融合DOM树结构向量的行为类别标签预测模型
2022-10-25王宝亮陈伟宁潘文采
王宝亮,陈伟宁,潘文采
(1.天津大学信息与网络中心,天津300072; 2.天津大学国际工程师学院,天津 300072; 3.天津大学电气自动化与信息工程学院,天津 300072)
1 引言
在互联网技术迅猛发展的背景下,用户画像技术被广泛应用于危险检测、大数据、新闻推荐等各个领域,其核心是通过对用户各类行为进行分析,从而将用户特征抽象为标签形式。在校园网络行为日志中,关于用户行为的描述信息可分为两大类,一类是用户使用的APP名称、类别及使用时间、使用时长等各类附加属性,另一类则是用户访问的URL地址及其各类附加属性,校园网络日志工具并未对URL进行分类,但判断此类别却对准确描述用户行为特征具有极其重要的意义。
本文以真实校园网络行为日志为基础,对校园网络用户画像进行了深入研究。文献[2]通过网络访问日志得出的学生兴趣雷达图,采用一种基于互信息和关联规则的文本特征提取方法分析用户的潜在兴趣。文献[3]针对传统的机器学习分类方法基本没有考虑文本数据特征,提供无差别的分类服务的问题,提出以文本标题为突破口实现快速分类。
与上述文献不同,为了提高模型的准确率,本文所提模型不仅提取了URL对应网页中的特征文本内容用于词向量训练,还提取并压缩了网页的DOM(Document Object Model)树结构,构建了压缩DOM树结构向量。在生成文本特征向量时,利用TF-IDF方法将每个词向量赋予不同的权重。在生成DOM树结构特征向量时,考虑到3个问题:1)在单一网页中相同结构出现频次的问题,2)在不同网页间各类结构总数的差异问题,3)未过滤出现次数较少的结构,导致向量数目巨大且不统一的问题。本文所提方法对DOM树结构进行了压缩,生成压缩结构向量。最后将文本特征向量和DOM树结构向量进行融合后,通过分类器进行分类并输出分类结果。
2 DOM树理论基础
DOM的本质是基于树的应用程序接口,用于表示整个网页的文档模型。该模型将网页表达为树形结构,各层标签即为树的节点,因此可以系统描述网页标签之间的层级关系,同时提供相应的操作规范以方便渲染和修改标签内容。
为了增加DOM树结构中各节点与网页主题的关联性以提高刻画网页特征的能力,通常可将节点分为表1中的5种类别。
事实上,不同类型网站中的网页DOM树在节点使用和整体结构上都具有其特殊性。例如,图1左侧是常见购物类网站中频繁存在的图片链接与商品描述的捆绑型结构,可将该结构表示成右侧的DOM树结构。需要注意的是,部分视频类网站也存在大量该结构,但在其它布局结构上与购物类网站存在一定区别。

表1 常见DOM树节点类别

图1 购物网站商品捆绑型结构与对应DOM树案例图
又如,新闻类网站通常是以图2左侧所示的较为聚集的文本链接结构呈现,可将该结构表示成右侧的DOM树结构。
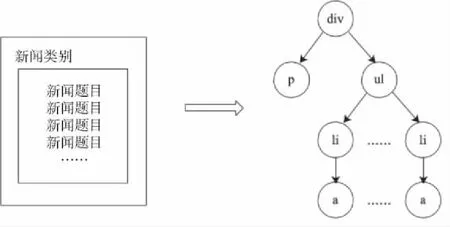
图2 新闻网站链接聚集型结构与对应DOM树案例图
由此可见,对于类别差异较大的网站,其网页结构各具特点,这些特点在一定程度上为网页类型的判别提供了支持。
3 模型构建及算法流程
本文提出了如图3所示的融合压缩DOM树结构向量的行为类别标签预测模型。
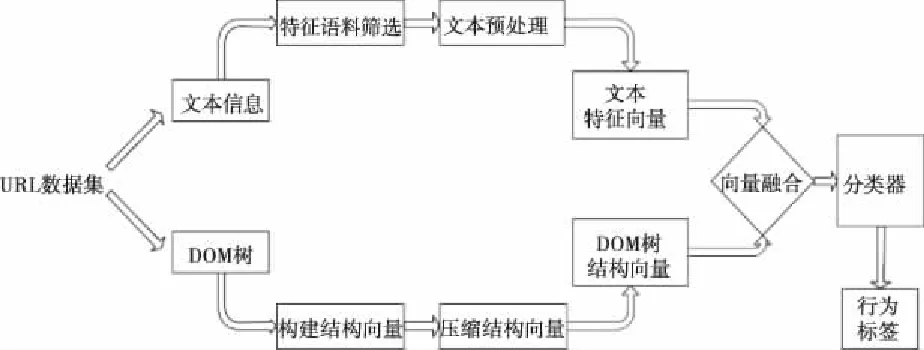
图3 融合压缩DOM树结构向量的行为类别标签预测模型
模型构建过程主要分为文本特征向量生成、DOM树结构向量生成以及向量融合三个部分,融合后的向量即可通过分类器进行分类。
3.1 文本特征向量生成
本部分旨在通过对网页中的关键信息进行合理利用以达到生成文本特征向量的目的,因此应充分挖掘其中最能表达网页特征的元素。传统做法通常是使用爬虫程序获取网页中全部标签内的文本并以此进行词向量模型的构建,这种做法存在明显缺点,因为全部文本信息中必然存在大量的噪声元素,例如用户在购物网站中浏览了一篇运动主题文章,则最终结果极可能将行为标签预测为“运动”类别。为了增强预测准确性,本文在深入研究网页结构及元素后,将表2所示的网页标签元素作为语料信息。
本文选取4类网页标签内容作为语料输入信息。需要说明的是,当网页中标签数量不足50个时,则从第一个标签开始,依次将标签中的内容写入空余位置,直至补全所有空位。另外,少量编写不规范的网页不包含所选两类标签,此时将随机选取5个标签中的内容写入对应位置,以平衡每段文本的信息量。
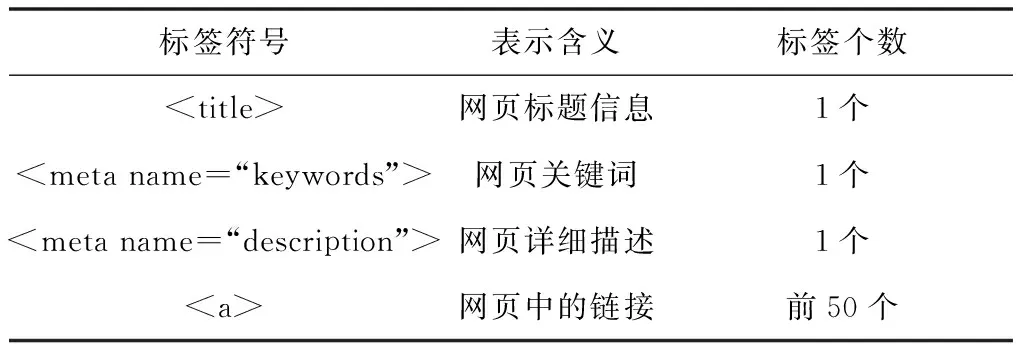
表2 文本语料提取信息
以上述文本语料为基础,将文本进行分词操作以保证文本被切割为最小单词形式,并对其中不具有特征的词进行去停用词过滤处理,然后将语料信息作为样本,使用词向量模型进行词向量的训练,从而得到文本中每一个词所对应的词向量。
而在表示整段文本特征向量时,传统方法通常使用词向量均值模型,将文本中所有词的词向量加和取平均后,作为整段文本的特征向量,即

(1)
其中()表示词的词向量,()表示文本的特征向量,为文本的词数量。
上述方法可以在不同文本之间词数量不相等的情况下,以相同维度的向量表征文本。但该方法也存在明显的缺陷,即在未考虑每个词重要程度的情况下,为所有词赋予了相同的权重,这与实际情况是违背的。故本文根据文献[9]所提方法,结合TF-IDF原理,计算每个词的权重,并在引入权重后进行加权平均,最终表示整段文本的特征向量,过程如下:
首先计算词频
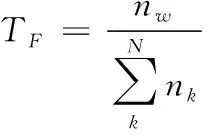
(2)
式中为特征词在文本中出现的次数,为文本中特征词总数,则可以衡量特征词在文本中的重要程度。
然后计算逆文本概率

(3)
式中为文本总数,为包含特征词的文本数,则可以衡量特征词在所有文本中的重要程度。
结合式(2)和式(3)可得,特征词权重为
-=×
(4)
因此,引入词权重的文本特征向量表示方法可由式(1)改写为
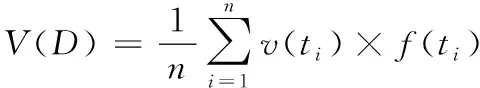
(5)
由上式即可构建考虑词权重的文本特征向量。
3.2 DOM树结构向量生成
上文提到,不同类型网站中的网页DOM树在节点使用和整体结构上都具有一定特点,因此可将DOM树的结构转化为向量,并作为辅助条件与文本特征向量融合,构建成最终的融合向量。
本文在参考相关文献[10-12]并对各类网页的DOM树结构进行深入考察和统计后发现,网页DOM树结构中出现标签的类别一般较为固定且网页核心内容的DOM节点深度一般为5-10层,最多不超过15层,因此筛选了如表3所示的出现频率最高的非

表3 DOM树结构中14类频率最高的标签
在上述研究的支持下,进行DOM树结构向量的构建。需要提出的是,在文献[13]中,作者使用了类似的思路,提取网页中的全部DOM树结构,并构建20维向量。但该方法未对向量做任何处理,以0-1标注的形式表示标签出现位置,未考虑在单一网页中相同结构出现频次的问题以及在不同网页间各类结构总数的差异问题,且未过滤出现次数较少的结构,因此该方法必然导致向量数目巨大且不统一。
本文所提方法对DOM树结构进行了二次压缩,能有效降低向量冗杂度并筛选出高频向量,改善上述方法中的缺点。本文将DOM树结构向量初始维度设置为15维,并在此向量中按DOM树的节点顺序以
=[,,…,]
(6)
当多次重复出现相同结构时,可将该结构进行压缩简化表达,则在向量末尾追加一维从而构成16维向量,向量可改写为:
=[,,…,,]
(7)
而在通常情况下,网页中的结构有几种或十几种,均以不同频次出现,则可初步将DOM树结构的全部向量表示为矩阵形式:

(8)
根据(8)构建出的结构向量具有明显特点,即都以多个
例如如下向量:
[1,1,1,1,8,3,2,0,0,0,0,0,0,0,0,108]
在经过上述转化过程后成为
[8,3,2,0,0,0,0,0,0,0,0,0,0,0,0,108]
即去除了所有的起始“1”标签编号,将关键项提前,并用“0”补全原向量维数。
另一方面也可以发现,不同DOM树的子结构出现频次差异较大,而出现频次低的往往是网页整体框架或其它非标志性板块。为提取出网页中比例最大、出现最频繁的DOM结构,可再次对向量进行压缩,去除频次低的向量,只保留出现频次最高的前5位。同时,考虑到网页之间的容量差异,将出现频次统一为位次高低形式而不使用比例形式。则此时的DOM树结构向量通式为
[,,…,,5]
[,,…,,4]
[,,…,,3]
(9)
[,,…,,2]
[,,…,,1]
此外,若因网页容量较小而不足以提取出至少5类结构时,则使用0补全后续向量。最后将上述5行向量进行扁平化压缩,得到最终的压缩树结构向量形式为:
[,…,5,,…,4,,…,3,,…,2,,…,1]
(10)
上述压缩树结构向量生成过程如下:
算法1:压缩树结构向量生成算法
输入:遍历后的树矩阵
输出:压缩树特征向量
初始化:123
1)查找中的所有相同项共类,记录每一类中相同项的重复数目、2,…,;
2)根据式(7),将行向量1,2,…,均统一为16维,前15位存放节点标签编号,末位存放对应类别的重复数目,存入1;
3)删除1中每行向量最前方的标签编号“1”,并将每行向量重新补全为16维,存入2;
4)筛选出2中重复数目最多的前5位21、22、23、24和25,存入3;
5)根据式(9),将3中5行向量依照末位数的大小改写为5、4、3、2、1;
6)根据式(10),将3中5行向量压缩为一行并存入;
7)
3.3 向量融合
在得到文本特征向量和树结构向量之后,对向量进行融合,首先设文本的特征向量形式为
=[1,2,…,]
(11)
其中表示文本特征向量的维数,该维数在词向量训练过程中定义。
对应树结构向量形式如(10)所示,为简化表达,将其改写为
=[1,2,…,]
(12)
其中表示树结构向量的维数,在本文中为80维。
则将二者融合后得到融合向量形式为
=[1,2,…,,1,2,…,]
(13)
融合后的向量即可通过分类器进行分类。
4 实验分析
4.1 数据集与实验设置
本文使用的数据集为Amazon数据集和DMOZ数据集。Amazon数据集是在Amazon的Alexa网址排名网站中获取的URL集合,共分为10类,每类3000条,共30000条数据。DMOZ数据集则是在DMOZ网址分类网站中获取的URL集合,也分为相同的10类,每类800条,共8000条。其中数据是使用爬虫程序爬取对应URL而获取的网页所有标签符号及标签内容,爬取过程中已经使用递归方式对每一棵DOM树进行了遍历。类别是在参考网站中的分类类别以及校园网络行为日志中的APP类别后进行整理合并来确定的,分为“游戏”、“影视”、“音乐”、“社交”、“阅读”、“学习”、“购物”、“运动”、“新闻”和“服务”。上述两种数据集均采取4:1的比例划分训练集和测试集。
实验运行的系统环境为macOS Catalina 10.15.3,硬件环境为2.6GHz 六核 Intel Core i7 CPU以及32G 2667MHz DDR4内存,软件环境为Python 3.8.1。
在词向量构建部分,使用jieba分词库进行分词操作,使用整理后的stopwords.txt进行去停用词操作。使用gensim函数库训练Word2vec模型,其中模式sg设置为Skip-Gram,词向量维数size设置为100维,上下文窗口大小window设置为8,最小词频mincount调低为1,其余参数设置为默认值。TF-IDF过程使用Scikit-learn中的CountVectorizer和TfidfTransformer完成。GloVe词向量训练过程使用python-glove库,词向量维数仍然设置为100维。
在分类器部分,分别使用Scikit-learn提供的naive_bayes中的MultinomialNB实现朴素贝叶斯分类,linear_model中的LogisticRegression实现逻辑回归分类,以及svm中核参数少且速度快的LinerSVC实现支持向量机分类。
在评价部分,使用F(F-Measure)值作为评价指标
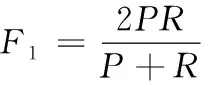
(14)
式中为准确率(Precision),为召回率(Recall),计算公式分别为
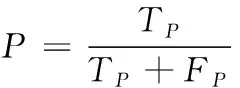
(15)
式中代表被正确分类的样本数,代表不属于该类别却被误分到该类别的样本数
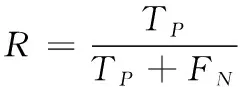
(16)
式中代表属于该类别却未被分入该类别的样本数。
4.2 结果分析
实验共分为两部分。一部分是为了比较使用2均值模型(以下简称)、2+-权值模型(以下简称)以及均值模型(以下简称)三类方法构建出的词向量模型分别进行分类的效果,设置实验的原因在于该模型本身使用了共现矩阵的方法,不仅考虑了词在上下文中的关联度,还考虑了词在全语料中的出现情况,因此将其作为探索性实验以比较其与之间的性能差异。分类器使用了朴素贝叶斯(以下简称)、逻辑回归(以下简称)以及支持向量机(以下简称)。另一部分实验则是在得出、和三类方法中的最优方法后,使用最优方法比较不融合树结构向量(以下简称)、文献[13]中融合未压缩树结构向量(以下简称)以及本文所提融合压缩树结构向量(以下简称)三类方法的效果,分类器仍然使用、和三种。
表4、5和6分别列出了三类不同分类器结合三种不同文本特征向量模型的分类效果平均值,由于在两种数据集上的实验结果差异不大,因此将两者加权平均后得出表中实验数据,本组实验未融合树结构向量。

表4 NB分类器结合Wa、WT及Ga的分类F1平均值

表5 LR分类器结合Wa、WT及Ga的分类F1平均值

表6 SVM分类器结合Wa、WT及Ga的分类F1平均值
从整体上看,无论使用哪种模型组合方式,“游戏”、“影视”、“音乐”和“购物”这4种类型的分类效果较好,而“阅读”“学习”、“运动”和“服务”这4种类型效果不太理想。从文本特征向量模型上看,W模型和G模型相比于W模型均有不同程度提高,W模型的提升率在1.3%~5%之间,提升幅度较为平稳;而G模型的提升率在0.4%~5.7%之间,但表现极不稳定,并且在某些类别上的效果低于W模型。从分类器上看,NB效果一般,LR和SVM均在某些类别上呈现出良好的效果。
图4则是将表中10种类别取平均值后的柱状图对比效果,由图像可以看出,WT模型和Ga模型相比于Wa模型,在最终的平均值上均有不同程度提升,WT模型平均提升率为2.3%,Ga模型平均提升率为1.4%。因此综合考量模型的稳定性和总提升率,决定在下一部分实验中使用WT模型来进行。
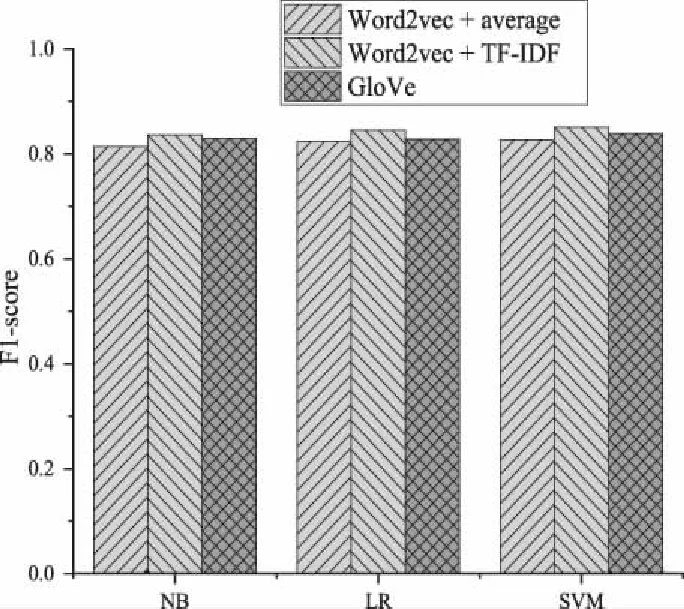
图4 三种分类器结合Wa、WT及Ga的分类F1平均值

表7 NB分类器结合WT、WTD及WTDc的分类F1平均值

表8 LR分类器结合WT、WTD及WTDc的分类F1平均值

表9 SVM分类器结合WT、WTD及WTDc的分类F1平均值
表7、8和9分别列出了三类不同分类器结合三种不同树结构向量的分类效果1平均值,数据使用了数据集和数据集,将两者加权平均后得出表中实验数据。
由数据可知,文献[12]所提WD方法与未引入DOM树结构向量的W方法相比,提升率在0%~3%,提升幅度较为平稳,虽然在某些类别上存在下降趋势,但数值较小,整体上取得了不错的效果。本文所提WD方法与W方法相比,提升率在0.1%~5.3%,提升幅度较为平稳,尤其在“新闻”和“服务”类别上,获得了大幅度提升,但值得注意的是,“阅读”类别存在下降趋势。从分类器上看,仍然是NB效果一般,LR和SVM效果较好。
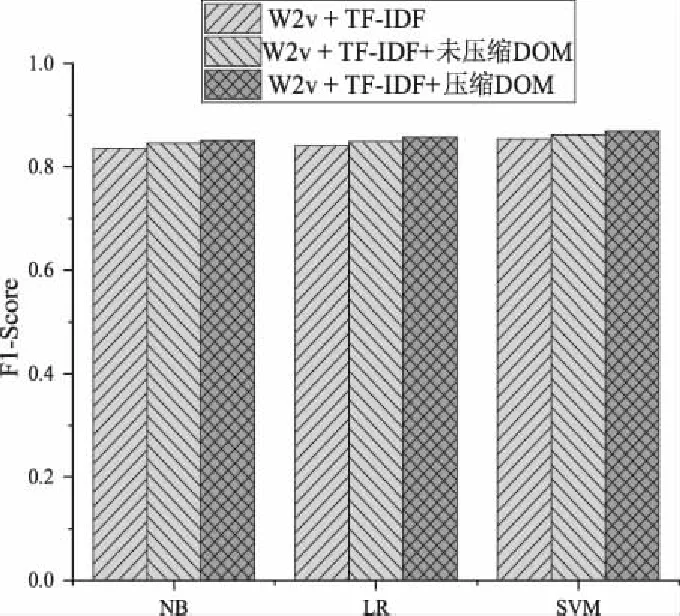
图5 三种分类器结合WT、WTD及WTDc的分类F1平均值
图5则是将表中10种类别取平均值后的柱状图对比效果,由图像可以看出,WD模型和WD模型相比于W模型,在最终的平均值上均有不同程度提升,WD模型平均提升率为0.9%,而本文所提WD模型平均提升率为1.6%。
5 结束语
为了解决现有的校园网络行为日志分析仅考虑文本内容而忽视结构信息,导致对学生行为类别表述模糊的问题,提出了融合压缩树结构向量的行为类别标签预测模型。在生成文本特征时,区别于基于词向量的均值模型,本文为每个词向量赋予不同权重。在生成结构特征时,将树的结构转化为向量,并作为辅助条件与文本特征向量融合,构建成最终的融合向量。实验结果表明,所提的模型的1值相较于比较的方法平均提升率为16,从而验证了算法的有效性。
