_by_css_selector('.company-text .name a' )#公司名称
salary=li.find_element_by_css_selector('.job-limit clearfix .red' )#薪水
company_type=li.find_element_by_css_selector('.false-link' )#公司类型
company_fuli=li.find_element_by_css_selector('.info-desc' )#公司福利
定位到六种待提取的标签之后,通过text属性即可提取出标签内的文本内容。输出后的部分结果如图1所示。

图1 提取元素结果
3.3 模拟浏览器操作
获取到一页的招聘信息后,可以继续通过Selenium实现自动翻页,继续获取后续的信息。此时需要先找到每一页的翻页按钮,点击进行跳转,定位到源码,源码中有class="next"属性,代码为:bro.find_element_by_css_selector('.next' ).click(),将节点定位元素提取和翻页操作作为get_job函数的函数体,为完整的一页招聘信息提取过程。通过for循环语句,即可控制爬取具体页数,如爬取10页招聘信息,代码为:
for i in range(10):
time.sleep(2)
get_job()
3.4 数据存储
本系统将爬取的数据存储到boss.csv文件中,首先需要导入csv模块,然后写入表头,写入表头的代码为:
import csv
f=open(' boss.csv',mode="a",encoding="utf-8",newline="")
csv_writer=csv.DictWriter(f,fieldnames=[' 工作名称',' 地区',' 公司名称',' 薪水',' 公司类型',' 公司福利' ])
csv_writer.writeheader()
写入表头后,需要继续写入爬虫获取到的招聘信息,由于writerow可以接收字典格式的数据,在每获取到一则信息后,需要按行写入csv文件,代码为:
dict={"工作名称":job_name,"地区":area,"公司名称":company_name,"薪水":salary,"公司类型":company_type,"公司福利":company_fuli}
csv_writer.writerow(dict)

图2 部分数据存储
4 数据清洗
数据分析前很重要的一个工作是数据清洗,以便于数据分析的结果更为准确,其中,数据清洗主要有处理重复值、缺失值和脏数据。本系统以分析各地区平均薪资为例,说明数据清洗的过程。
首先要通过语句data=pd.read_csv(' boss.csv',encoding="gbk")读取boss.csv数据并查看当前数据是否存在重复值和缺失值,如果有,进行去重复值和填充缺失值。其次我们观察到部分地区信息太具体,例如“成都·武侯区·新会展中心”,需要提取出“成都”城市名,去掉后面的地区信息。最后针对当前的薪水格式为“12-24 k”或者“12-18 k·15薪”,需要提取出最高和最低值,计算平均薪水。
4.1 处理重复值和缺失值
通过语句data.duplicated().sum()查看是否有重复值,结果显示存在,通过语句data.drop_duplicates(inplace=True)在原数据上进行处理。
通过语句data.isnull().sum()查看是否有缺失值,结果显示公司福利列有14条缺失值,通过语句data["公司福利"].fillna("无",inplace=True)在原数据上进行处理。
4.2 处理地区名称
通过split函数对地区列数据进行分割,结果为列表,取出列表中的第一个元素,即为城市名。语句为data[' 地区' ]=data[' 地区' ].apply(lambda x:x.split('·' )[0])通过data[' 地区' ].unique()查看数据集包含的所有城市名。结果为:
array([’成都’,’长沙’,’烟台’,’西安’,’北京’,’深圳’,’上海’,’宁波’,’合肥’,’郑州’,’广州’,杭州’,’佛山’,’芜湖’,’石家庄’,’武汉’,’天津’,’青岛’,’东莞’,’渭南’,’南京’,’运城’,’无锡’,’重庆’,’长春’,’珠海’,’沈阳’,’厦门’,’南宁’,’保定’,’淄博’,’大连’,’南昌’,’哈尔滨’,’苏州’,’济南’],dtype=object)
4.3 计算平均薪水
通过字符串的字符提取方法extract提取出薪水列的最低薪水和最高薪水,并计算平均值,代码和结果如图3所示。

图3 计算平均薪水
5 数据分析和可视化
本系统分析各个地区的平均薪水,需要对地区进行分组,计算各组的平均薪水。结果显示爬虫工程师的薪水都比较高,其中佛山的平均薪水最高22.5 k,深入分析后发现,是由于佛山只有一则招聘信息。平均薪水最高的前10个地区结果如图4所示。

图4 各地区平均薪水
为了使结果更加直观,使用pyecharts库对平均薪水最高排名前10的地区进行可视化展示,绘制地区与平均薪水的柱状图,代码与结果如图5所示。
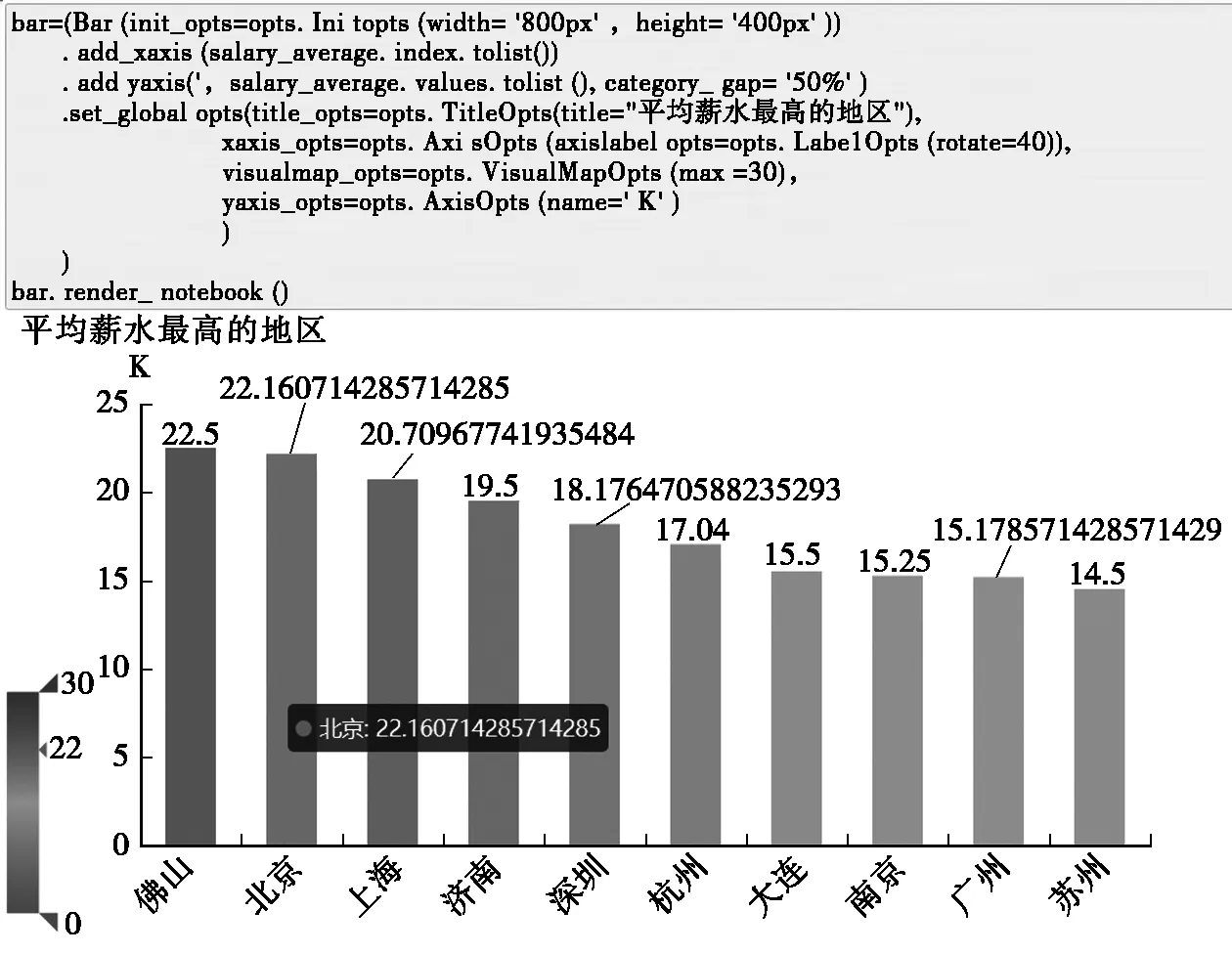
图5 各地区平均薪水柱状图
6 结束语
爬虫作为获取数据的重要工具之一,广泛应用于各种网站,具有广阔的应用前景[4]。但是大部分的网站都设置了一些反爬机制,本系统采用Selenium框架绕过反爬机制,实现了Boss直聘网的招聘信息爬取,同时对求职者较关注的薪资进行了分析并完成了可视化展示。数据分析和可视化适用于继续分析其他有价值的信息。在《数据爬取》课程中以此为教学案例,让学生看到本专业学生的就业前景,提升学生的专业和职业认同感。
