基于CEEMDAN-ELM-Adaboost 的水电机组故障诊断
2022-10-27游仕豪郑阳闫懂林陈盛陈天涯陈启卷
游仕豪,郑阳,闫懂林,陈盛,陈天涯,陈启卷
(武汉大学动力与机械学院,湖北武汉 430072)
0 引言
水电机组是水电能源转换的核心设备,其高效安全稳定运行是保证电站安全和电网稳定的重要前提。因此,开展水电机组故障诊断研究,能减少水电机组事故的发生,对保障电网安全稳定的运行具有重要意义。
到目前为止,学者们针对水电机组的故障诊断进行了诸多研究。党建等[1]通过经验模态分解(EMD)和连续几何分布相似性结合实现对水电机组振动信号降噪;杜义等[2]提出经验模态分解的奇异值为基础的水电机组特征提取方法,并结合时域和频域特征,实现对工况的精确识别;陈喜阳[3]等利用PSO优化BP 神经网络的连接权值,提高BP 分类器的识别速度和精度。何葵东[4]等通过采用EEMD 分解后各本征模态函数(IMF)的多尺度熵作为特征值,并结合极限学习机(ELM)对水电机组进行故障诊断。
经过上述的分析可以看出,现已形成了以信号去噪、信号特征提取、诊断模型构建为核心的水电机组故障诊断基本流程。在信号去噪方面,EMD降噪[1],小波降噪[5]、EEMD[6]降噪等方法被广泛使用。但上述降噪方法分别存在模态混叠、适应范围不广泛、IMF分量中残留白噪声等问题,往往导致降噪的效果不理想。本文采用CEEMDAN 方法[7]对振动信号进行降噪处理,能很好的解决模态混叠现象和信号中残留白噪声的问题。在信号特征提取方面,单一的时域特征、频域特征或者信号复杂程度等特征往往不能全面地表征信号特性,在本文中,分别对时域、频域和各IMF 分量样本熵进行提取,构建混合特征向量来表征振动信号特性。最后对于模型构建方面,BP 神经网络[8]、SVM[9]、朴素贝叶斯网络[10]等方法被广泛使用,但存在训练速度慢、精度较低等问题。而GAO Huang等[11]提出了极限学习机(ELM),该方法无需通过迭代调节网络参数,因此训练速度得到大幅提升,具有学习速度快、泛化能力强等优点。本文利用Adaboost算法[12]和ELM 进行组合,能大大提高对水电机组故障诊断的精度和稳定性。
综上,本文将首先对机组原始振动信号利用CEEMDAN 进行分解降噪和重构。然后对降噪后的水电机组振动信号,提取常规的时域和频域特征,通过特征的离散程度大小实现特征的降维,并结合CEEMDAN 分解后主要IMF 分量的样本熵构建混合特征向量,将其作为ELM-Adaboost 强分类器的输入最终得到智能诊断模型,从而实现对水电机组实测振动故障样本集的高精度识别诊断。
1 研究方法
1.1 CEEMDAN
完全自适应噪声集合经验模态分解(CEEMDAN)是互补集合经验模态分解(CEEMD)算法的一种改进算法,该方法能更有效地消除模态混叠现象并且分解后的IMF 分量中无白噪声残留[7]。CEEMDAN分解的步骤如下:
(1)将服从正态分布的高斯白噪声uj(t)(j=1,2,…,N为加入白噪声的次数)加入待分解信号y(t)中得到新信号y(t)+εvj(t),对其进行EMD 分解,得到第一阶本征模态函数分量C1,对产生的N个模态分量取均值得到CEEMDAN 分解的第一个IMF分量为:
(2)计算原始信号去除IMF1后相应的残差。
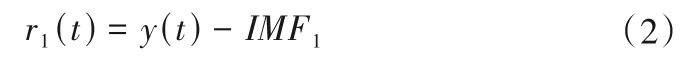
(3)在残差r1(t)中加入服从正态分布的高斯白噪声uj(t)(j=1,2,…,N为加入白噪声的次数)得到新信号,对新信号进行EMD分解得到第一阶模态分量D1,则有:

(4)计算相应的残差。

(5)重复上述步骤,直至残差信号为单调函数且不适合被分解时,算法结束。此时得到m个本征模态函数分量和剩余的残差分量。则原始信号可以表示为:
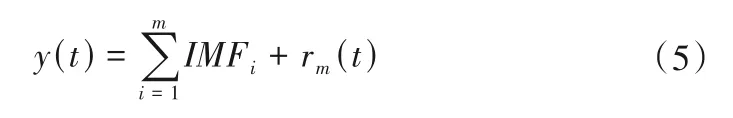
1.2 ELM-Adaboost强分类器
Adaboost 算法[12]的核心是合并多个弱分类器的输出实现更加精确的分类,从而形成强分类器。ELM-Adaboost强分类器即把ELM 分类算法作为弱分类器,通过多次迭代训练ELM 分类器,并通过Adaboost 算法赋予每个ELM 分类器相应的权重并组合成强分类器。ELM-Adaboost 强分类器相比传统的ELM 弱分类器具有分类精度高,分类结果波动性小的优点,其具体步骤如下[13]:
(1)随机选择m组样本作为强分类器的训练数据,赋予每组样本初始权值D1,同时根据数据的输入输出确定ELM 弱分类器的输入层、隐含层和输出层中神经元的个数。
(2)对于每次迭代t(t为ELM-Adaboost 中ELM 弱分类器的个数),重复以下步骤:
①训练第t个ELM 弱分类器并对训练数据的输出进行预测,得到训练数据的预测序列g(t)以及其预测误差和et,预测误差和的计算公式为:

②根据第t个弱分类器的预测误差和et计算该分类器的权重αt,分类器权重计算公式为

③根据弱分类器的权重αt调整下一次迭代中训练样本的权重,调整公式为

式中:Bi是归一化因子,i=1,2,…,m
(3)经过n次迭代后,得到n组弱分类器的输出函数f(gt,αt),并将其组合成强分类的输出函数h(x)。

1.3 基于CEEMDAN-ELM-Adaboost 的故障诊断流程
基于CEEMDAN-ELM-Adaboost 的水电机组故障诊断流程如图1所示,其步骤如下:利用CEEMDAN 对振动信号进行分解重构,实现对振动信号的降噪。提取样本数据的IMF 样本熵特征、时域特征和频域特征,建立包含21个特征的特征数据池,充分挖掘出蕴藏在振动信号中的故障信息。考虑到特征量之间可能存在耦合性和特征冗余性,故对特征池中的特征量做降维处理,从每类特征数据中筛选出差异性明显的特征,构建包含样本数据的时域、频域以及IMF 样本熵的混合特征向量矩阵,将所有样本的混合特征向量划分为训练集和测试集,输入到ELM-Adaboost 强分类器中训练强分类器模型并输出测试集的预测结果。
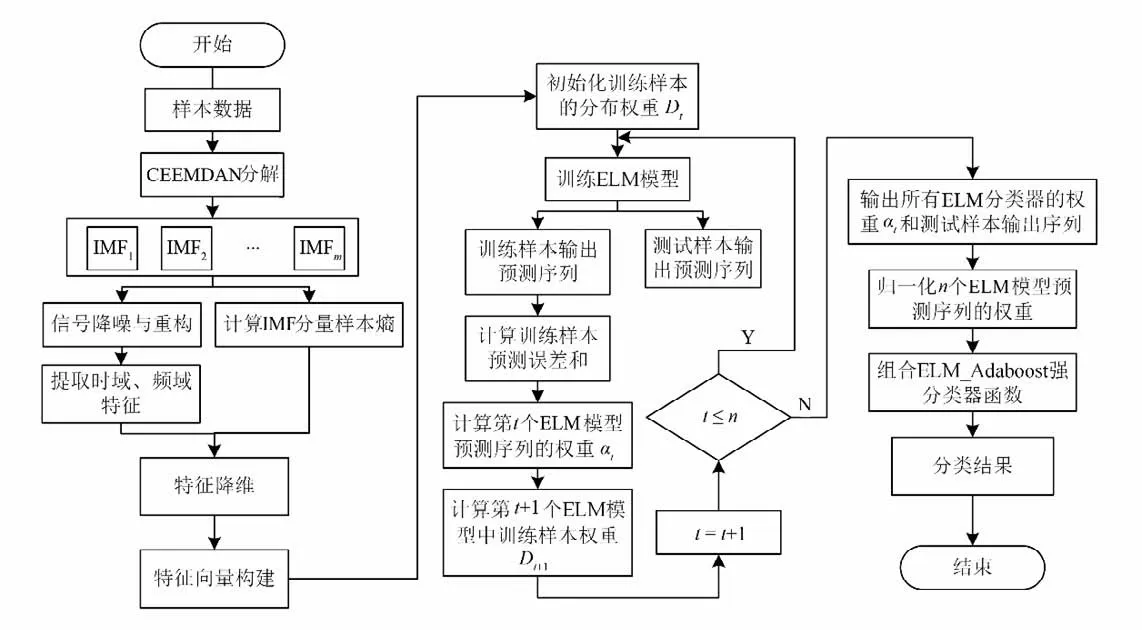
图1 基于CEEMDAN-ELM-Adaboost的故障诊断流程图Fig.1 Fault diagnosis flow based on CEEMDAN-ELM-Adaboost
2 实例研究
2.1 数据来源
本文数据来源于某水电站的三号机组,该机组水轮机型号ZZA315-LJ-800,发电机型号SF200-56/11950,额定功率200 MW,立轴半伞式。分析数据为机组主轴轴向的振动数据,机组故障类型为转轮室碰摩故障。分别将采自于机组故障发生前的数据标记为故障预警状态、故障发生后的数据标记为故障状态、检修后正常运行的数据标记为正常运行状态,其中每种状态数据各40组,每组数据波形长度为4 096 个采样点,数据点的采样频率为458 Hz。
2.2 数据降噪
对每个样本中的原始振动信号进行CEEMDAN 分解,经过多次试验分析,设定加入高斯白噪声的次数为100,高斯白噪声标准差为0.2,最大的迭代次数为1 000。信号分解得到若干个IMF分量,同时计算每个IMF分量与原始振动信号的相关系数,各个IMF分量的相关系数如表1所示。由表1可知,前几个IMF分量与原始信号的相关系数较大,能很大程度地表征原始信号的特征,故可通过选取前几个相关系数较大的IMF 分量进行重构从而达到信号去噪的效果[14-16]。综合120 个样本的分解结果,本文选取前6个IMF分量进行信号重构。

表1 IMF分量与原始数据的相关系数表Tab.1 Table of IMF components in relation to raw data
2.3 特征提取及降维
为更加全面获取振动信号深度蕴含的信息,提高故障诊断的准确性,本文对样本数据中常规的时域特征、频域特征和各IMF 分量的样本熵进行提取,提取的特征及其对应的编号如表2所示。

表2 振动信号特征集Tab.2 Characteristic set of vibration signal
考虑到提取的特征量过多,特征量之间可能存在耦合性和特征冗余性,本文对提取的高维特征集进行降维处理,通过特征值离散程度的差异对提取的特征进行筛选。计算14个时域、频域特征的标准差,得到各特征的离散程度(即标准差的大小)见图2。由图2 可知,部分特征的离散程度几乎趋近于0,即特征值基本都聚集于某一个值的附近,不能对3 种运行状态进行有效区分,故分别剔除掉时域特征和频域特征中离散程度较小的无效特征。通常前几个IMF 分量集中了原始振动信号中最显著、最重要的信息[17]。为保证提取特征的代表性和算法运行的快速性,本文选用CEEMDAN 分解后的前3 个与原始信号相关性系数较大的IMF 分量并计算其样本熵,最后筛选出T1、T4、T5、F2、F3、F4、S1、S2、S3九个特征用来构建混合特征向量。
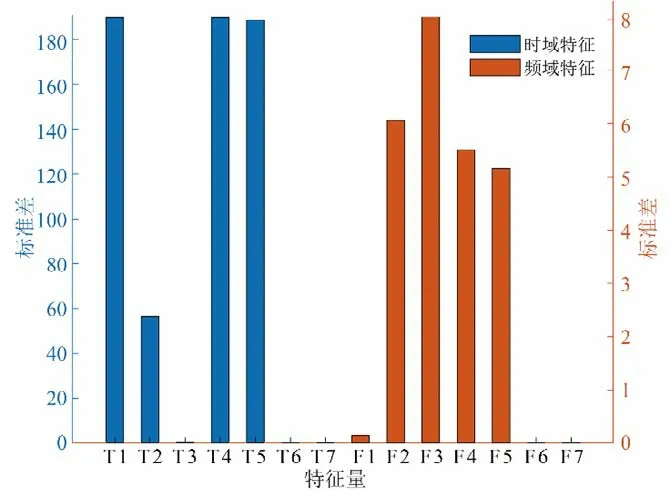
图2 样本特征的离散程度Fig.2 Degree of dispersion of sample features
图3、4 和图5 分别为特征降维处理后的筛选出的时域特征、频域特征和样本熵在不同样本上的分布图,其中样本序号1~40 为正常运行样本,序号41~80 为故障预警样本,序号81~120为故障样本。由图3、4和图5可知,在所筛选出的特征分布图中,故障样本和其他两种样本有较明显的差异,正常运行样本和故障样本在部分特征上的分布上也存在差异。

图3 样本的时域特征分布图Fig.3 Time-domain distribution of the sample

图4 样本的频域特征分布图Fig.4 Frequency domain feature distribution of the sample

图5 样本的IMF样本熵分布图Fig.5 IMF sample entropy distribution of samples
2.4 ELM-Adaboost分类
将降维后的9 个特征组合成混合特征向量,其格式为[T1,T4,T5,F2,F3,F4,S1,S2,S3]。依据每种运行状态对120 组样本按6∶4 的比例随机划分为72 组训练集和48 组测试集。首先对ELM-Adaboost 的输入参数进行初始化,经过多次试验分析,设定ELM 选取的个数为10,ELM 的输入层节点数为9,输出层节点数为3,单隐含层的节点数为50,激活函数为sigmoid 函数。利用训练样本对模型进行训练,对比在EMD 和CEEMDAN 两种不同降噪方法下不同分类方法的分类准确性。考虑到ELMAdaboost 算法在水电机组小样本故障诊断上的适用性,设置训练集和测试组样本数量比例为4∶6 的对照组,并对每种组合运行100 取平均值来避免随机误差的影响,对比试验结果如表3所示。其中实验组中最能代表平均结果的分类结果见图6和图7。
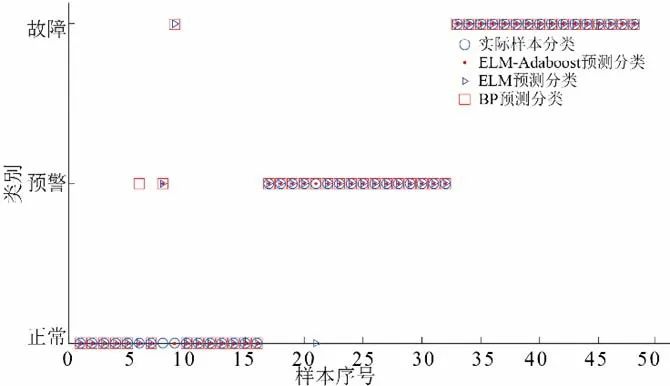
图6 基于CEEMDAN降噪的分类结果Fig.6 Classification result based on CEEMDAN denoising

图7 基于EMD降噪的分类结果Fig.7 Classification result based on EMD denoising
从表3 可知,相比于EMD 分解降噪,利用CEEMDAN 方法进行降噪可以提高分类的准确性。此外,对比相同降噪方法下的3 中分类方法的分类情况,ELM-Adaboost 相比于ELM 和BPNN 分类方法,其对水电机组的故障分类更加精确。同时ELM-Adaboost 也继承了ELM 网络训练速度快的优点,其相比于BPNN 分类方法其运行时间更短。最后,相比于其他两者分类方法,ELM-Adaboost 方法在水电机组小样本故障分类问题上,其识别精度基本不随样本数量的变化而变化,表现出良好的鲁棒性。综上,本文提出的基于CEEMDAN-ELM-Adaboost的水电机组故障诊断方法相比于传统方法具有更好的应用性。

表3 分类准确度对比Tab.3 Comparison of classification accuracy
3 结论
本文提出了基于CEEMDAN-ELM-Adaboost 的水电机组故障诊断方法,并利用水电机组转轮室碰摩故障的实际数据进行分析,得到以下结论。
(1)相比于传统的EMD 降噪方法,通过CEEMDAN 对原始信号降噪能提高后续故障分类的准确性。
(2)相对于传统的BPNN 和ELM 方法,ELM-Adaboost 方法在水电机组小样本的故障分类问题上具有更高的识别精度和鲁棒性。此外,该方法在保证高识别率的前提下具有训练速度的特点。
(3)CEEMDAN-ELM-Adaboost方法在水电机组转轮室碰摩故障识别问题上具有很好的适应性,其识别精度可以达到97.92%。
