基于SVMFE的往复压缩机气阀故障诊断方法
2022-10-21李纯辉马永财徐国林赵海洋赵海峰
李纯辉,马永财,徐国林,赵海洋,赵海峰
(1.黑龙江八一农垦大学工程学院,黑龙江大庆 163319;2.东北石油大学机械科学与工程学院,黑龙江大庆 163318)
往复压缩机振动信号呈现出非平稳、非线性的特性,且故障信号中包含着大量的噪声信号,直接提取故障特征难度较大,如何有效地提取出往复压缩机的故障特征是目前往复压缩机故障诊断的热点和难点。随着非线性理论的发展,众多学者对非线性分析方法的研究已逐渐成熟,分形维数、混沌时间指数、Lyapunov指数及信息熵等分析方法被提出[1-7],目前已广泛应用到往复压缩机故障诊断中。Zhao等[8]提出基于多重分形的SVD故障特征提取的方法,实现了对往复压缩机轴承间隙定量描述;赵海峰等[9]提出基于奇异值与近似熵划分阶段的方法来提取故障数据,得到了分段后信号的近似熵更具有相对一致性;针对近似熵在熵值计算中存在自身匹配的问题,Richman等提出了样本熵[10],样本熵在避免自身匹配问题的同时,在相对一致性上更为优秀,能够衡量序列的无规则程度。样本熵在信号复杂程度的描述上比较单一,不能全面地反映出不同尺度下的特征信息,Costa 等[11]在样本熵的基础上提出多尺度熵,用以描述不同元素在多尺度因子下的序列的结构复杂程度和自身之间的相关性。陈伟婷[12]在深入研究样本熵的理论基础上,针对样本熵中存在的问题,将模糊集的基本概念与样本熵有机地结合,提出了带有模糊集的熵,即模糊熵。模糊熵与样本熵相比,熵值变化波动较小,不会存在突然失去熵值的问题,连续性和相对一致性方面都更优越。在模糊熵的基础上,郑近德等[13]借鉴多尺度熵的思想在模糊熵概念的基础上提出了多尺度模糊熵。
MFE 集合了多尺度熵与模糊熵的所有主要优点,无论是在描述序列的完整性上还是相对一致性上均更加优越,且不受数据长度的限制,拥有所需数据短,相对一致性高等特点。但MFE在粗粒化计算过程存在以下问题:
(1)MFE 的粗粒化计算是基于均值的计算方法,这仅能反映出序列的平均幅值,缺少对信号波动性的描述;
(2)忽略相邻点信息,数据长度变短,稳定性降低,故障信息不完整。
针对问题(1)本文将方差法代替均值法引入到粗粒化计算中;针对问题(2)本文将滑动法代替粗粒化计算。故本文提出基于滑动方差的多尺度模糊熵。最后将SVMFE 与ELM 相结合,提出一种基于SVMFE 与ELM 的往复压缩机故障诊断方法,将其应用于气阀故障数据的分析。实验结果表明,本文所提方法能有效地实现气阀故障诊断,具有较高的故障识别率。
1 SVMFE算法
1.1 MFE算法
MFE的计算步骤如下[13]:
(1)对时间序列xi={}x1,x2,…,xN,建立粗粒序列:
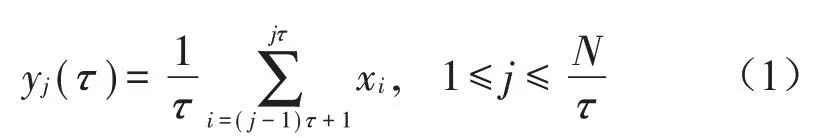
其中:τ为尺度因子,当τ=1 时,yj(1)为原序列。对于非零τ,原序列被分割成每段长为N τ的粗粒向量yj(τ)。以τ=2 为例,粗粒序列计算方式如图1所示。
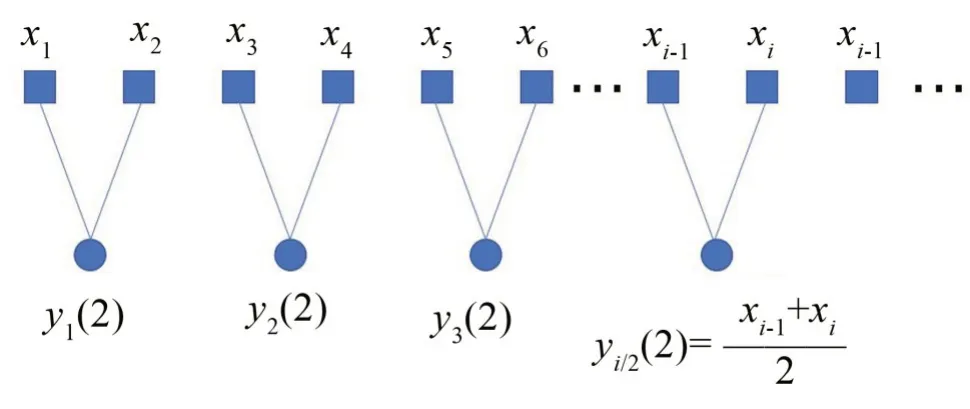
图1 τ=2时粗粒序列计算分割图
(2)根据文献[13]中对模糊熵的定义,分别计算每个τ下序列的模糊熵值,称为多尺度模糊熵。
由式(1)的粗粒化计算可以看出,粗粒序列的长度随着尺度因子的增大而变短,稳定性会降低,熵值的偏差也会随之变大。从图1可以看出,当τ=2时,粗粒化序列的计算为x1和x2,x3和x4,…,xi-1和xi等之间的信息,忽略了x2和x3,x4和x5等之间的信息,导致故障信息不完整。而粗粒化计算过程实质上就是计算数据间的均值,只能反映出序列的平均幅值,忽略了信号中的波动性。针对多尺度模糊熵存在的上述缺陷,本文将滑动方差法引进到粗粒化计算中,提出基于滑动方差的多尺度模糊熵(SVMFE)方法。
1.2 SVMFE算法
SVMFE算法的具体步骤如下:
(1)对时间序列xi={}x1,x2,…,xN,建立粗粒序列:
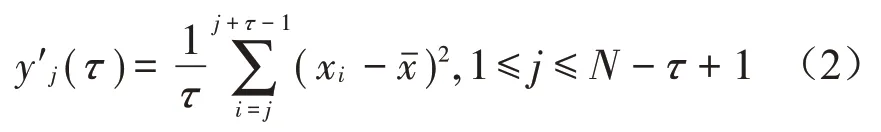
在上式中,当τ不等于1或0时,序列xi被分割成τ段长度均为N-τ+1 的粗粒向量yj′(τ)。以τ=2 为例,SVMFE中粗粒序列计算方式如图2所示。
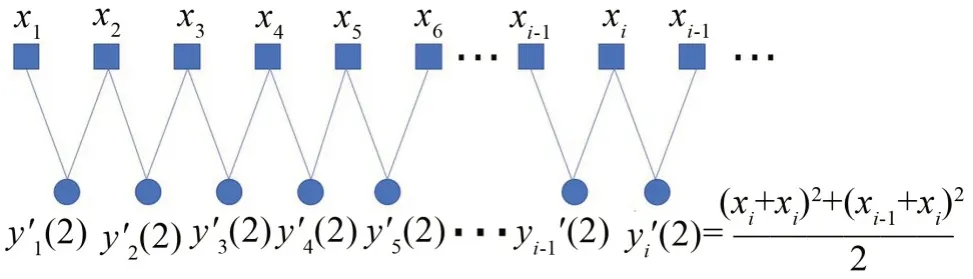
图2 τ=2时SVMFE算法的粗粒序列计算分割图
(2)对新序列yj′(τ)分别计算每个τ下粗粒序列的模糊熵,得到基于滑动方差的多尺度模糊熵,定义如下:
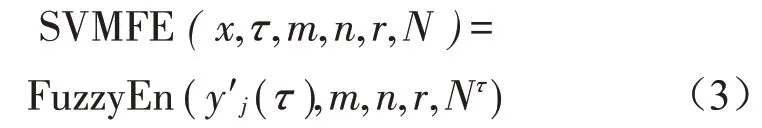
由式(2)的粗粒化计算可以看出,粗粒序列的长度与原序列相比变化小,稳定性高,熵值偏差较小,而且SVMFE算法考虑了序列中相邻数据间的信息,避免信息泄露,同时展现出了原序列的波动性。
2 SVMFE方法仿真分析及方法对比
2.1 参数选择
根据SVMFE的定义,其计算所需参数如下:
(1)嵌入维数m。文献[9]表明嵌入维数越大,序列需要重构的信息越多,所需序列的长度就会越长(数据长度N的选取范围为10 m 至30 m)。故出于综合考虑,避免数据不足,维数m选为2。
(2)数据长度N。文献[13]已证明在模糊熵计算中,熵值结果受数据长度N影响比较小,所取数据的长或短,都可以定义出模糊熵值,故本文便不再赘述数据长度对SVMFE 值的影响,数据长度N取2 048。
(3)相似容限r。r为函数原始时间边界的最大宽度,r过大会使统计信息冗杂,选择过小使统计效果不好。r的大小选取在0.1 SD 和0.25 SD 之间(其中SD为原始数据的标准差),本文中r选为0.15 SD。
(4)梯度n。梯度n决定了相似容限r的梯度,n过小会使细节信息过多,统计效果不理想,n过大会使细节信息的丢失。文献[14]中建议在计算时n取较小的正整数,如2或3。本文梯度n选为2。
(5)尺度因子τ。为了保证粗粒序列的长度不能过短,所以τ的选择不能过大。一般情况下取τmax≥10,本文取τmax=20。
2.2 仿真对比分析
为体现SVMFE在特征提取上的优越性,将其与MFE 对比,并采用数据长度为2 048 的高斯白噪声为研究对象,首先以相似容限为0.1 SD、0.15 SD、0.2SD 及0.25 SD 计算两种方法的在不同尺度下的模糊熵值,其中m=2、n=2、τmax=20,结果如图3至图4所示。
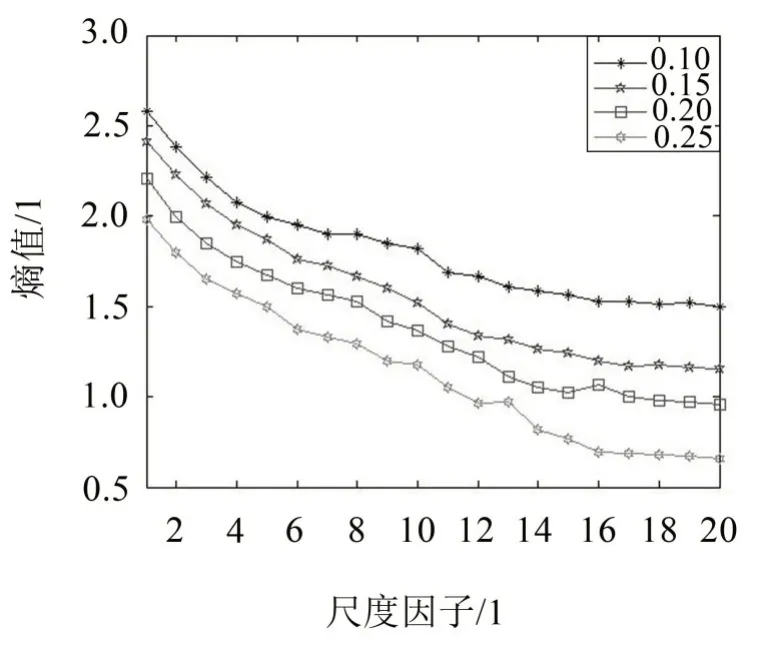
图3 高斯白噪声在四种相似容限下的MFE
由图3、图4 可以看出,两种方法计算熵值的结果均受到相似容限的影响,都满足r增大熵值变小的情况;但SVMFE 的熵值曲线与MFE 相比明显更光滑,且不同相似容限下的熵值更接近,说明受相似容限的影响更小。此外可以看出,r的取值大小会直接影响序列的描述情况,通过综合考虑,本文r取0.15 SD。
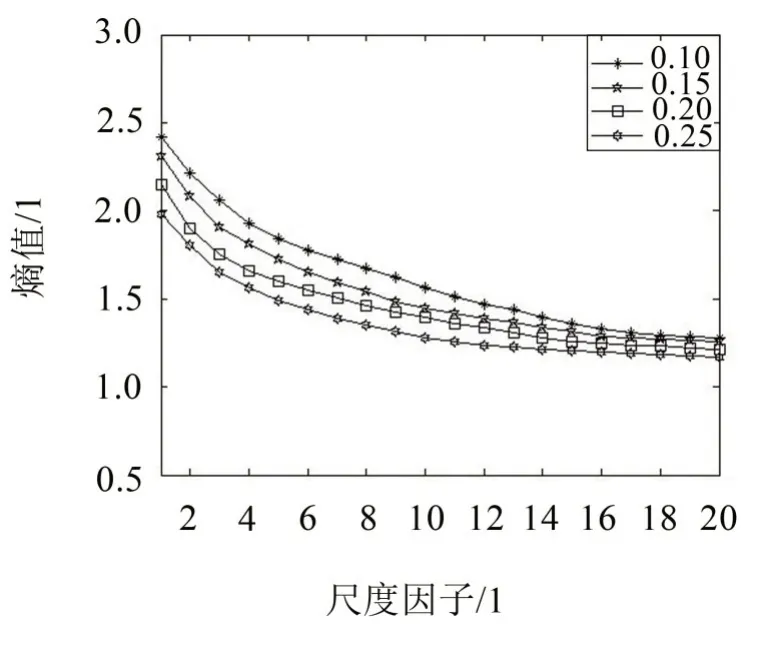
图4 高斯白噪声在四种相似容限下的SVMFE
为了更明显地说明SVMFE 的优越性,选定r=0.15 SD、m=2、n=2、τmax=20 的参数条件下,计算高斯白噪声在不同尺度下的MFE 值与SVMFE 值,两种方法计算得到的熵值随τ的变化如图5所示。
图5 SVMFE和MFE方法下高斯白噪声的模糊熵值
由图5 可以看出,两种方法的得到的熵值曲线变化趋势相同,均是先随着尺度因子的增大,熵值变小,然后趋近于稳定,两个曲线的光滑性都在减弱,但SVMFE 曲线在尺度因子较大时才出现波动,而MFE 曲线出现波动的位置明显更加靠前,说明SVMFE 的稳定性更好。综合以上分析结果表明,SVMFE 与MFE 都能描述时间序列的复杂性,但SVMFE 受相似容限的影响较小,熵值曲线更光滑,波动更少,说明SVMFE方法在衡量序列复杂性上更准确、更稳定。
3 基于SVMFE的气阀故障诊断
3.1 方法流程
通过以上分析,本文提出基于SVMFE与极限学习机的气阀故障诊断方法。具体流程如下:
(1)设置k种气阀故障状态,将每种状态信号随机分为训练集和测试集,对所有数据计算SVMFE,选取合适数量的SVMFE值作为特征向量。
(2)从每种状态的特征向量中随机选取i个,作为ELM分类器的训练样本,剩余特征向量作为测试样本。
(3)将训练集中各个状态的特征向量输入到ELM 中训练,得到ELM 训练模型,然后将测试集中的特征向量输入到ELM中识别故障类型。
(4)根据ELM 分类器的输出结果实现气阀故障诊断。
3.2 实验信号分析
本文的研究对象为2D12-70型双作用对动式往复压缩机,对气阀故障进行研究,主要参数为:轴功率500 kW、排气量70 m3/min、活塞行程240 mm、曲轴转速496 r/min。模拟了弹簧失效、阀片断裂和阀片缺口三种常见故障,在气阀阀盖处布置传感器测定振动信号,采集正常和故障两种振动信号,信号采样频率为50 kHz。设置了四种状态:弹簧失效、阀片断裂、阀片缺口以及正常状态,每种状态的样本数取40个,四种状态共计160个,而每个样本的数据长度均为2 048。四种状态的时域波形如图6所示,
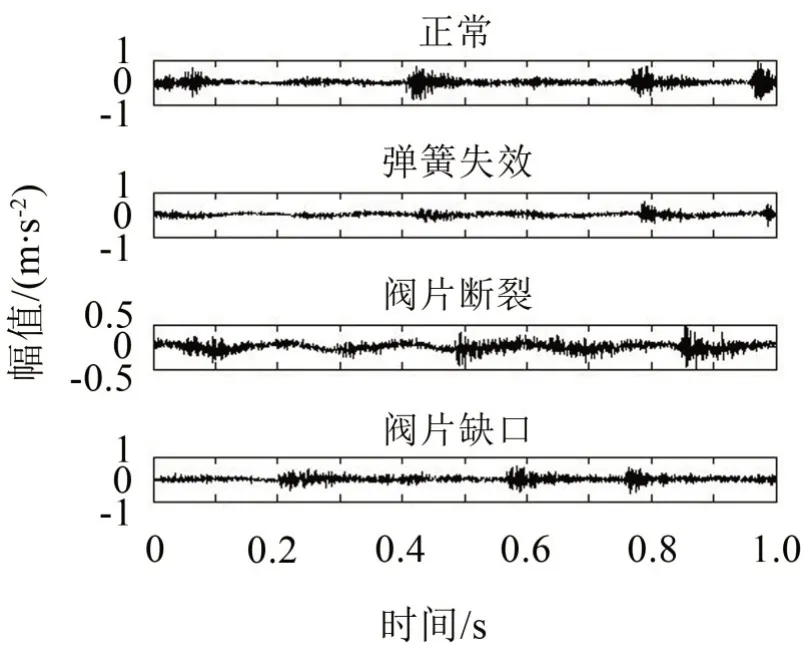
图6 气阀四种状态振动信号的时域波形图
计算所有样本的SVMFE值,每种状态在不同尺度因子下的SVMFE值如图7所示。
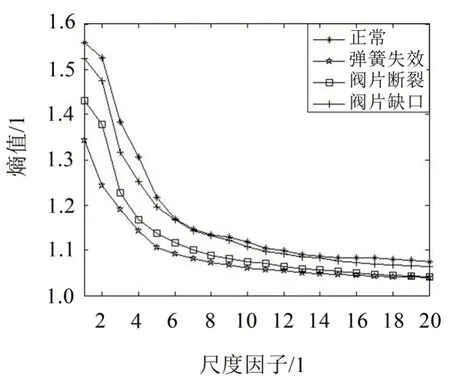
图7 气阀四种状态振动信号的SVMFE值
由图7 可以看出,四种状态振动信号的SVMFE值随尺度因子变化的趋势大体相同,均是在第一到第六个尺度急速下降,之后缓慢下降趋于稳定。在大部分尺度上,四种信号的SVMFE 值的大小顺序是:正常>阀片缺口>阀片断裂>弹簧失效。此外,在尺度因子较大时,四种状态的SVMFE 值差别较小,还出现交叉和重叠的现象,如果将大尺度下的SVMFE值作为特征向量,虽然也能大体区分故障类型,但容易出现信息冗余,不利于状态的分类识别,导致故障信息不能充分描述。结合图7 的SVMFE值曲线,四种状态的前五个尺度对应的SVMFE值区分明显,故本文选取每种状态的前五个尺度因子对应的SVMFE 值作为样本的特征向量,并采用ELM对这些特征向量进行分类,以实现气阀各种状态的分类和识别。其中,ELM 的激活函数选Sigmoid 函数[15],隐层神经元的数目设置为25。首先,从每个状态下随机抽取10个样本作为训练集,另外30个为测试集,具体信息如表1所示。其次,将训练样本输入到ELM 中进行训练。最后将测试样本输入到训练好的ELM中进行识别,结果如图8所示。
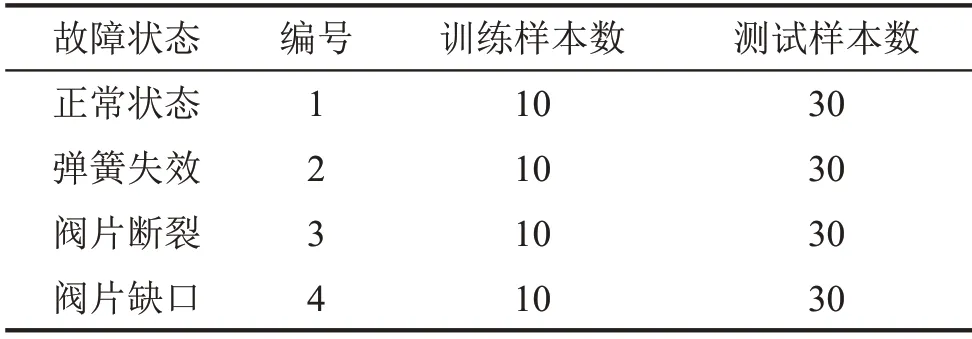
表1 训练和测试实验数据列表
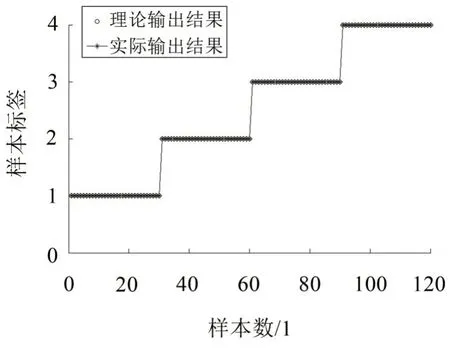
图8 基于SVMFE与ELM的识别结果
由图8 中可以看出,实际的输出结果与理论结果完全相同,故障识别率为100%(120/120),说明本文所提方法能有效地识别气阀的故障类型。
为了更好地验证SVMFE 方法在特征提取上的优越性,将其与MFE 进行对比,计算160 个样本的MFE值,取每种状态前5尺度因子的MFE值作为特征向量,输入到相同的ELM 分类器中训练和测试,识别结果如图9所示。
由图9 可以看出,基于MFE 的特征提取方法总计有三个样本被错误识别,一个弹簧失效被错分为阀片断裂、一个阀片断裂被错分为弹簧失效,一个阀片缺口被错分为正常,故障识别率为97.5 %(117/120)。
SVMFE 与MFE 方法的故障识别结果如表2 所示,当气阀为正常状态时,两种方法的故障识别率均为100%,说明二种方法都能够准确地识别出气阀的正常状态;对于其他三种状态,SVMFE 方法的故障识别率依然为100%,而MFE 方法出现错分。结果表明SVMFE 方法无论是在整体上还是个别状态的识别率均优于MFE 方法,验证了SVMFE 方法在特征提取上的优越性。
为了研究训练样本数是否会对气阀故障识别率的结果产生影响,选择训练样本数为:5、10、15、20、25 和30 进行训练,训练和测试的数据与上文相同,故障识别结果如表3所示。
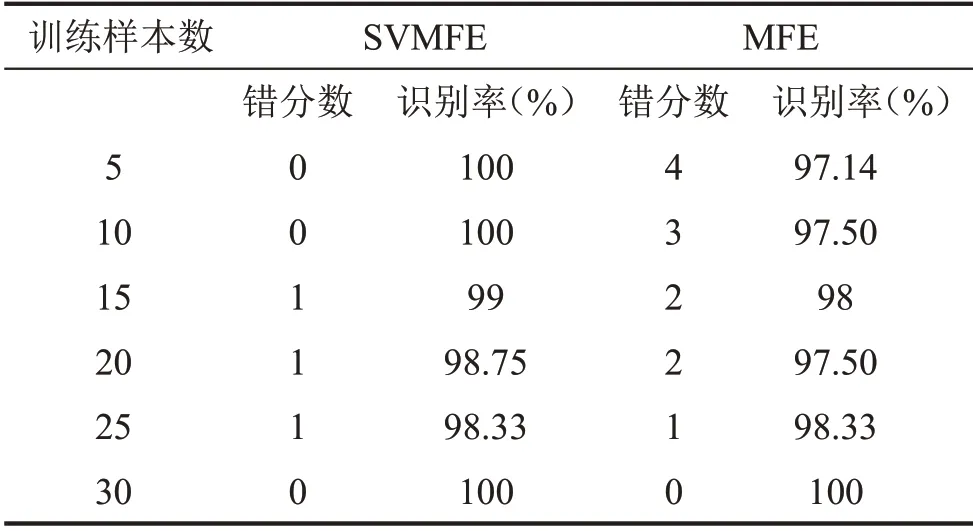
表3 不同训练样本数两种方法的识别结果
通过在不同样本数下,两种方法的对比可以看出,SVMFE 方法在样本数为5 和10 时,错分数为0,识别率为100%,远高于MFE方法;当样本数逐渐增加时,SVMFE 方法出现错分,识别率降低,而MFE方法的错分数逐渐减少,故障识别率增高,当样本数为25时,两种方法的识别率相同,当样本数为30时,两种方法识别率为100%。说明无论训练样本数是多或者少,SVMFE方法的故障识别率均高于或者等于MFE的,表明基于SVMFE与ELM相结合的故障诊断方法更适用于训练样本小的往复压缩机气阀故障诊断。在大型设备中,往往故障信号采集很困难,训练样本数稀少,该方法能有效地解决小样本的故障识别问题。
为了研究特征向量中熵值的数目是否会对气阀故障识别率的结果产生影响,运用SVMFE 和MFE两种方法计算尺度因子为2 到20 上的熵值,作为信号的特征向量用于气阀故障诊断。训练和测试的数据与上文相同。两种方法在不同特征值数目下的故障识别率如图10所示。
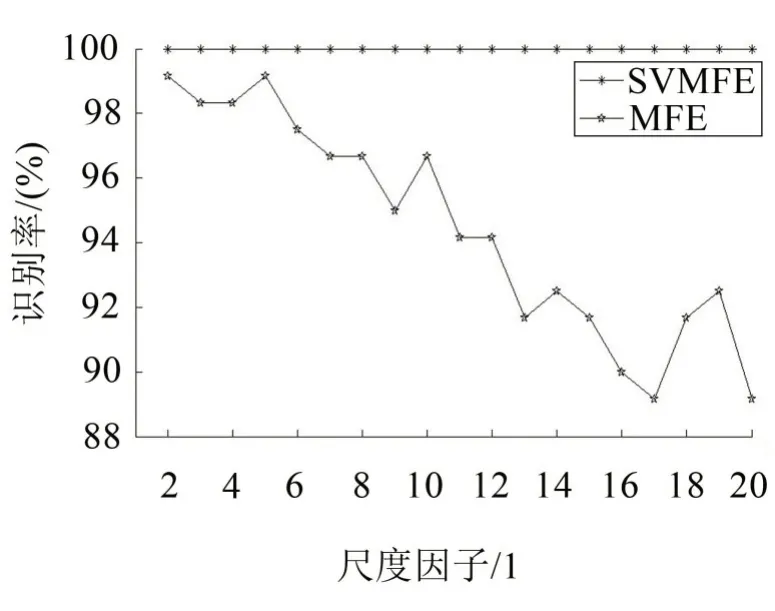
图10 两种方法的故障识别率对比
由图中可以看出,从第2 到20 个尺度因子的熵值作为特征向量,故障识别率均为100%,说明基于SVMFE的特征提取方法,识别率不受特征向量中熵值数目的影响;而基于MFE 的特征提取方法,识别率明显受特征向量中熵值数目的影响较大。这表明SVMFE 方法只需要较小的特征向量就能够完整地反映出故障特征信息,从而有效地实现故障识别。
4 结语
本文提出了一种描述时间序列复杂程度的SVMFE算法,并将其与MFE对比,说明了本文方法的优越性。提出基于SVMFE与ELM的往复压缩机气阀故障诊断方法,通过分析气阀四种状态的实验数据,将其与MFE对比,结果表明SVMFE方法在特征提取时误差更小,结果更稳定,能够全面地描述气阀各种状态的故障信息,同时基于SVMFE 与ELM的方法更适合于小训练样本数据,仅需要较小的特征向量就能够完整地反映出气阀的故障特征信息,且具有较高的故障识别率。综上所述,SVMFE有效地解决了MFE在粗粒化计算中存在的问题,在表征故障特征方面有一定的优势,希望能将它推广到其他机械设备的故障诊断中。
