基于k-shape算法的行业典型负荷特征研究
2022-10-27国网四川省营销服务中心王良之姚岱州马浩原
国网四川省营销服务中心 王良之 姚岱州 马浩原
1 引言
2020年迎峰度冬受寒潮和电煤供应短缺的影响,电力供需形势严峻。开展重点行业典型负荷特征研究,为提升电力市场分析预测、实施需求侧响应,以及准确把握负荷供需形势奠定技术基础。文献[1]利用反映负荷特征的向量,通过聚类方式对负荷开展分类,提升了短期负荷预测准确率。另外,掌握行业负荷特征,也将有利于开展对重要工业客户的用能结构和成本分析,为进一步做好综合能源服务和开展电力市场交易奠定基础,成为经营效益的重要抓手。
电力负荷曲线的特征研究中,往往以曲线聚类为研究起点,目前常用的电力负荷曲线聚类的方法有k 均值聚类、层次聚类、模糊C 均值聚类、动态时间弯曲距离(DTW),以及以此为基础改进的算法,这些算法多以欧式距离作为相似性判距的方式,难以识别曲线形态。因此,刻画曲线形态成为聚类的关键。另外,使用传统聚类方法对96点负荷数据进行聚类,计算量大,分类效果未必有很大的提升。
电力负荷曲线采集频率精细化,有利于负荷分析,然而也带来了高维数据计算量大的问题。负荷曲线96点采集频次,虽然对于区分刻画负荷曲线的差异有帮助,也同样增加了噪声因素,给聚类分析带来不便,影响分析结果。因此,如何对负荷曲线提取有效特征,成为分析负荷的关键核心,而如何开展对负荷曲线特征的分类,正是聚类分析所研究的命题。因此,有效提取特征,也成为聚类分析的起点[2]。
本文基于k-shape 的聚类算法,对负荷序列进行聚类,此算法提出基于时间序列形态相似性的距离度量方式,并采用一种新的聚类中心计算方式提取每类簇的负荷曲线形态。类似其他文献的做法[3],笔者在进行聚类之前,对负荷数据进行了降维处理,基于负荷曲线的波动特性,采取分段刻画曲线特征,从而降低了曲线数据维度。另外,对比了其他降维方法或选取特征指标的方式,开展对负荷特征的聚类,结果表明从聚类有效性指标判断,k-shape 算法与k-means、DTW 算法相比综合表现更佳。
2 算法原理
2.1 时间序列形态相似性度量
在进行时间序列相似度计算时,通常采用以下两种方式:一是欧式距离,可以进行同等维度下的时间序列相似性的比较,但其对噪声和异常点较敏感。二是动态时间弯曲距离(DTW),允许时间序列弯曲时间轴,可以度量不同维度下的时间序列的相似性,计算量较大,结果并不理想。为此,考虑使用互相关作为相似性判断方式,互相关是用来比较两个序列x=[x1,x2,...,xm]与y=[y1,y2,...,ym]相似性的一种统计测度方式。
理论上来看,同一类型的电力负荷,如同一个行业或同一家企业产生的负荷曲线,其形态特征及时序特征应该相似,除开外部敏感因素导致的差异可能对负荷特征造成影响。如果将具有相同形态的但存在时域差异的负荷曲线,进行平移。其不同时域下相似形态的曲线并为一个曲线类别,能更好地归并用户用电模式。有鉴于此,为比较不同负荷曲线的相关关系,将样本X 的时间窗口适度平移使之与Y 全局对齐,以便进行两序列全局形状特征的比较。计算平移s 后的时间序列X,s为平移量,由此得出互相关序列CW(X,Y)=[c1,c2,...,cw],其中,cw=Rw-m(X,Y),w ∈{1,2,...,2m-1}。
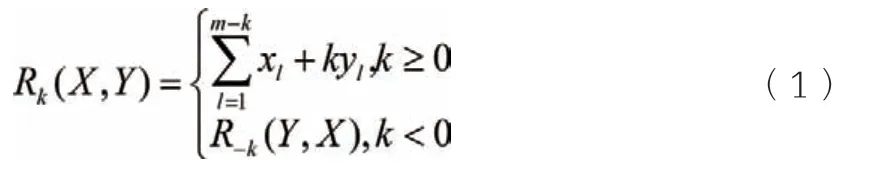
计算当cw达到最大值时w 的位置,相对于Y,X 的最佳位移量s=w-m。最后将互相关系数归一化,互相关系数在-1,1之间,互相关系数越大,两个序列正相关度越高,基于以上计算,提出时间序列相似性判断D 距离量度的方法,即:

2.2 时间序列聚类中心的计算
聚类中心代表时间序列曲线形态特征,k-means 通过计算每类数据中各个坐标序列相对应数值的算术平均值来提取每类簇聚类中心,容易受到极端数据的污染。因此,提取聚类中心可以看作是一个优化选择问题,通过找寻与每类时间序列平方和最小的序列:

其中,c*为使用该方法提取的最终聚类中心,ui是数据序列,c为寻优迭代的聚类中心。该式表明,最优聚类中心,拥有最大互相关系数。
3 K-shape 算法步骤
基于上述理论描述,利用互相关方法找出类的中心,迭代进行,聚类的具体步骤如下:
第一步:制定聚类数k,初始化每类聚类中心c。输入预处理后的负荷数据。第二步:利用公式(1)依次计算负荷集中每一个负荷ui到各类中心c 的距离D,并将ui归入到和c 聚类最小的类i 中。第三步:利用公式(2)提取每类聚类形态特征及每类聚类中心。第四步:重复第二步和第三步。设n为最大迭代次数,当达到最大迭代次数或者每类曲线集合不再发生变化时,停止迭代。第五步:输出分类结果。
4 分析过程
利用部分国民经济主要行业近两年每日的96点负荷数据,使用k—shape 算法进行聚类。考虑到电力数据的高维特征,考虑将负荷数据依据某种特征降维。如平均分段法,把负荷曲线分段聚合近似的方法来降低维度,具体来讲,将时间序列平均分段,比如将96点负荷数据划分为48点或24点数据,利用平均分段后的子序列的均值重构原始数据序列以实现数据的降维处理。然而,使用将时间序列平均分段并利用子序列的均值近似原始数据以实现数据降维的方式,对波动剧烈的时间序列,会丢失很多特征信息。如同平均值容易受到异常值的影响,对原始数据的信息刻画存在失真一样。这样的重构降维方式无法准确反映原有序列的主要形态特征,从而使得曲线聚类出现偏差。为此,需要其他量化曲线的特征的方法,这种方法对极端数据点不敏感,或者可以更有效地刻画波动型数据特征。从而通过有限的曲线特征值来捕捉原始曲线的高维信息,从而实现对高维数据的降维。
对高维曲线的降维,还是基于时间分段,并刻画分段曲线的变化幅度和变化方向这一思路开展降维处理。由于负荷曲线在不同时点上的变化不同,利用在固定时间窗口内,负荷曲线的极差,即固定时间窗口内,最大负荷与最小负荷的差。当这个极差大于某个固定值的点的个数R,来刻画曲线在固定时间内的波动程度。这个点在时间段内出现的次数越多,表明波动幅度越大。另外,除了刻画曲线波动幅度,还应掌握曲线变化方向的信息。基于连续曲线斜率,利用观测点前后曲线的斜率变化情况,来刻画该点是否为曲线显著的拐点,即斜率变化最大的边缘点。对边缘点的个数E 的统计,将有利于衡量负荷曲线变化方向特征。具体做法如下:
第一步:将每段负荷曲线U 分成m 段,若负荷曲线是n 点数据,则每段曲线有n/m 个数据点,计算每段曲线内的Ri(极差个数)和Ei(边缘点个数),最后计算曲线总的R 和E。
第二步:若R 小于阈值a 并且E 小于阈值b,则使用每段平均值代表每段曲线。表明曲线段本身波动在可接受的范围内,可由该段数据的平均值直接代替该段数据,从而实现以一个数据刻画一段数据的降维作用。若R 小于阈值a 并且E 大于阈值b,表明曲线段内振幅不大,但曲线的斜率变化较为剧烈,则利用该段极大值或者极小值替代该段数据。
这种情况表明,该段曲线虽然波动幅度不大,但在波动范围内,曲线趋势发生较大变化,或由平缓变得倾斜,或由倾斜变为平缓。仅仅利用该段内极大值或者极小值就可以刻画这种变化特征。若在其他曲线中出现类似变化,则该段时间内的相似曲线极大或极小值会更为接近。若R 大于阈值a 并且E 大于阈值b,则保留原始数据。如此,该段曲线振幅较大,趋势变化剧烈,直接用原始数据点表达这种异质性。简言之,无振幅的数据,以一代众,降维显著,有振幅有变向的数据保留原始,不降维。
第三步,通过R 和E 刻画现有曲线,计算现有数据的维度,若数据所降维度没有满足要求,则扩大阈值a 和b,继续进行第二步,直到降维数据满足要求。扩大a 和b 会使得曲线振幅和方向性减弱,平均点刻画的情况增多,原始点刻画的情况减少,从而进一步减少维度数。
为了便于与传统方法比较,使用负荷曲线的统计数值特征,来刻画原始数据并参与聚类,同样起到了数据降维的作用。或者采用主成分分析方法先对负荷进行降维,再把降维之后的数据进行聚类。前者做法中,分别选取了负荷数据的统计特征,如均值、方差、变异系数、斜率、端点值等来刻画负荷数据的曲线特征。后者做法上,使用主成分分析法,将96点负荷数据进行了降维,对降维之后的数据进一步开展了负荷聚类。从多项评价指标来看,k-shape 算法呈现出一定的算法稳健特性。下文以某金属品制造行业为例,分析分类的结果,图1显示该行业聚类得到的典型曲线。

图1 某金属品制造96点负荷曲线的聚类
聚类评价指标上选取了SIL 指标、DBI 指标和CP 指标进行聚类效果评价,具体见表1。其中,SIL指标将单个样本与同簇样本相似程度和其他类簇样本相似程度进行比较,SIL 指标越高,聚类效果越好。DBI 指标计算簇内部距离之和与类外距离之比,其指标值越小,聚类效果越佳。CP 指标通过计算样本集,每个样本到该数据集聚类中心的平均距离来判断每类簇紧密程度,指标值越低,聚类效果越好。

表1 各种算法的效果比较
首先,输入降维数据,使用三种算法分别开展聚类分析,在不同聚类类别数时呈现的聚类评价如下:从聚类有效性指标来看,k—shape 算法与其余两种算法综合相比,在不同簇类上,SIL 的值相对较大,DBI 值相对较小,CP 值相对更小,说明较k-means和DTW 算法而言,k-shape 算法的表现更佳。
其次,在上述几种算法的基础上,区分了降维方式,对比不同降维方式下的分类效果。计算了该行业所有负荷曲线的统计指标,用以描述其曲线特征,所有负荷数据进行了标幺化处理后,做了描述性统计分析,选取了平均值、方差、极差、变异系数、中位数等五个主要的统计指标。在统计指标的基础上,进行了k-means 算法的聚类。
另外,通过主成分分析法,将所有负荷数据进行了降维,前4个成分的信息总和超过70%,因此选取前4个成分进行k-means 聚类,并且通过与DTW 等算法进行了比较。以SIL 指标的取值为评价依据,分析结果见表2。

表2 不同数据处理方式的效果比较
以SIL 指标为依据,统计指标降维方式和主成分降维方式,并未在不同算法中并未体现出明显的优势,表明上述两种方式的降维对于刻画曲线形态的作用不明显,另外使用k-shape 算法对原始数据和降维数据聚类的对比依然显示了较强的稳健性。
5 结语
针对电力负荷数据高维度,多形态的特征和传统算法的局限性,k—shape 的聚类算法显示出了一定的优势。一方面在与k-means、DTW 算法的比较中显示较好的聚类特性。另一方面,考虑到降维带来的实际工作效率提升,同时对比了不同算法对降维数据的聚类效果,结果表明k-shape 算法较其他算法更为稳健,且以统计指标、成分分析作为负荷曲线形态刻画的方式和降维思路,在聚类效果上并未有所提升。本文对算法的验证,有助于深刻把握电力负荷的行为模式和曲线特征,在分时电价模式下制定购售电策略,负荷预测等方面有实际作用,未来针对高维负荷数据的形态刻画和聚类效率提升,仍有较大的研究空间。
