基于ConvLSTM机器学习的风暴潮漫滩预报研究
2022-10-22谢文鸿徐广珺董昌明
谢文鸿,徐广珺,董昌明②*
① 南京信息工程大学 海洋数值模拟与观测实验室,江苏 南京 210044;② 南方海洋科学与工程广东省实验室(珠海),广东 珠海 519000;③ 广东海洋大学 电子与信息工程学院,广东 湛江 524088
风暴潮是一种由于剧烈的大气扰动引起海区潮位大幅上涨的现象,也被称之为“风暴增水”“风暴海啸”等。风暴潮是否成灾,主要取决于大气扰动所引起的潮位是否与天文大潮的潮期相叠。台风、温带气旋、寒潮大风等大气现象都可能导致对应海域的风暴潮发生,而根据风暴潮的诱因,通常也会将风暴潮分为温带风暴潮和台风风暴潮两种。本文我们主要讨论台风风暴潮。温带风暴潮的增水较缓,增水高度一般也不如台风风暴潮。台风风暴潮多发生于夏秋两季,来势快且破坏力强。据《中国海洋灾害公报》统计,台风风暴潮所造成的直接经济损失一直位居我国海洋灾害之首。所以,及时、有效地预报和预警风暴潮在国家经济和社会民生方面都具有迫切的需求和重要的意义。
传统的风暴潮预报方式是动力驱动的数值模式预报,需要预报的参数是沿岸水位的变化及其漫滩过程。如:美国国家海洋和大气管理局(NOAA)、美国国家飓风中心(NHC)等部门基于SLOSH(Sea,Lake,and Overland Surges from Hurricanes)模型研究提供风暴潮概率产品和最大可能增水产品等,为政府等部门提供决策支持(Glahn et al.,2009)。海洋与海洋气象学技术联合委员会(JCOMM)等国际组织支持推动下,基于数值模式产品,对风暴潮、海啸等灾害已具备较好的数值预报能力(Kohno et al.,2018)。得益于计算机技术的发展,风暴潮数值预报模式迅猛发展,已发展出多个非结构网格的海洋数值模型包括ADCIRC(The ADvanced CIRCulation model;Luettich and Westerink,2004)、FVCOM(Finite-Volume Coastal Ocean Model;Chen et al.,2006)、SELFE(Semi-implicit Eulerian-Lagrangian Finite Element model;Zhang and Baptista,2008)等。但在现阶段,直接利用数值模式模拟风暴潮漫滩漫堤过程,还存在一定的困难,一方面较难获取精细化的海堤特性、陆地高程、陆地地块属性等基础数据,另一方面对于模拟结果的现场检验缺少调查资料,因此还需要开展大量的工作(侯一筠等,2020)。
直接利用数值模式模拟风暴潮漫滩漫堤过程,需要获取精细化的海堤特性、陆地高程、陆地地块属性等较难获取的基础数据,同时运算高分辨率的数值模式也需要耗费巨大的研究资源和计算时间。针对研究资源和计算时间的消耗,近年来兴起的数据驱动的机器学习预报方法显然更具优势,只需要一次性耗费训练时间,就可以用训练好的模型实现快速地预报。此外,使用机器学习的方法预测还可以在使用过程中不断地优化模型,达到持续强化预报能力的效果。目前机器学习方法已成功应用于气候和气象预测(智协飞等,2020;贺圣平等,2021;黄超等,2022)、海洋特征智能识别(Xu et al.,2019,2021)、海洋参数智能预测(Bethel et al.,2021,2022;Zhou et al.,2021a;刘泉宏等,2022)等一系列研究中,同时机器学习算法的兴起也带来了新的台风灾情预报手段(陈有利等,2018)和更多预报风暴潮的方法,例如:Lee(2006)、Rajasekaran et al.(2008)和Hashemi et al.(2016)将风速、风向、压强等台风要素作为输入,训练人工神经网络(Rumelhart et al.,1986)或是使用支持向量机(Schölkopf et al.,1998)来对风暴潮进行预报。近年来,也有研究者开始使用循环神经网络的方法,以加强时序预报的表现。如雷森等(2017)使用递归神经网络算法对风暴潮进行预报,结果显示,相对于BP神经网络,递归神经网络能得到更好的预测结果,误差更小。刘媛媛(2020)等利用LSTM建立了单个站点的风暴潮临近预报模型,综合考虑气象要素和前时间序列的潮位因素,考虑了四种不同输入参数的组合分析了未来1~3 h的潮位高度。综上所述,在处理风暴潮水位预报问题时,前人普遍都使用了一些统计分析方法或是将机器学习与数值模式结合的方式,将台风的信号如中心最低气压、中心最大风速等信息分解整合到一维,再通过机器学习算法进行风暴潮的水位预报。这些研究取得了一些成效,但是台风在大气中表现出极强的二维场甚至三维特征,对其进行分解整合到一维中难免丢失太多信号,从而使得预报的精度和预报时效性仍有提升空间,而且也只能开展单个站点水位的时序预报。
随着卷积神经网络的兴起,不少研究人员开始将卷积神经网络(LeCun et al.,1998)用于热带气旋的强度研究(金龙等,2020)。如改进各类卷积神经网络从卫星资料中估算热带气旋的强度(Chen et al.,2019;Lee,2019;Wimmers et al.,2019;Zhang et al.,2020),以及利用图形处理单元设计深度卷积神经网络结构,用于热带气旋强度分类(Pradhan et al.,2018)。这些结果表明,卷积神经网络能较好地用于台风强度的判断,说明卷积神经网络有利于台风空间特征的提取,但将卷积神经网络用于风暴潮预测的研究还未见文献报道。这可能是因为卷积神经网络有较强的空间特征提取能力,但在时间序列预报模型中表现不佳。卷积和LSTM结合的ConvLSTM(Shi et al.,2015)的出现解决了这样的难题。有研究学者开始将其用于海洋要素的预报,如Zhou et al.(2021b)将ConvLSTM用于波浪有效波高预报,经过台风海况下的数据集训练,在台风海况下也能完成波浪有效波高的预报。
综上所述,前人使用的机器学习算法在风暴潮的预报研究都还集中在对单个站点的时序预报上,针对风场二维信号的提取和对风暴潮漫滩过程的数据驱动预报还有待开展。通过前人的研究可以发现,卷积神经网络有利于台风特征的提取,而循环神经网络有利于时序预报,而将两者结合的ConvLSTM兼具两者优势。因此,本研究拟使用ConvLSTM网络,开发了两种智能预报模型,一种是提取二维海表面高度场的时序信号进行预报,另一种是提取二维的风场特征,再与初始海表面高度场融合,进行预报。
接下来,本文将分为四个部分展开:第一部分是资料和方法,介绍了本研究中用于训练和检验模型的数据来源,以及所使用的机器学习模型结构;第二部分是结果,分别展示了动力驱动模型FVCOM模式的结果和数据驱动模型ConvLSTM的结果;最后是结论与讨论,介绍我们在研究中所做的一些试验,并得出本研究的主要结论。
1 资料和方法
1.1 资料
本研究中使用的资料包括:台风资料、再分析资料以及验潮站资料。台风资料用于筛选和确认需要使用FVCOM模拟的台风个例,再分析资料用于驱动FVCOM模式,验潮站资料用于验证模式结果;同时,部分再分析资料还会被用于机器学习模型的训练。
1)台风资料
采用的台风资料是中国气象局(CMA)热带气旋资料中心的西北太平洋海域热带气旋最佳路径数据集(Ying et al.,2014;Lu et al.,2021)。该数据集记录了每6 h的台风位置和强度。从2017年起,对于登陆我国的台风,在其登陆前24 h时段内,最佳路径时间频次加密为逐3 h一次。从2018年起,对于登陆我国的台风,除了加密其登陆前的24 h时段,还加密其在我国陆地活动期间的最佳路径时间频次。在本研究中下载整理了1958—2018年热带气旋最佳路径数据集,遍历其中的所有台风,提取影响研究区域(112°~116°E,21°~24°N)的台风信息,包括时间、台风等级、纬度、经度、中心最低气压,近中心最大风速等信息。
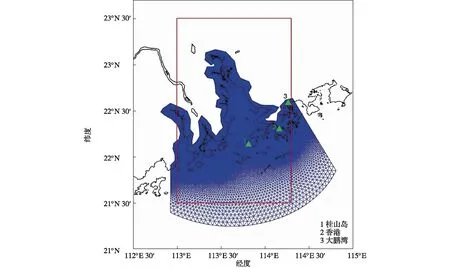
图1 FVCOM模式格点(蓝网格)、验潮站位置(绿三角)和机器学习模型关注区域(红框)Fig.1 FVCOM model mesh (blue grid),tide-gauge stations (green triangles) and interested region for mechine learning model (red box)
2)再分析资料
在本研究中使用了两套再分析资料,包括美国国家环境预测中心(NCEP)气候预报系统再分析(CFSR)资料和欧洲中期天气预报中心(ECMWF)提供的ERA-40再分析资料,时间分辨率分别为1 h和6 h。根据模拟需求,我们主要收集了风场和气压场要素。根据资料的时间范围不同,NCEP提供了两个版本的再分析资料,其中CFSR再分析资料集覆盖的时间范围是1979年1月1日—2011年1月1日,CFSv2再分析资料集覆盖的时间范围是2011年1月2日—2019年12月1日。而ERA-40资料则可以覆盖1979年以前的时间,可以追溯到1958年。
3)验潮站资料
收集和整理了研究区内三个验潮站的实测水位数据用于与模式模拟结果的验证。本研究主要收集了2013、2018年珠江口海域三个站点的潮汐数据,包括桂山岛(113.49°E,22.08°N)、香港(114.10°E,22.18°N)和大鹏湾(114°E,22.35°N)。潮位站的分布如图1所示。
1.2 方法
在本研究中利用有限体积近岸海洋环流模型(FVCOM)建立风暴潮数值模型,模拟生成的台风过程历史后报数据经过验证后被用于机器学习模型的训练、验证和测试。机器学习模型使用的是ConvLSTM模型。关于模式和机器学习模型的更详细设置在下文中介绍:
1) FVCOM
本研究以珠江口以及临近海域为主要研究区构建风暴潮数值模型,利用FVCOM模式模拟了过去60年(1958—2018年)间袭击珠江口的79个台风引起的风暴潮过程。这些台风过程的筛选是通过CMA的西北太平洋海域热带气旋最佳路径数据集完成的。通过判断热带气旋是否出现在研究区域,并结合其持续时间和强度等因素综合考察。FVCOM采用的是有限体积法,这种方法综合了有限差分和有限元模型的特点,既可以与浅海复杂岸界拟合,又便于离散差分原始动力学方程组,从而保证较高的计算效率。其采用的方程积分形式以及先进的计算格式,对于具有复杂地形岸界的计算问题可以更好地保证质量的守恒性。引入了干湿网格处理模块,可以对近岸滩涂、潮间带的涨潮和落潮过程进行精确模拟。本研究模拟区域的空间范围为112.8°~114.8°E、21.2°~23.2°N。模式采用的三角网格由SMS模型(Surface-Water)制作,开边界和陆架区域的三角网格水平分辨率为5 km,近岸区域以及潮间带区域的网格分辨率为200 m,向陆地延伸大约10 km,模型网格如图1所示。陆地高程和水深地形数据来自GEBCO数据集(The General Bathymetric Chart of the Oceans;Kapoor,1981),空间分辨率为10′,模拟区域网格共有53 058个节点和104 850个元素,河流开边界有10个节点,外海开边界有198个节点。
模式受到了海面上时间变化的风和气压的强迫,在开边界上设置了潮汐,模拟了海表面高度以及气压变化引起的逆气压效应。其中1979—2018年的海表面风和气压数据来源于CFSR和CFSv2全球再分析数据集的10 m风场数据和气压场数据;1958—1978年的海表面风和气压数据来源于ECMWF的ERA-40全球再分析数据集。模拟区域开边界的潮汐,来源于OTIS(OSU Tidal Inversion Software)/TPXO7.2预报的潮高,包括16个分潮。河流开边界上添加的径流数据来自珠江干流和主要支流水文站(石角、高要、博罗、潮安)测得的月平均气候态径流量数据。模式垂向均匀分10层,时间步长内模为12 s,外模为1.2 s,每小时输出一次,主要模拟海表面高度、流场、以及沿岸地区的漫滩过程。
2)ConvLSTM
本研究中风暴潮漫滩机器学习算法预报是基于ConvLSTM模型开展的。ConvLSTM是从传统长短时记忆网络(Long Short Term Memory,LSTM)演变而成的用于二维预报的深度学习模型。传统LSTM在时序数据问题上已经被广泛应用,但是在面对二维数据时,若将输入展开成全连接层处理不仅会耗费巨大的计算资源,并且难以捕获到二维空间场的空间相关性以及空间特征。ConvLSTM将LSTM中的矩阵乘法换成了卷积操作,使之在面对二维数据预报时有更好的性能,在一个单元格内的具体表达式为:
=(*+*-1+∘-1+);
=(*+*-1+∘-1+);
=∘-1+∘tan(*+*-1+);
=(*+*-1+∘+);
=∘tan()。
其中:代表输入门;代表遗忘门;表示输出门;表示当前时刻的状态;-1表示上一时刻的状态;表示最终的输出;表示权重系数;表示相应的偏置系数;为sigmoid函数;∘代表哈达玛乘积;*代表卷积。卷积操作可以很好地提取数据的空间特征,而LSTM可以很好地提取数据的时间相关性,因此ConvLSTM同时具备了时序建模和刻画空间特征的能力,适用于一些时空相关性较强的物理量预报中。
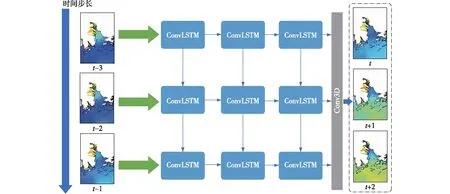
图2 基于ConvLSTM建立的风暴潮智能预报模型结构示意图Fig.2 Schematic diagram of storm surge intelligent prediction model based on ConvLSTM
基于ConvLSTM神经网络建立的风暴潮智能监测模型结构如图2所示。本模型中将三个连续时间步长的海表面高度场数据作为输入数据,分别通过三层ConvLSTM层,最后经过一层3维卷积层输出未来某个时刻的海表面高度(Sea Surface Height,SSH)信息。该模型每一层都使用ReLu作为激活函数以提高模型的非线性表达能力,循环步骤使用sigmoid作为激活函数。同时,为了模型能够更好地刻画不同空间尺度的特征,将四层的卷积核分别设置为5×5、3×3、3×3和5×5,以平衡训练参数的数量和模型感受野。为了保证模型的输出结果分辨率和输入的一致,在卷积的过程中我们并未加入池化层或上采样层,并使用填充设置使得中间过程生成的特征图大小一致。上述网络结构的设置所参考的是前人研究的基于ConvLSTM的台风浪有效波高预测模型(Zhou et al.,2021b)。ConvLSTM最后会输出3 h的预报场,它和对应时刻的FVCOM模式模拟结果间会存在误差。我们使用均方根误差作为损失函数,从而完成模型的构建。由于FVCOM模拟的是漫滩的过程,网格会有干湿网格之分,因此ConvLSTM也能从中学习到漫滩信息,从而实现漫滩预报。通过这样的网络设置,可以较为容易从FVCOM模拟的结果中生成样本,每个样本的输入是起报时刻前3 h的SSH,标签是后3 h的SSH。将FVCOM模拟得到的历史台风数据集,通过此方式进行样本制作,可以得到9 000多个样本。将这些样本按照8∶1∶1的比例划分为可以得到训练集、验证集和测试集。在训练过程中,使用了Adam的优化方式,如果经过多个轮次训练后验证集的损失值仍未下降,则停止继续训练。通过这一过程,得到了基于ConvLSTM的漫滩预报模型,其在测试集中的表现会展示在结果中。
上述的构建方式实际上是完成了SSH的自回归,因为并没有在其中直接输入大气强迫或其他信号。在这样的构建方式下,我们对模型期望是它能从输入的SSH场中推算出大气强迫可能对其造成的影响趋势,从而进行预测。为了实现更好的预报,我们尝试搭建了第二个模型,在输入中加入了海面风场的信号,结构如图3所示。为了方便描述,在下文中将这一模型称为模型二。模型二的结构与在卷积核的选择上与上一模型保持一致,但在第3层的ConvLSTM层中不再按照所有时序输出,仅输出最后的时序。相应的,接收这一特征图不再需要3维卷积层(Conv3D),使用2维的卷积层(Conv2D)即可完成调整。在模型二的输入中,使用了4个时序的输入,前3个为未来3 h的海面风场,最后一个为当前时刻的SSH,输出则是未来第3小时的SSH。这样的设置是处于两个方面的考虑,一方面是模仿数值模式的驱动方式,利用初始场和时间变化的风场驱动;另一方面是在实际的业务预报中,相较于3 h的SSH,海面十米风场的预报要更容易获得,其精度和分辨率都较高,而想获得高时空分辨率的SSH数据几乎是不现实的。在这样的模型设置下,在训练和测试的过程中,除了要使用FVCOM模拟的结果外,还加入驱动FVCOM的海表面风场数据。我们尽量确保了驱动FVCOM模式的海表面风场资料和“驱动”模型二的资料是一致的,以免产生额外的误差使得训练难以进行。在训练的过程中,使用的损失函数和优化方案分别是平均绝对误差(Mean Average Error,MAE)和Adam,训练至验证集损失值多轮次不下降后停止训练,然后再使用MSE作为损失函数,利用SGD的优化方式继续训练,再次训练至验证集的损失值多轮次不再下降后停止训练。

图3 模型二的结构示意图Fig.3 Schematic diagram of Model 2
2 FVCOM模拟结果
尽管FVCOM模拟的结果会关乎机器学习模型的训练质量,FVCOM模拟的是否准确至关重要,但对模式模拟结果的验证并非本研究的重点,所以在此只展示模式模拟的某个台风过程作为验证示例。以2013年1311号台风“尤特”为例,该台风于2013年8月8日在菲律宾以东的西太平洋上生成热带低压,并逐渐向西北方向移动;于8月12日穿过菲律宾进入南海海域并增强至台风等级,进一步向中国大陆移动;于8月14日06:00(世界时,下同)左右在广东省阳西市附近沿海登陆,登陆时中心附近最大风力14级(42 m·s),登陆时中心气压955 hPa,其登陆前期给广东各市带来了大风和强降水;登陆后其强度迅速减弱并最终消亡。图4展示了该台风8月13—14日CFSv2再分析资料中的风场和海表面气压信息,这一时间段很好地捕捉到了台风进入研究区域到登陆时的过程,可以明显看到台风明显影响了珠江口以外的南海北部海区,在海上移动过程和登陆期间,其外部风圈覆盖住了珠江口,因此我们将这一台风过程选为驱动FVCOM模式模拟的历史风暴潮漫滩过程之一。
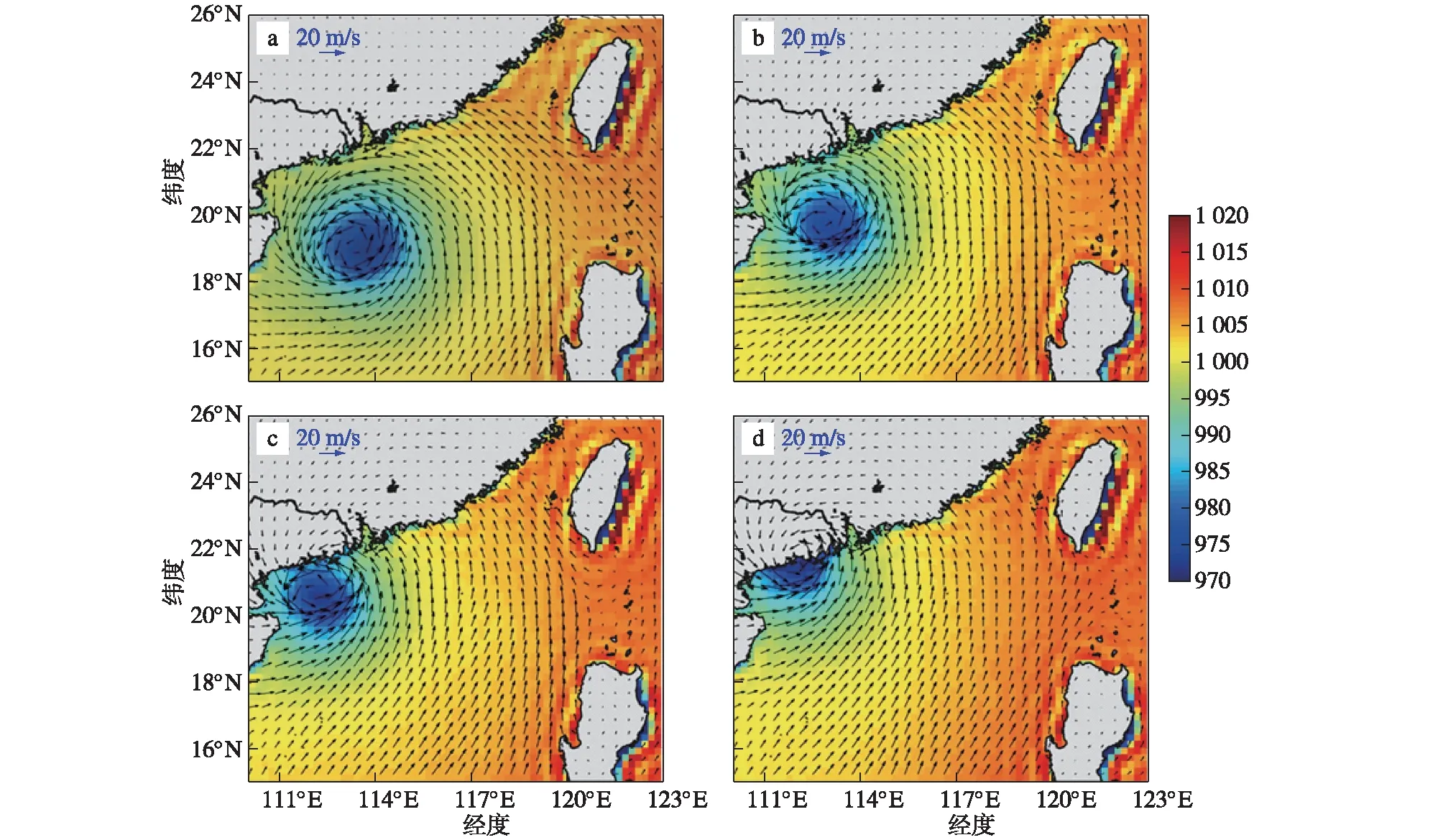
图4 1311号台风“尤特”的海表面风场(箭矢;单位:m/s)和海平面气压场(彩色区域;单位:hPa):(a)13日12时;(b)13日18时;(c)14日00时;(d)14日06时Fig.4 Sea surface wind field (arrows;units:m/s) and sea level pressure field (color areas;units:hPa) of Typhoon Utor (1311):(a)1200 UTC 13;(b)1800 UTC 13;(c)0000 UTC 14:(d)0600 UTC 14
图5描述了FVCOM模式模拟的1311号台风“尤特”在珠江口引起的风暴潮过程,与图4所展示的时刻相对应。模式此时已经经过7 d以上的稳定过程,消除了初始场的影响,并且大气和潮汐的驱动信号都可以被完全相应。虽然台风并没有直接在珠江口区域登陆,但其外围风圈还是对珠江口区域造成了影响,引发风暴潮增水和漫滩过程,在模式中被较好地模拟了出来。随着台风不断地靠近陆地,珠江口的水位不断增长,尤其风暴潮增水叠加天文潮在深圳与东莞交界处引起了漫滩过程,漫滩区域水位最高达到1.3 m左右;台风登陆后,沿岸的水位也随之退去。
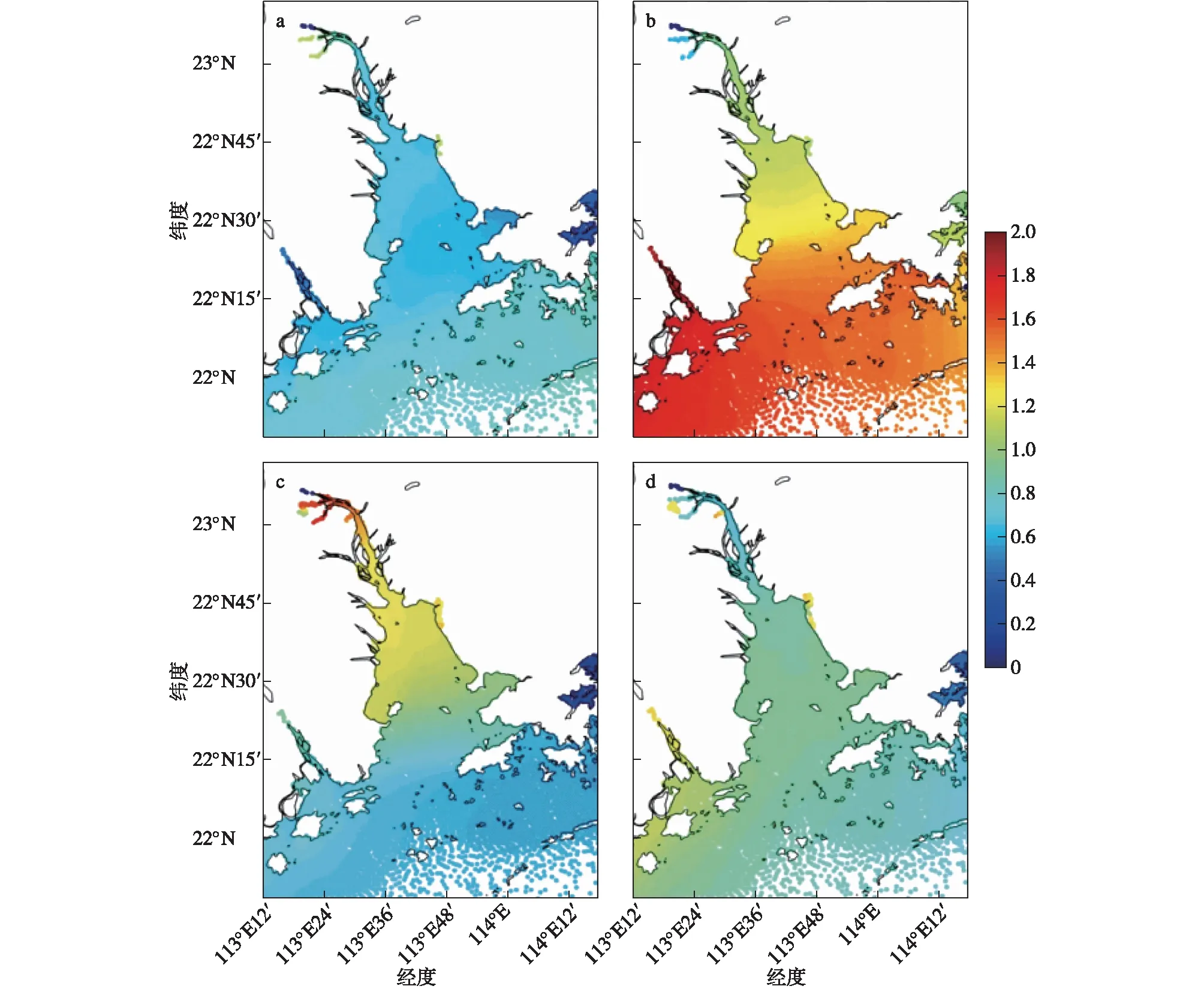
图5 FVCOM模式模拟的1311号台风“尤特”登陆前后的海表面高度变化(单位:m):(a)13日12时;(b)13日18时;(c)14日00时;(d)14日06时Fig.5 Sea surface height changes before and after landing of Typhoon Utor (1311) simulated by FVCOM model (units:m):(a)1200 UTC 13;(b)1800 UTC 13;(c)0000 UTC 14;(d)0006 UTC 14
为了验证模式模拟的结果,将FVCOM模式模拟的海表面高度与沿岸潮汐站点(大鹏湾、香港、桂山岛)的实测数据进行比较(图6)。发现FVCOM模式模拟的结果与潮汐站点实测的水位不仅相位一致,振幅也相差不大。桂山岛、香港、大鹏湾潮汐站(分布见图1)分别于8月13日18:00、19:00和19:00观测到台风引起的风暴潮增水,水位分别达到0.54、0.75和0.45 m,FVCOM模式结果也得到了响应的风暴潮增水过程,桂山岛、香港和大鹏湾潮汐站实测与模拟结果的相关系数分别为0.95、0.96和0.95,均方根误差分别为0.12、0.10和0.1 m。桂山岛和香港站点分别位于珠江口的中部和东部,模拟结果较好地复现这两个验潮站的增水过程可以在一定程度上说明,从珠江口进出的水体总量在模式中模拟得比较准确。通过把FVCOM模拟的结果与这些站点资料进行比对可以说明,FVCOM的模拟能较好地复现台风来临时SSH升高以及漫滩的过程。
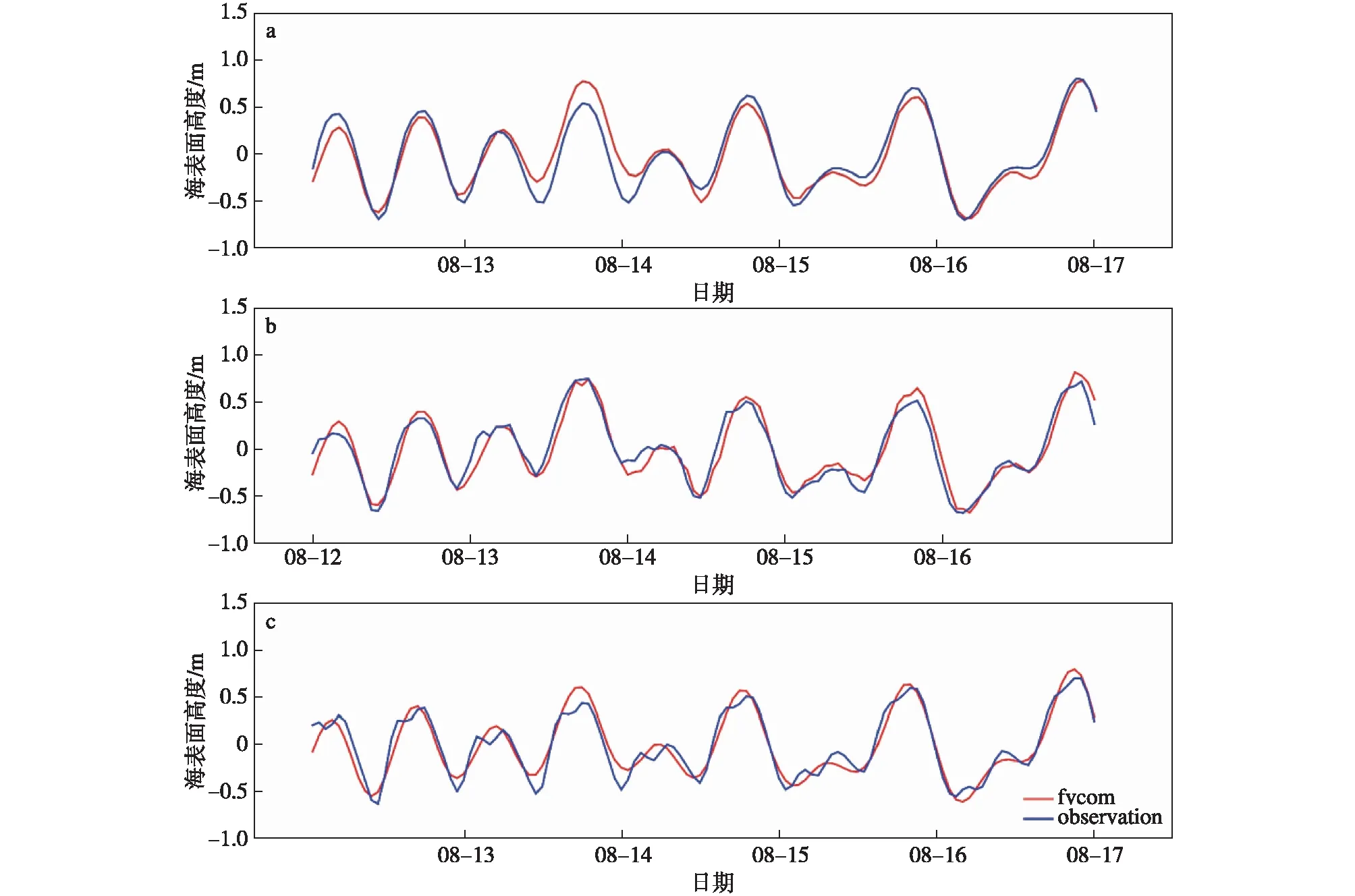
图6 桂山岛(a)、香港(b)、大鹏湾(c)潮汐站观测的每小时海表面高度变化(蓝色)及FVCOM模式结果(红色)Fig.6 Hourly sea surface height changes from tide-gauge observations(blue) and FVCOM model results(red) at (a)Guishan Island,(b)Hongkong and (c)Dapeng Bay
3 ConvLSTM测试结果
上述FVCOM的验证结果可以说明,FVCOM模拟的结果具有一定的准确性,可以用于机器学习模型训练。依照方法中提及的数据集制作方法,制作了ConvLSTM的训练集、验证机和测试集。ConvLSTM经过训练集数据的训练,训练至验证集的损失函数值不再下降后停止训练。将训练好的模型用于测试集测试,在测试集中取得了不错的表现。以1995年9月1日13—15时的预报结果为例展示于图7。在这一样本中,在近岸沿海区域发生了较大范围的漫滩,而珠江口外部也呈现出海面高度上升的趋势,是一个典型的风暴潮漫滩过程。可以看出,ConvLSTM能较好地捕获海表面高度的动态变化特征,能做出和FVCOM相似的海面高度分布预测。在漫滩区域的预报方面,ConvLSTM也能较好地模拟出和FVCOM几乎一致的海水蔓延上陆地的区域,漫滩的数值预报上与FVCOM相比也能维持在低于0.2 m的差,只在少数个别地区误差达到0.4 m左右。在较为开阔的海域,对于2 h和3 h的预报误差并没有显著增大,反而有些区域存在误差减少的情况。但在沿岸和发生漫滩的区域,误差随着预报时间的推移有所增加。在此个例的1 h预报中,ConvLSTM在绝大部分区域都低估了SSH;而在2 h的预报中,ConvLSTM则轻微高估了漫滩区域的海水高度;至3 h,低估和高估的情况并存。这一结果说明了ConvLSTM模型的预报并不是普遍偏小或偏大。
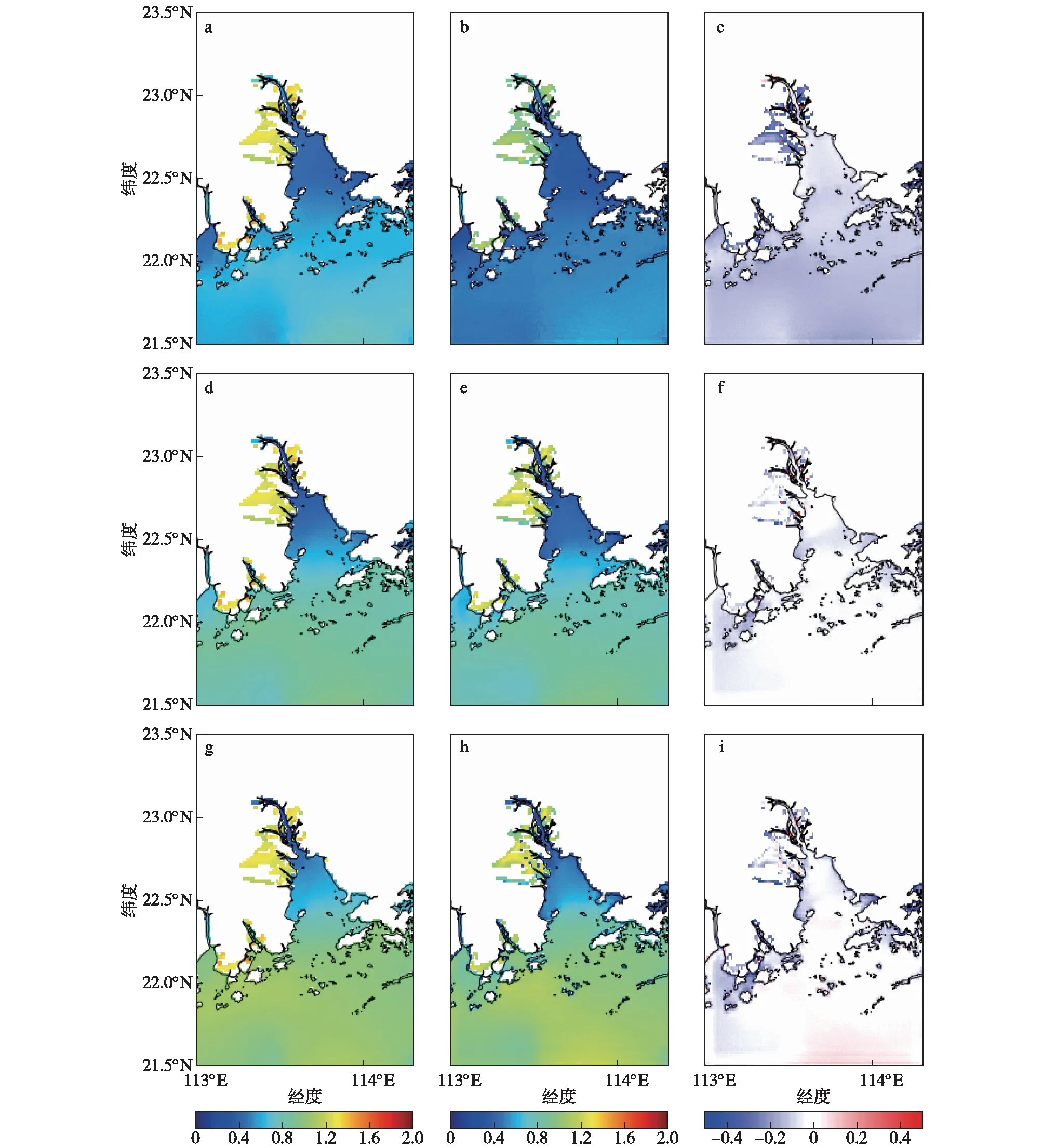
图7 FVCOM(a、d、g)与ConvLSTM(b、e、h)的漫滩预测结果及其差值(c、f、i;ConvLSTM减FVCOM):(a、b、c)1 h;(d、e、f)2 h;(g、h、i)3 hFig.7 Floodplain prediction results of (a,d,g)FVCOM and (b,e,h)ConvLSTM,and (c,f,i)their differences (ConvLSTM minus FVCOM):(a,b,c)1 h;(d,e,f)2 h;(g,h,i)3 h
为了进一步评估考察ConvLSTM模型在全部测试样本中的预报能力,我们在所有测试样本中分别计算了ConvLSTM的3 h预报结果与FVCOM之间的绝对误差,并求样本平均得到了两者间MAE的空间分布(图8)。从图8中可以看到,对于珠江口和珠江口以外的相对开阔的海域,误差分布比较均匀,普遍维持在低于0.2 m的范围内。这表明模型对于大部分区域的SSH变化模拟效果都较好,且不会存在明显的空间差异。而对于漫滩区域,ConvLSTM模型也做出了较好的预报,大部分区域的误差也能维持在0.4 m以下。更多的误差是集中在沿海近岸的河流入海口两侧。
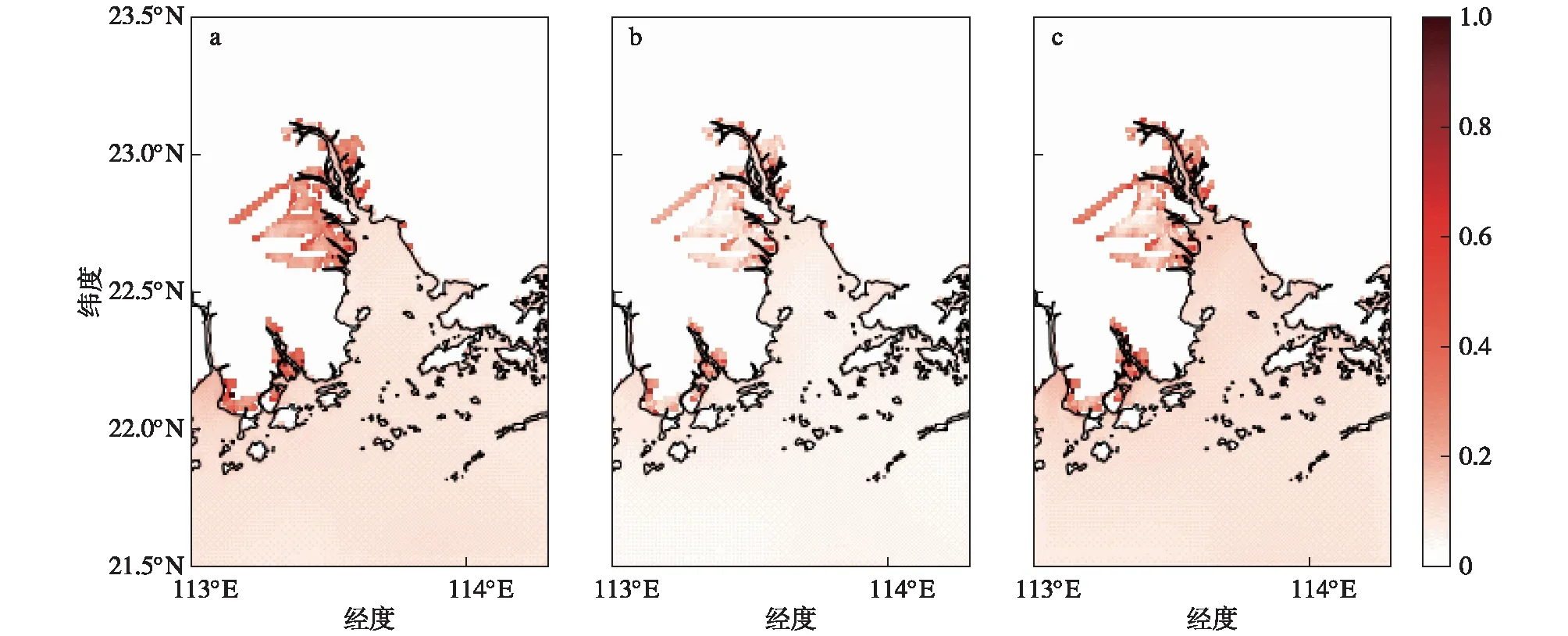
图8 ConvLSTM预报样本平均绝对误差的空间分布:(a)1 h;(b)2 h;(c)3 hFig.8 Spatial distributions of mean absolute error (MAE) from ConvLSTM predictions:(a)1 h;(b)2 h;(c)3 h
将图7的误差结果和图8结合对比后可以发现,所选取的这一样本符合所有样本的平均水平。但在边界区域,存在一定的特异性。从图7可以看到,ConvLSTM模型在对于这一边界的预报上表现得并不是很好,尤其是在南边界中,出现了较为突兀的线状预报结果。研究认为这样的误差来源于关注区域以外的驱动。由于训练和测试模型用的区域都是从FVCOM中切割出来的,如果在区域以外发生了较大的变化,但是信号仍未能传输至区域内无法被ConvLSTM捕捉到,那在边界上则可能会发生较大的误差。换言之,图7中的FVCOM结果是带有边界条件的,而ConvLSTM对于边界上所做的预测都是基于区域内的信号做外推得来的。但从图8可以看到,这样的误差并没有显著发生在所有的样本中,可以相信在绝大多数的条件下,尽管缺失有效的边界条件,ConvLSTM模型也能在边界上做出较为准确的预报。
在上述的研究中,需要在机器学习预报的模型中考虑的因素还较少,下面讨论加入新驱动因素对预报结果的影响。当研究风暴潮漫滩过程时,同时还有很多因素的影响:天文潮汐、波浪、海流或降水等(Kohno et al.,2018)。但是,使用和开发数据驱动的机器学习模型的其中一个重要原因是因为其轻便,如果需要完全加入考虑到的各种因素,其使用难度会不亚于一个动力学预报模型。每一个因素的加入都需要大量的数据进行训练,需要耗费大量的计算和存储资源,所以研究的目标是:在保障一定准确性的前提下,使用尽量少的变量因素实现预报。但出于实验完备性的考虑,尝试加入了海面十米风场的信号,以初步试验加入更多因素对预报结果的影响。在风场资料中,台风的近中心最大风速是台风强度的重要判据之一,台风风圈范围可提取出台风的半径信号,这些因素都可能直接或间接地对预报结果产生影响。
依照模型2的构建方式,将驱动FVCOM的10 m风场资料也加入了机器学习模型的输入中,试图从中获得大气信号并对预报结果进行一定的改善。模型2针对未来第3小时的SSH预报样本平均绝对误差如图9所示,误差计算的方式与结果部分的一致。对比图9与图8可知,加入风场信息后,误差的分布更为不均匀,在少部分较开阔海域,模型2的误差有些许减小,但对于极大部分的区域,模型2并未能显著减少误差,反而会稍有增大。对于漫滩区域,两个模型的表现结果几乎一致,没有太明显的差距。而对于误差较大的近岸沿海和径流两侧的区域,模型2也未能对其进行较为有效的改进,有些区域还存在误差增加的情况。这从侧面印证了这些误差的主要原因还是来自海洋要素,风场的加入无法提供有效的信息支撑,而随着SSH输入时长的减少,模型能从中提取出潜在包含的径流和地形信息更少,导致这些区域的误差进一步增大。
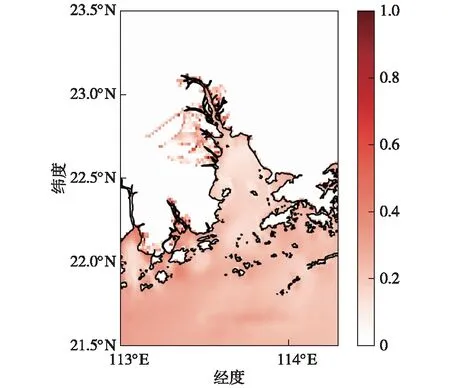
图9 模型二预报样本MAE的空间分布(单位:m)Fig.9 Spatial distribution of MAE from Model 2 predictions (units:m)
4 结论和讨论
在本研究中,分别使用了动力驱动的数值模式FVCOM和数据驱动的机器学习模型ConvLSTM进行了风暴潮的漫滩预报研究。使用ERA-40和CFSR再分析资料驱动FVCOM,模拟了历史影响珠江口的台风过程,以此构建供机器学习模型训练的数据集。通过上文展示的结果,可以得出结论,经过训练后的ConvLSTM模型可以很好地复现FVCOM模拟的漫滩情况,对漫滩的区域和SSH分布可以做出较好的预测。相较于动力驱动模型的复杂,ConvLSTM显得更为轻便,在边界条件、地形、径流和大气驱动信号都未知的情况下,仅需要3小时的SSH输入,就可以做出较好的短临预报。尽管在缺失边界的条件的情况下,在某些个例中会出现边界区域预报较差的情况,但这并非是普遍存在于所有样本中,在样本平均的误差分布中,在边界上并无明显的增加。因此可以得出结论,ConvLSTM能较好地完成包括边界在内的全场预报。ConvLSTM的预报的误差主要集中在近海沿岸区域,尤其是河道两侧。推测这是由于地形和径流资料的缺失所导致的。实际上,精细的海堤特性、陆地高程、陆地地块属性等资料的缺失也一直是制约更高分辨率的风暴潮漫滩数值模式发展的原因之一。ConvLSTM在没有地形资料支持的情况下仍能做出较为准确的漫滩预报,给了一定的启发性,说明使用数据驱动的预报模型,可以在一定程度上忽视漫滩预报中精细地形资料的需求。
尽管使用自回归模型进行预报已经在模型二的研究中,选用了风场作为新增输入以考察增加大气要素对模型预报结果的优化效果。结果显示,风场的加入并没有对预报结果有较好的改善。为了进一步探讨产生这一结果是归因于过多的无效信号引入还是归因于大气信息的输入不足,研究构建了一个新的模型使其可以输入海表面气压场(Sea Level Pressure,SLP)。在已有的模型二的输入端,每一个时序的输入都加入了新的通道。在模型二中输入风场的层,都会和SLP在通道维上堆叠共同输入,原SSH输入则保持不变。模型的卷积核大小、个数、层数、激活函数和输出等均与模型二保持一致。将这个双通道输入的能提取SLP信号的模型称之为模型三。利用和模型二一致的训练策略,仅在数据集中加入对应驱动数值模型的SLP,得到了模型三。将模型三运用于增加了SLP的测试集进行测试,其样本平均MAE空间分布如图10所示。
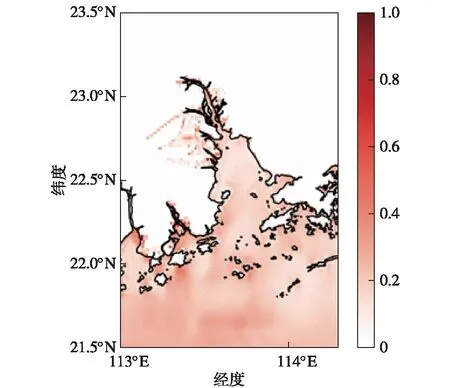
图10 模型三预报样本MAE的空间分布(单位:m)Fig.10 Spatial distribution of MAE from Model 3 predictions (units:m)
与其他两个模型的误差分布区间较为相似地,图10展示的模型三样本平均MAE也都在普遍低于0.2 m部分可达0.4 m的程度。通过对比图9和图10可以发现,模型二和模型三的样本平均MAE分布非常相似,仅在少许区域模型三的误差有所减少。显然,增加SLP作为预报因子,并不能有效提高模型二的预报水平。这个实验说明,一味地增加大气信号也并不能对此数据驱动模型再有较好的改善作用。在信号缺失的条件下,利用大气驱动加海洋初始场的预报并不能优于针对漫滩过程的自回归预报。
综上所述,在本研究中,主要基于ConvLSTM机器学习算法进行风暴潮漫滩预报研究,可以采用两种预报方式,一种是基于SSH的自回归预报,另一种是依赖大气信号和初始海表面高度场进行预报,基于SSH的自回归预报效果更优。相较于传统动力学数值预报,其结构更为轻便,所需要的驱动数据更少,在缺少边界条件、地形、径流等信号时,仍能基本复现模式模拟的结果,可以供业务部门用作短临预报的参考。通过讨论发现,企图导入更多的因素至数据驱动模型中并不一定能显著地提升其漫滩预报水平。如何在数据驱动的预报模型中以更少的数据导入更多的信号,从而更有效地训练模型,还需要进一步地研究。
NCEP、ECMWF提供了CFSR、ERA资料的在线下载服务,Kenny T.C.Lim Kam Sian先生为本文数据获取和英文写作提供了帮助。谨致谢忱!
